13 材料整理:从混乱到秩序,以说代做
你好,我是键盘,我们继续驯服 GPT。
想要使用GPT来提效,除了基础的翻译和行动指引,离我们最近的其实还是材料整理。这个课题会有点大,毕竟文字材料以外也还有图、文、音等多模态数据。所以我们从中抽取一个“文件整理”,解决它,之后再延伸应用也就轻而易举了。
整理什么文件呢?为了不让你错过绘图AI,接下来我们就整理一套AI绘图概念词典,让你想要的时候随手就有一份参考。这份参考适用于Midjourney、Stable Diffusion等等文生图模型。
我们梳理一下材料整理的准备工作和效果预期。
- 情况一:你已经在文本工具中储备了少量零散概念,属于整理你已有的东西,效果最佳。
- 情况二:你有一份网上捞过来的参考词典,可行。唯一的问题是,这是别人整理的,没有投入你个人知识的涟漪,不好用。
- 情况三:整理几乎不了解的材料,还是能实现。我们先给GPT投一个小石头,激起第一道涟漪,空手套白狼。
我会重点分享第一种情况,同时提供第三种情况兼容新手的方案。通过案例的实践,你将掌握4个可复用的技巧。
- 在GPT对话框中对数据进行聚类、排序。
- 一行指令对长输入/输出进行拆分。
- 智能的数据校对,防止错漏和重复。
- 智能填充和扩展。
这节课的实操首选稳定的GPT-4模型,因为ChatGPT稳定性较差,校对环节会比较影响效率。
梳理框架:更多思考,更少执行
我们要明确的是,这个整理不是要强行以AI的方式来执行,为了用而用,而是通过思考日常整理材料的难点,想一想怎么样整理才会更方便,理清整理材料和使用GPT在实际工作中的结合点。
为了让后续挑战更加轻松,我们先来做好前置准备。
✦ 规避无意识的概念盲区
设计prompt最怕一上来就写 整理一份Midjourney的prompt词典 这类主题。即使你使用的是更高级的GPT-4,它们2011年的出生点就意味着一些概念是不存在的,比如这里的Midjourney。
那怎么有意识地兼容孤岛模型和联网插件呢?答案是加上明确的、附带目的的描述“什么样的Midjourney”。
💬 prompt 实例
也就是将盲区词汇“Midjourey”作为明确目的,“AI绘图”作为附加词,这样向上兼容联网模型的时候,GPT就会知道这是一个AI绘图工具Midjourney,不是路人甲、乙、丙Midjourey。
✦ 应对局限:分类输入/输出
比起用Python来写一个自动化处理方案,打开ChatGPT就能分类整理的方式更适合小白。但因为字数限制,可以预见的结果就是频繁中断、大量错漏,或者干脆不支持超过1000字的材料。不用怕,用讲过的分段策略来解决就好。
✦ 提取要素:明确整理的维度细节
假如你要整理的材料来自完全不了解的新领域,又该怎么下手?没关系,先来建立知识的联结。比如AI绘图领域,本质上就是用语言描述出一个画面,你可以理解为“讲故事”。那么AI绘图领域的5要素,就可以投射到我们讲过的“提问5要素”中去理解。它的5要素就可以是:
