19 深入理解DeepSpeed,提高大模型训练效率
你好,我是独行。
前面第16课,我们从0~1手敲了Transformer,并且进行了一次完整的训练,当时我用的A10-24G显卡,准备了500M的训练文本,结果预估需要1个月时间才能跑完,可见训练对机器的要求有多么高,我们使用的数据集大小才500M,一般训练一个大模型,绝对不止这么点数据,而且参数规模也会更大。
据我所知,GPT-3和GLM-130B这种千亿规模的大模型,训练周期基本在3个月左右,所以按照我们目前的这种做法,肯定是不行的。那在实际的训练过程中,如何才能提高训练速度呢?
答案是使用分布式训练,目前比较流行的训练框架有微软的DeepSpeed和NVIDIA的NCCL等,这节课我们就主要聊聊微软的DeepSpeed。
DeepSpeed
DeepSpeed是由微软开发的一个非常优秀的分布式训练库,专为大规模和高效的深度学习训练设计,在分布式训练领域提供了多项创新的技术,比如并行训练、并行推理、模型压缩等。你可以看一下官方说明的4个创新点。

简单整理下:
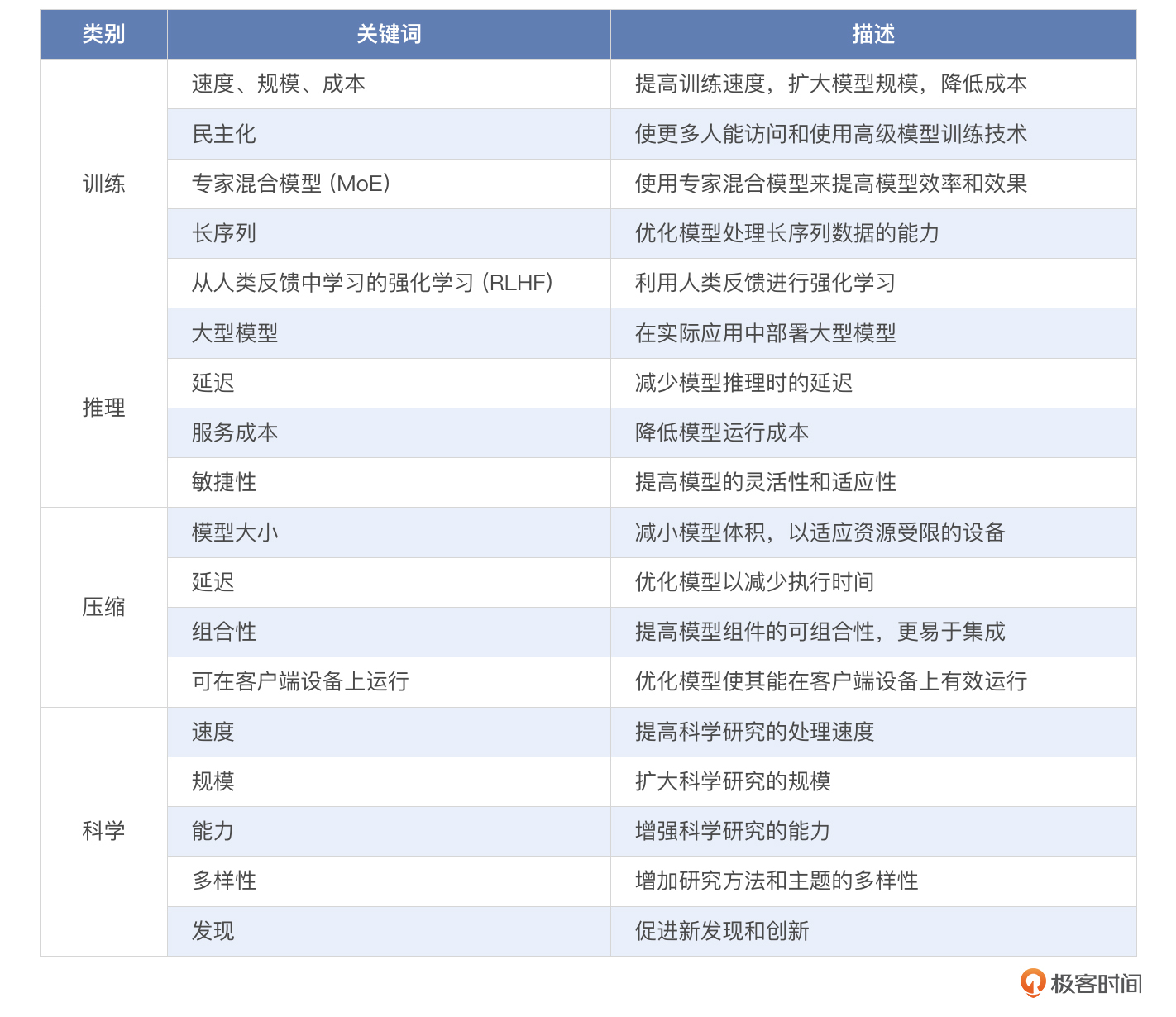
下面我就向你依次介绍DeepSpeed在这几方面的能力。
训练
对于复杂的深度学习模型,除了模型设计具有挑战性之外,使用先进的训练技术也尤为重要,比如分布式训练、混合精度、梯度累积和检查点等。DeepSpeed在这些方面比较擅长,可灵活组合三种并行方法:数据并行性、管道并行性和模型并行性,简称3D并行性,可适应不同工作负载的需求。目前已经支持超过一万亿超大参数的模型,实现了近乎完美的内存扩展和吞吐量扩展效率。
数据并行性
数据并行性是指将训练数据集切分成更小的切片,DeepSpeed提供了一种高效的数据并行方法,能够在不使用模型并行技术的情况下进行模型训练。例如通过一个单独的GPU,就能够处理多达130亿参数的模型。相比而言,传统的框架,比如PyTorch的分布式数据并行处理技术,最多在处理14亿参数时就可能会出现内存溢出。这里主要使用的是ZeRO技术,通过对模型状态和梯度进行分割,来大幅节约内存,并同时减少了激活和碎片内存的使用。现阶段的ZeRO-2能够将内存需求降低至八分之一。
模型并行性
