21 DID和PaddleGAN:表情生动的数字人播报员
你好,我是徐文浩。
上一讲里,我们已经学会了通过AI来进行语音合成。有了语音识别、ChatGPT,再加上这个语音合成,我们就可以做一个能和我们语音聊天的机器人了。不过光有声音还不够,我们还希望这个声音可以是某一个特定的人的声音。就好像在电影《Her》里面那样,AI因为用了影星斯嘉丽·约翰逊的配音,也吸引到不少观众。最后,光有声音还不够,我们还希望能够有视觉上的效果,最好能够模拟自己真的在镜头面前侃侃而谈的样子。
这些需求结合在一起,就是最近市面上很火的“数字人”,也是我们这一讲要学习的内容。当然,在这么短的时间里,我们做出来的数字人的效果肯定比不上商业公司的方案。不过作为概念演示也完全够用了。
制作一个语音聊天机器人
从文本ChatBot起步
我们先从最简单的文本ChatBot起步,先来做一个和第 6 讲一样的文本聊天机器人。对应的代码逻辑和第6讲的ChatGPT应用基本一样,整个的UI界面也还是使用Gradio来创建。
唯一的区别在于,我们把原先自己封装的Conversation类换成了Langchain的ConversationChain来实现,并且使用了SummaryBufferMemory。这样,我们就不需要强行设定只保留过去几轮对话了。
import openai, os
import gradio as gr
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
openai.api_key = os.environ["OPENAI_API_KEY"]
memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(
llm=OpenAI(max_tokens=2048, temperature=0.5),
memory=memory,
)
def predict(input, history=[]):
history.append(input)
response = conversation.predict(input=input)
history.append(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, history
with gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
txt.submit(predict, [txt, state], [chatbot, state])
demo.launch()
对应界面:
增加语音输入功能
接着,我们来给这个聊天机器人加上语音输入的功能,Gradio自带Audio模块,所以要做到这一点也不难。
- 首先,我们在Gradio的界面代码里面增加一个Audio组件。这个组件可以录制你的麦克风的声音。
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
- 然后,我们封装了一个transcribe方法,通过调用OpenAI的Whisper API就能够完成语音识别。这里有一点需要注意,OpenAI的Whisper API有点笨,它是根据文件名的后缀来判断是否是它支持的文件格式的。而Gradio的Audio组件录制出来的WAV文件没有后缀,所以我们要在这里做个文件重命名的工作。
def transcribe(audio):
os.rename(audio, audio + '.wav')
audio_file = open(audio + '.wav', "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
return transcript['text']
- 接着,我们就要把麦克风录好的声音自动发送给语音识别,然后再提交给原先基于文本聊天的机器人就好了。
我们先在Audio的change事件里,定义了触发process_audio的函数。这样,一旦麦克风的声音录制下来,就会直接触发聊天对话,不需要再单独手工提交一次内容。
然后在process_audio函数里,我们先是转录对应的文本,再调用文本聊天机器人的predict函数,触发对话。
修改后的完整代码在下面,你可以在本地运行,体验一下。
import openai, os
import gradio as gr
import azure.cognitiveservices.speech as speechsdk
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
openai.api_key = os.environ["OPENAI_API_KEY"]
memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(
llm=OpenAI(max_tokens=2048, temperature=0.5),
memory=memory,
)
def predict(input, history=[]):
history.append(input)
response = conversation.predict(input=input)
history.append(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, history
def transcribe(audio):
os.rename(audio, audio + '.wav')
audio_file = open(audio + '.wav', "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
return transcript['text']
def process_audio(audio, history=[]):
text = transcribe(audio)
return predict(text, history)
with gr.Blocks(css="#chatbot{height:350px} .overflow-y-auto{height:500px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
with gr.Row():
audio = gr.Audio(source="microphone", type="filepath")
txt.submit(predict, [txt, state], [chatbot, state])
audio.change(process_audio, [audio, state], [chatbot, state])
demo.launch()
对应界面:

增加语音回复功能
在能够接收语音输入之后,我们要做的就是让AI也能够用语音来回答我们的问题。而这个功能,通过上一讲我们介绍过的Azure的语音合成功能就能实现。我们只需要封装一个函数,来实现语音合成与播放的功能,然后在predict函数里面,拿到ChatGPT返回的回答之后调用一下这个函数就好了。
- 封装一个函数进行语音合成与播放。
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('AZURE_SPEECH_KEY'), region=os.environ.get('AZURE_SPEECH_REGION'))
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# The language of the voice that speaks.
