06 特征工程:数据点石成金,给你的系统赋予灵魂
你好,我是Tyler。
上节课我们学习了AI系统的建模策略,你掌握得如何?希望你已经对AI系统有了初步的了解。从今天开始,你将学习与AI系统特征工程相关的内容。
特征工程其实是数据工程的一部分,我们把它单独拿出来讲是因为特征工程是数据工程的灵魂,而且它与模型工程也密切相关。从这节课开始,我们的课程也逐渐进入深水区,请你带好泳镜泳帽,我们要开始学游泳了。
其实特征工程和模型工程没有特别明显的边界,许多特征工程的动作,在足够复杂的模型中已经被自动化掉了,所以你要清楚,特征工程主要是为了帮助模型减轻压力。
我先用一句话概括一下特征工程的核心工作:特征处理的过程是对数据进行微观和宏观投影的过程,所以虽然叫特征处理,但特征本身其实没有变化,变的只是你观察的维度。接下来,我会循序渐进,带你从不同的维度观察特征。
从特征到特征
我先举个例子,让你直观理解一下从不同观察角度提取的特征,它们的差异有多大。
如果将光作为一个特征,你只能告诉模型这里有一条光线。但是如果加上一个三棱镜,你便可以告诉模型,这里有七种颜色的光。
是不是找到一些感觉了?其实这是在从不同角度刻画你的特征,其实是在寻找特征的特征。

通常情况下,合理的数据变换能帮助现有模型更好地理解样本中的信息。一个常见的例子是年龄特征,因为往往各年龄段用户的数据量往往参差不齐,所以如果你给模型的特征是年龄,它学起来可能会很吃力。
这时候做一些离散化处理,比如将年龄转化为老、中、青,这样可以帮助模型快速学到一些宏观的特点。
同样的道理,如果我们将数值型特征直接给到线性模型,可能会导致模型很难发现特征中的一些非线性特点,这时你可以让它做幂函数、指数函数、三角函数等等这些变化之后再给到线性模型,就可以更好地处理非线性特征了。
当然,除此之外我们还有很多的处理手段,比如对数值特征做归一化,让所有的特征都“一样高”,以免模型觉得取值范围大的特征就更重要。例如模型会以为“年龄”比“气温”先天就更重要。这种谁更重要的事情应该交给模型自己去学习、决定,而在特征中,最重要的是“公平公正”。
除了单一特征的投影之外,还有多个特征组合使用的方法。这些特征交叉组合的策略在后面的一些复杂模型(如DeepFM)中已经自动化了。
从低维到高维
刚才我们学习了如何从微观维度观察一个特征的特征,不过,我们同时有必要从更高的维度来观察你的宏观特征,否则系统会像下图一样,成为一个困在低维的生物,看不到世界的原貌。
那具体怎么做呢?第一步便是将你的特征映射到更高的维度上,后面的例子会帮助你理解这种映射的必要性。
以性别特征为例,业务平台通常情况下会用枚举值0、1和2来表示男性、女性和未知。但如果你直接将这些数值传递给模型,会出现什么问题呢?
模型可能会错误地认为女性+女性=未知,男性+女性<未知,未知>女性>男性。如果把这样的数据给到类似LR这类的线性模型,模型可能在学完所有训练数据之后,还是没搞懂男性、女性和未知之间的关系。
当机器学不会的时候也会“放弃”,它只能将性别的权重学为零,这个特别重要的特征和我们擦肩而过了,是不是特别可惜?
所以,我们在做特征工程的时候,要提供更加平易近模型的数据,正所谓 “rubbish in rubbish out”。你可能会问,如果它们之间真的有关系呢?
