13 厚积薄发:如何让模型更好地理解人类语言?
你好,我是Tyler。
在之前的课程中,我们已经了解了语言模型的发展历程,这让我们可以明显看到,NLP领域的发展速度并不亚于计算机视觉(CV)领域,NLP研究人员不断推动着相关方法的不断发展。
然而,在NLP领域,一直存在一个令人尴尬的问题,这也是我们在第11节课时提过的一个问题:既然在计算机视觉领域,预训练模型的表现如此出色,NLP领域是否从他们的成功经验中学到了一些什么呢?
答案是NLP 确实汲取了灵感,但在实践中难以完全复制。NLP 的研究人员只是知道了外面世界的美好,却发现自己没有 CV PTM 的命,为什么这么说呢?这节课我就带你一探究竟。
重建巴别塔
首先,视觉能力是人类天生就具备的,而语言能力则要后天学习,所以对人类来说语言能力本来就更难。此外,语言存在不同的语种,每种语种都有不同的词汇、词法和语法。这进一步增加了处理语言的复杂性。
语言的多样性分散了人类的注意力,因此构建一个涵盖多种语言的带标签数据集这件事,变得异常困难。这也使得全球范围内的科学家们很难共同构建“巴别塔”,只能在自己的小圈子里打转。所以 NLP 也被我们称为人工智能皇冠上的宝石。
然而,是不是就没办法了呢?当然不是,只是这个过程非常漫长。既然无法构建一个多语种的、带标签的自然语言数据集,NLP 的预训练模型大军只能早早地离开监督学习的母星,探索无监督学习的深邃宇宙,以光年为单位飞往目标星球。
从此,人们进入了漫长的探索时期,这一路充满了坎坷。相比 CV 领域,在 2012 年就已有 AlexNet 级别的 PTM “杀器”,NLP 在 2013 年才刚刚在特征表征模型预训练上崭露一些头角,这就是我们接下来要学习的Word2Vec。
