07 应用:为什么说控制逻辑才是C语言自动判题系统的核心
你好,我是金伟。
上节课我们重点介绍了C语言自动判题系统的程序设计和提示词工程。如果说提示词占到这个项目的50%,那应用逻辑的开发则是另外50%。之所以有这么大的应用逻辑工作,本质还是由于大模型存在幻觉问题,在C语言自动判题系统这个场景下不能保证100%准确,只能靠控制逻辑来增强可靠性。
在这个项目中,让我印象最深的就是C语言作业对比功能的实现,这个功能经历了多次迭代才驯服大模型,类似的例子还有多个,我会在这节课一一分析出来。
为了让你更好地理解,让我们先从C语言自动判题系统的用户交互设计开始说。
用户交互设计
根据上一节课的程序设计原则,我将C语言自动判题系统分为了两个部分,分别是题库模块和判题模块。其中,题库模块负责利用AI自动化配置题库,判题模块负责利用AI,在题库基础上判学生的作业题,再给他们评分。
题库模块设计
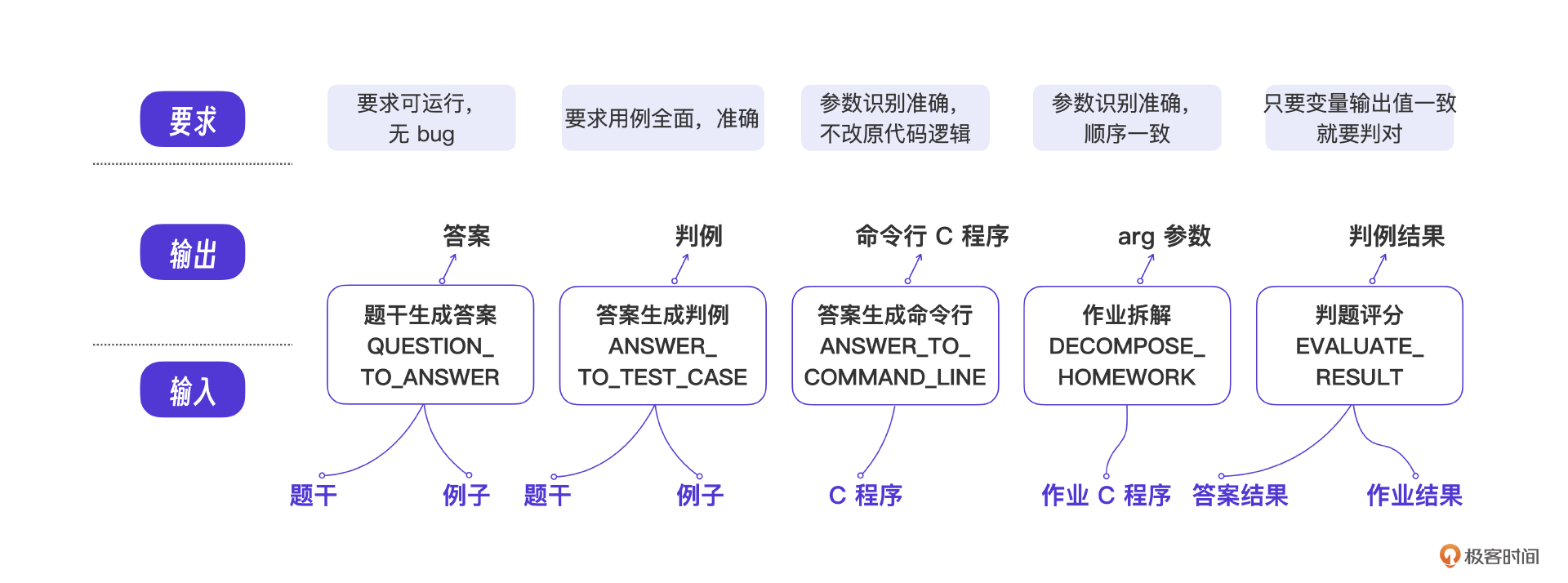
