06 Shuffle管理:为什么Shuffle是性能瓶颈?
你好,我是吴磊。
在上一讲,我们拜访了斯巴克国际建筑集团总公司,结识了Spark调度系统的三巨头:DAGScheduler、TaskScheduler和SchedulerBackend。相信你已经感受到,调度系统组件众多且运作流程精密而又复杂。
任务调度的首要环节,是DAGScheduler以Shuffle为边界,把计算图DAG切割为多个执行阶段Stages。显然,Shuffle是这个环节的关键。那么,我们不禁要问:“Shuffle是什么?为什么任务执行需要Shuffle操作?Shuffle是怎样一个过程?”
今天这一讲,我们转而去“拜访”斯巴克国际建筑集团的分公司,用“工地搬砖的任务”来理解Shuffle及其工作原理。由于Shuffle的计算几乎需要消耗所有类型的硬件资源,比如CPU、内存、磁盘与网络,在绝大多数的Spark作业中,Shuffle往往是作业执行性能的瓶颈,因此,我们必须要掌握Shuffle的工作原理,从而为Shuffle环节的优化打下坚实基础。
什么是Shuffle
我们先不急着给Shuffle下正式的定义,为了帮你迅速地理解Shuffle的含义,从而达到事半功倍的效果,我们不妨先去拜访斯巴克集团的分公司,去看看“工地搬砖”是怎么一回事。
斯巴克集团的各家分公司分别驻扎在不同的建筑工地,每家分公司的人员配置和基础设施都大同小异:在人员方面,各家分公司都有建筑工人若干、以及负责管理这些工人的工头。在基础设施方面,每家分公司都有临时搭建、方便存取建材的临时仓库,这些仓库配备各式各样的建筑原材料,比如混凝土砖头、普通砖头、草坪砖头等等。
咱们参观、考察斯巴克建筑集团的目的,毕竟还是学习Spark,因此我们得把分公司的人与物和Spark的相关概念对应上,这样才能方便你快速理解Spark的诸多组件与核心原理。
分公司的人与物和Spark的相关概念是这样对应的:
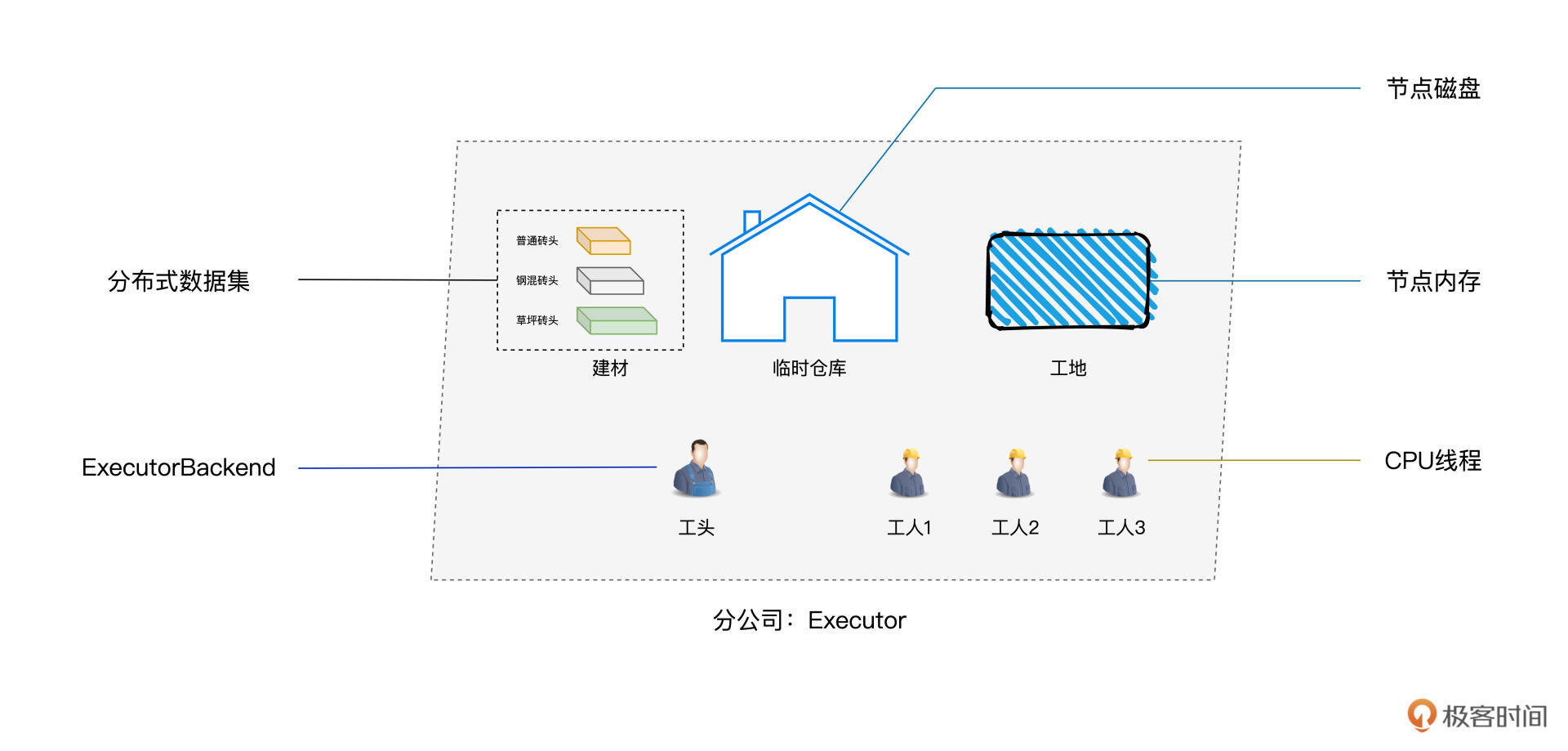
