01 洞察本质:从工程学角度看ChatGPT为什么会崛起
你好,我是独行。
2022年11月底,OpenAI发布了ChatGPT,2023年1月注册用户超过一亿,成为历史上增长最快的应用,上一个纪录保持者是TikTok,注册用户超过一亿用时9个月。2023年3月开始,ChatGPT燃爆中国互联网界。
实际上国内外同一时期搞大模型的团队很多,为什么ChatGPT会突然火起来?还有在ChatGPT发布后,为什么各个大厂在短时间内相继发布大模型产品?比如3月百度发布文心一言,4月阿里云发布通义千问,5月科大讯飞发布星火认知大模型等等。

我们最容易想到的原因是,OpenAI在自然语言处理(NLP)方面取得了突破性的进展,这是技术层面看到的。实际上,ChatGPT背后包含了一系列的资源整合,包括技术、资金、大厂背书等等,以及多个国际巨头的通力合作,比如OpenAI、微软、NVIDIA、GitHub等。所以说,ChatGPT不仅仅是技术上的突破,更是工程和产品的伟大胜利!
那么ChatGPT具体是如何赢得这场胜利的呢?我们一一来看。
NLP技术突破:强势整合技术资源
基于Transformer架构的语言模型大体上分为两类,一类是以BERT为代表的掩码语言模型(Masked Language Model,MLM),一类以GPT为代表的自回归语言模型(Autoregressive Language Model,ALM)。OpenAI的创建宗旨是:创建造福全人类的安全通用人工智能(AGI),所以创立之初就摒弃了传统AI模型标注式的训练方式,因为可用来标注的数据总是有限的,很难做得非常通用。那么为了实现AGI,OpenAI在技术上到底做对了什么呢?
基于自回归的无监督训练
GPT系列的模型一直走的是和BERT不一样的线路,早些年压力巨大,毕竟BERT是Google发布的,非常权威。但是OpenAI一直认为自回归模型训练潜力更大,尤其在GPT-2引入zero-shot后,更加有信心了。
按照人类语言的习惯,语言本身就有先后顺序,而且我们日常说话也是下文依赖上文。所以有人猜测,自回归语言模型代表了标准的语言模型,利用上文信息预测下文,这比传统AI预测更加复杂,但是上限更高,更有望通向AGI,这正是OpenAI的愿景。尽管在GPT-1和GPT-2的探索中没有取得压倒性的效果,但确实验证了标准语言模型在zero-shot等方面的潜在能力。
无监督自回归的训练方式,使GPT模型可以接受大量文本数据,所以后面有了GPT-3,1750亿的参数规模,使GPT-3直接问鼎当时最大的模型,GPT-3使用了大约45TB的文本数据,一次训练费用近460万美元,在当时,相比上一代模型GPT-2,效果已经非常好了,这也是人们所讲的大力出奇迹。
