13 Spark SQL:让我们从“小汽车摇号分析”开始
你好,我是吴磊。
在开篇词我们提出“入门Spark需要三步走”,到目前为止,我们携手并肩跨越了前面两步,首先恭喜你学到这里!熟练掌握了Spark常用算子与核心原理以后,你已经可以轻松应对大部分数据处理需求了。
不过,数据处理毕竟是比较基础的数据应用场景,就像赛车有着不同的驾驶场景,想成为Spark的资深赛车手,我们还要走出第三步——学习Spark计算子框架。只有完成这一步,我们才能掌握Spark SQL,Structured Streaming和Spark MLlib的常规开发方法,游刃有余地应对不同的数据应用场景,如数据分析、流计算和机器学习,等等。

那这么多子框架,从哪里入手比较好呢?在所有的子框架中,Spark SQL是代码量最多、Spark社区投入最大、应用范围最广、影响力最深远的那个。就子框架的学习来说,我们自然要从Spark SQL开始。
今天我们从一个例子入手,在实战中带你熟悉数据分析开发的思路和实现步骤。有了对Spark SQL的直观体验,我们后面几讲还会深入探讨Spark SQL的用法、特性与优势,让你逐步掌握Spark SQL的全貌。
业务需求
今天我们要讲的小例子,来自于北京市小汽车摇号。我们知道,为了限制机动车保有量,从2011年开始,北京市政府推出了小汽车摇号政策。随着摇号进程的推进,在2016年,为了照顾那些长时间没有摇中号码牌的“准司机”,摇号政策又推出了“倍率”制度。
所谓倍率制度,它指的是,结合参与摇号次数,为每个人赋予不同的倍率系数。有了倍率加持,大家的中签率就由原来整齐划一的基础概率,变为“基础概率 * 倍率系数”。参与摇号的次数越多,倍率系数越大,中签率也会相应得到提高。
不过,身边无数的“准司机”总是跟我说,其实倍率这玩意没什么用,背了8倍、10倍的倍率,照样摇不上!那么今天这一讲,咱们就来借着学习Spark SQL的机会,用数据来为这些还没摸过车的“老司机”答疑解惑,帮他们定量地分析一下,倍率与中签率之间,到底有没有关系?
准备工作
巧妇难为无米之炊,既然是做数据分析,那咱们得先有数据才行。我这边为你准备了2011年到2019年北京市小汽车的摇号数据,你可以通过这个地址,从网盘进行下载,提取码为ajs6。
这份数据的文件名是“2011-2019 小汽车摇号数据.tar.gz”,解压之后的目录结构如下图所示。
可以看到,根目录下有apply和lucky两个子目录,apply目录的内容是 2011-2019 年各个批次参与摇号的申请号码,而lucky目录包含的是各个批次中签的申请号码。为了叙述方便,我们把参与过摇号的人叫“申请者”,把中签的人叫“中签者”。apply和lucky的下一级子目录是各个摇号批次,而摇号批次目录下包含的是Parquet格式的数据文件。

数据下载、解压完成之后,接下来,我们再来准备运行环境。
咱们的小例子比较轻量,Scala版本的代码实现不会超过20行,再者摇号数据体量很小,解压之后的Parquet文件总大小也不超过4G。
选择这样的例子也是为了轻装上阵,避免你因为硬件限制而难以实验。想要把用于分析倍率的应用跑起来,你在笔记本或是PC上,通过启动本地spark-shell环境就可以。不过,如果条件允许的话,我还是鼓励你搭建分布式的物理集群。关于分布式集群的搭建细节,你可以参考第4讲。
好啦,准备好数据与运行环境之后,接下来,我们就可以步入正题,去开发探索倍率与中签率关系的数据分析应用啦。
数据探索
不过,先别忙着直接上手数据分析。在此之前,我们先要对数据模式(Data Schema)有最基本的认知,也就是源数据都有哪些字段,这些字段的类型和含义分别是什么,这一步就是我们常说的数据探索。
数据探索的思路是这样的:首先,我们使用SparkSession的read API读取源数据、创建DataFrame。然后,通过调用DataFrame的show方法,我们就可以轻松获取源数据的样本数据,从而完成数据的初步探索,代码如下所示。
import org.apache.spark.sql.DataFrame
val rootPath: String = _
// 申请者数据
val hdfs_path_apply: String = s"${rootPath}/apply"
// spark是spark-shell中默认的SparkSession实例
