13 深入理解Seq2Seq:让我们看看语言翻译是怎么来的
你好,我是独行。
上节课我们一起学习了Word2Vec,Word2Vec的主要能力是把词汇放在多维的空间里,相似的词汇会被放在邻近的位置。这节课我们将进入Seq2Seq的领域,了解这种更为复杂且功能强大的模型,它不仅能理解词汇,还能把这些词汇串联成完整的句子。
Seq2Seq
Seq2Seq(Sequence-to-Sequence),顾名思义是从一个序列到另一个序列的转换。它不仅仅能理解单词之间的关系,而且还能把整个句子的意思打包,并解压成另一种形式的表达。如果说Word2Vec是让我们的机器学会了理解词汇的话,那Seq2Seq则是教会了机器如何理解句子并进行相应地转化。
在这个过程中,我们会遇到两个核心的角色:编码器(Encoder)和解码器(Decoder)。编码器的任务是理解和压缩信息,就像是把一封长信函整理成一个精简的摘要;而解码器则需要将这个摘要展开,翻译成另一种语言或形式的完整信息。这个过程有一定的挑战,比如如何确保信息在这次转换中不丢失精髓,而是以新的面貌精准地呈现出来,这就是我们接下来要探索的内容之一。
基本概念
Seq2Seq也是一种神经网络架构,模型的核心由两部分组成:编码器(Encoder)和解码器(Decoder)。你可以看一下这个架构的示意图。
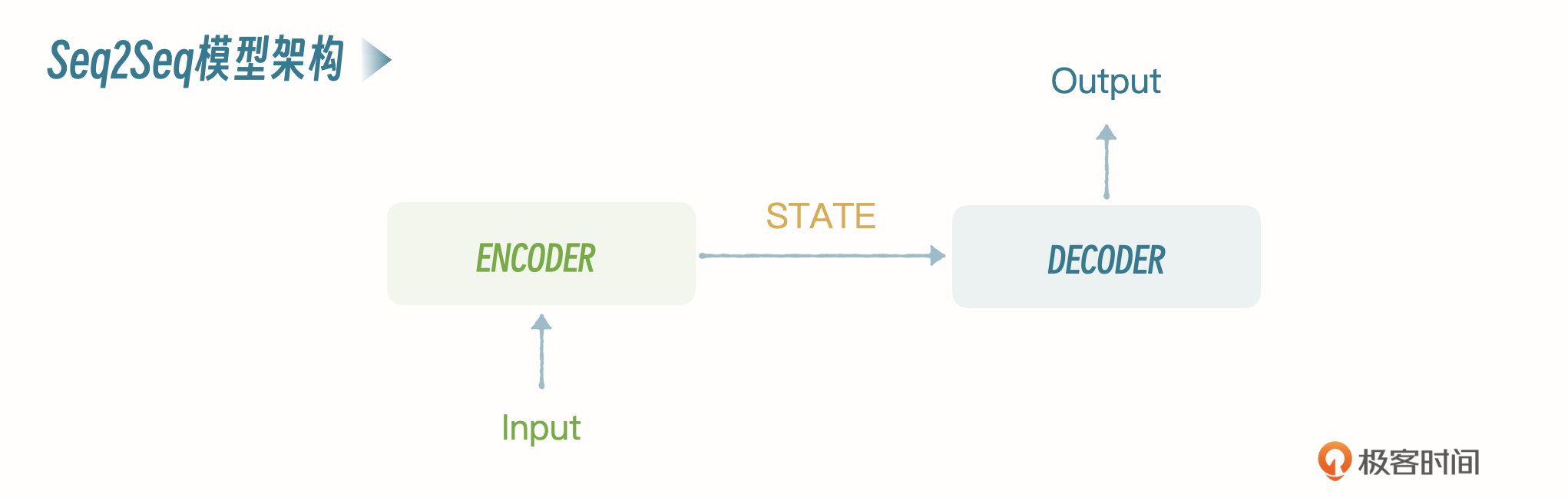
编码器
编码器的任务是读取并理解输入序列,然后把它转换为一个固定长度的上下文向量,也叫作状态向量。这个向量是输入序列的一种内部表示,捕捉了序列的关键信息。编码器通常是一个循环神经网络(RNN)或其变体,比如长短期记忆网络(LSTM)或门控循环单元(GRU),它们能够处理不同长度的输入序列,并且记住序列中的长期依赖关系。
解码器
解码器的任务是接收编码器生成的上下文向量,并基于这个向量生成目标序列。解码过程是一步步进行的,每一步生成目标序列中的一个元素,比如一个词或字符,直到生成特殊的结束符号,表示输出序列的结束。解码器通常也是一个RNN、LSTM或GRU,它不仅依赖于编码器的上下文向量,还可能依赖于自己之前的输出,来生成下一个输出元素。
注意力机制(可选)
