05 大模型微调:如何基于ChatGLM3 6B+Lora构建基本法律常识大模型?
你好,我是独行。
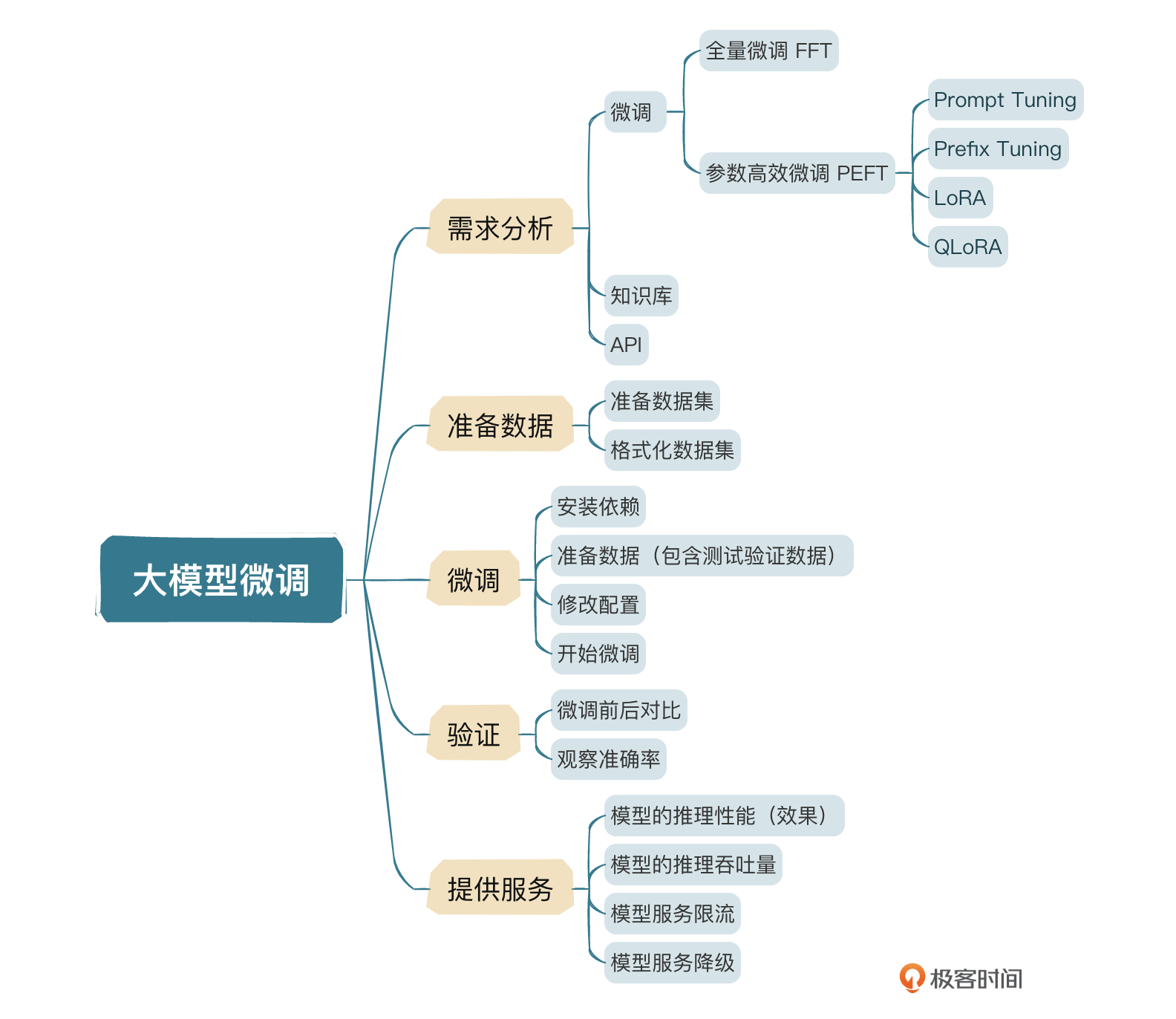
上节课我们本地化部署了ChatGLM3-6B,对于大模型有了进一步的了解。这节课我会从实际需求出发,完整地讲解一个AI大模型需求,从提出到完整落地的过程,学完这节课的内容,你也可以在自己所在的企业进行AI大模型落地实践了。
目前我们接触的无论是千亿大模型,如130B、ChatGPT,还是小规模的大模型,如6B、LLaMA2,都是通用大模型,就是说通过通用常识进行预训练的,如果我们在实际使用过程中,需要大模型具备某一特定领域知识的能力,我们就需要对大模型进行能力增强,具体如何做呢?
