16 从零开始,构建一个具有100M参数规模的Transformer模型
你好,我是独行。
前两节课,我从理论层面向你介绍了Transformer的架构原理,到现在为止,我们所有介绍基础理论知识的部分基本结束了。从这节课开始,我们会进入实战环节,对模型的设计、构建、预训练、微调、评估等进行全面的介绍,所以接下来的课程会越来越有意思。这节课,我们先来学习下,如何从0到1构建基于Transformer的模型。
选择模型架构
Transformer架构自从被提出以来,已经演化出多种变体,用来适应不同的任务和性能需求。以下是一些常见的Transformer架构方式,包括原始的设计以及后续的一些创新。
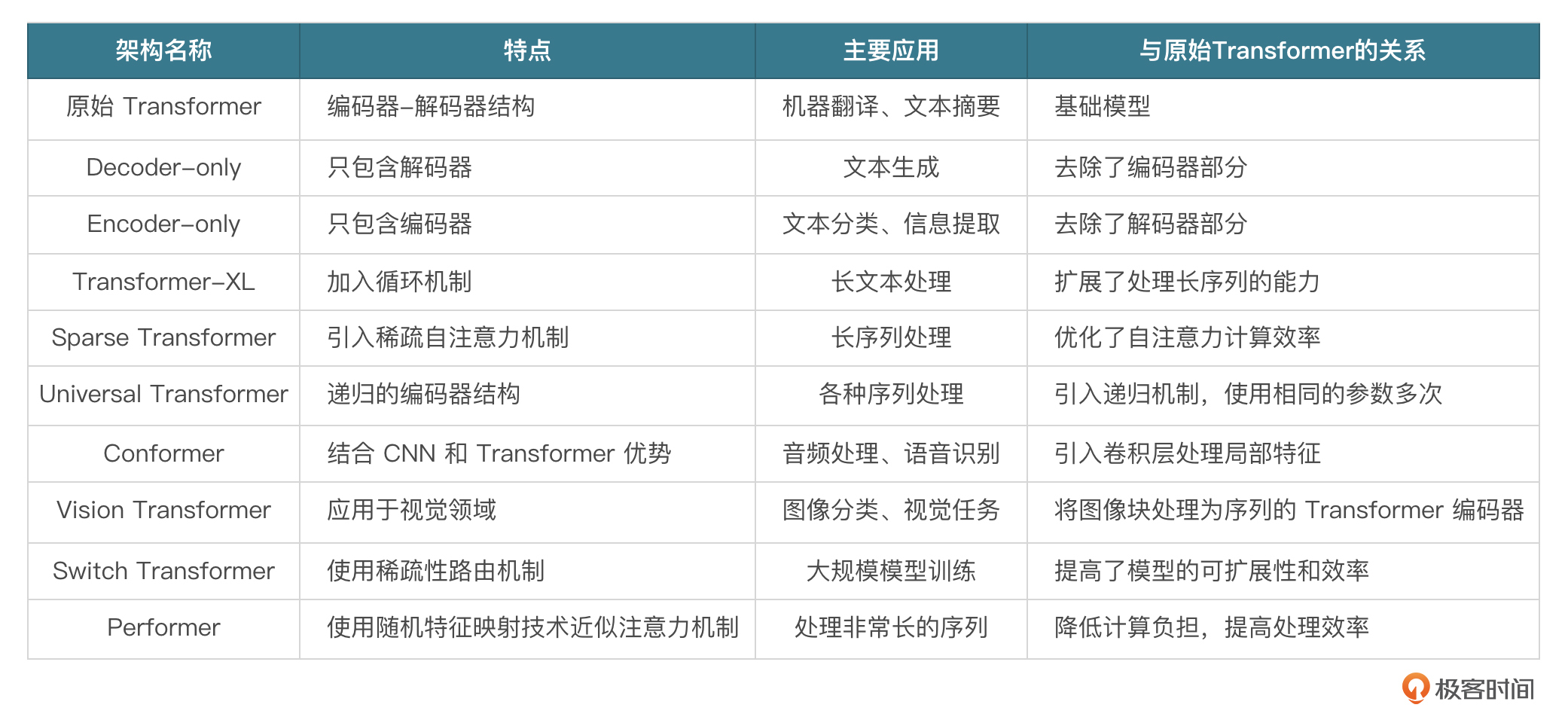
我们熟知的GPT系列模型,使用的是Decoder-only架构,Google的Bert模型使用的是Encoder-only架构。GPT系列模型之所以选择使用Decoder-only架构,主要出于以下几点考虑:
- GPT是语言模型,根据给定的文本预测下一个单词,而解码器就是用来生成输出序列的。
- Decoder-only模型采用自回归方式进行训练,在生成每一个新词时,都会利用之前所有已生成的词作为上下文。这种自回归的特性使得GPT能够在生成文本时保持内容的连贯性和逻辑性。
- 与编码器-解码器结构相比,Decoder-only架构简化了模型设计,专注于解码器的能力。
其他原因如并行性、长距离依赖、自注意力就不讲了,这是Transformer架构的通用特点,我们这节课就基于Decoder-only架构构建一个模型。
构建模型
模型设计比较复杂,需要先设计模型大概的结构,比如层数、多头注意力头数、隐藏层层数等,甚至词汇表大小都要有一个预估,根据这些参数,我们可以大概计算出模型的参数量,然后根据Scaling Law,计算出大概需要的运算量,进而评估训练成本。
Scaling Laws,简单理解就是随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,这三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系,其中包含一个计算公式:浮点运算量(FLOPs)C、模型参数N以及训练的token数D之间存在关系:$C\approx6ND$。不过需要注意,这个公式成立的前提是,我们的模型基于Decoder-only架构。
我们先来看看参数规模的计算方式:总参数量=嵌入层参数量+位置编码参数量+解码器层参数量+线性输出层参数量。
- 嵌入层参数量 = vocab_size * embed_size
vocab_size是指词汇表的大小,预训练数据集处理后会转换成词汇表,vocab_size就是这个词汇表的大小;embed_size是指词嵌入向量的维度数,简单理解就是每个词的特征数。
- 位置编码参数量 = embed_size
- 解码器层参数量 =(自注意力机制参数量 + 前向馈网络参数量)* 层数
自注意力部分通常包括四个核心组件的参数。
- 查询矩阵 (Q):embed_size * embed_size
- 键矩阵 (K):embed_size * embed_size
- 值矩阵 (V):embed_size * embed_size
- 输出线性变换:embed_size * embed_size
所以自注意力机制参数量 = 4 * embed_size * embed_size,前馈网络参数量 = 2 * (embed_size * hidden_dim),hidden_dim是指隐藏层层数。
- 线性输出层参数量 = vocab_size * embed_size
