04 本地部署:如何本地化部署开源大模型ChatGLM3 6B?
你好,我是独行。
前面听我讲了这么多,相信你也很想上手试一试了。从这节课开始,我们进入一个新的章节,这部分我们会学习如何部署开源大模型ChatGLM3-6B,本地搭建向量库并结合LangChain做检索增强(RAG),并且我会带你做一次微调,从头学习大模型的部署、微调、推理等过程。
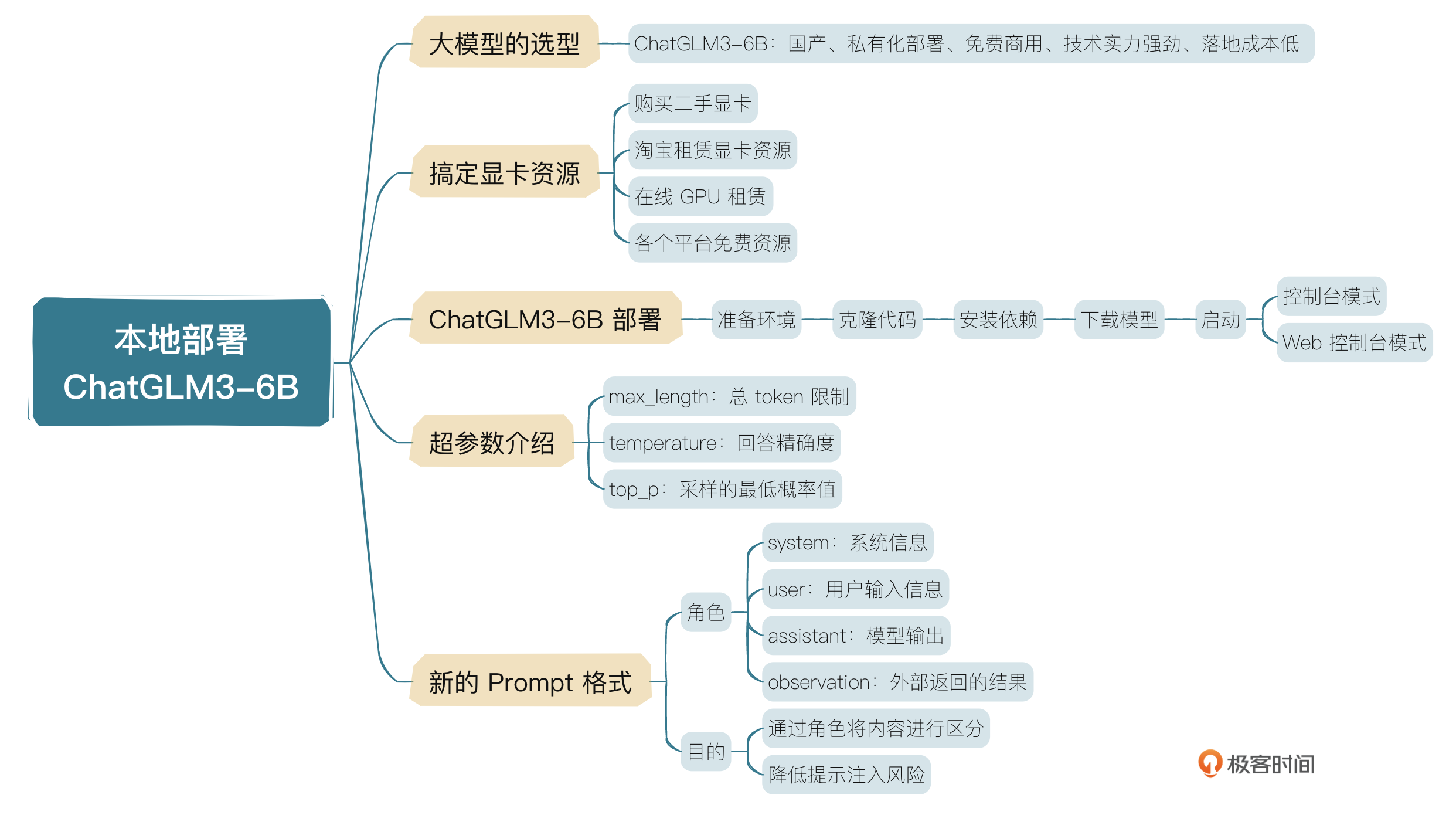
这节课我们就来讲一下如何本地化部署ChatGLM3-6B(后面我们简称为6B)。讲6B之前我们先整体看一下目前国内外大模型的发展状况,以便我们进行技术选型。
大模型的选择
