14 数据清洗:挑战大量噪音的需求
你好,我是键盘,我们继续驯服 GPT。
数据的处理通常有两种类型,一种是上节课的“重建秩序”,所有的数据都是有用的,而且让你在有序的状态下可以轻松地填充更多内容。另一种,就是这节课我们要讲的典型情况“沙里淘金”。什么意思呢?就是说交给GPT处理的数据里,只有一部分是有用的,其他的全是干扰。我们把这种数据叫做脏数据(Dirty Read),里面的干扰项和多余的信息,就是噪音。

我会结合一个可调整多个参数的智能配图方案来讲解实现过程,搞定它,你的所有配图需求就不用再通过人力搜索了。另外,区别于之前分享过的Unsplash接口,这个新接口获取到的可商用资源,格局又打开了“亿”点,除了照片题材,它还支持插画、矢量图、视频等等。
人人都能用的“AI清洗法”
我们的整活目标是让包含众多图片链接的数据流到自己手里,从中自动洗出想要的图片。这个思路同样适用于其他具备物料需求的场景,比如获取某段时间的一类数据、文章配图、宣传材料的视频和BGM等等。
实现原理比较简单,而且通用。以“清洗图片”为例,我简单描述下。
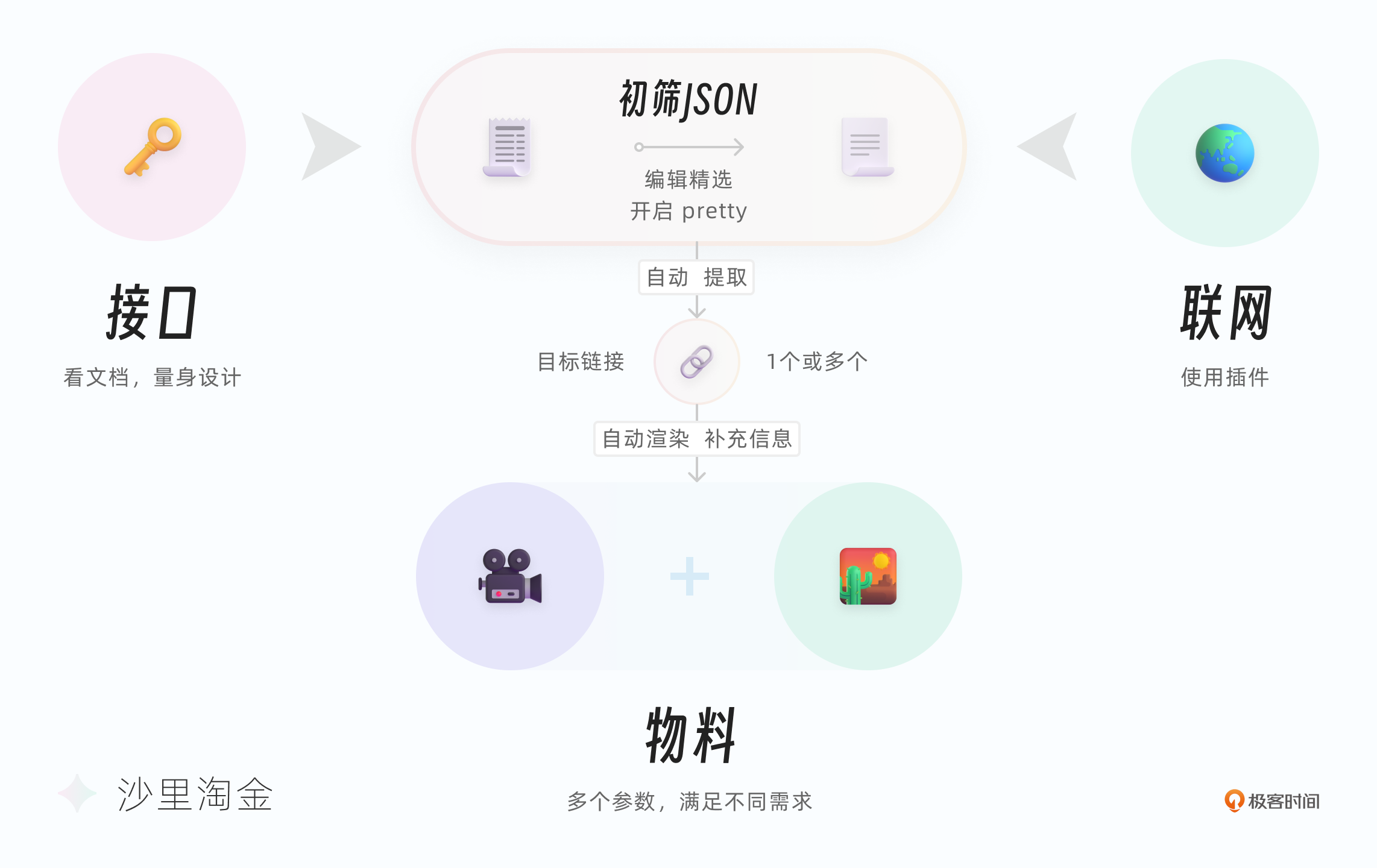
- 我们自己手动获取某个可商用图片网站的API key(以下用“私钥”指代)。结合我们想要的目标图片细节要求,让GPT将私钥和参数组装成“请求链接”。
- 在浏览器中输入请求链接,如果你有ChatGPT Plus,也可以用联网插件直接处理,得到一个用来初筛目标范围的JSON文件。
- 让GPT从JSON文件中提取出合适的图片链接。
- 让GPT将其输出为图片或其他资源。
")
这节课的案例,我选取了比较贴合需求的图片网站 Pixabay 来做方案的接口。没有技术背景的朋友可以将“接口”简单理解为标准化管道,用管道来连接不同的服务,数据就能流通起来。
正式开始之前,再提示你一下准备工作。
- 注册一个 Pixabay 账户:用来获取API key,使用它来组成“请求链接”,获取目标JSON文件。

