19 如何在项目中使用开源模型
你好,我是郑晔!
上一讲,我们讲了如何使用 Hugging Face 上的开源模型。这一讲,我们看看如何在实际的项目中使用这些模型。
最简单的方式,当然是把上一讲的代码直接拿过来用。不过,有些项目可能需要依赖于不同的模型,比如,既有开源模型,又有供应商提供的大模型。在这种情况下,我们就需要做一层封装,保证代码的灵活性。
这一讲,我们就来谈谈两种常见的封装:使用 LangChain 和使用集中接入。
使用 LangChain
前面我们讲 LangChain,重点在于它提供的不同抽象,帮助我们搭建各种大模型应用。现在,让我们回到 LangChain 最基础的抽象——模型。
LangChain 的模型就是 LangChain 给我们提供的一层封装,屏蔽掉了不同大模型之间的差异,让我们可以方便地在不同大模型之间进行切换。任何想要接入 LangChain 体系的大模型,只要实现了相应的接口,就可以无缝地嵌入到 LangChain 的体系中去,Hugging Face 的模型就是这么做的。
我们之所以要把 Hugging Face 模型嵌入到 LangChain的体系中,主要是因为我们希望使用 LangChain 提供的其它抽象。
要使用 Hugging Face 相关的代码,首先需要安装相应的包:
langchain-huggingface 是 Hugging Face 和 LangChain 共同维护的一个包,其目标是缩短将 Hugging Face 生态的新功能带给 LangChain 用户的时间。它里面包含了很多功能:
- 有各种模型的实现,比如聊天模型和 Embedding 模型;
