17 模型解剖:探究模型内部到底是什么?
你好,我是独行。
上节课我们手敲了一个Transformer模型,实际最终训练出来的模型,参数量大概在1.2亿左右,文件大小约505M,这一节课我们再来探究一个非常有意思的问题:这个505M的文件内部到底存放的是什么?
前段时间我们本地运行过ChatGLM3-6B,你还记得吗?6B的模型文件分为8个,有的版本是5个,几个文件加在一起大约20G,6B的爷爷130B模型文件加起来近240G。不知道你有没有同样的疑问,在我最早接触大语言模型的时候,就非常好奇,大模型文件里到底存的是什么?随着不断地研究学习,总算有了一知半解,这节课就来和你分享一下。
模型文件
所谓模型文件,也可以叫模型权重,里面大部分空间存放的是模型的参数:权重(Weights)和偏置(Biases),当然也有一些其他信息,比如优化器状态、其他元数据,比如epoch数等。我们使用的是PyTorch框架,生成的模型权重文件格式是.pth,如果使用TensorFlow或者Hugging Face Transformers等框架,也有可能是.bin格式的文件。模型预训练完成后,我们可以调用下面的代码保存模型。
- 只保存权重
- 保存权重和架构(模型的结构)
一般来说,生产环境不建议把模型的架构也一起保存,因为这个方法保存的模型与Python的版本和模型定义的代码紧密相关,如果在不同的环境或PyTorch版本中加载,可能会遇到兼容性的问题。而方法一具有更好的兼容性,当你需要迁移到不同的平台或更新项目依赖的时候,这种方式通常会带来更少的问题。
权重和偏置
权重是神经网络中最重要的参数之一。在前向传播过程中,输入数据会与权重相乘,这是神经网络学习特征和模式的基本方式。权重决定了输入数据如何影响输出结果。