这是一个非常好的问题,但在没有额外证据之前,你还不能将这些存在线性关系的数值直接传递给模型。你应该先假设男性、女性和未知之间没有线性数值关系,它们是相互独立的。
还是那句话,即使它们之间存在隐含的关系,也需要交给模型去挖掘和学习。当然如果你能证明它们之间存在关系,稍后我也会教你如何处理。
现在,你需要设计一种映射方案,将男、女和未知设计成相互独立的值,这样模型才能自己理解这个特征在真实世界中的含义。
最简单的方法就是保证它们之间在数值上是正交的,确保每个值只占据空间中的一个维度,简而言之就是用各个维度的单位向量表示一个分类,这种编码方式叫独热编码(one-hot encoding)。
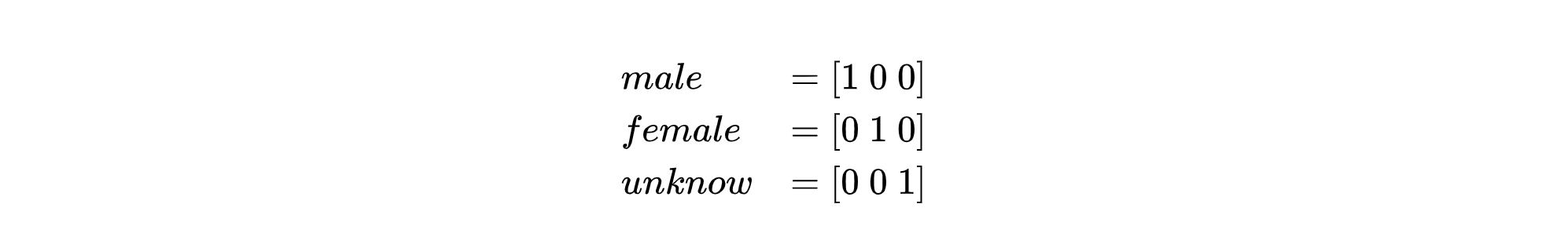
因此,独热编码最大的特点就是能够将数据投射到高维空间,并同时保证它们之间的正交关系。
import torch
# 输入标签
labels = torch.tensor([0, 1, 2])
# 确定OneHot编码的维度
num_classes = 3
# 生成OneHot编码
onehot = torch.eye(num_classes)[labels]
print(onehot)
从空间到世界
好了,现在我们的特征已经成功投影到高维空间了,模型也在正交关系中知道了不同性别的独立性,不会再误以为未知>女性>男性了。
但是我要回答你刚才的问题了,这三个分类之间真的没有关系吗?
性别我不知道,但是其他特征,比如兴趣一定有关系,羽毛球与高尔夫、钓鱼之间一定关系更近,而羽毛球与绘画、插花之间一定关系更远。可是在独热编码之后,它们在空间中的距离可是一模一样的,这时候只能让模型不断地总结学习,才可能得到它们之间的关系。