如何增强模型能力?
微调是其中的一个方法,当然还有其他方式,比如外挂知识库或者通过Agent调用其他API数据源,下面我们详细介绍下这几种方式的区别。
- 微调是一种让预先训练好的模型适应特定任务或数据集的方案,成本相对较低,这种情况下,模型会学习训练者提供的微调数据,并且具备一定的理解能力。
- 知识库使用向量数据库或者其他数据库存储数据,为大语言模型提供信息来源外挂。
- API 和知识库类似,为大语言模型提供信息来源外挂。
简单理解,微调相当于让大模型去学习一门新的学科,在回答的时候进行闭卷考试,知识库和API相当于为大模型提供了新学科的课本,回答的时候进行开卷考试。几种模式并不冲突,我们可以同时使用几种方案来优化模型,提升内容输出能力,下面我简单介绍下几种模式的优缺点。
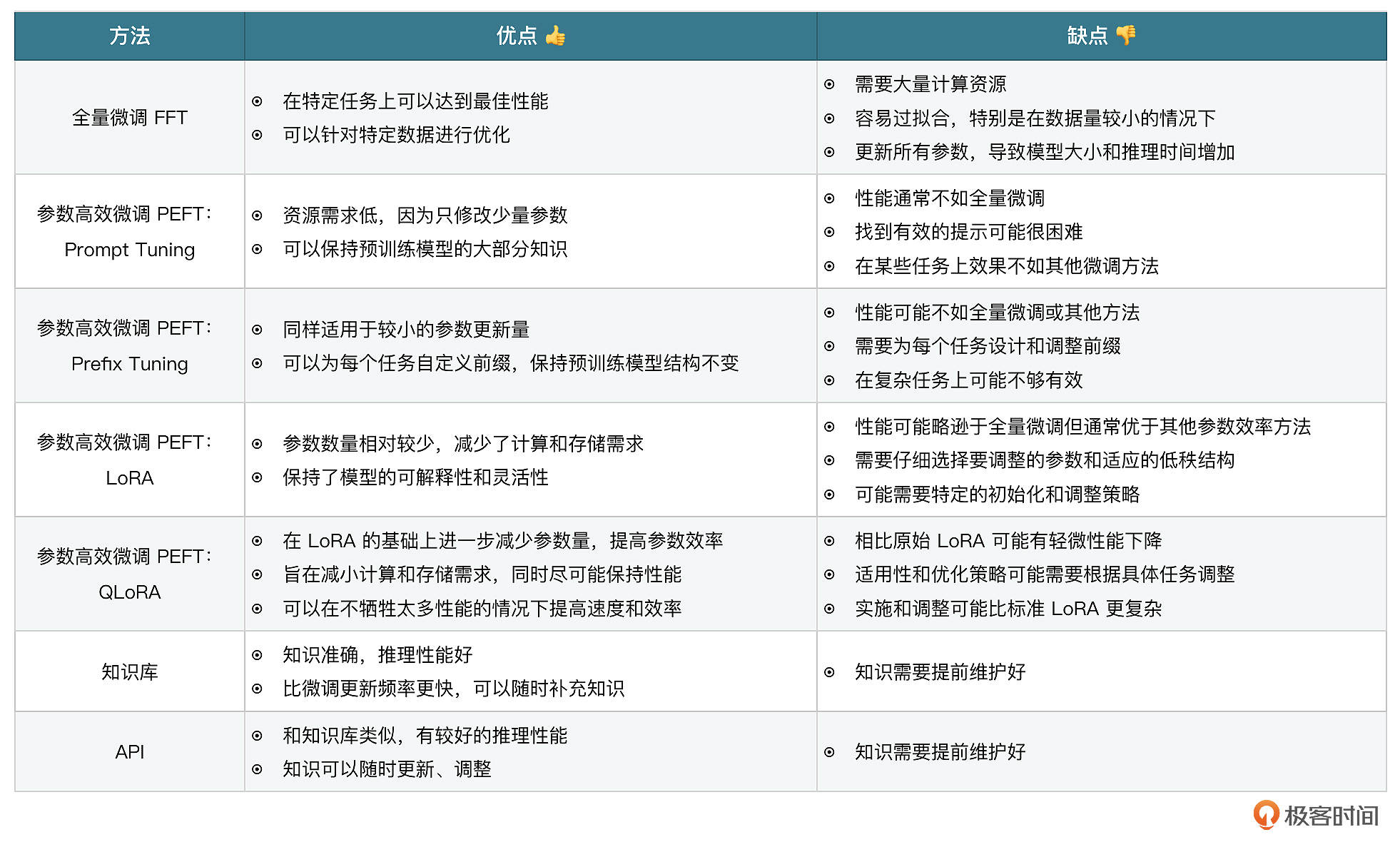
注意,大模型领域所谓的性能,英文原词是Performance,指推理效果,并非我们软件开发里所说的接口性能,比如响应时间、吞吐量等。
了解这几种模型的区别,有助于我们进行技术方案选型。在大模型实际落地过程中,我们需要先分析需求,然后确定落地方式。
- 微调:准备数据、微调、验证、提供服务。
- 知识库:准备数据、构建向量库、构建智能体、提供服务。
- API:准备数据、开发接口、构建智能体、提供服务。
接下来我会通过一个真实的案例,把整个过程串起来。
企业真实案例
在ChatGPT火爆以后,很多公司都在想办法将AI大模型引入日常工作中,一方面嵌入到产品中,提升产品的竞争力;一方面引入到企业内部,提升员工工作效率。就拿企业内部助手来说,它有很多使用场景,比如文案生成、PPT写作、生活常识等等。这里我们举一个法律小助手的例子。一般来说,当我们确定场景后,首先进行的就是需求分析,因为有些场景不一定是AI场景,有些是AI场景,但是可能可以通过小模型解决,所以我们在实际需求落地的过程中,一定要先进行完整的需求分析。
需求分析
法律小助手用来帮助员工解决日常生活中遇到的法律问题,以问答的方式进行,这种场景可以使用知识库模式,也可以使用微调模式。使用知识库模式的话,需要将数据集拆分成一条一条的知识,先放到向量库,然后通过Agent从向量库检索,再输入给大模型,这种方式的好处是万一我们发现数据集不足,可以随时补充,即时生效。
