16 缓存:节省使用大模型的成本
你好,我是郑晔!
上一讲,我们讲了一种工程实践——长期记忆,它可以让我们的应用更加了解自己的用户。这一讲,我们继续,讨论另外一种工程实践——缓存。
缓存
计算机科学中只有两大难题:缓存失效和命名。 —— Phil Karlton
稍有经验的程序员对缓存都不陌生,在任何一个正式的工程项目上都少不了缓存的身影。硬件里面有缓存,软件里面也有缓存,缓存已经成了程序员的必修课。
我们为什么要使用缓存呢?主要就是为了减少访问低速服务的次数,提高访问速度。大模型显然就是一个低速服务,甚至比普通的服务还要慢。
为了改善大模型的使用体验,人们已经做出了一些努力,比如采用流式响应,提升第一个字出现在用户面前的速度。缓存,显然是另外一个可以解决大模型响应慢的办法。
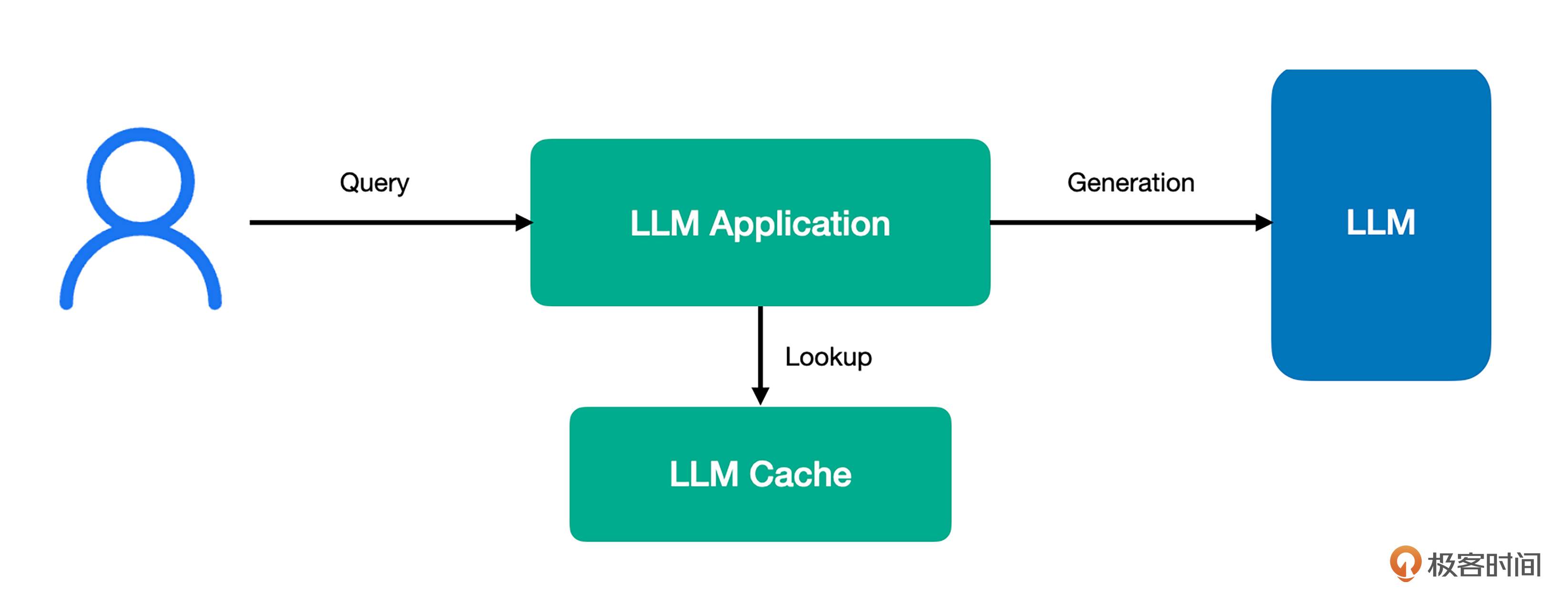
一个使用了缓存的大模型应用在接受到用户请求之后,会先到缓存中进行查询,如果命中缓存,则直接将内容返回给用户,如果没有命中,再去请求大模型生成相应的回答。
在这个架构中,关键点就是如果缓存命中,就直接将内容返回给用户,也就说明,在这种情况下无需访问大模型。我们使用大模型生成数据时,是根据请求和生成的内容计费的。
如果能够不请求大模型就给用户返回内容,我们就可以节省一次生成的费用,换言之,每次有效的缓存命中,就是在节省成本。所以,对大模型应用而言,缓存是至关重要的,一方面可以提升访问速度,另一方面,可以实实在在地节省成本。
LangChain 中的缓存
因为缓存在大模型应用开发中是一个普遍的需求,所以,LangChain 也为它提供了基础抽象。下面就是一段使用了缓存的代码:
from time import time
from langchain.globals import set_llm_cache
from langchain_core.caches import InMemoryCache
from langchain_openai import ChatOpenAI
set_llm_cache(InMemoryCache())
model = ChatOpenAI(model="gpt-4o-mini")
start_time = time()
response = model.invoke("给我讲个一句话笑话")
end_time = time()
print(response.content)
print(f"第一次调用耗时: {end_time - start_time}秒")
start_time = time()
response = model.invoke("给我讲个一句话笑话")
end_time = time()
print(response.content)
print(f"第二次调用耗时: {end_time - start_time}秒")
这段代码里只有一句是重点,就是设置大模型的缓存:
下面是一次执行的结果,从结果上看,因为有缓存,第二次明显比第一次快得多。
为什么鸡过马路?因为它想去对面看看有没有更好的“鸡”会!