总参数量N = vocab_size * embed_size+embed_size+(4 * embed_size * embed_size+2 * embed_size * hidden_dim)* 层数 + vocab_size * embed_size。公式大概就是这样的,我们先不计算最终结果,因为vocab_size取决于训练文本大小以及分词方式,所以参数量先放放,我们继续往下看。
我们接下来定义一个简单的Transformer模型,每行代码都有注释,你可以看下。
import torch
from torch import nn
# 定义一个仅包含解码器的Transformer模型
class TransformerDecoderModel(nn.Module):
def __init__(self, vocab_size, embed_size, num_heads, hidden_dim, num_layers):
super(TransformerDecoderModel, self).__init__() # 调用基类的初始化函数
# 创建嵌入层,将词索引转换为嵌入向量
self.embed = nn.Embedding(vocab_size, embed_size)
# 初始化位置编码,是一个可学习的参数
self.positional_encoding = nn.Parameter(torch.randn(embed_size).unsqueeze(0))
# 定义一个Transformer解码器层
decoder_layer = nn.TransformerDecoderLayer(d_model=embed_size, nhead=num_heads, dim_feedforward=hidden_dim)
# 堆叠多个解码器层构成完整的解码器
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
# 定义输出层,将解码器输出转换回词汇空间
self.fc = nn.Linear(embed_size, vocab_size)
def forward(self, src):
# 嵌入输入并添加位置编码
src = self.embed(src) + self.positional_encoding
# 生成源序列的掩码,用于屏蔽未来的信息
src_mask = self.generate_square_subsequent_mask(src.size(0))
# 通过解码器传递源数据和掩码
output = self.transformer_decoder(src, src, src_mask)
# 应用线性层输出最终的预测结果
output = self.fc(output)
return output
def generate_square_subsequent_mask(self, sz):
# 生成一个上三角矩阵,用于序列生成中遮蔽未来位置的信息
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
# 将掩码的非零位置设为无穷大,零位置设为0
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
__init__方法类似于Java里类的构造函数,用来初始化属性。forward方法是前向传播的具体实现,generate_square_subsequent_mask方法用来生成掩码矩阵。这个类会在训练的时候进行实例化。在正式训练之前,我们先看下怎么准备数据。
准备训练数据
本次训练我找的是一个公开的中文wiki数据集。因为是自回归训练,所以不需要使用像翻译模型那种语料对,而是直接使用自然语言文本。单条文本格式如下:
{"id": "66", "url": "https://zh.wikipedia.org/wiki?curid=66", "title": "信息学", "text": "信息学\n\n信息学,旧称情报学(外来语),主要是指以信息为研究对象,利用计算机及其程序设计等技术为研究工具来分析问题、解决问题的学问,是以扩展人类的信息功能为主要目标的一门综合性学科。\n\n\n作为一门新型的综合性学科,信息学的理论主要是建立在数学中的离散数学之上的。因为信息学所研究的对象信息本身即是离散体。在某些特定的条件下,信息学与计算机科学是等价的。\n"}
不需要ID和URL这些,只保留text字段,所以先进行文本预处理。你可以看一下文件目录。
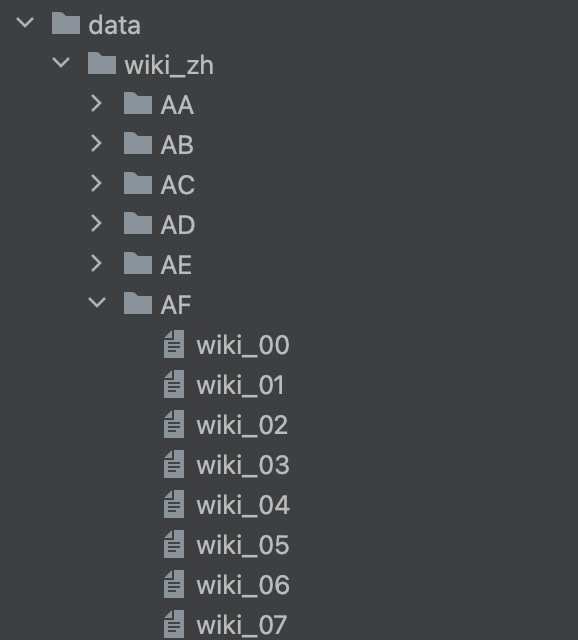
循环遍历子目录,然后分别读取每个文件里的文本,再从json格式的数据里抽取text字段对应的数据,保存成sentence.txt文件。抽取完成的sentence.txt文件有1.2GB。你可以参考我给出的代码。
import json
import os
class PrepareData():
@staticmethod
def prepare():
root_dir = 'data/wiki_zh'
ds = []
for dir_path, dir_names, file_names in os.walk(root_dir):
for file_name in file_names:
file_path = os.path.join(dir_path, file_name)
if "." in file_path:
continue
with open(file_path, 'r') as file:
for line in file:
try:
text = json.loads(line)["text"]
print(text)
ds.append(text)
except json.JSONDecodeError:
print("格式不正确")
print(len(ds))
with open('data/sentence.txt', 'w') as file:
for i in ds:
file.write(i + '\n')
return ds
data_set = PrepareData.prepare()
for item in data_set:
print(item)
数据处理好,我们就可以开始训练了。
训练模型
模型训练是非常复杂的过程,也是最消耗资源的过程。我们先定义一个数据集处理类,将sentence.txt里的内容逐行读入,使用jieba进行分词,转化成词汇表保存到本地。
# 导入必需的库
from torch.utils.data import Dataset
import torch
import jieba
import json
# 定义TextDataset类,该类继承自PyTorch中的Dataset
class TextDataset(Dataset):
# 初始化函数,filepath为输入文件路径
def __init__(self, filepath):
words = [] # 创建一个空列表来存储所有单词
# 打开文件并读取每一行
with open(filepath, 'r') as file:
for line in file:
# 使用jieba库进行分词,并去除每行的首尾空白字符
words.extend(list(jieba.cut(line.strip())))
# 将所有单词转换为一个集合来去除重复,然后再转回列表形式,形成词汇表
self.vocab = list(set(words))
self.vocab_size = len(self.vocab) # 计算词汇表的大小
# 创建从单词到整数的映射和从整数到单词的映射
self.word_to_int = {word: i for i, word in enumerate(self.vocab)}
self.int_to_word = {i: word for i, word in enumerate(self.vocab)}
