26 模型工程(二):算力受限,如何为“无米之炊”?
你好,我是 Tyler。
上节课,我们学习了如何对特定领域的问题进行训练数据增强。在Alpaca的原文中,虽然已经大幅减少了模型微调所需的计算资源,但仍然需要相当大的算力开销。
Alpaca 论文的作者,使用了 8 块 80GB 的 A100 显卡,进行了 3 小时的微调,才完成训练。不难发现,这样的成本仍然很高,所以业界也一直在探索更具性价比的训练方法,其中最经典的方法莫过于 LoRA。
我们这节课将重点介绍LoRA技术的原理和使用方法,通过理论讲解和实践练习,帮助你掌握LoRA技术,并且在下一节课中用LoRA技术来微调自己的预训练大语言模型。
LoRA:低秩适应
如果你对文生图的领域有所关注,那么你一定对 LoRA 模型一定不陌生,它似乎已经成为自动定制二次元小姐姐的代名词。

然而,实际上LoRA是一种通用的模型训练方法。它最早本就是用来加速大语言模型训练的,这点你从它的全称 “Low-Rank Adaptation of Large Language Models” 就能看出来。
为了进一步降低微调的成本,来自斯坦福大学的研究员Eric J. Wang采用了LoRA(低秩适应)技术复制了Alpaca的结果。
具体来说,Eric J. Wang使用了一块RTX 4090显卡,仅用了5个小时就成功训练出了一个与原版Alpaca相媲美的模型,成功将这类模型对计算资源的需求降低到了消费级显卡的水平。此外,这个模型甚至可以在树莓派上运行,非常适合用于小型的研究团队。
总的来说,LoRA的应用范围广泛,可以帮助我们以更低的成本完成模型训练。
核心思想
在深入研究 LoRA 之前,我先带你简要回顾一下模型训练或者微调的过程。
首先,我们回顾一下什么是权重变化 $\Delta W$ ?假设 $W$ 代表神经网络层中的权重矩阵。使用标准的反向传播,我们可以计算梯度来得到权重的更新 $\Delta W$ 。至于梯度下降法的原理则是我们在第七节课中学习的内容(如下图)。

LoRA技术的核心观点是,预训练的大语言模型在适应特定任务时,可能仅仅依赖于较低的“内在维度”。即使将其权重投射到较小的子空间,模型仍然可以有效地学习,这一观点构成了LoRA技术的理论基础。
具体而言,LoRA的作者认为模型通常是过度参数化的,它们具有更低的“内在维度”,模型主要依赖于这个更低的维度来完成任务。LoRA技术允许我们通过在微调过程中,使用全连接层(dense layer)的秩分解矩阵,间接训练神经网络中的一些全连接层,同时保持预先训练的权重不变。
通过文稿后面的这张图,你会发现,LoRA 的实现思想很直观:我们首先冻结一个预训练模型的矩阵参数,然后选择使用A和B矩阵来代替这些参数。在下游任务的训练中,我们只对A和B进行更新即可。
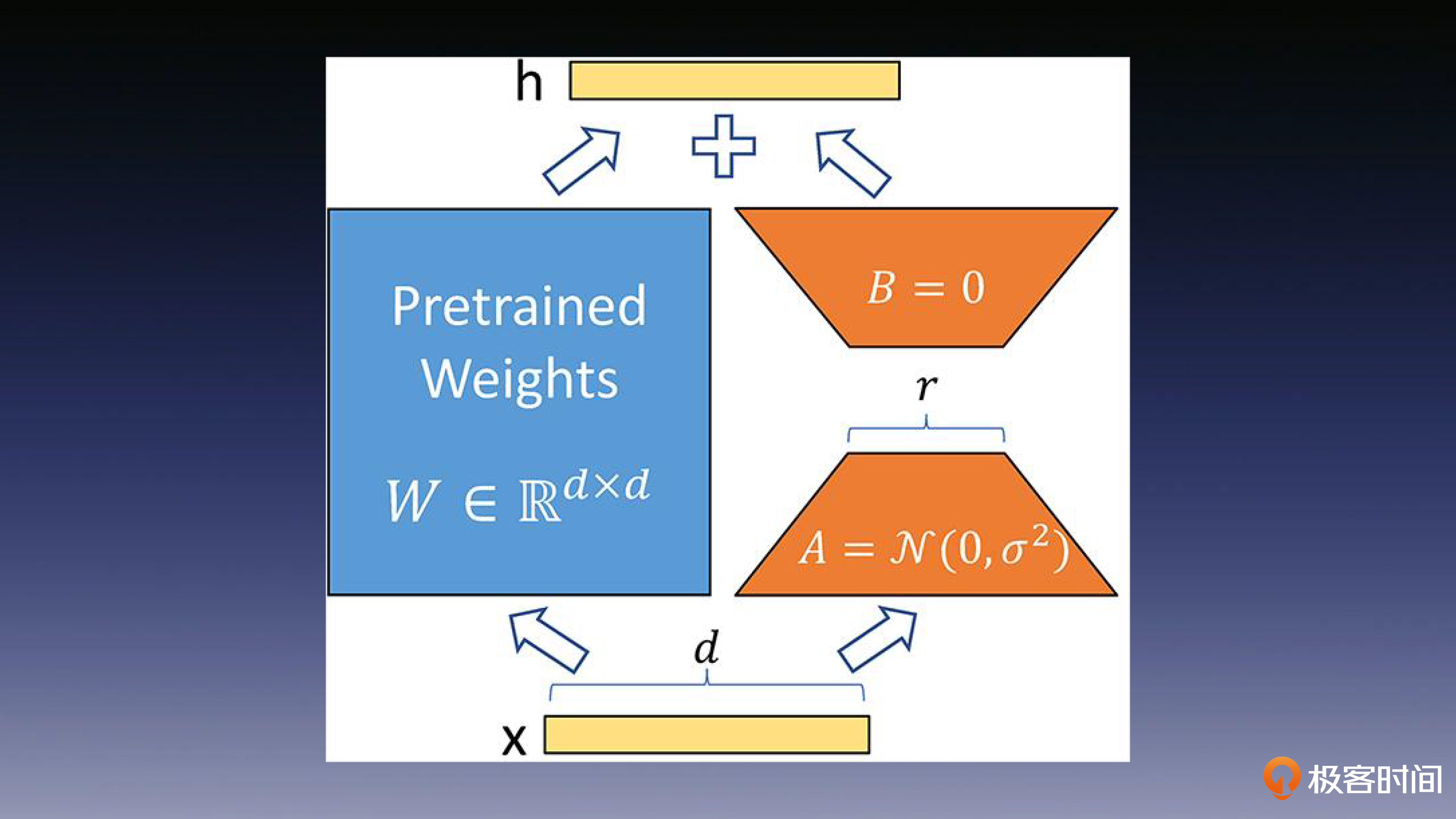
该方法会在原始的预训练模型右侧添加一个侧通道,进行降维和升维的操作,以模拟内在维度的概念。在训练的过程中,需要保持预训练模型的参数不变,只对降维矩阵A和升维矩阵B进行训练。模型的输入输出维度保持不变,在输出时,将BA矩阵与预训练的参数相叠加即可。
这里我想提醒你注意的是,我们需要使用随机高斯分布来初始化矩阵A,同时使用零矩阵初始化矩阵B,这样可以确保在训练开始时,这个侧通道矩阵是一个零矩阵。
方法原理
接下来,我们将从数学公式的角度详细解释LoRA的实现。
当我们需要对一个预训练语言模型(如GPT-3)进行下游任务的微调时,我们需要更新预训练模型的参数。这个过程可以用如下数学公式表示:$W_0 + \Delta W$。
