02 技术视角:你应该知道的LLM基础知识
你好,我是郑晔!
上一讲,我们站在用户视角介绍了LLM,这个视角可以帮助我们更好地理解如何使用大模型。
不过,站在用户视角,我们只能关心到语言输入和输出,而如果要开发一个 AI 应用,我们不可避免地会接触到其它一些概念,比如,Token、Embedding、温度等等,这些概念是什么意思呢?这一讲,我们就从技术的视角看一下大模型,到这一讲的末尾,你也就知道这些概念是怎么回事了。
在出发之前,我要强调一下,我们不是为了打造一个大模型,而是为了更好地理解应用开发中的各种概念。好,我们开始!
技术视角的大模型
站在技术视角理解大模型,核心就是搞懂一件事,大模型到底做了些什么。其实,大模型的工作很简单,一次添加一个词。
怎么理解这个说法呢?本质上说,ChatGPT做的是针对任何文本产生“合理的延续”。所谓“合理”,就是“人们看到诸如数十亿个网页上的内容后,可能期待别人会这样写”。我们借鉴 Stephen Wolfram 的《这就是 ChatGPT》(What Is ChatGPT Doing … and Why Does It Work?)里的一个例子一起来看一下。
选择下一个词
假设我们手里的文本是“The best thing about AI is its ability to”(AI 最棒的地方在于它能)。想象一下,我们浏览了人类编写的数十亿页文本(比如在互联网上和电子书中),找到该文本的所有实例,然后,猜测一下接下来要出现的是什么词,以及这些词出现的概率是多少。
实际上,GPT 做的就是类似的事情,只不过它查看的不是字面意义上的文本,而是寻找在某种程度上“意义匹配”的事物。最终的结果是,它会列出随后可能出现的词及其出现的“概率”(按“概率”从高到低排列):

有了这个带有概率的词列表,我们就会从这些词中选择一个词。接下来,我们再把这个词附加到我们的文本上,再次询问大模型下一个词是什么。本质上,我们生成的一段内容就是这样一遍一遍地询问“下一个词是什么”,不断地重复这个过程。
下面就是一个例子,从这个例子中,我们可以清晰地看到文本不断生成的过程。

这里有一个问题需要澄清一下,虽然我们这里说的是添加一个词,但严格意义上说,每次添加的是一个 Token。Token 就是我们理解大模型编程的第一个重要概念。这个 Token 可能是我们传统理解的一个完整的单词,可能是一个单词组合,甚至可能是单词的一部分(这就是大模型可以“造出新词”的原因)。
Token 的概念在大模型编程中是非常重要的,现在各大厂商的竞争中,有一个很重要的指标就是上下文窗口(Context Window)的大小。这里的上下文窗口,指的就是大模型可以处理 Token 数量,上下文越大,能处理的 Token 越多。能处理的 Token 越多,大模型对信息的理解就越充分,生成的内容就越接近我们需要的结果。所以,现在各个大模型比拼的其中一项就是上下文窗口的大小。