模型并行性是指将模型的权重切分成更小的权重切片,切分方法有好几种,像层级并行、张量并行、专家并行等。模型并行主要是用在模型远大于设备显存的情况,比如模型大小为3100GB,而显存大小为80GB甚至40GB,当然处理起来也更加复杂。
管道并行性
管道并行性是指将模型分成几个较小的部分或“阶段”,并行化处理,每个阶段由不同的处理单元负责。通过这种方式,不同的输入数据可以在不同阶段同时进行处理,从而提高整体的处理效率和硬件利用率。每个处理单元负责其中一个部分的前向和反向传播。当一批数据完成在一个处理单元上的计算后,会被立即传送到下一个处理单元继续接下来的计算,而当前的处理单元则可以开始处理新的输入数据。
综合看,在实际应用中,数据并行性是最常见的模型并行化技术,通过将训练数据分批处理,然后将每个批次分配到多个处理单元上并行处理。每个处理单元都有模型的完整副本,并独立执行前向和反向传播,最后通过网络同步或汇总各个处理单元的梯度或参数更新,然后在每个模型进行参数更新操作。
当然对于更大的模型,层级并行和张量并行也相对常见,尤其是在需要训练大型模型(如大型Transformer模型)的场景中。这些方法能够分担单个GPU内存的负载,允许更大的模型在多个设备上进行训练。
推理
推理方面,目前最新的版本是DeepSpeed-FastGen,利用 DeepSpeed-MII 和 DeepSpeed-Inference 的组合来提供服务。在Llama2-70B上做测试,推理速度提升2.3倍。DeepSpeed-FastGen核心技术是Dynamic SplitFuse,就是将长提示分解成更小、更易于管理的块,这些块可以在多个前向传递中更高效地处理。大概处理流程是这样的:
- 将长的输入提示动态分解为更小、更易管理的块来工作。这些小块可以是词、短语或句子,取决于具体实现和模型的需求。这种分解允许系统并行处理多个块,从而优化了资源使用和响应时间。
- 分解后的小块将被组织成连续的批次,这些批次可以在不同的处理单元上同时进行前向和反向传递。连续批处理技术确保了系统可以持续处理输入,而不需要等待整个长提示处理完成,从而提高了整体的吞吐量,降低了延迟。
- 在处理每个批次时,Dynamic SplitFuse 使用一种优化的令牌组合策略,这种策略调整了令牌生成的顺序和速度,以最大化处理效率和输出质量。这可能涉及到智能地预测哪些令牌或块应该优先处理,以及如何最有效地利用可用的计算资源。