但是,我们现在来看这个问题,GPT-3发布时间大概是2020年3月,当时的GPT-3还不具备直接和人类对话的能力。而ChatGPT所使用的模型是GPT-3.5,爆火时间在2022年年底到2023年3月,期间将近2年的时间,OpenAI在做什么呢?答案是他们在想办法让GPT模型可以优雅地和人类进行对话。
与人类意识对齐(Alignment)
我们知道,人类是有感情的,很多事物是有极限的,比如人再怎么能吃也不可能一顿饭吃100个馒头,万一大模型输出的内容有这类意识,那么肯定是不合理的,所以要进行微调对齐。
GPT-3和GPT-3.5其实是两个不同的系列,使用过OpenAI API的人应该知道,还有几个细化的模型,比如code-davinci、text-davince系列。顾名思义,code-davince就是OpenAI另一个产品codex使用的模型,在text-davince-001的基础上使用源代码进行训练,产生了code-davinci-002模型(codex)。再后来在code-davinci-002模型基础上,基于有监督的指令微调,产生了text-davinci-002,最后在text-davinci-002模型基础上,使用RLHF,产生了text-davinci-003和ChatGPT模型。演进过程如图所示:
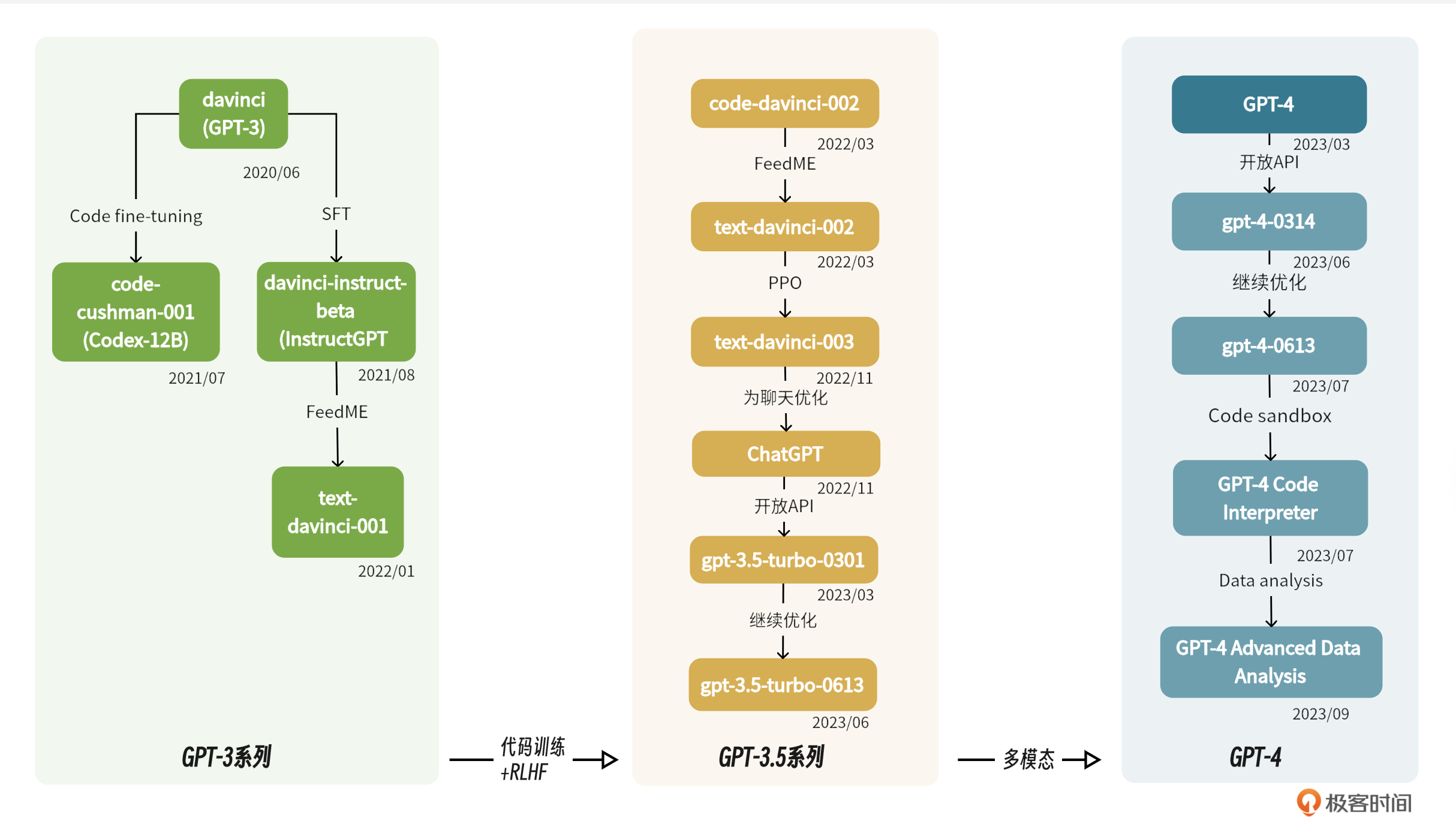
GPT-3经过充分训练,但是依然不是一个适合与人类进行对话的模型,所以从GPT-3到GPT-3.5再到InstructGPT和ChatGPT,参数规模并没有太大变化,主要是经过了各种技术的微调,说白了就是去适配人类情景。其中,最突出的就是RLHF。RLHF就是Reinforcement Learning From Human Feedback(人类反馈强化学习)的简称。关于RLHF的详细介绍,我们会放在后面的章节中。
突现能力(Emergent Ability)
突现能力是指大语言模型展现出来的特有的强大能力,比如复杂推理、思维链等。这些是NLP领域一直追求的能力,在大模型出现后,这些能力也随之浮现出来。我们举一个简单的例子。
这个推理看着简单,实际上对于AI来说有一定的难度,因为语言和数学混在一起了。在早期GPT-3模型上进行类似的推理,准确率并不高,低于40%,后来在code-davinci-002上进行推理,准确率能达到80%以上。为什么性能会有这么大的提升?