当前环境下,大模型百花齐放。我筛选出了一些核心玩家,你可以看一下表格。非核心的其实还有很多,这里我就不一一列举了。厂商虽然很多,但真正在研究技术的没多少,毕竟前面我们讲过,玩大模型投入非常大,光看得见的成本,包括人才、训练和硬件费用,一年就得投入几个亿,不是一般玩家能玩得起的。
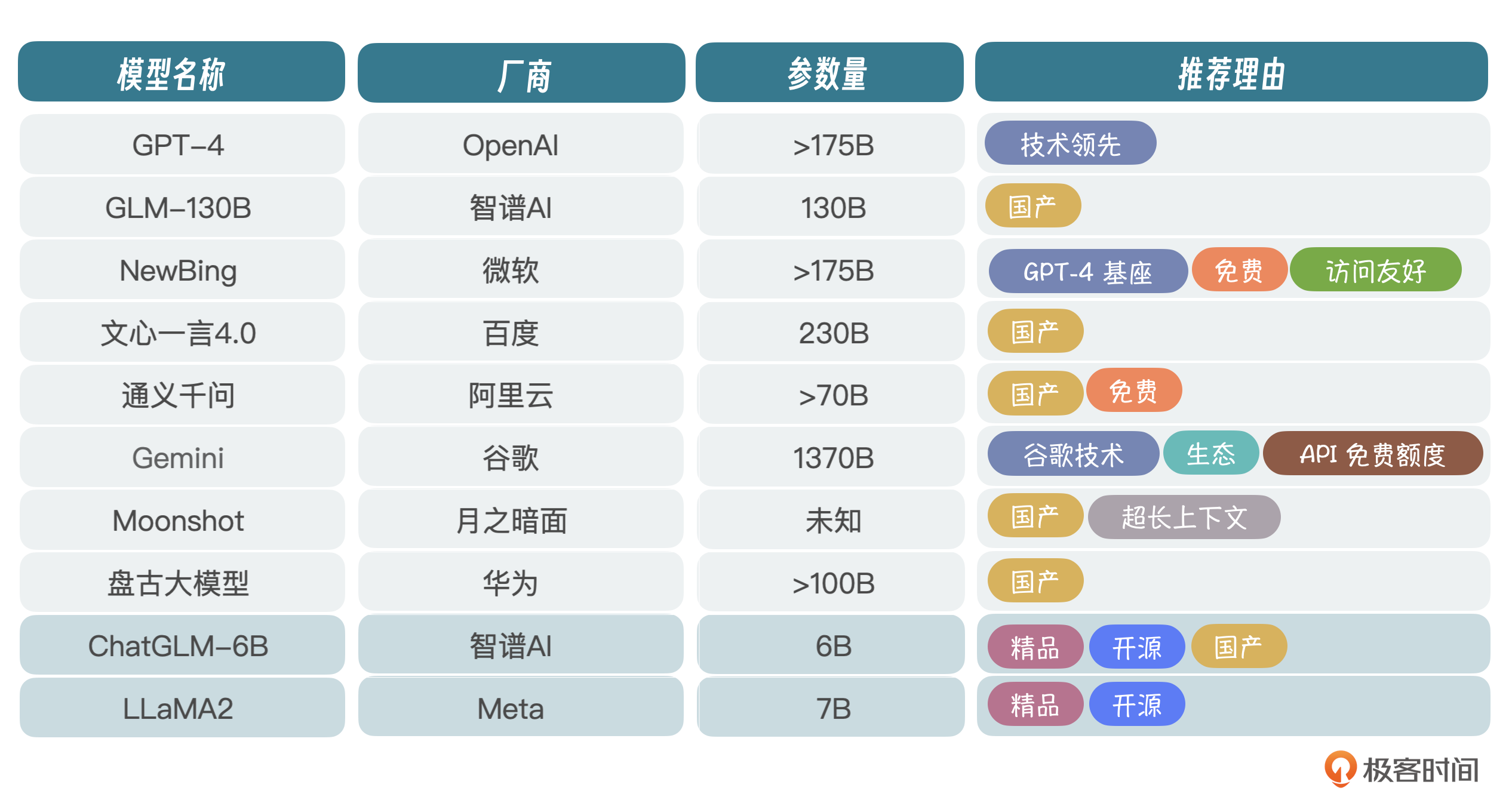
当然,也有不少厂商是基于LLaMA爆改的,或者叫套壳,不是真正意义上的自研大模型。
ChatGLM-6B和LLaMA2是目前开源项目比较热的两个,早在2023年年初,国内刚兴起大模型热潮时,智谱AI就开源了ChatGLM-6B,当然130B也可以拿过来跑,只不过模型太大,需要比较多的显卡,所以很多人就部署6B试玩。
从长远看,信创大潮下,国产大模型肯定是首选,企业布局AI大模型,要么选择MaaS服务,调用大厂大模型API,要么选择开源大模型,自己微调、部署,为上层应用提供服务。