speech_config.speech_synthesis_language='zh-CN'
speech_config.speech_synthesis_voice_name='zh-CN-XiaohanNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def play_voice(text):
speech_synthesizer.speak_text_async(text)
- 在拿到ChatGPT的返回结果之后调用一下这个函数。
def predict(input, history=[]):
history.append(input)
response = conversation.predict(input=input)
history.append(response)
play_voice(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, history
完整的语音对话的Demo代码我一并放在了下面,你可以像第 6 讲里我们介绍过的那样,直接部署到Gradio里面体验一下分享出去。
import openai, os
import gradio as gr
import azure.cognitiveservices.speech as speechsdk
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
openai.api_key = os.environ["OPENAI_API_KEY"]
memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(
llm=OpenAI(max_tokens=2048, temperature=0.5),
memory=memory,
)
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('AZURE_SPEECH_KEY'), region=os.environ.get('AZURE_SPEECH_REGION'))
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# The language of the voice that speaks.
speech_config.speech_synthesis_language='zh-CN'
speech_config.speech_synthesis_voice_name='zh-CN-XiaohanNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def play_voice(text):
speech_synthesizer.speak_text_async(text)
def predict(input, history=[]):
history.append(input)
response = conversation.predict(input=input)
history.append(response)
play_voice(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, history
def transcribe(audio):
os.rename(audio, audio + '.wav')
audio_file = open(audio + '.wav', "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
return transcript['text']
def process_audio(audio, history=[]):
text = transcribe(audio)
return predict(text, history)
with gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
with gr.Row():
audio = gr.Audio(source="microphone", type="filepath")
txt.submit(predict, [txt, state], [chatbot, state])
audio.change(process_audio, [audio, state], [chatbot, state])
demo.launch()
用D-ID给语音对口型
