09 微调:向量数据库+微调+规则引擎,定制营销文章内容生成
你好,我是金伟。
上节课说到,虽然使用微信AI的用户一开始增加了不少,但只是好玩,并不实用。然后我们意识到,文本AI聊天没有真实的客户价值。那问题来了,怎么才能在营销AI领域做出价值点呢?
我们选定了两个项目继续探索。一个是用AI生成营销文章,另一个是自动生成微信AI视频。事后证明,营销文章生成项目带来了几十倍的效率提升,而视频自动生成项目是一个几十万成本的教训。
我会在这节课着重分析营销文章的部分,分享向量数据库+微调+大模型三者之间的配合方式。同时,复盘图片视频AIGC产品的踩坑点。
营销文章AIGC
先说营销文章功能,他其实是整个AI营销系统的核心功能。下面有一张示意图,是我让AI写了一篇介绍极客时间的营销文章。产品的界面看起来很简单,不过呢,后端的实现其实总共经历了3个阶段,微调+信息储备,增加规则引擎以及GPT改写。
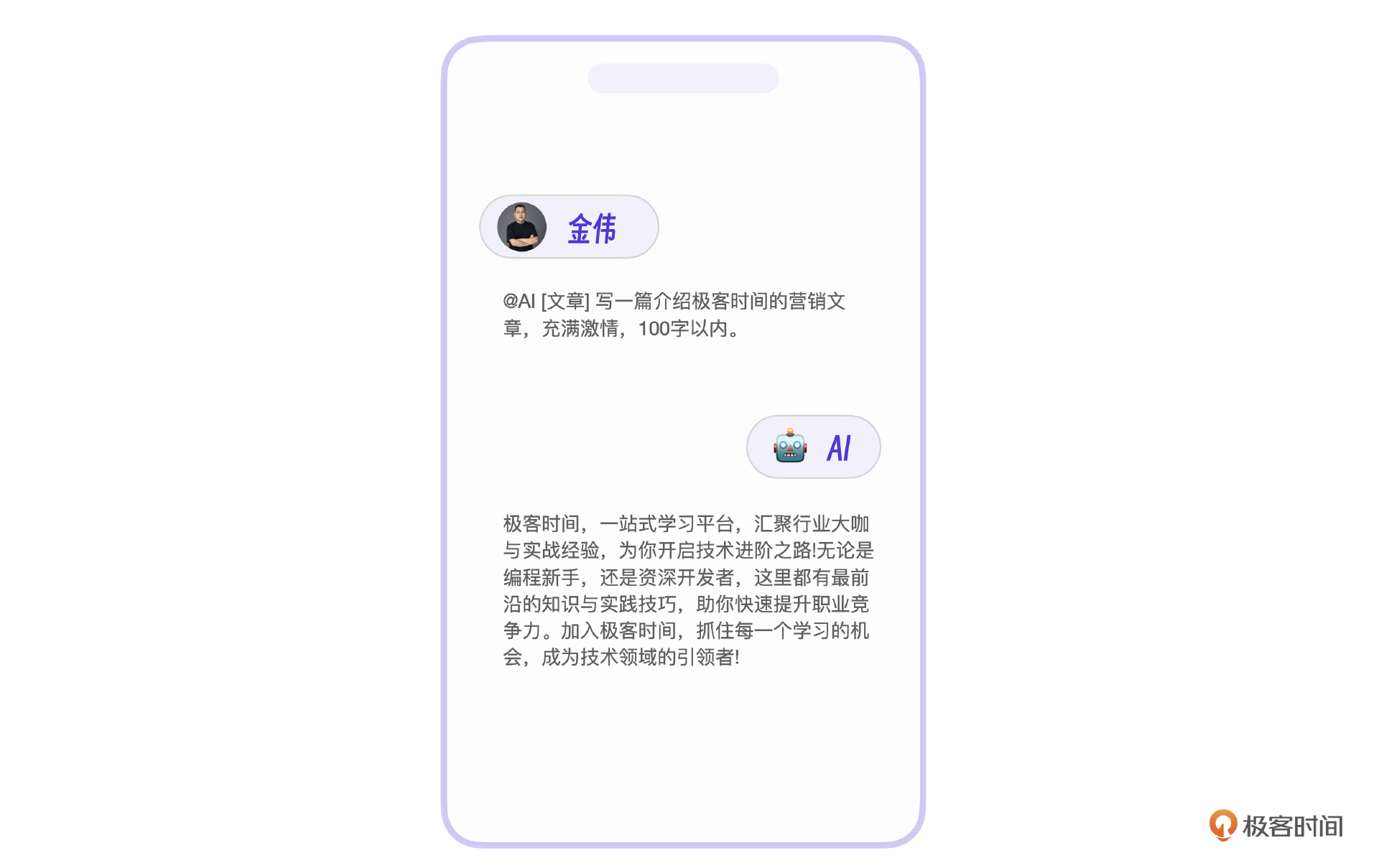
V1:向量数据库方案,储备信息
我们一开始的想法是通过微调,把产品信息数据写入大模型。未来写营销文章的时候,可以直接让大模型根据产品信息生成文章。这肯定也是很多同学刚接触大模型的第一想法。
举个智能硬件产品的例子,下面是一个产品信息的格式示例。
1. 智能空气净化器 AirPure Pro
- 产品名称: AirPure Pro 智能空气净化器
- 产品型号: AP5000
- 核心特点:
- 四层过滤系统: 高效的四层过滤,包括初效滤网、活性炭滤网、HEPA滤网和负离子发生器,能够去除99.97%的空气污染物。
- 空气质量检测传感器: 内置的高精度传感器实时监测空气中的PM2.5、甲醛、二氧化碳等有害物质,显示在LCD屏幕上,并自动调整净化模式。