下面是 gpt-4o-mini 的上下文窗口处理的 Token 情况(摘自 Open AI 官网)。

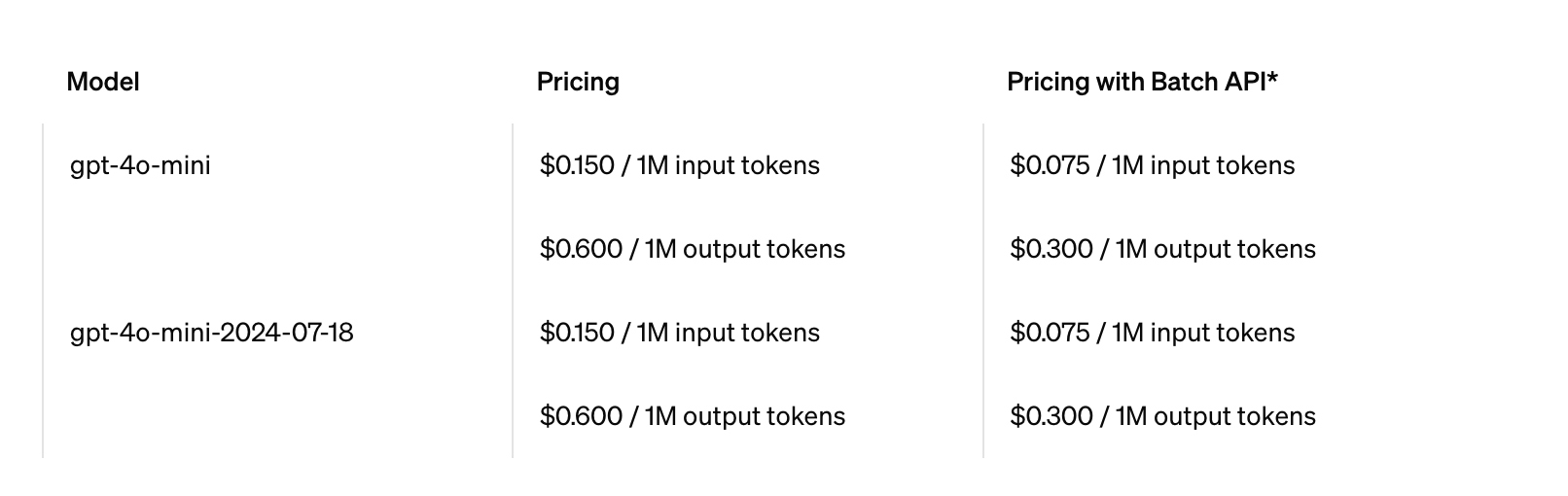
除此之外,Token 还有一个非常现实的作用,就是计费,现在的大模型编程都是根据 Token 进行收费,Token 越多收费越高。下面是 gpt-4o-mini 的的计费情况(摘自 Open AI 官网),可以看出它就是根据 Token 计算的。
引入随机性
好,我们回到内容生成的过程中。前面我们说了,我们会从一个带有概率的词列表中进行选择。接下来,我们需要确定选择哪个词添加到我们的内容中。
有人认为应该选择“概率最高”的词。但是,如果我们总是选择排名最高的词,通常会得到一篇非常“平淡”的文章,完全显示不出任何“创造力”。这就好比你问别人一个问题,他每次都给你同样的回答,你一定会觉得这个人非常的无趣。所以,在选择的时候,我们可以有一些随机性,选择排名较低的词,这样我们就可以得到一篇“更有趣”的文章。
有了随机性,也意味对于同样的提示词,我们每次得到的内容可能会不同。为了达到这样的效果,我们就引入了一个表示随机性强弱的概念:温度(Temperature)。这是大模型编程中另一个重要的概念。
很显然,温度这个概念借鉴自物理学,不过,它和物理学之间并没有实际的联系。站在理解这个概念的角度,你可以认为它是表示大模型活跃程度的一个参数,通过调节这个参数,大模型变得更加活跃,或是更加死板。
在大模型编程中,温度是一个非常重要的概念,温度设定的情况很大程度上决定了大模型给出怎样的表现。在 OpenAI 的 API 中,这个参数越小,表示确定性越强,越大,表示随机性越强,简单理解就是,温度越高越活跃。
下面就是有了“温度”之后,对于同样的提示词,就产生了不同的结果。

到这里,你已经对大模型生成文本的过程有了一个最基本的了解。不过,这里还有一个细节需要解释一下,这里面会牵扯到一个在大模型编程中的另一个重要概念:Embedding。
从字符串到向量
虽然我们给大模型提供的是一个待补齐的字符串,但实际上,在大模型内部处理的并不是字符串,而是向量。之所以要将字符串转换为向量,简单理解,就是现在大部分的 AI 算法只支持向量。
你可能会好奇,为啥不支持字符串呢?因为字符串只是这些 AI 算法的一种输入,我们还可以输入图片、输入视频,甚至各种各样的信息,只要把这些输入都转换成向量,AI 算法都可以轻松地驾驭。由此,你可以知道,交给 AI 算法处理的前提就是把各种信息转换成向量。
理解了向量的意义,接下来的问题就是,字符串是怎样变成向量的?
