12 博观约取:重走NLP领域预训练模型的长征路
你好,我是Tyler。
上节课,我们学习了计算机视觉领域预训练模型(PTM)的发展历程和重要成果,了解到CNN的平移不变性和边缘提取能力为视觉任务提供了巨大的帮助。
不过你可能会问,上节课学到的 CNN 是根据生物的视觉结构而设计的,我总不能用 CNN 来处理自然语言问题吧?
虽然这样也不是不行,不过NLP领域确实有自己更偏好的模型结构。在这节课,我将带你解决自然语言处理领域所独有的一些问题,重走NLP “长征路”,看看NLP模型预训练技术在黎明前都经历过哪些考验。
RNN:生而 NLP 的神经网络
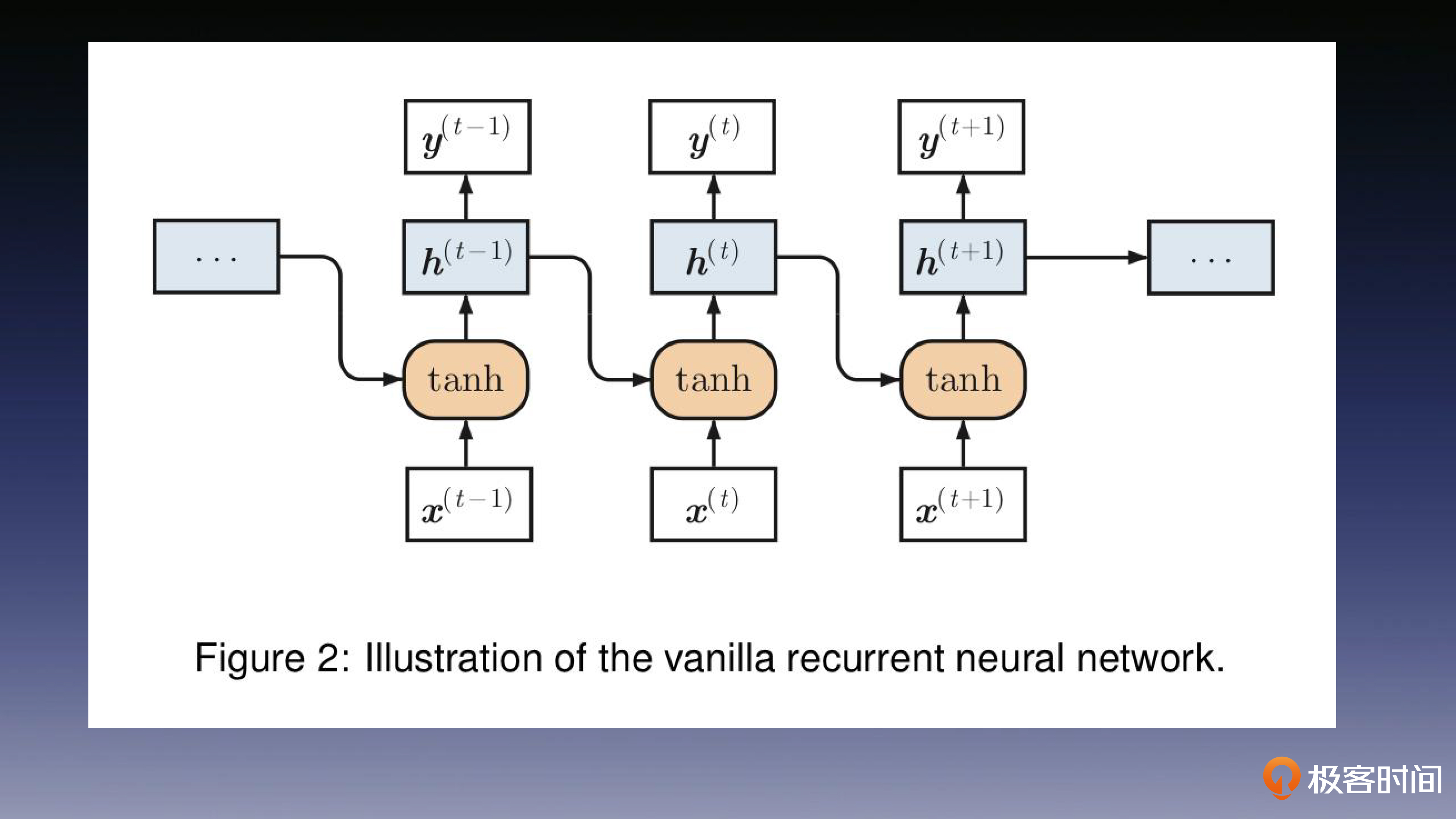
我们第一个要学习的模型是循环神经网络(Recurrent Neural Network,RNN),它是一种用于处理“序列数据”的神经网络模型。
RNN引入了循环结构,如下图所示,在RNN中,每个单元都具有一个隐藏状态来存储之前的信息,并将其传递给下一个节点。
如下图所示,每个单元 i 不仅仅接收自身的输入 $x_i$ 来获取当前步骤的文本信息,同时还接收前一个单元的输出 $h_{i-1}$ 作为另一部分输入,获得上下文信息的补充。
就像前面学习CNN的时候一样,从生物尤其是人类的智能中寻找灵感这种做法,在AI领域屡见不鲜。
所以你发现没有?RNN这样的结构就类似人类语言的模式。在人类对话中,我们也会不断结合之前听到的内容来理解当前语境的含义。因此,RNN恰好适合用来给NLP中的长序列数据建模,这也是为什么我在小标题里强调,RNN天生适合做NLP任务。
LSTM:解决主要矛盾,扫清前进障碍
还记得上节课我们学到的 CNN 在网络层数增加时,提到的梯度爆炸或消失问题吗?这个问题不仅在 CNN 中会出现,在 RNN 中也同样存在。