- 智能控制: 支持Wi-Fi连接,用户可通过专属手机App远程查看空气质量报告、设置定时开关机、调整净化速度等。
- 节能与静音: 采用超静音风扇设计,夜间模式下噪音低至20分贝,并具备节能模式,自动调节风速以减少电能消耗。
- 滤网寿命提示: 内置滤网更换提醒功能,根据使用情况智能提示滤网更换时间,确保净化效果最佳。
- 技术参数:
- 适用面积: 60-80平方米
- CADR值: 500立方米/小时
- 噪音水平: 20-50分贝
- 功率: 45W
- 目标市场:
- 城市家庭,特别是有婴幼儿、老人或宠物的家庭
- 关注室内空气质量的用户,如过敏患者、呼吸道疾病患者
- 促销策略:
- 新用户优惠: 首次购买享受20%折扣
- 赠品: 赠送一年的替换滤网
- 推荐奖励: 推荐朋友购买可获得额外优惠券
要通过微调将这些产品信息内化到大模型里,最核心问题是,如何将产品信息整理成问答的数据集,也就是一个数据工程问题。
我们的方法是假设自己是一个客户,整理出一系列的产品问题,然后根据产品信息回答这些问题。
比如最简单的一个问题 AirPure Pro 智能空气净化器的产品型号是多少?。下面是整理的数据集例子,每一条数据都是一问一答的形式。
问:AirPure Pro智能空气净化器的产品型号是多少?
答:AP5000
.. ..
问:AirPure Pro智能空气净化器内置的传感器可以检测哪些空气中的有害物质?
答:PM2.5、甲醛、二氧化碳等有害物质
问:AirPure Pro智能空气净化器的空气质量监测结果显示在哪个地方?
答:LCD屏幕上
.. ..
问:AirPure Pro智能空气净化器的目标市场有哪些?
答:城市家庭,特别是有婴幼儿、老人或宠物的家庭;关注室内空气质量的用户,如过敏患者、呼吸道疾病患者
问:购买AirPure Pro智能空气净化器的新用户可以享受什么优惠?
答:首次购买享受20%折扣
.. ..