- 推荐使用GPT-4和WebPilot插件:因为GPT模型无法直接联网,需要搭配联网插件来处理接口。假如你是ChatGPT Plus会员,使用这个组合的效果最好。
假如你的手里只有ChatGPT,也可以兼容。只要通过一些参数处理手段,比如开启“编辑精选”精细筛选题材或尺寸等等,让目标JSON大幅缩短而且变得规整好读,然后手动发给ChatGPT来提取,让ChatGPT写一个本地的批处理提取脚本,也是没问题的。
准备完毕,我们要开始整活了。
✦ 获取数据:设计自己的接口
刚刚我们说了用Pixabay的接口来获取图片。具体怎么做呢?先看看官方接口文档,了解这个接口都能干什么。假如你对英语阅读有一定的困难,使用智学三件套中分享的沉浸式翻译来做辅助即可。
Pixabay给出的参数(Parameters)总共有17个, 参数=什么 这个结构的作用就是告诉接口“你要什么细节”,参数里面主要包含两类。
- 字符串
str=,比如q=read表示“搜索关键词read相关的图片”。 - 开关
bool=true/false,比如 editors_choice=true 表示“打开编辑精选”。(=true就是开启的意思,后面同理)
我从17个参数里挑出了重点影响结果质量和处理效率的部分,下面的图稿里也提供了注解,供你参考。