// 通过read API读取源文件
val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply)
// 数据打印
applyNumbersDF.show
// 中签者数据
val hdfs_path_lucky: String = s"${rootPath}/lucky"
// 通过read API读取源文件
val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky)
// 数据打印
luckyDogsDF.show
看到这里,想必你已经眉头紧锁:“SparkSession?DataFrame?这些都是什么鬼?你好像压根儿也没有提到过这些概念呀!”别着急,对于这些关键概念,我们在后续的课程中都会陆续展开,今天这一讲,咱们先来“知其然”,“知其所以然”的部分咱们放到后面去讲。
对于SparkSession,你可以把它理解为是SparkContext的进阶版,是Spark(2.0版本以后)新一代的开发入口。SparkContext通过textFile API把源数据转换为RDD,而SparkSession通过read API把源数据转换为DataFrame。
而DataFrame,你可以把它看作是一种特殊的RDD。RDD我们已经很熟悉了,现在就把DataFrame跟RDD做个对比,让你先对DataFrame有个感性认识。
先从功能分析,与RDD一样,DataFrame也用来封装分布式数据集,它也有数据分区的概念,也是通过算子来实现不同DataFrame之间的转换,只不过DataFrame采用了一套与RDD算子不同的独立算子集。
再者,在数据内容方面,与RDD不同,DataFrame是一种带Schema的分布式数据集,因此,你可以简单地把DataFrame看作是数据库中的一张二维表。
最后,DataFrame背后的计算引擎是Spark SQL,而RDD的计算引擎是Spark Core,这一点至关重要。不过,关于计算引擎之间的差异,我们留到下一讲再去展开。
好啦,言归正传。简单了解了SparkSession与DataFrame的概念之后,我们继续来看数据探索。
把上述代码丢进spark-shell之后,分别在applyNumbersDF和luckyDogsDF这两个DataFrame之上调用show函数,我们就可以得到样本数据。可以看到,“这两张表”的Schema是一样的,它们都包含两个字段,一个是String类型的carNum,另一个是类型为Int的batchNum。

其中,carNum的含义是申请号码、或是中签号码,而batchNum则代表摇号批次,比如201906表示2019年的最后一批摇号,201401表示2014年的第一次摇号。
好啦,进行到这里,初步的数据探索工作就告一段落了。
业务需求实现
完成初步的数据探索之后,我们就可以结合数据特点(比如两张表的Schema完全一致,但数据内容的范畴不同),来实现最开始的业务需求:计算中签率与倍率之间的量化关系。
首先,既然是要量化中签率与倍率之间的关系,我们只需要关注那些中签者(lucky目录下的数据)的倍率变化就好了。而倍率的计算,要依赖apply目录下的摇号数据。因此,要做到仅关注中签者的倍率,我们就必须要使用数据关联这个在数据分析领域中最常见的操作。此外,由于倍率制度自2016年才开始推出,所以我们只需要访问2016年以后的数据即可。
基于以上这些分析,我们先把数据过滤与数据关联的代码写出来,如下所示。
// 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段
val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum")
// 摇号数据与中签数据做内关联,Join Key为中签号码carNum
val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq("carNum"), "inner")
在上面的代码中,我们使用filter算子对luckyDogsDF做过滤,然后使用select算子提取carNum字段。
