04 提示工程:更好地释放LLM的能力
你好,我是郑晔!
上一讲,我们讨论了站在用户角度怎么写提示词。从使用的角度来说,提示词公式基本上涵盖了日常使用的大多数场景。但是,仅仅掌握提示词公式,对于开发一个大模型应用而言,这个公式就显得有些不够了。为了开发大模型应用,我们需要进一步扩展自己对于提示词的理解,掌握更多关于提示词的知识,这就是我们这一讲要来讨论的内容——提示工程。
提示词工程
提示工程,顾名思义,就是研究怎么写提示词。之所以有提示工程,很重要的原因就是大模型在不同人眼中做的事情差异很大。普通用户只是把大模型当作一个聊天机器人,他们的关注点是大模型能否给予及时且正确的反馈,我们上一讲提到的提示词公式就足以应付绝大多数的使用场景。
而在开发者眼中,我们需要的是大模型处理复杂任务场景的能力,比如,现在很多 Agent 背后的技术就是让大模型推断出下一步的行为,这是利用大模型的推理能力,而这依赖于提示词的编写。
大多数人是先知道 ChatGPT,然后知道提示词,再知道提示工程。但其实提示工程并不是在 GPT 流行之后才诞生的技术。提示工程最早是诞生于自然语言处理(Natural Language Processing,简称 NLP),人们发现,在任务处理过程中,如果给予 AI 适当的引导,它能更准确地理解我们的意图,响应我们的指令。
于是,如何对 AI 进行引导就成了很多人的研究方向,这就形成了提示工程。在 GPT 流行之后,人们发现同样的技术对大模型同样适用,所以,越来越多的人开始关注提示工程。
从技术本质上说,我们为大模型提供的背景信息越多,越有助于大模型理解我们的意图,而我们给大模型提供信息的方式就是提供提示词。从某种意义上说,我们上一讲讲到的提示词公式也算是提示词工程的一个范例,我们根据这个公式就能为大模型提供其推理所需的各种信息。
至此,你已经对提示工程有了一个初步的了解。接下来,我们就来介绍几个典型的提示工程中的技术。
零样本提示(Zero-Shot Prompting)
前面我们说过,大模型的一个特点是知识丰富,所以,大模型本身是知道很多东西的。我们就可以利用这个特点,让它帮我们做一些通用的事情。在这种情况下,我们不需要给大模型过多的信息提示,这种提示词的写法称为零样本提示(Zero-Shot Prompting)。
我们来看一个例子:

在这个例子里,我们让大模型完成一个文本分类的工作,帮助我们判断文本的内容属于中性、负面或正面。显然,大模型知道分类是什么意思,也知道如何根据文本判断其情感,所以,在这个例子里,我们并没有给出任何更多的提示,大模型就能很好地帮我们完成分类的工作。
零样本提示是提示工程中比较好理解的一项技术,比较适合简单的任务。比如,一些简单查询就可以使用零样本提示。我们需要做的就是调整提示词,让大模型能够更好地返回我们需要的内容。
有时候,我们的任务不那么通用,零样本就不起作用了,我们可以给出一些例子,帮助大模型来理解,这就是我们要讨论的下一项提示技术——少样本提示。
少样本提示(Few-Shot Prompting)
虽然大模型知识丰富,但它并不是无所不知的,尤其是它对我们要完成的工作甚至是一无所知的。这时,我们只要给它一些例子,帮助它理解我们的工作内容,它就能很好地进行推理。下面是一个例子:

在这个例子里,老师要根据学习成绩安排学生假期活动,活动的具体内容大模型不可能事先知道的。这里我们采用了少样本提示,也就是我们给出了一些具体的例子:
成绩85分以上的,预习下学期课程 成绩60到85的,完成假期作业 成绩不足60分的,复习本学期课程内容
有了这些例子,我们就可以要求大模型回答我们具体的问题,也就是:
小刚的期末成绩是74分,他的假期活动应该是什么?