基于图中不同概念的对应关系,接下来,我们来看“工地搬砖”的任务。斯巴克建筑集团的3家分公司,分别接到3个不同的建筑任务。第一家分公司的建筑项目是摩天大厦,第二家分公司被要求在工地上建造一座“萌宠乐园”,而第三家分公司收到的任务是打造露天公园。为了叙述方便,我们把三家分公司分别称作分公司1、分公司2和分公司3。
显然,不同建筑项目对于建材的选型要求是有区别的,摩天大厦的建造需要刚性强度更高的混凝土砖头,同理,露天公园的建设需要透水性好的草坪砖头,而萌宠乐园使用普通砖头即可。
可是,不同类型的砖头,分别散落在3家公司的临时仓库中。为了实现资源的高效利用,每个分公司的施工工人们,都需要从另外两家把项目特需的砖头搬运过来。对于这个过程,我们把它叫作“搬砖任务”。
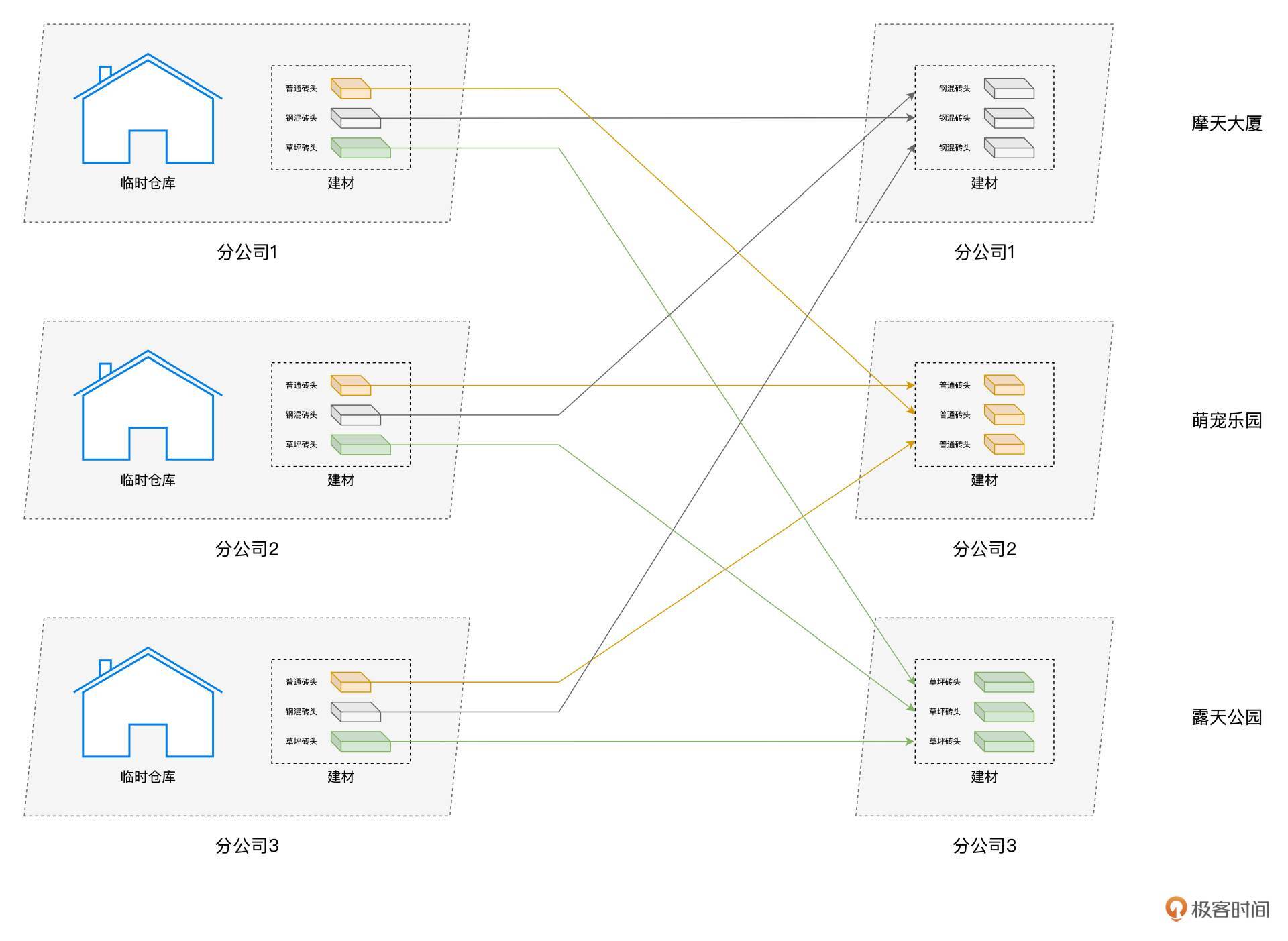
有了“工地搬砖”的直观对比,我们现在就可以直接给Shuffle下一个正式的定义了。
Shuffle的本意是扑克的“洗牌”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发。在工地搬砖的任务中,如果我们把不同类型的砖头看作是分布式数据集,那么不同类型的砖头在各个分公司之间搬运的过程,与分布式计算中的Shuffle可以说是异曲同工。
要完成工地搬砖的任务,每位工人都需要长途跋涉到另外两家分公司,然后从人家的临时仓库把所需的砖头搬运回来。分公司之间相隔甚远,仅靠工人们一块砖一块砖地搬运,显然不现实。因此,为了提升搬砖效率,每位工人还需要借助货运卡车来帮忙。不难发现,工地搬砖的任务需要消耗大量的人力物力,可以说是劳师动众。
Shuffle的过程也是类似,分布式数据集在集群内的分发,会引入大量的磁盘I/O与网络I/O。在DAG的计算链条中,Shuffle环节的执行性能是最差的。你可能会问:“既然Shuffle的性能这么差,为什么在计算的过程中非要引入Shuffle操作呢?免去Shuffle环节不行吗?”