这里我们设计的聊天机器人不仅能够完全听懂我们说的话,还能通过语音来对话,这的确是一件很酷的事情。而且这里我们算上空行,也只用了60行代码。不过,我们并不会止步于此。接下来,我们还要为这个聊天机器人配上视频画面和口型。
现在,国内外已经有一些公司开始提供基于AI生成能对上口型的“数字人”的业务了。这里,我们就来试试目前用户比较多的 D-ID 提供的API,毕竟它直接为所有开发者提供了开放平台,并且还有5分钟的免费额度。
通过D-ID生成视频
首先,你要去d-id.com注册一个账号。别紧张,d-id.com 有邮箱就能注册账号,不像ChatGPT那么麻烦,并且D-ID送给注册用户20次调用API的机会,我们可以好好利用这些免费额度。
注册好账号以后,你就可以去访问自己的 Account Setting 页面生成一个API_KEY了。
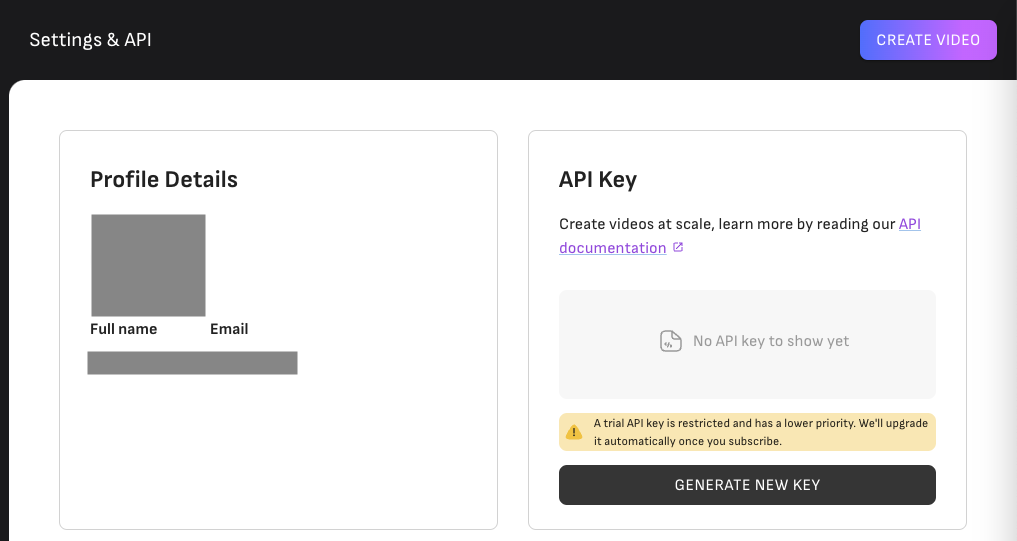
之后,你可以查看一下D-ID的文档,里面不仅有API的使用说明,还有一个类似Playground的界面,你可以设置参数,并且可以测试调用API。
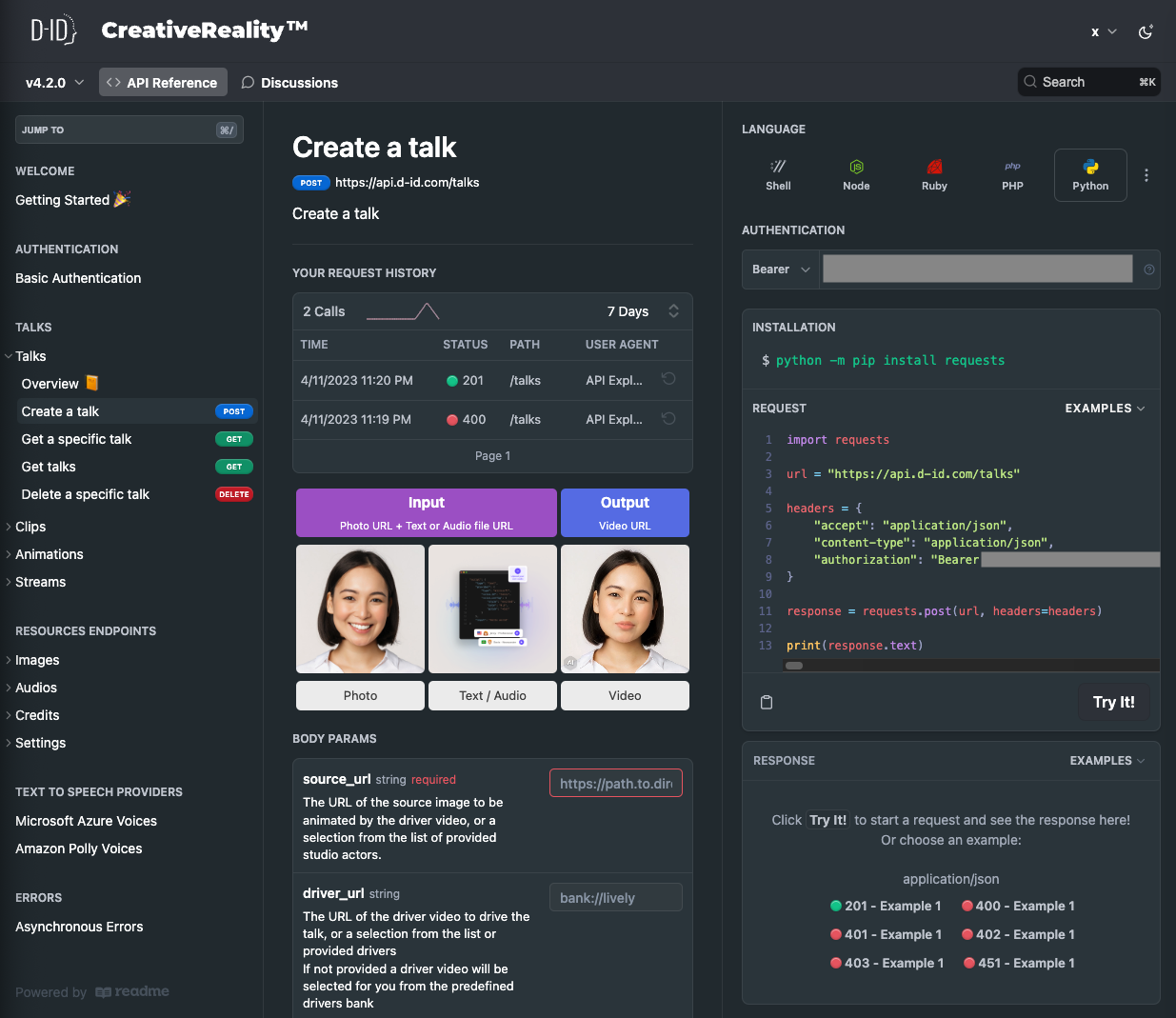
我们设置一下对应的API KEY并且确保安装了requests这个专门用来写HTTP请求的Python包,就可以测试一下这个代码的效果了。
安装requests包:
设置DID_API_KEY的环境变量:
我们可以先调用D-ID的Create A Talk接口,来创建一段小视频。只需要输入两个东西:一个是我们希望这个视频念出来的文本信息input,另一个就是一个清晰的正面头像照片。
在下面的代码里面可以看到,这其实就是一个简单的HTTP请求,并且文本转换成语音的过程,其实调用的也是Azure的语音合成功能。
import requests
import os
def generate_talk(input, avatar_url,
voice_type = "microsoft",
voice_id = "zh-CN-XiaomoNeural",
api_key = os.environ.get('DID_API_KEY')):
url = "https://api.d-id.com/talks"
payload = {
"script": {
"type": "text",
"provider": {
"type": voice_type,
"voice_id": voice_id
},
"ssml": "false",
"input": input
},
"config": {
"fluent": "false",
"pad_audio": "0.0"
},
"source_url": avatar_url
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Basic " + api_key
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
avatar_url = "https://cdn.discordapp.com/attachments/1065596492796153856/1095617463112187984/John_Carmack_Potrait_668a7a8d-1bb0-427d-8655-d32517f6583d.png"
text = "今天天气真不错呀。"
response = generate_talk(input=text, avatar_url=avatar_url)
print(response)
输出结果:
{'id': 'tlk_Nk9OfTGu_ZvLztD3HHC4b', 'created_at': '2023-04-12T03:07:38.593Z', 'created_by': 'google-oauth2|103752135956955592319', 'status': 'created', 'object': 'talk'}
这段代码运行成功之后,返回的结果是一个JSON。JSON里面有一个对应视频的id,我们可以通过这个id用Get A Talk的API拿到我们刚刚生成的口播视频,然后在Notebook里面播放。
获取生成的Talk视频:
def get_a_talk(id, api_key = os.environ.get('DID_API_KEY')):
url = "https://api.d-id.com/talks/" + id
headers = {
"accept": "application/json",
"authorization": "Basic "+api_key
}
response = requests.get(url, headers=headers)