使用MaaS服务会面临数据安全问题,所以一般企业会选择私有化部署+公有云MaaS混合的方式来架构。在国产厂商里面,光从技术角度讲,我认为智谱AI是国内大模型研发水平最高的厂商,这也是我选择ChatGLM-6B的原因。
还有一点需要考虑,就是6B参数规模为62亿,单张3090显卡就可以进行微调(P-Turing)和推理,对于中小企业而言,简直就是福音。
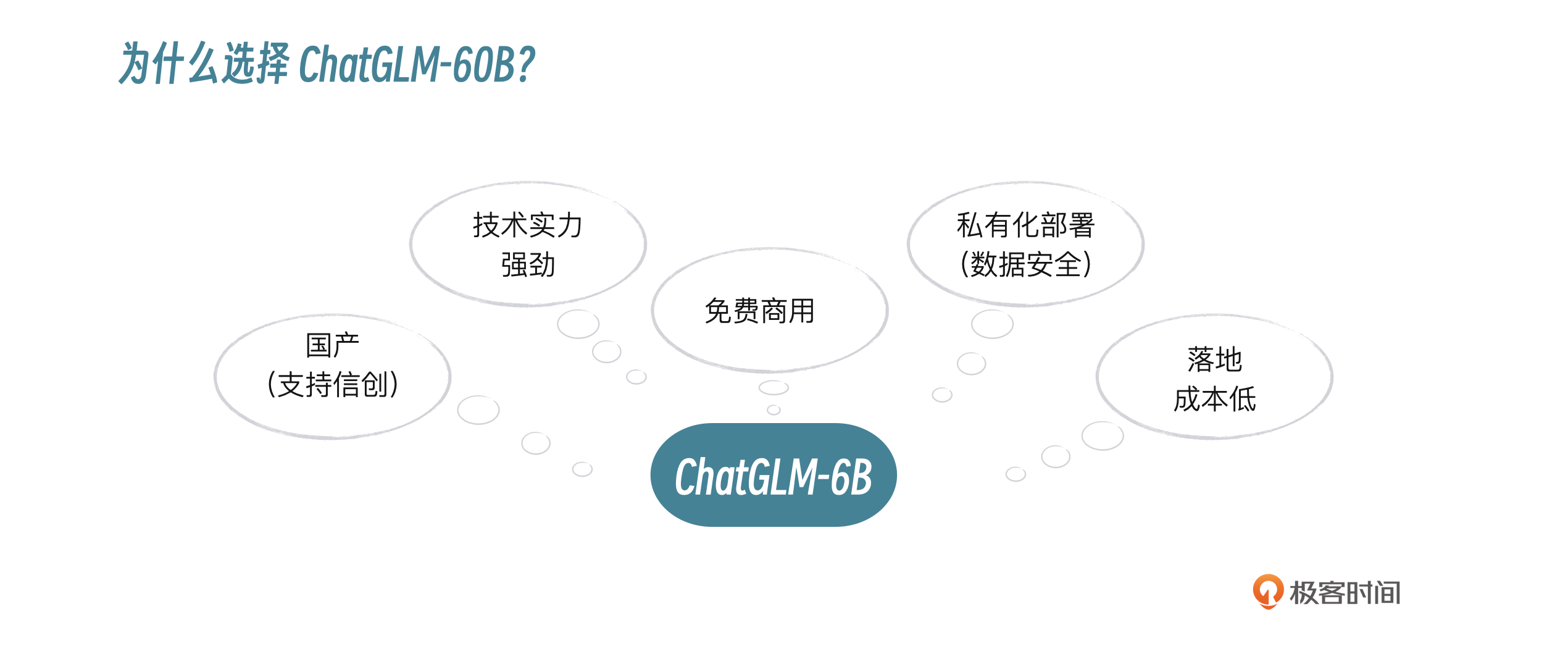
当然,如果企业预算充足(百万以上),可以尝试6B的老大哥GLM-130B,简称130B,千亿参数规模,推理能力更强,使用130B的话除了GPU资源费用,还需要进行商业授权,这个要注意。

下面我们讲讲预算不足的情况下,怎么搞定显卡资源?