看到这儿,你可能要问了,一个提示被切成多份,不会影响原来的语义吗?答案是:会,所以Dynamic SplitFuse也做了一些策略来保证语义的完整性,比如通过一定的算法来确认切分点,尽量在语义的边界附近切分,减少上下文丢失的情况。同时,使用高级的模型,能够处理断断续续的语义,也是一个解法。
压缩
DeepSpeed Compression是一个专门构建的库,旨在使研究人员和从业人员能够轻松压缩模型,同时提供更快的速度、更小的模型大小,并显著降低压缩成本。官方说明,使用极限压缩技术,可将模型大小缩小 32 倍,而几乎没有精度损失,或者在保留 97% 的精度的同时实现模型大小缩小 50 倍,想想还是挺厉害的。
前面我们已经学习过模型的网络结构了,那你可以想一想,想要压缩模型,该从哪些方面入手?
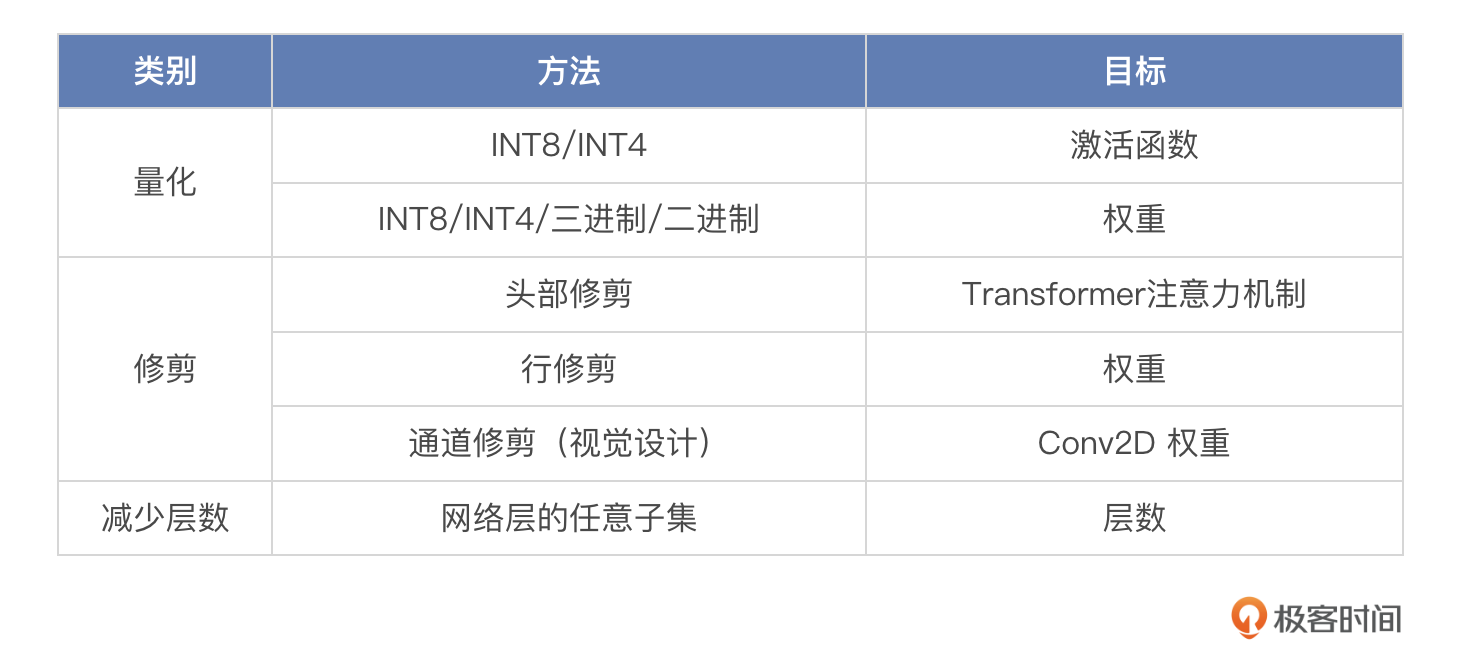
- 量化,也可以叫轻量化,记不记得我们在讲6B的时候提到,6B模型默认以FP32的精度运行,需要13GB的显存,如果你的电脑显存不够,可以以INT8甚至INT4轻量化模式运行。我们前面的课程讲过,计算模型大小的时候,参数如果以FP32的精度存储,占用4个字节的空间,那么如果我们量化成INT8(1字节)或者INT4(0.5字节),那么模型大小将减少到原来的1/4和1/8,当然,减少的不仅仅是存储空间,计算空间也相应减少。
- 修剪,和我们剪树枝一样,把那些长得歪的,枯掉的枝叶剪掉,放在这里,就是把那些不需要的结构去掉,比如头部修剪,去掉不需要的头,行修剪,把不重要的权重置为零值,通道修剪把不重要的卷积通道移除。
- 减少层数,需要先用工具分析层的重要性,来确定哪些层对最终预测结果的影响最小,哪些层是冗余的,然后进行层移除或者合并。
研究
微软DeepSpeed团队推出了一项名为DeepSpeed4Science的新计划,希望通过人工智能系统技术创新构建独特的能力,帮助领域专家解开当今最大的科学谜团,这块我就不详细讲解了,你感兴趣的话可以去官网看看,虽然定位是解决当今世界最大的科学谜团,不过既然放在DeepSpeed框架的一部分,那大概率还是聚焦在AI大模型上。从这一点不难看出,老外做事情还是很讲究情怀的,尤其是像微软和Google这类公司,很多时候,做事情的出发点并不是盈利,而是为了解决人类面临的一些问题,虽然最后可能都朝着盈利的方向发展,但做事情的初衷和我们很多人都不一样。