还有一种方式就是进行微调,因为法律知识有的时候需要一定的逻辑能力,不是纯文本检索,而微调就是这样的,通过在一定量的数据集上的训练,增加大模型法律相关的常识及思维,从而进行推理。经过分析,我们确定下来,使用微调的方式进行。接下来就是准备数据了。
准备数据
准备数据有很多种,可以从公共数据集下载,然后进行调整并加入私有化的知识,也可以完全自己整理,为了便于展示,我从GitHub上面找了一个公开的数据集,下载下来的是一个CSV格式的文件。官方给的微调数据格式如下:
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿到夏天也很舒适。"}]}
现在我们需要把CSV里的内容,转成官方要求的格式。转化代码我直接让ChatGPT帮我生成,用了如下提示:
原始数据是CSV格式,包含4列:title、question、reply、is_best,需要通过Python语言处理该CSV文件,来构建大语言模型的微调数据集,目标数据集格式是JSON的,单条数据格式为:{"conversations":[{"role":"user","content":"value1"},{"role":"assistant","content":"value2"}]},需要将原始CSV文件里的title列填充到目标JSON文件里的value1处,原始CSV文件里的reply填充到目标JSON文件里的value1处,请注意:最终生成的不是JSON数组,而是每个JSON对象生成一行,出示示例代码。
ChatGPT生成的Python代码:
import csv
import json
# CSV文件的路径
csv_file_path = 'your_csv_file.csv'
# 输出JSON文件的路径
json_file_path = 'output_json_file.json'
# 打开CSV文件,并进行处理
with open(csv_file_path, mode='r', encoding='utf-8') as csv_file, \
open(json_file_path, mode='w', encoding='utf-8') as json_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
# 根据CSV文件的列名获取数据
title = row['title']
reply = row['reply']
# 构造单条对话的JSON结构
conversation_entry = {