大模型参考我们给出的例子,进行推理,得出了相应的结论:
小刚的期末成绩是74分,他的假期活动应该是完成假期作业。
看到这个例子,你或许会有些奇怪,我们怎么会这么与大模型聊天呢?事实上,这的确不是我们常规的聊天方式,而是应用的编写方式。我们会把前面的样例作为一个提示词的固定部分,而后面的问题,则是根据用户的提问拼接上去的。
在我们之后讲到 LangChain 时,有一个概念叫提示词模板(PromptTemplate),就是用来拼接提示词的。现在你可以理解为什么我们说这讲学到的提示工程的内容都属于技术范畴了。
少样本学习在简单分类的场景是很好用的,但它也有很强的局限性,比如,在一些复杂的推理任务中,它就显得力不从心了。这就轮到下一项提示词技术登场了,它就是思维链。
思维链提示(Chain-of-Thought Prompting)
大模型是一个语言模型,它的特长在语言能力上,不过,从另外一个角度看,它在数学、推理等问题上是存在不足的。所以,我们经常看到大模型在一些简单的数学问题上闹笑话,比如 3.8 和 3.11 到底谁大(当然,各个大模型都在积极修复这些发现的问题)。
在我看来,大模型是典型的嘴比脑子快,很多东西未经思考就说了出来。为了让大模型很好地完成工作,我们需要让它慢下来,不要用直觉回答问题,而是开启理性的一面。
思维链提示就是这样一种技术,我们来看一个例子,这个例子来自将思维链介绍给行业的论文:
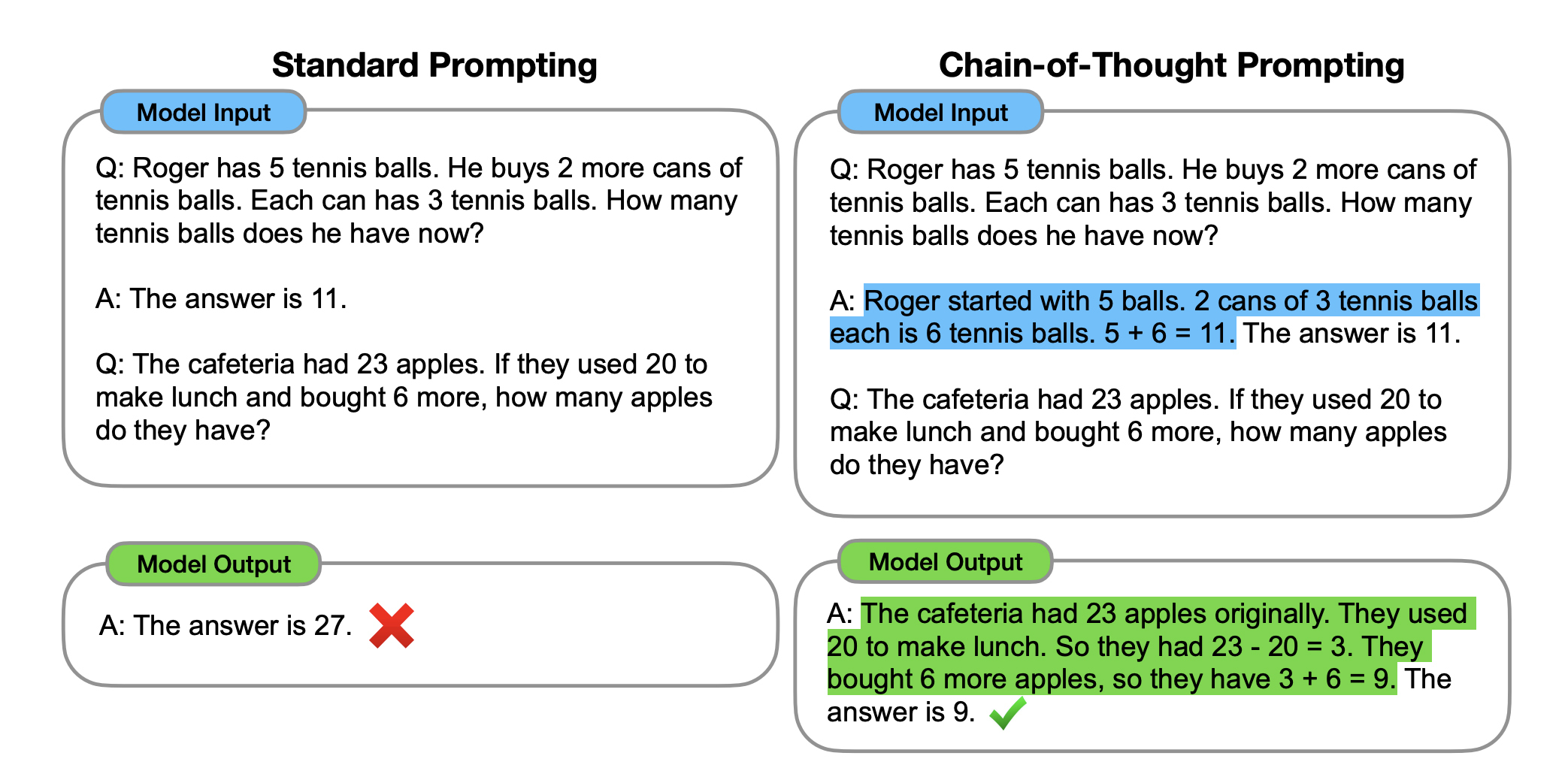
在这个例子里面,左右两边同样是为了得到数学题的答案,甚至给了同样一道题作为样例。二者的差别是标准提示里,样例回答是直接给出了答案,而采用思维链提示的样例回答,则给出了一个完整的推导过程。
我们看到,因为样例的不同,模型的回答就出现了差异,标准提示直接给出了回答,也就是“未经思考”的答案,结果这个答案是错的;而思维链提示给出的答案则是带有完整的思考过程,是一个“慢下来”的答案,于是得到了一个正确的答案。你现在明白了,所谓思维链,就是这个思考过程。
这个例子里的思维链列举了示例,所以,它也算是一种少样本提示。你可能会想,既然有少样本思维链,那是不是有零样本思维链,还真有。只要提示词里添加 Let’s think step by step 就行,很明显,它就是告诉大模型慢下来,一步一步想。
无论是我前面的例子,还是零样本思维链,如果你自己测试,效果很有可能是不同的,原因很简单,大模型的推理能力是不断提升的,可能前一天还很傻,后一天就聪明了。所以,在实际开发大模型应用时,还是要基于特定模型测试,保证提示词的效果。