在大模型的处理过程中,字符串转成向量会经历两个步骤,第一步叫 One-Hot 编码,第二步则是把编码的结果进行压缩。
One-Hot 编码就是将离散的分类值转换为二进制向量。比如,我们有一个颜色的分类值,分别是红(red)、绿(green)、蓝(blue),其编码如下所示:
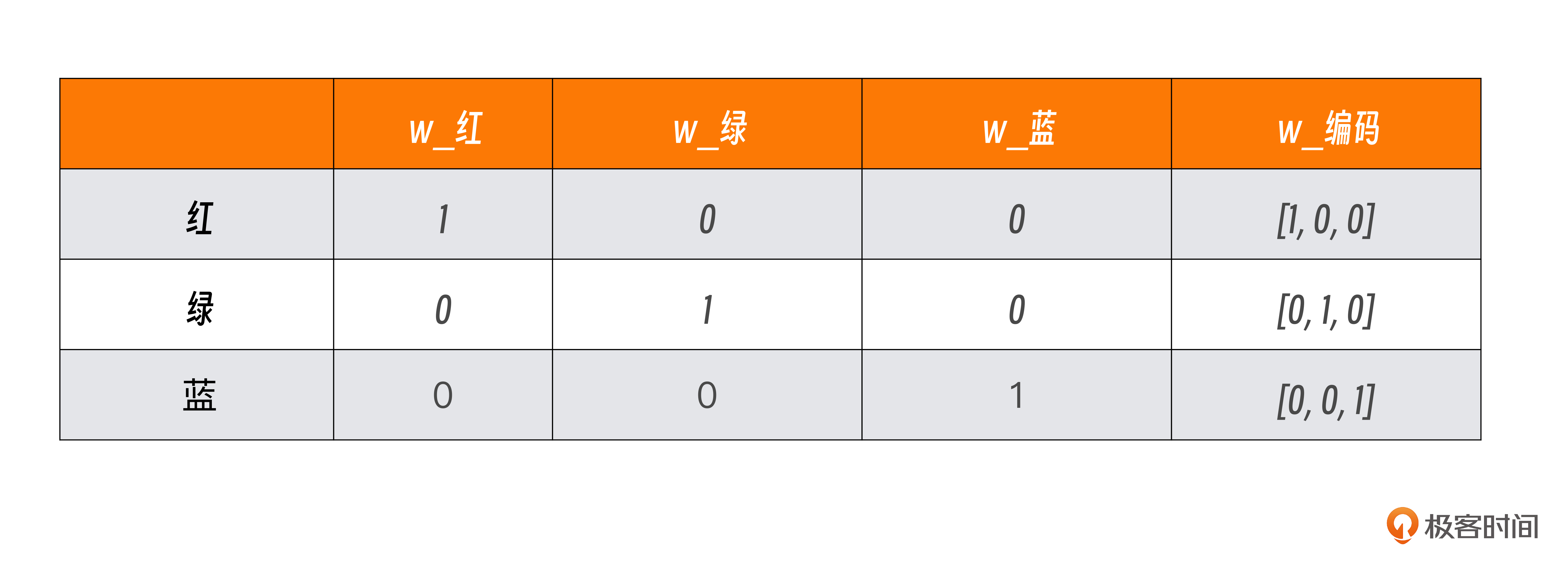
在这个表格中,我们可以看到红绿蓝在向量里各占一位,有值则为 1,没有值对应 0,所以,红对应的向量是[1, 0, 0]、绿对应的是[0, 1, 0],而蓝对应的是[0, 0, 1]。当我们输入是“红绿红蓝”,就会得到对应的四个向量:[1, 0, 0]、[0, 1, 0]、[1, 0, 0]、[0, 0, 1]。这就是最简单的One-Hot 编码.
在大模型中,离散的值是什么呢?就是我们前面提到的 Token。我们把字符串转成 Token 列表,每个 Token 都会自己对应的一个唯一标识,而这个标识就是向量中的内容。你或许已经想到了,在一个有规模的语料库中,Token 数量会非常多,下面是一个示例:
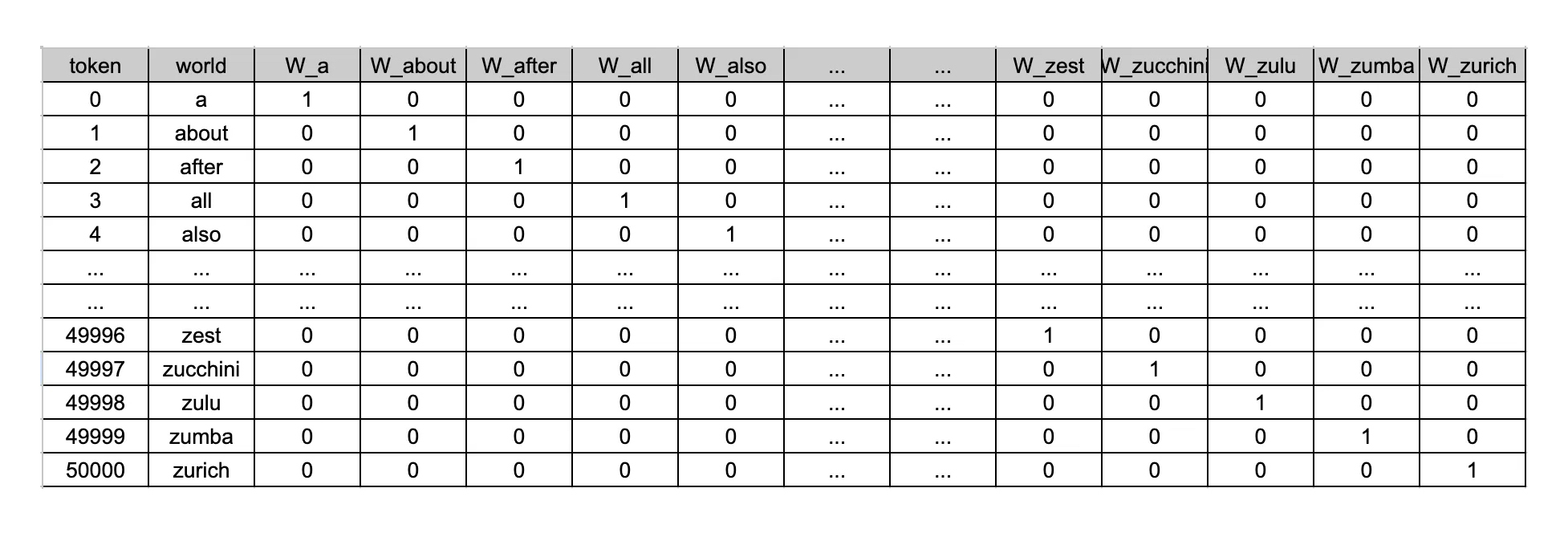
从这个图中,我们就可以看到,这是典型的稀疏存储,也就是说,一个向量中就有大量的 0 存在,真正有含义的位并不多。我们文本中的每个 Token 都会对应一个向量,可想而知,这里面的 0 会有多少。所以,我们会经历下一个处理过程,对这个编码结果进行压缩,得到我们想要的 Embedding。
获取 Embedding 常用的方法有两种,降维和把 Embedding 训练成神经网络。降维的技术有很多,比如主成分分析(Principal component analysis)。但在大模型中,通常使用把 Embedding 训练成神经网络的方法,也就是把我们前一步得到的向量送给一个神经网络,得到最终的压缩过的向量。具体如何训练是一个更为复杂的过程,这不是我们这里关注的重点。
你只需要知道,经过这个处理之后,一个硕大的向量就会压缩成一个固定大小的向量。比如,在 GPT 3 中,每个 Token 都由 768 个数字组成的向量表示。之后,再把压缩过的向量作为输入传给大模型,用来生成最终的结果,这时才轮到我们听说过的神经网络、自注意力机制这些东西登场。不过,对于我们要编写大模型应用来说,这些东西就超过了基本的范畴,你稍微有个印象就够了。
如果你对 GPT 的详细运作原理感兴趣,我给你推荐几篇文章看看。
Inside GPT — I : Understanding the text generation Inside GPT — II : The core mechanics of prompt engineering
总结时刻
这一讲,我们站在开发大模型应用的视角来理解大模型是如何运作的。我们知道了大模型的核心任务是每次添加一个词,经过了上面的学习,你应该清楚,更准确的说法是每次添加一个 Token。Token 在大模型编程中非常重要,上下文窗口的大小决定了大模型一次可以处理多少个 Token,大模型通常是用 Token 进行计费的。