# 将映射关系保存为JSON文件
with open('data/word_to_int.json', 'w') as f:
json.dump(self.word_to_int, f, ensure_ascii=False, indent=4)
with open('data/int_to_word.json', 'w') as f:
json.dump(self.int_to_word, f, ensure_ascii=False, indent=4)
# 将所有单词转换为对应的整数索引,形成数据列表
self.data = [self.word_to_int[word] for word in words]
# 返回数据集的长度减1,这通常是因为在机器学习中可能需要使用当前数据点预测下一个数据点
def __len__(self):
return len(self.data) - 1
# 根据索引idx返回数据,这里用于返回模型训练时的输入序列和目标输出
def __getitem__(self, idx):
# 从数据中提取最多50个整数索引作为输入序列
input_seq = torch.tensor(self.data[max(0, idx - 50):idx], dtype=torch.long)
# 提取目标输出,即索引位置的单词
target = torch.tensor(self.data[idx], dtype=torch.long)
return input_seq, target # 返回一个元组包含输入序列和目标输出
通过下面的代码加载数据集,并处理成DataLoader,DataLoader可以理解成数据迭代器,可以便利地进行数据加载、批次划分和数据打乱等操作。
# 加载数据集
dataset = TextDataset('data/sentence.txt')
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn, drop_last=True)
初始化模型:
# 初始化TransformerDecoderModel,设置特定的参数:
# vocab_size - 数据集中的词汇表大小
# embed_size - 嵌入层的维度(这里是512)
# num_heads - 多头注意力机制中的注意力头数(这里是8)
# hidden_dim - 变换器中前馈网络模型的维度(这里是2048)
# num_layers - 模型中的层数(这里是6)
model = TransformerDecoderModel(vocab_size=dataset.vocab_size, embed_size=512, num_heads=8, hidden_dim=2048, num_layers=6)
# 将模型传送到定义的设备上(例如GPU或CPU),以便进行训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 初始化优化器,这里使用Adam优化器,并设置学习率
# model.parameters() - 从模型中获取参数
# lr - 学习率(这里用变量learning_rate表示)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 初始化损失函数,这里使用交叉熵损失,适用于分类问题
criterion = nn.CrossEntropyLoss()
前面讲的计算参数规模的几个变量,基本都在这里了,我们再来看看参数量计算公式:总参数量N = vocab_size * embed_size + embed_size +(4 * embed_size * embed_size + 2 * embed_size * hidden_dim)* 层数 + vocab_size * embed_size