在处理较长序列时,RNN会展开成多层,导致同一权重参数在各个单元中复制。在反向传播过程中,这些参数的梯度可能在复制时成倍地增长或减少,最终甚至出现梯度爆炸或消失的问题。
所以如果不能解决这个问题,RNN 这项面向长序列设计的技术将很难推广。所以这时 LSTM(Long short-term memory)模型应运而生,解决了这个难题。
LSTM是一种特殊的RNN,其内部包含三个关键的门控制单元:遗忘门、输入门和输出门。这些“门”控制了信息的流动和保留,使网络能够有选择地记住或遗忘相关信息,从而有效解决了梯度消失和爆炸问题。
你可以先看看后面的网络架构图,再听我具体分析。

- 遗忘门使用 Sigmoid 激活函数计算遗忘值,输出一个介于0和1之间的值,表示要保留多少之前的记忆。
- 输入门使用 Tanh 激活函数计算一个新的记忆值。而且同样使用 Sigmoid 激活函数来算出一个介于0和1之间的值,表示保留的新记忆值量的多少。
- 输出门使用 Sigmoid 激活函数保留输入信息,并使用 Tanh 激活函数取得记忆细胞内容,配合控制输出值。
这里我想提醒你注意,在后续的学习中,你会频繁发现Sigmoid被用作门控的激活函数。你可以思考一下为什么这样设计?在你自己设计模型时,是不是也可以尝试使用Sigmoid作为门限激活函数。
我们继续回到 LSTM 的主题,结合上面的这张图,你会发现,我们引入的$C_t$这条链路扮演着记忆细胞的角色,负责传递着各个门和单元之间的信息。虽然之前的 RNN 也可以依靠$h_t$这条链路来传递局部的时序语义关系,但是记忆细胞可以捕捉并传递更长序列的语义关系,这能帮助模型更好地建模长距离依赖的关系。
Seq2Seq:一统架构,众人拾柴火焰高