如何搞定显卡资源?
玩儿大模型第一步就是要想办法解决计算资源问题,要么CPU要么GPU,当然还有TPU,不过TPU太小众,这里我就不介绍了。我建议你想办法申请GPU,因为适合CPU计算的大模型不多,有些大模型可以在CPU上进行推理,但是需要使用低精度轻量化模型,而低精度下模型会失真,效果肯定不行,只适合简单把玩。如果要真正体验并应用到实际项目,必须上GPU。那我们可以从哪些渠道去购买GPU呢?
- 购买二手显卡:无论是个人使用还是企业使用,都可以考虑在网上购买二手RTX3090显卡,单卡24G显存,8000块左右,可以用于本地微调、推理。如果想用在产品上,也可以通过云服务做映射,提供简单的推理服务,但是不适合为大规模客户提供服务。
- 淘宝租赁显卡资源:适合个人学习使用,可以按天/周/月/年购买服务,比较灵活,成本也不高。
- 在线GPU租赁:比如autodl、RTX3090-24G,每月大概不到900块钱,也很划算。不仅仅可以用来本地测试,还可以用于生产环境推理,如果用在生产环境的话,最好按照实际推理需求,评估每秒推理量(具体方法我会在大模型应用架构部分讲解),搭建高可用推理环境。
- 各个平台免费资源:比如阿里云PAI平台、智谱AI的开放平台等,对于新人都有一定的免费GPU额度,这个方式省钱,但是不推荐,因为有时需要为平台推广拉人,也挺耗时间的。
ChatGLM3-6B部署
ChatGLM-6B目前已经发展到第3代ChatGLM3-6B,除了中英文推理,还增强了数学、代码等推理能力,我记得一年前的6B在代码或者数学方面是比较弱的。根据目前的官方信息,在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base在10B以下的基础模型中性能是最强的,除此之外,还具有8K、32K、128K等多个长文理解能力版本。下面我们就一步一步来安装部署ChatGLM3-6B,你也可以在官方文档里找到安装教程。
准备环境
操作系统推荐Linux环境,如Ubuntu或者CentOS。

- Python推荐3.10~3.11版本。
- Transformers库推荐4.36.2版本。
- Torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
克隆代码
安装依赖
注意:要切换成国内pip源,比如阿里云,下载会快很多。
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
cd ChatGLM3
pip install -r requirements.txt