Word2Vec:对比学习加持特征表征
Word2Vec这个词是不是有点眼熟?没错,我们在第 6 节课就提过它。Word2Vec算法由Google的研究人员于2013年提出。这个算法的最大贡献,是找到了一种无监督学习的方法,对大规模的语料库进行预训练,学习其中的语义,这绕开了对大规模有标签数据集的依赖,打破了NLP预训练数据上的困境。
让我们回顾一下之前的内容:Word2Vec有两种训练方法,一种是跳字模型(Skip-gram),另一种是连续词袋模型(CBOW)。
简而言之,跳字模型的目标是通过给定一个中心词来预测其周围的单词,而连续词袋模型的目标是通过周围的单词来预测中心词。其实这里隐含一个假设,即在字面上相近位置经常出现的单词之间,相关性会更强。
在学习词与词之间的语义关系时,模型将每个词映射到高维向量空间中,这些向量可以应用于多种自然语言处理任务。举例来说,在机器翻译任务中,你可以将每个词的嵌入向量作为输入,这样能够显著提升语言模型对每个单词含义的理解能力。
这种方法不但大大提升了之前机器翻译任务的效果,更重要的是给NLP预训练模型指明了正确方向,给后续研究提供了信息和希望。
ELMo:语言模型消除歧义
不过,Word2Vec也有明显的短板,比如无法处理词在不同语境中的多义性。举例来说,“苹果”可以指水果,也可以指手机。Word2Vec无法理解这些差异,可能导致产生错误的结果。