- 有数据集的实现,它实现成了 DocumentLoader;
- 有工具的实现,比如文本分类、文本转语音等。
从提供的内容上来看,这个包封装了 Hugging Face 上的主要能力——模型和数据集。其中,不同的模型因为能力上的差异做了不同归结:属于大语言模型的,就归结到了 LangChain 模型上,而无法归结的,就以工具的形式提供。
有了最基本的了解,我们来实现一个简单的功能:
import torch
from langchain_huggingface import HuggingFacePipeline, ChatHuggingFace
device = 0 if torch.cuda.is_available() else -1
llm = HuggingFacePipeline.from_model_id(
model_id="Qwen/Qwen2.5-0.5B-Instruct",
task="text-generation",
device=device,
pipeline_kwargs=dict(
max_new_tokens=512,
return_full_text=False,
),
)
chat_model = ChatHuggingFace(llm=llm)
result = chat_model.invoke("写一首赞美秋天的五言绝句。")
print(result.content)
这里我们也是先构建了一个管道,通过上一讲的学习,这个构建管道的过程我们其实并不陌生,无非就是设定模型 ID、模型用途(task)以及其它一些配置参数。虽然从命名上看,我们是在构建一个管道,但这里的 HuggingFacePipeline 是一个 LangChain 的 LLM 类型。
之所以要强调一下这点,是因为这里的用途(task)只能是与文本相关的能力。相比之下,pipeline 里的参数就会丰富很多,比如,图像分类(image-classification)、视频分类(video-classification)。
llm = HuggingFacePipeline.from_model_id(
model_id="Qwen/Qwen2.5-0.5B-Instruct",
task="text-generation",
device=device,
pipeline_kwargs=dict(
max_new_tokens=512,
return_full_text=False,
),
)
有了 HuggingFacePipeline,我们再把它转成一个 ChatModel,实际上就是做了一层封装:
ChatModel 我们之前已经谈了很多,有了 ChatModel,接下来它就可以与我们熟悉的那些 LangChain 抽象配合在一起了。在我们的示例里,我们就是直接调用它。
前面我们说过,在 LangChain 的体系下,有 ChatModel 和 LLM 两种抽象都可以处理大模型。我们这里定义出的 HuggingFacePipeline 就是 LLM,它也完全可以拿过来单独使用。