显示以下内容表明依赖安装成功。
下载模型
如果Huggingface下载比较慢的话,也可以选择ModelScope进行下载。下载完将chatglm3-6b文件夹重新命名成model并放在ChatGLM3文件夹下,这一步非必需,只要放在一个路径下,在下一步提示的文件里,指定好模型文件路径即可。
命令行模式启动
打开文件 basic_demo/cli_demo.py,修改模型加载路径。
执行 python cli_demo.py。
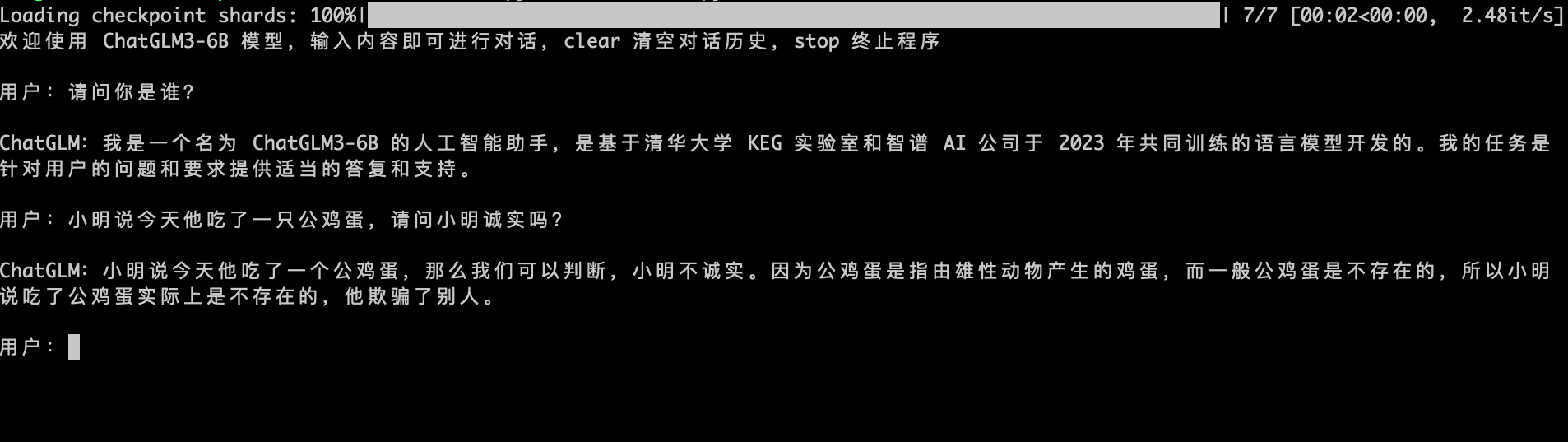
Web控制台模式启动
打开文件 basic_demo/web_demo_gradio.py,修改模型加载路径。
同时修改最后一行:
server_name修改为本地IP,并指定端口server_port即可。也可以设置share=True,使用gradio提供的链接进行访问。
执行 python web_demo_gradio.py。
默认情况下,模型以FP16精度加载,大概需要13GB显存。如果你的电脑没有GPU,只能通过CPU启动,6B也是支持的,需要大概32G的内存。我们修改一下模型加载脚本。
如果你的电脑有GPU,但是显存不够,也可以通过修改模型加载脚本,在4-bit量化下运行,只需要6GB左右的显存就可以进行流程推理。
同时,官方也提供了一个全新的web demo,支持Chat、Tool、Code Interpreter,就在我们克隆下来的代码里,在文件夹composite_demo下。
cd composite_demo
pip install -r requirements.txt
export MODEL_PATH=../model
streamlit run main.py 或者 python -m streamlit run main.py
页面确实上了一个档次。
接下来我简单总结一下部署过程:
- 安装Python环境,包含pip;
- 下载代码;
- 下载模型;
- 安装依赖;
- 修改示例代码,指定模型路径、精度等参数;
- 命令行启动。
整体来说,如果Python版本在3.10~3.11之间,网络环境也没问题的话,安装还是很快的,如果有GPU的话,推理效果也是很好的。在我们部署好模型之后,就可以进行推理了。推理之前,6B有几个参数可以进行设置,就是超参数,用来控制模型的推理准确度,我们知道大模型推理每次给的回答可能都和之前不一样,这也是为什么大模型不能用来处理精确度要求很高的任务的原因,比如让大模型算个税、算工资等等。
超参数介绍