其实,计算过程之所以需要Shuffle,往往是由计算逻辑、或者说业务逻辑决定的。
比如,对于搬砖任务来说,不同的建筑项目就是需要不同的建材,只有这样才能满足不同的施工要求。再比如,在Word Count的例子中,我们的“业务逻辑”是对单词做统计计数,那么对单词“Spark”来说,在做“加和”之前,我们就是得把原本分散在不同Executors中的“Spark”,拉取到某一个Executor,才能完成统计计数的操作。
结合过往的工作经验,我们发现在绝大多数的业务场景中,Shuffle操作都是必需的、无法避免的。既然我们躲不掉Shuffle,那么接下来,我们就一起去探索,看看Shuffle到底是怎样的一个计算过程。
Shuffle工作原理
为了方便你理解,我们还是用Word Count的例子来做说明。在这个示例中,引入Shuffle操作的是reduceByKey算子,也就是下面这行代码(完整代码请回顾第1讲)。
我们先来直观地回顾一下这一步的计算过程,然后再去分析其中涉及的Shuffle操作:
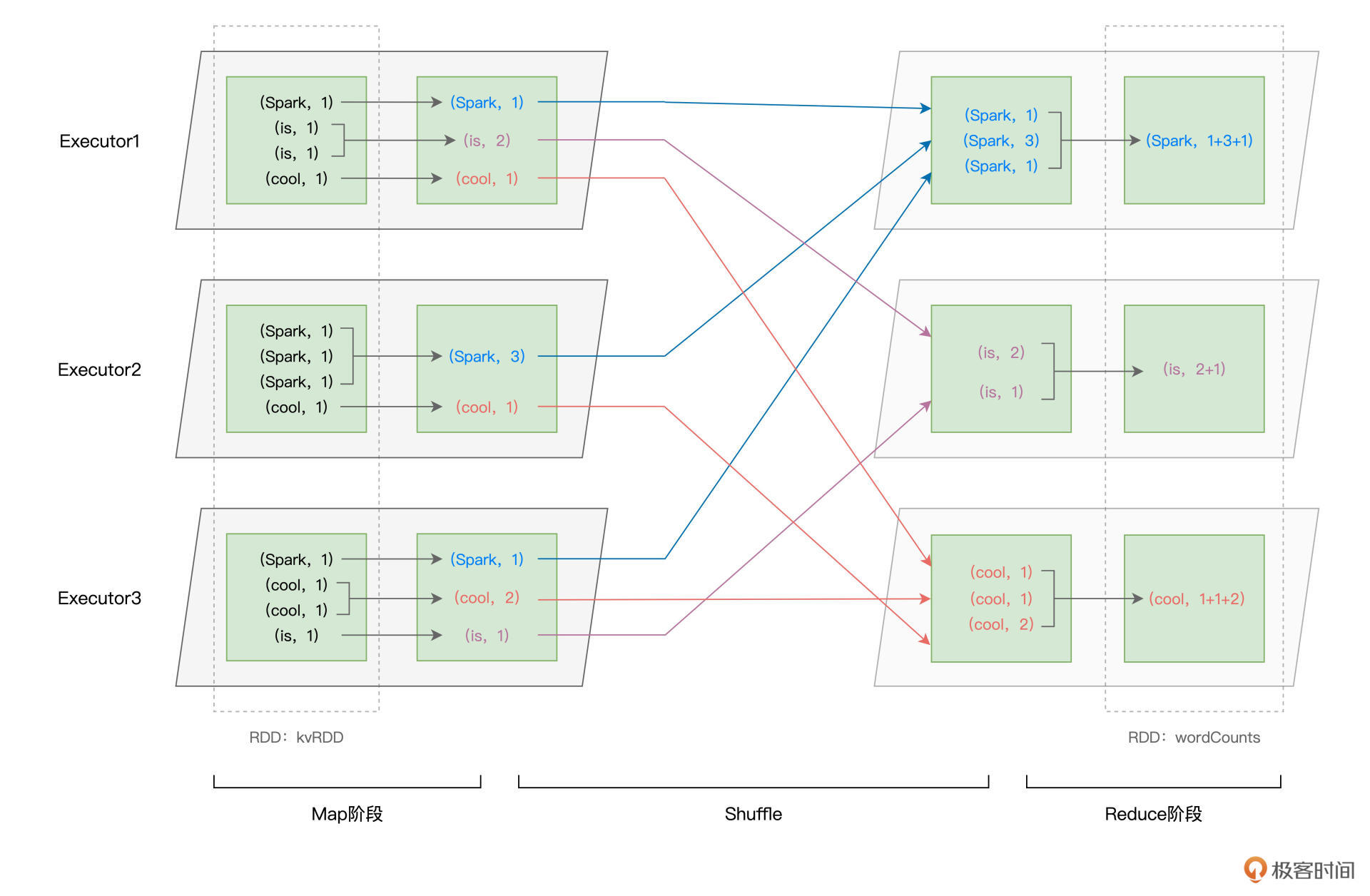
如上图所示,以Shuffle为边界,reduceByKey的计算被切割为两个执行阶段。约定俗成地,我们把Shuffle之前的Stage叫作Map阶段,而把Shuffle之后的Stage称作Reduce阶段。在Map阶段,每个Executors先把自己负责的数据分区做初步聚合(又叫Map端聚合、局部聚合);在Shuffle环节,不同的单词被分发到不同节点的Executors中;最后的Reduce阶段,Executors以单词为Key做第二次聚合(又叫全局聚合),从而完成统计计数的任务。
不难发现,Map阶段与Reduce阶段的计算过程相对清晰明了,二者都是利用reduce运算完成局部聚合与全局聚合。在reduceByKey的计算过程中,Shuffle才是关键。
仔细观察上图你就会发现,与其说Shuffle是跨节点、跨进程的数据分发,不如说Shuffle是Map阶段与Reduce阶段之间的数据交换。那么问题来了,两个执行阶段之间,是如何实现数据交换的呢?