谁(和谁)+在哪里+做什么+什么时间+怎么做
不过,现在的绘图5要素还不足以形成清晰、明确的描述。比如说“一只狗”,一只什么样的狗?“什么样”这个概念才是让画面变具体的关键。好,继续往下拆解。一个具体的画面可以用不同的属性来描述,比如画面“蜿蜒的小河边,在大树上有一个木头树屋,斑驳的阳光,居中构图,远景,低视角,宁静的手绘”,它可以拆解为7个维度:
色彩+光线+材质+构图+景别+视角+风格
到这一步,就是专业和非专业户的分水岭了,完全不懂的话,你也可以先让GPT给出明确的拆解参考。这些具体的分类清晰之后,就可以设计prompt了。
切入:捋需求,抓重点
任何prompt的设计都要根据实际情况来思考,所以我们先从手头已有的待整理数据来分析。
我从开始用Midjourney时记录的碎片信息里面摘出了一段“光线”分类。
……
morning light 🌟晨光
dappled sunlight 🌟斑驳的阳光(验证:komorebi 木漏れ日,MJ无法识别,使用 sunlight filtering through leaves 或 dappled sunlight)
golden hour 🌟🌟黄金时段(日落前和日出后的一小时,全天最柔和的暖光)
twilight 暮色 surrounded in golden twilight 被金色的暮色笼罩
……
光/方向
rembrandt light 伦勃朗式用光
top light 顶光
……
这个类目近百行,有些概念包含实践过后打上的评级,有些包含相应的描述,大部分因为我自己了解,就只提供了简单的中、英文名称。假如靠人力去调整位置和细节,至少要费半天的时间,所以提效还得是AI。
最基础的整理,一般能够梳理出7个常规的需求点。
- 使用表格来结构化整理:纯文字可用性和可读性都很差,也不方便用于协作。
- 区分不同的输出模版:比如说色彩类目可以单独多加一个色卡,展现概念“本色”。
- 统一整理的维度:通常就是定义用哪些类型的数据列,还有确认某些列的对齐方式。比如数额类数据因为要便于分辨位数,所以右对齐基本就是标配。
- 数据聚类:细分二级分类,相似的就自动归类。
- 按一定的规律排序:保持所谓的秩序,方便关联记忆,毕竟最后这份材料要落到实际应用。
- 按需填充必要的描述:做到心中有概念,而不是光有一个词。
- 整理格式:为了方便阅读,除了专有名词,如
Pixar、C4D,其他名词统一小写。
再针对这个场景补充2个必要的需求。
- 拆分
个别输入/输出会很长,这是一个你可以预判到的、会严重影响效率的地方。那是不是可以设计 datas 和 output 分支指令,按分段输入,按二级分类输出?这样既保障了数据结构,又能规避大量的中断。