怎么帮助模型消除歧义呢?这就不得不说到ElMo(Embeddings from Language Models)了,它是Google AI在2018年提出的一项技术。
ElMo是一种基于上下文生成词向量的方法,能够通过综合考虑“前到后”和“后到前”两个序列单词的含义,动态调整生成的词向量,让词语的表示变得更加准确。
比如,在句子“我掏出苹果手机下单了一袋苹果”中,单词“苹果”可以指代“手机”或“水果”。ELMo能够根据上下文来动态理解这两种含义。
ELMo的训练目标是根据单词的上下文来预测单词本身。它的网络结构如下图所示。
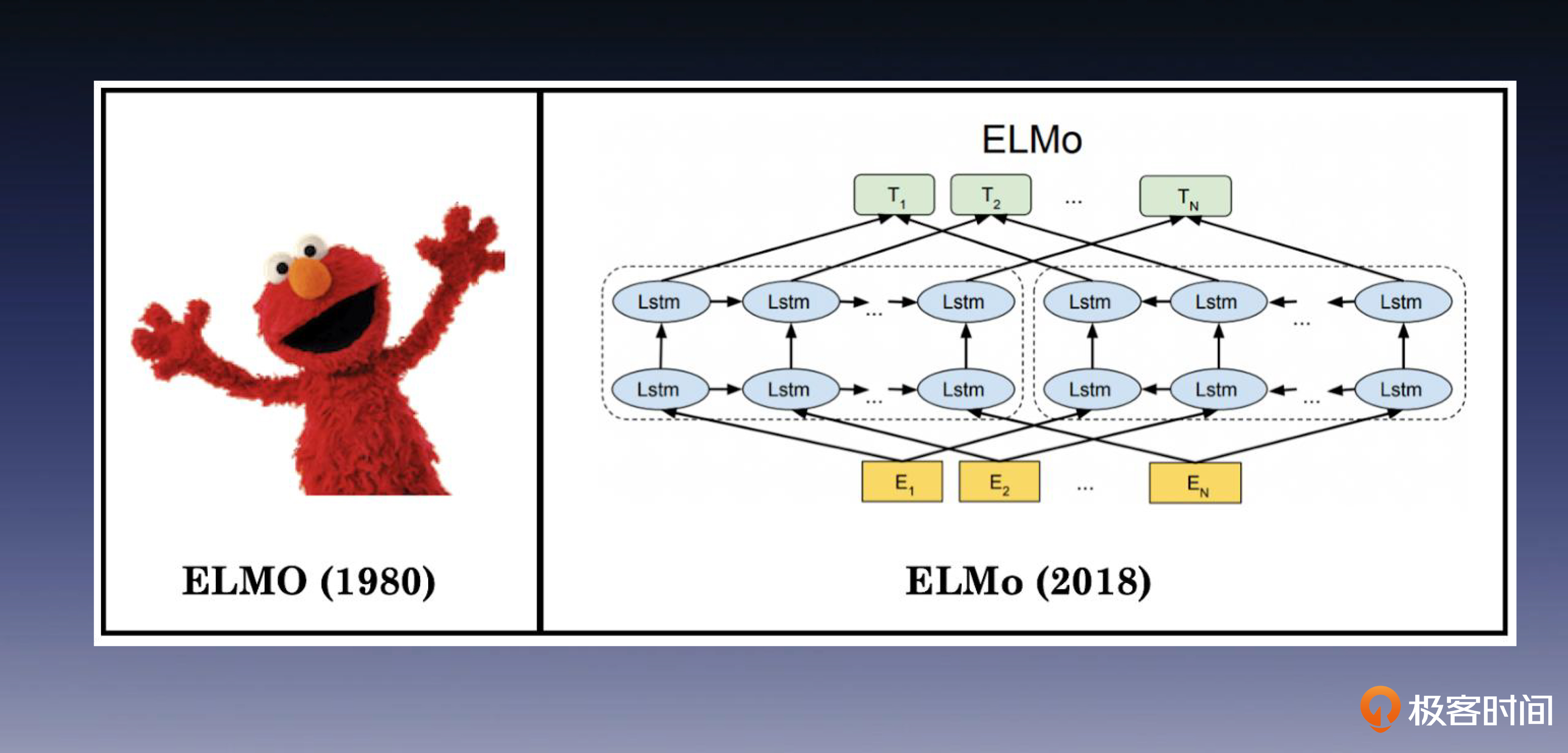
可以看到,ELMo由左侧的前向双层LSTM编码器和右侧的逆向双层LSTM编码器组成,每个编码器都由两层LSTM叠加而成。ELMo的重要贡献在于将上下文信息融入NLP词向量的表示中,提升了词向量的表达能力。
不过我们需要注意,尽管ELMo使用双层双向LSTM网络结构进行语言模型训练,但这两个双向模型是完全独立训练的,最终只是将它们的输出连接在一起,不是一个端到端的方法,这可能会导致一些信息的丢失(“端到端”是什么,你可以回顾第 7 节课)。
这时候人们已经逐渐意识到可以通过语言模型,基于对比学习的方式来进行 NLP 模型的预训练了,各家公司暗流涌动,直到 OpenAI 发布了历史性的 GPT-1。
GPT:预训练模型走上舞台
GPT-1(Generative Pre-Training)标志着一个重要的里程碑。我们看名字就知道,OpenAI一开始就将预训练模型(PTM)作为目标,因此也相应地设计了适用于多种NLP下游任务的微调方法。这一刻,NLP领域终于拥有大模型预训练+领域微调的策略了。
