08 关于机器学习,你需要了解的基本概念(一)
你好,我是独行。
前面我们已经完整体验了大模型的相关技术,可以把大模型简单地运行起来辅助业务了。但是如果我们想要进行更复杂的使用,比如训练、全参数微调等,那以目前的技术和能力还是不够的,我们还需要进一步掌握一些内部的技术原理。
对比软件开发来说,目前我们仅仅是把一个开源的软件在自己的服务器环境里跑了起来,并且可以简单做一些配置和开发,如果想真正进行二次开发,或解决实际运行中遇到的问题,我们必须去了解软件的运行原理,甚至去阅读源代码。
从这一章开始,我会向你介绍大模型底层用到的一些技术和原理,虽然网上关于这类技术的教程和文章很多,但是我会以软件开发人员能够理解的方式去介绍,方便你理解,快速掌握。这节课我主要会讲解一下机器学习的基本概念和常用的一些算法。我们先来了解下什么是机器学习。
机器学习
通俗来讲,机器学习(Machine Learning,ML)就是让计算机利用数据来“学习”如何完成任务。和传统编程不同,你需要明确地告诉计算机每一步怎么做,机器学习允许计算机通过分析和学习数据来自我改进及作出决策。
我们先看一个简单的例子,假设我们想要预测一个地区的房价。在这个场景中,我们的数据集可能包含很多房屋的信息,比如面积、卧室数量、地理位置等,以及每个房屋的售价。在传统编程中,你可能需要根据经验编写复杂的规则和公式来估算价格。但在机器学习中,我们让模型自己去“学习”这些规则。
我们使用Python和一个流行的机器学习库,如scikit-learn,来实现这一目标,代码可能会是这样的:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import pandas as pd
# 加载数据集
data = pd.read_csv("housing_data.csv") # 假设这是我们的房屋数据
# 准备数据
X = data[['面积', '卧室数量', '地理位置']] # 特征
y = data['售价'] # 目标变量
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用模型进行预测
predictions = model.predict(X_test)
# 现在,`predictions`包含了我们模型预测的房价
简单解释下,假设 housing_data.csv 的数据格式是这样的:
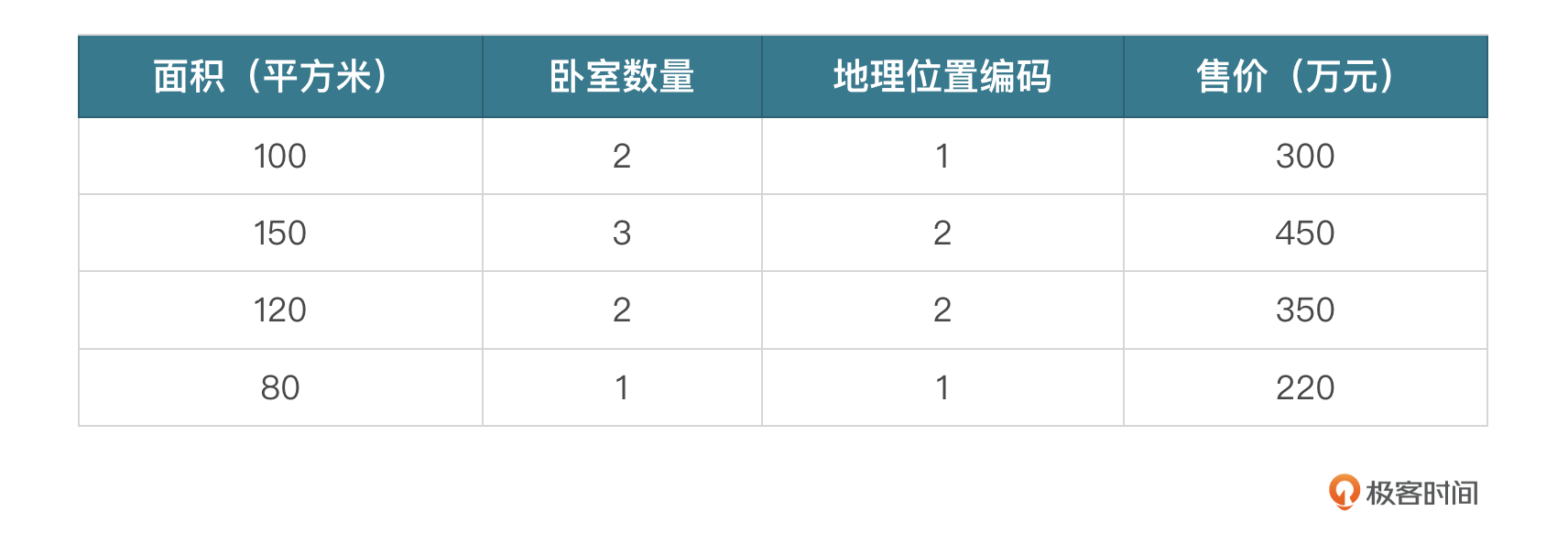
