24 架构设计(上):企业如何设计大模型应用架构?
你好,我是独行。
截止到上一节课,大模型本身的基础知识和实践你已经学得差不多了,这节课我们深入大模型的规模化落地过程,把前面学习过的大部分知识都融合进来,你可以把这节课当做企业内部落地大模型的技术方案,我会把各种需要考虑的细节全部放进去,我们就拿上一节课提到的批量处理发票作为场景。
需求背景
在日常出差报销流程中,我们需要单次/批量上传发票,手动填写行程单,非常耗时且繁琐,本次需求将实现这个场景的自动化,不仅可以节省时间,还可以提高数据处理的准确性。本次需求存在几个难点:
- PDF处理,包括长文本切割、OCR高精度识别、文字组装等;
- 向量库语义准确性、向量库性能;
- 数据安全与隐私;
- 大模型运维与部署;
- 大模型、Agent系统集成等;
- 知识库的维护。
下面我们思考下系统架构。
系统架构
系统由产品、AI中台以及后台管理系统几部分组成。
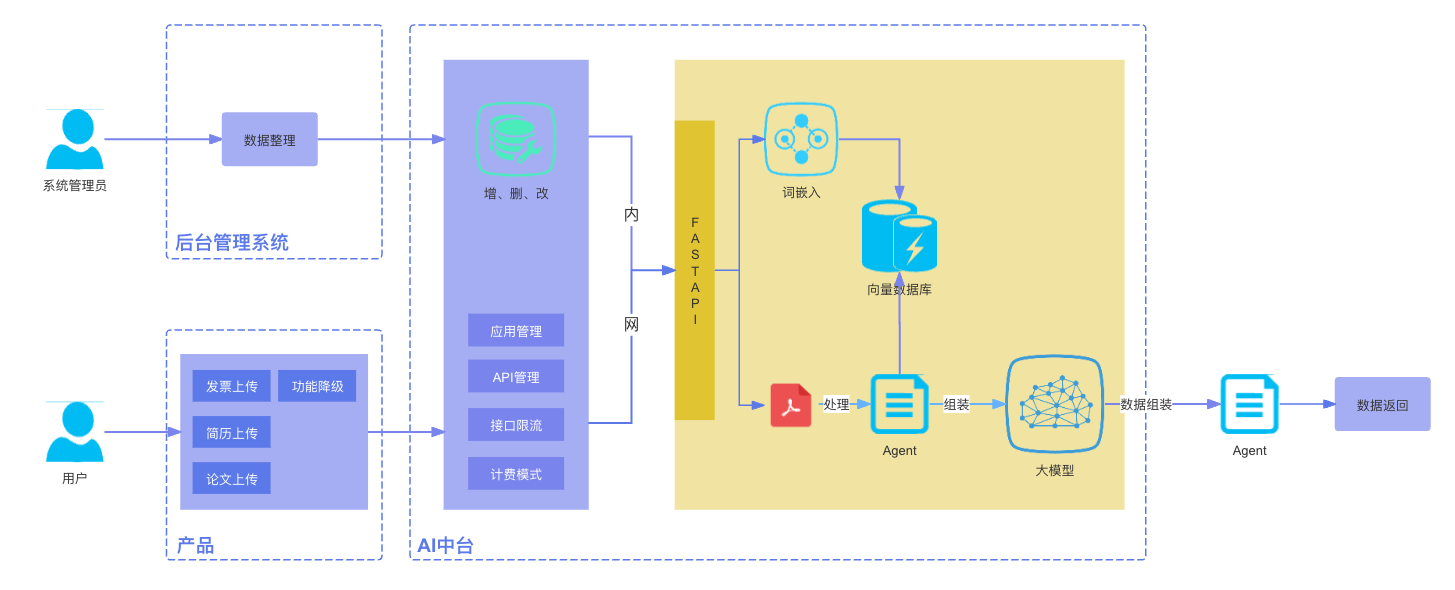
AI中台
不管是大模型还是小模型,我们需要将AI相关的能力集中管理起来,这里我们只用到了模型服务(MaaS),也就是说,我们这里假设模型已经训练好,微调好,可以直接通过接口进行调用。实际上AI中台还包括其他模块,比如数据采集、标注、模型训练等等,这里我们只用到模型服务,下一节课我们再详细介绍AI中台的架构设计。AI中台最好至少通过2个应用去承接,一个提供对外API服务,使用Java语言构建,一个AI模型服务,使用Python应用构建。
应用服务
为了确保服务的稳定性和安全性,我们采用Java语言开发对外接口服务应用。这个应用通过App进行管理,并使用AppKey和AppSecret进行接口鉴权。此外,我们还基于AppKey实施了接口权限控制和调用频率限制。
主要考虑以下几点:
- 接口调用限速,大模型推理需要使用比较多的GPU资源,尤其对于刚上线、流量比较大的应用,除了提前做好资源评估,准备适量的设备资源,还要做好降级的准备,因为有很多不可预估的情况可能会出现,比如流量突增、推理效率下降等等,都会导致GPU资源缺乏,从而影响用户使用,一旦GPU出现GPU资源紧张的情况,要及时启动限流,可以提前制定几种策略,比如按分钟/秒限制QPS,或者把一些流量大户加入黑名单,可以通过用户IP/ID等标识进行控制,这块和我们普通软件应用限流原理一致。
- 文件大小和格式限制,对文件大小和类型做一个限制,保护系统免受“攻击”,比如将文件类型限定在只能处理PDF上,甚至只能处理原生PDF格式,大小不超过10M,否则你不知道会有什么人直接上传多大的文件到系统,增加系统宕机风险。
- 上传文件频率限制,其实这是限制接口调用频率的一种,比如同一个用户每分钟只能上传1次,要不然一个人不断重复上传也会给系统带来很大压力。
- 模型服务计费,无论是使用自己搭建的大模型,还是调用大厂API服务,最好要把tokens记录下来,方便做费用统计以及最终对账。
模型服务
这部分是AI能力的核心,涉及数据处理、词嵌入、模型实际调用等等,我们使用Python作为构建语言,用过的人都知道,Python就是天然为机器学习而生的,大量的工具库,要比其他任何语言都方便。这个场景下主要涉及以下几个模块:
- PDF处理