偏置是添加到加权输入之后的参数,用于调整输出。偏置允许模型输出在没有输入或所有输入都为零的时候调整到某个基线值。
我们可以简单理解,在线性方程 $y=kx+b$ 中,$k$ 就是权重,$b$ 就是偏置。在神经网络中,权重 $k$ 决定了每个输入特征对于输出的重要性和影响力。偏置 $b$ 是一个常数项,它提供除了输入特征之外的额外输入,允许模型输出可以在没有任何输入或所有输入都为零的时候调整到一个基线或阈值。
根据我们前面学习的神经网络相关的内容,我们知道,在复杂的神经网络中,每个神经元可能都有这样的权重和偏置,用来从前一层接收多个输入信号,对这些信号加权求和后加上偏置,然后通常通过一个非线性激活函数,比如tanh和relu来生成输出信号,这个输出信号会传递到下一层。每层的权重和偏置都是模型需要学习的参数,它们会根据训练数据进行调整,以最小化模型的预测误差。
模型可视化
通过一些工具,比如Netron、TensorBoard、torchviz等,我们可以窥探一下模型内部的结构。我们先通过Netron看一下之前训练好的模型的内部结构。Netron的使用方法比较简单,下载安装,然后运行软件,出现了这样一个页面:

我们直接点击Open Model,加载本地存放的权重文件。之后就出现了模型的结构图。
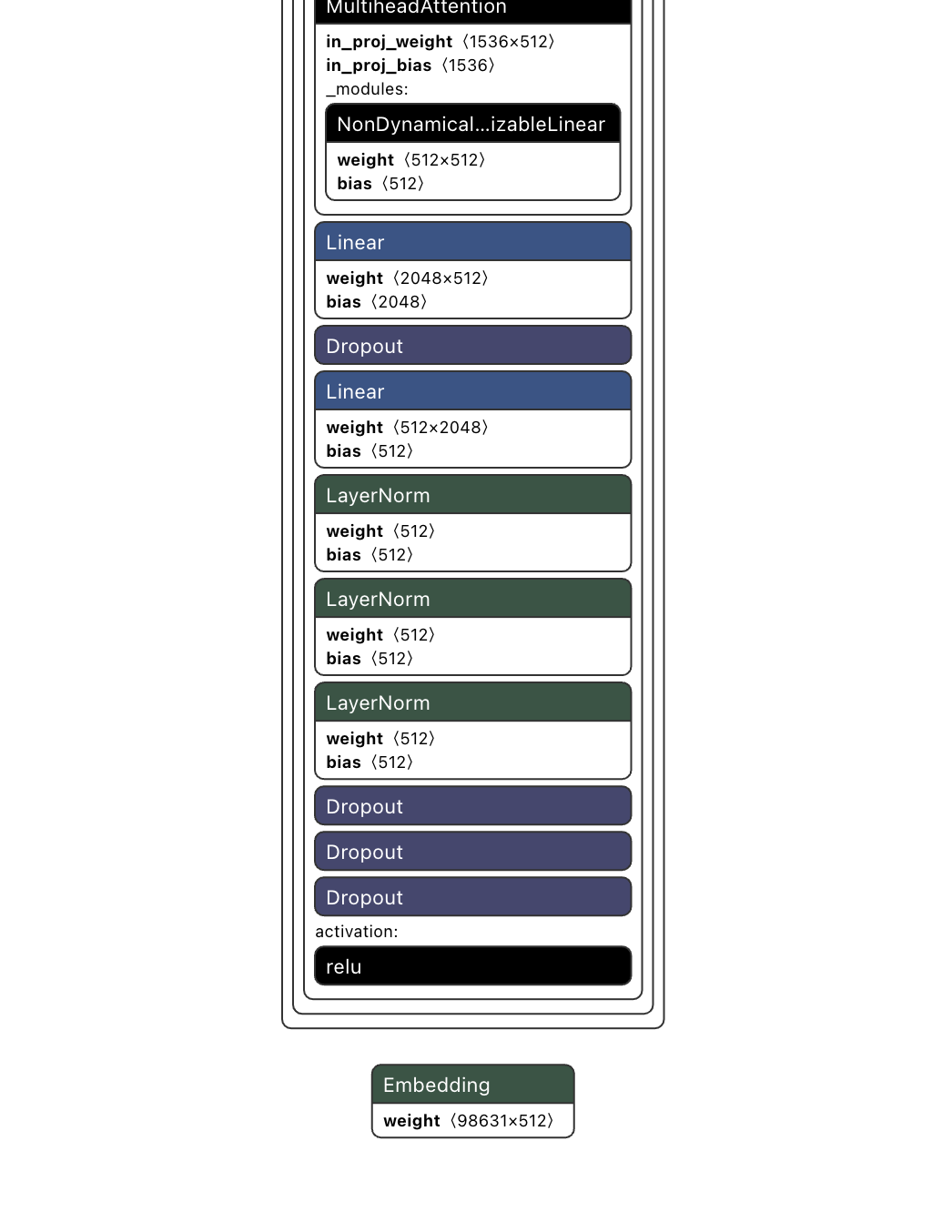
回想一下上节课构建模型的代码,我们设计这个模型的时候,选择了6层Transformer Decoder-only架构,通过可视化模型结构,我们可以看到模型内部包含的各个层,比如Embedding、6个TransformerDecoderLayer、Linear等。接下来我们挨个看一下。