紧接着,我们在applyNumbersDF之上调用join算子,从而完成两个DataFrame的数据关联。join算子有3个参数,你可以对照前面代码的第5行来理解,这里第一个参数用于指定需要关联的DataFrame,第二个参数代表Join Key,也就是依据哪些字段做关联,而第三个参数指定的是关联形式,比如inner表示内关联,left表示左关联,等等。
做完数据关联之后,接下来,我们再来说一说,倍率应该怎么统计。对于倍率这个数值,官方的实现略显粗暴,如果去观察 apply 目录下 2016 年以后各个批次的文件,你就会发现,所谓的倍率,实际上就是申请号码的副本数量。
比如说,我的倍率是8,那么在各个批次的摇号文件中,我的申请号码就会出现8次。是不是很粗暴?因此,要统计某个申请号码的倍率,我们只需要统计它在批次文件中出现的次数就可以达到目的。
按照批次、申请号码做统计计数,是不是有种熟悉的感觉?没错,这不就是我们之前学过的Word Count吗?它本质上其实就是一个分组计数的过程。不过,这一次,咱们不再使用reduceByKey这个RDD算子了,而是使用DataFrame的那套算子来实现,我们先来看代码。
val multipliers: DataFrame = jointDF.groupBy(col("batchNum"),col("carNum"))
.agg(count(lit(1)).alias("multiplier"))
分组计数
对照代码我给你分析下思路,我们先是用groupBy算子来按照摇号批次和申请号码做分组,然后通过agg和count算子把(batchNum,carNum)出现的次数,作为carNum在摇号批次batchNum中的倍率,并使用alias算子把倍率重命名为“multiplier”。
这么说可能有点绕,我们可以通过在multipliers之上调用show函数,来直观地观察这一步的计算结果。为了方便说明,我用表格的形式来进行示意。

可以看到,同一个申请号码,在不同批次中的倍率是不一样的。就像我们之前说的,随着摇号的次数增加,倍率也会跟着提升。不过,这里咱们要研究的是倍率与中签率的关系,所以只需要关心中签者是在多大的倍率下中签的就行。因此,对于同一个申请号码,我们只需要保留其中最大的倍率就可以了。
需要说明的是,取最大倍率的做法,会把倍率的统计基数变小,从而引入幸存者偏差。更严谨的做法,应该把中签者过往的倍率也都统计在内,这样倍率的基数才是准确的。不过呢,结合实验,幸存者偏差并不影响“倍率与中签率是否有直接关系”这一结论。因此,咱们不妨采用取最大倍率这种更加简便的做法。毕竟,学习Spark SQL,才是咱们的首要目标。
为此,我们需要“抹去”batchNum这个维度,按照carNum对multipliers做分组,并提取倍率的最大值,代码如下所示。
val uniqueMultipliers: DataFrame = multipliers.groupBy("carNum")
.agg(max("multiplier").alias("multiplier"))
分组聚合的方法跟前面差不多,我们还是先用groupBy做分组,不过这次仅用carNum一个字段做分组,然后使用agg和max算子来保留倍率最大值。经过这一步的计算之后,我们就得到了每个申请号码在中签之前的倍率系数:
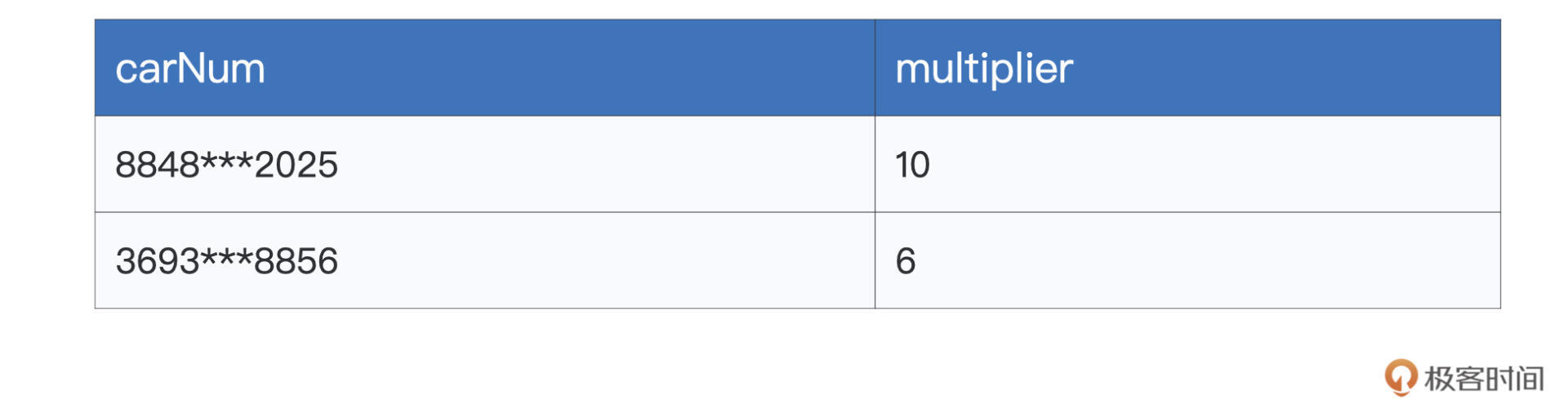
可以看到,uniqueMultipliers这个DataFrame仅包含申请号码carNum和倍率multiplier这两个字段,且carNum字段不存在重复值,也就是说,在这份数据集中,一个申请号码,只有一个最大倍率与之对应。
好啦,到此为止,我们拿到了每一个中签者,在中签之前的倍率系数。接下来,结合这份数据,我们就可以统计倍率本身的分布情况。
具体来说,我们想知道的是,不同倍率之下的人数分布是什么样子的。换句话说,这一次,我们要按照倍率来对数据做分组,然后计算不同倍率下的统计计数。不用说,这次咱们还是得仰仗groupBy和agg这两个算子,代码如下所示。
val result: DataFrame = uniqueMultipliers.groupBy("multiplier")
.agg(count(lit(1)).alias("cnt"))
.orderBy("multiplier")
result.collect