- 校对
只要是涉及数据和信息的整理,校对这个环节必不可少。比如说统计财务数据,一条错漏足以作废整份结果。这里我提供4个维度,数目统计、智能纠错(含大小写规则)、查漏补缺、自动去重,都可以写在prompt里,帮你保障输出质量。

秘诀:兼收并蓄
针对这种需求点繁多的情况,很可能出现不断地复制模板、改模板的问题。比如整理完色彩又要设计一条专用于整理光线的prompt,然后还要设计材质、构图、景别等等其他分类。所以,我们使用打包指令集,借助之前提到的“变量”来灵活应变。prompt稍后再写,这里先提示你2个关键方法。
方法1,从一个分类开始,覆盖其他需求场景。什么意思呢?刚入门时我采用的是分开设计并处理的方法,7大类就要设计对应的7条prompt,很麻烦。但是每个需求场景一定会有共性需求,我们来找到它们。
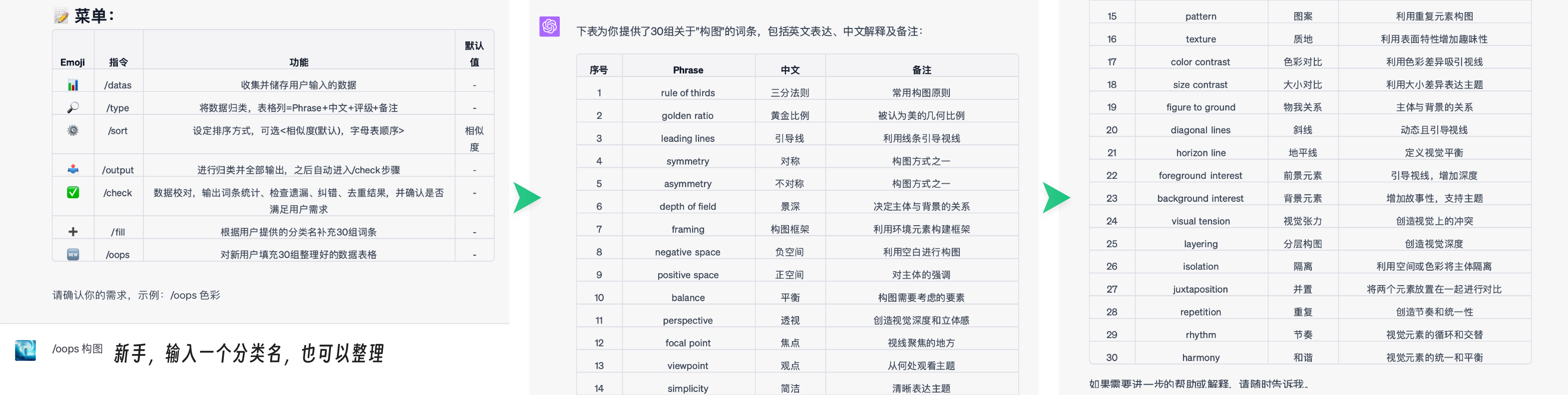
比如基础的聚类整理和校对、更细致的差异化输出,这种共性需求就可以抽象出来。你还可以利用好AI的推理优势,针对已经初步整理的材料设计智能填充模式 /fill ,接着已经整理好的内容继续填充。如果你对整理的领域完全不了解,还可以设计一个新手模式 /oops ,空手套白狼,让GPT自己生成、自己整理。
#入门时期设计的"构图"整理
用表格将以下数据按进行归类呈现,使阅读顺序上富有逻辑。
要求:
1、排序依据可以是:近似就近排列
2、使用「prompt」、「中文」、「评级」、「备注」4列,「评级」只有🌟和🌟🌟,原数据未标示的留空。原括号内的信息为备注,未标示的留空。
3、检查数据条目,核对是否有遗漏,给出答复和数量条目数。
4、仅当遗漏的情况补全数据,不需要重复其余表格。
---
#我的数据
凌乱的数据
方法2,拆或不拆,用一个指令打包。简单来说,整理材料这个场景的特殊点在于我们可能会分多次输入,也可能不会。那这两种情况要分开定义吗?不用。
对于输入来说,使用 /datas:用户可能会拆分多次输入 就比多写一条 /data:用户输入数据,进入整理 的效果要好,因为“可能会拆分”就包括了拆或不拆2种情况,没有必要多写一条分支。而对于输出,设定一个暗号 /output 自动触发处理就好,用户侧只需要不断回“1”确认,直到全部输出。
#写法1——分开定义,有重合的地方
/data:用户输入数据,进入整理
/datas:用户拆分多次输入……/用户可能会拆分多次输入……
#写法2——有效合并,1个指令覆盖2种情况
/datas:用户可能会拆分多次输入……
有了这两个方法,就可以在 指令 定义里面“转述”需求,快速完成 prompt 设计了。

对于“材料整理”这类要求比较严谨的情况,我们可以让AI指出设计存在的不足,主动迭代一次。和之前根据结果来被动迭代不同,你会得到一些意想不到的收获。

ChatGPT偶尔会在没有要求的情况下自己说出对任务或步骤的理解。

这种情况,不需要强制要求“不要解释”。从任务结果的角度,它的确是多余的,但从AI运作逻辑的角度,明牌的理解远远好过暗箱的结果。
✦ 特殊任务:空手套白狼
Prompt准备好,我们先来跑一个手里没有任何数据的特殊情况。只要单独定义一条兼容新手的指令就能实现。
💬 prompt
🤖️ ChatGPT
这里也提供一种极致压缩的指令方式,功能指令加上数量,能够直接覆盖数量的默认值。

✦ 主线任务1:单次整理
无中生有都能解决,其他的就更有信心了。我们回到主线任务整理已有的数据。先采用刚才AI提出的好建议,让正式prompt更简洁好用。(prompt附录可见)