OK,信息整理好之后,就要开始微调了。具体的大模型微调可以采用 LLaMA-Factory 大模型微调框架,LLaMA-Factory 支持上百种大模型的微调,也支持简单的界面操作,比较好上手。
准备好数据之后,我们打开微调界面。
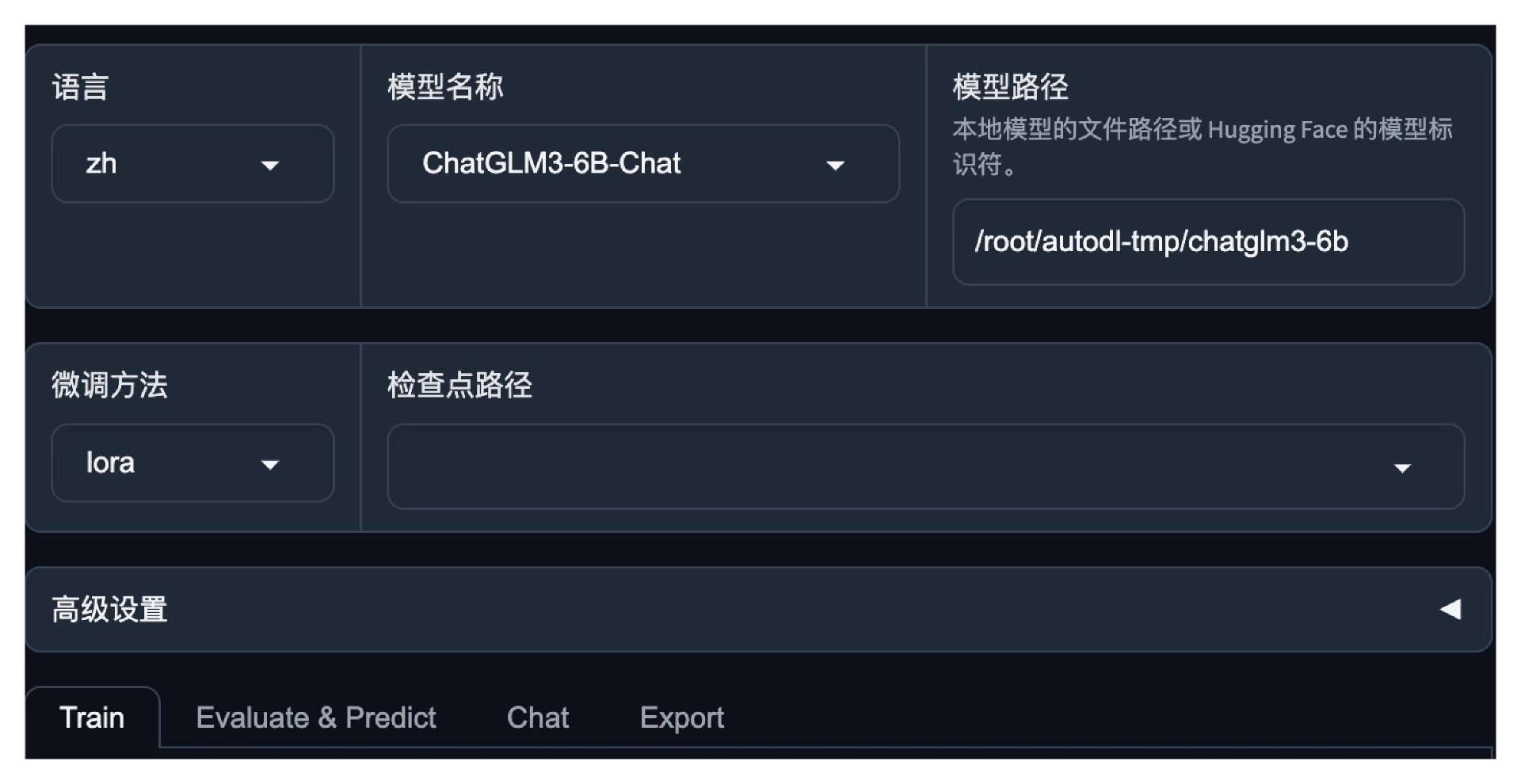
从数据集中选择出我们刚才准备的数据集,查看数据,确保数据准确无误即可。其他微调参数不用改。