随着研究的深入,人们发现在 NLP 领域中,经常需要处理“输入为序列,输出也为序列”的任务,ChatGPT就是典型的应用。
为了更好地解决这些问题,研究者将这一类任务抽象为 “Seq2Seq”(Sequence-to-Sequence)任务,并为此提出编码器-解码器的架构。
在技术层面上,相比直接使用序列模型进行预测,这一架构能够处理不定长度的序列,灵活性更高,也为引入各种机制(如注意力机制)提供了更多的操作空间。
如果你认真学习了前面的课程,理解编、解码器的工作原理将非常轻松。我们以机器翻译为例来带你梳理一下。
在这个过程中,首先编码器会将输入序列从源空间(例如中文)投影到一个高维语义空间的向量表示中。接着,解码器将这个高维向量从语义空间映射回目标空间(例如英文),生成一个新的序列作为翻译输出。
这是不是和特征工程那节课学习的知识很像?你只是在做各个语义空间中的相互投影罢了,只不过这个投影的方法叫做编码器和解码器。
下面的图片直观展示了编码器-解码器的工作过程,我们一起来看看。
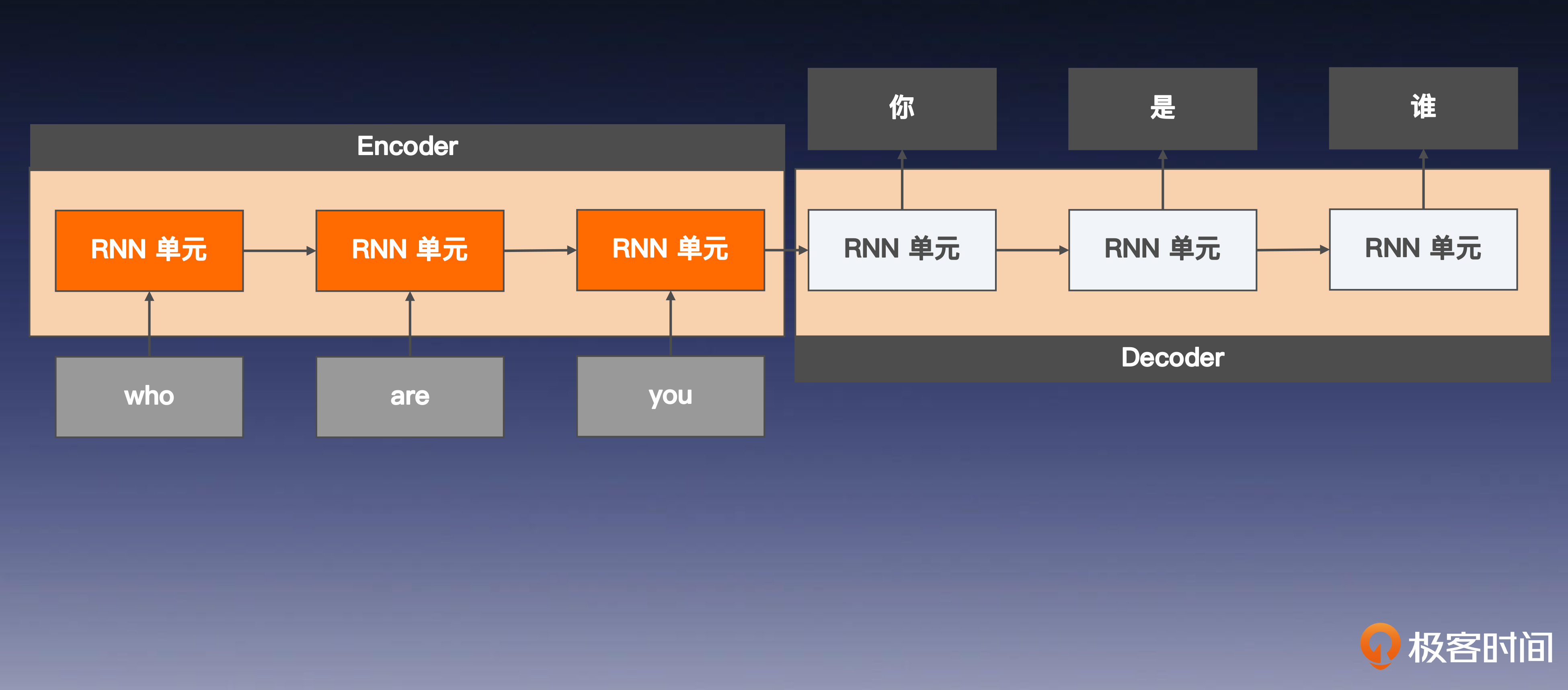
在编码器(Encoder)中,输入序列经过 RNN,更新每一个单元的隐藏状态,并用最后一个单元的隐藏状态,作为编码器阶段产出的高维向量,因为它包含了完整输入序列的语义信息。
接着,解码器(Decoder)用编码器产出的高维向量,作为自己的初始隐藏状态向后传递,“报出”自己的内容,并且向后面的RNN 单元传递更新后的状态。当后面的 RNN 单元传递接收到前一步的输入时,也会“报出”自己的内容,并继续向下一个单元传递隐藏状态,直到持续生成完整的目标序列。
这种架构的价值在于它规范这类问题的解决范式,促使全球的研究人员达成共识,这可以凝聚该领域的多数力量共同建设发展。
