14 Transformer技术原理:为什么说Transformer是大模型架构的基石?(上)
你好,我是独行。
铺垫了这么多,终于到重头戏了,如果把前面讲的基础知识都当作开胃小菜的话,那么这节课我们讲的Transformer妥妥的算主菜、大菜了。
回想一下上节课讲的Seq2Seq,我们的案例中底层使用的是GRU(门控循环单元),我们在讲RNN的时候提过但没有深入介绍。不论是GRU还是LSTM都面临一系列问题,比如梯度消失和梯度爆炸,还有RNN必须按照顺序处理序列中的每个元素,没法并行处理,当然还有长依赖问题,虽然RNN可以处理长序列,但是实战中效果并不是很好,等等。
这些问题一直困扰学术界多年,直到有一天,Google的研究员发表了一篇论文——Attention Is All You Need,提出了Transformer模型,名字就霸气侧漏,瞬间这些问题貌似迎刃而解!我们今天这节课就来扒一扒细节,学习下为什么Transformer能解决这些问题。
Transformer
Transformer是一种基于自注意力机制的深度学习模型,诞生于2017年。目前大部分大语言模型,像GPT系列和BERT系列都是基于Transformer架构。Transformer摒弃了之前序列处理任务中广泛使用的循环神经网络(RNN),转而使用自注意力层来直接计算序列内各元素之间的关系,从而有效捕获长距离依赖。这一创新设计不仅明显提高了处理速度,由于其并行计算的特性,也大幅度提升了模型在处理长序列数据时的效率。
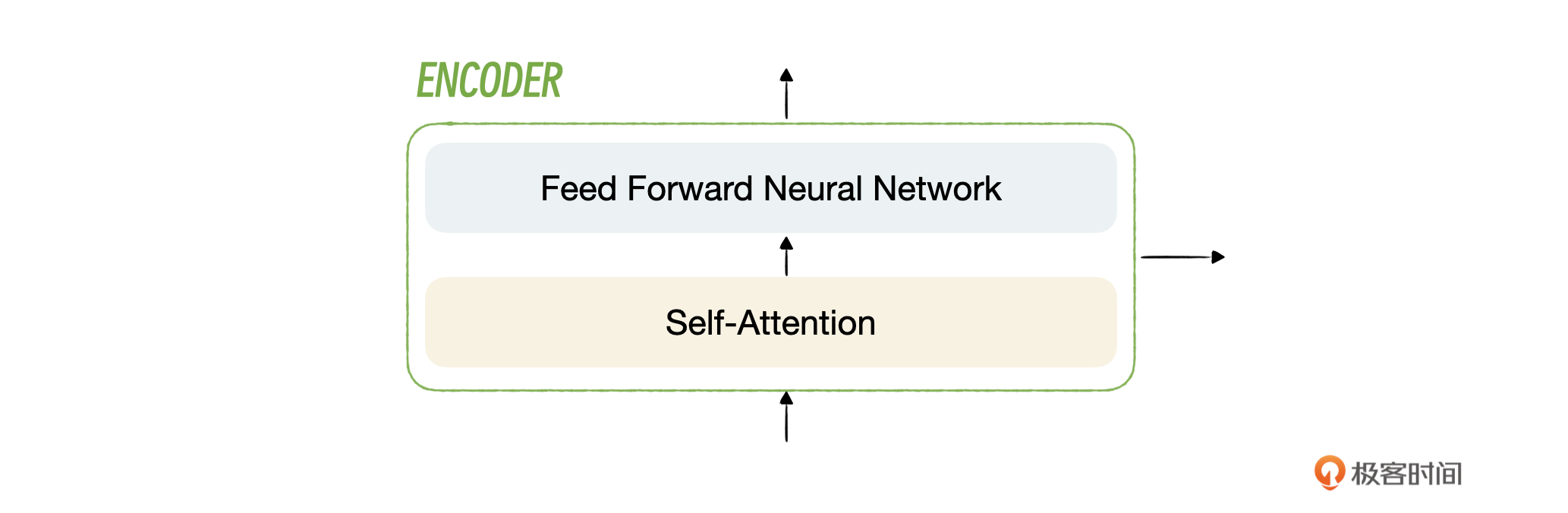
看看这幅图你就明白Transformer在江湖中的地位了。

Transformer模型由编码器和解码器组成,每个部分均由多层重复的模块构成,其中包含自注意力层和前馈神经网络。接下来我们依次了解下这些模块。
Transformer核心概念
注意力机制(Attention)
我们上节课在学习Seq2Seq的时候,就了解过注意力机制,不过没有展开介绍,也就是说在Transformer出现之前,2014年注意力机制已经被提出了,也被用于Seq2Seq之上。那为什么Transformer还在强调注意力机制呢?