"conversations": [
{"role": "user", "content": title},
{"role": "assistant", "content": reply}
]
}
# 将单条记录以JSON格式写入文件,每条记录一行
json_line = json.dumps(conversation_entry, ensure_ascii=False)
json_file.write(json_line + '\n')
通过上面的代码,我们就可以成功将下载下来的CSV格式的数据集,格式化成微调所需的数据集。接下来就可以准备微调了。
微调
- 安装依赖
我们先进入到finetune_demo文件夹。执行 pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple,过程中报了一个错。
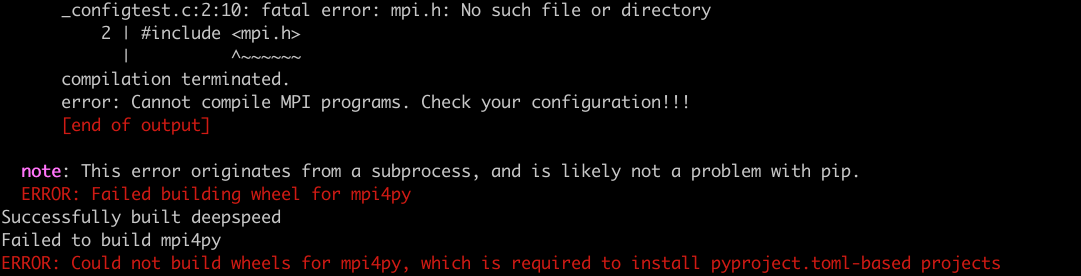
原因是缺少libopenmpi-dev库,所以我们需要安装这个库。
紧接着安装nltk库。
到这里,依赖包基本就安装完了。你在操作的过程中,如果遇到其他库的缺失,有可能是操作系统库也有可能是Python库,按照提示完成安装即可。
- 准备数据
训练需要至少准备两个数据集,一个用来训练,一个用来验证。我们把“准备数据”环节格式化好的文件命名为train.json,再准备一个相同格式的测试数据集dev.json,在里面添加一些测试数据,几十条即可,当大模型在训练的过程中,会自动进行测试验证,输出微调效果。然后在finetune_demo文件夹下建立一个data文件夹,将这两个文件放入data文件夹中。
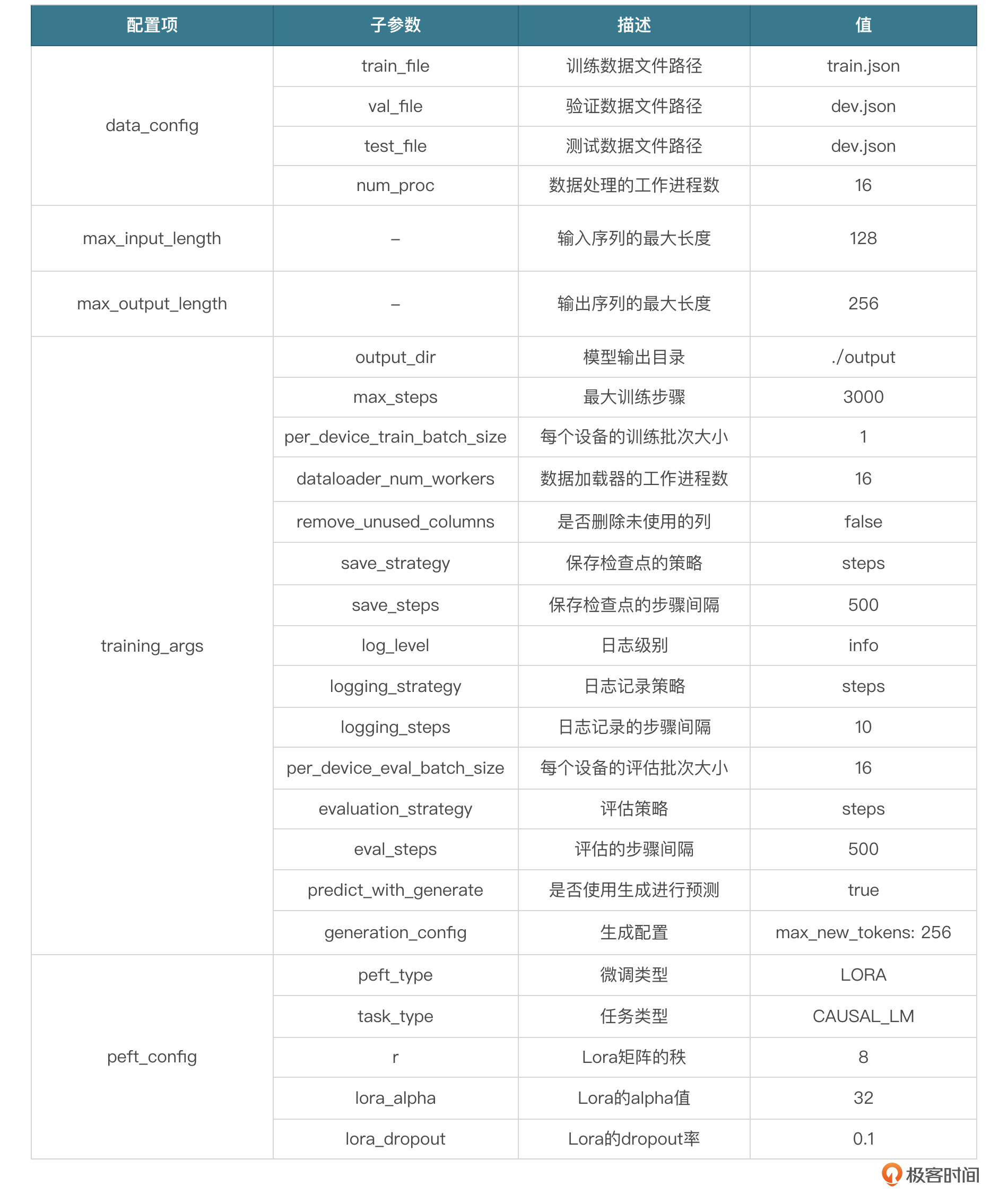
- 修改配置
修改finetune_demo/configs下的lora.yaml文件,将train_file、val_file、test_file、output_dir定义好,记得写全路径,其他参数也可以按需修改,比如:
- max_steps:最大训练轮数,我们填3000。
- save_steps:每训练多少轮保存权重,填500。
其他参数可以参考下面这张表格。
- 开始微调
如果数据量比较少的话,比如少于50行,注意这一行,会报数组越界,修改小一点即可。
微调脚本用的是finetune_hf.py。
- 第一个参数是训练数据集所在目录,此处值是 data。