Shuffle中间文件
如果用一句来概括的话,那就是,Map阶段与Reduce阶段,通过生产与消费Shuffle中间文件的方式,来完成集群范围内的数据交换。换句话说,Map阶段生产Shuffle中间文件,Reduce阶段消费Shuffle中间文件,二者以中间文件为媒介,完成数据交换。
那么接下来的问题是,什么是Shuffle中间文件,它是怎么产生的,又是如何被消费的?
我把它的产生和消费过程总结在下图中了:
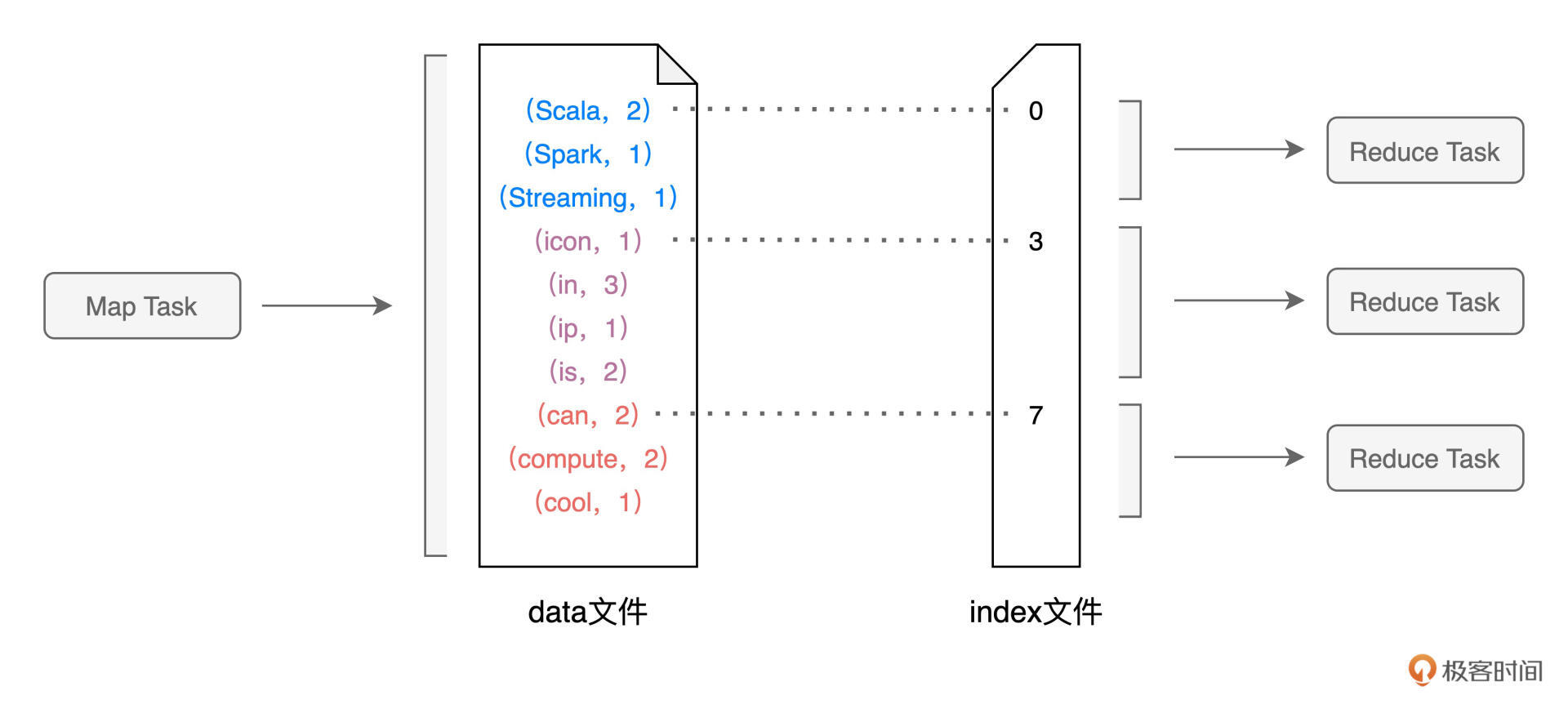
在上一讲介绍调度系统的时候,我们说过DAGScheduler会为每一个Stage创建任务集合TaskSet,而每一个TaskSet都包含多个分布式任务(Task)。在Map执行阶段,每个Task(以下简称Map Task)都会生成包含data文件与index文件的Shuffle中间文件,如上图所示。也就是说,Shuffle文件的生成,是以Map Task为粒度的,Map阶段有多少个Map Task,就会生成多少份Shuffle中间文件。
再者,Shuffle中间文件是统称、泛指,它包含两类实体文件,一个是记录(Key,Value)键值对的data文件,另一个是记录键值对所属Reduce Task的index文件。换句话说,index文件标记了data文件中的哪些记录,应该由下游Reduce阶段中的哪些Task(简称Reduce Task)消费。在上图中,为了方便示意,我们把首字母是S、i、c的单词分别交给下游的3个Reduce Task去消费,显然,这里的数据交换规则是单词首字母。
在Spark中,Shuffle环节实际的数据交换规则要比这复杂得多。数据交换规则又叫分区规则,因为它定义了分布式数据集在Reduce阶段如何划分数据分区。假设Reduce阶段有N个Task,这N个Task对应着N个数据分区,那么在Map阶段,每条记录应该分发到哪个Reduce Task,是由下面的公式来决定的。
对于任意一条数据记录,Spark先按照既定的哈希算法,计算记录主键的哈希值,然后把哈希值对N取模,计算得到的结果数字,就是这条记录在Reduce阶段的数据分区编号P。换句话说,这条记录在Shuffle的过程中,应该被分发到Reduce阶段的P号分区。
熟悉了分区规则与中间文件之后,接下来,我们再来说一说中间文件是怎么产生的。