Embedding层
点击第一个Embedding节点,右边会展示这个节点的详细信息。
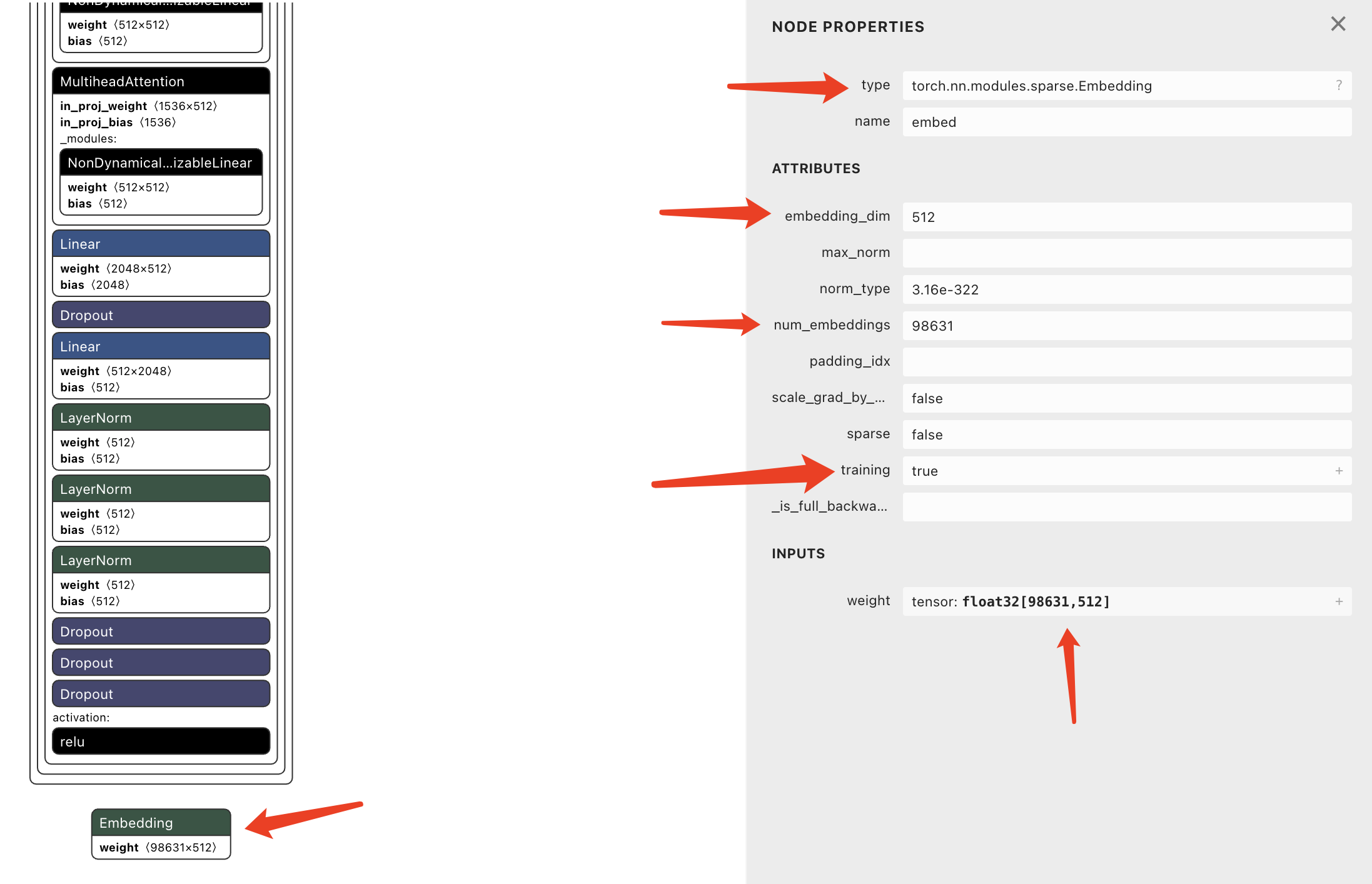
weight(98631*512)表明这是一个有98631行和512列的矩阵。在这个矩阵里,每一行对应一个特定的词向量。对一个词汇表中的每一个可能的词或标记,这个矩阵提供了一个512维的嵌入向量。在实际处理过程中,这一步不需要乘法计算,只需要一个索引查找操作即可。tensor: float32[98631,512]表明这是一个FP32精度的变量,98631表明训练时使用了98631个词汇。后面在模型轻量化的部分我会给你介绍精度的概念,这里我就不多说了。
TransformerDecoderLayer
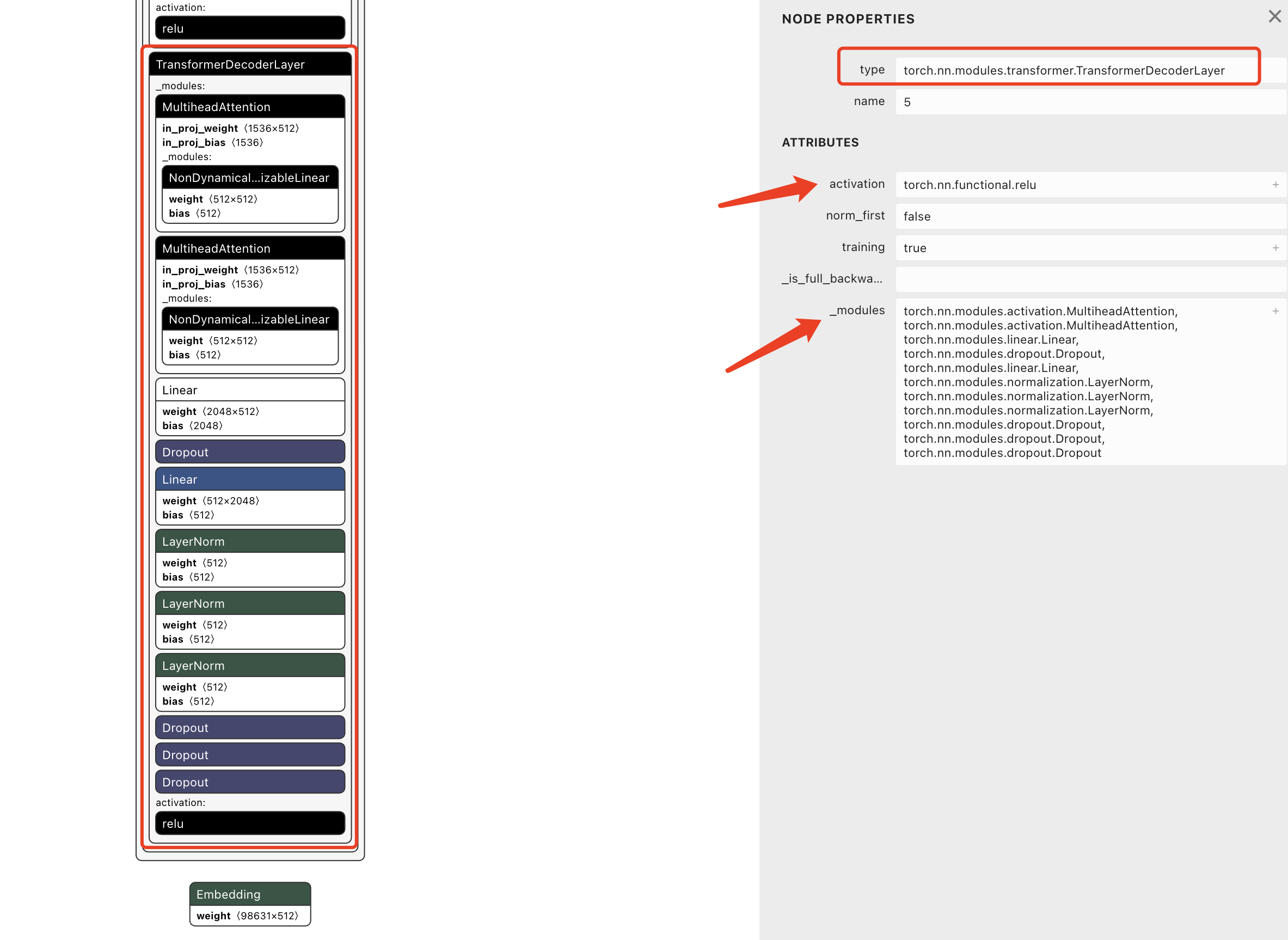
我们选中其中一个TransformerDecoderLayer层,右侧会展示这一层的详细信息,可以看到具体的实现类是torch.nn.modules.transformer.TransformerDecoderLayer,包含下面这些组件:
torch.nn.modules.activation.MultiheadAttention, torch.nn.modules.activation.MultiheadAttention,
torch.nn.modules.linear.Linear,
torch.nn.modules.dropout.Dropout,
torch.nn.modules.linear.Linear,