就在我写下这段文字没多长时间,OpenAI 发布了 o1,其核心原理就是将思维链引入了大模型的处理过程中,大幅度提升了模型的推理能力。如果能够理解思维链,我们即便使用的是能力稍弱一些的大模型也依然能达到不错的推理效果。
ReAct 框架
前面提到的这些提示技术都是在说大模型自身的推理过程,不过,很多人对大模型的预期可不仅仅局限于“文字游戏”。那如果大模型能够跳脱自说自话,和周边做更多结合,是不是就可以做更多的事情了呢?
ReAct 框架就是在这个想法下诞生的。ReAct 实际上是两个单词的缩写:Reasoning + Acting,也就是推理+行动。下面是这个例子来自引入 ReAct 框架的论文,其原始问题是:
除了苹果遥控器,还有哪些设备可以控制苹果遥控器最初设计用来交互的程序? Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?
下面就是回答这个问题涉及到的不同的步骤:

在这个例子里,大模型为了完成一个大目标,需要不断地做一些任务。每个任务都会经历思考(Thought)、行动(Action)、观察(Observation)三个阶段。思考,决定了下一步的行动;行动是完成了一个具体的动作;而观察,则是对行动结果进行评估,决定是否要结束这个处理过程。
如果说推理的部分都是大模型可以完成的,但行动要做的事恐怕就不是大模型可以单独完成的,比如搜索苹果遥控器,这显然就需要有一些其它的方式,帮助大模型完成这个搜索的动作。实际上,这也就是 ReAct 这项技术被称为框架的原因,它需要有一些其它的动作嵌入到这个执行过程中。
如果单看这个例子,你还可能会有些困惑,那下面的例子可以帮助你更好地理解 ReAct 是一个框架。这是来自 LangChain 社区的一个提示词模板,后面我们会讲到 LangChain,这里我们先把注意力放到提示词本身:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action Observation: the result of the action … (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer Final Answer: the final answer to the original input question
Begin!