在最后一步,我们依然使用groupBy和agg算子如法炮制,得到按照倍率统计的人数分布之后,我们通过collect算子来收集计算结果,并同时触发上述的所有代码从头至尾交付执行。
计算结果result包含两个字段,一个是倍率,一个是持有该倍率的统计人数。如果把result结果数据做成柱状图的话,我们可以更加直观地观察到中签率与倍率之间的关系,如下图所示。

不难发现,不同倍率下的中签者人数,呈现出正态分布。也即是说,对于一个申请者来说,他/她有幸摇中的概率,并不会随着倍率的增加而线性增长。用身边那些“老司机”的话说,中签这件事,确实跟倍率的关系不大。
重点回顾
今天这一讲,我们一起动手,开发了“倍率的统计分布”这个数据分析应用,并解答了中签率与倍率之间是否存在关联关系这一难题。
尽管在实现的过程中,我们遇到了一些新概念和新的算子,但你不必担心,更不必着急。今天这节课,你只需要对Spark SQL框架下的应用开发有一个感性的认识就可以了。
在Spark SQL的开发框架下,我们通常是通过SparkSession的read API从源数据创建DataFrame。然后,以DataFrame为入口,在DataFrame之上调用各式各样的转换算子,如agg、groupBy、select、filter等等,对DataFrame进行转换,进而完成相应的数据分析。
为了后续试验方便,我把今天涉及的代码片段整理到了一起,你可以把它们丢进spark-shell去运行,观察每个环节的计算结果,体会不同算子的计算逻辑与执行结果之间的关系。加油,祝你好运!
import org.apache.spark.sql.DataFrame
val rootPath: String = _
// 申请者数据
val hdfs_path_apply: String = s"${rootPath}/apply"
// spark是spark-shell中默认的SparkSession实例
// 通过read API读取源文件
val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply)
// 中签者数据
val hdfs_path_lucky: String = s"${rootPath}/lucky"
// 通过read API读取源文件
val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky)
// 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段
val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum")
// 摇号数据与中签数据做内关联,Join Key为中签号码carNum
val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq("carNum"), "inner")
// 以batchNum、carNum做分组,统计倍率系数
val multipliers: DataFrame = jointDF.groupBy(col("batchNum"),col("carNum"))
.agg(count(lit(1)).alias("multiplier"))
// 以carNum做分组,保留最大的倍率系数
val uniqueMultipliers: DataFrame = multipliers.groupBy("carNum")
.agg(max("multiplier").alias("multiplier"))
// 以multiplier倍率做分组,统计人数
val result: DataFrame = uniqueMultipliers.groupBy("multiplier")
.agg(count(lit(1)).alias("cnt"))
.orderBy("multiplier")
result.collect
每课一练
1.脑洞时间:你觉得汽车摇号的倍率制度应该怎样设计,才是最合理的?
2.请在你的Spark环境中把代码运行起来,并确认执行结果是否与result一致。
欢迎你在留言区跟我交流互动,也推荐你把这一讲的内容分享给更多的朋友、同事。我们下一讲见!
