21 如何面对不断更新的大模型
你好,我是郑晔!
前面我们用了二十讲的篇幅,讨论 AI 应用开发的主要内容。所有这些内容的前提条件都是我们基于已有的大模型,但是,我们并没有讨论如何选择大模型,原因很简单,大模型发展很快,今天选择的理由可能明天就不成立了。
大模型领域本身就是一个发展迅速的领域:才说 GPT 3.5 好,又来了个更强大的 GPT 4,没过多久,GPT-o1 又展现出强大的推理能力;今天有个 Llama,明天出个 QWen,后天 Mistral 也很强大;总而言之,只要你关注,总会有新的大模型以各种能力展现在你面前。这确实是一件令人焦虑的事情。
这一讲,我们就来谈谈,如何面对这些不断更新的大模型。
大模型的不变
虽说大模型领域是以“变”为主,不断推陈出新,但从做一个软件系统的角度,我想先谈谈大模型的不变。因为在软件开发中,我们一直在追求的就是将变与不变隔离开,让不变的东西尽可能稳定下来。
大模型的不变首先体现在 API 上。我在前面的内容说过,OpenAI API 在某种意义上已经成为了行业的事实标准,加之集中接入的引入,我们只要使用统一的 OpenAI 接口,几乎可以访问所有的模型。从这个角度上说,访问大模型的 API 就是统一的。
有了统一的大模型 API,也就意味着我们的代码可以通过相同的方式进行处理,无需考虑不同 API 之间的差异性。站在开发的角度看,这是代码稳定的前提条件。不同的模型之间的差异,主要体现在给 API 传入的模型参数的差异。
不过,前面我们也说过,大模型应用开发中,API 的影响是很低的,真正的核心内容都在于大模型的交互上。从我们的观感上看,各种新的大模型层出不穷,大模型有不变的东西吗?答案是有。
虽然 GPT 刚出现时,让人眼前一亮,而且 OpenAI 又几次发布了让人惊讶的新模型,但本质上说,大模型的底层技术在短时间之内并没有更大的进步。
从 GPT 3.5 到 GPT 4,我们可以理解为是有了更多的数据,让大模型表现进了一步,而 GPT 4 到 GPT-o1,其实是一些工程上的进步,简单地理解,是把提示工程的技术内置到大模型里了。不光 Open AI 的大模型是这样,其它大模型也是如此。
我们目前看到的这些进步基本上都是工程层面的进步,也就是说,一个大模型有的东西,另一些大模型很快就能跟上,比如,当 GPT 4 支持了图像识别,Llama 也很快有了一个 Vision 版本;GPT-o1 用提示工程让大模型的推理能力得到提升,不久,Qwen 就推出了 QwQ,它也具备不错的推理能力。
工程上的进步很重要,但这些都是量变,不是质变,所以,虽然想做好有难度,却并非遥不可及。一个新技术出现,追随者很快就能跟上。出现这种情况,也很好理解,毕竟大家处于同一个时代,底层技术都是公开的。
正是因为如此,大模型的能力都会处于一个类似的水平线上,而且,底线会越来越高。这些大模型的底线能力就是大模型里不变的东西。