因为Transformer是一个完全基于注意力机制构建的模型,它的核心思想就是:Attention Is All You Need(注意力是你所需要的全部),与之前依赖循环神经网络(RNN)或长短期记忆网络(LSTM)的模型不同,Transformer通过自注意力机制来处理序列数据,这使得每个输出元素都能直接与输入序列中的所有元素相关联,从而有效捕获长距离依赖关系。
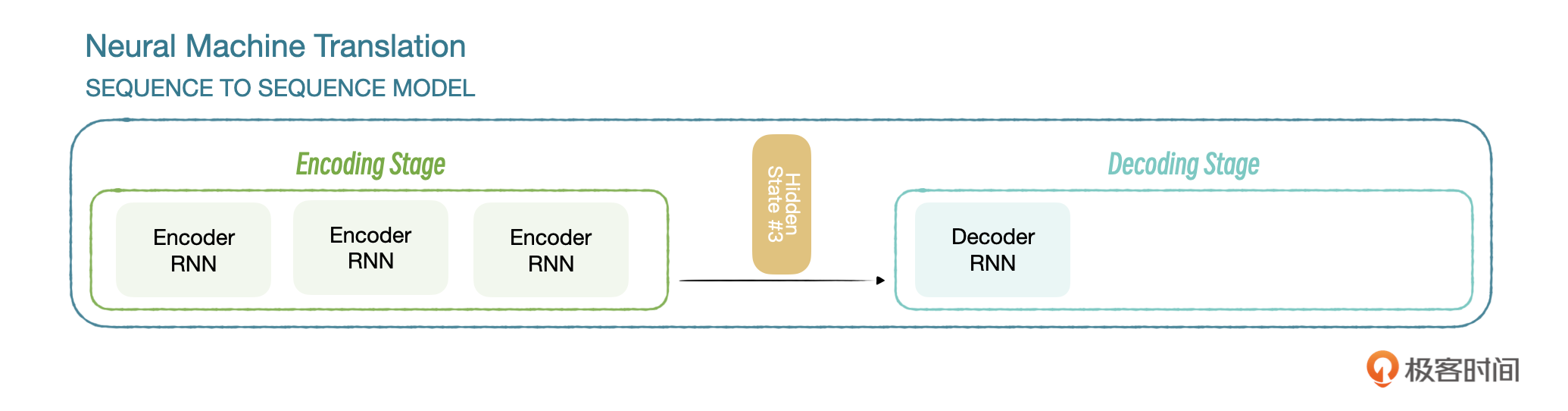
拿我们上节课讲的Seq2Seq举例,在编码阶段结束后,会产生一个上下文向量,或者叫隐藏状态,解码器根据这个向量计算下一个词的概率。参考下图:
解码阶段参考公式:
$$y_1=f©$$ $$y_2=f(C,y_1)$$ $$y_3=f(C,y_1,y_2)$$
C代表隐藏状态,解码器在不同解码阶段,仅依赖同一个隐藏状态C。加入注意力机制后,编码器传给解码器多个隐藏状态,解码器根据不同的隐藏状态计算下一个词的概率。
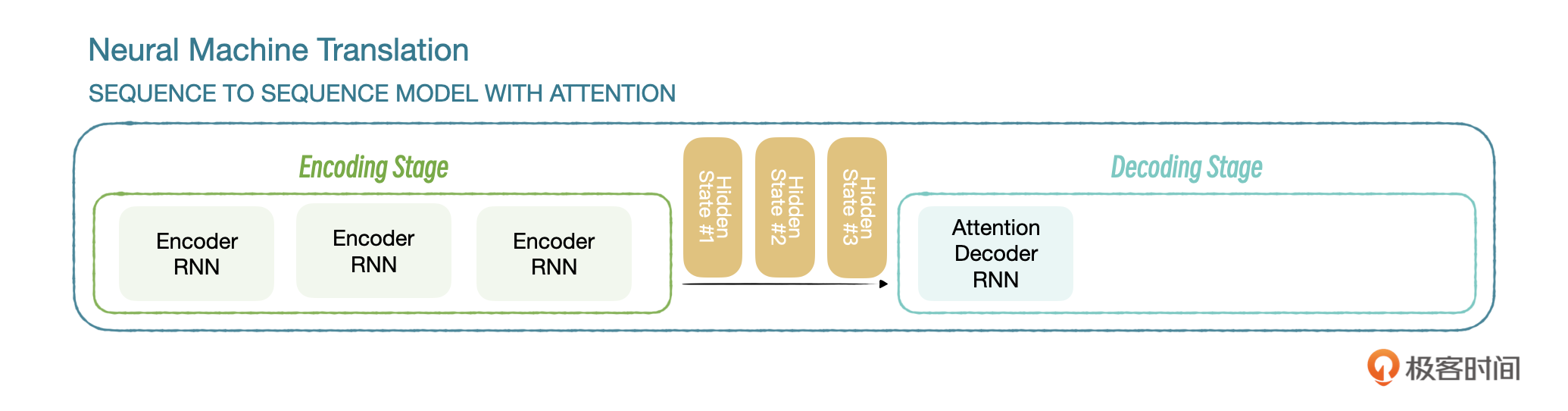
这个时候,每推测一个词之前,都会计算一下所有和这个词相关的概率,这就是注意力。我们拿上节课的例子说明一下。
在推测machine的时候,会先计算一下和machine相关的词的概率,也叫分配注意力,比如 (我,0.2)(like,0.3)(学习,0.4)(机器,0.6),这时模型就知道了下一个词和机器相关,会把注意力集中在机器上,解码阶段参考公式:
$$y_1=f(C_1)$$ $$y_2=f(C_2,y_1)$$ $$y_3=f(C_3,y_1,y_2)$$
那这个注意力分配概率怎么来的呢?不同的论文可以有不同的做法,这里我给你讲一个通用的做法。一般分为3步。
- 转换为查询(Query)、键(Key)和值(Value)
我们首先将输入序列中的每个词和目标词转换为三种向量表示。
- 查询:代表目标词的向量,用于查询与输入序列中哪些词相关。
- 键:代表输入序列中每个词的向量,用于被查询匹配。
- 值:也是代表输入序列中每个词的向量,一旦词的重要性(通过键与查询的匹配)被确定,其值向量将被用来计算最终的输出。
- 计算相似度
接下来,模型需要判断目标词(查询)与输入序列中每个词(键)之间的相关性。这是通过计算查询向量与每个键向量之间的点积来实现的。点积的结果越大,表示两个向量越相似,也就意味着输入中的这个词与目标词越相关。在词嵌入那节课我们讲过,具有相同意思的词,在同一个向量空间中比较接近,而点积就是衡量两个向量在方向上的一致性,正好可以用来计算向量的相似度。
- 转换为注意力权重
由于点积的结果可能会非常大,为了将其转换为一个合理的概率分布,即每个词的重要性权重,我们会对点积结果应用Softmax函数。Softmax能够确保所有计算出的权重加起来等于1,每个权重的值介于0和1之间。这样,每个输入词的权重就代表了它对于目标词的相对重要性。
我们可以用代码来表示这个过程。
import torch
import torch.nn.functional as F