我来梳理一下题库模块的设计,它的输入是现有系统的题干,输出是借助AI整理完成的题库,从下面的示意图里能看到,这个题库里还包含了题目的答案、命令行答案、案例以及运行结果。整体思想是借助AI提高题库内容的生产效率,先由AI一步步生成题库内容,最终再由老师修改并确定AI生成的内容,从而保证题库信息的准确性。
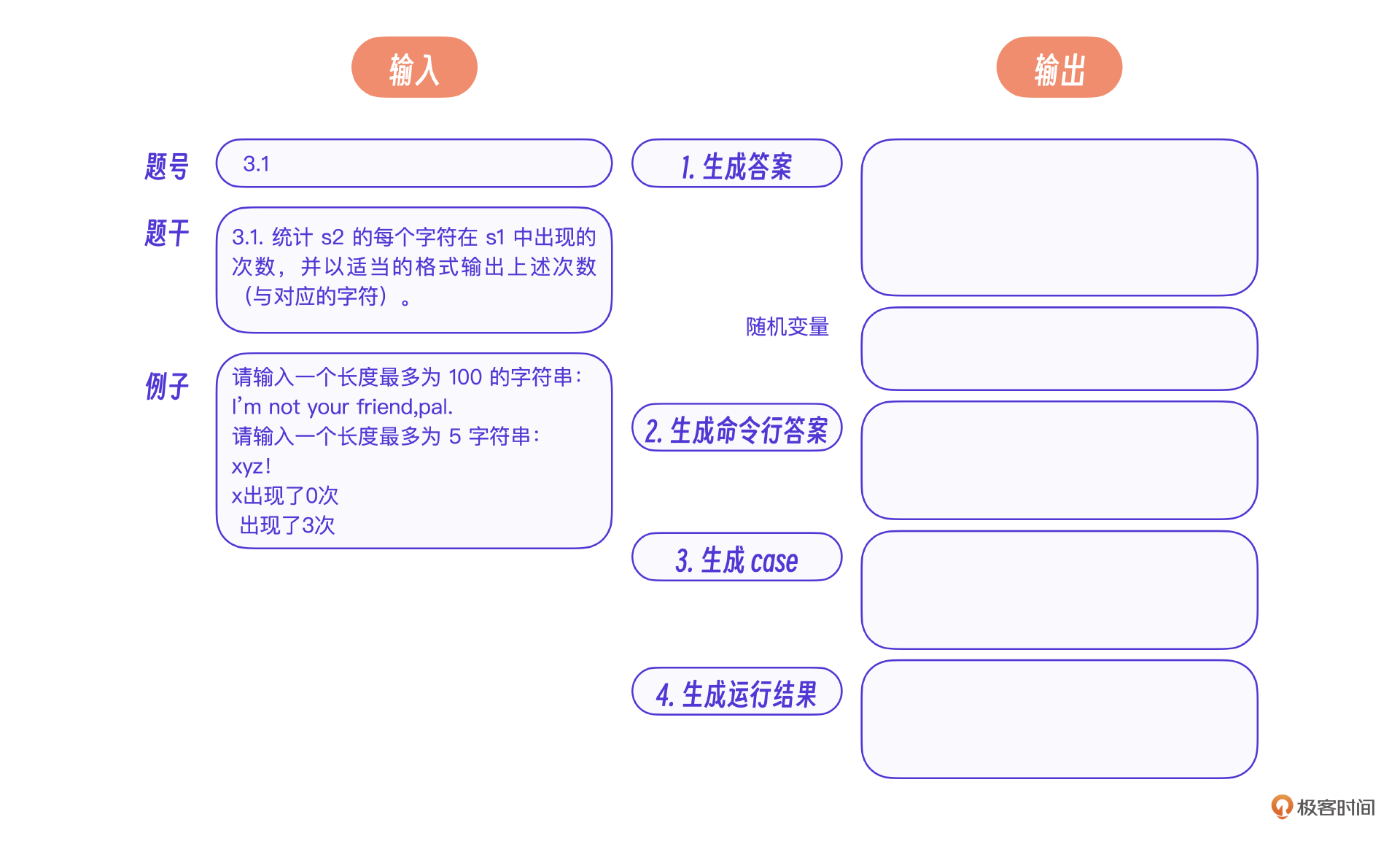
也就是说,这个交互的核心流程分为4步,分别是生成答案、生成命令行答案、生成case用例和生成运行结果。前面步骤生成的结果决定了后面步骤的结果,因此需要用户依次检查、确定每一步的生成结果。核心流程的前3步借助AI生成内容,第4步则采用传统应用程序。
题库模块确认的标准答案和case用例,都会在接下来的判题模块里用到。
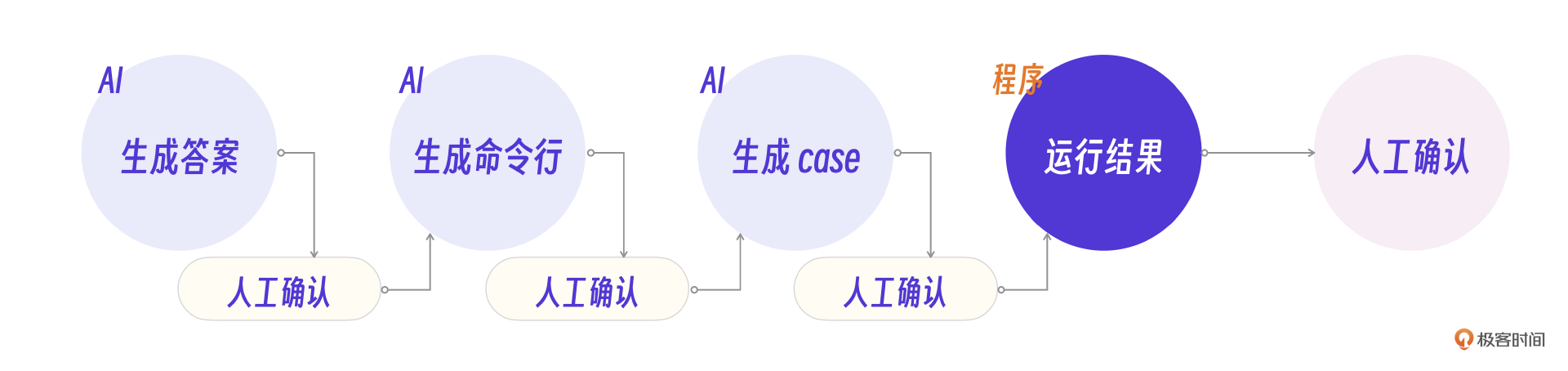