我们在应用开发部分讲了很多内容,虽然我们使用的是 OpenAI 的 GPT 模型,但你也可以尝试着把这些应用运行在其它的模型上,最简单的方案就是使用我在前面几讲介绍过的 Ollama。你会发现,很多大模型的表现得都还不错。我们在这些应用里用到的能力几乎就是大模型中最基础的能力,比如,聊天、按格式输出内容、基本的推理能力等等。
讨论大模型中这些不变的东西,我想说的是,开发一个 AI 应用,核心点并不是选择一个更好的大模型,而是自己的业务。在现阶段,再好的大模型也不能帮我们把业务理顺,再好的大模型也只能起到一个辅助的作用,不要过分高估大模型所能起到的作用。我们要做的是,用大模型改造我们的业务流程,让 AI 嵌入到我们的业务流程中去。
由“不变”带来的设计
理解了大模型现在的水准,还可以帮助我们做出一些更好的架构决策。举个例子,我们之前好几次强调过 AI 应用的成本问题,一个重要的原因是,调用大模型服务,不管你的内容是什么,大模型服务都要按照同样的标准进行收费。
仔细分析一下,我们便不难发现,我们应用中,有一部分的工作属于简单的推理工作,比如我们介绍过的 ReAct,其中一个核心步骤就是确定调用哪个工具。如果我们搭建了一个本地的开源模型,这些简单的推理工作完全可以在本地完成,无需为此支付模型调用的费用,以此节省调用模型的成本。
一旦我们想清楚,不同的请求可以发给不同的模型,我们就可以在架构上做一个区分,一部分请求需要发给大模型服务获取更好的表现,一部分请求(比如简单推理)交给本地的模型,完成基本的操作。在这种思路下,整个的服务处理过程就会有多个不同的模型参与。既然可以引入一个额外的模型,我们完全可以再进一步,在处理过程中,引入多个模型,让不同的模型完成不同的工作。
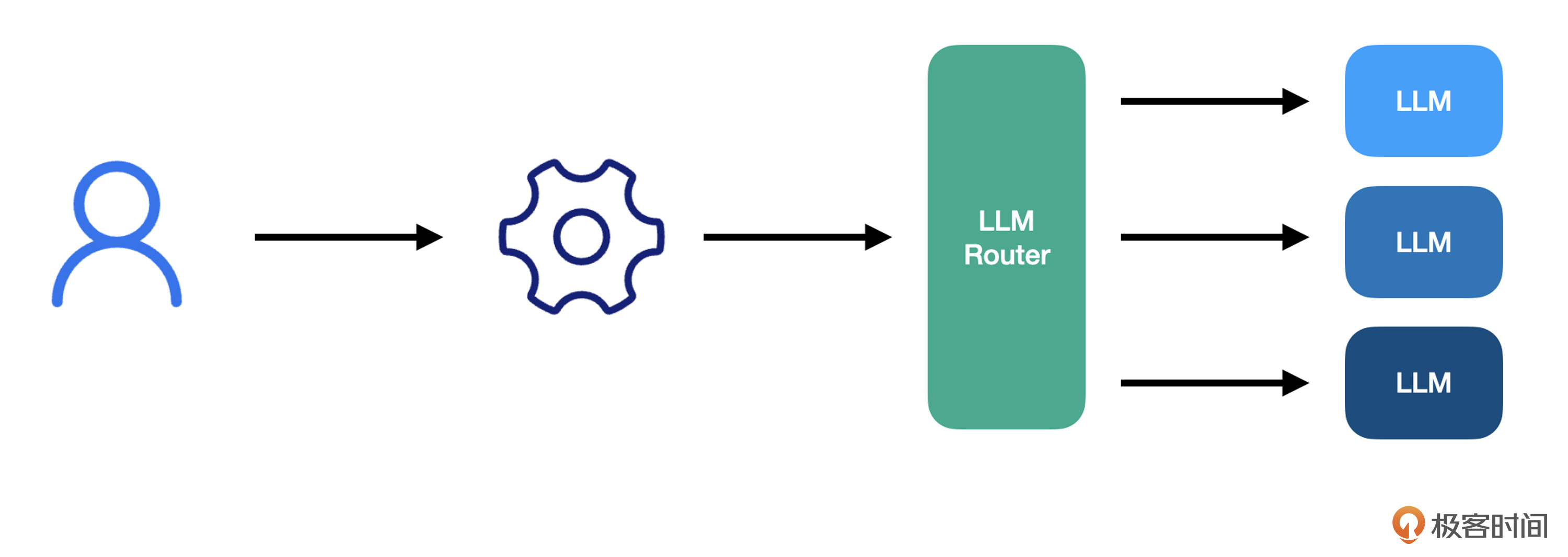
在这个架构中,我们引入了一个 LLM Router,也就是大模型路由,它负责根据用途的差异,采用不同的模型。比如,聊天就用 Open AI 的服务,推理使用本地部署的开源模型。有了大模型路由,我们就可以把应用和使用不同模型隔离开来,以保证应用代码的稳定。
学过前面的课程,你可能会觉得这个结构有点类似于前面说过的大模型代理。二者不同的点在于,大模型代理是做一个独立的部分,它只提供标准的 OpenAI API,我们在调用时,需要指定模型,而大模型路由,则是要根据用途确定不同的大模型,请求方甚至都不用指定模型,因为我们到底使用哪个模型已经在路由内部配置好了。
之所以把用途与模型隔离开来,是因为评估什么模型适合用在什么地方,本质上是一个技术选型的工作。这点一旦确定,在一段时间内是可以保持稳定的。
大模型的变
你或许会有疑问,按照我的说法,我真的不需要关心大模型的新进展了吗?我只要把大模型应用开发完,就放在那不动了吗?