- qinsi 👍(16) 💬(3)
spark无关。讨论下摇号。 评论区有匿名读者质疑文中的结论。这里尝试换个角度代入具体的数字分析下。 简单起见,假设每轮摇号有1000人中签,并且倍率和轮次一致,即第一轮大家都是1倍,第一轮没中的人在第二轮变为2倍,第二轮又没中的人到了第三轮就变成3倍,依次类推。 先看第一轮的1000个中签者,显然他们的倍率都是1,没有其他倍率的中签者,记为: [1000, 0, 0, ...] 再看第二轮的1000个中签者。由于新加入的申请者倍率为1,第一轮未中的人倍率为2。按照倍率摇号的话,期望的结果就是,倍率为2的中签人数是倍率为1的中签人数的2倍,记为: [333, 667, 0, 0, ...] 以此类推,第三轮就是: [167, 333, 500, 0, 0, ...] 尝试摇个10轮,可以得到下表: [1000, 0, 0, ...] [333, 667, 0, 0, ...] [167, 333, 500, 0, 0, ...] [100, 200, 300, 400, 0, 0, ...] [67, 133, 200, 267, 333, 0, 0, ...] [48, 95, 143, 190, 238, 286, 0, 0, ...] [36, 71, 107, 143, 179, 214, 250, 0, 0, ...] [28, 56, 83, 111, 139, 167, 194, 222, 0, 0, ...] [22, 44, 67, 89, 111, 133, 156, 178, 200, 0, 0, ...] [18, 36, 55, 73, 91, 109, 127, 145, 164, 182, 0, 0, ...] 可以看到在每一轮的中签者中,确实是倍率越高中签的人数越多。 而文中的统计方法,相当于把这张表按列求和: [1819, 1635, 1455, 1273, 1091, 909, 727, 545, 364, 182, 0, 0, ...] 可以看到这是一条单调递减的曲线。然而却不能像文中一样得出“中签率没有随着倍率增加”的结论。高倍率的中签人数比低倍率的人数少,是因为能达到高倍率的人本身就少。比如上面例子中,10轮过后10倍率的中签者只有182人,是因为前9轮没有人能达到10倍率。相比之下,在第一轮就有1000个1倍率的人中签。 至于文中配图为什么会是一条类似钟型的曲线,猜测可能第一次引入倍率摇号的时候,就已经给不同的人分配不同的倍率了,而不是大家一开始都是1倍率。在上面的例子中,如果只对后5轮求和,可以得到: [152, 302, 455, 606, 758, 909, 727, 545, 364, 182] 这样就和文中的配图比较接近了。 所以结论就是要验证中签率和倍率的关系,不能按照倍率去累加中签人数,而是要看单次摇号中不同倍率的中签者的分布。
2021-10-12 - Alvin-L 👍(6) 💬(2)
``` import os from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession from pyspark.sql.functions import first, collect_list, mean, count, max import matplotlib.pyplot as plt def plot(res): x = [x["multiplier"] for x in res] y = [y["cnt"] for y in res] plt.figure(figsize=(8, 5), dpi=100) plt.xlabel('倍率') plt.ylabel('人数') plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(x, y, width=0.5) plt.xticks(x) plt.show() # py文件就在项目的根目录下 rootPath = os.path.split(os.path.realpath(__file__))[0] conf = SparkConf() conf.set('spark.executor.memory', '4g') conf.set('spark.driver.memory', '8g') conf.set("spark.executor.cores", '4') conf.set('spark.cores.max', 16) conf.set('spark.local.dir', rootPath) spark = SparkSession(SparkContext(conf=conf)) # 申请者数据 # Windows环境 # 注意点1:增加 option("basePath", rootPath) 选项 # 注意点2:路径 hdfs_path_apply 需要追加 /*/*.parquet hdfs_path_apply = rootPath + "/apply" applyNumbersDF = spark.read.option("basePath", rootPath).parquet( hdfs_path_apply + "/*/*.parquet" ) # 中签者数据 hdfs_path_lucky = rootPath + "/lucky" luckyDogsDF = spark.read.option("basePath", rootPath).parquet( hdfs_path_lucky + "/*/*.parquet" ) # 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段 filteredLuckyDogs = ( luckyDogsDF .filter(luckyDogsDF["batchNum"] >= "201601") .select("carNum") ) # 摇号数据与中签数据做内关联,Join Key为中签号码carNum jointDF = applyNumbersDF.join(filteredLuckyDogs, "carNum", "inner") # 以batchNum、carNum做分组,统计倍率系数 multipliers = ( jointDF .groupBy(["batchNum", "carNum"]) .agg(count("batchNum").alias("multiplier")) ) # 以carNum做分组,保留最大的倍率系数 uniqueMultipliers = ( multipliers .groupBy("carNum") .agg(max("multiplier").alias("multiplier")) ) # 以multiplier倍率做分组,统计人数 result = ( uniqueMultipliers .groupBy("multiplier") .agg(count("carNum").alias("cnt")) .orderBy("multiplier") ) result.show(40) res = result.collect() # 画图 plot(res) ```