判题模块设计
判题模块的设计思路仍然是借助AI辅助判题,最终由老师确认结果。一个典型的例子就是让老师随时可以修改学生的答案,以便根据实际情况修正对学生作业的评估。
判题模块分为两个核心流程,分别是单个学生判题和一次性判题。
交互设计如下图。
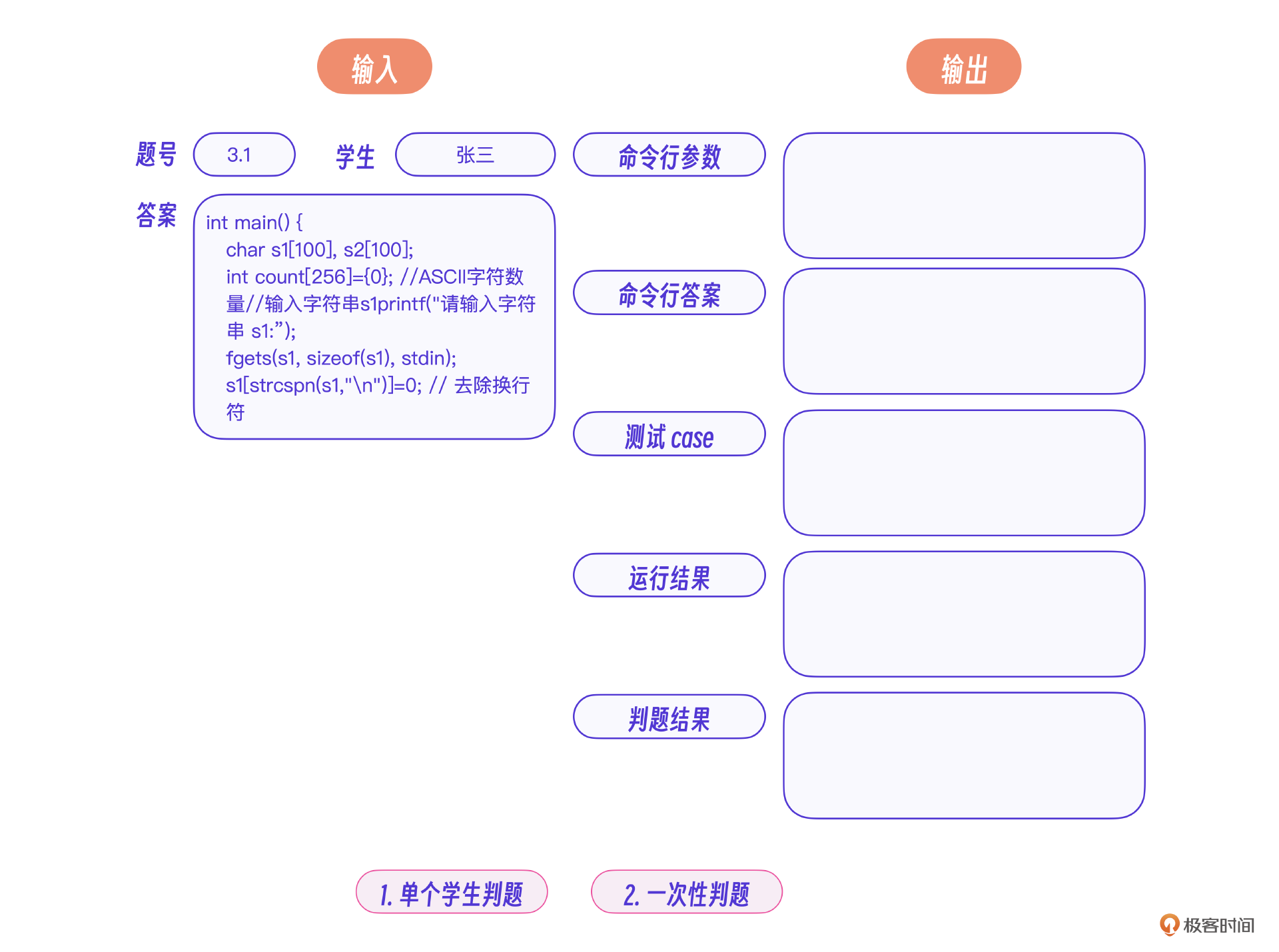
一次性判题的逻辑是用当前规则对所有学生依次自动判题,运行过程中不需要人工监督,内部则是依次运行单个学生判题流程。而单个学生的判题流程也是全自动的,运行过程不需要人工干预。
显然,判题模块的挑战在于每个学生,每一道题都可能不一样,容易漏判和误判。我们的解决方案是让用户先对部分学生运行单个学生判题流程,根据结果调整其中某一道题的判题规则,确认之后再运行一次性判题。
当然这个模块的实际细节更多,我们慢慢来,不着急。
有了交互设计和上一节课的基本提示词,就可以开始编写应用程序来实现整个系统了。
如何用AI写代码?