参数的使用也非常简单,在 http://pixabay.com/api/ 后面加上参数是什么,还有状态开(ture)或关(false)就可以了,没有编程什么事。
之后你会得到下面这个基础的请求链接 。使用时记得替换 你的私钥 和目标关键词 keywords ,这样它才是完整的。
然后把完整的请求链接贴到浏览器地址栏中,现在我们要来面对脏兮兮的JSON文件了。这里可以先打住,思考一下,如果这个JSON可以变简单,处理不就更轻松了?ChatGPT无法接收冗长信息的问题也将迎刃而解。
✦ 清洗数据:智取,不硬刚
想要让“清洗”变简单,就一定要掌握2个重点参数。
- 编辑精选。是的,让赛博编辑为你打工,自动挑出质量更好的结果。对应代码中的
editors_choice=true。 - 干得“漂亮”,
pretty=true。让输出的JSON文件变整洁,既方便GPT更快地计算,还能大幅节省Token的用量,当你使用GPT API来做方案的时候,节省Token就等于省钱。所以,务必带上。
组合起来,就能得到一个用于获取目标JSON的“漂亮请求”。
https://pixabay.com/api/?key=`填入你的key`&q=`keywords`&image_type=`type`&editors_choice=true&pretty=true
✦ 手动测试
接下来不要急匆匆开始写prompt,玩转GPT的正确姿势永远是一步一步思考。我们先在浏览器中粘贴上面的“漂亮请求”,观察能不能手动“洗”出图片。
")
图稿的左侧是没有开启 pretty 的后果,肉眼可见的“脏”。在GPT中流转这样的材料真的脑壳疼,你疼,AI也疼。中间开启 pretty 后瞬间“漂亮”,官方命名诚不我欺。这里面可以清晰地找到一个标签为 largeImageURL 的链接。全场最靓的高清大图,就是你了!我们粘贴链接打开,成功。
通过这个验证,我们就可以设计一行告诉GPT提取配图,渲染到对话框的Markdown模版。
上面所有设计好的参数和私钥也准备交给GPT,让它来智能组装。
✦ 设计prompt
只要掌握了接口的设计逻辑,所有具备智能搭配属性的需求都能用,prompt同理。我会聚焦最核心的提取部分,你按需延展即可。这种执行目标直接了当的情况,我定义为“直接提问型”,不需要什么角色扮演,直说需求就好。
💬 直接提问型 prompt 框架
这个prompt需要解决5个核心问题。
- 提供私钥,让GPT 自动拼合出获取JSON的“漂亮请求”,然后通过联网插件来处理这个请求。这里需要清理一个广泛的误区,不是说更高级的GPT-4就能联网,去处理网络请求,像Bard这种联网模型才能够直接处理网络请求。要记得,联网插件才是连接的核心。
- 获取图片时你可能需要多个关键词,API的
q参数里用关键词 + 关键词这样的格式来支持。用单样本示例(One-Shot Prompt)来教给GPT即可。
- 指明目标题材。你想要照片、插画还是矢量图?用综合人设用的方法,多设计一个开关来切换就可以。
- 告诉GPT怎么提取目标图片。使用前面提到的Markdown配图代码就可以,这里我还要求默认给目标图片配上和关键词相关的一句名人名言。
- 使用“判断技巧”,假如用户没有插件的“通行证”,那么只输出“漂亮请求”代码,用户通过请求拿到的数据发给GPT也能实现。
插件判断—>N:只执行到步骤2,等待用户输入JSON或者目标链接,再继续。Y:执行全流程。
#由于GPT自己无法判断插件情况,设计一个对应的开关指令来应对:
/plugin:Y=开启插件(默认),N=无插件
整合起来,你会得到一个pretty prompt。如果你不想频繁地修改prompt,记住一个永不过时的指导原则:更多思考,更少设计。

💬 洗图 prompt(注意替换私钥和keywords)
请根据我输入的关键词来配图:
步骤:
1、将关键词翻译为英语`keywords`(此处不使用插件)。多个关键词的情况,使用形式:keyword A+keyword B+…+keyword N
2、拼合成API链接,用代码块输出:
https://pixabay.com/api/?key=`API`&q=`keywords`&image_type=`type`&editors_choice=true&pretty=true
3、插件判断—>N:只执行到步骤2,等待用户输入JSON或者目标链接,再继续。Y:执行全流程。
4、将接口返回的JSON中的目标图片提取出来,用Markdown渲染,不要用代码块回复。
5、输出模版:
## 关键词

输出关键词相关的名人名言,使用Markdown引用格式渲染。不超过40个字。示例:
> “伸手摘星,即便一无所获,也不至于满手污泥”—李奥贝纳(Leo Burnett)
说明:
`API`: 🔑 替换你的key
`type`: all(Default), photo, illustration, vector
/plugin:Y=开启插件(默认),N=无插件
—
请一步一步思考。
/plugin= N,`关键词`=阅读
这里面有2个实用小技巧。
- 步骤1的翻译提醒“此处不使用插件”,用来告诉模型“好钢用在刀刃上”,不是所有步骤都需要联网处理。
- 尽可能利用AI的优势,我用Markdown引用格式示例后面加
> 搭配名人名言的方式,让GPT自动去填充信息,这样结果就不是单调的图片,而是可以灵活组装的材料。
躺着收图
现在我们只要提出关键词需求就可以自动获取目标图片了,来看看实际跑机怎么做。
✦ 跑机任务1:兼容ChatGPT
先来解决比较艰苦的“村里没联网”的情况,对应的“洗图prompt”结尾的指令是:
🤖️ ChatGPT