在编码器和解码器之间,可能还会有一个注意力机制(Attention Mechanism)。注意力机制使解码器能够在生成每个输出元素时“关注”输入序列中的不同部分,从而提高模型处理长序列和捕捉复杂依赖关系的能力。编码器、解码器、注意力机制之间是怎样协作的呢?你可以看一下我给出的示意图。
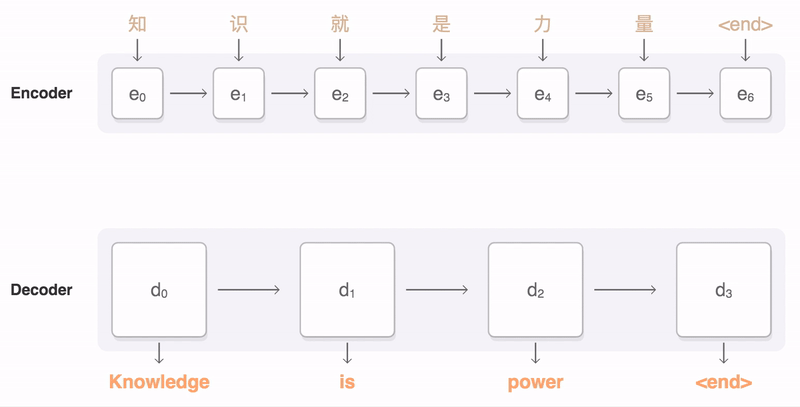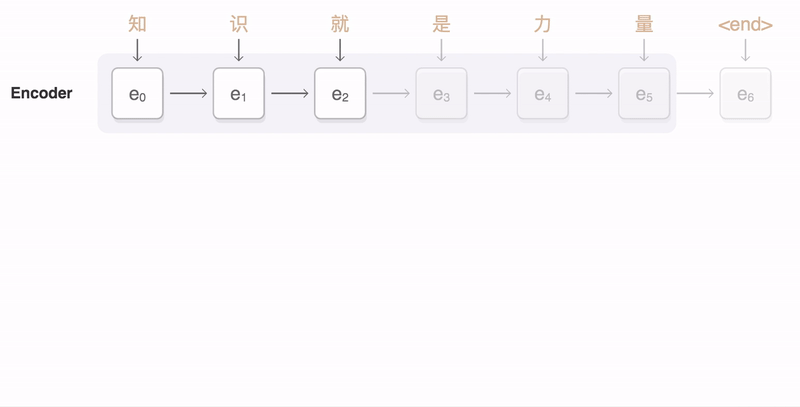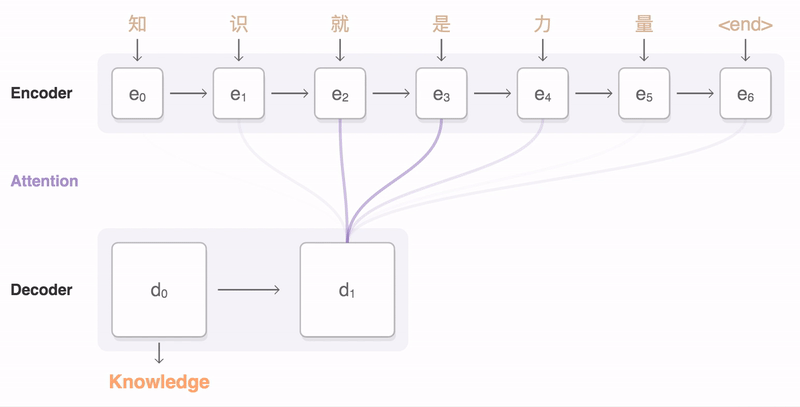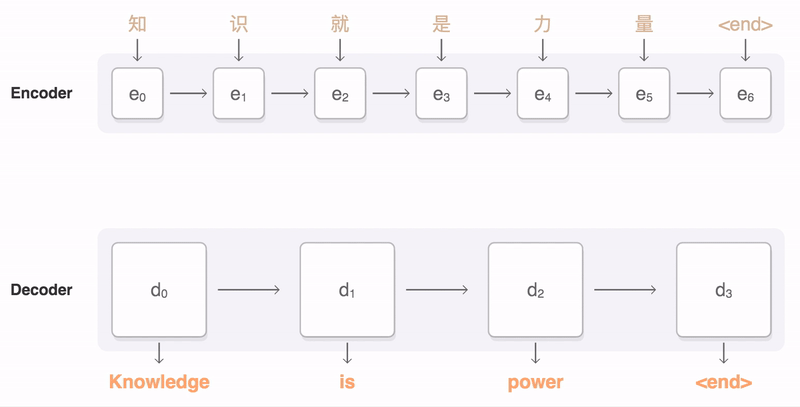
下面我通过一个翻译的例子,来说明Seq2Seq的工作原理。
工作原理
我们先从模型的训练开始,Seq2Seq的训练和Word2Vec不太一样,因为我们讲解的是中英文翻译场景,所以训练的时候,训练数据是中英文数据对。Seq2Seq的训练会比Word2Vec更加复杂一些。上节课的Word2Vec,我们使用的是gensim库提供的基础模型,直接进行训练,这节课我们完全从头写起,训练一个Seq2Seq模型。
模型训练
我们先准备训练数据,可以在网上找公开的翻译数据集,我们用的是 AIchallenger 2017,这个数据集有1000万对中英文数据,不过因为电脑配置问题,我直接从里面中文和英文的部分各取了10000条进行训练。数据集名称是train_1w.zh和train_1w.en。
cn_sentences = []
zh_file_path = "train_1w.zh"
# 使用Python的文件操作逐行读取文件,并将每一行的内容添加到列表中
with open(zh_file_path, "r", encoding="utf-8") as file:
for line in file:
# 去除行末的换行符并添加到列表中
cn_sentences.append(line.strip())
en_sentences = []
en_file_path = "train_1w.en"
# 使用Python的文件操作逐行读取文件,并将每一行的内容添加到列表中
with open(en_file_path, "r", encoding="utf-8") as file:
for line in file:
# 去除行末的换行符并添加到列表中
en_sentences.append(line.strip())
接下来,基于训练数据集构建中文和英文的词汇表,将每个词映射到一个唯一的索引(integer)。
# cn_sentences 和 en_sentences 分别包含了所有的中文和英文句子
cn_vocab = build_vocab(cn_sentences, tokenize_cn, max_size=10000, min_freq=2)
en_vocab = build_vocab(en_sentences, tokenize_en, max_size=10000, min_freq=2)
我们再来看 biild_vocab的源码。
def build_vocab(sentences, tokenizer, max_size, min_freq):
token_freqs = Counter()
for sentence in sentences:
tokens = tokenizer(sentence)
token_freqs.update(tokens)
vocab = {token: idx + 4 for idx, (token, freq) in enumerate(token_freqs.items()) if freq >= min_freq}
vocab['<unk>'] = 0
vocab['<pad>'] = 1
vocab['<sos>'] = 2
vocab['<eos>'] = 3
return vocab
思路就是把所有的句子读进去,循环分词,放入字典,放的时候要判断一下是否大于等于min_freq,用来过滤掉出现频率较低的词汇,最后构建出来的词汇表如下:
vocab = {
'<unk>': 0,
'<pad>': 1,
'<sos>': 2,
'<eos>': 3,
'i': 4,
'like': 5,
'learning': 6,
'machine': 7,
'is': 8,
'very': 9,
'interesting': 10,
...