那么,如果你已经提前知道它们之间的关系了,那有没有抄近道的方法,也能让模型快速理解它们之间的关系呢?其实还真有一个办法,就是把这种真实世界中的关系直接给模型。
这也涉及到AI大模型的关键技术——预训练模型,你可以用它来刻画真实世界中各个实体之间的关系,让模型知道“羽毛球”与“高尔夫”和“插花”之间哪一个“距离”更近。
那么我们如何获取各个实体在真实世界中的空间关系呢?你可以通过浩如烟海的语料来学习,比如 OpenAI 使用了几乎全网的文章来训练它们的模型,教会模型理解自然语言。当然了,如果你只需要解决“羽毛球与谁关系更近”这种级别的实体关系,找一些常识性的图书和文章,交给模型去学习就好了。
下面我们说说具体的过程。首先,你需要将上述语料中所有的单词做独热编码,映射到高维空间中,得到单词的高维向量表达。
不过,这时独热编码所投影出来的全部单词之间,都是正交的关系。所以接下来,我们需要用相邻单词之间的字面距离,来描述它们的空间关系。
这里使用了对比学习的方法,利用了“你的基友A和基友B之间更相似的”这类假设,去训练一个模型,来刻画单词之间的相似度。
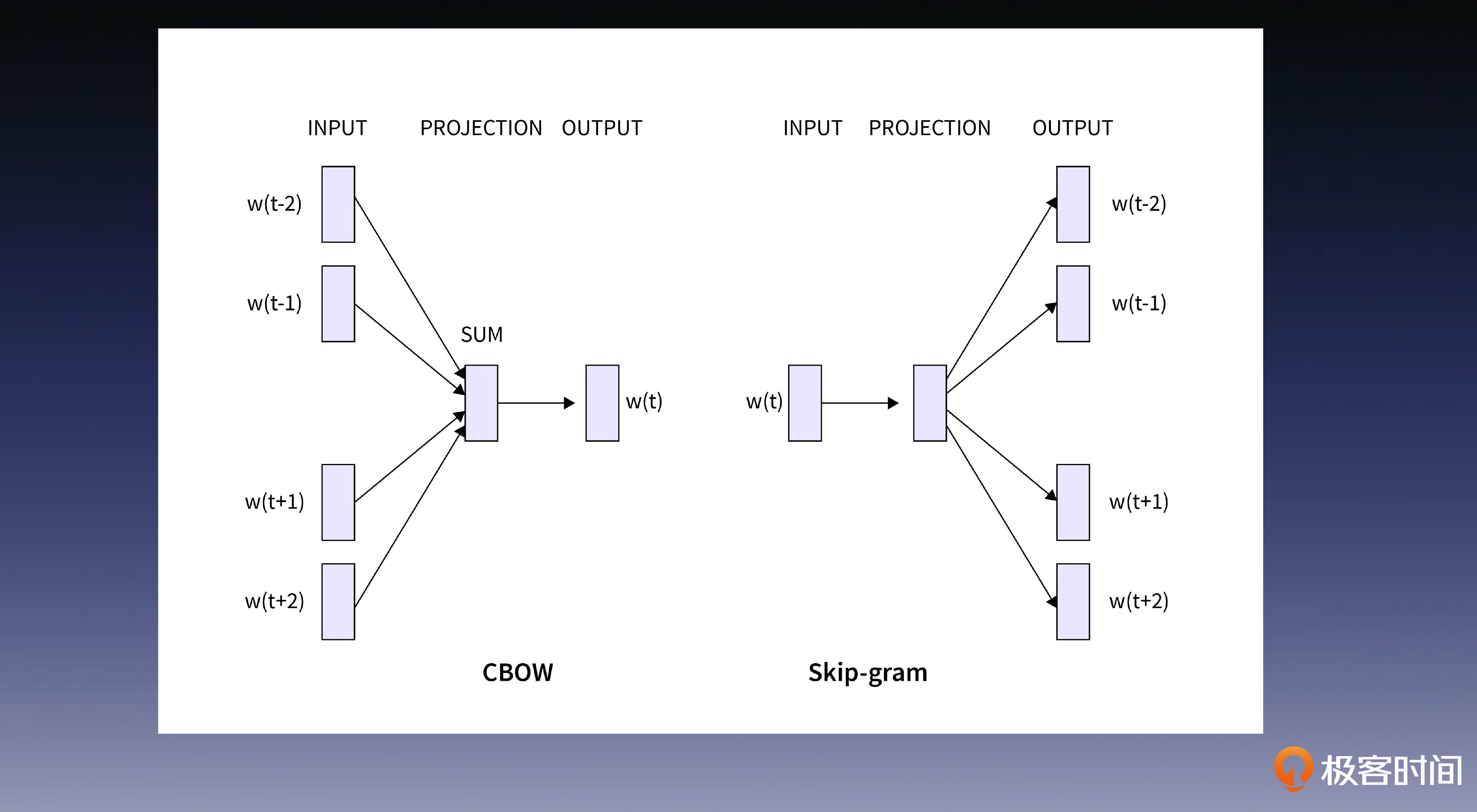
那你可能会问,该如何去衡量,语料中词与词的关系呢?这里有两种方法,第一种是跳字模型Skip-gram,第二种是连续词袋模型CBOW(Continuous Bag of Words)。
简单来说,跳字模型的目标是,通过给定一个中心词用它来预测前后单词;而在连续词袋模型中,模型的目标是通过前后词来预测中心词。这里有一个假设,那就是在字面上相近位置经常出现的单词之间,相关性会更大。
举个例子,假设我们的语料中有这么一段话。
John likes to watch movies and Mary likes to read books.