在我写下这段文字的时候,langchain-huggingface 这个包的发布时间并不算很长,实现上还有一些不够完善的地方。比如,ChatHuggingFace 的流式应答支持得就不算特别好。在 langchain-community 这个包里,还有一个旧版的 ChatHuggingFace,它本身提供了流的支持,只不过,它需要与旧的一套代码配合使用,而这套代码都处于被舍弃的状态(Deprecated)。
虽然我们可以在代码中支持不同模型的封装,但其实我们还有另外一种选择,就是采用集中接入的方案,彻底摆脱在代码中集成模型。
使用集中接入
无论是直接使用 Hugging Face 的 API,还是使用 LangChain 的 Hugging Face 封装,我们都是把接入管理在自己的代码里。在第 17 讲中,我们介绍了集中接入的工程实践,主要目的就是把接入复杂度从代码里拿出去,放到大模型代理中。除了接入 OpenAI API 之外,接入不同的模型也是一种接入,显然,它也可以放到大模型代理去处理。
我们继续以 One-API 为例。在创建新渠道的时候,类型是有很多选项的,它决定着后端会接入到哪个供应商的模型上。其中的一个选项是 Ollama:
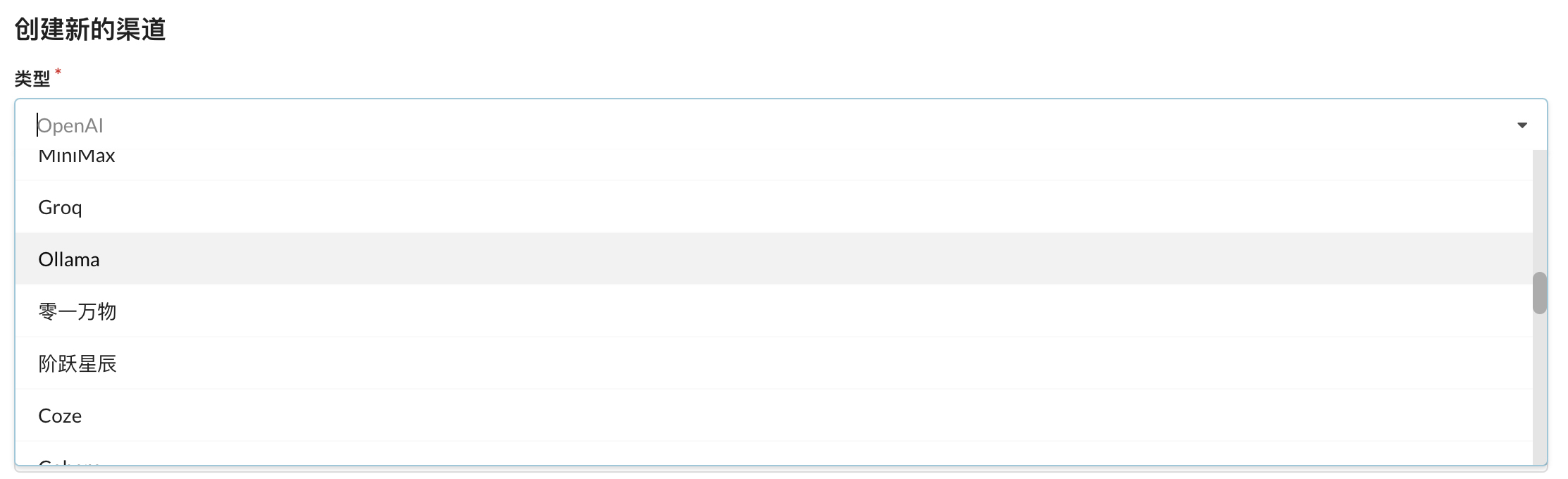
Ollama 是什么呢?它是一个可以在本地运行大模型的轻量级框架。同我们在本地运行代码访问大模型类似,它可以在本地启动一个服务,我们可以通过这个服务去使用相应的大模型。类似的东西也有不少,比如 vllm、gpt4all 等。
有一个运行在本地的大模型,我们就可以做很多的事情了。比如,搭建一个属于自己的聊天机器人,尝试不同的大模型,还有一些新的 AI 编码工具,也是可以接入到本地的大模型。单纯从一个用户的角度,我也推荐每个程序员尝试着在本地运行大模型,做一些不同的事情,它会加深你对大模型的理解。