- 第二个参数是模型所在目录,此处值是 ./model。
- 第三个参数是微调配置,此处值是 configs/lora.yaml。
执行微调命令,记得Python命令使用全路径。
如果控制台输出下面这些内容,则说明微调开始了。
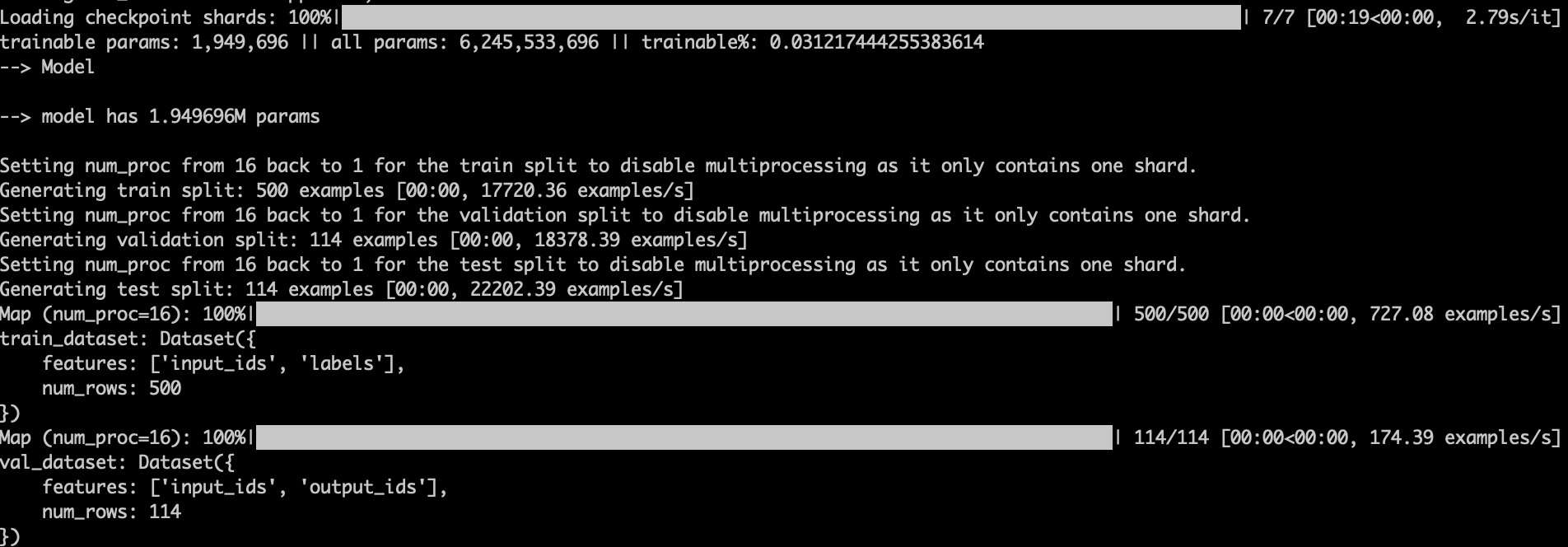
trainable params指的是在模型训练过程中可以被优化或更新的参数数量。在深度学习模型中,这些参数通常是网络的权重和偏置。它们是可训练的,因为在训练过程中,通过反向传播算法这些参数会根据损失函数的梯度不断更新,以减小模型输出与真实标签之间的差异。通过调整lora.yaml配置文件里peft_config下面的参数 r 来改变可训练参数的数量,r值越大,trainable params越大。
我们这次微调trainable params为1.9M(190万),整个参数量是6B(62亿),训练比为3%。
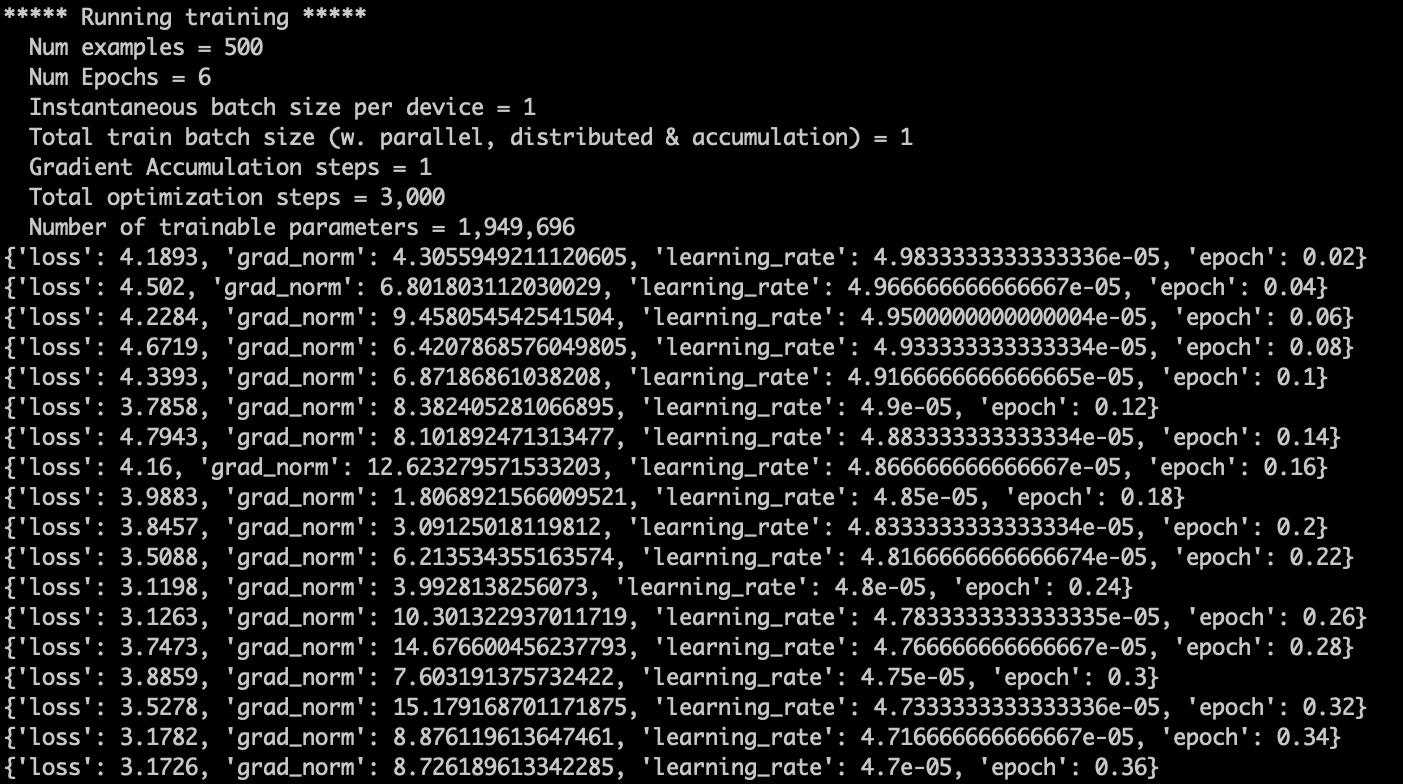
这里有几个参数我来简单讲解下。
- loss:损失函数衡量模型预测的输出与实际数据之间的差异或误差。在训练过程中,目标是最小化这个损失值,从而提高模型的准确性。
- grad_norm(梯度范数):在训练深度学习模型时,通过反向传播算法计算参数(如权重)的梯度,以便更新这些参数。梯度范数是这些梯度向量的大小或长度,它提供了关于参数更新幅度的信息。如果梯度范数非常大,可能表示模型在训练过程中遇到了梯度爆炸问题;如果梯度范数太小,可能表示存在梯度消失问题。
- learning_rate(学习率):学习率是一个控制参数更新幅度的超参数。在优化算法中,学习率决定了在反向传播期间参数更新的步长大小。太高的学习率可能导致训练过程不稳定,而太低的学习率可能导致训练进展缓慢或陷入局部最小值。
- epoch(周期):一个 epoch 指的是训练算法在整个训练数据集上的一次完整遍历。通常需要多个 epochs 来训练模型,以确保模型能够充分学习数据集中的模式。每个 epoch 后,通常会评估模型在验证集上的表现,以监控和调整训练过程。

验证
等待微调结束,就可以进行验证了,官方demo提供了验证脚本,执行如下命令:
output/checkpoint-3000是指新生成的权重,模型启动的时候会将原模型和新权重全部加载,然后进行推理。–prompt是输入的提示。