}
我们来看一下里面比较重要的几个部分。
<unk>:未知单词,表示在训练数据中没有出现过的单词。当模型在处理输入文本时遇到未知单词时,会用这个标记来表示。<pad>:填充单词,用于将不同长度的序列填充到相同的长度。在处理批次数据时,由于不同序列的长度可能不同,因此需要用这个标记把短序列填充到与最长序列相同的长度,以便进行批次处理。<sos>:句子起始标记,表示句子的开始位置。在Seq2Seq模型中,通常会在目标句子的开头添加这个标记,以指示解码器开始生成输出。<eos>:句子结束标记,表示句子的结束位置。在Seq2Seq模型中,通常会在目标句子的末尾添加该标记,以指示解码器生成结束。
创建训练数据集,将数据处理成方便训练的格式:语言序列,比如 [1,2,3,4]。
dataset = TranslationDataset(cn_sentences, en_sentences, cn_vocab, en_vocab, tokenize_cn, tokenize_en)
train_loader = DataLoader(dataset, batch_size=32, collate_fn=collate_fn)
然后检测是否有显卡:
# 检查是否有可用的GPU,如果没有,则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("训练设备为:", device)
创建模型,参数的解释可以参考代码注释。
# 定义一些超参数
INPUT_DIM = 10000 # 输入语言的词汇量
OUTPUT_DIM = 10000 # 输出语言的词汇量
ENC_EMB_DIM = 256 # 编码器嵌入层大小,也就是编码器词向量维度
DEC_EMB_DIM = 256 # 解码器嵌入层大小,解码器词向量维度
HID_DIM = 512 # 隐藏层维度
N_LAYERS = 2 # RNN层的数量
ENC_DROPOUT = 0.5 # 编码器神经元输出的数据有50%会被随机丢掉
DEC_DROPOUT = 0.5 # 解码器同上
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# 假定模型已经被实例化并移到了正确的设备上
model.to(device)
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=en_vocab['<pad>']) # 忽略<pad>标记的损失
开始训练:
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
model.train()
total_loss = 0
for src, trg in train_loader:
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad() # 清空梯度
output = model(src, trg[:-1]) # 输入给模型的是除了最后一个词的目标句子
# Reshape输出以匹配损失函数期望的输入
output_dim = output.shape[-1]
output = output.view(-1, output_dim)
trg = trg[1:].view(-1) # 从第一个词开始的目标句子
loss = criterion(output, trg) # 计算模型输出和实际目标序列之间的损失
loss.backward() # 通过反向传播计算损失相对于模型参数的梯度
optimizer.step() # 根据梯度更新模型参数,这是优化器的一个步骤
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f'Epoch {epoch + 1}/{num_epochs}, Average Loss: {avg_loss}')
我拿下面的素材举例,简单解释一下训练过程。
在开始训练之前,先把原文本转化成在对应词语表里的语言序列,比如在中文词汇表中,我 喜欢 学习 机器 学习 分别对应的是 1,2,3,4,5,那么转化成的语言序列就是 [1,2,3,4,5],也就是前面讲的train_loader里的格式。
编码器接收到语言序列,经过神经网络GRU单元处理后,生成一个上下文向量,这个上下文向量会作为解码器的初始状态。
解码器接收上下文向量作为输入,并根据当前上下文以及已生成的部分目标语言序列,计算目标词汇表中每个单词的概率分布。例如,在第一个时间步,解码器可能计算出目标词汇表中每个单词的概率分布,如 "I": 0.3, "like": 0.1, "studying": 0.5, "machine": 0.05, "learning": 0.05,根据解码器生成的概率分布,选择概率最高的词studying作为当前时间步的输出。
模型将解码器生成的输出词汇与目标语言句子(“I like studying machine learning.”)中当前时间步对应的词汇进行对比。这里解码器输出的 "studying" 与目标语言句子中的 "I" 进行对比,发现它们之间的差别较大。
根据解码器输出 "studying" 和目标语言句子中的真实词汇 "I" 计算损失,并通过反向传播算法计算梯度。损失值是一个衡量模型预测输出与真实目标之间差异的指标。然后,根据损失值更新模型参数,使模型能够更准确地预测下一个词汇。
重复以上步骤,直到模型达到指定的训练轮数或者满足其他停止训练的条件。在每次训练迭代中,模型都在尝试调整自己的参数,以使其预测输出更接近真实的目标语言序列,从而提高翻译质量。
所以这里就能看出,训练轮数就非常关键,不能太少,也不能太多。
模型验证
def translate_sentence(sentence, src_vocab, trg_vocab, model, device, max_len=50):
# 将输入句子进行分词并转换为索引序列
src_tokens = ['<sos>'] + tokenize_cn(sentence) + ['<eos>']
src_indices = [src_vocab[token] if token in src_vocab else src_vocab['<unk>'] for token in src_tokens]
# 将输入句子转换为张量并移动到设备上
src_tensor = torch.LongTensor(src_indices).unsqueeze(1).to(device)