Shuffle Write
我们刚刚说过,Shuffle中间文件,是以Map Task为粒度生成的,我们不妨使用下图中的Map Task以及与之对应的数据分区为例,来讲解中间文件的生成过程。数据分区的数据内容如图中绿色方框所示:
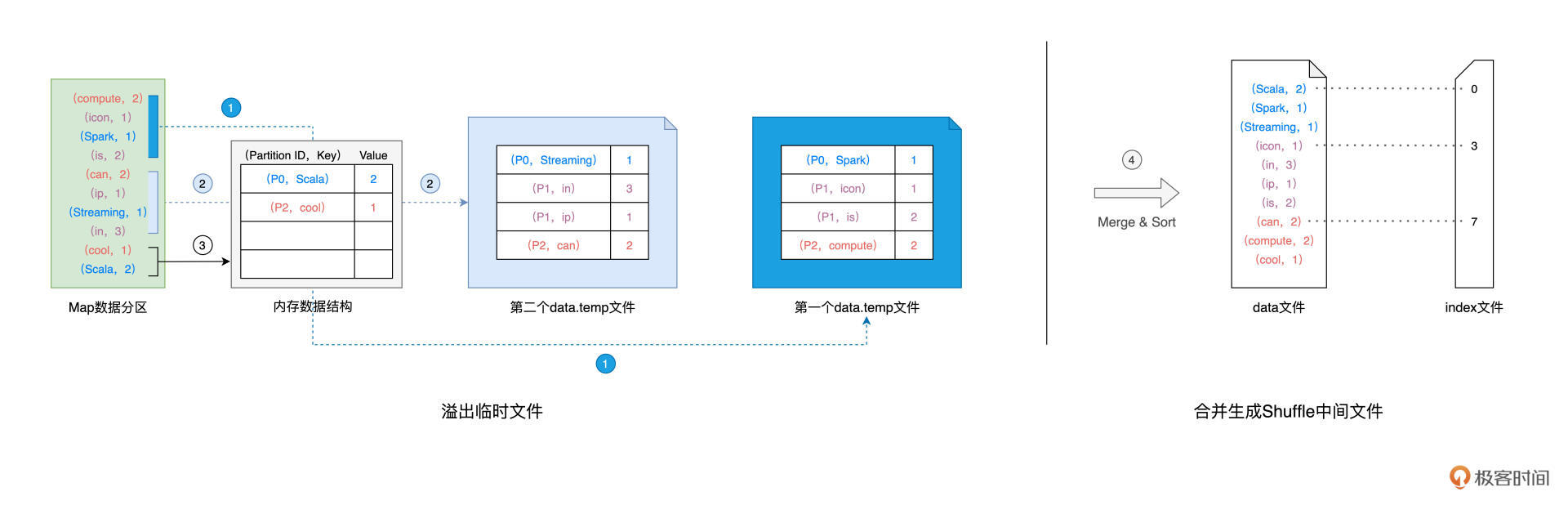
在生成中间文件的过程中,Spark会借助一种类似于Map的数据结构,来计算、缓存并排序数据分区中的数据记录。这种Map结构的Key是(Reduce Task Partition ID,Record Key),而Value是原数据记录中的数据值,如图中的“内存数据结构”所示。
对于数据分区中的数据记录,Spark会根据我们前面提到的公式1逐条计算记录所属的目标分区ID,然后把主键(Reduce Task Partition ID,Record Key)和记录的数据值插入到Map数据结构中。当Map结构被灌满之后,Spark根据主键对Map中的数据记录做排序,然后把所有内容溢出到磁盘中的临时文件,如图中的步骤1所示。
随着Map结构被清空,Spark可以继续读取分区内容并继续向Map结构中插入数据,直到Map结构再次被灌满而再次溢出,如图中的步骤2所示。就这样,如此往复,直到数据分区中所有的数据记录都被处理完毕。
到此为止,磁盘上存有若干个溢出的临时文件,而内存的Map结构中留有部分数据,Spark使用归并排序算法对所有临时文件和Map结构剩余数据做合并,分别生成data文件、和与之对应的index文件,如图中步骤4所示。Shuffle阶段生成中间文件的过程,又叫Shuffle Write。
总结下来,Shuffle中间文件的生成过程,分为如下几个步骤:
1.对于数据分区中的数据记录,逐一计算其目标分区,然后填充内存数据结构; 2.当数据结构填满后,如果分区中还有未处理的数据记录,就对结构中的数据记录按(目标分区 ID,Key)排序,将所有数据溢出到临时文件,同时清空数据结构; 3.重复前 2 个步骤,直到分区中所有的数据记录都被处理为止; 4.对所有临时文件和内存数据结构中剩余的数据记录做归并排序,生成数据文件和索引文件。
到目前为止,我们熟悉了Spark在Map阶段生产Shuffle中间文件的过程,那么,在Reduce阶段,不同的Tasks又是如何基于这些中间文件,来定位属于自己的那部分数据,从而完成数据拉取呢?