# 假设我们已经有了每个词的嵌入向量,这里用简单的随机向量代替真实的词嵌入
# 假设嵌入大小为 4
embed_size = 4
# 输入序列 "我 喜欢 学习 机器 学习" 的嵌入表示
inputs = torch.rand((5, embed_size))
# 假设 "machine" 的查询向量
query_machine = torch.rand((1, embed_size))
def attention(query, keys, values):
# 计算查询和键的点积,除以根号下的嵌入维度来缩放
scores = torch.matmul(query, keys.transpose(-2, -1)) / (embed_size ** 0.5)
# 应用softmax获取注意力权重
attn_weights = F.softmax(scores, dim=-1)
# 计算加权和
output = torch.matmul(attn_weights, values)
return output, attn_weights
output, attn_weights = attention(query_machine, inputs, inputs)
print("Output (Attention applied):", output)
print("Attention Weights:", attn_weights)
代码输出:
Output (Attention applied): tensor([[0.4447, 0.6016, 0.7582, 0.7434]])
Attention Weights: tensor([[0.1702, 0.2151, 0.1790, 0.2165, 0.2192]])
最后两个权重0.2165和0.2192表明,machine和结尾的两个词“机器”和“学习”最相似,也就是为计算过程赋予了注意力:要注意最后这两个词。
多头注意力(Multi-head Attention)
多头注意力是Transformer模型中的一个关键创新。它的核心思想是将注意力机制“分头”进行,即在相同的数据上并行地运行多个注意力机制,然后将它们的输出合并。这种设计允许模型在不同的表示子空间中捕获信息,从而提高了模型处理信息的能力。Transformer默认8个头,其工作过程如下:
- 分割:对于每个输入,多头注意力首先将查询、键和值矩阵分割成多个“头”。这是通过将每个矩阵分割成较小的矩阵来实现的,每个较小的矩阵对应一个注意力“头”。假设原始矩阵的维度是 $d_{model}$,那么每个头的矩阵维度将是 $d_{model}/h$ ,其中 h 是头的数量。
- 并行注意力计算:对每个头分别计算自注意力。由于这些计算是独立的,它们可以并行执行。这样每个头都能在不同的表示子空间中捕获输入序列的信息。
- 拼接和线性变换:所有头的输出再被拼接起来,形成一个与原始矩阵维度相同的长矩阵。最后,通过一个线性变换调整维度,得到多头注意力的最终输出。