小结
这节课我从四个方面向你介绍了DeepSpeed的特点:训练、推理、压缩、研究。有些人认为,这块知识可能很少用得到,因为DeepSpeed很多时候是用在大规模分布式场景下的,不论是预训练,还是推理,起码要构建起一个集群的规模才会用得到。但我觉得不一定,因为像模型裁剪、量化这些操作,我们即便处理单一模型也用得到,而且随着技术的发展,未来很多“小规模”大模型也会登上历史舞台,比如1.2B、1.5B的模型,现在已经用在了车载终端上。
同时,作为一个扩展知识点,我觉得你也可以了解下,起码知道有这么个内容,对全方位理解模型也是有帮助的。
思考题
前面我们讲了DeepSpeed的几个使用场景,训练、推理、压缩,你可以思考一下,DeepSpeed是否适合用在微调场景?前面我们学习过基于Lora技术的微调过程,如果通过DeepSpeed+Lora进行微调,效果会怎么样呢?欢迎你把想法分享在评论区,也欢迎你把这节课分享给其他朋友。我们下节课见!
- 石云升 👍(4) 💬(0)
结合 DeepSpeed 和 LoRA,可以显著优化微调过程,尤其是在资源受限的环境下。 1.减少计算资源需求:LoRA 本身已经减少了微调的计算需求,再加上 DeepSpeed 的内存和计算优化,可以进一步降低显存占用和计算时间。例如,在微调 GPT-3 这样的大型模型时,DeepSpeed+LoRA 的组合可以让单个 GPU 处理更多的微调数据,从而提高效率。 2.提升微调速度:由于 LoRA 只需要对模型的部分参数进行调整,而不是对整个模型进行完整的更新,因此微调过程中的计算量大幅减少。DeepSpeed 的混合精度训练和 ZeRO 优化技术进一步加快了这个过程,从而可以在更短的时间内完成微调。 3.提高模型性能:DeepSpeed 的优化方法能够确保在微调过程中,计算资源的利用率达到最大化。同时,LoRA 只在模型的特定部分进行更新,减少了过拟合的风险。因此,两者结合可以在较短时间内实现更好的性能,同时保持模型的泛化能力。
2024-09-05