很明显原因不是模型规模,因为code-davinci-002在规模上并没有扩大,唯一能解释的就是 code-davinci-002是基于代码进行训练的,这些突现能力是大模型经过大量代码训练后展现出来的能力。也有人说,面向过程的编程跟人类逐步解决任务的过程很类似,面向对象编程跟人类将复杂任务分解为多个简单任务的过程很类似。所以有人认为,代码训练和思维链及复杂推理有很强的相关性,不过到目前为止没有非常确定的证据可以证明这一点。
我们可以总结一下。
- 模型不是越大越好。论参数,GPT-3的1750亿不是参数最大的模型,比如,微软和英伟达联合开发的Megatron-Turing模型拥有超过5000亿个参数,但是在性能方面并不是最好的,因为模型未经充分地训练。
- RLHF也不是最早用在GPT上的,却在恰当的时机用到了ChatGPT身上。
- 在语言模型上使用大量代码进行训练,只有codex这么做了。
所以,ChatGPT在技术上的突破可以理解为:
$$自回归语言模型+充分无监督训练+大量代码训练+有监督指令微调+RLHF$$
放眼望去,全球仅此一家!那这么多技术叠加在一起,怎么才能“大力出奇迹”呢?答案就是进行超大规模预训练。
超大规模数据集:超过40T的文本数据
大模型训练首先需要搞定高质量数据集,我们分两个点去考虑。
首先,我向你介绍下基础模型GPT-3的训练数据集。GPT-3模型具有1750亿个参数,训练数据集大约500B个token(1B=1 billion,也就是10亿)。下面是训练数据大概的组成结构:

原始大约45T的纯文本数据,经历过滤后,大概是750G的高质量文本数据。
我们再来看下ChatGPT的训练数据。ChatGPT属于GPT-3.5系列,官方并没有明确说明这个模型的参数规模,所以网上看到的大部分的数据都是猜测,有人说15亿,也有人说20亿甚至1500亿。但是大概率,ChatGPT的参数规模是小于GPT-3的,其训练数据基于大量对话型数据进行指令微调,典型训练数据如下:
- Persona-Chat 的数据集:专门用于训练ChatGPT等会话式AI模型。由两个人类参与者之间的超过160,000条对话组成,每个参与者都被分配了一个独特的角色来描述他们的背景、兴趣和个性。这使得ChatGPT能够学习如何生成个性化且与对话的特定上下文相关的响应。
- 康奈尔电影对话语料库:包含电影脚本中角色之间对话的数据集。包括10,000多个电影角色对之间的200,000多次对话,涵盖各种主题和类型。