return response.json()
talk = get_a_talk(response['id'])
print(talk)
输出结果:
{'metadata': {'driver_url': 'bank://lively/driver-03/original', 'mouth_open': False, 'num_faces': 1, 'num_frames': 48, 'processing_fps': 22.996171137505605, 'resolution': [512, 512], 'size_kib': 386.990234375}, 'audio_url': 'https://d-id-talks-prod.s3.us-west-2.amazonaws.com/google-oauth2%7C103752135956955592319/tlk_Nk9OfTGu_ZvLztD3HHC4b/microsoft.wav?AWSAccessKeyId=AKIA5CUMPJBIK65W6FGA&Expires=1681355260&Signature=2RluUIQyg%2FnIz54O2xEIr%2FqjaXA%3D', 'created_at': '2023-04-12T03:07:38.593Z', 'face': {'mask_confidence': -1, 'detection': [205, 115, 504, 552], 'overlap': 'no', 'size': 618, 'top_left': [45, 25], 'face_id': 0, 'detect_confidence': 0.9987131357192993}, 'config': {'stitch': False, 'pad_audio': 0, 'align_driver': True, 'sharpen': True, 'auto_match': True, 'normalization_factor': 1, 'logo': {'url': 'd-id-logo', 'position': [0, 0]}, 'motion_factor': 1, 'result_format': '.mp4', 'fluent': False, 'align_expand_factor': 0.3}, 'source_url': 'https://d-id-talks-prod.s3.us-west-2.amazonaws.com/google-oauth2%7C103752135956955592319/tlk_Nk9OfTGu_ZvLztD3HHC4b/source/noelle.jpeg?AWSAccessKeyId=AKIA5CUMPJBIK65W6FGA&Expires=1681355260&Signature=LNSFBaEUWtPYUo469qzmUGeHzec%3D', 'created_by': 'google-oauth2|103752135956955592319', 'status': 'done', 'driver_url': 'bank://lively/', 'modified_at': '2023-04-12T03:07:42.570Z', 'user_id': 'google-oauth2|103752135956955592319', 'result_url': 'https://d-id-talks-prod.s3.us-west-2.amazonaws.com/google-oauth2%7C103752135956955592319/tlk_Nk9OfTGu_ZvLztD3HHC4b/noelle.mp4?AWSAccessKeyId=AKIA5CUMPJBIK65W6FGA&Expires=1681355262&Signature=slWpvS1eEqcw4N%2FqVWN6K0zewuU%3D', 'id': 'tlk_Nk9OfTGu_ZvLztD3HHC4b', 'duration': 2, 'started_at': '2023-04-12T03:07:40.402'}
将对应的视频展示播放出来:
from IPython.display import display, HTML
def play_mp4_video(url):
video_tag = f"""
<video width="640" height="480" controls>
<source src="{url}" type="video/mp4">
Your browser does not support the video tag.