很多人可能会想,既然已经有了核心提示词和用户交互的详细设计,那是不是把这些信息给AI,就可以完整实现整套系统了?
理论上确实如此。你想想看,每一步的输入输出都详细设计清楚了,有了这些信息,AI完全有能力输出整套系统代码。
实际情况并非如此。用大模型写代码和用大模型生成其他内容一样,往往是“不靠谱”的,需要控制才能达到商用级别。
我们先回顾一下上一节课提到的核心提示词。
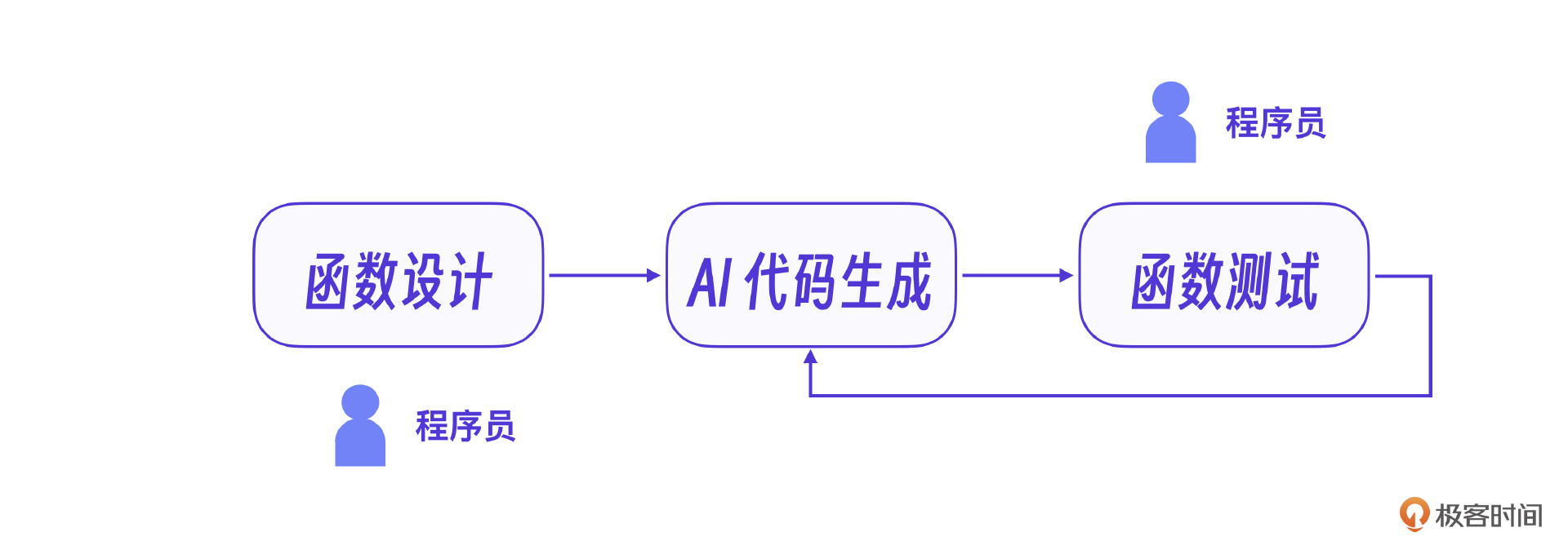
结合这节课的交互设计,可以发现,每一个用户交互正好对应一个提示词,相当于我们的系统已经设计到函数这个级别了,接下来要做的就是让AI按每个函数要求写出代码,程序员根据AI生成的代码做测试,然后进一步完善这个函数。
为了说明这个过程,我来举一个典型的例子。虽然这个例子不是本节课的代码,但它具有很强的参考意义。
假设我现在的需求是用 pytube 模块实现视频的下载和分割,每30s分割一个视频并保存。可以用下面简单的提示词让AI生成代码。
生成的核心代码如下。
# 分割视频v1
def split_video(input_path, segment_length=30):
video = VideoFileClip(input_path)
duration = video.duration
basename, ext = os.path.splitext(input_path)
segments = []
for start in range(0, int(duration), segment_length):
end = min(start + segment_length, duration)
segment = video.subclip(start, end)
segment_filename = f"{basename}_part{start//segment_length + 1}{ext}"
segment.write_videofile(segment_filename, codec="libx264", audio_codec="aac")
segments.append(segment_filename)
return segments
我们直接运行这段代码发现效果很好,没有任何bug。然而当我的需求发生变化时,比如我希望分割时间按我提供时间序列来进行,类似 "20,50,70,120.." 这样按设定的秒数分割,把提示词和版本1的代码提交给AI,生成的代码经过多次修改仍然达不到预期的效果。
# 分割视频v2
def split_video(input_path, segment_lengths=[30]):
video = VideoFileClip(input_path)
duration = video.duration
basename, ext = os.path.splitext(input_path)
segments = []
start = 0
for i, segment_length in enumerate(segment_lengths):
print(segment_length)
while start < duration:
end = min(segment_length, duration)
segment = video.subclip(start, end)