GPT系列一直采用了Decoder Only的Transformer架构,当时Transformer刚刚发表,足以看出OpenAI的判断非常准确。
ElMo提出了一个两阶段的方法:首先,在第一阶段使用一个庞大的语言模型进行预训练;然后,在第二阶段,使用特定下游任务的数据集做模型微调。后面这张图展示了如何修改GPT预训练模型,以便其兼容各种下游的NLP任务。
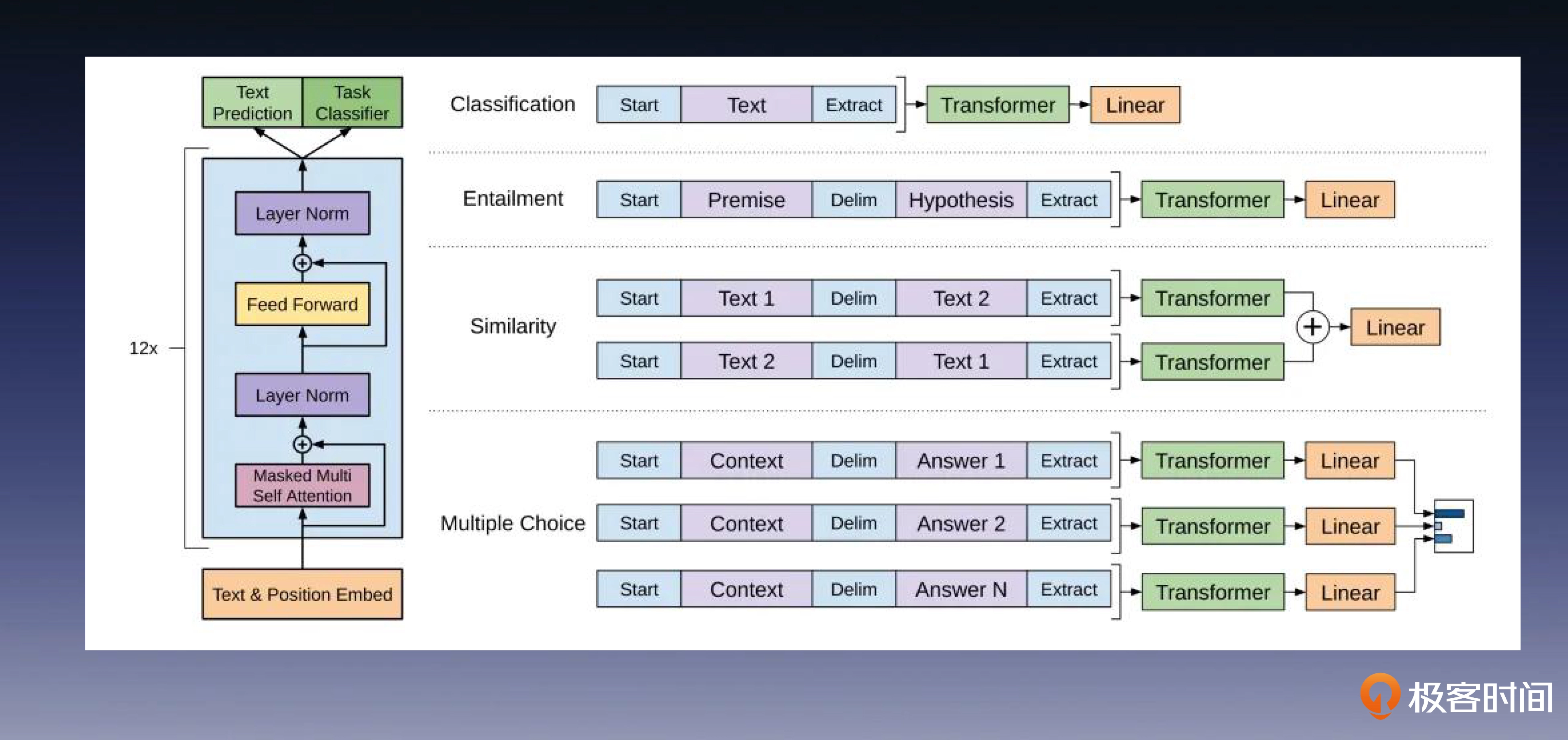
为了与下游任务的网络结构相匹配,GPT-1提出了一种对齐改造的策略。这种改造非常便捷,不同的任务,只需要对输出分进行适应性修改和微调就可以,具体的实现在后面的课程中我会详细展开。
如下图所示,由于GPT-1采用的是仅利用上文信息的Decoder Only架构,在完形填空等问题上显然存在一定的天然劣势,这就为BERT提供了施展才能的机会。

不过我们换个角度看,这种“劣势”在ChatGPT这类对话生成型任务上,反而成为了一项优点。这个巧妙的设计为OpenAI在生成式AI大模型领域的异军突起埋下了伏笔。在后面的课程,我将继续带领你深入学习GPT-1到GPT-3系列模型的更多内容。这里你先重点把握NLP PTM 的历史发展规律就可以。
BERT:预训练模型一鸣惊人
接下来,让我们将目光转向另一个重要的NLP预训练模型——BERT。BERT和GPT-1是在同一时期诞生的,当然,它的发表时间比GPT-1稍晚一些。