torch.nn.modules.normalization.LayerNorm,
torch.nn.modules.normalization.LayerNorm,
torch.nn.modules.normalization.LayerNorm,
torch.nn.modules.dropout.Dropout,
torch.nn.modules.dropout.Dropout,
torch.nn.modules.dropout.Dropout
这是模型的整体结构图,我们用另一个工具,查看一下具体的节点图。安装torchviz,执行下面的代码:
x = torch.randint(10000, (50,)) # 假设一个序列长度为10的输入
y = model(x)
dot = make_dot(y.mean(), params=dict(model.named_parameters()), show_attrs=True, show_saved=True)
dot.render(filename="net", format='png')
生成一张大的png图片,当然也支持pdf格式,改成 format='pdf' 就可以。实际测试下来,pdf比png清晰度更高,我截取了一部分图片,你可以看一下。
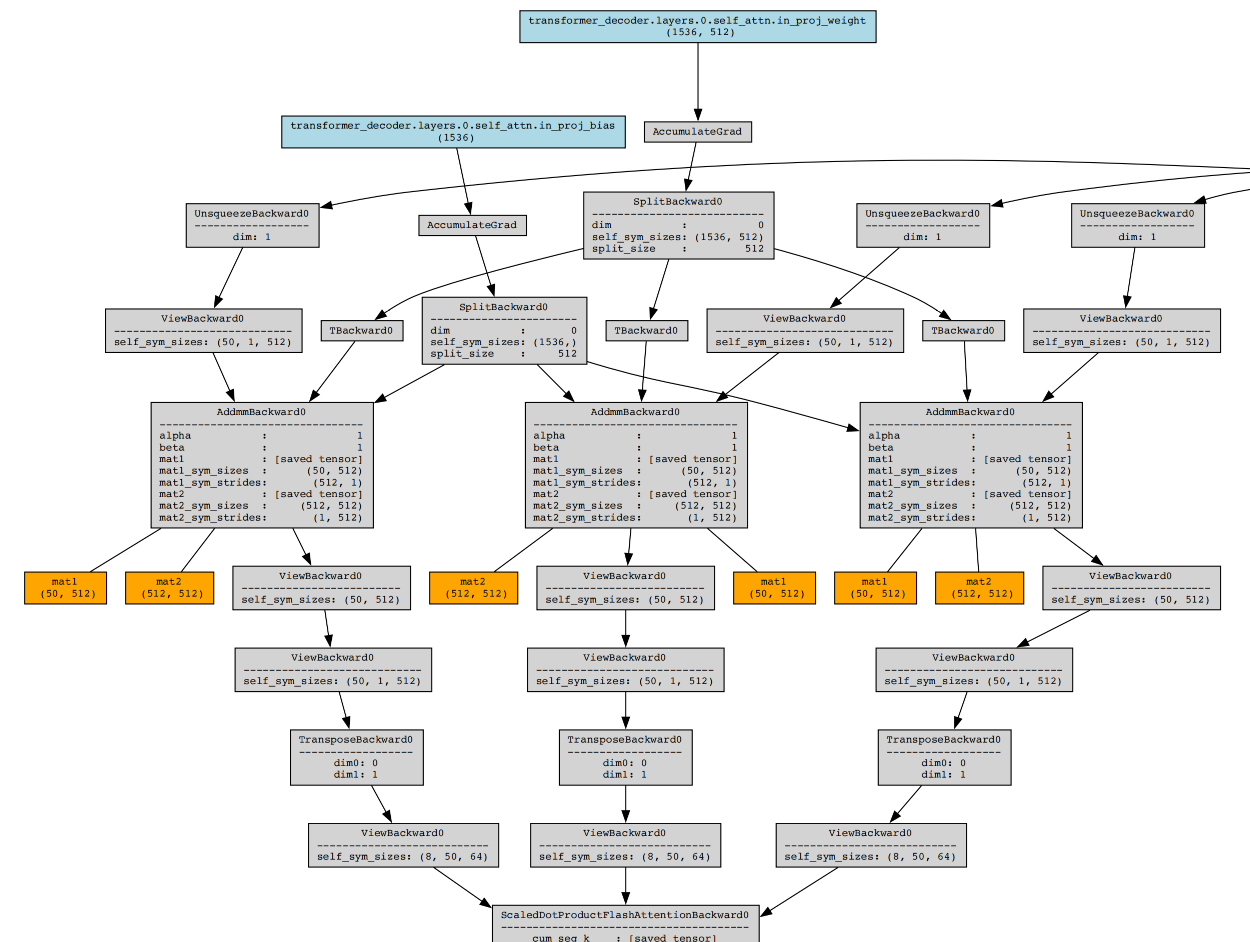
这里有整个网络结构的顺序图,具体每个节点的含义,感兴趣的话你可以查询下,比如AccumulateGrad、SplitBackward0、UnsqueezeBackward0这些,基本都是和计算损失相关的。你要知道,模型的训练过程就是不断调整权重的过程,调整权重的依据就是根据损失函数计算损失,通过反向传播不断调整权重使损失最小,达到理想损失值后,把权重记录下来保存。