segment_filename = f"{basename}_part{i + 1}_{start}-{end}{ext}"
segment.write_videofile(segment_filename, codec="libx264", audio_codec="aac")
segments.append(segment_filename)
start += segment_length
break
return segments
注意,这个V2版本的视频分割代码中,第18行的 break 是我手工添加的,因为AI生成的逻辑一直无法解决多次循环的问题,所以最终还是程序员出手才解决了这个bug。
C语言自动判题系统里用AI编写函数的过程过于简单,在此不一一说明。但你现在一定能理解,用程序调整、控制大模型的逻辑并达到商用级别,是整个项目里的重中之重。
控制大模型的经验
如果回顾整个项目的开发经验,整个开发过程中我做得更多的是大模型和应用逻辑的权衡工作。这句话要怎么理解呢?我想回顾一些典型的例子,这样更有助于你理解清楚AI程序开发的这个特性。
问题1:不稳定的输出格式
应用程序和大模型是一个机机交互过程,机机交互和人机交互有所不同,最典型的就是机机交互要求大模型的输出具备一定格式,这样才方便程序后续读取内容。
例如上节课里的 QUESTION_TO_ANSWER 提示词。
这是题干生成答案应用的提示词,其中 $$$start$$$ 和 $$$end$$$ 是希望大模型输出的分隔符,但实际运行过程中,输出总有一定的几率不受这个规则控制,它不按预定义的格式输出,喜欢自己添加一些额外说明,或偷偷更换分隔符,所以最终还是需要写程序控制。
就像这段处理代码显示的那样,大模型实际输出用的是 ````c` 和 ````` 这两个分割符。在大模型应用里,更常见的就是json格式输出,同样需要先用代码检测json格式的合法性,再进一步处理其他逻辑。
问题2:case生成的教训
再看 答案生成判例 应用里的问题,它使用的是上一节课提到的 ANSWER_TO_TEST_CASE 提示词,实际运行结果发现,大模型总是生成很多极端的case。
例如下面的输出。
在这个case的输出里,第一个参数10是输入的总长度,第二个参数是分割的长度。但是从用例2开始,分割长度已经超过总长度,明显不合理。这些用例确实是一些极端边界,但是我们可以想象,在判题场景里,每道题不一样,而老师希望考察学生的点也比较主观,尝试调整 ANSWER_TO_TEST_CASE 提示词也也没办法完成这些个性化的需求。
最后我采用的方法是将这个AI输出作为参考,而非直接使用。这里得到的经验是什么呢?是我们可以在AI程序设计阶段评估AI的能力界限,从而设定边界,降低对AI的预期。
正如这个项目里的另外一个例子,在题库系统运行答案获得结果的环节,系统设计时直接采用gcc来运行代码的方案,而没有用AI直接运用C程序。这就是一个很好的边界设计。
#编译C代码
try:
subprocess.run(['gcc', '-std=c99', c_file_path, '-o', 'compiled_program', "-lm"], check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
except subprocess.CalledProcessError as e:
... ...