这块我们通过一个Agent去处理,包含PDF切分、OCR识别等。PDF处理可能会面临各种各样的问题,比如如果PDF文件里是图像嵌入的,那么就需要OCR,一旦使用OCR就会涉及正确率的问题;再比如文件处理本身就是资源密集型操作,容易导致系统负载过重的情况。PDF处理工具有很多种,比如pdfplumber、PyPDF2、pytesseract等,有的是纯文本PDF内容抽取,比如PyPDF2,有的是OCR识别,如pytesseract,作为一个通用工具,我们可以先检测PDF中是否包含图片,不包含图片的话直接使用PyPDF2,你可以看一下示例代码。
import PyPDF2
from pytesseract import image_to_string
from PIL import Image
import pdf2image
def extract_text_from_pdf(pdf_path):
"""
从给定的PDF文件中提取文本,包括图像中的文本。
"""
all_text = ""
try:
# 打开PDF文件
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
num_pages = len(reader.pages)
# 将PDF转换为图像,一页一页处理
images = pdf2image.convert_from_path(pdf_path)
for i in range(num_pages):
page = reader.pages[i]
image = images[i]
# 先尝试直接从PDF页提取文本
text = page.extract_text() or ""
# 如果提取到的文本太少,可能需要OCR
if len(text.strip()) < 50: # 例如,少于50个字符视为提取失败
text = image_to_string(image, lang='chi_sim')
all_text += f"Page {i + 1}:\n{text}\n\n"
except Exception as e:
print(f"An error occurred: {e}")
return all_text
# 示例用法
pdf_file_path = 'path_to_your_pdf_file.pdf'
extracted_text = extract_text_from_pdf(pdf_file_path)
if extracted_text:
print(extracted_text)
- 词嵌入
词嵌入的原理我就不讲了,前面的课程中有详细的解释。在这个场景里,我们可以把发票图像的特征提取出来,生成向量,存放到向量数据库做图像数据检索,当然本质还是文本检索,用向量搜索的好处是语义检索,比如有些词汇长得不一样,但实际含义是一样的,那么这种场景用向量检索就很容易检索出来。
比如我们要检索所有维修服务类的发票,发票A写着:车辆维修费用包括更换刹车片和轮胎检查,发票B写着:为汽车进行的常规保养服务,包括制动系统和轮胎的维护,发票C写着:完成对车辆制动系统的全面检查及轮胎更换服务,那么通过向量检索,这3种情况都有可能搜索出来。
具体选择哪个词嵌入模型,可以自己判断,一般像Google的Word2Vec,Meta的fastText效果都不错,当然国产的也有,比如腾讯的TX-WORD2VEC。
- 向量数据库
向量数据库可以选择Meta的faiss,也可以选择国产的Milvus或者各个云厂商的云向量数据库,向量数据库效果好坏的关键在于向量的准确性,怎么分词很关键,比如刚刚的例子,检索维修服务,分词的时候如果把维修和服务分开,然后拿服务这个词去检索,那么准确度会大打折扣。所以在一些场景下,避免客户直接输入检索内容,效果可能会更好。