那么 CBOW 的训练数据格式如下所示。
"John" -> ["likes"]
"to" -> ["likes", "watch"]
"likes" -> ["Mary"]
"watch" -> ["to"]
"movies" -> ["watch"]
"and" -> ["movies"]
Skip-gram 的训练数据格式如下所示。
"likes" -> ["John", "to"]
"to" -> ["likes", "watch"]
"watch" -> ["to", "movies"]
"movies" -> ["watch", "and"]
随着你的语料不断增加,每个单词后面的链条也会越来越长。这样,模型就能通过统计,知道哪些单词之间的关系更相近了。
这就是Word2Vec的思想,也是NLP预训练模型(PTM)的重要工作。现在的 GPT 系列最早也是从 Word2Vec 一步步发展出来的,所以它的重要性不言而喻。

相信你已经理解“特征工程的本质是空间投影的过程”这句话的含义了。
接下来,你可以思考一下,你所在的业务场景里有哪些数据?如何为这些数据选择合理的空间投影方法,才能对模型更加友好。这节课的目标呢,正是为了让你理解特征工程的定位和价值。不过也请放心,正如我们在开篇时所说,我将在总体回顾的部分给出一个完整的架构方案。
小结
今天的内容告一段落,我带你做个回顾总结。这一讲我们解决了特征工程的三大问题。
首先,你学习了怎样对特征进行微观投影,得到特征的特征。我们用非线性处理、特征组合处理和归一化处理等特征处理方法,让你的特征更好地服务于模型。
接下来,你还学习了怎样把低维特征投射到高维空间。我们使用独热编码,将特征投射到高维空间,并保证它们在高维空间的独立性,避免对模型造成干扰。
最后,你学习了怎样在高维空间,刻画特征之间的语义关系,我们用对比学习的方法,刻画了高维空间中的特征距离,也就是单词之间的语义关系,进而让模型“抄近道”理解特征在现实世界中的关系。
思考题
为了更好地巩固今天所学内容,请你尝试回答后面的问题。可以选择一个有把握的,也可以都作答。
- 独热编码是如何处理分类特征的?
- 为什么需要进行正交的空间投影?
- 解释一下在高维空间刻画特征距离的意义和作用。
恭喜你完成我们第 6 次打卡学习,期待你在留言区和我交流互动。如果你觉得有收获,也欢迎你分享给你身边的朋友,邀 TA 一起讨论。
- Paul Shan 👍(24) 💬(2)
独热编码是如何处理分类特征的? 独热编码是把每个类型分配一个维度,这样不同的维度可以做到独立和正交 为什么需要进行正交的空间投影? 正交投影是确保了维度不缩小,并且不同的维度不相关,在这个基础上可以压缩维度和寻找关系,如果不正交的话,必然预设了不同维度之间的关系,这些预设值很可能和现实不符,会增加了模型走弯路的可能,如果丢失了维度,再让模型回到原来的维度就不可能了,高维映射到低维是可能的,反之就不可能了。 解释一下在高维空间刻画特征距离的意义和作用。 特征在高维空间中的距离反应了事物的相似程度,可以用来聚类和分类
2023-08-23 - 张金磊 👍(4) 💬(3)
老师,明明都是数字的向量,为什么在NLP这里就叫嵌入(虽然是中文的翻译,但英文原文也不是 vector),非常想知道这个答案,有什么历史“渊源”吗?或者去哪里查资料可以知道这个问题的答案,谢谢老师
2024-02-19 - piboye 👍(2) 💬(1)
老师, 现在词的embedding 还是用 cbow, skip-gram 来训练的吗?
2023-10-04 - GAC·DU 👍(2) 💬(1)
独热编码将每个分类值转换为一个二进制向量,其中只有一个元素为1,其余元素为0。优点是独立,缺点是可能会引入大量维度,导致维度灾难。 进行正交空间投影是为了数据降维,减少数据的维度,解决独热编码的缺点。 高维空间中刻画特征距离的意义在于帮助理解数据的结构、相似性和关联性,从而支持各种数据分析和机器学习任务。选择适当的距离度量方法,在特征工程中,通过分析特征距离,可以帮助选择最具信息量的特征,从而提高模型的性能和效率。
2023-08-23 - 默默且听风 👍(0) 💬(1)
从空间到世界:这部分基本上能懂 从低维到高维:这部分结合one-hot encoding和代码能get到 从特征到特征:这个还有什么例子吗?脑子里基本没有想象空间啊,我现在的大脑就像那个三菱的光一样什么一没存住
2023-11-20 - l_j_dota_1111 👍(0) 💬(1)
三个类型可以相互正交,但是超过三个如何相互正交呢,还有就是为何要保证每个类型相互正交
2023-09-21 - `¿` 👍(0) 💬(1)
为啥听了之后,后面的问题还是不太能回答。是需要补充更多概念知识嘛
2023-09-02 - peter 👍(0) 💬(1)
第5讲中的PID是自动控制中的PID吗?