在推理的时候就简单了,数据达到节点(神经元)后,先从输入层到隐藏层,再从隐藏层到输出层。每一层都执行类似 $y=kx+b$ 的公式计算,然后应用激活函数,比如 $a=ReLU(y)$,最后把 $a$ 继续传递到下一层,当做 $x_{2}$,下一层的权重 $k_{2}$ 和偏置 $b_{2}$ 是已知的,继续计算得出 $y_{2}$。实际应用公式可能会稍微复杂一点,前面第 14 课我们有讲过这方面的内容,这里就不赘述了。另外,基本都是张量相乘,而不是简单的整数小数相乘。
模型内部的逻辑基本就是这样,机器学习框架如PyTorch可以根据描述文件,将模型重构出来,进行训练和推理。接下来我们再看一下模型的容量。
模型容量
这节课我们使用的模型大小是505M,根据上节课模型参数量的计算方式,我们得出参数量N=1.2亿,模型的精度使用的是float32。也就是说,每个参数需要4字节的存储空间,所以我们大致算一下,纯参数方面需要约460M的空间(1.2亿*4/1024/1024),其余的40M空间可能存放的是模型结构、元数据等等。
上面我们提到的Embedding层,权重是tensor: float32[98631,512],表示在Embedding层参数量=98631*512=50491392,存储量大约在200M,所以这么看来Embedding层在存储方面基本就占用了整个模型的40%,参数方面,5049万/1.2亿也约等于40%,所以Embedding层在整个模型中的作用还是非常大的。
模型参数
基于这些知识,我们再来梳理一下参数的含义,还是以embedding层来解释,我们举一个小一点的例子,用5*10的矩阵来讲。