</video>
"""
return HTML(video_tag)
result_url = talk['result_url'])
play_mp4_video(result_url)
输出展示:

在这里,我用Midjourney生成了一张ID Software的创始人——大神约翰卡马克的头像。然后让D-ID给这个头像生成对应的对口型的视频,看到心目中的技术偶像开口说话还是非常让人震撼的。
将视频嵌入到Gradio应用中
有了这样可以对口型播放的视频,我们就可以再改造一下刚才通过Gradio创建的应用,不要光让机器人用语音了,直接用视频来开口说话吧。
我们在前面语音聊天界面的基础上,又做了几处改造。
- 我们在原有的Gradio界面中,又增加了一个HTML组件,显示头像图片,并用来播放对好口型的视频。默认一开始,显示的是一张图片。
……
with gr.Row():
video = gr.HTML(f'<img src="{avatar_url}" width="320" height="240" alt="John Carmack">', live=False)
注:这里增加了一个用来播放视频的HTML组件。
- 在录音转录后触发Predict函数的时候,我们不再通过Azure的语音合成技术来生成语音,而是直接使用 D-ID 的API来生成基于头像的且口型同步的视频动画。并且视频动画在生成之后,将前面HTML组件的内容替换成新生成的视频,并自动播放。
def predict(input, history=[]):
if input is not None:
history.append(input)
response = conversation.predict(input=input)
video_url = get_mp4_video(input=response, avatar_url=avatar_url)
video_html = f"""<video width="320" height="240" controls autoplay><source src="{video_url}" type="video/mp4"></video>"""
history.append(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, video_html, history
else:
video_html = f'<img src="{avatar_url}" width="320" height="240" alt="John Carmack">'
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, video_html, history
注:通过ChatGPT获取回答,然后将回答和头像一起生成一个视频文件自动播放。
- 在获取视频的时候需要注意一点,就是我们需要等待视频在D-ID的服务器生成完毕,才能拿到对应的result_url。其实更合理的做法是注册一个webhook,等待d-id通过webhook通知我们视频生成完毕了,再播放视频。不过考虑到演示的简便和代码数量,我们就没有再启用一个HTTP服务来接收webhook,而是采用sleep 1秒然后重试的方式,来实现获取视频的效果。
def get_mp4_video(input, avatar_url=avatar_url):
response = generate_talk(input=input, avatar_url=avatar_url)
talk = get_a_talk(response['id'])
video_url = ""
index = 0
while index < 30:
index += 1
if 'result_url' in talk:
video_url = talk['result_url']
return video_url
else:
time.sleep(1)
talk = get_a_talk(response['id'])
return video_url
注:result_url字段会在服务器端把整个视频生成完成之后才出现,所以我们需要循环等待。
改造完整体代码如下:
import openai, os, time, requests
import gradio as gr
from gradio import HTML
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
openai.api_key = os.environ["OPENAI_API_KEY"]
memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(
llm=OpenAI(max_tokens=2048, temperature=0.5),
memory=memory,
)
avatar_url = "https://cdn.discordapp.com/attachments/1065596492796153856/1095617463112187984/John_Carmack_Potrait_668a7a8d-1bb0-427d-8655-d32517f6583d.png"
def generate_talk(input, avatar_url,
voice_type = "microsoft",
voice_id = "zh-CN-YunyeNeural",
api_key = os.environ.get('DID_API_KEY')):
url = "https://api.d-id.com/talks"