站在开发的角度,运行在本地的大模型,也就意味着我们可以做私有的部署。我们前面提到的几个本地运行大模型的工具,都提供了服务部署的能力,我们完全可以把它部署到自己的服务器上,通过接口去访问相应的模型,而且,这些工具都提供了 OpenAI API 兼容接口,这使得它们可以与市面上的很多工具配合到一起。
下面我就以 Ollama 为例,介绍一下基本的用法。安装 Ollama 只要找到对应的安装包即可,如果是 Linux,我们可以通过命令行进行安装:
理解 Ollama 的使用,可以类比于 Docker,所以,在 Ollama 的命令中,我们会看到 pull、push、run 等命令。要想使用大模型,我们首先要把大模型拉到本地:
同一个模型会有多个不同的版本,比如,通义千问 2.5 就有 0.5B、1.5B、3B、7B、14B、32B、72B 等不同规模的版本。即便是同一个规模,还会有不同配置的版本。在 Ollama 中,这些不同的版本是通过 Tag 区分的,比如,如果我们想使用 0.5B 版本的,可以这样拉取。
如果想做一些简单的测试,我们可以直接在本地把它运行起来。
启动之后,就是一个命令行版的对话框,对于程序员来说,这就比较熟悉了。
启动 Ollama 实际上是启动了一个服务,所以,我们也可以通过 API 访问这个服务。Ollama 提供了两类 API,一类是它自身定义的 API,另一类就是 OpenAI 兼容 API。下面就是通过它自身 API 访问服务的示例。
curl http://127.0.0.1:11434/api/chat -d '{