这是一个具有50个参数的矩阵,每个参数(矩阵中的每个数值)表示词向量在特定维度上的权重或特征。例如,第一行 [0.5, -0.2, 0.3, …, 0.7] 表示第一个词在10个不同特征维度上的数值表示。如果我们把Embedding层设置为“可训练”,那么在模型训练的过程中会根据损失计算,反向传播后更新某个参数,这样可以让模型更好地表示某个词,来达到训练的目的。在最终推理过程中,词向量会被传播下去,作为下一层的神经网络的输入,参与到后续计算过程中。
小结
这节课的内容比较有意思,而且很少有人从这个角度去分析。实际上是前面课程内容的一个反向理解,就好比通过Java字节码文件反推Java编码过程一样。我们来简单梳理下重点。
- 模型里存放的是各个层的权重和偏置,类似于 $y=kx+b$ 里的 $k$ 和 $b$。
- 机器学习框架如PyTorch可以识别模型文件,并且把模型结构重构出来进行训练和推理。
- 模型训练过程就是不断前向传播、损失计算、反向传播、参数更新的过程。
- 模型推理就是根据训练好的参数,进行前向传播的过程。
- 我们可以使用Netron、torchviz等工具可视化模型结构,辅助理解。
思考题
刚刚我们提到过,像6B、130B这些商用的大模型,权重文件是分开存放的,比如6B,8个权重文件,每个大约2GB,请你思考一下,为什么要这么设计?分开存放的话最终使用的时候是怎么合并的,或者说需不需要合并?这个问题有点难度,欢迎你在评论区留言和我一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎分享给其他朋友,我们下节课再见!