特征 x 是一个二维数组,包含了面积、卧室数量和地理位置编码这三列。值为:
目标 y 是一个一维数组,包含了“售价”这一列。值为 [300, 450, 350, 220]。
train_test_split 是一个非常实用的函数,来自于scikit-learn库。主要作用是将数据集分割成训练集和测试集两部分。训练集用于训练模型,而测试集用于评估模型的性能,以检查模型对于未见过的数据的泛化能力。
参数 test_size 表示测试集在整个数据集中所占的比例。例如,test_size=0.2 意味着20%的数据将被用作测试集,剩下的80%则作为训练集。参数 random_state 是一个整数,用于控制随机数生成器的状态,提供一个确切的值可以确保每次分割都是相同的。
这个例子展示了如何使用机器学习来从数据中学习规律,并应用这些规律来作出预测。在这个过程中,我们没有明确地告诉计算机如何计算房价;相反,计算机通过分析提供的数据自己学习了如何进行预测。机器学习的真正魅力在于它的广泛应用,从简单的任务(如预测房价)到复杂的任务(如自动驾驶汽车、语言翻译等),都有机器学习技术的身影。大语言模型实际是各种机器学习技术的叠加,其中比较重要的一项就是机器学习的重要分支:深度学习,也就是以神经网络为主要算法的学习技术。
深度学习
深度学习主要以深度神经网络(Deep Neural Networks, DNNs)为主,神经网络这种结构完全模拟人的大脑结构,由多层神经元组成。我们知道正常成年人的大脑有大约1000亿个神经元,每个神经元又和其他大约1000个神经元产生连接,每个连接就是我们说的突触,也就是说人的大脑大概有100万亿个突触。
我们平时所说的大模型的参数,其实就类似于突触,GPT-3有1750亿个参数,就是约1750亿个突触,除以1000的话,GPT-3大约有1.75亿个神经元,智商大约是正常成年人的0.175%,光从这些数据看,离人类智商还有一定差距。
不过据说OpenAI已经训练完成100万亿参数的GPT-x模型,这样的话,理论智商已经接近普通人,因为训练的效果,实际可能到不了人这么高,有人说和狗的智商差不多,对应IQ值大概在30~40,但是这仅仅是100万亿的参数,200万亿、300万亿呢?超过人类智商只是时间问题。
注:以上数据都是大约取值,不是精确取数。
深度学习强大之处在于它的深度神经网络,一个多层的神经网络结构,每一层都可以学习不同级别的特征,我们举一个识别图片中是否有猫的例子。