"model": "qwen2.5",
"messages": [
{
"model": "qwen2.5","prompt": "写一首关于AI的诗"
}
]
}'
有很多 AI 工具都提供了配置本地服务的能力,我们完全可以通过 Ollama 用一个本地模型来辅助我们工作。有了本地模型,我们可以节省大模型的使用成本,也可以保证自己的数据不外流。下面是一个辅助开发的工具 Cline (也就是曾经的 Claude Dev)的配置界面,我们就可以配置 Ollama 提供服务:
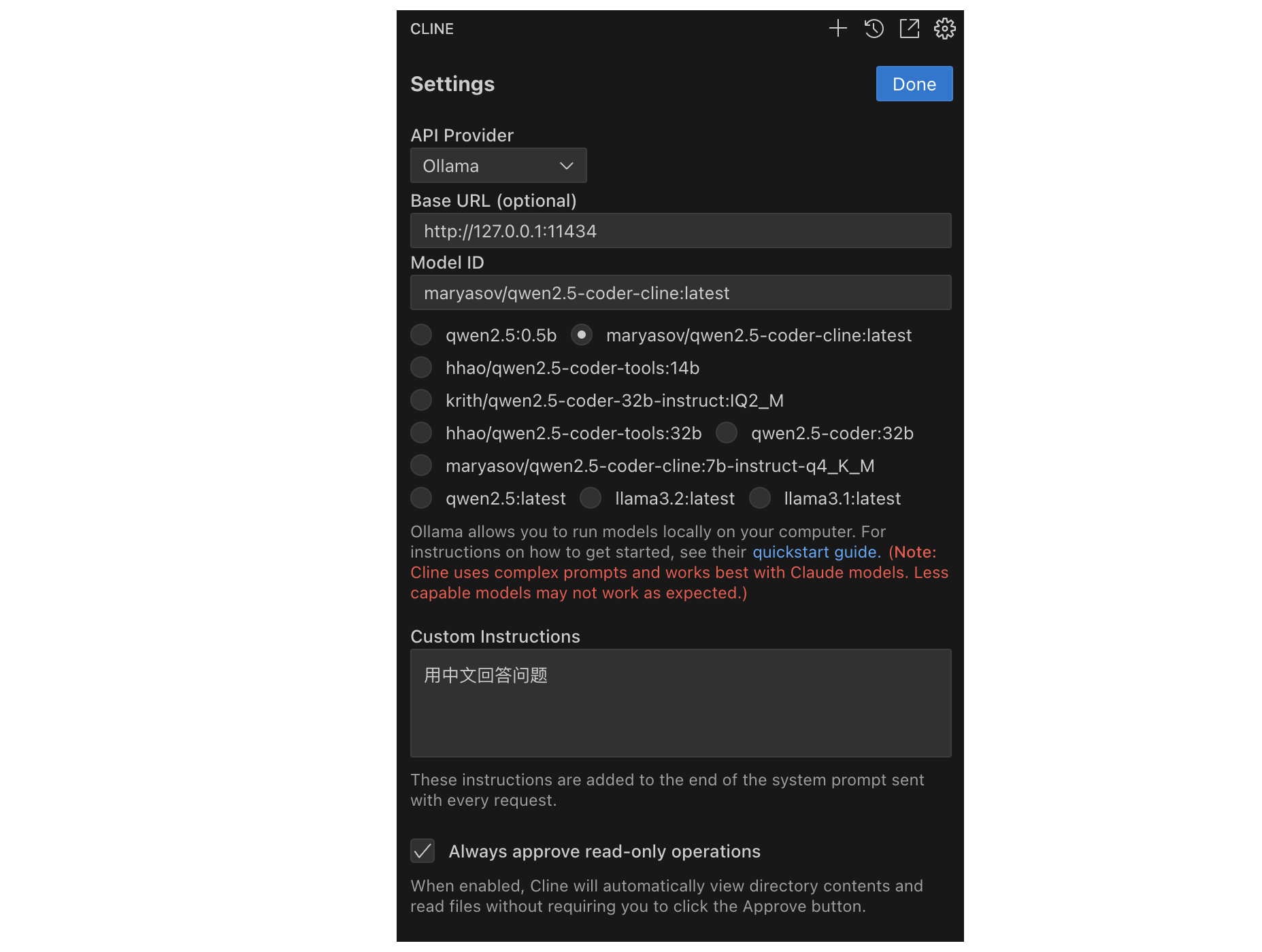
你现在知道了,既然 Ollama 提供了服务,One API 当然可以通过服务接口连接它。配置Ollama 服务,主要是根据自己的需要配置所需的模型。
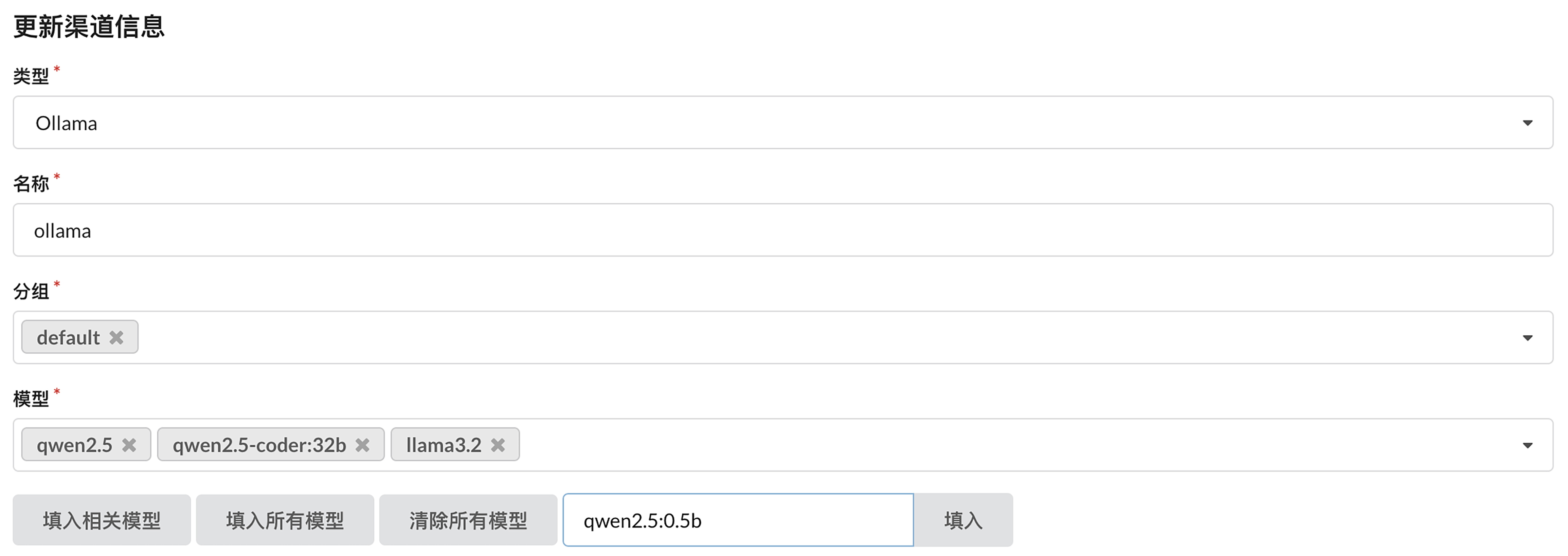
我们可以通过 list 命令查看已经安装的模型。
ollama list
NAME ID SIZE MODIFIED
qwen2.5:0.5b a8b0c5157701 397 MB 16 hours ago
qwen2.5-coder:32b 4bd6cbf2d094 19 GB 2 days ago
qwen2.5:latest 845dbda0ea48 4.7 GB 7 days ago
llama3.2:latest a80c4f17acd5 2.0 GB 8 days ago