BERT与GPT-1在预训练过程中有明显差异。BERT采用了类似ELMo的双向语言模型,同时利用上文和下文信息进行建模预测。
BERT 在模型和方法方面的创新主要体现在 Masked 语言模型和 Next Sentence Prediction。Masked 语言模型使用掩码标记替换部分单词,并要求模型预测这些被替换的单词。Next Sentence Prediction 则要求模型判断两个句子之间的关系。因为在预训练阶段中同时使用这些技巧和各类任务的数据,所以 BERT 具备了多任务学习的能力。
BERT系列从一开始就采用了Encoder Only的Transformer架构,这一架构能够同时利用上文和下文信息,为BERT带来了显著的性能提升。所以它在各类NLP任务上表现出色,赢得了工业界的广泛认同,取得了巨大的成功,将NLP预训练模型技术推向了不可或缺的地位。
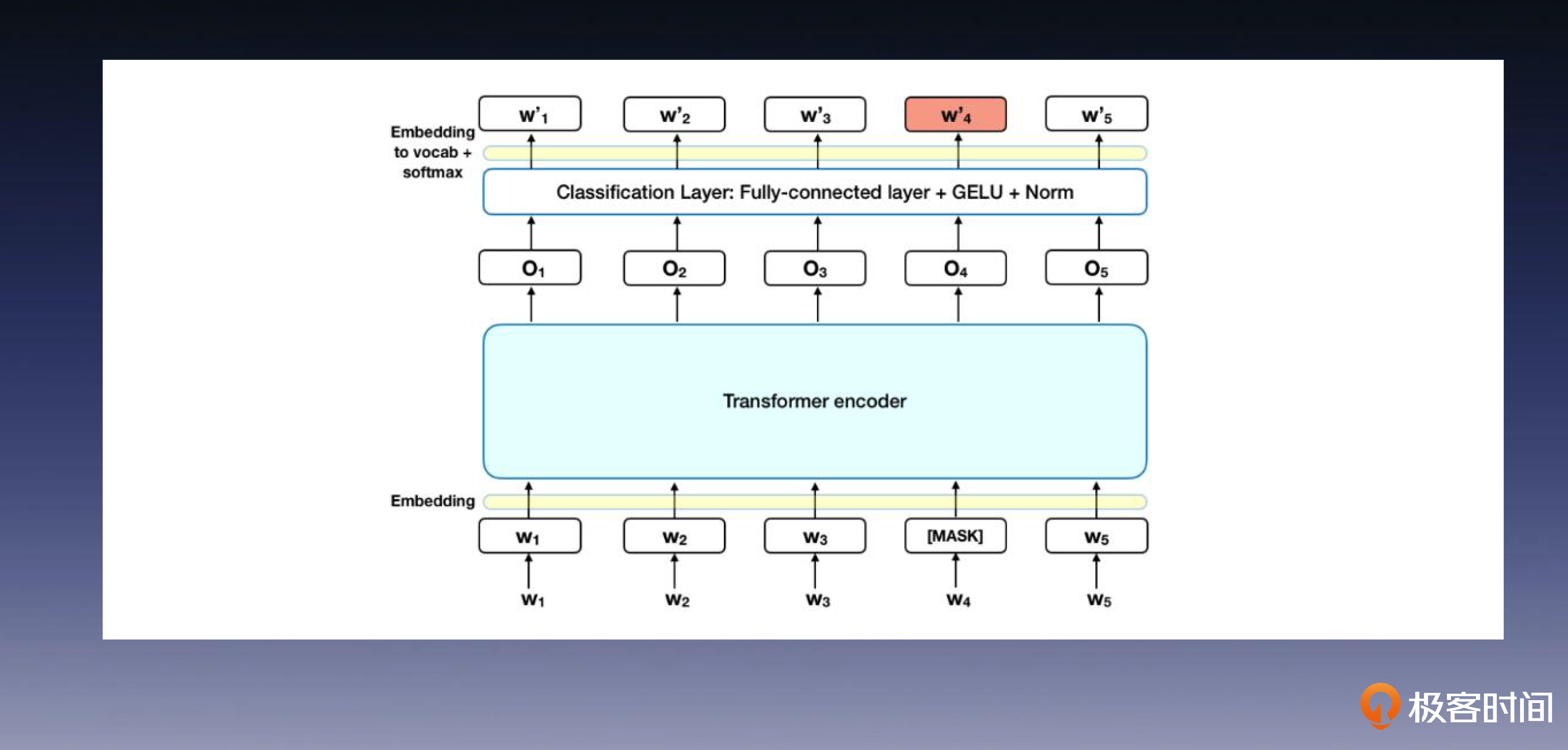
据传 OpenAI 与 Google 之间存在一段有趣的爱恨纠葛。传闻说,OpenAI认为BERT在方法上只是借鉴了GPT-1的设计思想,它的声誉很大一部分都源于训练数据量的提升以及Google强大的公关宣传。
由于BERT在NLP 预训练模型领域获得几乎所有赞誉,作为开创者的OpenAI一直在憋着一口气,准备超越BERT。
命运的齿轮在这时开始转动,最初一次偶然的选择导致这两家公司发展出了不同的技术路线。几年后,OpenAI的Decoder Only架构成为全世界关注的焦点,风头无人能敌。
总结
今天的内容告一段落,我们来做个总结。