命令行的优化与权衡
在命令行生成的应用里,也能很好地体现这种边界设计的经验。对学生作业C语言程序,一开始我们用命令行提示词 ANSWER_TO_COMMAND_LINE 去处理学生作业。
ANSWER_TO_COMMAND_LINE: """
我在做一个判题系统,下面是答案的C语言程序,要求把输入变量的输入方式有键盘输入改为命令行接收输入,其他任何语句一个字母都不要改,printf("\\n") 不要改成 printf("\n")
注意:你可以从答案C语言里找所有scanf函数,并且全部替换为命令行输入方式,一个也不能遗漏
下面是答案C语言程序:
\"\"\"
{程序}
\"\"\"
换行符要用 "\\n" 输出
注意C语言程序输出要有明确的分隔符,以便后续我提取,例如:
$$$start$$$
C语言程序
$$$end$$$
"""
你可以看到这个提示词里 其他任何语句一个字母都不要改 之类的限定条件,但实际结果是什么呢?实际运行过程中,学生作业的命令行修正没有问题,但是学生作业原有的错误却也被自动修改了。这显然不是我们要的。
于是我修改了设计,只让AI解决args参数判断这个小问题,最后仍然用程序控制来做剩余的工作。
DECOMPOSE_HOMEWORK: """
... ..
输出所有的参数名字和每个参数的argv,以及变量类型就行,下面例子的x,y,z就是学生作业里的输入参数变量名字,int表示整型,string表示字符串类型,float表示浮点型,例子:
"x": "argv[1],int",
"y": "argv[2],string"
"z": "argv[3],float"
输出是一个json串即可,不要任何额外说明和代码。
"""
也就是用 DECOMPOSE_HOMEWORK 这个提示示词,大模型可以把学生作业里的参数识别得非常准确,现在则用程序代码实现控制逻辑,将学生作业的args参数部分做对应的修改,实现方法如下。
#参数替换程序
def replace_argv(c_code, argv):
lines = c_code.split("\n")
last_line = ""
for line in lines:
iput = ""
if line.find("scanf(") >=0 or line.find("fgets(") >=0:
for k in argv.keys():
v = argv[k]
print(k,v)
v,t = v.split(",")
if t == "int": #对参数单独替换
v = "atoi(" + v + ")"
... ...
i = c_code.find(line)
c_code = c_code[:i] + iput + c_code[i+len(line):]
... ...
return c_code
这个案例也可以得到一些经验,是什么呢?在 AI 开发中遇到一个复杂问题的时候,不一定要将问题全部交给 AI 解决,可以拆解为多个任务,让 AI 完成合适的子任务即可。
核心逻辑和交互的迭代
这个项目的 结果比对 应用是最复杂的。比如实际运行过程中,用于结果比对的 EVALUATE_RESULT 提示词总是对数字完全相同但文字描述略有不同的结果存在误判,怎么修改都无法解决这个问题。最终,我们还是使用了一个程序控制逻辑来解决这个常见问题。
看下下面的代码。
##二次判题(保证完全一致的不判错)
def judgement2(answer_result, homework_result, pan_result_code):
... ...
for case in answer_result.keys():
if diff2(answer_result[case]['运行结果'], homework_result[case]['运行结果']):
pan_result_code[case]['结果'] = '正确'
pan_result_code[case]['错误说明'] = '无'
注意,在上述 judgement2 控制代码逻辑里,我直接使用了 diff2 来判断两个输出的核心数据是不是一致。
实际上我们发现误判情况无法避免,那怎么办呢?最终的解决方案是引入一个判题策略的可定制机制,修改提示词 EVALUATE_RESULT 加入如下部分。
EVALUATE_RESULT: """
你的角色是一个判断学生作业的系统,你根据下面数据直接判断结果,不要写程序,
... ...
补充规则如下:
\"\"\"
{补充规则}
\"\"\"
以补充规则优先,你直接根据数据按规则自己判断,不要输出程序,不要有任何代码
... ...
