20 模型微调:创建一个属于自己的大模型
你好,我是郑晔!
前面两讲,我们讲了如何使用别人创建好的开源模型,这可以帮助我们控制成本,或是规避风险。这些大模型都需要与我们前面讲的技术配合起来,才能够实现特定的应用功能。除了使用别人的模型,我们也可以使用自己的模型。
前面讲 RAG 时,我们说过,它本质上是让大模型知道更多的东西,尤其是属于你自己业务领域的东西。当时我们就说,RAG 只是其中的一种选择,还有另外一种选择,就是模型微调。这一讲,我们就来说说模型微调。
什么是模型微调
模型微调,顾名思义,就是对模型微微做一些调整。为什么要做微调呢?如果可以的话,每个公司都想拥有一个属于自己的大模型。但是,现实比较残酷,训练一个大模型需要花太多的钱。按照一些大公司的说法,一个千亿参数的大模型,训练一次的成本大约需要几百万美元。这显然就超过一个普通公司承受的范围。虽然我们无法训练一个属于自己的大模型,但一个好消息是,我们可以做模型微调。
大模型是构建于神经网络基础之上的,神经网络可以理解成一个一个的神经元构建的网络。训练模型,就是在调整神经元之间的连接方式。一次完整的训练就相当于把所有的神经元连接都调整一遍,这个计算规模相当之大,是我们无法承受的。
所谓微调,就是把一个训练好的模型中的一部分连接重新调整。因为只做了一部分的调整,所以,规模就要小得多,训练成本也就要小得多。
前面说过,RAG 和模型微调可以解决同样的问题,从本质上说,就是把核心业务数据放在提示词里,还是放在模型里。
两种做法各有优劣。放到提示词里,优势就是做法比较简单,但其问题的关键在于能否取到恰当的数据。如果不能取到恰当的数据,就可能会出现“幻觉”问题,也就是大模型会一本正经地胡说八道。放到模型里,优势是数据准确性会提高,但前提条件是在训练的时候,要准备高质量的数据,否则就是“垃圾进,垃圾出”了,而微调好一个模型,并不是一件很容易的事情。
在工程实践中,二者往往是结合使用的。模型微调不是时刻在进行,所以,一些团队的做法是,用 RAG 的方式提取新的业务数据,积累到一定阶段,用这些数据进行模型微调,把这些数据内置到模型中,再把新模型替换到业务系统中。这样一来,既保证数据的新鲜,又保证了基本的服务质量。
怎样微调模型
模型微调,需要我们先选定一个模型。如果选定的模型是像 OpenAI 这样的闭源模型,就需要使用其对应的模型微调服务。不过,使用这种服务也就意味着要把数据提供出去。所以,很多团队的实际做法是,基于开源模型的微调。
具体的模型微调通常分成几个步骤:
- 准备训练数据
- 训练模型
- 评估结果
- 使用模型
这其中最耗时耗力的,应该是准备数据了。首先,微调大模型需要多准备一些数据,数据量过少,可能看上去完全不起作用。毕竟大模型那么多参数,如果只改动几个,占比太低,就和没改动效果差不多。其次,数据也要精心挑选一下,还是那句话:垃圾进,垃圾出。所以,这个过程不是技术活,而是一个体力活。什么数据是好数据?最好由一个懂业务的人说了算。
顺便说一下,因为准备数据耗时耗力,有人把一些整理好的数据开源了出来,Hugging Face 上有大量这种数据集。如果站在学习的角度,我们可以把这些数据集拿过来直接用。
我们知道了要准备数据,但数据格式是什么样的呢?这取决于模型微调的具体方式,比如,OpenAI 的模型微调需要把数据准备成下面这样:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
接下来,我们就以 LLaMA Factory 为例具体看一下模型微调的过程。
使用 LLaMa Factory 微调模型
LLaMA Factory 是这样自我介绍的:它是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。它当然有很多优点,比如,支持很多不同的模型、支持很多训练方法,而且效率很高。如果你初次接触模型微调,它更真实的优点是,能够在本地运行,还有一个图形化的界面。
使用 LLaMa Factory 需要先把它的代码 clone 下来。
然后就是安装相应的依赖。为了不把现有的 Python 环境搞乱,我们还可以创建一个虚拟环境。
cd LLaMA-Factory
conda create -n llama-factory python=3.12
conda activate llama-factory
pip install -e ".[torch,metrics]"
安装依赖之后,我们就可以运行下面的命令判断安装是否成功。
接着,我们需要先准备一下训练数据。LlaMA Factory 支持 alpaca 格式和 sharegpt 格式,它们实际上都是 JSON 的格式。下面是一个 alpaca 格式的示例:
[
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""
}
]
接下来是 sharegpt 格式的示例:
[
{
"conversations": [
{
"from": "human",
"value": "你能解释一下算法分析中的大O记法概念吗?"