payload = {
"script": {
"type": "text",
"provider": {
"type": voice_type,
"voice_id": voice_id
},
"ssml": "false",
"input": input
},
"config": {
"fluent": "false",
"pad_audio": "0.0"
},
"source_url": avatar_url
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Basic " + api_key
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
def get_a_talk(id, api_key = os.environ.get('DID_API_KEY')):
url = "https://api.d-id.com/talks/" + id
headers = {
"accept": "application/json",
"authorization": "Basic "+api_key
}
response = requests.get(url, headers=headers)
return response.json()
def get_mp4_video(input, avatar_url=avatar_url):
response = generate_talk(input=input, avatar_url=avatar_url)
talk = get_a_talk(response['id'])
video_url = ""
index = 0
while index < 30:
index += 1
if 'result_url' in talk:
video_url = talk['result_url']
return video_url
else:
time.sleep(1)
talk = get_a_talk(response['id'])
return video_url
def predict(input, history=[]):
if input is not None:
history.append(input)
response = conversation.predict(input=input)
video_url = get_mp4_video(input=response, avatar_url=avatar_url)
video_html = f"""<video width="320" height="240" controls autoplay><source src="{video_url}" type="video/mp4"></video>"""
history.append(response)
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, video_html, history
else:
video_html = f'<img src="{avatar_url}" width="320" height="240" alt="John Carmack">'
responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
return responses, video_html, history
def transcribe(audio):
os.rename(audio, audio + '.wav')
audio_file = open(audio + '.wav', "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file, prompt="这是一段简体中文的问题。")
return transcript['text']
def process_audio(audio, history=[]):
if audio is not None:
text = transcribe(audio)
return predict(text, history)
else:
text = None
return predict(text, history)
with gr.Blocks(css="#chatbot{height:500px} .overflow-y-auto{height:500px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
with gr.Row():
audio = gr.Audio(source="microphone", type="filepath")
with gr.Row():
video = gr.HTML(f'<img src="{avatar_url}" width="320" height="240" alt="John Carmack">', live=False)
txt.submit(predict, [txt, state], [chatbot, video, state])
audio.change(process_audio, [audio, state], [chatbot, video, state])
demo.launch()
输出结果:
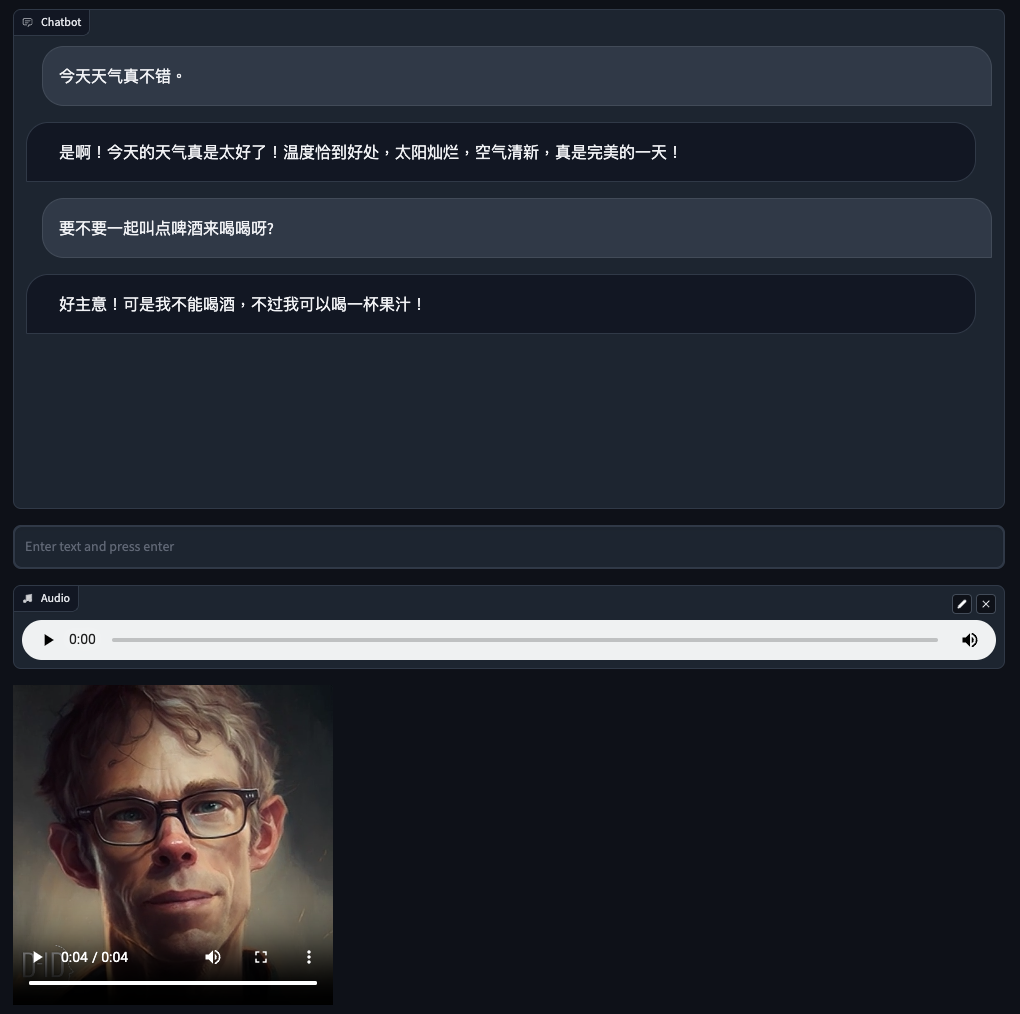
改造完整个应用,你可以试着运行一下。你的问题会由ID大神卡马克“亲口”+“当面”回答,是不是非常酷炫?