- 准备数据:包含训练集和测试集。
- 构建模型:在构建神经网络的时候,可以让前面的层学习边缘和纹理,更深的层则学习如何组合这些特征来识别更复杂的形状和对象,如猫的耳朵、鼻子等。
- 训练模型:通过输入成千上万张猫的图片来训练网络,通过调整内部参数(权重)使预测错误最小化。
- 评估和使用:训练完成后,可以用模型来对图片进行分类。
第二步和第三步会涉及多个层之间的信息处理,一般这些层被分为三种主要类型。
- 输入层:接收原始数据输入,例如图片的像素值。
- 隐藏层:多个层级,每一层都通过数学函数转换数据,逐步提取和学习数据的特征。较低层可能学习简单特征,如边缘和角点,而更深层则学习复杂特征,如对象的部分和整体结构。
- 输出层:根据学到的特征作出最终的预测或分类,例如判断图像中是猫还是狗。
在训练过程中,模型通过一种叫作反向传播的算法自动调整其内部参数(称为权重和偏差),来最小化模型的预测和实际结果之间的差异,整个过程通常需要大量的数据和计算资源。这是简单的介绍,后面我们会通过案例去不断深入理解和学习。
机器学习过程
了解了机器学习的基本概念后,我们来看看机器学习一般有哪些过程,从工程化角度,我梳理了10个步骤,从问题提出到模型上线及运维,算是比较全面的了。
1. 定义问题
明确你希望机器学习解决的问题。比如可能是一个分类问题(如区分图片中是猫还是狗),或者是一个回归问题(如预测房价),也有可能是一个聚类问题(如识别有相似需求的客户群体)。
2. 收集数据
数据是机器学习的基础。你需要收集足够多、质量好的数据,这些数据需要能够代表你试图解决的问题。数据可以通过各种方式获取,如公开数据集、公司内部数据、网络爬虫等。还记不记得我们前面讲过的GPT-3的训练数据集,大约45TB的公开数据,其中占比最大的一块是Common Crawl,大约占了60%,就是一个通过爬虫长期爬取的数据集。
3. 数据预处理
收集到的原始数据往往是杂乱无章的。数据预处理的目的是将这些数据转换成一种更适合机器学习算法处理的格式。这包括处理缺失值、异常值、数据标准化、特征选择等步骤。GPT-3的45TB的数据集,经过预处理,生成大概750GB的高质量数据。
4. 分割数据
将数据分为训练集和测试集(有时还有验证集)。训练集用于训练模型,测试集用于评估模型的性能。这样做的目的是检验模型对未知数据的泛化能力。我们上面讲的scikit-learn库的train_test_split函数,就是用来将数据集进行切割的函数,当然还有其他库的其他方法。