"""
提示词里的 补充规则 就是让老师可以对每个题目制作自己的正向-负向判题规则,再修改提示词的生成代码,之后加入如下代码逻辑,就能实现正负向规则嵌入。
反映到操作交互界面,则是加入一个判题规则的可定制交互。
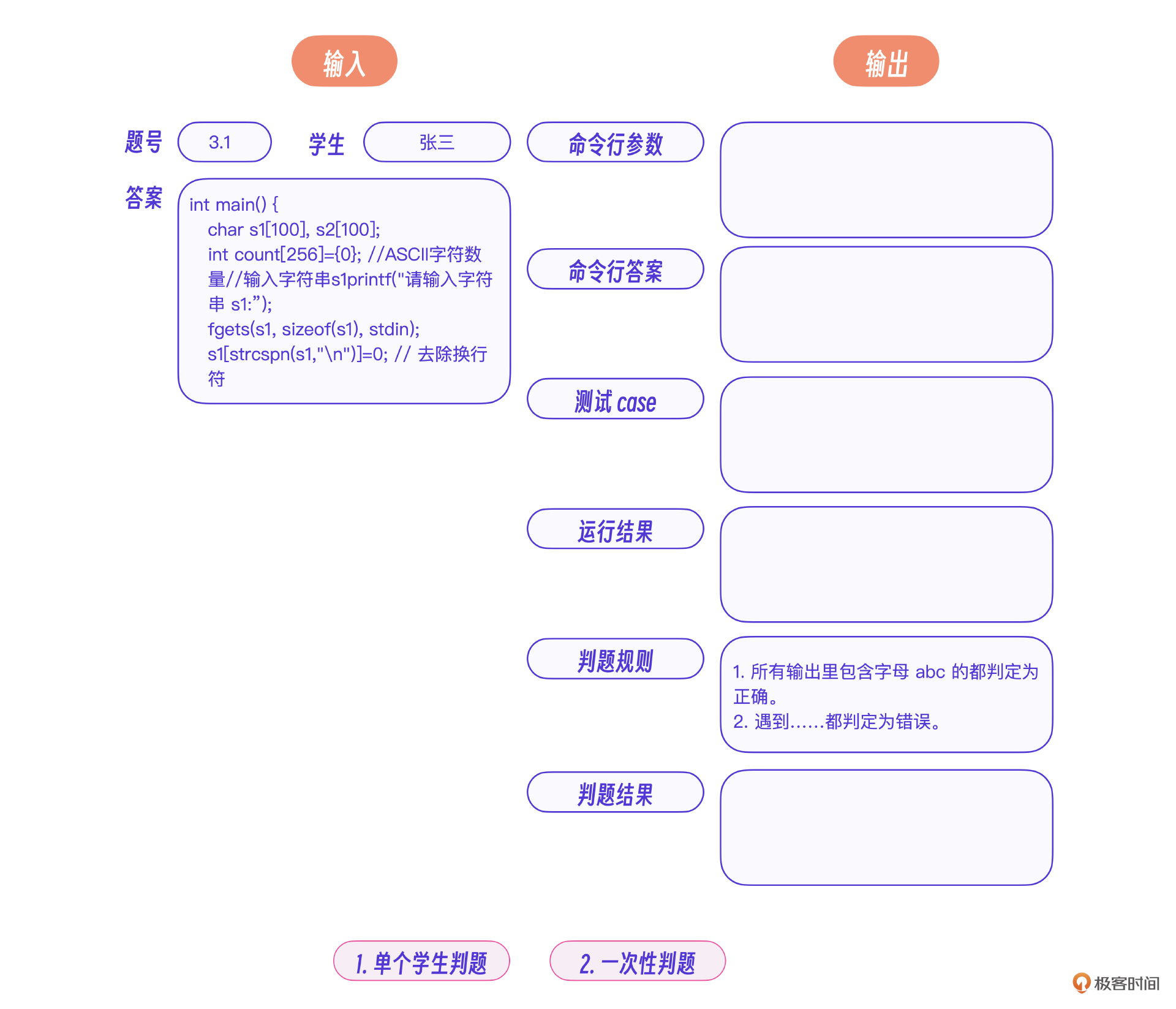
正如图中的例子,老师可以将 所有输出里包含字母 abc 的都判定为正确 之类类的规则插入到判题规则中,最终效果很好。
老师真正的判题流程就是,先人工判定若干学生作业,根据这些学生的情况获得这次作业常见的问题修改规则,最后再一键运行。获得整体excel结果后查看,根据结果回来改判部分学生作业,最后人工评分。
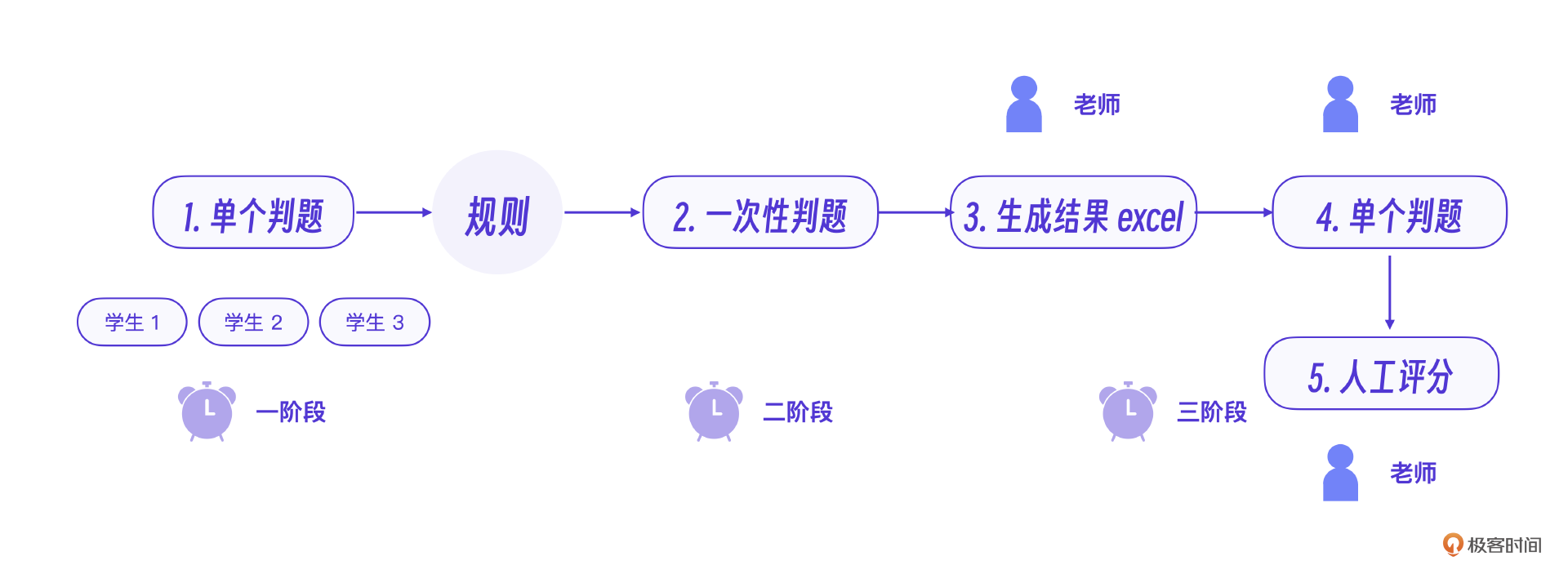
不要看这个流程里有很多的控制逻辑,其实相比原有的业务操作流程,这个逻辑已经可以做到10倍的效率提升了。不过注意,这里的一次性判题,实际系统设定每道题只能运行一次,为什么呢?这其实涉及大模型应用里的一个关键问题:成本考量。
成本考量与权衡
其实多次全量运行对老师来说也不一定就方便,不如花一点成本,先让判题规则的适用性更广泛,这样批量运行成功率反而提高了。
除了这个设计,其实在用户交互的每个步骤里,都对大模型结果做了缓存,对于有前后关系的结果,除非前置条件改变,否则尽量不让大模型重复生成,题库模块和判题模块都是这样。
你可能注意到了,要真正用好大模型的能力,每一个应用交互的程序和提示词都是需要良好配合,程序控制逻辑需要给AI提示词“兜底”,才能实现整体应用的可靠性。
运营情况小记
系统最终提交老师运营之后,老师效率提升明显,整体效率提升了10倍左右。
老师尤其满意的是系统给了足够多的人工干预接口。换言之,就是让老师在原有流程和AI应用流程之间做到了完全无缝衔接,对于很多AI功能,既可以使用AI的结果,也支持人工修改。在题库和判题规则逐渐人工参与完善的情况下,后续系统的效率会有更多提高。
