06 OpenAI API:LLM编程的事实标准(下)
你好,我是郑晔!
通过上一讲的介绍,我们已经知道了,OpenAI API 已经成为了 LLM 编程的事实标准,作为开发者,我们需要对它有一个基本的了解,并且选择了聊天补全这个最核心的 API 作为学习的切入点。
不过,我们上一讲只讲聊天补全的请求部分,让你对怎样对 LLM 提问有了基本了解。在实际工作中,我们还有更重要的部分要去处理,这就是大模型的回答。这一讲,我们就书接上文,看看 LLM 怎样回答我们的问题。
聊天应答
在正常情况下,聊天补全的应答内容本身是比较简单的,就是一个标准的 HTTP 的应答。之所以我们还要把它单独拿出来说一下,主要是它还有一种流式应答的模式。
我们先来看正常的 HTTP 应答,也就是一个请求过去,大模型直接回复一个完整的应答。下面是一个应答的例子:
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4o-mini",
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"logprobs": null,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
我们先来了解几个简单的参数:
- id,应答的唯一标识。这个比较好理解,方便在出问题时定位问题。
- object,对象类型。这是 OpenAI API 应答的一个通用字段,不同类型的应答都会有自己固定的对象类型,在聊天补全接口中,它的值就是 chat.completion。
- created,Unix 时间戳。它表明了这个应答生成的时间。
- model,生成应答的模型。大部分情况下,它就是请求时所带的模型。不过,同一个模型可能存在不同版本的情况,它有时会返回具体的版本,比如:gpt-4o-mini-2024-07-18。
- system_fingerprint,系统指纹。它代表了模型运行时使用的后端配置。在讲到请求中的技术参数时,我们提到过一个 seed 参数,可以当做后端缓存来看。seed 参数就是要与这个 system_fingerprint 配合使用的。
前面几个参数都非常好理解,接下来的 choices 才是我们应答的重点,这是大模型给我们回复的真正内容。choices 本身是一个对象列表,其中的每个对象就是大模型生成文本的一部分。我们来具体看一下:
- index,索引。这就是一个顺序编号,如果文本被切分了,通过索引就可以将内容重新排列,生成正确的顺序。不过,如果对于标准的 HTTP 应答,切片的必要性不大,往往只有一块。
- finish_reason,停止生成 token 的原因。文本不会无限生成,总会停下来。到了停止点或遇到停止序列,原因就是 stop,到了一定的长度,原因就是 length,生成了工具调用就是 tool_calls。
- message,回复的消息。在这个例子中,包含了两个字段:角色(role)和内容(content)。这个部分与请求中的消息是一样的,最核心的字段就是内容,角色部分已经解释过了(可以回看上一讲的核心参数部分)。
除了常规的回复内容之外,如果回复内容是一个工具调用,也是通过 message 里返回的,我们再来看一个例子:
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1699896916,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\n\"location\": \"Boston, MA\"\n}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 17,
"total_tokens": 99
}
}
在这个例子里,我们看到 content 字段是空的,但多了一个 tool_calls,正如其名字所示,它也是一个对象列表,也就是一次可以返回多个工具调用。其中的每个对象都包含了一些字段:
- id,函数调用的 ID。
- type,目前只支持 function,这在前面讲请求的时候也说过了。
- function,函数调用部分,其中包含了名字(name)和参数(arguments),在这个例子里,就表示调用 get_current_weather 这个函数,其参数 location 的值是 Boston, MA。
除了基本的内容,我们前面还提到过,大模型生成文本是根据概率进行计算的,我们上一讲说过,设置 logprobs 就可以让大模型把概率返回给我们,设置 top_logprobs 可以返回概率比较高的几个选项。
下面这个例子里,我们开启了 logprobs,还把 top_logprobs 设置成了 2。