注意力机制:集中精力办大事,好钢用在刀刃上
你会发现,我们刚刚学习的LSTM在编码器阶段,将所有输入信息都被“压缩”到了一个固定长度的向量中——也就是最后一个RNN单元的隐层表示。
你也许会疑惑,这么狭小的空间真的能够容纳如此丰富的信息吗?
这是个很好的问题,因为这种“压缩”确实可能会导致关键信息的流失。正因如此,为了更加有效地捕捉输入序列中的关键信息,我们就需要引入注意力机制。
这里我举个例子来帮你理解注意力机制。综艺节目里有个非常经典的节目——“传声筒游戏”。在这个游戏中,通常会有N个参与者,每个人有一个编号。每个人只能听取编号比自己小的人传来的话,同时只能将这段话传递给编号比自己大的下一个人。

这个游戏本身确实具有一定难度,因为它需要考验每一个人在过程中的记忆和表达能力。但是,如果我们稍作改变,允许后面的人与之前所有的人进行对话,那么游戏的难度就会大大降低。
而Attention 就是在做这个事情,它允许后面的人询问(Query)他前面所有人知道的内容(Key & Value),甚至后面的人还能知道之前哪个人说的话对他来说是“更重要的”,是不是感觉这太过“作弊”了?
没错,注意力机制的思路和原先的循环结构相比,简直是开了挂,这正是它的强大之处。
具体来说,类似于在 LSTM 中我们引入$C_t$这条记忆链路,使得模型能够更好地建模长距离依赖的关系。如下图所示,Attention 则是为解码器阶段的每个单元,单独准备了一个自己的$C$,它会基于当前单元内容和输入之间的关系进行“私人定制”,让解码器的每个单元都能获得定制化的全局信息。
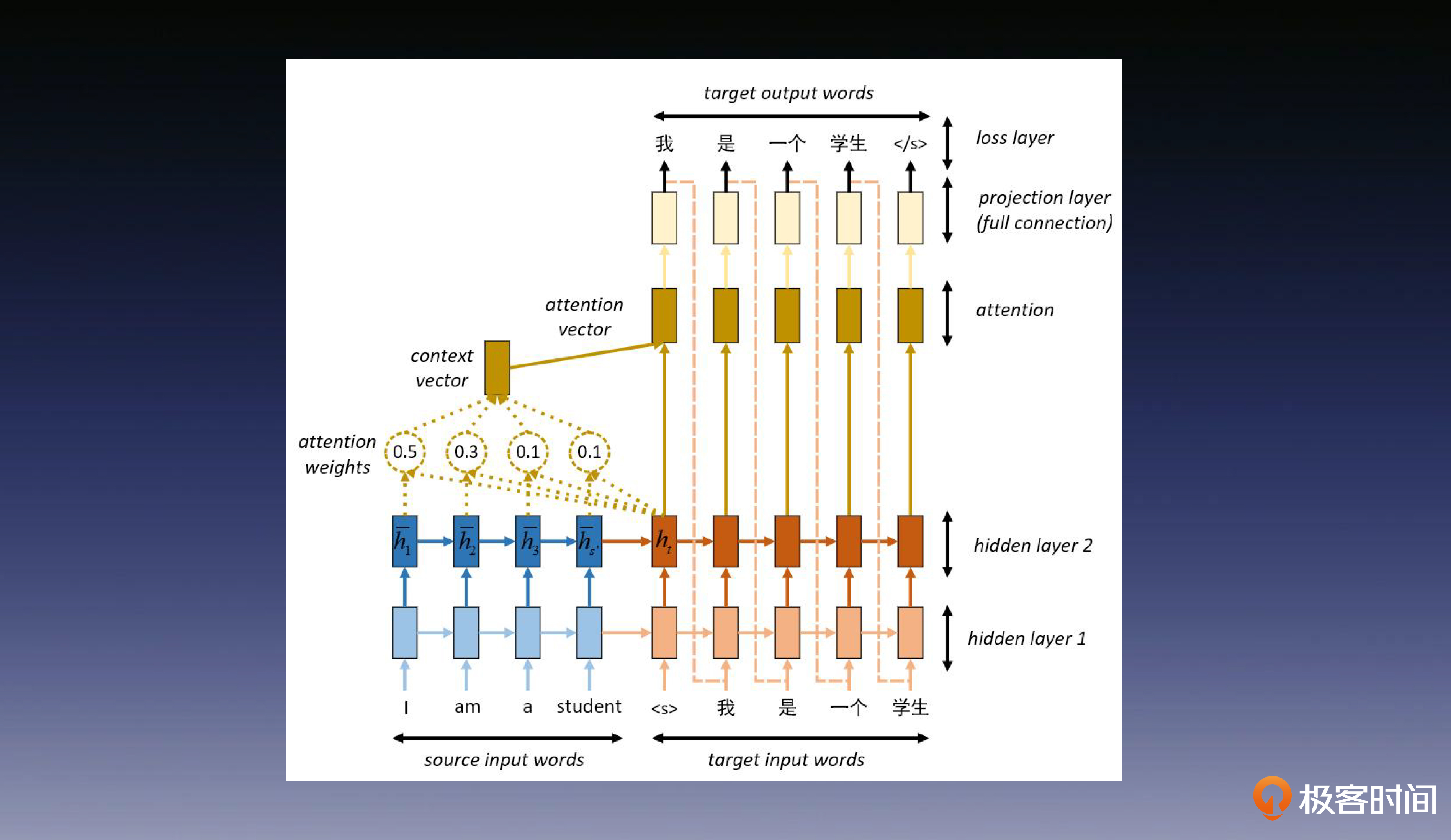