5. 选择模型
根据问题的类型和数据的特点选择合适的机器学习模型,下面列举一些常见的机器学习模型。
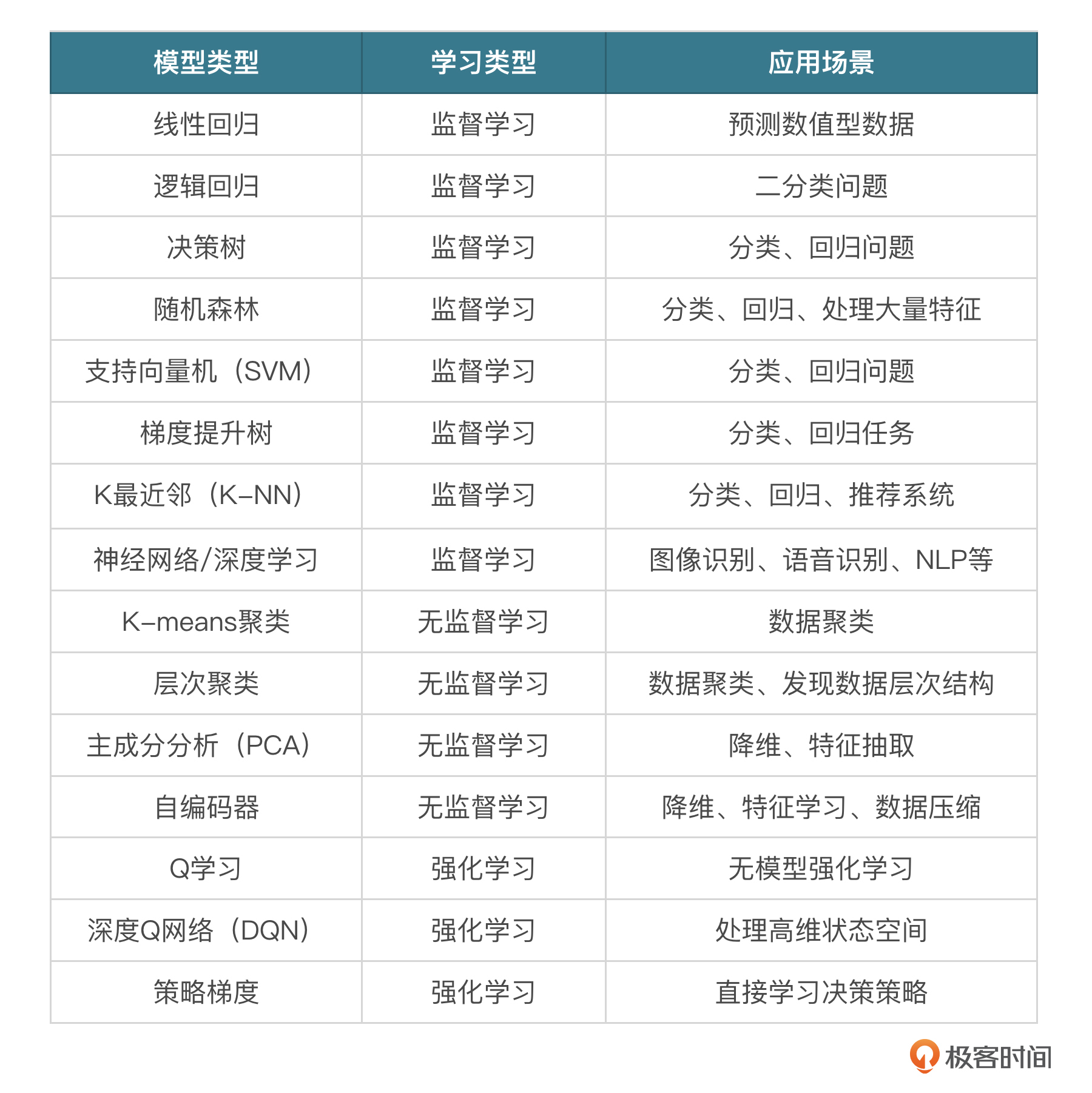
你先不用着急去理解,后面我会挑几个去讲解,慢慢地等整个课程学习下来,我们深入研究几个模型,其他的即便课程中没有涉及,你自己去学习也是能学懂的。
6. 训练模型
训练就是使用训练集数据训练选定的模型。整个过程中,模型会尝试学习数据中的规律和关系,以便在遇到新数据时能够作出准确的预测或分类。有时模型也会自动调整参数(权重),自动进行测试,并调整权重使效果最好,这个过程非常耗费资源,GPT-3单次训练成本高达近500万美金,一般每3个月训练一次,一年如果训练4次的话,光训练成本就接近1亿人民币了。
7. 评估模型
使用测试集数据评估模型的性能。常用的评估指标包括准确率、召回率、F1 分数等。评估过程可能会揭示模型的不足之处,需要回到前面的步骤进行调整。当然,我们经常看到各种各样的模型性能评估基准,有MMLU、CEval、GSM8K等。我们也会看到各大厂商会去刷这些基准测试的榜单。比如:

8. 参数调优和模型优化
根据模型在测试集上的表现,调整模型的参数或进行其他优化,以提高模型的性能。这个过程可能会反复进行多次,包含在训练、微调过程中。
9. 部署模型
当模型的推理效果达到预期值时,比如准确度超过xx%,我们就可以认为模型的效果是OK的,可以将其部署到实际应用中。部署后,模型将开始对真实的数据进行推理。
10. 监控和维护
在模型部署后,需要持续监控其性能,并根据新收集的数据定期进行维护和更新。这是因为随着时间的推移,数据的分布可能会发生变化,这种现象被称为概念漂移,可能会导致模型性能下降。模型维护部分的数据,可以是模型的开发者主动进行收集,也可以在公开的产品内由用户进行反馈,比如现在的大模型产品,ChatGPT、ChatGLM都有实时的用户反馈,这一招其实非常厉害,广泛收集用户的反馈进行学习。

经典算法
线性回归
线性回归是一种预测分析技术,用于研究两个或多个变量之间的关系。简单来说,它尝试用一条直线(在二维空间中)或一个平面(在三维空间中)等,尽可能地拟合这些变量间的数据点。这条直线或平面可以用来预测或估计一个变量基于另一个变量的值。
假设我们有一个因变量y和一个自变量x。线性回归会尝试找到一条直线y=ax+b,其中a是斜率,b是截距,以便这条直线尽可能地接近所有数据点。假设你想预测一个地区的房价。这里,房价是因变量y,而房屋的面积是自变量x。通过收集一些数据,我们可以用线性回归模型来预测房价。