代入变量:N = vocab_size * 512 + 512 +(4 * 512 * 512+2 * 512 * 2048) 6 + vocab_size * 512,假设vocab_size = 100000(100000其实非常小,几个MB的训练数据,词汇量基本就能达到100000了),那么参数量N = 100000 * 512 + 512 +(4 * 512 * 512 + 2 * 512 * 2048) 6+100000 * 512 = 121,274,880,这已经是1.2亿规模的参数了。GPT-3的训练数据大约570GB,Transformer层数为96。你可以想象一下,1750亿参数是怎么来的。按照我们这个计算方式,不止1750亿了,所以我猜测embed_size没有512,就是说一个单词不一定需要那么多维度去描述。
接下来我们开始训练。
# 将模型设置为训练模式
model.train()
# 循环遍历所有的训练周期
for epoch in range(num_epochs):
# 循环遍历数据加载器中的每个批次
for i, (inputs, targets) in enumerate(dataloader):
# 将输入数据转置,以符合模型的期望输入维度
inputs = inputs.t()
# 在每次迭代前清空梯度
optimizer.zero_grad()
# 前向传播:计算模型对当前批次的输出
outputs = model(inputs)
# 选择输出的最后一个元素进行损失计算
outputs = outputs[-1]
# 计算损失值
loss = criterion(outputs, targets)
# 反向传播:计算损失的梯度
loss.backward()
# 更新模型的参数
optimizer.step()
# 每隔50步打印一次当前的训练状态
if i % 50 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{i + 1}/{len(dataloader)}], Loss: {loss.item()}')
# 保存模型到指定路径
torch.save(model, model_path)
print('模型已保存到', model_path)
训练过程太过于消耗资源,我的本地用的是A10-24G显卡,按照上面这个参数设置,准备了500M的训练文本,预估大概需要1个月时间才能跑完,所以为了快速出模型,我只截取了其中一部分训练数据,大概10M,用了半天时间进行训练。
模型测试
接下来加载训练好的模型,然后对输入语句进行分词等等,你可以参考下面的代码:
# 导入所需库
import torch
import json
import jieba
def load_model(model_path):
# 加载模型到CPU
model = torch.load(model_path, map_location=torch.device('cpu'))
# 设置为评估模式
model.eval()
return model
def load_vocab(json_file):
"""从JSON文件中加载词汇表。"""
# 读取词汇表文件
with open(json_file, 'r') as f:
vocab = json.load(f)
return vocab
def predict(model, initial_seq, max_len=50):
# 加载数字到单词的映射
int_to_word = load_vocab('int_to_word.json')
# 确保模型处于评估模式
model.eval()
# 关闭梯度计算
with torch.no_grad():
generated = initial_seq