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1702685778,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
"logprobs": {
"content": [
{
"token": "Hello",
"logprob": -0.31725305,
"bytes": [72, 101, 108, 108, 111],
"top_logprobs": [
{
"token": "Hello",
"logprob": -0.31725305,
"bytes": [72, 101, 108, 108, 111]
},
{
"token": "Hi",
"logprob": -1.3190403,
"bytes": [72, 105]
}
]
},
{
"token": "!",
"logprob": -0.02380986,
"bytes": [
33
],
"top_logprobs": [
{
"token": "!",
"logprob": -0.02380986,
"bytes": [33]
},
{
"token": " there",
"logprob": -3.787621,
"bytes": [32, 116, 104, 101, 114, 101]
}
]
},
{
"token": " How",
"logprob": -0.000054669687,
"bytes": [32, 72, 111, 119],
"top_logprobs": [
{
"token": " How",
"logprob": -0.000054669687,
"bytes": [32, 72, 111, 119]
},
{
"token": "<|end|>",
"logprob": -10.953937,
"bytes": null
}
]
},
{
"token": " can",
"logprob": -0.015801601,
"bytes": [32, 99, 97, 110],
"top_logprobs": [
{
"token": " can",
"logprob": -0.015801601,
"bytes": [32, 99, 97, 110]
},
{
"token": " may",
"logprob": -4.161023,
"bytes": [32, 109, 97, 121]
}
]
},
{
"token": " I",
"logprob": -3.7697225e-6,
"bytes": [
32,
73
],
"top_logprobs": [
{
"token": " I",
"logprob": -3.7697225e-6,
"bytes": [32, 73]
},
{
"token": " assist",
"logprob": -13.596657,
"bytes": [32, 97, 115, 115, 105, 115, 116]
}
]
},
{
"token": " assist",
"logprob": -0.04571125,
"bytes": [32, 97, 115, 115, 105, 115, 116],
"top_logprobs": [
{
"token": " assist",
"logprob": -0.04571125,
"bytes": [32, 97, 115, 115, 105, 115, 116]
},
{
"token": " help",
"logprob": -3.1089056,
"bytes": [32, 104, 101, 108, 112]
}
]
},
{
"token": " you",
"logprob": -5.4385737e-6,
"bytes": [32, 121, 111, 117],
"top_logprobs": [
{
"token": " you",
"logprob": -5.4385737e-6,
"bytes": [32, 121, 111, 117]
},
{
"token": " today",
"logprob": -12.807695,
"bytes": [32, 116, 111, 100, 97, 121]
}
]
},
{
"token": " today",
"logprob": -0.0040071653,
"bytes": [32, 116, 111, 100, 97, 121],
"top_logprobs": [
{
"token": " today",
"logprob": -0.0040071653,
"bytes": [32, 116, 111, 100, 97, 121]
},
{
"token": "?",
"logprob": -5.5247097,
"bytes": [63]
}
]
},
{
"token": "?",