下面是一组微调前后的对比问答,我们对比着来看一下。
【微调前】
User:不交房电费多出由谁承担?法律法规第几条 ChatGLM:这个问题先要明确是哪一种房屋。如果是商业用房,交房后产生的费用一般是由开发商来处理的;如果是住宅用电,那么就属于个人日常用水产生的费用了。如果是因为开发商的过错造成,可以要求开发商进行赔偿,反之也是一样。建议查阅合同以及相关法律条文,也可以向当地的水管公司或者开发商进行咨询。
【微调后】
User:不交房电费多出由谁承担?法律法规第几条? ChatGLM:协商解决,协商不成可诉讼。
我们的微调数据集中有下面这条内容:
{"conversations": [{"role": "user", "content": "不交房电费多出由谁承担?法律法规第几条?"}, {"role": "assistant", "content": "按照约定处理,协商不成可以委托律师处理。"}]}
部分回答效果是比较明显的。
当然,这里只是通过快速搭建一个demo向你展示Lora微调的细节。实际生产过程中,需要考虑的事情比较多,比如训练轮数、并行数、微调效果比对等一系列问题,需要我们根据实际情况进行调整。
提供服务
当微调完成,我们验证后得知整体效果满足一定的百分比,那我们就认为这个微调是有效的,可以对外服务,接下来就可以通过API组件将模型的输入输出封装成接口对外提供服务了。实际生产环境中,我们还需要考虑几件事情:
- 模型的推理性能(效果);
- 模型的推理吞吐量;
- 服务的限流,适当保护大模型集群;
- 服务降级,当大模型服务不可用的时候,可以考虑通过修改开关,将AI小助手隐藏暂停使用。
具体架构思路,后面第四章我会进行专门的讲解,到那时我们再详细学习具体内容。
小结
这节课我们通过一个微调案例,来学习一下真正企业在布局AI大模型过程中,到底该怎么做,怎么进行大模型私有化的落地。
其中模型能力增强有几个重要的策略:微调、外挂知识库和 API 调用等。每种方法并不是唯一的,在实际生产环境中,我们可以采用多个方法来增强模型的推理能力。
为了让你熟悉大模型微调整个操作流程,我通过一个法律小助手的案例,展示了需求分析、数据准备、微调训练、模型验证到提供服务的每一步操作,以及在实际操作中可能遇到的问题和解决方案。在这个过程中你还可以通过微调前后的问答对比,看到模型微调后的效果。