Transformer架构原理
模型结构
下图出自《Attention Is All You Need》论文,大部分介绍Transformer的文章都会引用这张图片,接下来我将带你一步一步揭开这个架构的神秘面纱。
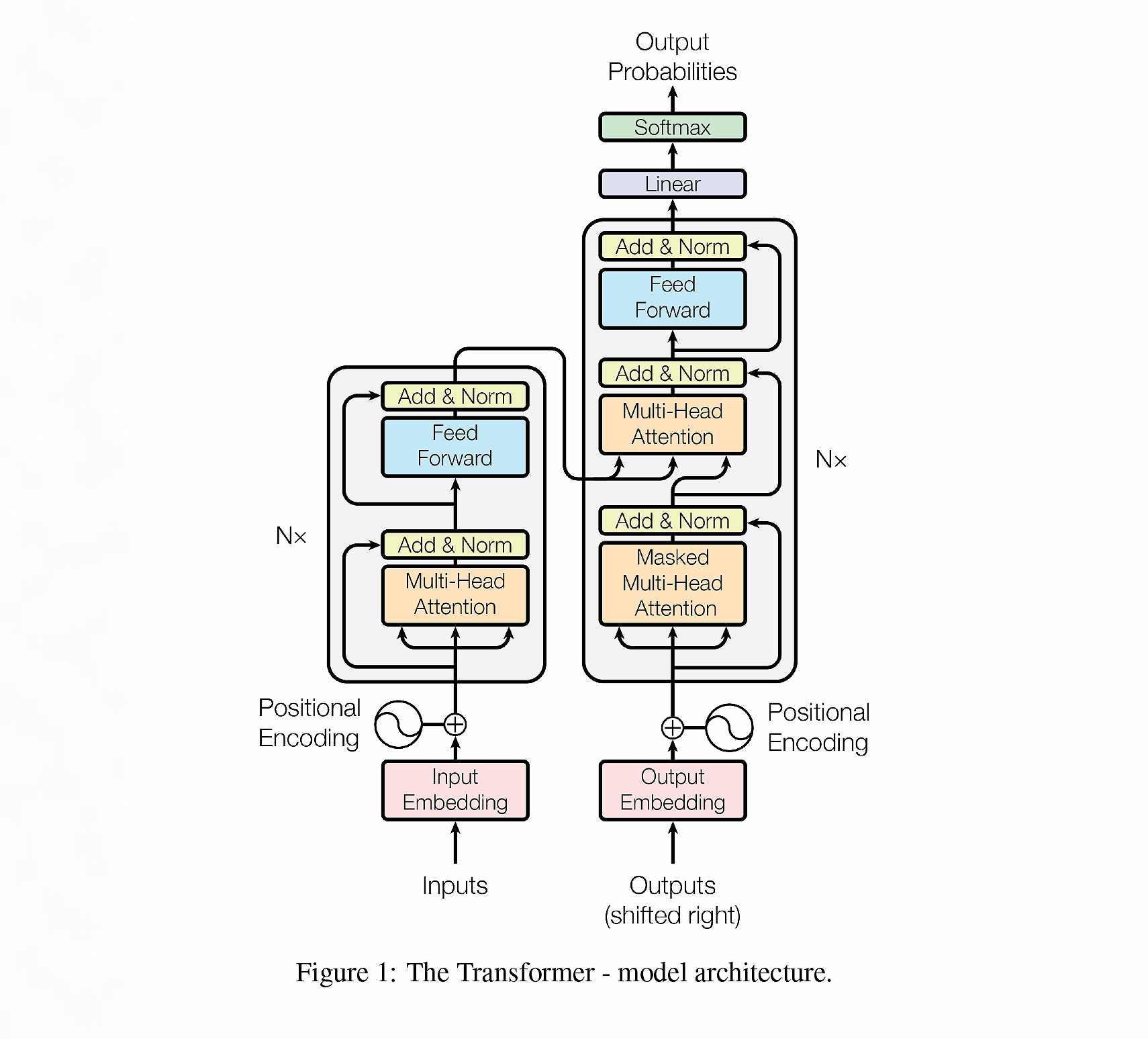
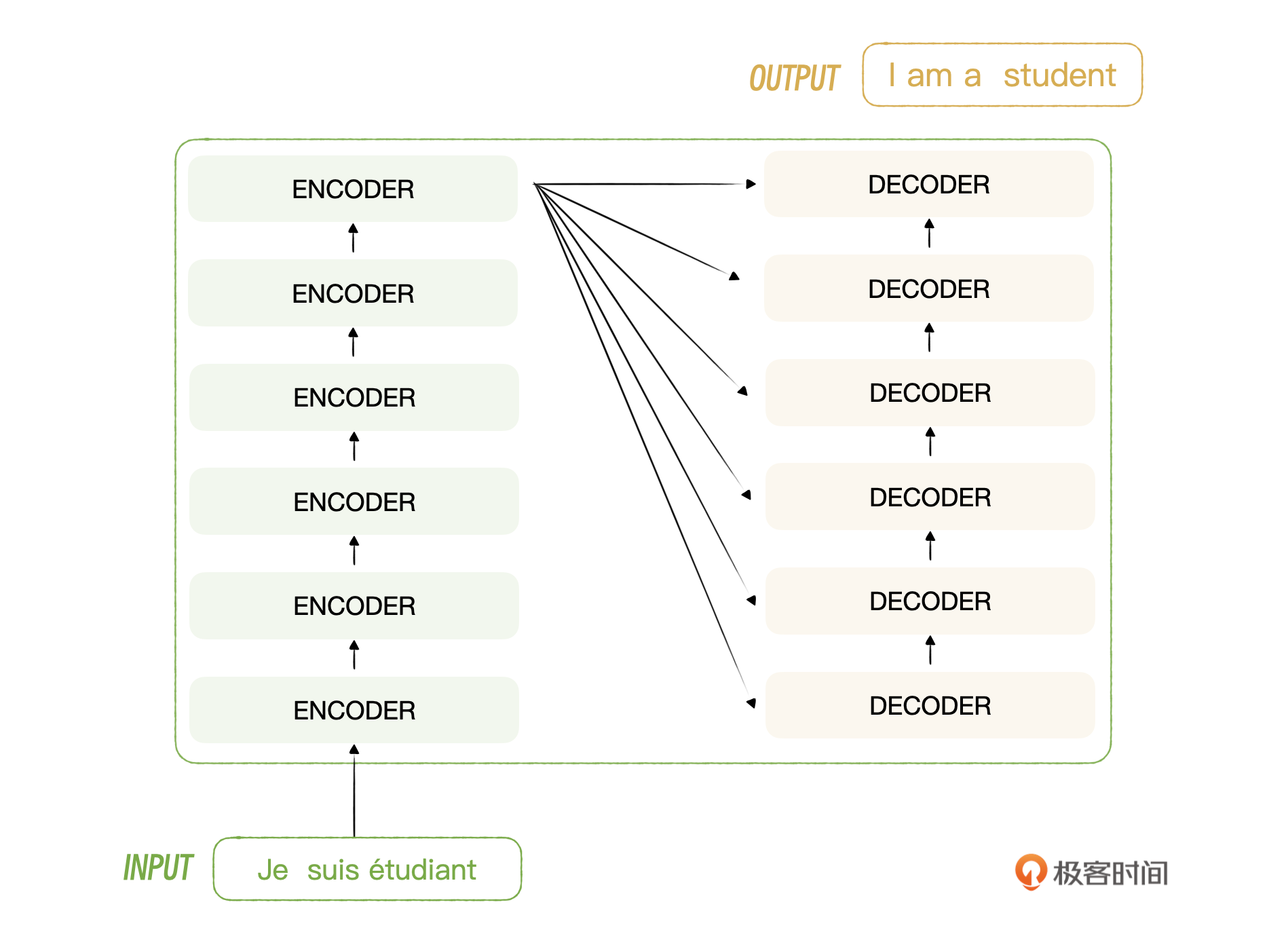
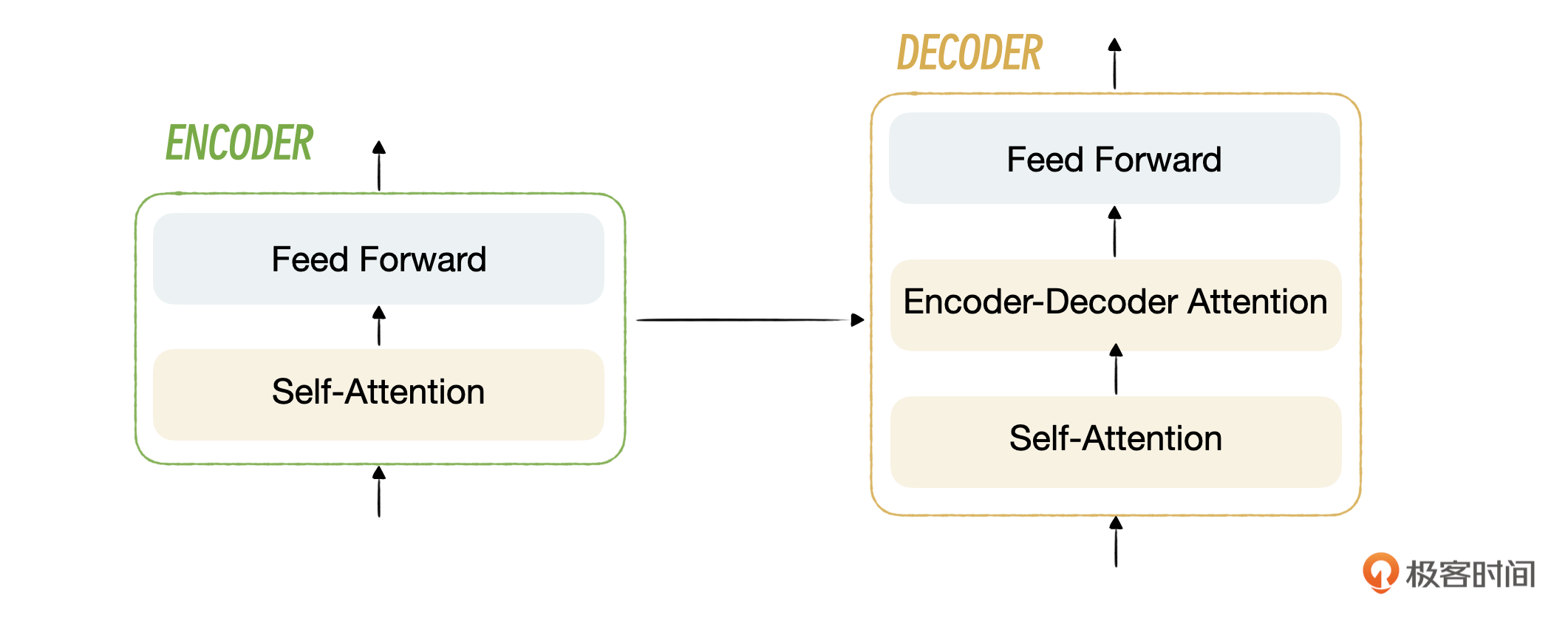
在Transformer中,编码器可以叫做编码器组,解码器也一样,叫做解码器组,就是说它们不仅仅是由一个编码器和一个解码器组成的。
每一个编码器内部又分为自注意力层和前馈神经网络层,你可以看一下图示。
每一个解码器内部又分为三层:自注意力层、编码-解码注意力层和前馈神经网络层。
输入处理(编码器)
第一步进行词嵌入处理,在第一个编码器中,将单词向量化,然后进行位置编码,就是为每个单词添加位置信息,因为Transformer不像RNN或者CNN,顺序处理序列,所以需要引入位置编码机制,确保模型能够记住单词的顺序。
自注意层处理(编码器)
这一层模型会计算每个输入元素与序列中其他元素的关系,使每个元素的新表示都富含整个序列的上下文信息。这意味着,通过自注意力机制,模型能够理解每个词,不仅仅在其自身的语义层面上,还包括它与句子中其他词的关系。之后数据经过Add & Norm操作进入前馈处理层(Feed Forward),Add & Norm是什么意思呢?