Question: {input} Thought:{agent_scratchpad}
这个提示词模板主要是用来借助一些工具,完成一些具体的任务。你在这里看到和前面类似的思考(Thought)、行动(Action)、观察(Observation)的阶段。
重点是在行动里,我们可以使用不同的工具,这些工具就是我们可以嵌入到执行过程中的内容。大模型会结合问题以及工具的特点选择下一步的行动,比如,告诉我们用哪个工具完成任务,然后,就可以执行相应的工具代码。这里的工具代码就是我们本地的代码,显然,它能做的事情就多了,会超出大模型本身的能力范围。如果你能理解这个提示词模板,你就具备了实现一个 Agent 的基础。
到这里,我们已经快速了解了最基本的几个提示技术。显然,这不是提示技术全部。如果你有兴趣了解,可以到提示工程指南这个网站上去了解更多。
总结时刻
这一讲,我们讨论了提示工程,主要是为了引导大模型给出更好的答案。我们介绍几个基本的提示技术:
- 零样本提示:用于通用的任务。
- 少样本提示:用于特定的简单任务。
- 思维链提示:引入推理过程,可以与零样本提示和少样本提示结合。
- ReAct 框架:将大模型推理和一些行动能力结合起来,超越大模型自身的限制。
如果今天的内容你只能记住一件事,那请记住:提示工程是为了引导大模型给出更好的答案。
练习题
我们这里只提到了基本的几项提示技术,算是抛砖引玉。希望你可以到提示工程指南学习一项提示技术,然后,在评论区分享你的理解。
- hao-kuai 👍(3) 💬(1)
提示词有推荐的认证考试吗?或者说如何提高自己的编写能力?
2024-11-28 - Demon.Lee 👍(3) 💬(1)
思维链,把思考的过程链接起来,有理有据,顺便把正确率提升了,只不过响应会慢一点,并且多费点精力(成本高一点)。我们人类也是:背答案很快,但把答案推导一遍就慢了。
2024-11-11 - grok 👍(3) 💬(1)
1. ReAct 框架看不太懂,后面有项目细讲嘛? 2. 最近Anthropic推出的computer use,跟ReAct有什么关系吗?https://www.anthropic.com/news/3-5-models-and-computer-use. 都是操作“工具”? 3. 文中说ReAct“具备了实现一个 Agent 的基础”, 还有没有其他主流的实现agent的框架?(除了ReAct)
2024-11-08 - 晴天了 👍(1) 💬(2)
是否可以这么理解: ai应用工程师 = system提示词工程师. 😃.
2024-11-21 - 技术骨干 👍(0) 💬(1)
提示工程释放大模型的能力,如虎添翼可以这么讲吧
2024-12-02 - CPF 👍(1) 💬(0)
GPT-4o mini 免费 3.11 比 3.8 大。虽然它们的整数部分相同,但小数部分的比较中,0.11 大于 0.8,因此 3.11 大于 3.8。
2024-12-23 - 张申傲 👍(1) 💬(0)
第4讲打卡~
2024-11-20 - 淡漠尘花划忧伤 👍(0) 💬(0)
笔记:提示工程是为了引导大模型给出更好的答案: 零样本提示:用于通用的任务。 少样本提示:用于特定的简单任务。 思维链提示:引入推理过程,可以与零样本提示和少样本提示结合。 ReAct 框架:将大模型推理和一些行动能力结合起来,超越大模型自身的限制。
2025-02-09 - 大叶枫 👍(0) 💬(0)
极客AI总结的不错哦“1. 提示工程是研究如何写提示词的技术,旨在扩展对提示词的理解,以更好地释放大模型的能力。 2. 零样本提示(Zero-Shot Prompting)利用大模型的丰富知识,无需过多信息提示即可完成通用任务,适用于简单查询等场景。 3. 少样本提示(Few-Shot Prompting)通过给出一些例子,帮助大模型理解特定工作内容,适用于简单分类场景。 4. 思维链提示(Chain-of-Thought Prompting)旨在让大模型慢下来,进行推理和思考,提升在数学、推理等问题上的表现。 5. ReAct 框架结合了推理和行动,超越大模型自身的限制,使其能够更多地参与实际行动。”
2025-01-10 - Seachal 👍(0) 💬(0)
提示工程是研究如果写好提示词的技术
2024-11-16