第一次调用耗时: 4.399242162704468秒
为什么鸡过马路?因为它想去对面看看有没有更好的“鸡”会!
第二次调用耗时: 0.00045371055603027344秒
在 LangChain 里,缓存是一个全局选项,只要设置了缓存,所有的大模型都可以使用它。如果某个特定的大模型不需要缓存,可以在设置的时候关掉缓存:
当然,如果你不想缓存成为一个全局选项,只想针对某个特定进行设置也是可以的:
LangChain 里的缓存是一个统一的接口,其核心能力就是把生成的内容插入缓存以及根据提示词进行查找。LangChain 社区提供了很多缓存实现,像我们在前面例子里用到的内存缓存,还有基于数据库的缓存,当然,也有我们最熟悉的 Redis 缓存。
虽然 LangChain 提供了许多缓存实现,但本质上说,只有两类缓存——精确缓存和语义缓存。精确缓存,只是在提示词完全相同的情况下才能命中缓存,它和我们理解的传统缓存是一致的,我们前面用来演示的内存缓存就是精确缓存。
语义缓存
但大模型应用的特点就决定了精确缓存往往是失效的。因为大模型应用通常采用的是自然语言交互,以自然语言为提示词,就很难做到完全相同。像前面我展示的那个例子,实际上是我特意构建的,才能保证精确匹配。所以,语义匹配就成了更好的选择。
语义匹配我们并不陌生,前面讲 RAG 时,我们讲过了基于向量的语义匹配。LangChain 社区提供了许多语义缓存的实现,在各种语义缓存中,我们最熟悉的应该是 Redis。
在大部分人眼中,Redis 应该属于精确匹配的缓存。Redis 这么多年也在不断地发展,有很多新功能不断地拓展出来,最典型的就是 Redis Stack,它就是在原本开源 Redis 基础上扩展了其它的一些能力。
比如,对 JSON 支持(RedisJSON),对全文搜索的支持(RediSearch),对时序数据的支持(RedisTimeSeries),对概率结构的支持(RedisBloom)。其中,支持全文搜索的 RediSearch 就可以用来实现基于语义的搜索。全文搜索,本质上也是语义搜索,而这个能力刚好就是我们在语义缓存中需要的。
你现在知道了,Redis 对于语义缓存的支持是基于 RediSearch 的。所以,要想使用语义缓存,我们需要使用安装了 RediSearch 的 Redis,一种方式是使用 Redis Stack:
下面是一个使用 Redis 语义缓存的例子:
from langchain.globals import set_llm_cache
from langchain_community.cache import RedisSemanticCache
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
RETURN_VAL_TYPE = Sequence[Generation]
def prompt_key(prompt: str) -> str:
messages = json.loads(prompt)
result = ["('{}', '{}')".format(data['kwargs']['type'], data['kwargs']['content']) for data in messages if
'kwargs' in data and 'type' in data['kwargs'] and 'content' in data['kwargs']]
return ' '.join(result)
class FixedSemanticCache(BaseCache):
def __init__(self, cache: BaseCache):
self.cache = cache
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
key = prompt_key(prompt)
return self.cache.lookup(key, llm_string)
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
key = prompt_key(prompt)
return self.cache.update(key, llm_string, return_val)
def clear(self, **kwargs: Any) -> None:
return self.cache.clear(**kwargs)
set_llm_cache(
FixedSemanticCache(
RedisSemanticCache(redis_url="redis://localhost:6379",
embedding=OpenAIEmbeddings())
)
)
model = ChatOpenAI(model="gpt-4o-mini")
start_time = time()
response = model.invoke("""请给我讲一个一句话笑话""")
end_time = time()
print(response.content)
print(f"第一次调用耗时: {end_time - start_time}秒")
start_time = time()
response = model.invoke("""你能不能给我讲一个一句话笑话""")