在这个公式中,$W_0$ 代表了预训练模型的初始参数,而 $\Delta W$ 代表了需要更新的参数。如果我们要进行全参数微调,那么 $\Delta W$ 的参数量将等于 $W_0$ 的参数量,比如对于GPT-3来说, $W_0$包含了约175B个参数,所以全参数微调对于大语言模型而言,所需的计算资源是巨大的。
然而,得益于低维“内在维度(intrinsic dimension)”的存在,让我们可以在任务适配过程中做到“四两拨千斤”。也就是说,即使将权重参数随机投影到较小的子空间,模型仍然能够继续有效地学习。
因此,从本质上看,LoRA的目标就是引入一个较小的参数模块,用于学习参数变化 $\Delta W$。后面有不少的公式,会用到前面课程的人工智能基础知识,忘记的同学回去复习一下。
具体而言,LoRA使用低秩分解的方法来表示预训练的权重矩阵 $W_0$ 的更新,预训练的权重矩阵表示为 $W_0 \in \mathbb{R}^{d \times k}$,其中 d 是输入维度, k 是输出维度。更新可以表示为 $W_0 + \Delta W = W_0 + BA$,其中 B 是一个 $d \times r$ 的矩阵, A 是一个 $r \times k$ 的矩阵,而秩 $r \ll \min(d, k)$。
在训练过程中,我们保持 $W_0$ 不变,不接受梯度更新,而 A 和 B 包含了可训练的参数。当输入向量 x 通过 $W_0$ 进行线性变换,得到输出向量 $h = W_0x$ 时,修正后的前向传播可以表示为 $h = (W_0 + \Delta W)x$。
在推理的过程中,只需要将 $\Delta W$ 放回原始模型。我们可以把 W 表示为后面的形式,也就是 $W = W_0 + BA$。
如果需要切换到另一个任务,只需在切换过程中减去 BA,然后使用另一个任务的训练好的参数 B’ 和 A’ 来替代就可以了。你可以仔细看看后面 LoRA 实现的伪代码,再对照一下我刚才说的过程。
input_dim = 768 # 例如,预训练模型的隐藏层大小
output_dim = 768 # 例如,层的输出大小
rank = 8 # 低秩适应的秩 'r'
W = ... # 从预训练网络中获取,形状为 input_dim x output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA 权重 A
W_B = nn.Parameter(torch empty(rank, output_dim)) # LoRA 权重 B
# 初始化LoRA权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
def regular_forward_matmul(x, W):
h = x @ W
return h
def lora_forward_matmul(x, W, W_A, W_B):
h = x @ W # 常规矩阵相乘
h += x @ (W_A @ W_B) * alpha # 使用缩放的LoRA权重
return h
技术价值
LoRA技术让我们在充分利用了预训练模型的知识的前提下,大幅降低了微调训练的计算和内存开销,是一种高效的方法。
当然,LoRA技术并不仅仅适用于大语言模型,它可以应用在深度模型的各个模块,通过减少可训练参数的数量来提高效率。
举个例子,比如在 Transformer 模型中的在 Self-attention(自关注) 模块中通常包含四个权重矩阵(wq、wk、wv、wo),而在 MLP 模块(多层的神经网络)中通常包含两个权重矩阵。