Shuffle Read
首先,我们需要注意的是,对于每一个Map Task生成的中间文件,其中的目标分区数量是由Reduce阶段的任务数量(又叫并行度)决定的。在下面的示意图中,Reduce阶段的并行度是3,因此,Map Task的中间文件会包含3个目标分区的数据,而index文件,恰恰是用来标记目标分区所属数据记录的起始索引。
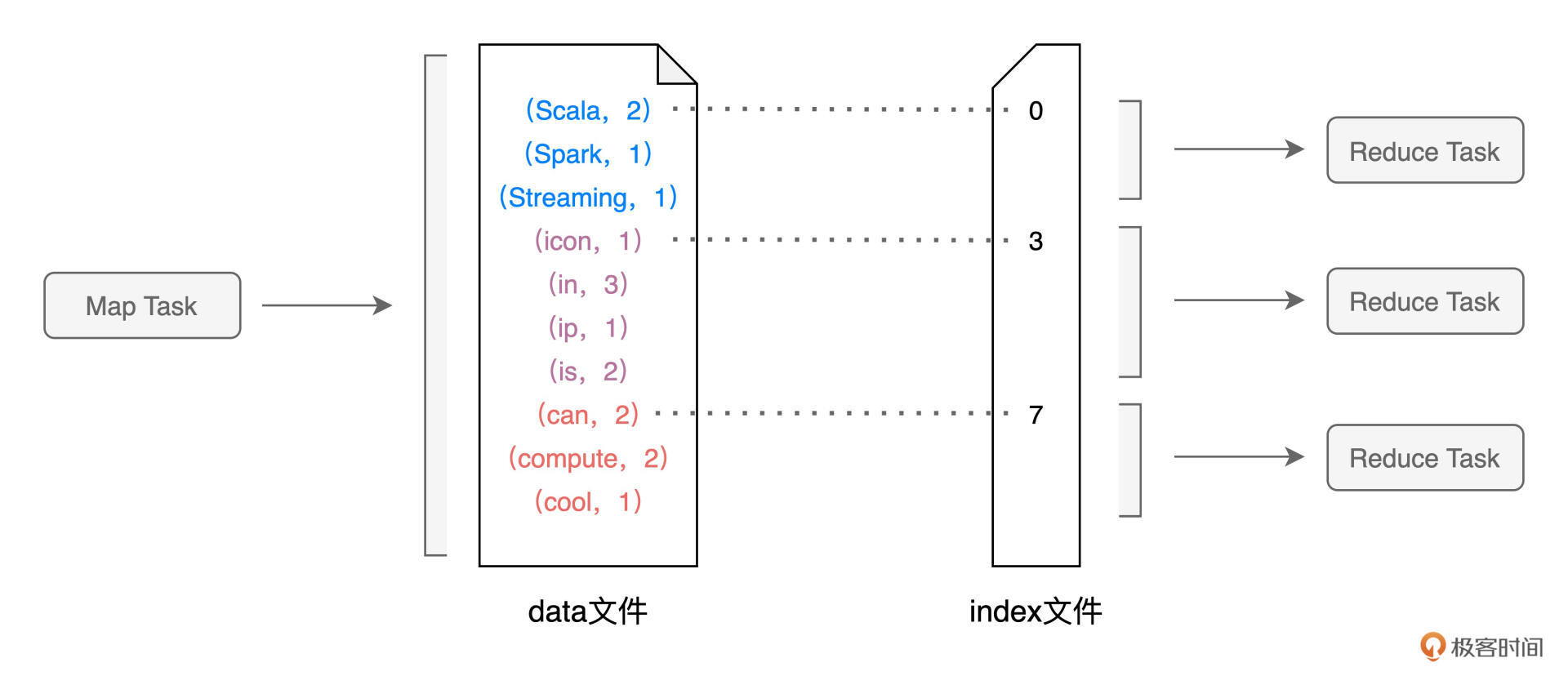
对于所有Map Task生成的中间文件,Reduce Task需要通过网络从不同节点的硬盘中下载并拉取属于自己的数据内容。不同的Reduce Task正是根据index文件中的起始索引来确定哪些数据内容是“属于自己的”。Reduce阶段不同于Reduce Task拉取数据的过程,往往也被叫做Shuffle Read。
好啦,到此为止,我们依次解答了本讲最初提到的几个问题:“什么是Shuffle?为什么需要Shuffle,以及Shuffle是如何工作的”。Shuffle是衔接不同执行阶段的关键环节,Shuffle的执行性能往往是Spark作业端到端执行效率的关键,因此,掌握Shuffle,是我们入门Spark的必经之路。希望今天的讲解,能帮你更好地认识Shuffle。
重点回顾
今天的内容比较多,我们一起来做个总结。
首先,我们给Shuffle下了一个明确的定义,在分布式计算场景中,Shuffle指的是集群范围内跨节点、跨进程的数据分发。
我们在最开始提到,Shuffle的计算会消耗所有类型的硬件资源。具体来说,Shuffle中的哈希与排序操作会大量消耗CPU,而Shuffle Write生成中间文件的过程,会消耗宝贵的内存资源与磁盘I/O,最后,Shuffle Read阶段的数据拉取会引入大量的网络I/O。不难发现,Shuffle是资源密集型计算,因此理解Shuffle对开发者来说至关重要。
紧接着,我们介绍了Shuffle中间文件。Shuffle中间文件是统称,它包含两类文件,一个是记录(Key,Value)键值对的data文件,另一个是记录键值对所属Reduce Task的index文件。计算图DAG中的Map阶段与Reduce阶段,正是通过中间文件来完成数据的交换。
接下来,我们详细讲解了Shuffle Write过程中生成中间文件的详细过程,归纳起来,这个过程分为4个步骤:
1.对于数据分区中的数据记录,逐一计算其目标分区,然后填充内存数据结构; 2.当数据结构填满后,如果分区中还有未处理的数据记录,就对结构中的数据记录按(目标分区 ID,Key)排序,将所有数据溢出到临时文件,同时清空数据结构; 3.重复前 2 个步骤,直到分区中所有的数据记录都被处理为止; 4.对所有临时文件和内存数据结构中剩余的数据记录做归并排序,生成数据文件和索引文件。
最后,在Reduce阶段,Reduce Task通过index文件来“定位”属于自己的数据内容,并通过网络从不同节点的data文件中下载属于自己的数据记录。
每课一练
这一讲就到这里了,我在这给你留个思考题:
在Shuffle的计算过程中,中间文件存储在参数spark.local.dir设置的文件目录中,这个参数的默认值是/tmp,你觉得这个参数该如何设置才更合理呢?
欢迎你在评论区分享你的答案,我在评论区等你。如果这一讲对你有所帮助,你也可以分享给自己的朋友,我们下一讲见。
- Geek_2dfa9a 👍(39) 💬(7)