此外,使用前还要先评估好容量、数据库权限等等。
- Agent
我们把处理PDF的整个过程放到一个Agent内处理,处理的结果直接喂给大模型,大模型输出的内容可以调用Agent的另一个tool进行组装,返回给用户。这里主要涉及prompt组装(需要提前设定好prompt模版)、文本格式化、文件生成等内容。
- 大语言模型
大语言模型就是这个系统的核心,这里我们要先考虑是用本地自己搭建的模型,还是用大厂提供的API。一般来说,大厂的模型性能会更好,比如文心一言、智谱清言、通义千问等,效果都不错,价格也不贵,自己搭建的大模型为了节省资源,一般使用的是小规模参数的模型,比如ChatGLM3-6B、LLaMa3-8B、Qwen-7B等,实测下来,效果确实不如云上的大模型,云上的一般大厂都会放自己王牌的模型,效果肯定不会差。
另外,如果选择自己搭建模型,首先要注意这个模型是否支持免费商用,别一不小心造成侵权。同时,需要合理评估GPU资源,根据可能的QPS评估每秒token数,再根据这个模型实际的每秒处理token数,评估需要多少块显卡,预留一定的余量,防止突发情况。
如果选择云上模型服务,要注意保证账户余额充足,同时也可以设置一些阈值,限制一定的tokens消耗数,避免因为bug或者攻击消耗大量金额。
后台管理系统
我们需要一个系统来维护知识库,定期更新数据,这是使用知识库模式的一个不同点,而且会有一定的工作量,比如如何进行分词,有的时候是人工操作,这样就更有难度了,短期内,如果时间来不及,可以由开发人员维护,只需要有接口就行,不需要界面,长远看,最好还是做成后台管理系统,分配一定的权限,交由特定人员处理。
其他
除了刚刚介绍的内容,其他注意事项,比如监控、告警,常规的数据库设计、接口设计等,就不详细描述了,和软件开发相关的内容我相信你是比较熟悉的,这里新增的像大模型、Agent的监控、向量数据库的监控,要记得添加到标准的ops流程中。
风险点
- PDF抽取文本信息的过程中,可能会遇到OCR准确率问题,可以在产品设计上给用户留有一定的权限,以便编辑信息,如果出现识别错误或者不能识别的情况,允许用户手动编辑信息。
- 词嵌入及向量数据库,需要多调试,不同的词嵌入模型使用的训练方式不同,效果不同,需要不断调试看效果。
- 大模型推理效率问题,需要合理评估设备资源,避免推理资源不足带来不好的体验。
- Agent集成,可以使用像我们前面学习的LangChain框架,也可以自己编写集成代码。
- 自己维护知识库,需要有一定的分词能力。
小结
这节课我通过一个应用场景向你介绍了大模型落地架构设计,在实际开发过程中需要不断调试,才能确定好的效果,而且涉及机器学习的场景,一定要接受“不准确”的可能性,因为机器学习推理本身就是概率问题,不论是OCR、词嵌入还是大模型推理,玩儿的都是概率,所以在产品设计上,要考虑这种不确定性。
思考题
在生产环境中,对于Java应用,我们知道可以使用滚动发布、金丝雀发布等方式进行优雅更新,你可以思考一下,对于大模型,该如何进行优雅更新呢?可以把你的想法放到评论区,我们一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 潇洒哥66 👍(1) 💬(1)
大模型更新,关键要能够有科学的效果评估机制。
2024-10-16 - 石云升 👍(1) 💬(0)
企业落地的避坑指南~
2024-09-08