# 生成最多max_len个词
for _ in range(max_len):
input_tensor = torch.tensor([generated], dtype=torch.long)
output = model(input_tensor)
predicted_idx = torch.argmax(output[:, -1], dim=-1).item()
generated.append(predicted_idx)
# 如果生成结束标记,则停止生成
if predicted_idx == len(int_to_word) - 1:
break
# 将生成的索引转换为单词
return [int_to_word[str(idx)] for idx in generated]
def generate(model, input_sentence, max_len=50):
# 使用结巴分词对输入句子进行分词
input_words = list(jieba.cut(input_sentence.strip()))
# 加载单词到数字的映射
word_to_int = load_vocab('word_to_int.json')
# 将单词转换为索引
input_seq = [word_to_int.get(word, len(word_to_int) - 1) for word in input_words]
# 生成文本
generated_text = predict(model, input_seq, max_len)
# 将生成的单词列表合并为字符串
return "".join(generated_text)
def main():
# 定义输入提示
prompt = "hello"
# 加载模型
model = load_model('transformer_model.pth')
# 生成文本
completion = generate(model, prompt)
# 打印生成的文本
print("生成文本:", completion)
if __name__ == '__main__':
# 主函数入口
main()
得到结果:
简直不忍直视,因为训练有限,所以得到这个结果在意料之中,不过基本流程都跑通了。想要模型性能好,是要一步一步调的,这也是我们说前提要有大量的计算资源的原因。
小结
这节课我带你手敲Transformer模型,总共加起来不到300行代码,实际上如果你阅读过GPT-2和BERT的模型构建代码,你会发现它们也没有多少行,所以模型构建本身其实并不复杂,模型的构建过程就是整个深度神经网络的架构过程,虽然有一点难度,但是没有想象的那么难,而我认为难点在于预训练过程,既吃训练资源又需要考虑训练效果,如何调整参数让训练效果更好是难点,这和传统CV小模型有点类似。
你也可以参考下面这个说明:
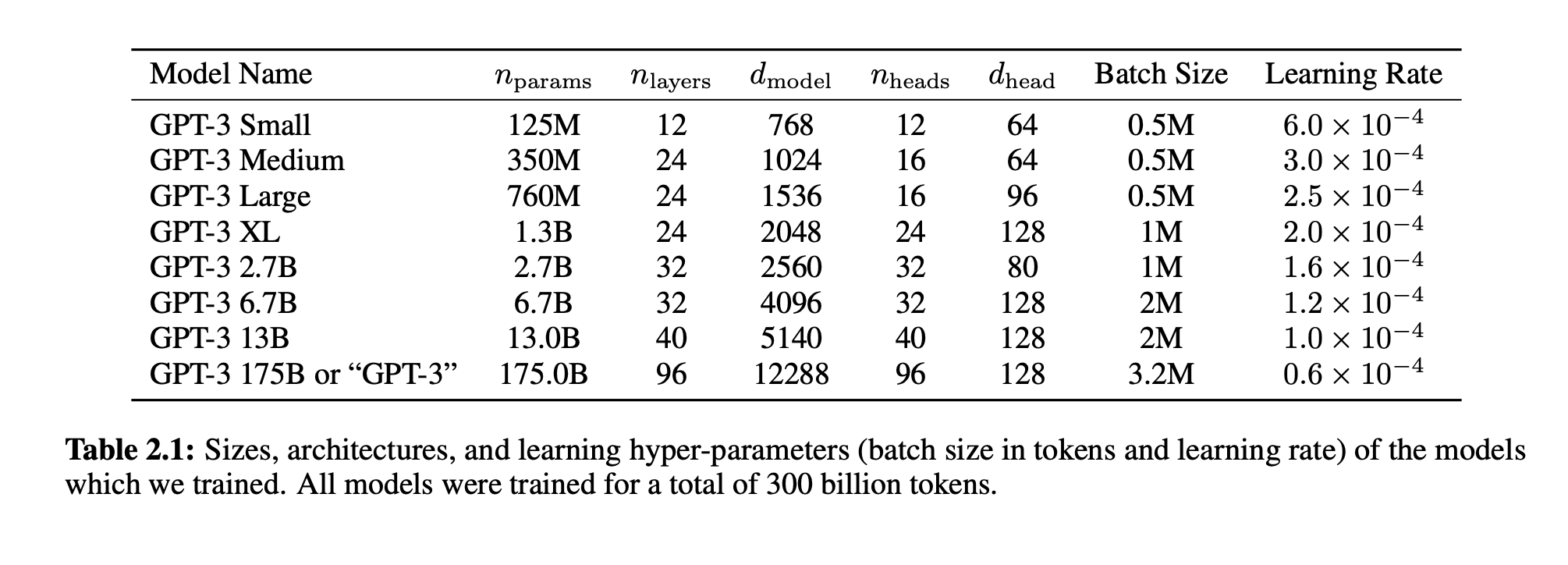
这是 GPT-3 论文里给出的不同参数规模下的设置,你可以根据自己的资源情况,选择适合自己的训练数据集以及设置合适的参数,比如embed_size,可以调小一点,隐藏层深度hidden_dim也可以适当调小一点,训练一个模型实际跑一遍,看看效果。
思考题
在这节课开头,我们提到过Scaling Law中的一个计算公式 $C\approx 6ND$,你可以思考一下,按照我们上面提到的参数量(1.2亿)和训练数据集大小(1.2GB),算一下训练过程需要多少算力资源,如果换算成A100-80G显卡,需要多少张?欢迎你在评论区留下你的计算结果,如果你觉得这节课的内容对你有帮助的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- newCheng 👍(7) 💬(1)
老师,帮忙推荐一台深度学习的电脑配置呗,或者有没有合适的云平台?