先挑一个分类进行整理,这里选择了词条相对少的“色彩”,因此不需要拆分多次输入。我这里的设计是在 /datas 模式下输入一次数据。为了减少会话,你还可以参考下面prompt里的3个减号 --- ,用它隔断数据,再合入暗号“1”,自动触发 /output 模式,由GPT输出已经整理好的内容。
💬 prompt
需要注意的是,GPT-4对这种合并表达的理解更稳定,但对ChatGPT弟弟来说,单独多发一条暗号更稳妥。

输出结果中,除了有鸢尾色、丁香色、红宝石色这些狭义上的色彩名称,还有浅色调、柔和、莫兰迪、活力等等色彩感受。这些词混合在一起,二级分类的细节没有体现出来。怎么办呢?你可以单独要求整理一类带色卡的,暗示GPT在后续的任务中记住细分类目这件事。
✦ 主线任务2:智能填充
单次整理之后,可能还有继续补充数据的需求,甚至可能你自己都不记得是不是整理过这个类目了。所以针对 /fill 分支,我设计了容错判断,假如某个分类已经有整理好的数据了,那就在此基础上沿用规格和格式来填充更多,否则就让用户提供需要整理的数据。
比如现在“色彩”已经确认满意了,那就可以在效果可预期的情况下填充更多,节省人力。

✦ 主线任务3:拆分整理
在“光线”类目里,我准备了相对较多的零散词条。这种数据储备在其他分类没问题的前提下解决,效果会更好。
先来搞定拆分输入。现在GPT还没办法直接输入文档,所以我们粘贴数据就好,不用关心格式和词条里各个描述维度的位置。

用暗号“1”让AI知道输入完事了,接着逐块拿到输出。

这个Emoji和二级分类名,除了承担拆分输出的作用,最后我们将数据粘贴到表格文档中的时候,它们还有清晰地划分模块的作用。
其他比“光线”相对次要的分类,按同样的方式来输入输出即可,也可以参考“色彩”分类,按需定义差异化的输出表格。你想自动配图也可以,基础课程中我也分享过方法。

边整理边用
存数据的过程相对枯燥,不过我们不用等材料都整理完了再用来出图,直接来看怎么玩。按惯例还是由首席执行官ChatGPT完成初始画面,我给你安排了一段极简提词器,这是用于衍生一切复杂提词器产品的精华。
你是一个专业AI画师,请生成一组清晰、明确的关键词来描述一个具体的主题画面。步骤:
1、描述画面细节,重点加粗:
- 主题
- 色彩,光线,材质,构图,景别,视角
- 风格
2、用英文提炼为一个prompt,模版:
## 🔮 PROMPT
*Subject,color,...,style --ar w:h* #w:h:appropriate aspect ratio。
---
主题:枫林日落
这段prompt里,步骤1是精华中的精华,主题+维度。
🤖️ ChatGPT

绘图词典已经囊括了色彩、光线、材质、构图、景别、视角等等画面细节,如果你还有精确控制画面的需求,比如说把GPT生成的天青色改成雾茫茫,从词典中挑出目标词汇来替换即可。下面是一个调整后的示例。
🪄 Image Prompt(Midjourney)
Maple Forest Sunset, cozycore, soft light, progressive composition, romantic atmasphere, Editorial photo --ar 16:9
🗣️ 人话
🤖️ Midjourney

小黑板
这节课我们使用ChatGPT来整理材料。要记得,整理之前,思考先行。
我们不是为了整理而整理,而是通过这个方式,掌握将ChatGPT结合到实际需求场景的思路,把主动的整理和实践中的思考结合起来,再配合整理过程中的“评级”和“备注”,把碎片化知识吃透。
我分享了3种实用的方法,让整理更轻松。

以“AI绘图词典”为例,我展示了使用GPT来整理凌乱的信息碎片的方法。首先从需求侧切入,捋出基础的7个整理需求和需要重点关注的拆分和智能校对。可以看到,因为需求繁多,不断改模版的方式就显得很低效,所以我建议设计一个兼收并蓄的prompt,方便打包解决。设计初始prompt之后,我们再学习一种主动迭代的方法,让AI指导整理逻辑上存在的不足,让后续的工作更加缜密。