LoRA技术允许将适应下游任务的注意力权重限制在自关注 Self-attention模块中,并冻结MLP模块,以简化和提高参数效率。有了LoRA技术的加持,我们在训练大规模深度学习模型时,就可以明显地降低 GPU 的资源开销。
对于使用 Adam 优化器训练的大型 Transformer,当 $r ≪ d$ 时,由于不需要存储被冻结参数的优化器状态,可以将VRAM使用量减少多达2/3。这是因为LoRA技术只需要训练r个低秩矩阵,而原始模型需要训练d个高秩矩阵。
Adam 优化器是一种在深度学习模型中用来控制梯度下降策略的优化算法,我们在前面的课程也略有提及,这里对不熟悉的同学展开一下。
首先,我们知道,模型训练的梯度下降是一个向最优解行走的过程,而优化器则决定了行走的姿势和效率。Adam 优化器的核心思想是使用动量和自适应学习率。动量可以帮助模型更快地收敛,而自适应学习率可以防止模型在鞍点处震荡。它是一种用来解决稀疏梯度和噪声问题的优化方法,而且 Adam 的调参相对简单,默认参数就可以处理绝大部分的问题。
我举个例子更具体一点的例子,来帮助你理解。在GPT-3 175B上,训练中的显存消耗从1.2TB减少到350GB。当 $r=4$ 并且仅调整query矩阵和value矩阵时,checkpoint大小减少了10000倍(从350GB减少到35MB)。
LoRA技术的另一个优点是,它可以在部署时以更低的成本切换任务。只需要交换LoRA权重即可。与完全微调相比,GPT-3 175B训练速度提高了25%,这是因为LoRA技术不需要计算绝大多数参数的梯度。
总结
这节课,我带你学习了一种名叫LoRA的技术,它的目标是省钱省力地微调大型语言模型。基本思路就是在调整这个模型的时候,仅考虑到它内在的“精简信息”,这样我们需要更新的参数就少了很多。
具体来说,LoRA通过把原模型的权重拆成小块矩阵,然后只训练这些小块,而不动原始权重。这个方法极大地减少了计算和内存的开销,让微调变得更划算。
实际上,这个LoRA技术可以用在各种深度学习模型上,帮助提高训练效率,同时降低了语言模型训练中昂贵的计算资源开销。另外,它在切换任务时的成本也很低,不需要重新训练整个模型,只需调整这些小块矩阵。不过,虽然 LoRA 在微调中会带来极大的算力节省,但是在推理上会带来一定的开销增长,在使用的时候需要做一下权衡。
现在我们已经了解了如何增强数据,并学习了低成本的训练方法。下节课就带你端到端地使用 Alpaca 训练一个模型,敬请期待。
思考题
- 通过你对 LoRA 的学习,分析一下在使用 LoRA 微调的过程中,可能会存在哪些问题?
- 请通过 AutoML 的方法自动化 LoRA 的调参过程。
- 结合你对前面学习的知识,辨析一下 LoRA 方法和向量检索中的经典 ANN 算法 PQ 之间有何联系?(这是一道我曾面试AI大模型相关业务候选人的题目)
恭喜完成我们第 26 次打卡学习,期待你在留言区和我交流互动。如果你觉得有收获,也欢迎你分享给你身边的朋友,邀 TA 一起讨论。
- Zachary 👍(2) 💬(0)
对于不典型的任务类型,LoRA这么做应该影响很大,因为不知道该换上哪套BA参数了?而GPT3/4的能力看起来是连续的,也就是能胜任很多我们无法明确指名道姓的非标准任务(尽管有强化学习和MoE来增强特定任务的能力),LoRA在这些非标准任务上也许就不太行了,能力比较离散。考虑到这一点后,用一些优化方法也许可以改善。
2023-11-14 - 顾琪瑶 👍(2) 💬(0)
1. 猪脑过载, 想不到 3. 内在联系, 就像介绍LORA时说的, "较低的内在纬度", 也就是说在针对特定任务微调时, 只需要关注一个子空间中的参数即可, LORA和ANN都是只关注部分向量即可, 也就是分而治之
2023-10-18