小结
C语言自动判题系统的真实开发和运行过程给了我们很多启示。其中最重要的启示就是大模型AI应用开发在大多数场景下,程序逻辑控制才是核心,仅仅靠提示词很难产生可靠的应用。
如果我们把上节课的提示词看做一个文科生,那这节课提到的各种程序控制逻辑则更像一个理科生。C语言自动判题系统的运行结果表明,只有文科生和理科生精准地配合,才能让系统达到商用级别。这个理科生具体的能力包括输出异常的控制处理,配合大模型分解复杂任务,对大模型的精准控制纠偏,实现成本控制等等。
最后我想补充一点,其实C语言自动判题系统用户交互上的设计也非常重要,最成功的一个设计是通过全流程的人工干预支持,达到和原有流程的无缝对接,达到了效率和可用性的平衡。
思考题
在真实C语言学生作业中,往往有一些类似拼写错误的常见错误,老师希望这类错误帮学生做一些修复,这个问题可以用AI应用解决吗?怎么解决?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 连瑞龙 👍(6) 💬(4)
其实这两节课下来,我们大模型落地实战中的体会和老师是一样的。客户有时候想要用大模型解决所有问题,流程全自动,结果自评判,这本身很不现实。要要让客户正确的认识大模型,认识AI。AI 更多的是对人的增强而不是替代,在整体流程中加入AI来让系统更好的运转,做好AI和程序控制的平衡非常关键,既要充分利用AI的智能性,也好利用程序执行的可靠性和准确性。
2024-08-25 - 白杨 👍(0) 💬(0)
这系统能用?
2025-02-18 - 赵鹏举 👍(0) 💬(0)
非常真实的案例 谢谢分享
2025-02-03 - 小猪猪猪蛋 👍(0) 💬(0)
太强了,原理+实践
2024-10-22