体验PaddleGAN开源模型下的数字主播
不过,使用D-ID的价格也不便宜,而前面的各个模块,我其实都给你看过对应的开源解决方案。比如ChatGPT我们可以用ChatGLM来代替,语音识别我们可以使用本地的Whisper模型,语音合成也可以通过PaddleSpeech里的fastspeech2的开源模型来完成。那么,我们这里也来尝试一下通过开源模型来合成这样的口播视频。
目前比较容易找到的解决方案,是百度PaddlePaddle下的 PaddleBobo 开源项目。它背后使用的是PaddleGAN的对抗生成网络算法,来实现唇形和表情的匹配。不过PaddleGAN很久没有更新了,对于最新的Python3.10的支持和依赖有些问题。我们也只能在这里做一个简单的演示。
这里的代码你不一定需要运行,因为这个程序对于GPU的显存要求比较高,而且对于Python以及Cuda的版本都有要求。而如果你使用CPU的话,对应的视频合成需要很长时间。你体验一下最后合成的视频效果就好了。
首先我们需要配置一个Python3.8的环境,并且安装对应的依赖包。
conda create -n py38 python=3.8
conda activate py38
#pip install paddlepaddle
#安装使用GPU的PaddlePaddle
pip install paddlepaddle-gpu
pip install ppgan
pip install isort
pip install typing-extensions
pip install lazy-object-proxy
pip install wrapt
pip install yacs
pip install paddlespeech
pip install "numpy<1.24.0"
brew install ffmpeg
然后,我们将PaddleBobo的代码通过Git下载到本地,并进入对应的目录。
我们将约翰卡马克的头像文件命名成johncarmack.png,复制到PaddleBobo的file/input目录下,然后修改对应的default.yml的配置,让我们的视频都基于约翰卡马克的头像来生成。
GANDRIVING:
FOM_INPUT_IMAGE: './file/input/johncarmack.png'
FOM_DRIVING_VIDEO: './file/input/zimeng.mp4'
FOM_OUTPUT_VIDEO: './file/input/johncarmack.mp4'
TTS:
SPEED: 1.0
PITCH: 1.0
ENERGY: 1.0
SAVEPATH:
VIDEO_SAVE_PATH: './file/output/video/'
AUDIO_SAVE_PATH: './file/output/audio/'
注:修改GanDriving的相关配置。
接着我们按照PaddleBobo的文档,通过create_virtual_human先生成一个能够动起来的人脸视频。如果你使用的是CPU的话,这个过程会很长,需要一两个小时。
因为PaddleBobo这个项目有一段时间没有维护了,对于最新版本的PaddleSpeech有一些小小的兼容问题,所以你还需要调整一下 PaddleTools 里面的TTS.py文件,修改import MODEL_HOME包的名称。
然后,我们再通过generate_demo输入我们希望这个视频口播的文字是什么。
python general_demo.py \
--human ./file/input/johncarmack.mp4 \
--output johncarmack_output.mp4 \
--text "我是约翰卡马克,很高兴认识大家"
最后生成的视频文件,我也放到我们的代码库的 data 目录里了,你可以下载下来体验一下效果是怎么样的。目前来说,通过GAN生成影像的方式,需要花费的时间还是比较长的,未来的技术发展也可能更偏向于Diffuser类型的算法,因此今天我们更多地是提供一种新的体验,让你感受一下人工智能带来的影像方面的创新。
这些命令行对应的Python程序其实也很简单,不超过50行代码,你有兴趣的话,可以读一下源代码看看它具体是调用哪些模型来实现的。
小结
好了,这一节课,到这里就结束了。
今天我们整合前两讲学习的知识,打造了一个可以通过语音来交互的聊天机器人。进一步地,我们通过D-ID.com这个SaaS,提供了一个能够对上口型、有表情的数字人来回复问题。当然,D-ID.com的价格比较昂贵,尤其是对于API调用的次数和生成视频的数量都有一定的限制。所以我们进一步尝试使用开源的PaddleBobo项目,来根据文本生成带口型的口播视频。而如果我们把语音识别从云换成本地的Whisper模型,把ChatGPT换成之前测试过的开源的ChatGLM,我们就有了一个完全开源的数字人解决方案。
当然,今天我为你演示的数字人,从效果上来看还很一般。不过,要知道我们并没有使用任何数据对模型进行微调,而是完全使用预训练好的开源模型。我写对应的演示代码也就只用了一两天晚上的时间而已。如果想要进一步优化效果,我们完全可以基于这些开源模型进一步去改造微调。