# 将输入句子传递给编码器以获取上下文张量
with torch.no_grad():
encoder_hidden = model.encoder(src_tensor)
# 初始化解码器输入为<sos>
trg_token = '<sos>'
trg_index = trg_vocab[trg_token]
# 存储翻译结果
translation = []
# 解码过程
for _ in range(max_len):
# 将解码器输入传递给解码器,并获取输出和隐藏状态
with torch.no_grad():
trg_tensor = torch.LongTensor([trg_index]).to(device)
output, encoder_hidden = model.decoder(trg_tensor, encoder_hidden)
# 获取解码器输出中概率最高的单词的索引
pred_token_index = output.argmax(dim=1).item()
# 如果预测的单词是句子结束符,则停止解码
if pred_token_index == trg_vocab['<eos>']:
break
# 否则,将预测的单词添加到翻译结果中
pred_token = list(trg_vocab.keys())[list(trg_vocab.values()).index(pred_token_index)]
translation.append(pred_token)
# 更新解码器输入为当前预测的单词
trg_index = pred_token_index
# 将翻译结果转换为字符串并返回
translation = ' '.join(translation)
return translation
sentence = "我喜欢学习机器学习。"
translation = translate_sentence(sentence, cn_vocab, en_vocab, model, device)
print(f"Chinese: {sentence}")
print(f"Translation: {translation}")
程序输出如下:
看上去只翻译成功了“我”这个字,其他都没出来,大概率是因为训练数据太少的原因。
推理过程和训练过程很像,区别在于,训练过程中模型会记住参数,推理的时候直接根据这些参数计算下一个词的概率即可。
结尾放一下完整的代码:
import torch
from torch.utils.data import Dataset, DataLoader
import spacy
import jieba
from collections import Counter
from torch.nn.utils.rnn import pad_sequence
import torch.nn as nn
import random
import torch.optim as optim
# 加载英文的Spacy模型
spacy_en = spacy.load('en_core_web_sm')
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
def tokenize_cn(text):
"""
Tokenizes Chinese text from a string into a list of strings (tokens)
"""
return list(jieba.cut(text))
def build_vocab(sentences, tokenizer, max_size, min_freq):
token_freqs = Counter()
for sentence in sentences:
tokens = tokenizer(sentence)
token_freqs.update(tokens)
vocab = {token: idx + 4 for idx, (token, freq) in enumerate(token_freqs.items()) if freq >= min_freq}
vocab['<unk>'] = 0
vocab['<pad>'] = 1
vocab['<sos>'] = 2
vocab['<eos>'] = 3
return vocab
class TranslationDataset(Dataset):
def __init__(self, src_sentences, trg_sentences, src_vocab, trg_vocab, tokenize_src, tokenize_trg):
self.src_sentences = src_sentences
self.trg_sentences = trg_sentences
self.src_vocab = src_vocab
self.trg_vocab = trg_vocab
self.tokenize_src = tokenize_src
self.tokenize_trg = tokenize_trg
def __len__(self):
return len(self.src_sentences)
def __getitem__(self, idx):
src_sentence = self.src_sentences[idx]
trg_sentence = self.trg_sentences[idx]
src_indices = [self.src_vocab[token] if token in self.src_vocab else self.src_vocab['<unk>']
for token in ['<sos>'] + self.tokenize_src(src_sentence) + ['<eos>']]
trg_indices = [self.trg_vocab[token] if token in self.trg_vocab else self.trg_vocab['<unk>']
for token in ['<sos>'] + self.tokenize_trg(trg_sentence) + ['<eos>']]
return torch.tensor(src_indices), torch.tensor(trg_indices)
def collate_fn(batch):
src_batch, trg_batch = zip(*batch)