},
{
"from": "gpt",
"value": "是的,大O表示法是一种描述算法性能随输入数据大小增加的方法。它用于估计算法在最坏情况下的时间复杂度或空间复杂度。大O中的“O”代表“数量级”,这意味着随着输入大小的增加,算法所需的操作数以一定的速率增长。\n\n例如,如果我们有一个需要n步才能解决大小为n的问题的算法,那么时间复杂度可以表示为O(n),这意味着操作数随着输入大小线性增长。如果我们有一个需要n^2步才能解决大小为n的问题的算法,那么时间复杂度可以表示为O(n^2),这意味着操作数随着输入大小二次方增长。\n\n还有其他几种大O表示法,如O(log n)、O(n log n)、O(2^n)等,它们代表了随着输入大小增加的不同操作数增长速率。通过分析算法的大O表示法,我们可以比较不同算法的性能,并选择给定问题最有效的算法。\n\n您是否有关于大O表示法或算法分析的特定问题?"
}
],
"tools": "[]"
}
]
从这两个示例我们不难看出,它们就是一个对话的结构,相当于一个人问了一个问题,大模型给出了一个回答。从简单直接的角度,sharegpt 格式更符合我们常规理解的会话形式,如果你是初次尝试,不妨使用这个格式。
确定了数据格式,我们需要把数据改写成这个格式,把它们存到一个文件里。然后,把这个文件放到 LLaMa Factory 的 data 目录里。接着,在 dataset_info.json 里加上这个文件的描述。dataset_info.json 相当于是一个元文件,用来描述在 LLaMa Factory 界面上可以看到的数据是什么样的。
下面是一个例子,我们指定了文件的名称和相应的文件格式:
"dreamhead": {
"file_name": "dreamhead.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
准备好数据,我们就可以开始训练了。前面说了,LLaMa Factory 对新手最友好的地方是它提供了图形化界面,我们可以通过下面的命令,启动图形化界面。
LLaMa Factory 的图形界面如下所示。
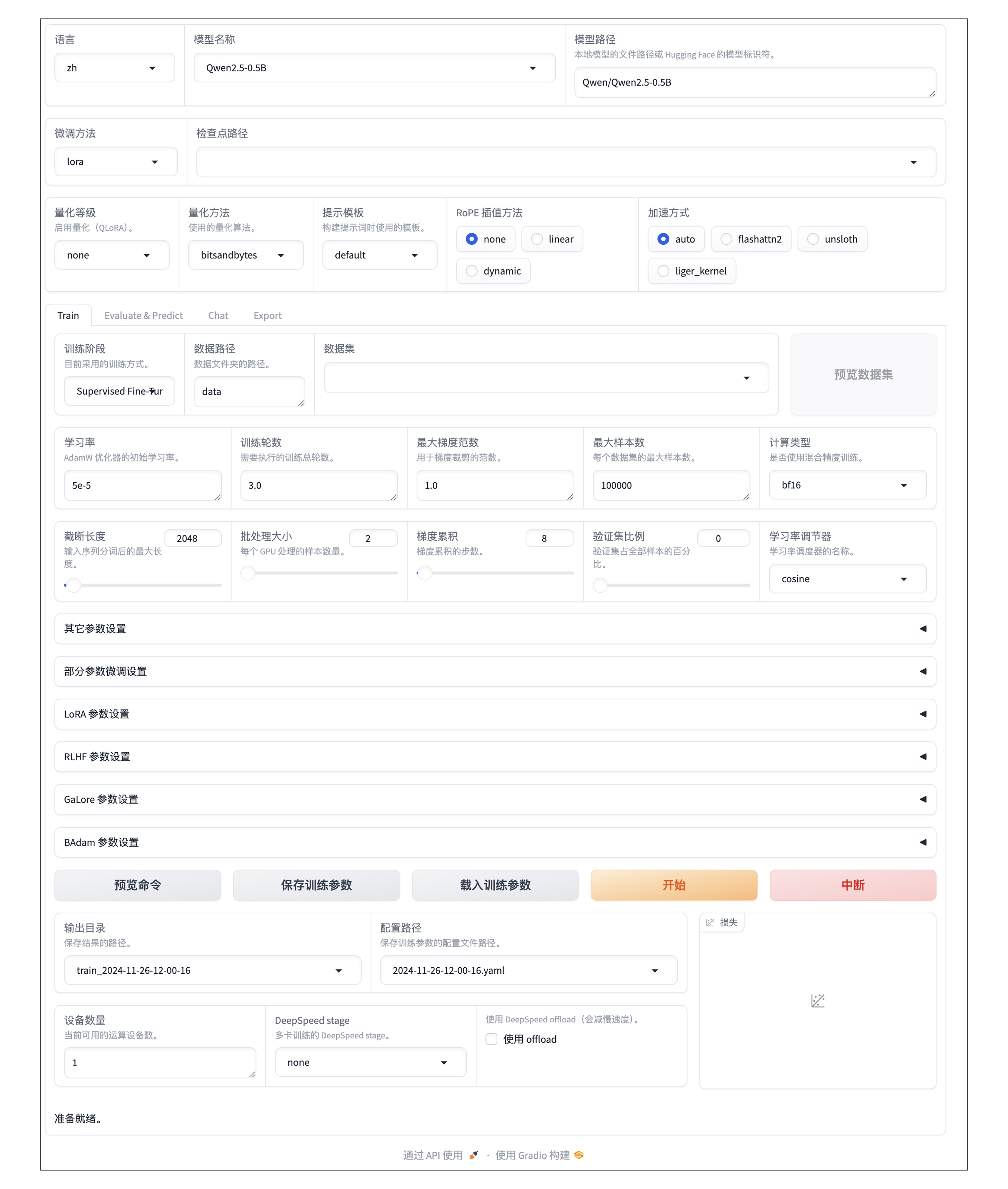
虽然说是一个图形界面,但这个界面上的参数之多,已经达到了眼花缭乱的地步。不过,我们并不需要一上来就把所有的参数搞清楚,要微调自己的模型,最核心的几个参数是:
- 模型名称,也就是我们用于微调的基础模型。
- 数据集,在这里可以找到前面准备好的数据。
- 除此之外,我们还需要知道输出目录,毕竟,我们还是要结果的。
做好了最基础的配置,我们只要点击“开始”,就可以开始执行训练了,训练的时间会因为配置的差异有所不同。如果一切顺利,我们只需要等待这个过程结束。
这些界面上的各种配置,最终都会以命令行的方式在后台运行。点击“预览命令”,我们就可以看到在后台要执行的命令。我们完全可以自己在命令行里执行这个命令进行训练。
当训练结束,我们可以在输出目录中找到微调之后的模型。有了模型,我们怎么把它用起来呢?根据我们上一讲讲到的做法,最简单的方案就是把它接入到 Ollama 中。
在 Ollama 中运行微调模型