2023-08-24 - iLeGeND 👍(0) 💬(1)
怎么感觉特征是离散的呢,怎么组成语言句子呢
2023-08-23 - 周晓英 👍(6) 💬(3)
独热编码 (One-Hot Encoding): 想象一下你有一盒彩色的蜡笔,有红色、蓝色和绿色。我们想把这些颜色告诉计算机,但计算机只能理解数字。独热编码就是一种解决办法。我们为每种颜色分配一个特殊的数字序列。例如,红色可以是[1, 0, 0],蓝色是[0, 1, 0],绿色是[0, 0, 1]。这样,每种颜色都有一个独一无二的数字序列,计算机就能区分它们了。 正交空间投影 (Orthogonal Projection): 正交空间投影有点像是影子。想象一下,当阳光直射到你身上时,你的影子会掉到地上。在这个过程中,三维空间(你的身体)被简化为二维空间(影子)。正交投影是一种特殊的投影,它保留了一些重要的信息,使得原始的数据(你的身体)和投影后的数据(影子)之间的关系更清晰。 高维空间中的特征距离 (Feature Distance in High-Dimensional Space): 在高维空间中,我们可以通过测量点之间的距离来了解它们的相似度。比如说,如果我们在一个大商店里,每个商品都放在不同的位置,我们可以通过测量两个商品之间的距离来了解它们是否相似或相关。在高维空间里,每个维度代表了一个特征,比如颜色、大小或品牌。通过测量这些特征的距离,我们可以更好地理解和比较不同的商品。 高维空间的特征距离对于机器学习和数据分析非常重要,它帮助我们理解数据的结构,找到相似的点,甚至可以帮助我们预测新数据点可能属于哪个类别。
2023-10-02 - Ghostown 👍(1) 💬(0)
有个疑惑的地方,male,female,unknow分别被one-hot编码之后表示成[1,0,0] [0,1,0] [0,0,1]之后,这三个特征的距离(三维空间欧氏距离)也就是关系被固定了,那么如何再在后面学习并更新三者之间的关系呢。还是说[1,0,0] [0,1,0] [0,0,1]只是代表向量空间的正交基,具体的male,female,unknow特征会在后面学到,可能学到的值是male:[0.9, 0.1, 0] female:[0.8, 0.2, 0] unknow:[0.5, 0.5, 0],望老师解惑!
2023-12-25 - Seachal 👍(0) 💬(0)
特征工程,AI里的重头戏,给数据做个“变身”,让模型看得更清。年龄离散化、数值变换,都是为了让模型吃得懂;特征交叉、低维到高维,看得更全面。独热编码,更是数据高维旅行的必备“护照”,特征间互不干扰。说到底,特征工程就是给模型送“大餐”,让它吃得准、吃得香,提升准确性和泛化力。这篇文章,就像是个开胃菜,让人对特征工程有了个初步了解。还有预训练模型、空间关系那些,对比学习,让模型在高维空间里找关系,更懂特征的真实含义。学完之后,感觉特征工程挺有意思的,还得继续深入探索。
2024-11-23 - Seachal 👍(0) 💬(0)
特征工程,AI里挺关键的一环,给数据做“美容”,让模型看得更清。文章里,比喻、实例一堆,把特征工程那点事儿说得挺透。年龄离散化、数值特征变换,都是为了模型好消化。特征交叉、低维到高维,也是常用手法。独热编码,更是把数据送上高维高速路,特征间互不干扰。说白了,特征工程就是让模型吃得准、吃得饱,提高准确性和泛化力。这篇文章,算是入门级的“菜谱”,让人对特征工程有了个大概认识。还有预训练模型、空间关系那些,对比学习,让模型在高维空间里找捷径,理解特征的真实关系。
2024-11-23 - Clying Deng 👍(0) 💬(0)
Skip-gram 和 CBOW是通过草料中单词和单词同时出现的概率来推出词与词的空间距离吗?如果是这样的话 经书 预处理效果就很差了
2024-10-24 - l_j_dota_1111 👍(0) 💬(0)
针对这句话“羽毛球与高尔夫、钓鱼之间一定关系更近,而羽毛球与绘画、插花之间一定关系更远。可是在独热编码之后,它们在空间中的距离可是一模一样的,这时候只能让模型不断地总结学习,才可能得到它们之间的关系”,独热编码后,这些词在高维空间中都是正交的,那么经过让模型不断学习,这些词经过相似度表达后,会调整他们在空间中的位置吗,在高维空间中从正交变成不正交吗
2023-12-26