在 One API 中填写的就是这里的 NAME 字段,比如,我们在配置中添加了 qwen2.5:0.5b。配置好之后,我们就可以在代码中直接指定模型名为 qwen2.5:0.5b。
completion = client.chat.completions.create(
model="qwen2.5:0.5b",
messages=self.messages,
temperature=0
)
你看到了,这里我们用到 OpenAI 的程序库,但我在这里指定的模型是 qwen2.5:0.5b,并不是 OpenAI 提供的模型。这也是我们集中接入采用 OpenAI 兼容 API 的意义所在。我们在代码层面上,不用考虑模型的差异,因为集中接入层做了这层封装,把不同的供应商屏蔽了,从而保证了我们代码的稳定性。
顺便说一下,Ollama 本身也提供了一个程序库,LangChain 也提供了 Ollama 的封装。如果有需要,可以自行查看。
细心的同学可能发现了,我们在讨论 Ollama 的过程中,并没有提到 Hugging Face。Ollama 相当于本身提供了一个仓库,我们是从 Ollama 的仓库里拉取的模型。但说到模型的丰富程度,肯定是 Hugging Face 更胜一筹的。我们可以使用 Hugging Face 的模型吗?答案是可以。
在 Ollama 上使用模型,运行的命令是后面这样。
不过,有一点要说明一下,并不是所有的模型都可以使用 Ollama 运行的。为了确认这一点,你可以在模型的说明页上查看一下。点击 “Use this model”,如果下拉菜单中有 Ollama,那就是可以使用,你可以复制相应的命令去执行;否则,这个模型可能无法直接使用。