- Ubuntu 对话语料库:寻求技术支持的用户与Ubuntu社区支持团队之间多轮对话的集合。它包含超过100万个对话,使其成为用于对话系统研究的最大的公开数据集之一。
- DailyDialog:各种主题的人与人对话的集合,从日常生活对话到有关社会问题的讨论。数据集中的每个对话都由几个回合组成,并标有一组情感、情绪和主题信息。
除了这些数据集之外,ChatGPT 还接受了互联网上大量非结构化数据的训练,包括网站、书籍和其他文本源。这使得 ChatGPT 能够从更一般的意义上了解语言的结构和模式,然后可以针对对话管理或情感分析等特定应用进行微调。
有这么多数据了,接着就要进行预训练了。下面这一步卡住了大部分大模型厂商,那就是计算资源。对于OpenAI这种创业公司而言,无疑是很大的困难,那他们是怎么解决的呢?没错,找金主爸爸。
找对了金主爸爸
OpenAI做对了一件非常重要的事儿,那就是找钱,而且还是找大钱,动辄几亿美元的投入。GPT-3的单次训练成本高达460万美元。在前景未知的情况下,这么大的投入是非常难的。找钱成了OpenAI非常重要的事情,为了找钱,OpenAI从开源转为闭源。
实际上,早期OpenAI是开源的,创办宗旨就是创建通用人工智能,造福人类,但是大模型训练需要大量的计算资源和数据,这是实打实需要资金投入的,所以OpenAI由开源转为闭源,设计了一种商业模式来吸引投资人,并吸引大量资金,其中最主要的就是微软。下面我向你介绍下这种商业模式。
OpenAI母公司是OpenAI Inc,属于非营利性质组织,这种情况下资本无法进入,所以后来成立了一家子公司,叫OpenAI LP,现在我们常说的OpenAI,其实就是OpenAI LP,这是一家纯粹的商业化公司,这家公司设置了最高100倍的回报上限,以此来权衡盈利和非盈利属性,也可以叫做“有限盈利”,既迎合资本家利益,也看似符合母公司非盈利组织的创建初衷。
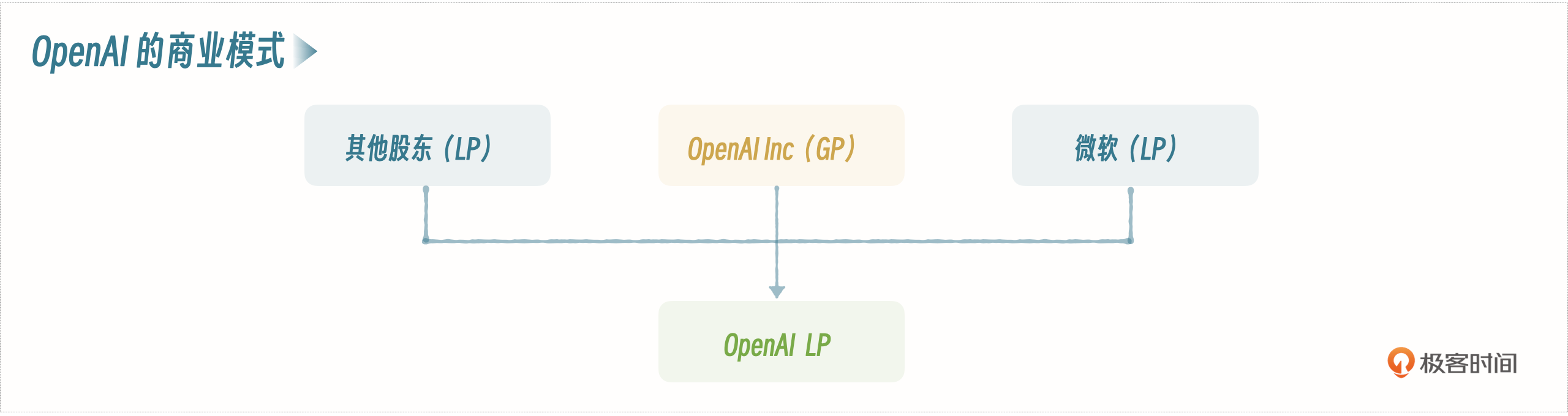
通过这种股权结构,成功获得微软累计超过100亿美金的投资,这里不得不说,微软为OpenAI带来的不仅仅是钱,更是强大的影响力,毕竟全世界人民是认微软的,包括我们中国人。
当模型完成大规模训练后,接下来就是面世了,OpenAI的玩法很直接,直接产品化,让大家随便玩。
产品化开放:让大家随便玩
ChatGPT成功之处在于,愿意公开免费给普通用户使用,虽然各大厂商都在宣称自己在搞大模型,且有多么厉害,但真正产品化后开放给用户的,还要数ChatGPT。
便捷使用
大部分的AI厂家只发布模型,感兴趣的技术人员去Huggingface下载,自己部署把玩,这样就把模型限制在了非常小的一个范围内。