Add 表示残差连接,是指在自注意力层后把这一层处理过的数据和这一层的原始输入相加,这种方式允许模型在增加额外处理层的同时,保留输入信息的完整性,从而在不损失重要信息的前提下,学习到输入数据的复杂特征。具体来说,如果某一层的输入是 $x$,层的函数表示为 $f\left( x \right)$,那么这层的输出就是 $x+f\left( x \right)$。这样做主要是为了缓解深层网络中的梯度消失或梯度爆炸问题,使深度模型更容易训练。
那为什么说它可以缓解梯度消失问题呢?因为 $x+f\left( x \right)$,而不仅仅是 $f\left( x \right)$,这样在反向传播过程中,可以有多条路径,可以减轻连续连乘导致梯度减少到0的问题。接下来我们继续看Norm操作。
Norm表示归一化(Normalization),数据在经过Add操作后,对每一个样本的所有特征进行标准化,即在层内部对每个样本的所有特征计算均值和方差,并使用这些统计信息来标准化特征值。这有助于避免训练过程中的内部协变量偏移问题,即保证网络的每一层都在相似的数据分布上工作,从而提高模型训练的稳定性和速度。
之后数据进入前馈层,也就是前馈神经网络。
前馈层处理(编码器)
前馈全连接网络(FFN)对每个位置的表示进行独立的非线性变换,提升了模型的表达能力。通过两次线性映射和一个中间的ReLU激活函数,FFN引入了必要的非线性处理,使模型能够捕捉更复杂的数据特征。这一过程对于加强模型对序列内各元素的理解至关重要,提高了模型处理各种语言任务的能力。我们通过公式来解释一下。
$$FFN\left( x \right)=max(0,xW_1+b_1)W_2+b_2$$
输入 $x$ 就是上一层自注意力层的输出,首先通过一个线性变换,即与权重矩阵 $W_1$ 相乘并加上偏置向量 $b_1$,这一步的计算可以表示为 $xW_1+b_1$。权重矩阵 $W_1$ 和偏置向量 $b_1$ 是这一层的参数,它们在模型训练过程中学习得到。
接着,线性变换的结果通过一个ReLU激活函数max(0,.)。ReLU函数的作用是增加非线性,它定义为 $max(0,z)$,其中 $z$ 是输入。如果 $z$ 为正,函数输出 $z$;如果 $z$ 为负或0,函数输出0。这一步可以帮助模型捕捉复杂的特征,防止输出被压缩在线性空间内。
其次,max函数的输出再次通过一个线性变换,即与第二个权重矩阵 $W_2$ 相乘并加上第二个偏置向量 $b_2$。这一步可以表示为 $max(0,xW_1+b_1)W_2+b_2$,其中 $max(0,xW_1+b_1)$ 是第一层的输出。
最后,同样经过和自注意力层一样的Add & Norm处理,完成归一化输出。
之后数据进入下一个编码器或者解码器。这里我们不再讲解编码器,我们进入解码器。到这里,Transformer架构的上半部分,也就是编码器处理数据的部分就讲完了,下一节课我们讲解下半部分,数据是如何经过解码器的处理的。
小结
这节课我们主要讲解了Transformer输入和编码器部分的处理,记住4个要点:1+2+1。
- 1 表示位置编码,方便处理序列顺序。
- 2 表示两层:自注意力层和前馈网络层。
- 1 表示每一层进入下一层前都需要进行Add & Norm操作。
Transformer整体看是比较有难度的,这节课我们讲了整体的概念,实际操作起来还是比较复杂的,涉及大量的张量计算、函数计算,我们会在后面的章节中,手把手敲一个Transformer模型,到时候可以再进一步深入理解。
思考题
这里我给你一个复杂的句子,比如,这部电影不坏,但也不算特别好。Transformer如何理解这种双重否定句子的情绪偏向?你可以思考下。欢迎你把思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- _jordan 👍(12) 💬(4)