下图我提供了一个示例。
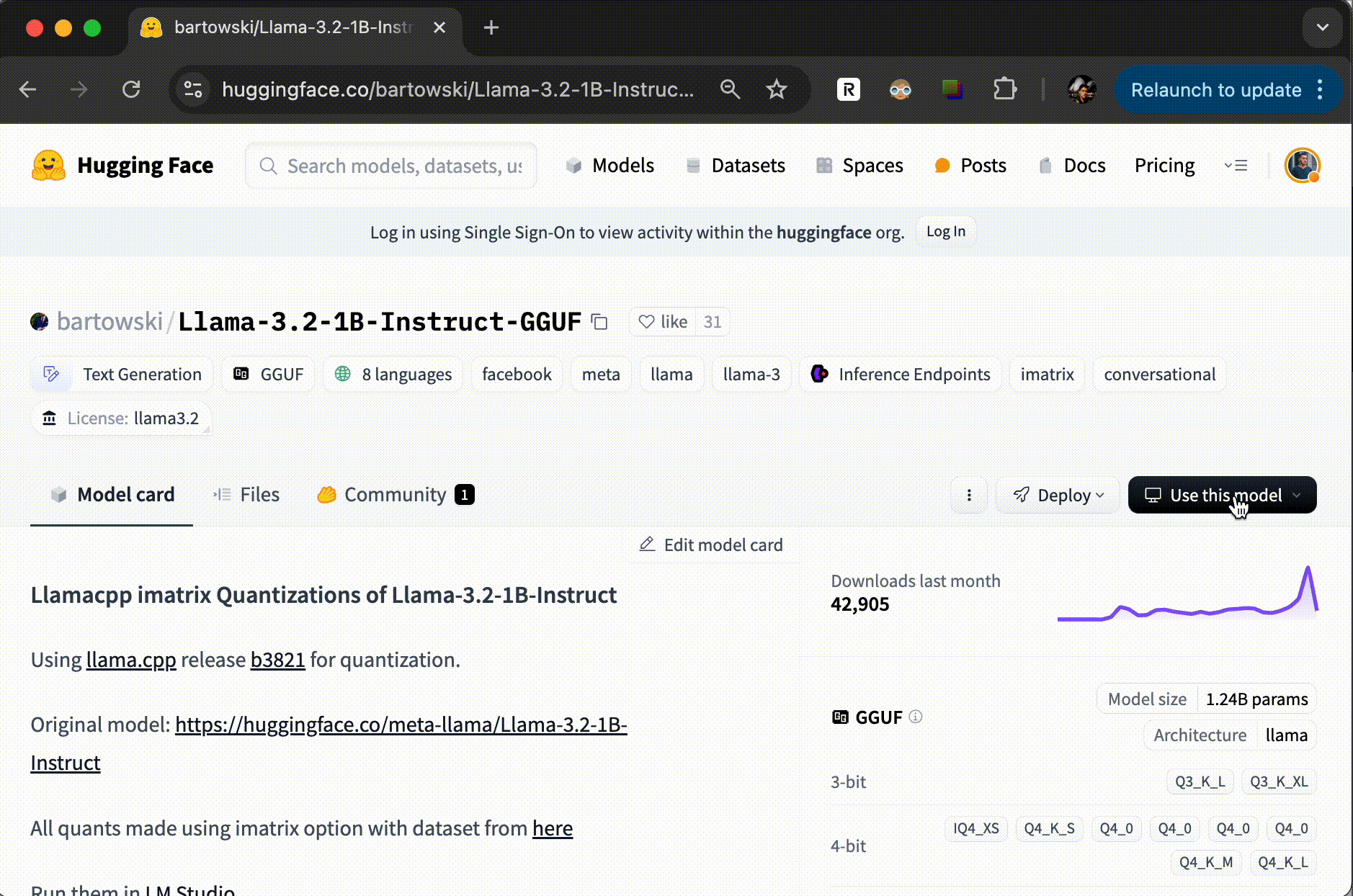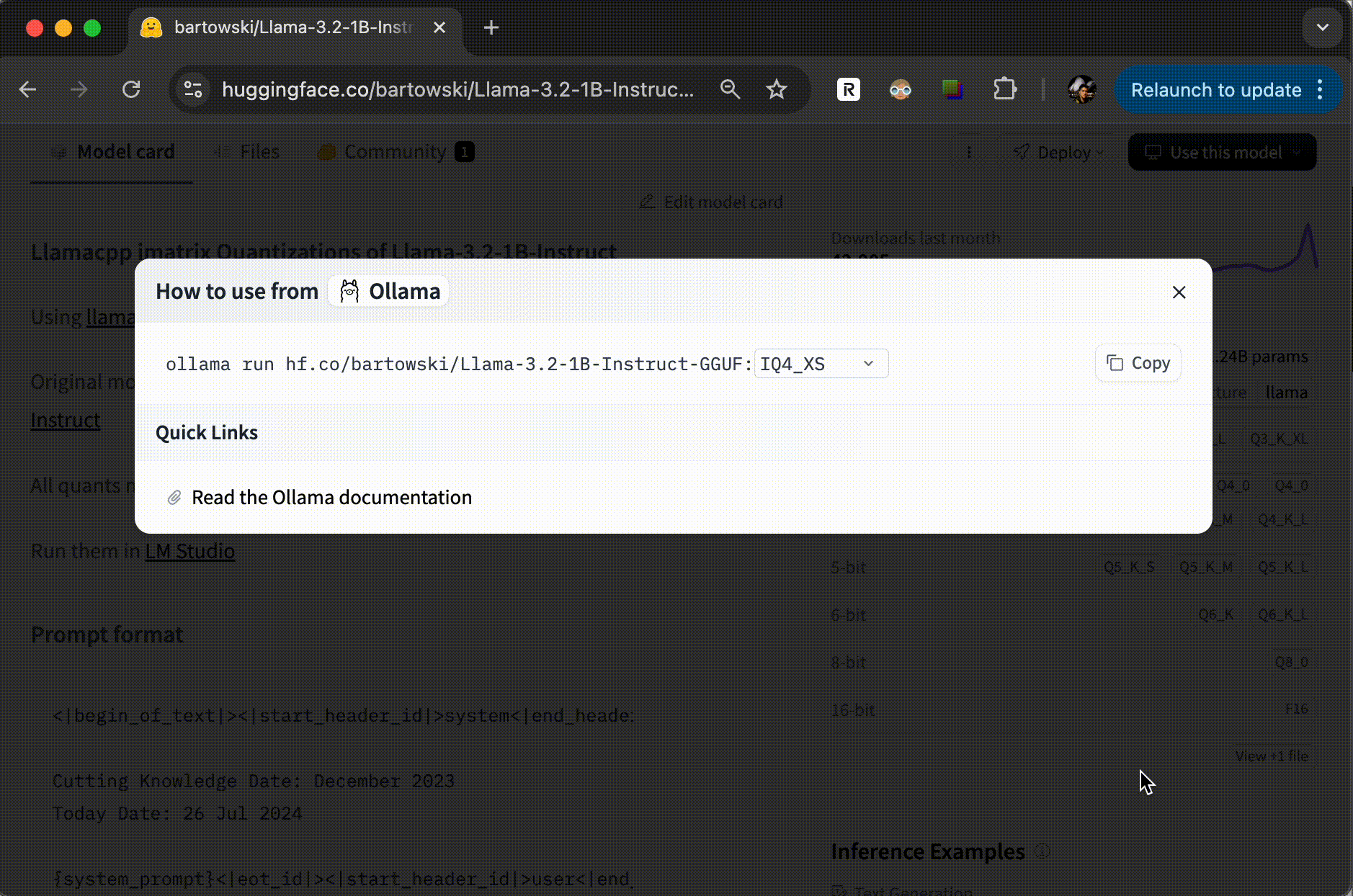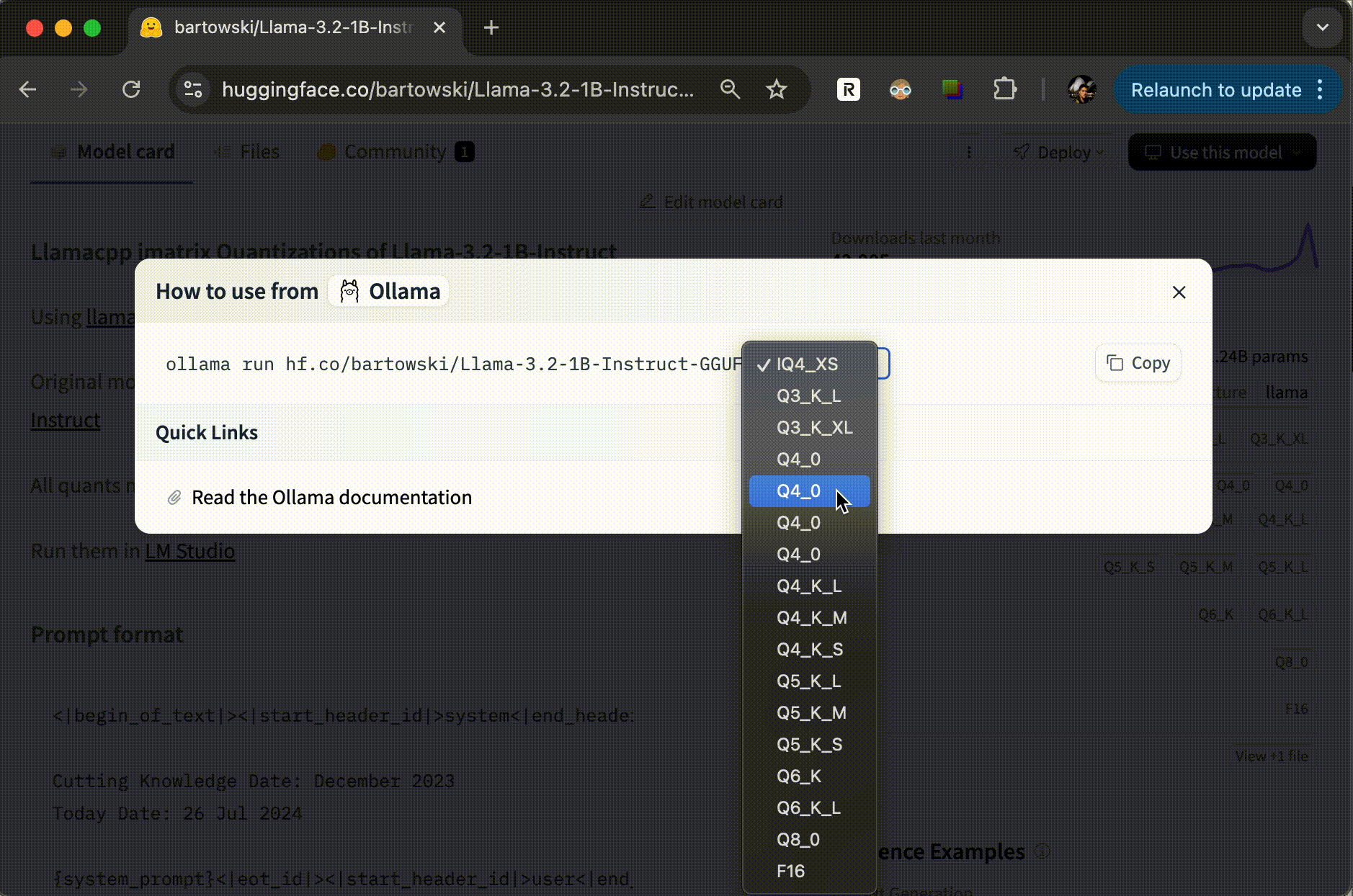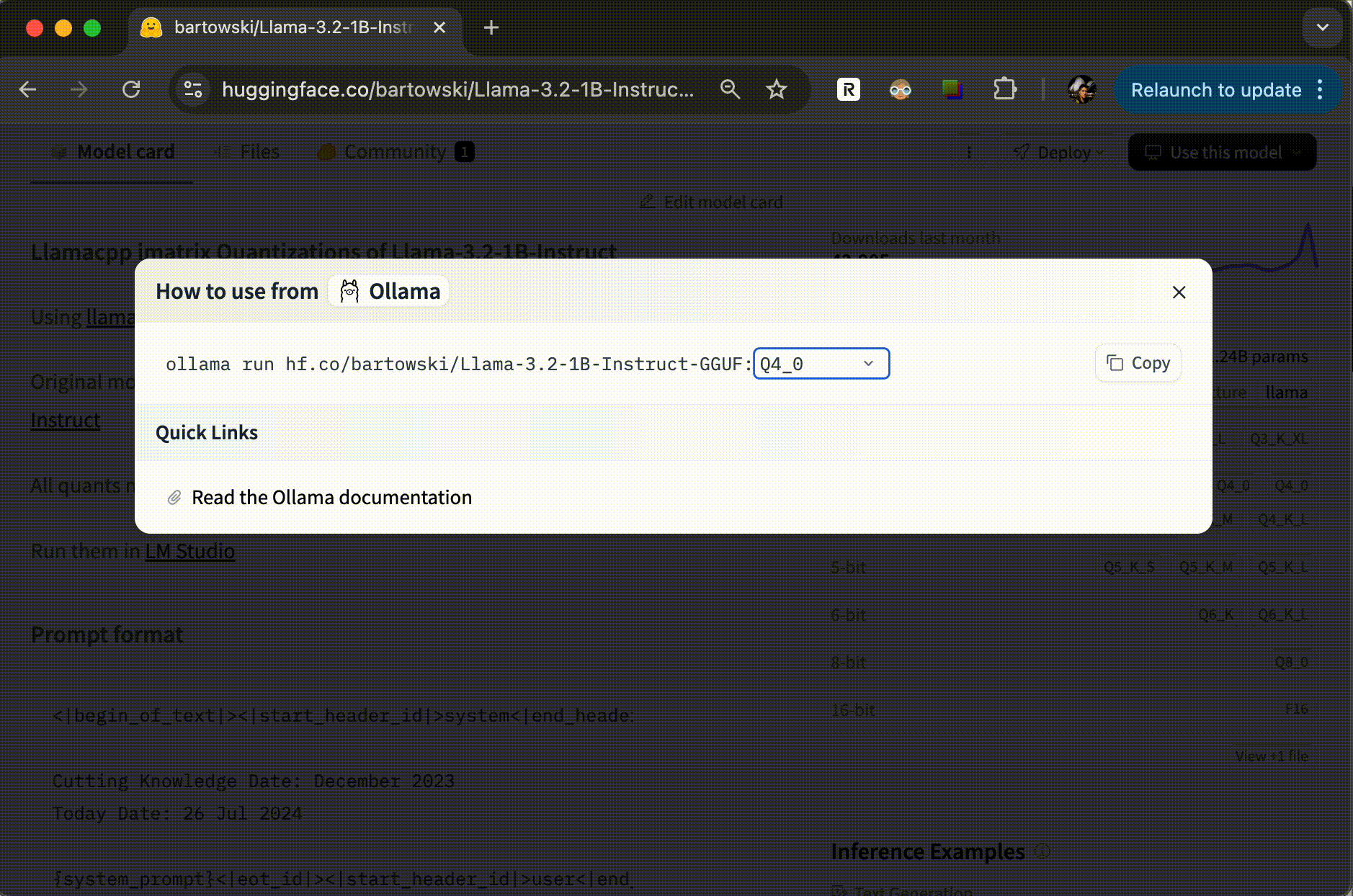
总结时刻
这一讲,我们讲了在工程上如何使用开源模型。为了让不同的大模型协调一致,我们需要一层封装,保证代码的灵活性。我们讲了两种封装方案:
- 在代码中封装,主要是讲了 LangChain 的封装。
- 采用集中接入,也就是在大模型代理中接入不同的模型。
LangChain 的核心抽象中的模型主要就是解决这个问题的。如果想集成 Hugging Face 的模型,我们只要引入 langchain-huggingface 这个包。它提供了各种模型的实现,有数据集的实现,还有工具的实现。
集中接入的方案中,我们以 One API 接入 Ollama 为主线讲解了如何使用开源模型。Ollama 本身是一个非常强大的工具。我们可以用它来提供服务,也可以用它在本地运行大模型,给自己的 AI 工具提供后端。
如果今天的内容你只能记住一件事,那请记住,在本地运行大模型,增进对大模型的了解。
思考题
我在这里只介绍了 langchain-huggingface 中大模型部分,我建议你去了解一下 Embeddings、数据集和工具,增加对 Hugging Face 上模型的了解。欢迎在留言区分享你的学习心得。
- 张申傲 👍(1) 💬(0)
第19讲打卡~
2025-02-13