ChatGLM3-6B有3个参数可以设置。
- max_length:模型的总token限制,包括输入和输出的tokens。
- temperature:模型的温度。温度只是调整单词的概率分布。它最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。数字越小,给出的答案越精确。
- top_p:模型采样策略参数。每一步只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的词。只关注概率分布的核心部分,忽略了尾部。
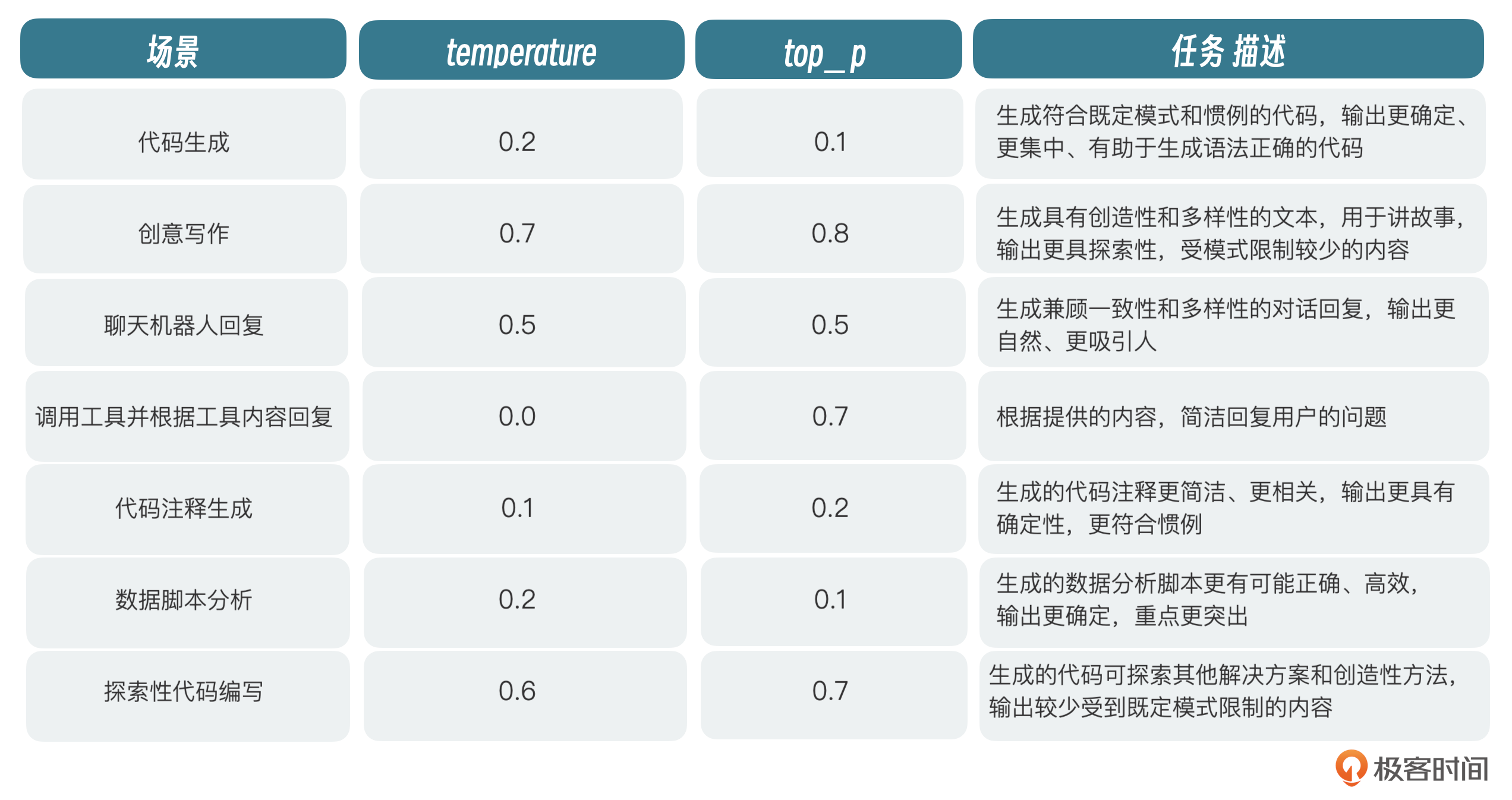
对于以下场景,官方推荐使用这样的参数进行设置:
系统设置好,我们基本就可以开始进行问答了,ChatGLM3-6B采用了一种新的Prompt格式,看上去应该是模仿的ChatGPT。下面我们介绍下这种提问格式。
新的Prompt格式
新的提示格式,主要是增加了几个角色,在对话场景中,有且仅有以下三种角色。
- system:系统信息,出现在消息的最前面,可以指定回答问题的角色。
- user:我们提的问题。
- assistant:大模型给出的回复。
在代码场景中,有且仅有user、assistant、system、observation四种角色。observation是外部返回的结果,比如调用外部API,代码执行逻辑等返回的结果,都通过observation返回。observation必须放在assistant之后。
下面这个是官方提供的例子,基本把以上4种角色都解释清楚了。
<|system|>
Answer the following questions as best as you can. You have access to the following tools:
[
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string"},
},
"required": ["location"],
},
}
]
<|user|>
今天北京的天气怎么样?
<|assistant|>
好的,让我们来查看今天的天气
<|assistant|>get_current_weather
```python
tool_call(location="beijing", unit="celsius")
<|observation|>
{"temperature": 22}
<|assistant|>
根据查询结果,今天北京的气温为 22 摄氏度。
为什么会这么设计呢?