2021-10-26 - 东围居士 👍(2) 💬(2)
补一个完整的 spark 代码(windows环境): package spark.basic import org.apache.spark.sql.functions.{col,count, lit, max} import org.apache.spark.sql.{DataFrame, SparkSession} object Chapter13 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[*]").appName("Chapter13").getOrCreate() import spark.implicits._ val rootPath: String = "E:\\temp\\yaohao_home\\yaohao" // 申请者数据 val hdfs_path_apply: String = s"${rootPath}/apply" // spark是spark-shell中默认的SparkSession实例 // 通过read API读取源文件 val applyNumbersDF: DataFrame = spark.read.option("basePath", rootPath).parquet(hdfs_path_apply + "/*/*.parquet") // 中签者数据 val hdfs_path_lucky: String = s"${rootPath}/lucky" // 通过read API读取源文件 val luckyDogsDF: DataFrame = spark.read.option("basePath", rootPath).parquet(hdfs_path_lucky + "/*/*.parquet") // 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段 val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum") // 摇号数据与中签数据做内关联,Join Key为中签号码carNum val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq("carNum"), "inner") // 以batchNum、carNum做分组,统计倍率系数 val multipliers: DataFrame = jointDF.groupBy(col("batchNum"),col("carNum")) .agg(count(lit(1)).alias("multiplier")) // 以carNum做分组,保留最大的倍率系数 val uniqueMultipliers: DataFrame = multipliers.groupBy("carNum") .agg(max("multiplier").alias("multiplier")) // 以multiplier倍率做分组,统计人数 val result: DataFrame = uniqueMultipliers.groupBy("multiplier") .agg(count(lit(1)).alias("cnt")) .orderBy("multiplier") result.collect result.show() } }
2021-11-12 - 火炎焱燚 👍(2) 💬(2)
对应的python代码为: # 在notebook上运行时,加上下面的配置 from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession sc_conf = SparkConf() # spark参数配置 # sc_conf.setMaster() # sc_conf.setAppName('my-app') sc_conf.set('spark.executor.memory', '2g') sc_conf.set('spark.driver.memory', '4g') sc_conf.set("spark.executor.cores", '2') sc_conf.set('spark.cores.max', 20) sc = SparkContext(conf=sc_conf) # 加载数据,转换成dataframe rootPath='~~/RawData' hdfs_path_apply=rootPath+'/apply' spark = SparkSession(sc) applyNumbersDF=spark.read.parquet(hdfs_path_apply) # applyNumbersDF.show() # 打印出前几行数据,查看数据结构 hdfs_path_lucky=rootPath+'/lucky' luckyDogsDF=spark.read.parquet(hdfs_path_lucky) # luckyDogsDF.show() filteredLuckyDogs=luckyDogsDF.filter(luckyDogsDF['batchNum']>='201601').select('carNum') jointDF=applyNumbersDF.join(filteredLuckyDogs,'carNum','inner') # join函数消耗内存较大,容易出现OOM错误,如果出错,要将spark.driver.memory调大 # jointDF.show() # 打印出join之后的df部分数据 # 进行多种groupBy操作 from pyspark.sql import functions as f multipliers=jointDF.groupBy(['batchNum','carNum']).agg(f.count('batchNum').alias("multiplier")) # multipliers.show() uniqueMultipliers=multipliers.groupBy('carNum').agg(f.max('multiplier').alias('multiplier')) # uniqueMultipliers.show() result=uniqueMultipliers.groupBy('multiplier').agg(f.count('carNum').alias('cnt')).orderBy('multiplier') result2=result.collect() # 绘图 import matplotlib.pyplot as plt x=[i['multiplier'] for i in result2] y=[i['cnt'] for i in result2] plt.bar(x,y)