相信学完这节课的内容,你对大模型微调有了一定的了解,不过前面我们也提到了增强模型能力的方法除了微调之外还有很多,下节课我们就来看看怎么用知识库,来增强大模型信息检索的能力。
思考题
在实际微调过程中我们发现微调不是轮数越多越好,有时轮数低产生的权重会比轮数高产生的权重效果更好,你可以想想这是为什么?欢迎你把你的想法分享在评论区,我们一起交流讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 张申傲 👍(16) 💬(1)
第5讲打卡~ 思考题:微调效果应该也和数据量关系很大吧?如果在小数据量下,训练的轮数过多,是不是会降低大模型的泛化能力?就类似人的学习过程,如果把一本没有营养的书反复看了很多遍,反而容易形成思维定式,降低抽象能力。
2024-06-15 - 冰冻柠檬 👍(3) 💬(1)
轮数过多就过拟合了啊,泛化能力自然不会好。
2024-06-14 - Geek_frank 👍(2) 💬(2)
打卡第五课。微调轮数过高不利于提升模型的泛化能力。但这个感觉也不好把控。所以有什么最佳实践之类的吗。比如先把参数调小一点。然后经过多次微调调整参数来使模型推理达满意的准确度
2024-07-01 - jsw 👍(2) 💬(1)
微调可以了,调整了一些参数,原理的没有按老是的修改。但是感觉微调后的效果很差。
2024-06-21 - jsw 👍(1) 💬(2)
原始数据是CSV格式,包含4列:title、question、reply、is_best,需要通过Python语言处理该CSV文件,来构建大语言模型的微调数据集,目标数据集格式是JSON的,单条数据格式为:{"conversations":[{"role":"user","content":"value1"},{"role":"assistant","content":"value2"}]},需要将原始CSV文件里的title列填充到目标JSON文件里的value1处,原始CSV文件里的reply填充到目标JSON文件里的value1处,请注意:最终生成的不是JSON数组,而是每个JSON对象生成一行,出示示例代码。 ----- 原始CSV文件里的reply填充到目标JSON文件里的value1处,这里应该是“value2”才对吧。
2024-06-21 - 阿斯蒂芬 👍(1) 💬(2)
需要业务逻辑特别是一定业务推理能力的时候,微调应该是比纯知识向量检索更合适的。大模型时代,“面向微调”在一定程度上让非资深算法人员也有了“训练模型”的可能😁