而ChatGPT不一样,发布的是普通大众用户都可以使用的产品。通过邮箱注册就可以使用,全天候不限时,直接通过网页对话,使用门槛非常低。这要放在国内,还不得让你下载个App,甚至拉几个朋友才可以用。毕竟这背后是实打实的GPU算力成本,据说2022年ChatGPT的算力费用(包含训练和推理)+人力成本接近5亿美金,试问一下哪个小厂具备这样的实力?而哪个大厂又会在看不到业务前景的背景下,每年投这么多钱去玩?但OpenAI做到了。
从2024年4月份开始,ChatGPT开启无需注册即可使用的模式,彻底成为互联网基础设施。
适用场景多
OpenAI官方公开的ChatGPT使用场景有30类(参考官方链接),可以用于代码编写、代码翻译、智能问答、语音识别、模拟面试、情感分析、机器翻译、智能客服等多个领域。这使得更多的人能够感受到ChatGPT带来的便利和价值,容易获得大众的支持和信任。
使用效果好
在ChatGPT之前,市面上已经有很多AI问答机器人产品,比如微软小冰、小度,用过的人都知道,它们都有很多局限性。小冰是由小模型组成的,只能同时处理特定类型任务,无法相互关联,小度也一样,这类产品无法做通用性的问答,无法像ChatGPT一样,像是真人在回答,甚至还有记忆、有感情。
工程化应用
工程化即系统化、模块化、规范化的一个过程。我们做工程技术的开发人员很清楚,一个优秀的产品背后一定是有着惊人的技术参数,就拿支付宝来说,双十一高峰期,50万笔/秒的支付吞吐量,背后是大量的服务堆出来的,比如数百万台的服务器、大量的分布式技术的应用,如缓存、消息、文件存储等等。
ChatGPT也一样,OpenAI不是仅仅提供一个模型,让我们自己部署自己玩,而是直接将以大模型为内核的整套技术完成了产品化。对于两个月注册用户过亿的世界级产品来讲,这里面涉及到的技术可想而知,除了AI本身涉及的技术外,常见的工程化技术一样少不了。Web相关的我们就不讲了,主要分享下和模型训练相关的技术。
为了方便进行大模型训练。2020年,微软为OpenAI在Azure上搭建了计算集群,包含285000个AMD infiniBand 连接的CPU内核,另外还有10000个NVIDIA V100 Tensor Core GPU,是当时世界上第五大超级计算机,也是有史以来在公共云中(Azure)建立的最大的超级计算机。
我们知道,大模型训练动不动就是几周、几个月的训练,而如果服务器出现故障或者网络连接不稳定,怎么办?肯定不希望从头开始。那么如何实现容错呢?