判断成功执行,复制“API链接”到浏览器地址栏,可以看到JSON数据。
- 第一种情况:贴入单个目标
由于我们开启了编辑精选和pretty参数,初筛结果干净多了,打开就能靠肉眼快速定位到“阅读”的目标大图链接,将它交给ChatGPT直接渲染出来,搞定。
- 第二种情况:贴入JSON,智取多个结果
我们试试组合 关键词 A + 关键词 B ,上面的截图里我的关键词是“阅读+光线”,结果精准匹配,没有问题。
再试一下JSON片段的提取方式。注意,ChatGPT的字数局限依然存在,超过1200汉字的片段,要么分拆输入,要么采用接下来我分享的技巧:截取一个字数不超标的片段就好,不用精确计算,大概1000字的长度就不会有太多段落。
根据观察,目标JSON文件里面有两个 _640.jpg 结尾的链接,对应2张中等精度的图片,我们让ChatGPT根据这个线索自动从贴入的JSON片段中提取出来,同样顺利搞定。
假如你的配图场景是手机壁纸,或者其他不讲究图片方向的情况,以上输出就可以满足你的需求。但是在日常工作和写文章的情景中,我们使用更多的是横版图片,根据官方文档提供的参数,在“漂亮请求”中加入 &orientation=horizon (表示构图方向为水平)就可以解决,当然你也可以在迭代沟通中补充参数的改动需求。
最后再试试切换题材?改变 type 参数,让它变成插画(illustration),稳!

✦ 跑机任务2:联网,效率起飞
现在我们证实了“孤岛模型”都能轻松解决任务,GPT-4 “接上网线”不就跟喝水一样简单了?试试就知道。
拿掉指令中的 /plugin= N ,在prompt说明中等效于 /plugin= Y ,也就是默认视为用户开启了插件。使用关键词“水母”来验收。
")
全流程提取自动化完美解决,脏活累活都让GPT-4包了。展开WebPilot的执行细节,你看这滚动条占比就能感受到AI都承受了什么。不过这都和我们没关系了,后续输入关键词,躺着拿图就行了。

好了,关闭箭头,让我们从此告别让人“眼前一黑”的数据清洗工作。
✦ 拓展玩法
假如你有一系列的关键词,还可以让 GPT 整理成一份完整的JSON文件,或者干脆就用一个符号,比如“,”做隔断,接着贴给GPT,设计暗号 “1” 来触发分段提取。这样的好处是省去了后续的重复输入。只要第一次调通了,一次性生成几个月的配图材料绝对轻而易举。
假如你想配可商用的视频呢?安排!这里选取关键词 light 来做验收。
同样从官方API文档中可以得到视频的请求链接,多加一节 video/,其他的可以原封不动。
https://pixabay.com/api/videos/
?key=`key`&q=`keywords`&video_type=`type`&editors_choice=true&pretty=true
其中,视频的 type 支持默认的 “all”,另外还有影视 “film”,动画 “animation”,按需定义就好。
🤖️ ChatGPT
 输出的素材传送门:在创造的过程中,神说:“要有光”,就有了光。
输出的素材传送门:在创造的过程中,神说:“要有光”,就有了光。
以前,即使已经掌握了一个可商用的素材平台,普通人获取这些素材的方式都离不开重复且线性的人力劳作,而现在AI就是要用来干掉这些毫无意义的工作,让我们腾出精力去应对高价值的事项。