2024-06-19 - Geek_999422 👍(0) 💬(1)
请问老师这个案例的目标输出是什么呢?
2025-01-06 - like life 👍(0) 💬(1)
“学习率是一个控制参数更新幅度的超参数。在优化算法中,学习率决定了在反向传播期间参数更新的步长大小。太高的学习率可能导致训练过程不稳定,而太低的学习率可能导致训练进展缓慢或陷入局部最小值”,训练轮数太多,学习率是不是可能会更高导致训练过程不稳定呢?
2024-11-08 - 艾尔·马格尼弗科 👍(0) 💬(1)
File "/home/naiqi/.cache/huggingface/modules/transformers_modules/model/modeling_chatglm.py", line 685, in get_masks past_length = past_key_values[0][0].shape[0] ^^^^^^^^^^^^^^^^^^^^^^^^^^^ AttributeError: 'str' object has no attribute 'shape' 老师,这种情况该怎么办呢
2024-09-10 - 吧啦啦能量 👍(0) 💬(1)
老师,这种情况该怎么办呢OutOfMemoryError: CUDA out of memory. Tried to allocate 214.00 MiB. GPU
2024-08-20 - 石云升 👍(0) 💬(1)
好课程,学到了。
2024-08-03 - 夏龙飞 👍(0) 💬(1)
准备数据的时候只有train.json和dev.json,但是后边的config中train_file、val_file、test_file有三个,这个怎么设置?
2024-07-09 - Standly 👍(0) 💬(1)
文章里多次提到的“反向传播”是什么意思?
2024-07-01 - jsw 👍(0) 💬(2)
微调老是报这个错误 OutOfMemoryError: CUDA out of memory. Tried to allocate 64.00 MiB. GPU RTX 3090(24GB) 的配置应该够吧,有什么办法调低内存占用吗?
2024-06-21 - 徐石头 👍(0) 💬(2)
默认情况下 chatglm3-6b 的微调需要 23G 左右的显存,而且启动运行只需要12G
2024-06-17