src_batch = pad_sequence(src_batch, padding_value=1) # 1 is the index for <pad>
trg_batch = pad_sequence(trg_batch, padding_value=1) # 1 is the index for <pad>
return src_batch, trg_batch
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src: [src_len, batch_size]
embedded = self.dropout(self.embedding(src))
outputs, hidden = self.rnn(embedded)
return hidden
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden):
input = input.unsqueeze(0) # input: [1, batch_size]
embedded = self.dropout(self.embedding(input))
output, hidden = self.rnn(embedded, hidden)
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src: [src_len, batch_size]
# trg: [trg_len, batch_size]
# teacher_forcing_ratio是使用真实标签的概率
trg_len = trg.shape[0]
batch_size = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
# 存储解码器输出
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# 编码器的最后一个隐藏状态用作解码器的初始隐藏状态
hidden = self.encoder(src)
# 解码器的第一个输入是<sos> tokens
input = trg[0, :]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden)
outputs[t] = output
# 决定是否使用teacher forcing
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs
cn_sentences = []
zh_file_path = "train_1w.zh"
# 使用Python的文件操作逐行读取文件,并将每一行的内容添加到列表中
with open(zh_file_path, "r", encoding="utf-8") as file:
for line in file:
# 去除行末的换行符并添加到列表中
cn_sentences.append(line.strip())
en_sentences = []
en_file_path = "train_1w.en"
# 使用Python的文件操作逐行读取文件,并将每一行的内容添加到列表中
with open(en_file_path, "r", encoding="utf-8") as file:
for line in file:
# 去除行末的换行符并添加到列表中
en_sentences.append(line.strip())
# cn_sentences 和 en_sentences 分别包含了所有的中文和英文句子
cn_vocab = build_vocab(cn_sentences, tokenize_cn, max_size=10000, min_freq=2)
en_vocab = build_vocab(en_sentences, tokenize_en, max_size=10000, min_freq=2)
# cn_vocab 和 en_vocab 是已经创建的词汇表
dataset = TranslationDataset(cn_sentences, en_sentences, cn_vocab, en_vocab, tokenize_cn, tokenize_en)
train_loader = DataLoader(dataset, batch_size=32, collate_fn=collate_fn)
# 检查是否有可用的GPU,如果没有,则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("训练设备为:", device)
# 定义一些超参数
INPUT_DIM = 10000 # 输入语言的词汇量
OUTPUT_DIM = 10000 # 输出语言的词汇量
ENC_EMB_DIM = 256 # 编码器嵌入层大小
DEC_EMB_DIM = 256 # 解码器嵌入层大小
HID_DIM = 512 # 隐藏层维度
N_LAYERS = 2 # RNN层的数量
ENC_DROPOUT = 0.5 # 编码器中dropout的比例
DEC_DROPOUT = 0.5 # 解码器中dropout的比例
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# 假定模型已经被实例化并移到了正确的设备上
model.to(device)
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=en_vocab['<pad>']) # 忽略<pad>标记的损失
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
model.train()
total_loss = 0
for src, trg in train_loader:
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad() # 清空梯度
output = model(src, trg[:-1]) # 输入给模型的是除了最后一个词的目标句子
# Reshape输出以匹配损失函数期望的输入
output_dim = output.shape[-1]
output = output.view(-1, output_dim)