- 张申傲 👍(7) 💬(1)
第17讲打卡~ 思考题:把模型文件分开存储,感觉很像分布式系统中的Partition操作,比如Kafka就会把1个逻辑上的Topic拆分成多个物理上的Partition。如这样做的好处主要是两点:1. 多个文件便于并行计算,可以提高模型训练和推理的效率;2. 容错和冗余,如果某个模型文件出现了损坏,只恢复特定的文件即可,无需修复整个模型。如果是这样的话,多个模型文件应该是不需要手动合并的,在模型训练或推理时,模型框架应该会自动处理。 以上都是个人的猜想,欢迎老师指正~
2024-07-05 - 石云升 👍(2) 💬(1)
商用的大模型将权重文件分开存放有几个关键原因: 1. 单个文件大小的限制 在许多操作系统和文件系统中,单个文件的大小有一定的限制(如 FAT32 文件系统的单个文件最大为 4GB)。因此,分开存储模型权重文件可以避免单个文件过大,防止存储和加载过程中的错误。 2. 便于分布式训练和推理 大模型的权重文件分开存放有助于分布式训练和推理,特别是在多个 GPU 或节点上运行时。每个 GPU 或节点只需要加载一部分权重文件,不需要一次性加载整个模型。这种方式不仅减少了单个计算单元的内存负担,还可以加速加载过程。 3. 更快的数据传输和存储管理 将权重文件分成多个较小的文件,能够提高数据传输速度。例如,如果你要从云端或远程服务器上加载模型文件,小文件更容易并行传输,从而加速整体模型的加载。此外,分开存放文件在存储管理和备份时也更加灵活。 4. 内存管理更高效 对于大模型而言,系统内存(RAM)或显存(GPU memory)的使用非常紧张。分开存放权重文件,允许在运行时只加载和处理部分权重,避免一次性占用过多的内存。 分开存放的权重在使用时如何处理? 无需合并:在实际使用时,模型框架(如 PyTorch 或 TensorFlow)并不需要将所有的权重文件合并成一个大文件。相反,框架可以在需要时动态加载各个分片的权重。这种方式节省了内存开销,同时保持灵活性。 按需加载:当模型被加载到 GPU 或 CPU 上时,权重文件可以按照分片结构加载。以分布式训练为例,不同的计算设备(如 GPU)可以各自加载一部分权重,分别负责不同的计算任务。训练或推理时,框架会自动管理各个设备之间的数据传递。 举个例子: 假设我们有一个6B参数的模型,它被分成8个权重文件存放在磁盘上。启动推理时,模型并不需要一次性将8个文件全部加载到内存中。相反,每个文件只会在相关计算任务中按需加载,比如一个GPU加载权重文件1和2,另一个GPU加载权重文件3和4,各自处理不同部分的神经网络计算。 这种设计能有效避免内存和计算资源的浪费,同时最大化利用硬件资源。
2024-09-05 - 两三天 👍(0) 💬(1)
老师:模型参数小节Embedding矩阵中每个数字对应的现实含义是什么,或者能不能对照一个真实世界的例子举例说明?
2024-12-26 - 乔克哥哥 👍(0) 💬(0)
嵌入层和线性输出层的参数量是一样的,存储占用也是40%吗
2025-02-07