首先,当前阶段的大模型经过训练后,都可以遵守系统消息,而系统消息不算用户对话的一部分,与用户是隔离的,但是可以控制模型与用户交互的范围,比如我们在system角色里指定模型充当Java技术专家,那么就可以指导模型的输出偏向于Java技术范围。
还有一个原因就是防止用户进行输入注入攻击。在进行多轮对话的时候,每次新的对话都会把历史对话都带进去。如果我们在前面的对话中,告诉模型错误的提示,那么这些错误的提示会在后续的对话中被当作正确的上下文带进去。我们知道基于自回归的模型,会根据上下文进行内容推理,这样就可能生成错误的内容。角色可以使内容更加容易区分,增加注入攻击的复杂度。这种方式不一定能处理所有的攻击类型,类似于我们日常开发中的XSS注入,只能尽可能减少,完全避免有点难。
小结
这节课我们学习了如何部署6B。从模型的选择到环境配置再到模型启动、推理,整体来说已经比较全面了,如果你在实际操作的过程中遇到环境问题,可以自己Google一下尝试去解决。毕竟每个人的环境不一样,可能会遇到各种各样的问题,主要还是Python相关的多一些。如果这一节课有些内容你没有看懂也不用急,先把模型部署及推理这一块熟悉一下,后面我们会逐渐深入地讲解。
思考题
我们知道ChatGLM3-6B是一个具有62亿参数规模的大语言模型,那你知道大模型的参数是什么意思吗?62亿表示什么?欢迎你把你的观点分享到评论区,我们一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 徐石头 👍(15) 💬(1)
1. 网络问题,可以用国内的地址,https://gitee.com/mirrors/chatglm3和 https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git,注意不要用 hf 的,模型不全报错 2. 显卡驱动问题,需要把N 卡驱动最低升级到11.8,要先卸载干净旧驱动,再升级。 3. chatglm 如果没有找到 GPU,就会使用 CPU 运算,响应速度会非常慢,用 TOP 查看 CPU 使用率 4. 注意 cuda 版本和pytorch的版本一定要匹配,这里我踩了坑
2024-06-17 - 张 ·万岁! 👍(8) 💬(1)
现在是24年7月15,刚刚结束这个模型部署模块。我使用的是阿里云的PAI平台,如果有人和我一样希望我能帮到你们。 1.git clone https://github.com/THUDM/ChatGLM3换成git clone https://gitee.com/mirrors/chatglm3。因为阿里云不支持HF 2.下载模型不要用git clone https://huggingface.co/THUDM/chatglm3-6b,我尝试过各种各样的lfs,都不好用。先pip install modelscope,然后使用python代码from modelscope import snapshot_download model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0"),他会下载到cache区,使用linux基本指令移过来就好 3.MODEL_PATH = os.environ.get('MODEL_PATH', '../model')这里,一定要用绝对地址!!!! 4.UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 24: invalid continuation byte如果有编码问题,命令行改编码export LANGUAGE=en_US.UTF-8,因为他一开始是zh_CN.UTF-8,一定要改成en_US.UTF-8。输入locale检查一下,确保都是en_US.UTF-8 5.使用综合web那个案例中,记得去client中改一下# MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b') MODEL_PATH = os.environ.get('MODEL_PATH', '/mnt/workspace/modelscope/hub/ZhipuAI/chatglm3-6b') 而且,这里transformers和huggingface_hub版本不能太高,我的transformer是4.30.2,huggingface_hub是0.19.0
2024-07-15 - 微笑的向日葵 👍(5) 💬(2)
我本地跑起来了 redmi G 2020 Windows 环境 , 显卡: RTX 3060 laptop 参考 的是 https://www.bilibili.com/video/BV1ce411J7nZ/?p=33&spm_id_from=pageDriver&vd_source=c16aa13fad5b13a7c51efcfcad58e883 https://www.bilibili.com/read/cv29866295/ 很详细
2024-07-06 - Geek_6bdb4e 👍(3) 💬(1)
国产也能成为推荐理由吗
2024-06-12 - Eleven 👍(2) 💬(1)
大模型的参数指的是在模型训练过程中需要学习和确定的变量或数值。这些参数决定了模型如何处理输入数据并生成相应的输出。在深度学习和自然语言处理领域,模型的参数数量通常与模型的复杂性和功能强大程度有关。
2024-06-12 - Geek_5203b4 👍(2) 💬(1)
学习打卡~想请教老师一个问题,temperature和top_p对生成的结果影响大吗?如何测试到最佳的数值呢?谢谢老师!