Attention机制的出色表现让AI领域的研究人员都感到兴奋不已,纷纷直呼“真香”。于是,Google的研究人员产生了一个有趣的想法:如果只用Attention这一招,会不会更香?
他们并没有停留在猜想环节,Google AI的论文 “Attention Is All You Need”应运而生。这就是大名鼎鼎的Transformer,灵感正是来自于“注意力机制”。即便 NLP 模型发展如此迅猛,还是没有走出自己的预训练模型之路,不过 Transformer 的出现为这一切带来了转机,后面的故事我下节课再为你揭秘。
总结
让我们总结一下。这节课我带你一起梳理了语言模型的发展历程。理解了这条脉络,也有助于你后续更好地学习大型语言模型(LLM)。
还是那句话,我们要自顶而下地学习,所以如果你之前没什么机器学习基础的话,这节课你可以先把重点放在串联技术发展脉络上。
其实,语言模型的发展历程与视觉模型有许多相似之处。例如,它们都考虑了生物行为的特点,找到了适合自身的神经网络结构——循环神经网络(RNN)和卷积神经网络(CNN)。
它们在模型规模不断扩大的过程中,也都遇到了梯度爆炸和梯度消失的问题,并基于各自模型结构的特点找到了应对方法,分别是LSTM和ResNet。
这种相似的发展轨迹,也许给当时的人们带来了一些“启发”,他们隐约认识到,或许存在一种方法能够对不同模态的数据进行“大一统”的建模。在后续课程的多模态算法部分,我会再次与你讨论这个问题。
希望你在课后认真吸收消化这节课的内容,认真理解语言模型所涉及的场景特点。在下一节课开始时,我将带领你正式踏入大型语言模型(LLM)的领域,共同探索其中的奥秘。
思考题
- 这节课我们学习了如何给 LSTM 增加 Attention 机制,你可以思考一下,如果要给上节课学到的 CNN 增加这个机制,该如何做呢?