从软件开发的角度来说,一个系统能够正常运作,我们也就没有必要经常动它。我们当然希望我们做好的系统能够长时间保持稳定。但作为一个有经验的程序员,我们知道,一个有生命力的系统不可能长时间稳定,总有一些新的需求会进来。有了大模型,这一点应该也是没有什么变化的——总会发现适合大模型的新场景,总要评估怎样的模型是合适的。
正如我们在各类新闻中看到的,新模型不断出现。作为技术人员,我们需要关注的这些模型的特点是什么,核心在于找到大模型中“变”的地方。这里的“关注”,首先是找出这些“变”的地方可以创造怎样的使用场景。举个例子,GPT-4V 的出现,让大模型具备了图像识别的功能,这就可以创造出很多不同的玩法,比如,根据手绘图生成代码。
其次,我们需要看看是否会有性能的大幅度提升,比如,GPT 3.5 到 4,虽然从功能上改变不大,但性能上有了大幅度提升。在这种情况下,我们就可以评估是否有替换模型的必要。我就曾经在一些项目中,把 GPT 3.5 用在了一些推理的场景上,而聊天的场景切换到 GPT 4 上。
再者,我们也可以关注使用成本。比如,2023 年的时候,GPT 4 在性能上可谓一骑绝尘,很多时候,我们想达到理想的效果,必须忍受其高昂的使用成本,但到了 2024 年,很多开源模型都已经达到了 GPT 4 的水准,我们完全可以用这些模型替代 GPT 4。当然,OpenAI 也是看到了这个趋势,GPT 4 新模型的使用成本也在逐渐降低。
前面说的是一些通用的考量,如果你的应用场景是比较特殊的,往往就需要关注针对这些场景的模型。比如,很多编程工具像 Cursor、Cline 会推荐使用 Claude 3.5 sonnect。这些模型针对特定的场景做了一些优化,在这些场景下,其表现会远远好于通用的模型。这些特定场景的模型还没有像通用大模型一样相对稳定,其变化还是值得开发者们关注。
前面我们说了大模型的“变”和“不变”,你可能会有些困惑,我到底该怎么应对呢?简单说,由于不变,我们可以把系统做稳定;应对变,我们可以抓住核心点,定期评估。大模型领域目前还是处于快速发展之中,我们普通程序员要做的,就是抓住大模型带给我们的机遇,做出更好的应用。
总结时刻
这一讲,我们谈到了如何面对不断更新的大模型,核心的关注点就是大模型的“变”和“不变”。
不变的是,大模型的 API 和基础能力。我们要利用这些能力构建自己的应用,而应用的核心是我们的业务,大模型是帮助我们提供更好的服务体验。
由于大模型基础能力的提高,我们可以在一个服务中使用多个不同的大模型,既可以节省成本,又可以找到最佳的表现。通过引入大模型路由,我们可以把其中的复杂度从应用中分离出来。
应对大模型的变,我们需要找到自己的核心关注点,是使用场景在增加,还是模型能力有提升,抑或是成本得到控制。只有找到自己的核心关注点,我们才不会在不断涌现的新模型中迷失。
如果今天的内容你只能记住一件事,那请记住,找到自己的关注点,让大模型为我所用。
思考题
大模型总在不断地更新,总会有新的大模型出现。我建议你了解一下近期发布的新模型,看看这些模型中有哪些特点引起了你的注意。欢迎在留言区分享你的学习心得。
- hao-kuai 👍(8) 💬(2)
看似在讲大模型,实则在教用已有的软件设计知识来处理大模型这种新技术带来的变化
2024-12-18 - 张申傲 👍(1) 💬(0)
第21讲打卡~ 软件设计的核心思想,就是将变与不变进行隔离
2025-02-14 - Geek_8cf9dd 👍(0) 💬(0)
老师的总结非常到位,通俗易懂
2025-02-18 - 🤡 👍(0) 💬(0)
授人以鱼,不如授之以渔
2025-02-06