2024-06-12 - go home 👍(1) 💬(1)
爲什麽不用LLaMA3呢,它在推理上面更加具有優勢。
2024-08-24 - 阿斯蒂芬 👍(1) 💬(1)
「如果你的电脑有 GPU,但是显存不够,也可以通过修改模型加载脚本,在 4-bit 量化下运行,只需要 6GB 左右的显存就可以进行流程推理。」如果没有GPU呢,怎么跑量化? win本,32G mem,纯cpu 跑还是挺吃力的,速度慢到怀疑人生。今天折腾了下使用 chatglm.cpp 成功部署了量化版,速度杠杠滴。
2024-07-06 - Eleven 👍(1) 💬(5)
RuntimeError: Internal: could not parse ModelProto from ../model/tokenizer.model
2024-06-14 - 张申傲 👍(1) 💬(1)
第4讲打卡~ 关于思考题,问了下ChatGPT,回答如下: 大模型的参数指的是模型中的可调整的变量,这些变量决定了模型如何处理输入数据并生成输出。在人工智能和机器学习中,参数是模型学习和适应新数据的关键部分。常见的参数如权重(w)和偏置(b)。
2024-06-12 - Geek_0a4616 👍(0) 💬(1)
老师 大模型 最终推理出来的是个数字,数字和词汇的映射关系 是存在权重文件 https://huggingface.co/THUDM/chatglm3-6b 里面的吗?
2024-09-22 - 赵鹏 👍(0) 💬(1)
pip3 install -r requirements.txt 执行报错,日志如下,请问如何解决?谢谢! ERROR: Command errored out with exit status 1: command: /Library/Developer/CommandLineTools/usr/bin/python3 /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/pip/_vendor/pep517/in_process/_in_process.py get_requires_for_build_wheel /var/folders/d_/zyrnlk3j65l1rrm5vlz_khnm0000gn/T/tmpi1loqnkg cwd: /private/var/folders/d_/zyrnlk3j65l1rrm5vlz_khnm0000gn/T/pip-install-axuijjbp/vllm_bde8e7d4069844fcbf5e5312fb56958f Complete output (20 lines): fatal: not a git repository (or any of the parent directories): .git setup.py:56: RuntimeWarning: Failed to get commit hash: Command '['git', 'rev-parse', 'HEAD']' returned non-zero exit status 128. embed_commit_hash() Traceback (most recent call last): File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 349, in <module> main() File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 331, in main json_out['return_val'] = hook(**hook_input['kwargs']) File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 117, in get_requires_for_build_wheel return hook(config_settings) File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/setuptools/build_meta.py", line 154, in get_requires_for_build_wheel return self._get_build_requires( File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/site-packages/setuptools/build_meta.py", line 135, in _get_build_requires
2024-08-02 - 废物点心的黄金时代 👍(0) 💬(1)
为啥不直接用ollama部署本地模型呢?
2024-07-27 - Twein 👍(0) 💬(1)
执行pip install -r requirements.txt报错:Getting requirements to build wheel ... error error: subprocess-exited-with-error × Getting requirements to build wheel did not run successfully. │ exit code: 1 ╰─> [20 lines of output] Traceback (most recent call last): File "D:\tools\python\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module> main() File "D:\tools\python\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main json_out['return_val'] = hook(**hook_input['kwargs']) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\tools\python\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel return hook(config_settings) ^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\twein\AppData\Local\Temp\pip-build-env-y57aktmf\overlay\Lib\site-packages\setuptools\build_meta.py", line 327, in get_requires_for_build_wheel return self._get_build_requires(config_settings, requirements=[]) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\twein\AppData\Local\Temp\pip-build-env-y57aktmf\overlay\Lib\site-packages\setuptools\build_meta.py", line 297, in _get_build_requires self.run_setup() File "C:\Users\twein\AppData\Local\Temp\pip-build-env-y57aktmf\overlay\Lib\site-packages\setuptools\build_meta.py", line 313, in run_setup exec(code, locals()) File "<string>", line 12, in <module> File "C:\Users\twein\AppData\Local\Temp\pip-build-env-y57aktmf\overlay\Lib\site-packages\torch\__init__.py", line 143, in <module> raise err OSError: [WinError 126] 找不到指定的模块。 Error loading "C:\Users\twein\AppData\Local\Temp\pip-build-env-y57aktmf\overlay\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.
2024-07-23 - 黄蓉 Jessie 👍(0) 💬(3)
MAC M2 pro的电脑安装ChatGLM3的依赖报错, AssertionError: vLLM only supports Linux platform (including WSL).应该是vllm这个包不支持
2024-07-22