2024-07-04 - 张申傲 👍(6) 💬(1)
第16讲打卡~ 这里简单补充一下GPT和Bert这两种模型的差异:GPT是Decoder-only架构,并且采用单向注意力机制,这意味着在生成文本时,它只考虑前面的上下文信息;而Bert是Encoder-only架构,并且采用双向注意力机制,也就是可以同时考虑上文和下文的信息。这两种结构的差别,也就决定了GPT和Bert有各自擅长的应用场景:GPT更擅长文本生成,也就是“续写”,即根据上文生成下文;而Bert可以被应用于更广泛的NLP任务中,如文本分类、情感分析、命名实体识别等。
2024-07-03 - 石云升 👍(4) 💬(1)
C ≈ 8.64 * 10^17 FLOPs A100-80G的理论峰值性能是312 TFLOPS,即每秒可以进行: 312 * 10^12 = 3.12 * 10^14 FLOPs/s 理论上最快完成时间: 时间 = 总FLOPs / 每秒FLOPs = (8.64 * 10^17) / (3.12 * 10^14) ≈ 2,769 秒 ≈ 46 分钟 所以,理论上使用一张A100-80G显卡,最快约46分钟就能完成训练。
2024-09-05 - 张 ·万岁! 👍(1) 💬(1)
参数量1.2亿,要训练的词元数 理论上,如果光看模型的内存,一张a100 80gb完全可以容纳得下来,因为120,000,000×4÷1,024÷1,024=457.763671875MB,绰绰有余。 算力上来看的话,我没太懂这个问法。按照我的理解来算,12gb的训练文本一共大概800万条样本,每个样本50个词元,词元数D=4亿。再算上参数量1.2亿。那么总的计算量就是C=2.88*10^17。 英伟达的a100 80gb的32位浮点运算的峰值是19.5tflops,也就说1.95*10^13。 那么有(2.88×10^(17))÷(1.95×10^(13))=14769.23 也就说等于14769张a100的算力? 总感觉我算的一点也不对。。。
2024-07-25 - Geek_f80ce5 👍(0) 💬(1)
老师,完整代码能分享下吗?根据课程中的代码,执行到中间会一直等待。不知道为什么
2024-12-28 - Geek_f80ce5 👍(0) 💬(1)
这个源代码有吗?
2024-12-26 - Lane 👍(0) 💬(1)
collate_fn应该怎么实现呢
2024-12-10 - Lane 👍(0) 💬(1)
代码缺失的地方呢
2024-12-10 - 就在这儿💋 👍(0) 💬(2)
老师,有没有完整的代码文件呀,课程里的示例代码缺了一些内容, DataLoader的 collect_fn是没有的
2024-07-16 - 大宽 👍(0) 💬(1)
老师 大模型训练都用哪些框架呢,pytorch 吗,还有其他工具不 ,或者咱国内的一些大模型都用什么框架训练的呢。老师可否整体介绍一下,一个模型从训练到推理 做成 api 需要的步骤及其对应的技术工具哈?
2024-07-13 - Lee 👍(0) 💬(1)
老师 能说说训练时间怎么预估吗
2024-07-08 - 翔 👍(0) 💬(1)
课程到这里,没人互动了,是不是都掉队了😟
2024-07-02 - 翔 👍(0) 💬(1)
训练模型必须要用显卡吗,跑一丢丢测试数据,用 cpu 不行吗
2024-07-02 - 乔克哥哥 👍(0) 💬(0)
自注意力参数的计算是不是直接把多头的参数合并一起算了,刚开始看没反应过来
2025-02-07 - Geek_4d9162 👍(0) 💬(0)
老师 求助,中文 wiki 数据集下载页面打不开, 能否上传一个阿里云盘或者腾讯云盘的,百度网盘下载太慢了。
2024-12-07