相比计算机视觉(CV)领域的PTM技术,NLP面临更多的困难和复杂性。为了让模型更好地理解人类语言,研究人员一直在探索和突破,这也推动了NLP 技术的发展。
早期的尝试,如 Word2Vec,为 NLP 预训练模型的发展找到了正确的方向,为后来的研究提供了信心和希望。然而,这些方法也存在着一些明显的缺点,如无法处理词在不同语境中的不同含义。
随后,ELMo 和 GPT 等模型的出现为 NLP 预训练模型的发展带来了突破。ELMo 使用双向的语言模型,将上下文信息融入到 NLP 词向量,更准确地表示了词语的含义。而GPT则通过大规模预训练,在各类NLP下游任务中取得了显著的成果。
BERT 通过引入双向语言模型和更大规模的预训练数据,在各种NLP任务中展现了出色的能力,在工业界取得了巨大的成功,成为了各大公司不可或缺的核心技术之一。
最后,我想附上一张我的老东家——亚马逊发表的一篇论文(https://arxiv.org/pdf/2304.13712.pdf)中的一张图。该图清晰地描绘了现在大语言模型发展的几条主要路线的进化过程,我们可以看出,在 WordVec 和 ELMo 之后 BERT 和 GPT 开始分道扬镳。
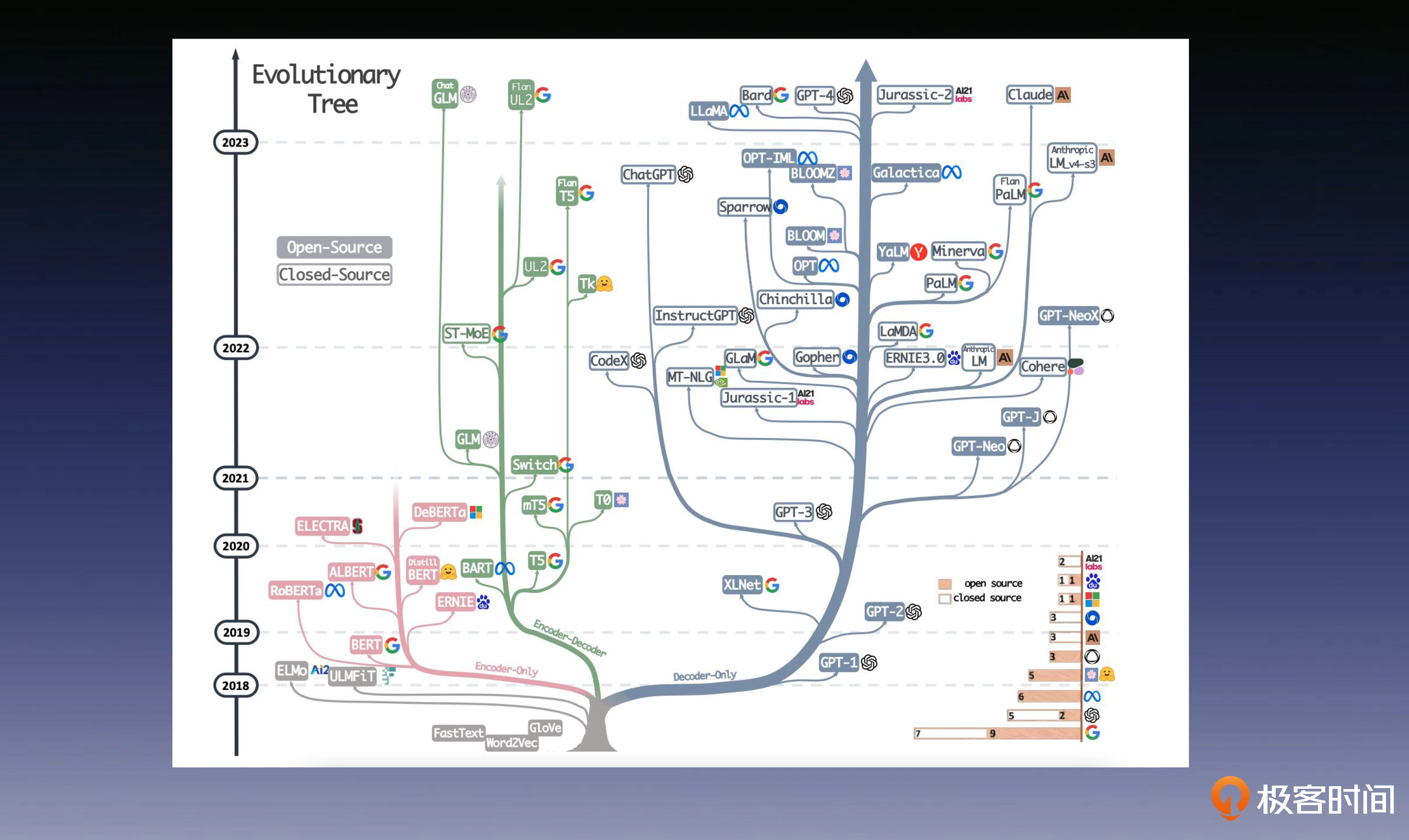
后面的故事将在后几节课揭晓,我会带你学习 GPT-1 到 GPT-3 的发展历程,让你知道 OpenAI 是如何一步步“战胜” Google 的。
思考题
既然 BERT 的模型使用了大数据和大参数模型进行训练,那它是否属于大语言模型(LLM)呢?