微软开发了Project Forge,即Azure容器化和全局调度服务,可以保证AI计算负载保持高水平的利用率;通过建立透明检查点,定期增量保存模型的状态和代码,出现故障,恢复到最近检查点;同时硬件厂家NVIDIA也做了调整,他们的GPU实现了CRIU(用户模式下的检查点恢复),可以恢复GPU的内存使用,最终和CPU的检查点保持一致。软件和硬件协同工作,提高了效率。
所以光是模型训练这一步,为了实现可靠性,就集微软工程部门、微软研究院、OpenAI团队、NVIDIA团队共同努力于一体。同时,还涉及了隐私计算、私密GPU、TE空间等等。除此之外,OpenAI还雇佣了大量工人(约7.7万人)进行人工标注,总体硬件成本接近10亿美金,单日运营成本高达70万美金,真的是很烧钱。
小结
这节课我从宏观方面向你介绍了ChatGPT崛起的原因,相信你也对ChatGPT有了更深入的理解。下面我们再简单总结一下。所谓工程化主要就是指集技术、数据、产品、资源于一身,是一个系统性、规范性的工程项目,很多人想到ChatGPT,就想到了大模型本身,其实这是片面的,具体你可以参考下面思维导图再回顾一下细节。
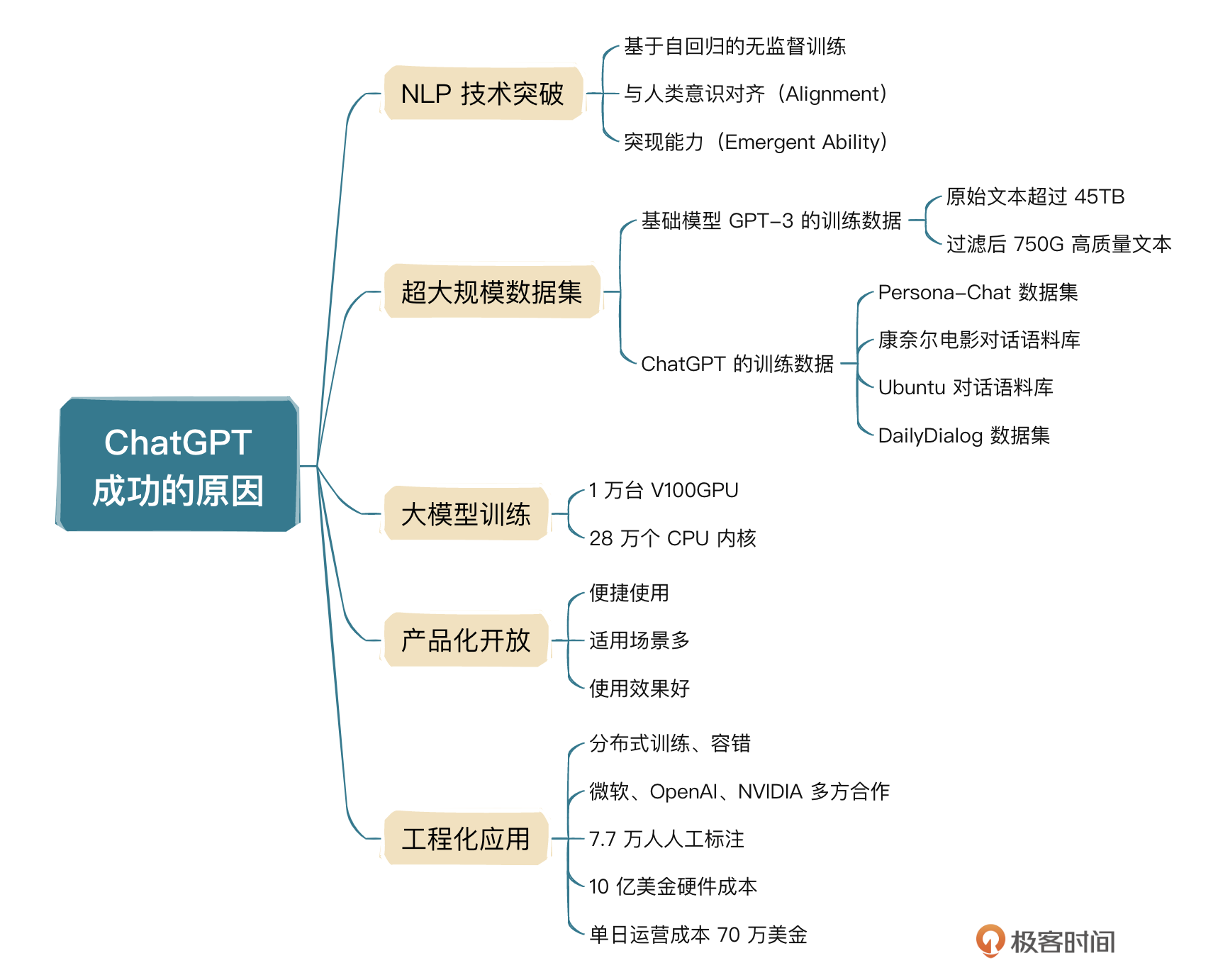
AI大模型还处于发展非常迅速的阶段,实际上天天都在发生变化,所以很多事情都还没有定论,我们需要保持开放的心态,不断接纳,不断学习。下一节课,我会从如何用好大模型这个角度,给你讲解下提示词工程,这也是刚接触AI大模型的用户非常容易忽略的问题,当然这也是能否用好AI大模型的核心。
思考题
学完了这节课的内容,请你来思考2个问题,ChatGPT已经这么强大了,那它是否已经具备了人类大脑的思维?还有AI到底能否代替我们目前的工作?欢迎你把你的观点分享到评论区,我们一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- wlih45 👍(0) 💬(1)
我认为从目前的技术来看还不可能代替,人类会根据所经历的事情去就行自我的一个反馈更改,但大模型用的啥数据训练出来就只知道啥,还无法不过的通过对话去就行回归训练
2024-08-04 - 干就完了 👍(6) 💬(1)
老师你好,问个问题: 有编程基础,没有深度学习和机器学习的基础,能看懂这门课吗?学完之后能达到什么程度?
2024-06-07 - zMansi 👍(4) 💬(1)
看了chatgpt 4o发布会演示,感觉真的具备初步的人脑思维了,场景对话以及语气等等都让人觉得未来将至 在我身边目前感觉还是偏向提效类工具,没有代替到真实工作 老师身边有工作被替代了吗?