在生成内容的过程中,为了让内容拥有更多的创造性,需要引入随机性。由此我们引入了一个温度的概念,表示大模型的活跃程度。
大模型内部处理的并不是字符串,而是向量。文本向量化之后,才能真正进入大模型的处理,这个过程就是一个 Embedding 的过程。在大模型的处理中,需要经过 One-Hot 编码,然后,再对 One-Hot 编码之后的结果进行压缩,得到我们最终需要的结果。
如果今天的内容你只能记住一件事,那请记住:大模型的工作就是一次添加一个 Token。
思考题
我们今天讨论了大模型内部的一些工作状况,你看过哪些介绍大模型工作原理的内容呢?欢迎在留言区分享你的学习经验。
参考资料
Inside GPT — I : Understanding the text generation
https://towardsdatascience.com/inside-gpt-i-1e8840ca8093
Inside GPT — II : The core mechanics of prompt engineering
https://towardsdatascience.com/inside-gpt-ii-why-exactly-does-your-prompt-matter-1aea1aef35da
嵌入
https://developers.google.com/machine-learning/crash-course/embeddings?hl=zh-cn
- Seachal 👍(11) 💬(1)
在大型模型中,Embedding 是一种将高维数据(如文本、图像、视频等)转换为低维向量表示的技术。这种技术在自然语言处理(NLP)、计算机视觉等领域有着广泛的应用。Embedding 的核心思想是将离散数据映射到连续的向量空间,使得相似的数据点在向量空间中的距离较近,而不相似的数据点则距离较远。
2024-11-16 - Tony Bai 👍(3) 💬(1)
“在大模型的处理中,需要经过 One-Hot 编码,然后,再对 One-Hot 编码之后的结果进行压缩,得到我们最终需要的结果。” -- 目前词嵌入不会有one-hot这一过程吧?不过从内容讲解的角度来看,以one-hot为例,倒不失为很好的方法😁。
2024-11-08 - 技术骨干 👍(1) 💬(1)
token 代表可以生成的内容有多少,温度代表生成内容的随机性,embedding 代表将高维数据转换成向量的技术,极其复杂,看不太懂。
2024-12-02 - 🤡 👍(0) 💬(1)
好像之前了解过一些搜索引擎做搜索的时候会对处理成向量的数据做一个余弦相似度的处理,不知道跟这个文章说的是否类似
2025-02-03 - 晴天了 👍(0) 💬(1)
还是对AI不大熟悉, 有个问题, 您以上讲的是 训练大模型的过程 还是 用户输入后, 大模型针对用户输入输出的过程?