最后我想和你分享的是,JSON可以提取的资源远远不止链接,只要是清洗数据,都可以用这节课的方法,比如下面的法律文书清洗。

这是我在3月份做的一个真实需求。我将爬取的法律文书数据交给GPT,从一大段凌乱的JSON中提取出一个规整的信息表格,对其进行总结,提炼出规律和思考。彼时我刚入门,还没有学习prompt工程,但是ChatGPT和GPT-4都跑通了,也就成为本次分享的星火,保留至今。
小黑板
现在我们已经讲齐了日常数据整理的两种情况,重建秩序和沙里淘金。这节课主要分享的是后者,通过寻找一个合适的接口获取包含大量数据的JSON文件,再通过GPT自动提取的方式,将目标物料“清洗”出来。掌握了这样的方法,清洗其他类型的数据也就有套路可循了。
设计GPT解决方案的过程,我建议向上兼容和向下兼容都要考虑,真正实现人人能用。普通用户靠ChatGPT能解决问题,高级用户使用联网插件让实现更高效。
接口其实离我们并不远,OpenAI 也提供了API keys,无论是接入GPT来打造自己的AI,还是体验各种第三方服务,比如备受赞誉的OpenAI Translator,我们都需要这把私钥。以前还需要研发同学帮忙才能通过网络爬虫的方式获取到宝贵的数据,如今,人人都可以用AI来取代低价值的重复工作,做更有价值的事情,做更好的决策。

最后我们总结一下,通过设计一个可调整多个参数的智能配图方案,我们都掌握了哪些方法呢?
- 设计之前,一定要阅读官方接口文档,少走弯路。
- 智取结果,用参数来初筛JSON,使计算和提取变简单。
- 量身定制参数,获得千变万化的智能结果。
- 先手动验证再攻破自动方案,稳扎稳打。
- 更多思考,更少设计,减少来回折腾。
- 让GPT自动拼合链接。
- 设计一个插件状态开关,指导GPT区分处理。既能向上支持联网,也能向下兼容孤岛模型。
- 好钢用在刀刃上,不是所有步骤都需要插件。
- 设计方案时,想方设法利用AI的优势,打造灵活、高效的组合。
通过亲自实践来吃透方法,我们就可以告别让人“眼前一黑”的数据清洗工作,躺收结果。但其实,哪有什么岁月静好,不过是通过思考,把负重前行转移给AI罢了。
要点:
踏浪扬帆
小伙伴们自己的清洗需求肯定不少,有些只是没有找到合适的AI切入点。关于清洗其他类型的数据你有什么想法吗?尽量试试套用这节课的方法而不是照搬prompt模版,设计一套自己的自动化清洗方案。
期待在评论区看到你的思考或感受分享,也欢迎你将这节课分享给感兴趣的朋友们,戳此加入课程交流群,我们下节课再会。
- peter 👍(2) 💬(1)
Q1:我让GPT给出一个产品的图片,GPT回答说“我是文本模型,无法提高图片”。这个问题怎么解决?老师的课里面好像能产生很多图片,怎么做到的? Q2:课程中,老师用到了一些符号,比如: ##, / 等,好像GPT可以把这些符号当做编程中的规则一样执行。请问:这些符号是GPT本身规定的吗?还是GPT自己实时理解的?
2023-07-01 - Seven七哥 👍(0) 💬(1)
3.5的ChatGPT无法直接使用本节提供的prompt,解析不了的感觉,4.0是可以的,附一张3.5的截图: 好的,让我们开始: **步骤 1:** 将关键词翻译为英语 关键词: 阅读 **步骤 2:** 拼合成API链接
**步骤 3:** 插件判断 - N (请提供 JSON 或者目标链接) **步骤 4:** 提取目标图片并用Markdown渲染 ## 关键词  **步骤 5:** 输出名言 > “阅读是心灵的窗户。” - 哈尔德·布卢姆(Harold Bloom)2024-01-29 - 6点无痛早起学习的和尚 👍(0) 💬(1)
数据清洗,我曾经用过 Python 然后去清洗一堆 json 里的数据,然后组装输出一句话,但是就实现这个功能而言,用 Python 实现优于 gpt
2023-09-24 - Geek_1ec717 👍(0) 💬(1)
这两期的文章读起来都感觉有点混乱,这个没说清楚就跳到下一个,难懂
2023-06-30 - Seven七哥 👍(0) 💬(0)
3.5无法解析本节给出的prompt: 好的,让我们开始: **步骤 1:** 将关键词翻译为英语 关键词: 阅读 **步骤 2:** 拼合成API链接
**步骤 3:** 插件判断 - N (请提供 JSON 或者目标链接) **步骤 4:** 提取目标图片并用Markdown渲染 ## 关键词  **步骤 5:** 输出名言 > “阅读是心灵的窗户。” - 哈尔德·布卢姆(Harold Bloom)2024-01-29