"logprob": -0.0008108172,
"bytes": [63],
"top_logprobs": [
{
"token": "?",
"logprob": -0.0008108172,
"bytes": [63]
},
{
"token": "?\n",
"logprob": -7.184561,
"bytes": [63, 10]
}
]
}
]
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 9,
"total_tokens": 18
},
"system_fingerprint": null
}
在这个例子里,在 logprobs 的 content 字段里,我们看到了一个个 token 与其对应的概率(logprob)。bytes 表示这个 token 对应的 UTF-8 的字节表现形式,而 top_logprobs 则包含了每个 token 对应的备选 token 及其概率。
流式应答
现在你已经对大模型回复的内容有了一个完整的了解。接下来,我们再来看大模型回复的一种重要行为:流式应答。
流式应答的出现主要是为了解决大模型生成文本比较慢的问题。如果等大模型把所有内容生成一次性返回,等待的时间会非常长。对于聊天的场景,这会让本已很长的等待时间会显得更加漫长。
如果想要提高响应速度,可以怎么做呢?之前我们讲过,大模型的核心工作就是一次添加一个 Token。正是因为有了这种工作原理,我们不用等所有内容生成完毕,已经确定生成出来的内容可以先推送给用户。
对于用户而言,看到第一个字出来,单纯的等待就结束了。这样给人的感觉就是,响应速度得到了大幅度提升。所以,在大部分的大模型聊天界面上,我们都会看到一个字一个字往外蹦的效果,要实现这种效果,通常就是采用流式应答的方式。

那什么时候该用流式应答,什么时候该用常规的应答呢?流式应答主要是为了提高聊天的响应速度,这就是流式应答的主要工作场景。如果不是这种情况,比如,我们把大模型当做推理引擎,让它觉得下一步该做什么,那就用常规的应答。
接下来的问题就是,流式应答可以采用什么技术实现呢?如果你做过服务端的开发,像这种涉及到服务端主动向客户端推送内容,我们可能会选择 Websocket,但 OpenAI 在这个问题上却选择了 SSE 这种技术。
SSE
SSE 是服务器发送事件(Server-Sent Event),它是一种服务器推送技术,客户端通过 HTTP 连接接收来自服务器的自动更新,它描述了服务器如何在建立初始客户端连接后向客户端发起数据传输。 ——Wikipedia
简单理解,SSE 就是在 HTTP 连接建立起来之后,由服务器端向客户端推送消息。就像下图所示,常规的应答会在建立起的 HTTP 通道上,一次性地把所有内容都发送给客户端,而 SSE 的方式是在连接建立之后,一块一块地把消息发给用户。对应到大模型上,就是每生成一部分内容就发送一次。
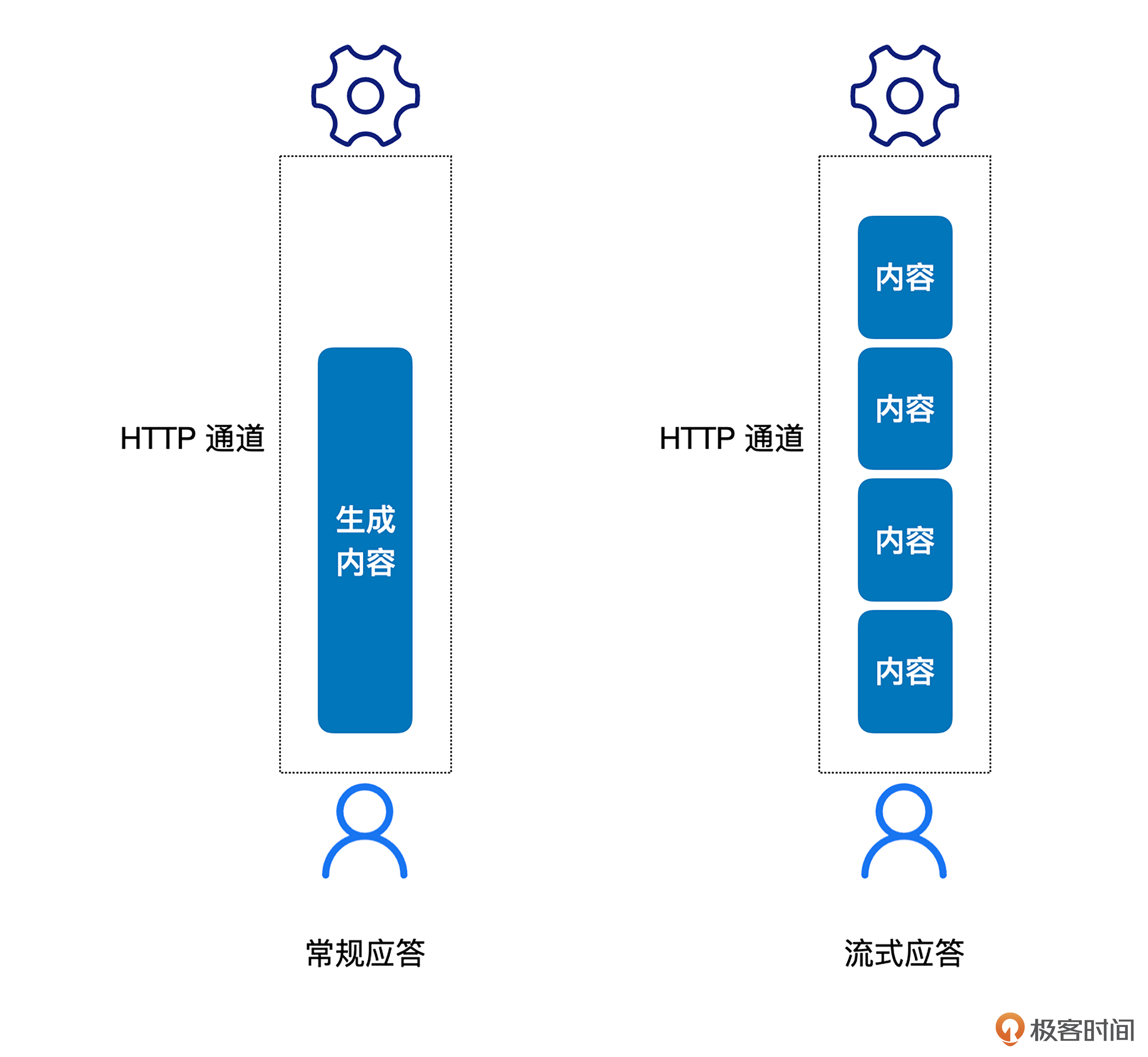
对比很多人熟悉的 Websocket 来看,我们会更清楚一些:
- 二者都是建立在 HTTP 协议基础上, Websocket 建立了一套自己的通信协议,而 SSE 则是可以理解为建立在 HTTP 通信协议基础上的一层应用协议。
- Websocket 主要是双向通信(客户端可以发消息给服务端,服务端也可以发消息给客户端),SSE 是单向通信(从服务端到客户端)。
- Websocket 通常用于长连接,SSE 更适合用在单次请求的场景。
OpenAI 之所以选择 SSE,而非 WebSocket,是因为 SSE 的技术特点刚好可以契合流式应答的需求:客户端与大模型的交互是一次性的,每产生一个 token,服务端就可以给客户端推送一次,当生成内容结束时,断掉连接,无需考虑客户端的存活情况。
如果采用 WebSocket 的话,服务端就需要维护连接,像 OpenAI 这样的服务体量,维护连接就会造成很大的服务器压力,而且,在生成内容场景下,也没有向服务端进一步发送内容,WebSocket 的双向通信在这里也是多余的。
单就 SSE 这项技术而言,它存在已经很长时间了,2004 年就有人提出,但直到大模型的兴起,这项技术才彻底流行起来。
这里有一点细节的问题,SSE 通常是用在 GET 请求上的,而 OpenAI 的聊天接口是一个 POST 请求,从规范的角度看,它的用法并不完全恰当,只是 OpenAI API 的流行让大家接受了它。如果严格遵守 SSE 程序库处理 OpenAI API ,就可能会遇到无法 POST 请求 SSE 的情况。
SSE 貌似是一项高深的技术,但只要我们看一下报文就不难理解它是如何实现的。根据报文的形式,SSE 通常分成纯数据消息和事件消息。纯数据消息,顾名思义就是只有数据的消息,下面是一个例子:
data: This is the first message.