恭喜完成我们第 13 次打卡学习,期待你在留言区和我交流互动。如果你觉得有收获,也欢迎你分享给你身边的朋友,邀 TA 一起讨论。
- baron 👍(4) 💬(1)
bert 训练也是无监督且双向训练出来的,我理解大数据量、无监督都满足,不满足的是不能进行多任务。说得不对的地方请大牛更正哈,我没有算法基础。
2023-09-10 - 糖糖丸 👍(2) 💬(1)
非端到端方法为什么就可能会导致信息丢失呢?应该如何理解?
2023-10-27 - 顾琪瑶 👍(1) 💬(2)
看到这个思考题去搜了一些关于大语言模型的定义, 其中说到几点 1. 大量的文本数据进行训练 2. 过大规模的无监督训练来学习自然语言的模式和语言结构 3. 表现出一定的逻辑思维和推理能力 搜了下, BERT并不符合第3点, 那就代表不是LLM
2023-09-08 - aLong 👍(1) 💬(0)
属于大模型,因为我看到那个亚马逊的论文图片中包含了BERT,他是在Encoder-Decoder的路线上面。
2023-12-30 - 榕树 👍(0) 💬(0)
BERT(Bidirectional Encoder Representations from Transformers)和大语言模型(LLM,Large Language Models)之间有一些关键的差别。以下是它们的主要区别: 1. 架构设计 BERT:BERT 是一种基于 Transformer 的 encoder-only 模型。它的设计目的是通过双向(即同时从左到右和从右到左)理解文本的上下文信息。 大语言模型(如 GPT-3):大语言模型通常是基于 Transformer 的 decoder-only 模型,或者是 encoder-decoder 结构。GPT 系列模型(如 GPT-3)是典型的 decoder-only 模型,它们主要用于生成文本。 2. 预训练任务 BERT:BERT 使用掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)作为预训练任务。MLM 通过随机掩盖输入文本中的一些单词,然后让模型预测这些被掩盖的单词。NSP 则用于训练模型理解句子之间的关系。 大语言模型(如 GPT-3):GPT 系列模型使用自回归语言模型(Autoregressive Language Model)进行预训练,即通过预测序列中的下一个单词来训练模型。这种方法使得模型在生成文本时能够逐步生成每个单词。 3. 应用场景 BERT:BERT 更适合于理解和处理文本的任务,如文本分类、命名实体识别、问答系统、文本匹配等。它在需要深入理解文本上下文的任务中表现出色。 大语言模型(如 GPT-3):大语言模型在生成文本、对话系统、内容创作等任务中表现出色。它们能够生成连贯且上下文相关的长文本段落。 4. 模型大小和计算资源 BERT:BERT 的模型大小相对较小,常见的版本有 BERT-Base 和 BERT-Large。虽然它们也需要大量的计算资源进行预训练,但相比于最新的大语言模型,它们的规模较小。 大语言模型(如 GPT-3):大语言模型的规模通常非常庞大,例如 GPT-3 具有 1750 亿个参数。这些模型的训练和推理需要极其庞大的计算资源。 5. 训练数据 BERT:BERT 在预训练时使用了大量的文本数据,但这些数据主要用于理解文本的语义和上下文。 大语言模型(如 GPT-3):大语言模型通常使用更大规模和更多样化的文本数据进行训练,以便在生成文本时能够更好地模拟人类语言。 总结 BERT 和大语言模型(如 GPT-3)在架构设计、预训练任务、应用场景、模型大小和计算资源等方面都有显著的差异。BERT 更侧重于文本理解任务,而大语言模型则在文本生成任务中表现出色。两者在自然语言处理领域都有广泛的应用,但它们的设计目标和优势有所不同。
2024-12-27 - Seachal 👍(0) 💬(0)
ERT那大数据大参数训练的模型,确实算大语言模型(LLM)里的一员了。 这篇文章啊,讲了NLP领域的挑战,语言多样性、数据集缺乏这些问题。然后Word2Vec无监督学习来了,语义理解、机器翻译都用上了。接着ElMo解决词义多义性问题,GPT-1预训练模型下游任务微调效果也挺好。还说了BERT和GPT-1预训练的不同,BERT的Masked语言模型、Next Sentence Prediction这些创新点也提了下。
2024-11-23 - St.Peter 👍(0) 💬(0)
https://arxiv.org/pdf/2304.13712 这是一篇非常好的梳理。其中的图片更是在网络上很流传。
2024-11-11