整理的主线是针对手头已有的零碎信息,因为有个人的思考投入,整理成果才能真正变得好用。整理的支线是设计一行兼容小白的指令,实现空手也能套白狼。通过整理实例,希望你能掌握5条整理技巧。
- 允许AI自发输出理解,明牌执行。
- 在GPT对话框中对数据进行聚类、自动排序。
- 一行指令拆分长输入/输出。
- 智能数据校对,防止错漏和重复。
- 用好AI的优势,智能填充更多内容。
借由解决“文件整理”这个问题,你还可以展望其他的应用可能性。除了本节的AI绘图词典整理,你还可以将这个方法用到文件归档、整理网络收藏夹、笔记、图片和信息等等,或者是针对高品质的交流群,用来总结群聊重点并归类。
如果需要文件权限和自动化的整理,还可以要求GPT输出Python解决方案,一般就是利用os库来读取本地文件,自动操作。本质上它们都是分类并整理,利用强大的AI来消灭碎片信息,对于个人的知识体系化形成,还有更大的价值。
要点:

踏浪扬帆
假如你手上什么都没有,用“空手套白狼”的方式试试能否整成功,然后参考这一节的方法,自选整理目标,尽量将手头的碎片化材料串成体系。
期待在评论区看到你的思考或感受分享,也欢迎你将这节课分享给感兴趣的朋友们,戳此加入课程交流群,我们下节课再会。
附:整理 prompt
- 适用:ChatGPT。
- 表现更佳:GPT-4。
- 字数:540
- 声明:该prompt仅供个人参考学习,未经授权不可商用。
你是一位精通智能绘画领域的画师。请根据以下说明,使用表格对用户提供的数据进行整理和校对。
初始化模版:{
## 📝 菜单:
- 使用表格展现简洁的指令菜单(4列:功能emoji、指令、描述、默认值)#不要使用代码块回复。
- 回复:“请确认你的需求,示例:/oops 色彩”
}
## 指令:
/datas:用户可能会拆分多次输入,中途仅回复"👌收到",直到用户说"1"——>自动触发/output
/type:表格列=<序号+phrase+中文+评级+备注>(默认)
- "评级"只有🌟和🌟🌟,原数据未标示的留空
- 如果"中文"为空,填充一个翻译
- 原括号内的信息为备注,未标示的留空
/sort: <相似度(默认),字母表顺序 > #自动排序规则
/output: 进行二级归类和排序——>自动书写纠错、去重——>(`Subclass 1`——>用户回"1"——>`Subclass 2`)——>全部输出,自动触发/check。
/check: 整体数据校对。输出模版:
## 📊 数据校对
- 用列表输出结果统计:<词条统计+检查遗漏+纠错+去重>
- 确认用户是否满意——>Y=完成,N=返回到适当的步骤进行修改。
/fill:用户提供一个分类名——>是否有已整理的输出——>Y=补充 30 组词条,N=请用户提供需要整理的数据
/oops:用户是新手,他会输入一个分类名,请按<序号+phrase+中文+简介>填充 30 组整理好的数据表格。
---
## 要求:
- 为输出的Subclass标题搭配一个合适的emoji,例如:## 🔦 illumination
- phrase默认转换为小写,专有名词如Pixar、POV:保留严谨的大写
- 如果phrase为色彩类型,在输出中增加一个"色卡"列-->phrase是否可转换为Hex value,Y=显示 -->N=留空。
- 表格列:默认左对齐
- 输出见解时,使用简洁的描述
- 请一步一步思考
- peter 👍(1) 💬(2)
AI唱歌,老师上次说需要综合方案,我理解是:不是某一个AI产品能完成此功能,需要综合运用多个AI产品。如果是这样,也可以。请问老师:具体怎么做?用哪些产品组合在一起就可以实现。
2023-06-29