2024-06-07 - 张申傲 👍(2) 💬(1)
第1讲打卡~ AI已经可以代替很多人类的日常工作了,我自己比较常用的包括代码生成、代码翻译、文章摘要、搜索等。并且未来的应用场景应该会越来越广泛!
2024-06-12 - 风轻扬 👍(2) 💬(1)
1、虽然不太想承认。但是AI现在确实已经具备了一定的人类思维,不过还不多。随着训练数据规模的不断加大,技术的持续迭代,我觉着AI会越来越具备人类的思维,像人类一样思考问题。 2、简单重复的场景,已经能替代人类了。复杂的场景,AI还需要学习,但只是时间问题。这给平时只会CRUD的同学已经敲响了警钟
2024-06-07 - TableBear 👍(1) 💬(1)
老师,请问代码训练是什么意思
2024-07-01 - 蒋波 👍(1) 💬(1)
个人理解目前大模型的确很强大了,而且还在多模态方向上发力提升学习能力,但我认为还不具备人类思维。个人理解人类思维很大的一个特点是具备自我反思能力,人类知道在有输出的每个节点自我完成了什么,知道下一步需要做什么,下一步可以做什么,还能根据自身的能力评估自我在可以做的里面能做什么,在发现不对时,还具备回退能力,总之具备在广泛意义上的大型网络上反馈(不仅仅是前馈)和各个节点列举、选择和评估路径的能力,更为重要的是在列举、选择和评估能力下,在顶层全局维度下,对当前局势、关系和情感的观察和评判,受情绪左右程度的把握。
2024-06-12 - JACOB 👍(1) 💬(1)
多久更新一次?
2024-06-05 - 石云升 👍(0) 💬(1)
Ai不是代替人,而是赋能人更高效的完成任务。
2024-08-10 - aiorosxu 👍(0) 💬(1)
Emergent,在复杂科学领域,好像一般会翻译为“涌现”,而不是“突现”。个人感觉涌现这个词更能体现Emergent的精髓。
2024-07-29 - 绿月亮 👍(0) 💬(1)
1. 我觉得已经具备了简单基本的思维。 一方面:人说话时是根据前面的信息想下一个字词要说什么,这跟大模型大量的训练让机器学习语言的规律,上文预测下个token的概率是一致的。 另一方面:我感觉婴儿学习也是类似的过程,他接收一般的语言规律(通过大量的观察并模仿,类似于无监督训练),在使用时经常犯错,这时候大人会纠正他(类似于有监督训练)。 2. 我觉得AI可以替代某些一成不变的工作,这些是标准化的,有规律的(这些正是大模型通过训练容易学习到的);有些创新性的倒是不容易被替代,也就是想象力不够(目前我们觉得大模型很强是因为我们人的记忆学习能力有限,但是机器是无限的,它学习了人类知识的大部分内容) 以上纯属个人见解,还请老师和前辈们批评指正。 另外有个疑问:大模型的有监督微调会不会就是让大模型记住了微调的内容?
2024-07-29 - 张 ·万岁! 👍(0) 💬(1)
我觉得chatgpt还是没有具备真正的人类大脑思维,他本质上还是对于已知资源的整合,直至信息准确率更高,记忆更长,在一个绘画中,如果有很多的聊天,他还是会忘掉一些记忆。
2024-07-12 - Geek_e9e5f5 👍(0) 💬(1)
一直对大模型的训练没法理解
2024-06-27 - Joe Black 👍(0) 💬(1)
现在做的项目,甲方想用大模型去做一些科学研究,创新性的东西,我觉得不现实,可能用大模型发现规律,汇总信息是可行的,但是它从来没见过的,新的理论怎么可能直接被发现呢?我该怎么说服甲方呢?🤣
2024-06-20 - hudy_coco 👍(5) 💬(1)
1.是否已经具备了人类大脑的思维,这个问题无法被验伪,那我们就姑且认为是真实的。从目前的测试表现来看,只能说明和人类大脑思维有差距,但这不一定是它全部的实力。 2.AI已经能够部分替代我们的工作,以后还会越来越多的,但个人认为最终无法完全替代,一是输出取决于输入,二是情感和想象是人类最后的高原。除非快进到智械时代,社会运转都由它来调控,那么人类就要找准自己新定位了。
2024-06-06