今天,大部分开源的深度学习技术已经进入了一个重大的拐点,任何人都可以通过云服务的API和开源模型搭建一个AI产品出来了。希望这一讲能让你拥有充足的知识和足够的创意去做出一个与众不同的产品来。
思考题
语音相关的AI产品市场上还有很多,但目前很多好的产品还都是闭源收费的。比如 elevenlabs 就可以模仿人的语音语调。它也支持中文,而且预设的“老外”语音说出来的中文还真有点儿老外说中文的腔调,你可以试着去体验一下。我们上一讲介绍过的PaddleSpeech,百度官方也给出了对应的小样本合成和小数据微调的示例,你也可以看一下。
基于这些SaaS或者开源项目,你是否可以尝试一下,把对应的数字人的声音替换成你自己的?欢迎你大胆尝试并且把你的体会分享到留言区,也欢迎你把这一讲的内容分享给感兴趣的朋友,我们下一讲再见。
推荐阅读
关于数字人,有很多开源方案,比如 FACIAL 就是由多个院校和三星研究院合作的解决方案。你也可以基于它们提供的代码来训练一个。感兴趣的话,可以去读一读它们的源码和论文。
- 勇.Max 👍(13) 💬(2)
特意赶到最新进度的文章给老师留言咨询个问题: 背景:首先,这个课程真的是干货满满,物超所值,感谢老师的辛苦、认真付出!但是,作为一个10来年经验的老码农(现在是区块链方面的架构、研发)总觉得跟得有点吃力,原因是缺少AI方面的基础知识,对课程中的一些库、算法的原理缺少基本的概念认知。当然如果只局限于”过一遍代码、熟练使用“基本是够了,但是我觉得还达不到入门级。所以,特地来请教下老师哪些可以作为入门的一手知识,越精简越好。 问题:能否请老师推荐或者总结归纳下入门AI或者大语言模型的最小基础知识是哪些?(李笑来老师提过的入门一个新领域的MAKE [Minimal Actionable Knowledge and Experience]) 可能上面的问题有点大,我再缩小下,我的目的不是转行AI领域开发,而是得心应手的使用AI大语言模型开发自己的应用或者提高工作效率,比如使用AI做些财务建议、投研之类的应用。我总觉得只是会调接口,完全不理解基础概念还是无法游刃有余的使用,离开课程,就很难有思路做自主开发了。 说的有点啰嗦了,感谢老师!
2023-04-24 - abc🙂 👍(3) 💬(2)
老师,如果想要AI学习我的写作风格,按照我的风格写作,要怎么训练呢?
2023-04-25 - John 👍(3) 💬(2)
这个paddleBoBo都一年没更新啦 还有没有平替或者潜在新产品呢
2023-04-24 - John 👍(1) 💬(1)
现在HeyGen不错 就是收费不低
2023-04-24 - 劉仲仲 👍(0) 💬(2)
出现error:module 'pexpect' has no attribute 'spawn',已经是最新的pexpect
2023-04-28 - 粉墨之下 👍(0) 💬(1)
本地运行后,回复时报错:Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised APIConnectionError: Error communicating with OpenAI: HTTPSConnectionPool(host='api.openai.com', port=443): Max retries exceeded with url: /v1/completions (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001F9C7DAD670>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。')).
2023-04-24 - 一叶 👍(0) 💬(2)
刚看了下,这个did的价格不是一般的贵....
2023-04-24 - 小理想。 👍(0) 💬(0)
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False) 官网文档也都没有.style(container=False)
2023-11-09 - 小理想。 👍(0) 💬(0)
audio = gr.Audio(source="microphone", type="filepath") 老师这段代码没有source属性,这个属性是sources才可以,可能写错了哈哈哈 audio=gr.Audio(sources="microphone", type="filepath")
2023-11-09 - 小理想。 👍(0) 💬(0)
https://cdn.discordapp.com/attachments/1065596492796153856/1095617463112187984/John_Carmack_Potrait_668a7a8d-1bb0-427d-8655-d32517f6583d.png 老师这个地址访问不了,是不是我需要把文件下载下来自己映射一下哈
2023-11-07 - 静心 👍(0) 💬(0)
如果能有一个完整的数字人开源方案就好了
2023-07-12