官网配置文档 https://spark.apache.org/docs/3.1.2/configuration.html Directory to use for "scratch" space in Spark, including map output files and RDDs that get stored on disk. This should be on a fast, local disk in your system. It can also be a comma-separated list of multiple directories on different disks. Note: This will be overridden by SPARK_LOCAL_DIRS (Standalone), MESOS_SANDBOX (Mesos) or LOCAL_DIRS (YARN) environment variables set by the cluster manager. 临时目录,用来存map output文件(shuffle产生)和save RDD到磁盘的时候会用到。应该配置成快速的本地磁盘。支持‘,’分隔的多个目录。 注意:这个配置会被SPARK_LOCAL_DIRS(Standalone部署),MESOS_SANDBOX(Mesos),LOCAL_DIRS (YARN)替换。 既然shuffle会带来很高的开销,除了优化driver程序也可以考虑优化系统配置。 首先/tmp是会被系统清理的(取决于不同linux分发版的清理策略),如果作业运行时/tmp中的文件被清除了,那就要重新shuffle或 重新缓存RDD(这块没有仔细研究,简单猜测下缓存失效策略是重新缓存),因此,不适合将配置spark.local.dir设置为默认的/tmp 其次,部署文档有提该配置项支持多个目录,那可以考虑配置多块硬盘(或者SSD),再把挂载不同硬盘的目录配置到spark.local.dir, 这样可以显著提升shuffle和RDD缓存的性能。请大家指教。
2021-09-22 - qinsi 👍(13) 💬(2)
看到哈希那边有个问题,就是遇到不均匀的数据会怎么样?比如对这篇论文执行word count:https://isotropic.org/papers/chicken.pdf 原本可能指望所有工人一起搬砖,结果发现只有一个工人在搬砖? 另外前几讲说过大数据的精髓在于数据不动代码动,但这讲说还是无法避免shuffle搬运数据,这个要怎么理解?
2021-09-23 - Unknown element 👍(10) 💬(1)
老师您在shuffle read部分说“不同的 Reduce Task 正是根据 index 文件中的起始索引来确定哪些数据内容是属于自己的”,这一步具体是怎么实现的呢?以文中的index文件举例,文中的index文件是0,3,7,那么不同的reduce task是各自有一个编号,然后按编号大小顺序确定自己应该拉取哪一部分数据吗?比如编号为0的reduce task拉取index文件的第一个索引到第二个索引之间的数据,也就是index为0,1,2的数据;编号为1的reduce task拉取index文件的第二个索引到第三个索引之间的数据,也就是index为3,4,5,6的数据;编号为2的reduce task拉取index文件的第三个索引到最后的数据,也就是index为7,8,9的数据?这样的话如果map task计算出来没有数据应该被发到第二个reduce task那index文件是0,3,3吗?