2024-11-19 - Demon.Lee 👍(0) 💬(1)
1、 …… --> 词 --> token --> 稀疏向量 --> 密集向量 --> …… 2、交给 AI 算法处理的前提就是把各种信息转换成向量 ==> 向量是多模态的前提; 3、你看过哪些介绍大模型工作原理的内容呢?推荐一下孙志岗老师的专栏:https://note.mowen.cn/note/detail?noteUuid=vKwymX8n5BEpqD5nCZPRo
2024-11-07 - 星期三。 👍(0) 💬(1)
One-Hot 只是针对单个词的,词与词之间的关系,甚至是整个句子,这些是怎么处理的
2024-11-07 - 星期三。 👍(0) 💬(1)
One-Hot是一个很老的技术吧,现在基于transformer架构embedding模型还在用这个吗
2024-11-07 - 末日,成欢 👍(0) 💬(1)
大模型会将'输入',会被隐射到多维空间的坐标点上,再经过某种压缩机制转化成向量 提示词中的内容词语权重不一样,所以大模型往往根据我们不同的提示词内容可以给出不同的结果,也就是大模型需要理解上下文,完成迁移学习。 预测下一个词我第一次知道,应该也是根据内容词语权重【理解上下文】,找出一堆向量,然后再通过概率找出【最合适】的一个向量
2024-11-07 - 张申傲 👍(1) 💬(0)
第2讲打卡~
2024-11-19 - 淡漠尘花划忧伤 👍(0) 💬(0)
重点总结: 1. 大模型的工作很简单,一次添加一个词。Token 就是我们理解大模型编程的第一个重要概念。这个 Token 可能是我们传统理解的一个完整的单词,可能是一个单词组合,甚至可能是单词的一部分(这就是大模型可以“造出新词”的原因)。有一个很重要的指标就是上下文窗口(Context Window)的大小。这里的上下文窗口,指的就是大模型可以处理 Token 数量,上下文越大,能处理的 Token 越多。 2. 表示随机性强弱的概念:温度它是表示大模型活跃程度的一个参数,通过调节这个参数,大模型变得更加活跃,或是更加死板。 3. 大模型内部处理的并不是字符串,而是向量。之所以要将字符串转换为向量,简单理解,就是现在大部分的 AI 算法只支持向量。
2025-02-09 - 江旭东01 👍(0) 💬(0)
上下文窗口的大小决定了大模型一次可以处理多少个 Token,什么决定上下文窗口的大小呢?
2025-02-07 - Geek_d4f4e7 👍(0) 💬(0)
个人理解希望老师和其他同学帮我纠正一下 本章主要大模型的核心,就是选择下一个词,针对回答的创新性更人性化更有温度,和我们讲了一下其中的一个参数叫做温度(随机性)。 其次和我们简单介绍了一下Token,Token是大模型理解的文本的基本单位,在不同大模型中token可以为字符、单词、子词,Token也是大模型计费的标准 其次和我们简单介绍了下字符串到向量的过程,和我们介绍了一下ai算法是基于向量进行运算,大模型会将字符串统一处理为向量,处理步骤有两步,第一步one-hot编码,将字符串处理为离散稀疏的高维向量,第二步把第一步结果进行压缩,将向量通过嵌入层矩阵压缩成低维密集向量
2025-02-07 - 公号-技术夜未眠 👍(0) 💬(0)
流式输出
2024-11-06