下面是一个使用sklearn库进行线性回归的简单例子。假设我们有以下面积和价格的数据:
我们将使用这些数据来拟合一个线性回归模型,并预测面积为50平方米的房屋的价格。
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 定义数据
X = np.array([35, 45, 40, 60, 65]).reshape(-1, 1) # 面积
y = np.array([30, 40, 35, 60, 65]) # 价格
# 创建并拟合模型
model = LinearRegression()
model.fit(X, y)
# 预测面积为50平方米的房屋价格
predict_area = np.array([50]).reshape(-1, 1)
predicted_price = model.predict(predict_area)
print(f"预测的房价为:{predicted_price[0]:.2f}万美元")
# 绘制数据点和拟合直线
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X), color='red')
plt.title('房价预测')
plt.xlabel('面积(平方米)')
plt.ylabel('价格(万元)')
plt.show()
执行上面的代码,得到如下图像:
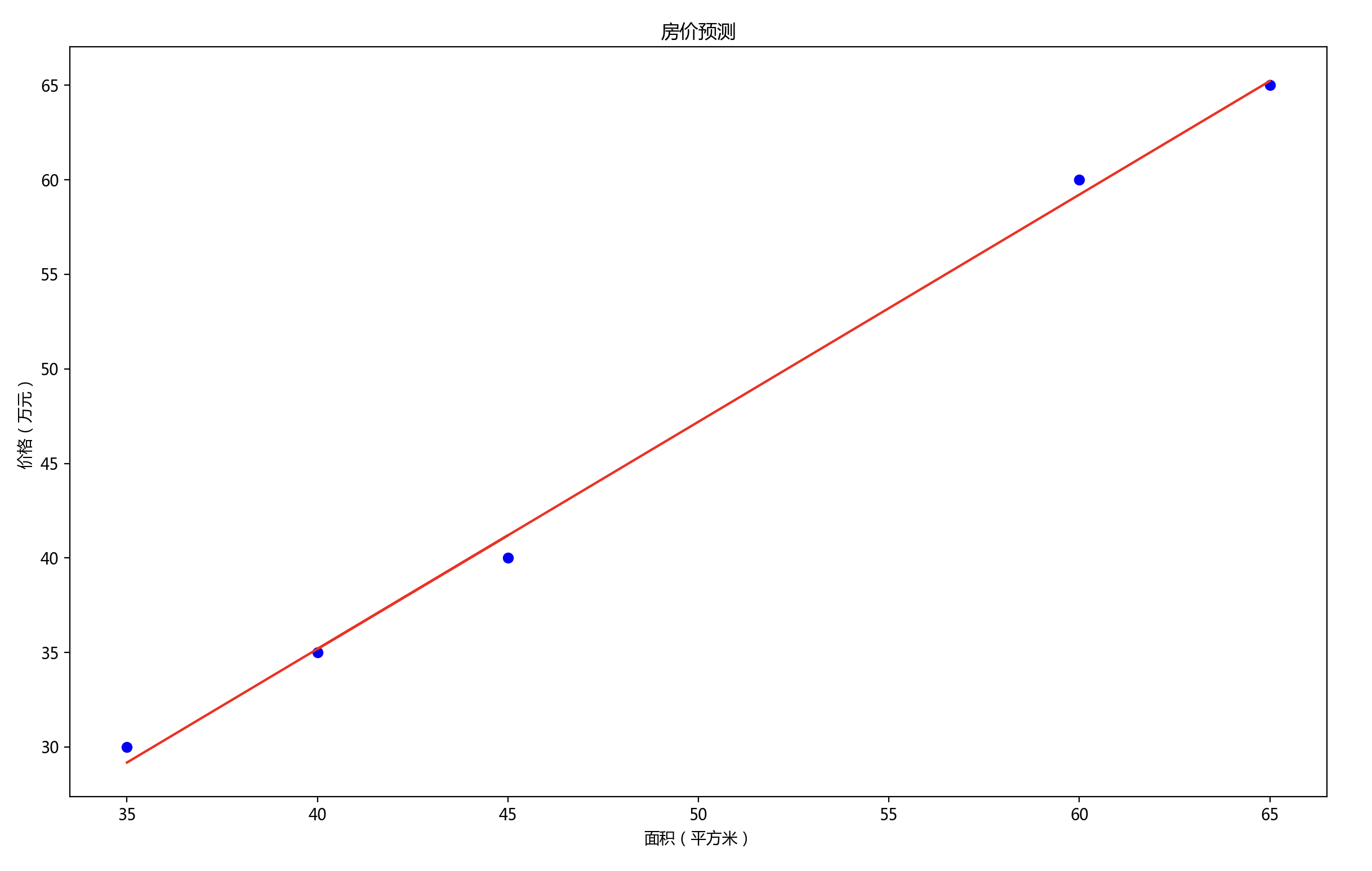
图中蓝色的点代表用于训练模型的实际数据点,红色的线则展示了模型拟合的结果。可以看出,这条直线尝试穿过所有的数据点,以此来预测面积与价格之间的关系。通过这个简单的例子,你可以看到线性回归是如何帮助我们理解和预测变量之间的关系的。它是一种非常实用的工具,广泛应用于经济学、生物统计学、环境科学和许多其他领域。
逻辑回归
逻辑回归主要用于处理分类问题,尤其是二分类问题。它的目的是预测一个事件发生的概率,并将这个概率转换为二元结果:0或1、是或否等。逻辑回归通过使用逻辑函数(也称为Sigmoid函数)将线性回归模型的输出映射到0和1之间的概率值上。这个逻辑函数定义如下:
$$\sigma(z)= \frac{1}{1+e^{-z}}$$