2021-10-08 - Unknown element 👍(8) 💬(3)
老师您好 我有两个问题想问下: 1. 对于所有 Map Task 生成的中间文件,Reduce Task 需要通过网络从不同节点的硬盘中下载并拉取属于自己的数据内容 那不同的reduce task是怎么知道哪些内容是属于自己的呢?比如对于文中的例子,reduce阶段的3个任务怎么知道自己应该拉取中间文件的哪些记录? 2. 对于评论区AIK的问题,您说shuffle过程不是数据交换,而是数据流转,那意思是在map阶段 所有将要执行reduce task的节点都是空闲的吗(等待map task生成shuffle中间文件)?那他们是不是在这个stage的整个计算过程中都是空闲的?这样的话岂不是没有发挥出集群的最大算力?
2021-09-29 - 钟强 👍(3) 💬(1)
如果集群中只有一个executor, 但是executor上面有多个map task, 这样的环境是不是不需要shuffle?
2022-03-08 - Ebdaoli 👍(3) 💬(1)
磊哥,关于 spark shuffle write 阶段有个问题不太理解,①:Maptask的 任务数的并行度由什么来决定的?根据文件大小来切分划分的吗? ②:为什么最终数据需要进行 sort?合并的方式选择的是 归并排序?
2022-03-06 - A 👍(3) 💬(2)
因rdd得依赖属性shuffle划分了两个stage0和1 运行stage0的executor产生的数据称作建材,结束后driver继续提交stage1,运行stage1的executor全集群得去拉去各自所需的建材,可以这样理解嘛老师? 那stage0产生的临时data、index是记录在哪里?如何返回给driver的呢?以及stage1提交时是如何获取的呢? 目前想到的是重新封装但是又说不过去 还望老师给条路,自己再去研究一下! 感谢老师!
2022-01-15 - 猫太太 👍(3) 💬(1)
您好,讲的很清楚,看完都有点想去去自己看源码了。这句有点不太理解,可以解释一下么:“Reduce 阶段不同于 Reduce Task 拉取数据的过程,往往也被叫做 Shuffle Read。” 请问shuffle read属于reduce阶段么?reduce task拉取数据的过程不包括在reduce阶段么?reduce task拉取数据的过程不是shuffle read么?reduce阶段有什么事情发生呢?谢谢~
2021-12-05 - 阿狸弟弟的包子店 👍(2) 💬(1)
Shuffle算法感觉需要补一补,看评论有hash得,还有sort-base的,还有其他的吗?
2022-01-27 - 实数 👍(2) 💬(1)
这个讲的是hashshuffle是吗,那么第二代的sortshuffle相比较如何呢。是不是两代的shuffle都不能保证全局有序啊
2021-11-29 - 啊秋秋秋秋 👍(2) 💬(2)
老师您好!请问为什么是reducer从mapper那里拉取数据,而不是mapper把数据push到reducer端呢?我自己的理解是,如果是mapper push的话,传递数据这部分工作主要在mapper端,比如需要存储各个reducer的地址,会给mapper增加workload?但是感觉两种方式都可以,不太清楚为什么MR Spark这种分布式计算模型里都是采用reducer pull,请指点一下!谢谢!!
2021-11-11 - Neo-dqy 👍(2) 💬(3)
老师好,学完这节课我主要有三个问题: 1. Shuffle Write 过程中,对所有临时文件和内存数据结构中剩余的数据记录做归并排序,这里是按照目标分区的ID进行排序,还是按照value(词频)进行排序的啊? 2. 除了reduce类型的算子会触发shuffle操作,还有什么别的算子能触发呢? 3. 既然shuffle操作是不可避免的,那我们又要怎么优化这个操作呢?
2021-09-22 - GAC·DU 👍(1) 💬(2)
中间存储文件,我理解它是一个不用永久存储的临时文件,理论上放到任何位置都可以。但是如果在生成文件这个临界点Executor宕机,存放在/tmp目录下的文件就会丢失,如果存放在正常的目录下就会避免这种问题。还有shuffle write如果是顺序写,选SSD或者HDD硬盘也没什么区别。 有两个问题想请教老师 第一,您说Reduce Task 通过 index 文件来“定位”属于自己的数据内容和index 文件,是用来标记目标分区所属数据记录的起始索引。那么Reduce Task如何知道从起始索引读取多少个数据为止,是Reduce Task内部还有算法吗? 第二,您说Map 阶段与 Reduce 阶段,通过生产与消费 Shuffle 中间文件的方式,来完成集群范围内的数据交换,我对此处的交换不是很理解,交换不应该是相互的吗,我理解的交换是双方拿出自己的交给对方,比如我在篮子里放一个苹果,您在篮子里放一个梨,我拿到了梨而您拿到了苹果。但是Map和Reduce两者之间Reduce更像是白拿。这里的数据交换能不能理解成数据传递或者数据流转?
2021-09-22 - Tianchen 👍(0) 💬(1)
老师好,想问下公式1的哈希值P,在后续流程中是对应的Map 结构中Reduce Task Partition ID(P0,P1 ,P2)还是index(0,3,7)
2022-03-03 - 小西门 👍(0) 💬(1)
老师好,我的问题是: 如果计算记录所属那个Reduce Task的算法是一致的话,会不会出现某些exectors中只有单个(k,v),但是通过算法计算出来的reduce task partition ID是另外一个executor?这样就产生了不必要的网络IO。 我个人猜想是,会不会计算reduce task partition ID是在各map task做完之后,通知到driver,dirver获得了全局信息后,再通知到reduce task不用去shuffle read只有单个(k,v)的executor的shuffle中间文件。
2022-02-16