data: This is the second message, it
data: has two lines.
data: This is the third message.
正如你在这里看到的,每一条消息开头都有一个 data,表示后面的内容就是一条数据。这种形式的数据消息就是流式应答里最常用的消息,每次生成了一个 token,就推送一条以 data 开头的数据块,所以,我们会看到一个又一个的消息块。
事件消息,我们看一个例子也就很容易理解了:
这里的消息会先有一个事件(event),后面跟着具体的数据(data),对于程序员来说,这种做法类似于函数和它的参数。服务端每次推送,都会推送一个事件加上一个数据。
清楚了 SSE 的实现,我们再来看聊天补全接口中流式应答的实现,你就很容易理解了,下面是一个例子:
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}
....
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
这里面我们看到了很多消息块,每块就对应着 SSE 中的一个 data 块。有了前面的基础,消息内容也很好理解了,我这里只把需要注意的一些细节说一下,其它部分含义同之前的解释是一致的。
- id,所有消息块的 ID 是一样的,保证它们是一个消息。
- object,消息类型是 chat.completion.chunk,这说明它是一个消息块。
- 消息内容是放在 choices 列表中对象的 delta 字段中,有了前面的基础,你已经知道了,这里面存放的是每次生成的 token。
总结时刻
这一讲,我们讨论了聊天补全接口的应答消息,其中,最核心的信息是消息内容。当然,根据请求内容的不同,应答可能还会包含很多其它信息,比如工具调用、生成 token 的概率信息等。
应答的模式有两种,一种是常规的 HTTP 同步应答,另一种是流式应答。流式应答主要是用在聊天的场景,用于提高响应速度。我们还讨论了流式应答的底层实现方式,也就是 SSE 技术。
思考题
除了聊天补全接口,还有一个 Embeddings API 在开发大模型应用中是非常常用的。我建议你去学习一下,然后在留言区分享你的心得体会。
- rOMEo罗密欧 👍(5) 💬(2)
请问一下有可以实战的环境或者平台吗
2024-11-13 - Demon.Lee 👍(5) 💬(1)
每个技术都有自己的适用场景:SSE(Server-Sent Event)自己可能都没想到,有一天我竟然会从无人问津,到火爆 AI 开发。
2024-11-13 - 技术骨干 👍(3) 💬(1)
无意带火 了一项技术SSE
2024-12-05 - 张申傲 👍(3) 💬(1)
第6讲打卡~ Stream 流式响应,特别是在 AI 聊天应用中,可以大幅提升用户体验。
2024-11-21 - grok 👍(3) 💬(2)
纯小白;有几个问题: 1. 这个SSE 技术,是在ChatGPT界面聊天的底层机制?还是我用python调用OpenAI API时的底层机制?估计两个都是? 2. 如果OpenAI采用WebSocket ("服务端需要维护连接"), 用户的使用体验和现在有什么不一样?更慢?更不稳定?还是用户的体验完全一样? 3. 同理claude/gemini/etc.全是SSE?
2024-11-13 - 腿毛茸茸 👍(0) 💬(1)
看到同事儿子背诵小学课文的视频,典型的“流式响应”,转几次眼珠吐几个词或半句话,偶尔还卡顿几秒中。
2025-02-10 - 淡漠尘花划忧伤 👍(0) 💬(0)
速记:聊天补全接口的应答消息,其中,最核心的信息是消息内容。当然,根据请求内容的不同,应答可能还会包含很多其它信息,比如工具调用、生成 token 的概率信息等。 应答的模式有两种,一种是常规的 HTTP 同步应答,另一种是流式应答。流式应答主要是用在聊天的场景,用于提高响应速度。
2025-02-09