其中 $z$ 是线性回归模型的输出,即 $z = \beta_{0} + \beta_{1}x_{1} + \beta_{2}x_{2} + … + \beta_{n}x_{n}$。在这个表达式中,$x_1,x_2,…,x_n$是特征变量,$\beta_0,\beta_1,…,\beta_n$ 是模型参数。
整体看这个公式,模型参数很关键,而取得模型参数的值就需要用到似然函数了。如何理解似然函数呢?一句话讲就是基于观测,通过结果反推模型参数。放到这个案例中,如果我们在某些特定场景下,得出了$\sigma$,并且知道了 $x_1,x_2…x_n$ 的值,我们就可以推测出使$\sigma$取得最大的$\beta_1,\beta_2…\beta_n$的值,而这个值就可以当做模型参数来用,从而进行概率推导。我们举个简单的例子。
假设我们要预测学生是否会通过考试,基于他们的学习时间进行预测,最终有两个分类:通过(用1表示)和未通过(用0表示)。使用逻辑回归模型来预测给定学习时间下学生通过考试的概率。
# 导入库
from sklearn.linear_model import LogisticRegression
import numpy as np
# 准备数据
X = np.array([[10], [20], [30], [40], [50]]) # 学习时间
y = np.array([0, 0, 1, 1, 1]) # 通过考试与否
# 创建逻辑回归模型并训练
model = LogisticRegression()
model.fit(X, y)
# 预测学习时间为25小时的学生通过考试的概率
prediction_probability = model.predict_proba([[25]])
prediction = model.predict([[25]])
print(f"通过考试的概率为:{prediction_probability[0][1]:.2f}")
print(f"预测分类:{'通过' if prediction[0] == 1 else '未通过'}")
代码执行结果如下:
这里逻辑稍微有点绕,涉及统计学的概念,如果你感兴趣,可以看一下相关的书籍,这样可以理解得更加深入一些。不过不看也没关系,这节课只是概念性的介绍,随着学习的深入,这些概念你都会慢慢熟悉起来,看得多了,慢慢就都懂了。我们下一节课会继续学习其他经典算法。
小结
从这节课开始难度慢慢大起来了,如果你没有数学、算法基础,学起来可能会稍微有点吃力,不过我讲的内容的特点就是希望在没有基础的情况下你也能理解机器学习,所以你不用着急,我会想办法,用开发工程师能看得懂的代码和讲解方式,让你更加轻松。