2021-10-23 - Geek_d447af 👍(1) 💬(2)
文章里的代码需要在 Hadoop 环境才能跑起来,spark 本身不支持解析 parquet 文件
2021-10-09 - lightning_女巫 👍(0) 💬(1)
我在本地跑这个代码碰到了如下错误,请问如何解决? 22/01/28 15:13:22 ERROR BypassMergeSortShuffleWriter: Error while deleting file /private/var/folders/hk/7j9sqdtn55j3cq_gv5qvp5pm39d49n/T/blockmgr-88ef94e9-943a-4971-a3a8-33d25949886f/1a/temp_shuffle_e0e163fb-852c-4298-b08e-dc4989277ab3 22/01/28 15:13:22 ERROR DiskBlockObjectWriter: Uncaught exception while reverting partial writes to file /private/var/folders/hk/7j9sqdtn55j3cq_gv5qvp5pm39d49n/T/blockmgr-88ef94e9-943a-4971-a3a8-33d25949886f/08/temp_shuffle_6c160c23-3395-445f-be03-b29a375e1139 java.io.FileNotFoundException: /private/var/folders/hk/7j9sqdtn55j3cq_gv5qvp5pm39d49n/T/blockmgr-88ef94e9-943a-4971-a3a8-33d25949886f/08/temp_shuffle_6c160c23-3395-445f-be03-b29a375e1139 (No such file or directory) at java.io.FileOutputStream.open0(Native Method) at java.io.FileOutputStream.open(FileOutputStream.java:270) at java.io.FileOutputStream.<init>(FileOutputStream.java:213) at org.apache.spark.storage.DiskBlockObjectWriter$$anonfun$revertPartialWritesAndClose$2.apply$mcV$sp(DiskBlockObjectWriter.scala:217) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1369) at org.apache.spark.storage.DiskBlockObjectWriter.revertPartialWritesAndClose(DiskBlockObjectWriter.scala:214) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.stop(BypassMergeSortShuffleWriter.java:237) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:105) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
2022-01-28 - 东围居士 👍(0) 💬(3)
老师,数据文件方便存一份到别的地方吗,比如马云家的网盘,或者做个种子下载什么的,百度网盘那速度真的是,我下到下午下班过周末都下不完
2021-10-22 - Geek_995b78 👍(0) 💬(2)
用scala实现,lit(1)是什么意思呀
2021-10-11 - GAC·DU 👍(0) 💬(1)
result具体数值: scala> result.collect res7: Array[org.apache.spark.sql.Row] = Array([1,8967], [2,19174], [3,26952], [4,29755], [5,32988], [6,34119], [7,29707], [8,26123], [9,19476], [10,9616], [11,3930], [12,1212])
2021-10-08 - Neo-dqy 👍(0) 💬(1)
【.agg(count(lit(1)).alias("cnt"))】问下老师,这里count中的lit(1)是什么意思啊? 对于汽车摇号的倍率制度,如果为了优先让倍率高的人摇到号,可以把每一期的资格分多次抽取。就是说,先构建一个所有人都在里面的样本,抽部分人;再将倍率高于某个阈值的人都取出来,构建一个新的样本,再抽取部分人。(具体划分成几个样本可以按倍率的人数分布来划分)当然这样又会对新来的人不公平,所以大家还是挤地铁吧~~
2021-10-08 - Spoon 👍(2) 💬(0)
Java实现 https://github.com/Spoon94/spark-practice/blob/master/src/main/java/com/spoon/spark/sql/CarNumAnalyseJob.java
2022-04-05 - 未来已来 👍(1) 💬(0)
大概看了下评论,发现一次摇号一个号码会出现多次,是为了增加n次参与的人被摇到的概率。相当于在一个封闭的箱子里摇球,一个号码的球多放了几个,摇箱子后个数多的号码被抽到的概率更高(n/N,N为箱子内球的总数)
2023-02-10 - 翡翠小南瓜 👍(1) 💬(2)
不懂北京的摇号规则,也没写清楚,所以是一个批次号里面,一个申请号可以有多次????
2022-04-12 - Each 👍(0) 💬(0)
老師您好, 無法下載 dataset, 可以提供海外載點嗎? 謝謝.
2024-10-15 - 风一样 👍(0) 💬(1)
上面的结论感觉不太正确,偏离了每个每个倍率下的基数,倍率越高中签概率肯定越大啊,对个人而言,如果我们每次参与抽签的人数大基数不变的情况下(基数1000),倍率越大,相当于往里面添加了多个样本(8倍率),本来是1/1000的概率变为了8/1000。但是考虑到每次倍率越大没中签的用户重复的次数越多,基数也会跟着变大,相对于新加入的人来说其实是有优势的,但是新增的人其实远小于已经参与过抽签的人,所以才导致了感觉上变化不大
2022-12-01