怎样在 Ollama 中接入一个新模型呢?我们需要给 Ollama 提供一份模型描述文件,也就是它的 Modelfile。在 Ollama 上运行的每个模型都有自己的 Modelfile,我们可以通过命令查看它们的 Modelfile,比如:
下面是一个 Modelfile 的示例:
在这个 Modelfile 里,FROM 指向基础模型,而 ADAPTER 指向了微调过的文件。不过,你可能会发现在生成模型的目录下并没有一个 gguf 文件。GGUF 是一种模型文件的存储格式,它也是 Ollama 支持的文件格式。坏消息是,我们微调的模型并不是以这种格式存储的,好消息是,我们可以把自己的模型转换成 GGUF。
在微调过程中,我们采用了缺省的 LoRA(Low-Rank Adaptation),这是一种微调模型的技术。llama.cpp 这个开源项目就提供了一个转换程序,可以将 LoRA 的结果转换成 GGUF 格式。这个转换程序是一个单独的 Python 程序,我们可以在本地执行它,其主要的依赖就是 transformers这个库。安装好依赖之后,我们就执行这个转换程序,得到相应的 GGUF 文件。
配置好相应的 Modelfile,我们就可以在 Ollama 中创建一个自己的模型了。
如果一切顺利,你就得到了一个可以在 Ollama 中运行的模型,然后,我们就像运行一个普通的模型一样运行它。
好,你现在可以测试你的模型了,评估微调之后大模型的效果,如果觉得不理想,就需要回到前面重新来过。正如上一讲所说,一个模型接入了 Ollama,它就能接入到 One-API 上,而接入了大模型代理,我们就可以在项目中访问它了。这样,我们就完成了一个完整的微调流程。
总结时刻
这一讲,我们介绍了模型微调。模型微调是 RAG 之外另一种扩展大模型知识面的手段。它是利用自己的训练数据对已经训练好的大模型进行“微微”的调整。在实际项目中,我们既可以在微调和 RAG 选择,也可以二者共同使用。
微调大模型的关键是数据准备。最好由懂业务的人参与到数据准备中,要想让微调效果对大模型有所影响,需要准备大量的数据。不同的训练工具格式是不同的,我们需要按照格式把数据准备好。
准备好数据之后,就进入到微调的训练阶段,这个过程会比较耗时。训练好的模型,我们可以通过 Ollama 接入到实际的项目中,这样,我们就能够使用自己的模型了。
如果今天的内容你只能记住一件事,那请记住,模型微调的关键是准备好数据。
思考题
这一讲我带你熟悉了一个微调的基本流程,关于微调还有很多细节的内容。我建议你去了解一下微调的各种知识,比如有哪些工具、各个参数是什么。欢迎在留言区分享你的学习心得。
- 张申傲 👍(1) 💬(1)
第20讲打卡~ 请教老师,关于微调模型的效果评估,有什么比较好的实践经验吗?
2025-02-13 - astop 👍(0) 💬(1)
郑烨老师,有deepseek的微调吗?
2025-01-31 - 大叶枫 👍(0) 💬(1)
看的很快,做一遍还挺费事的。。
2025-01-16 - Geek_f5ed6c 👍(0) 💬(1)
真实的投入进去练习
2025-01-15 - hao-kuai 👍(3) 💬(2)
训练模型不需要纠错吗?还是说准确性在训练数据那里已经解决了?
2024-12-16 - 张贺 👍(2) 💬(0)
看着简单,真的自己从头跑一遍还是挺不容易的。
2024-12-24