end_time = time()
print(response.content)
print(f"第二次调用耗时: {end_time - start_time}秒")
我们先把注意力放在后面的核心代码上,在调用模型时,我们给出了两句并不完全相同的提示词。作为普通人,我们很容易看出,这两句话的意图是一样的。如果采用精确匹配,显然是无法命中的,但如果是语义匹配,则应该是可以命中的。
这里的语义缓存,我们采用了 RedisSemanticCache。在配置中,我们指定了 Redis 的地址和 Embedding 模型。LangChain 支持的 Redis 缓存有精确缓存和语义缓存两种,RedisCache 对应的是精确缓存,RedisSemanticCache 对应的是语义缓存。
最后说一下 FixedSemanticCache,其实,它是不应该存在的,它是为了解决 LangChain实现中的一个问题而写的。LangChain 在实现缓存机制的时候,会先把消息做字符串化处理,然后,再交给缓存去查找。
在转化成字符串的过程中,LangChain 目前的实现是把它转换成一个 JSON 字符串,这个 JSON 字符串里除了提示词本身外,还会有很多额外信息,也就是消息对象本身的信息。当提示词本身很小的时候,这个生成的字符串信噪比就很低,正是因为噪声过大,结果就是不同的提示词都能匹配到相同的内容上,所以,总是能够命中缓存。
这段代码是写在框架内部的,不论采用什么样的缓存实现都有这个问题。只不过,因为精确缓存要完全匹配得上,这个实现的问题不会暴露出来,但对于语义缓存来说,就是一个非常严重的问题了。
在 LangChain 还没有修复这个问题之前,FixedSemanticCache 就是一个临时解决方案。思路也很简单,既然信噪比太低,就把信息提取出来,在这个实现里,把提示词和消息类型从字符串中提取出来,作为存储到 Redis 里的键值。如果后续 LangChain 解决了这个问题,FixedSemanticCache 就可以去掉了。
下面是一次执行的结果,从结果上看,第二次比第一次快了很多,这说明缓存起了作用:
正如你在这里看到的,我们把 Redis 当作语义缓存,它起到了和我们之前讲到的向量存储类似的作用。实际上,LangChain 社区确实已经有了实现 VectorStore 接口的 Redis,也就是说,我们完全可以用 Redis 替换之前讲过的向量存储。事实上,这里的语义缓存底层就是用了这个实现了 VectorStore 接口的 Redis。
顺便说一下,Redis 社区在向量的支持上也在继续努力,有一个项目 RedisVL(Redis Vector Library)就是把 Redis 当作向量数据库,有兴趣的话你可以了解一下。
无论是前面用 InMemoryCache 介绍精确缓存,还是这里采用 Redis 来介绍语义缓存,都是为了降低大家理解的难度。
实际上,LangChain 社区已经集成了大量的缓存实现,其中,有我们已经耳熟能详的,比如基于 SQL 和 NoSQL 的实现,也有基于 Elasticsearch 这样搜索项目的实现,这些都是基于传统项目实现的,还有一些项目就是针对大模型应用设计的缓存项目,这其中最典型的当属 GPTCache。总之,如果需要在项目上采用缓存,不妨先去了解一下不同的缓存项目。
总结时刻
这一讲,我们又讲了一个非常重要的工程实践——缓存。对大模型应用而言,缓存是至关重要的,一方面可以提升访问速度,另一方面,可以实实在在地节省调用大模型的成本。
我们结合 LangChain 框架介绍了缓存的实现。缓存主要分成两大类,精确缓存和语义缓存。精确缓存,是在提示词完全相同的情况下才能命中缓存,而语义缓存则是语义类似的情况下就能命中缓存。对于聊天类型的应用而言,语义缓存的实用价值更大一些。
我以 Redis 为例给你介绍了语义缓存,你也知道了,很多项目都是支持语义缓存的,有的是基于已有的项目进行改造,比如 Redis 和 Elasticsearch,有的是专门为了大模型应用而设计的,比如,GPTCache。
如果今天的内容你只能记住一件事,那请记住,对大模型应用而言,缓存可以提升访问速度,降低访问成本。
思考题
LangChain 社区提供了大量的缓存实现,你可以去了解一下不同的缓存实现,看看哪个实现可以与你在用的基础设施结合起来。欢迎在留言区分享你的所得。
- 风 👍(0) 💬(0)
def prompt_key(prompt: str) -> str: messages = json.loads(prompt) result = ["('{}', '{}')".format(data['kwargs']['type'], data['kwargs']['content']) for data in messages if 'kwargs' in data and 'type' in data['kwargs'] and 'content' in data['kwargs']] return ' '.join(result) 这里的代码是固定格式吗,实际开发怎么写
2025-02-18 - 张申傲 👍(0) 💬(0)
第16讲打卡~
2025-02-12 - Aaron Liu 👍(0) 💬(0)
又学习了redis的一个功能
2025-02-06 - MClink 👍(0) 💬(0)
第一次知道Redis还有语义缓存的使用
2025-01-29