下一节课我会继续讲解其他经典算法,比如决策树、随机森林、支持向量机、神经网络,你也可以抽空补补相关的数据和统计学知识。
思考题
这节课我没有给出各个算法的缺点,你可以思考一下,线性回归的局限是什么,逻辑回归的局限又是什么?欢迎你在评论区留言讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见。
- 张申傲 👍(13) 💬(5)
第8讲打卡。老师专栏的结构和思路对开发工程师真的特别友好~ 思考题:线性回归和逻辑回归的局限性很明显,那就是对非线性关系的拟合效果比较差。实际生活中存在大量的非线性关系,例如一个国家的GDP作为因变量,影响它的自变量有很多,比如国家人口、面积、经济体制、产业布局、历史文化等等因素,这里面存在大量的非线性关系,很难通过线性回归或者逻辑回滚来预测。 最后一个小补充:在机器学习领域,模型的“性能”,更多指的是准确率、召回率这些指标,并不完全等同于工程领域的程序性能,如响应时间、吞吐量等等。
2024-06-18 - gesanri 👍(1) 💬(1)
有个疑问,这里举的例子都是针对某一个问题进行训练,而实际的问题是不可穷举的,gpt是怎么训练的呢?首先对所有可能的问题进行分类,完后对每个分类依次选择对应的算法进行训练,最后汇总?
2024-07-14 - 阿斯蒂芬 👍(2) 💬(0)
线性回归局限:数据越离散,线性效果越不好,而现实生活中很多数据的分布就是非线性分布,而且维度也远超线性模型能够覆盖。 逻辑回归局限:对于N>2的分类,简单的逻辑回归是远远不够的,另外就如文中图所展示,还有关于推荐、语义理解等这类有“推理”和“创造”特性的,逻辑回归应该也无法很好的cover? 不过仔细想想,更“高级”的模型,是否也是基于线性和回归的思路壮大发展的?比如维度更多,也可以理解为更多的线性回归交叉织网一样,分类更多,就像递归进行二分类?
2024-06-25 - 小楼听风 👍(0) 💬(0)
打卡 线性回归:在于对于非线性拟合效果会很差,并且线性回归对数据是有假设前提的 逻辑回归:逻辑回归是基于线性假设进行建模的,非线性关系预测性能会下降,存在一个异常值或者样本数据不足时,容易过拟合或严重影响模型结果
2025-02-07 - 石云升 👍(0) 💬(0)
我感觉这个关键还是数据,如果给出的数据与预测的值之间相关性低,得出的结果就必然差。
2024-08-28