- 沿着课程中传声筒游戏可以“作弊”的思路想下去,你还能想出哪些作弊方法?越离谱越好!
恭喜完成我们第12次打卡学习,期待你在留言区和我交流互动。如果你觉得有收获,也欢迎你分享给你身边的朋友,邀 TA 一起讨论。
- perfect 👍(2) 💬(1)
你好,Tyler,我是做软件工程的,对模型设计的数学原理不太理解。听前面的课程感觉很有趣也能理解,但涉及到模型和算法后,不懂底层数学原路感觉理解起来很吃力。 想请教几个问题 1、是否可以把AI算法/模型当成一个黑盒使用?业界有没有一些黑盒使用手册 2、如果无法黑盒使用模型,针对非AI专业有什么入门学习路径吗?期望达到会使用会调参的水平,数学需要掌握哪些最少知识?
2023-09-28 - 有铭 👍(3) 💬(1)
允许后面的人问前面所有的人?那前面的那么多层存在意义在哪里?那干脆把前面的层都铺平让最后一个人挨个问过去,不是更好?没有研究者考虑过这个方向?
2023-09-10 - 跳哥爱学习 👍(3) 💬(1)
用这个传声筒游戏解释了自注意力机制 太秒了!
2023-09-07 - 周晓英 👍(3) 💬(0)
何为 CNN 添加注意力机制: 1. 设计注意力模块: 设计一个注意力模块,该模块能够为每个特征图分配一个权重。这个权重表示模型应该给予该特征图多少注意力。 常见的注意力模块包括 Squeeze-and-Excitation (SE) 模块、CBAM(Convolutional Block Attention Module)等。 2. 集成注意力模块: 将设计好的注意力模块集成到 CNN 的每一层或某些特定层中。例如,可以在每个卷积层之后添加一个 SE 注意力模块。 3. 注意力权重计算: 在前向传播过程中,计算注意力权重。通常,注意力权重是通过对特征图的全局池化、全连接层和激活函数(如 Sigmoid 函数)计算得到的。 4. 特征重标定: 使用计算得到的注意力权重来重标定特征图。通常,这是通过将注意力权重与原始特征图相乘来实现的。 5. 训练和优化: 训练新的 CNN 模型,并通过反向传播算法优化注意力模块的参数和 CNN 的参数,以最小化目标函数。 6. 评估和调优: 评估模型的性能,如果需要,可以调整注意力模块的设计或参数,以进一步提高模型的性能
2023-10-02 - 周晓英 👍(1) 💬(0)
作弊的可能方式: 1.每个参与者可以使用多种方式传递信息,包含语言,动作,文本,图示等。 2.每个参与者可以设法突出最重要的信息,例如将重要内容高亮或者加上音量。 3.每个参与者身上有一个标记,是他们在历史比赛中传递信息准确度的综合评分,帮助后面的人确定权重。
2023-10-02 - St.Peter 👍(0) 💬(0)
了解了用于NLP的预训练模型,从RNN、LSTM、Transformer.
2024-11-11 - 天之痕 👍(0) 💬(0)
老师您好,因为长时间都不在这个领域(在数据库领域),最近想了解一下大模型的知识,坚持看了12节,还会坚持看完,很多脉络性的知识都能够了解,但是很多底层算法确实一知半解,基础太差,不知道有什么算法入门类的课程可以推荐下,比如神经网络具体如何实现的,TensorFlow原理是啥?😂
2024-02-16