trg = trg[1:].view(-1) # 从第一个词开始的目标句子
loss = criterion(output, trg)
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f'Epoch {epoch + 1}/{num_epochs}, Average Loss: {avg_loss}')
# 可以在这里添加验证步骤
def translate_sentence(sentence, src_vocab, trg_vocab, model, device, max_len=50):
# 将输入句子进行分词并转换为索引序列
src_tokens = ['<sos>'] + tokenize_cn(sentence) + ['<eos>']
src_indices = [src_vocab[token] if token in src_vocab else src_vocab['<unk>'] for token in src_tokens]
# 将输入句子转换为张量并移动到设备上
src_tensor = torch.LongTensor(src_indices).unsqueeze(1).to(device)
# 将输入句子传递给编码器以获取上下文张量
with torch.no_grad():
encoder_hidden = model.encoder(src_tensor)
# 初始化解码器输入为<sos>
trg_token = '<sos>'
trg_index = trg_vocab[trg_token]
# 存储翻译结果
translation = []
# 解码过程
for _ in range(max_len):
# 将解码器输入传递给解码器,并获取输出和隐藏状态
with torch.no_grad():
trg_tensor = torch.LongTensor([trg_index]).to(device)
output, encoder_hidden = model.decoder(trg_tensor, encoder_hidden)
# 获取解码器输出中概率最高的单词的索引
pred_token_index = output.argmax(dim=1).item()
# 如果预测的单词是句子结束符,则停止解码
if pred_token_index == trg_vocab['<eos>']:
break
# 否则,将预测的单词添加到翻译结果中
pred_token = list(trg_vocab.keys())[list(trg_vocab.values()).index(pred_token_index)]
translation.append(pred_token)
# 更新解码器输入为当前预测的单词
trg_index = pred_token_index
# 将翻译结果转换为字符串并返回
translation = ' '.join(translation)
return translation
sentence = "我喜欢学习机器学习。"
translation = translate_sentence(sentence, cn_vocab, en_vocab, model, device)
print(f"Chinese: {sentence}")
print(f"Translation: {translation}")
小结
这节课我们自己动手训练了一个Seq2Seq模型,Seq2Seq可以算是一种高级的神经网络模型了,除了做语言翻译外,甚至可以做基本的问答系统了。但是,Seq2Seq缺点也比较明显,首先Seq2Seq使用固定上下文长度,所以长距离依赖能力较弱。此外,Seq2Seq训练和推理通常需要逐步处理输入和输出序列,所以处理长序列可能会有限制。最后Seq2Seq参数量通常较少,所以面对复杂场景,模型性能可能会受限。
带着这些问题,下一节课我将会向你介绍终极大boss:Transformer,我们学习了这么多基础概念,就是为学习Transformer做铺垫,从ML->NLP->Word2Vec->Seq2Seq->Transformer一步一步递进。
注:en_core_web_sm、train_1w.zh、train_1w.en 链接: https://pan.baidu.com/s/1_GG3bIAjqpPGLGugHEI5Dg?pwd=fm8j 提取码: fm8j
思考题
我刚刚讲过,推理的时候模型会使用训练过程中记住的参数来进行概率预测,你可以思考一下,模型的参数到底是什么?欢迎在评论区留言,我们一起讨论学习,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给需要的朋友,邀TA一起学习,我们下节课再见!
- 方梁 👍(1) 💬(1)
train_1w.zh train_1w.en 请提供一下哈,谢谢
2024-06-26 - 小毛驴 👍(0) 💬(1)
老师补充一下:OSError: [E053] Could not read config file from external\en_core_web_sm-2.3.0\config.cfg 从网盘下载的模型加载会报错,在huggingface上引用的模型每次执行pred_token_index = output.argmax(dim=1).item()返回都是0,这是为啥?
2024-09-12 - 小毛驴 👍(0) 💬(1)
老师,请教一下为什么 pred_token_index = output.argmax(dim=1).item()这段代码永远返回都是0,是我引用的模型不对嘛?
2024-09-12 - 石云升 👍(0) 💬(1)
第三章开始的技术原理部分越来越难了。
2024-09-03 - 王旧业 👍(0) 💬(1)
老师请教下文中这种动图咋做的
2024-08-24 - 方梁 👍(0) 💬(1)
en_core_web_sm 等文件在哪里下载?
2024-06-26 - Geek_7df415 👍(0) 💬(1)
模型训练部分, AIchallenger2017 的链接,AccessDenied
2024-06-26 - kiikii 👍(0) 💬(0)
反向算法传播过程中,会被更新的参数,是权重和偏置,weights和bais;权重即上下文向量中的每个词和已生成序列,影响到当前要被生成的词的权重、影响力有多大;baises是指一个基础阈值
2025-01-19