结合线形代数来理解就好理解了,大模型在数学上的原理其实很简单。 1. 向量的分解(投影到子空间) 在多头注意力机制中,查询(Query)、键(Key)、值(Value)向量首先被分割成多个子向量。在线性代数中,这可以看作是将一个高维向量投影到多个低维子空间。2. 线性变换的应用 在每个头中,都会对这些子向量应用注意力机制。这些操作本质上是对向量在低维空间中的一种线性变换。在每个子空间中,查询、键和值向量分别进行如下操作:这实际上是一种通过线性代数中的矩阵运算,计算向量之间的相似性并应用到值向量上的过程。尽管这里用到了 softmax 函数来归一化注意力权重,但本质上,每个注意力头中的操作都是在一个低维子空间中进行的矩阵乘法,这仍然属于线性代数范畴。 在这个阶段,向量在每个头中进行的变换都依赖于相应的投影矩阵和后续的点积相似度计算。每个子空间中的结果是独立的,但仍然保持线性的变换结构。3. 重新组合的线性变换 在每个头独立地完成注意力计算后,所有这些低维空间中的向量被拼接在一起,形成一个新的高维向量。这可以用拼接操作来表示,形式上相当于将多个线性变换的结果组合成一个更大的向量:这一步并不是矩阵乘法,而是通过简单的拼接将每个子向量连接成一个完整的高维向量。 最后,为了确保拼接后的向量维度与原始输入的维度一致,应用了一个线性变换:这个步骤的目的在于将不同子空间中捕获的特征重新映射回原始空间中。4. 能否恢复原来的向量? 从线性代数的角度来看,能否恢复原始向量取决于两个关键因素: 投影是否为可逆的。 是否丢失了信息。 投影的可逆性: 投影到低维子空间后,理论上来说,单独的投影操作是不可逆的,因为在投影到较低维度时,一部分信息被压缩或丢失了。例如,从 512 维向量投影到 64 维,意味着我们丢失了一部分维度上的信息。因此,单个头的投影操作无法恢复出完整的原始向量。 信息重构: 虽然单个头的投影无法完全保留原始信息,但由于我们有多个头(每个头是独立的线性投影),模型通过多个子空间的组合能够捕捉到输入的不同特征。因此,多个头的组合实际上可以帮助模型在不同方向上恢复原始向量的不同成分,并在重新组合时保留大部分信息。 因此,虽然单个头的投影是不可逆的,但是通过多个头的组合和最后的线性变换,可以很好地近似恢复原始的高维向量。换句话说,最终的输出保留了大部分输入信息,同时还引入了模型从多个不同子空间中学习到的特征。
2024-09-12 - Standly 👍(6) 💬(1)
完了,上一节还能骗自己看懂了,这一节彻底看不懂了
2024-07-10 - 张申傲 👍(6) 💬(0)
第14讲打卡~ 思考题:Transformer模型可能会先通过自注意力机制,识别出“不坏”和“不算特别好”这两个形容词,它们都是表达情感,但是在偏向性上有所不同,所以需要分析它们共同作用下的整体倾向。之后,Transformer可能会基于位置编码,判断出“不算特别好”是出现在“不坏”之后,并且使用“但”表达了情感转折,因此可能更倾向于后面的表达。最终整体的情感可能是轻微偏向负面的。 当然这只是理论上的推测,实际上这种比较模糊的情感表达,即使人类也未必能完全理解正确。
2024-06-28 - _jordan 👍(5) 💬(0)
5. 小结 从线性代数角度,多头注意力中的向量分割可以理解为将原始向量投影到多个低维子空间。 每个头在独立的子空间中执行线性变换,捕捉不同的特征。 最终通过拼接和线性变换,模型重新组合子空间中的特征,将它们映射回原始的高维空间。 单个子空间中的线性变换不可逆,但多个头的组合能够重建输入的丰富特征,并通过线性变换确保输出维度和输入一致。 因此,虽然经过分解和线性变换的向量并不完全等同于原始向量,但通过多头的组合,它们能够捕捉到原始向量的多个方面,使得模型能够从不同的视角理解输入数据,并最终生成富有意义的输出。
2024-09-12 - 石云升 👍(5) 💬(0)
1. 词嵌入和位置编码 首先,句子中的每个词都会被转换为向量表示(词嵌入),并添加位置信息: "这部 电影 不坏,但 也 不算 特别 好。" 2. 自注意力机制 在自注意力层,模型会计算句子中每个词与其他词的关系: "不坏"会与"电影"建立强联系 "不算"会与"特别好"建立强联系 "但"作为转折词,会得到特别的关注 3. 多头注意力 不同的注意力头可能关注句子的不同方面: 一个头可能专注于否定词("不坏"、"不算") 另一个头可能关注情感词("坏"、"好") 第三个头可能注意句子结构,特别是转折词"但" 4. 语义理解 通过多层编码器的处理,模型逐步构建对句子的深层理解: 理解"不坏"是一个轻微的正面评价 理解"不算特别好"是一个轻微的负面评价 捕捉到"但"表示前后两部分存在对比 5. 情感分析 在最后的处理阶段,模型会综合所有信息来判断整体情感倾向: "不坏"略偏正面 "不算特别好"略偏负面 "但"表示后半句更重要 最终,模型可能会得出这是一个略微偏向负面,但基本中性的评价。 6. 上下文理解 如果这句话在更大的上下文中,Transformer还会考虑周围的句子来进一步调整理解。
2024-09-03