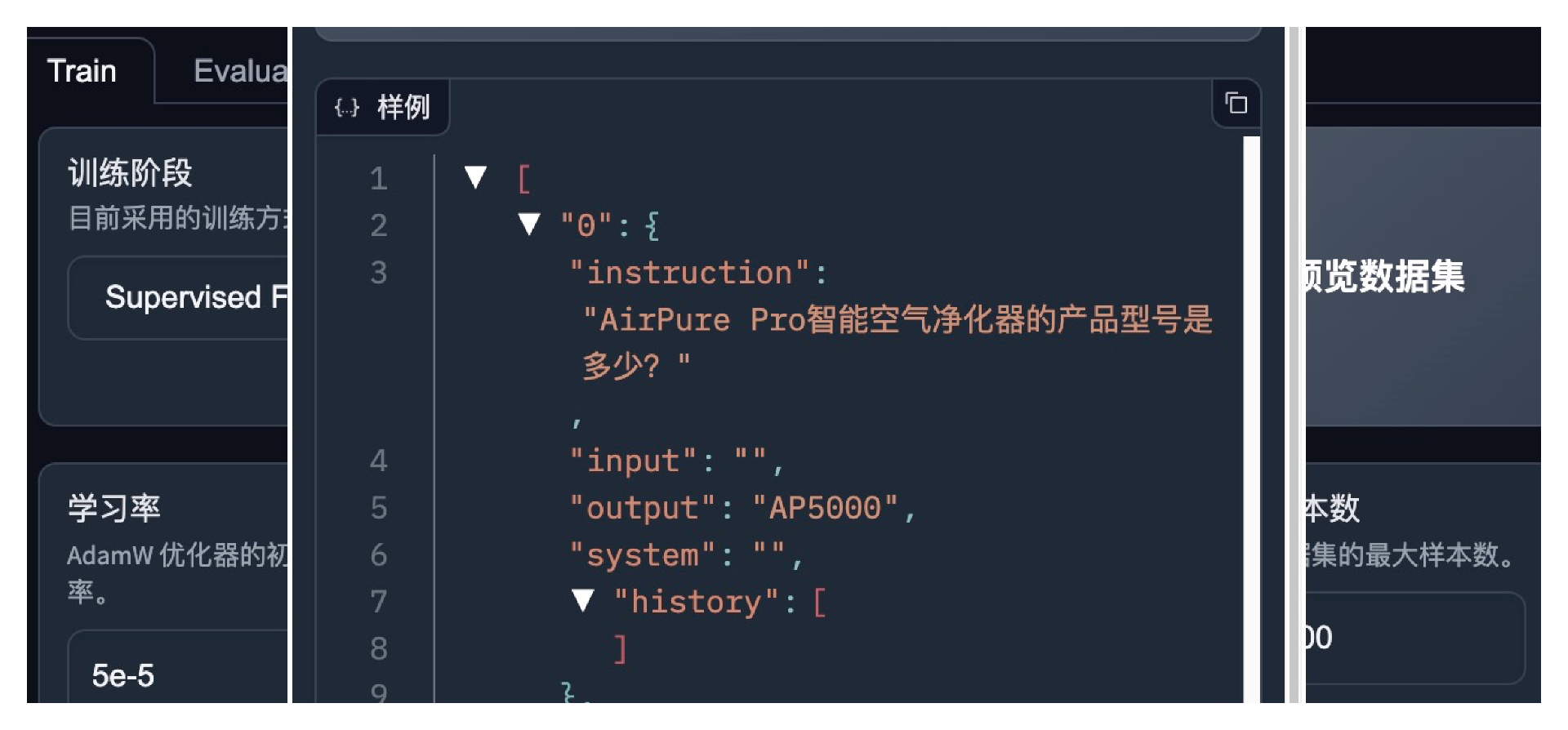
基础模型注意选择ChatGLM,微调方式选择LoRA微调。LoRA训练成本较低,也更容易训练成功。在微调过程中注意观察loss损失曲线,损失曲线下降并趋于平稳就可以了。
微调完成后,在这个界面的 Chat 中选择加载刚才微调后的LoRA模型。然后就可以针对产品提问测试了。
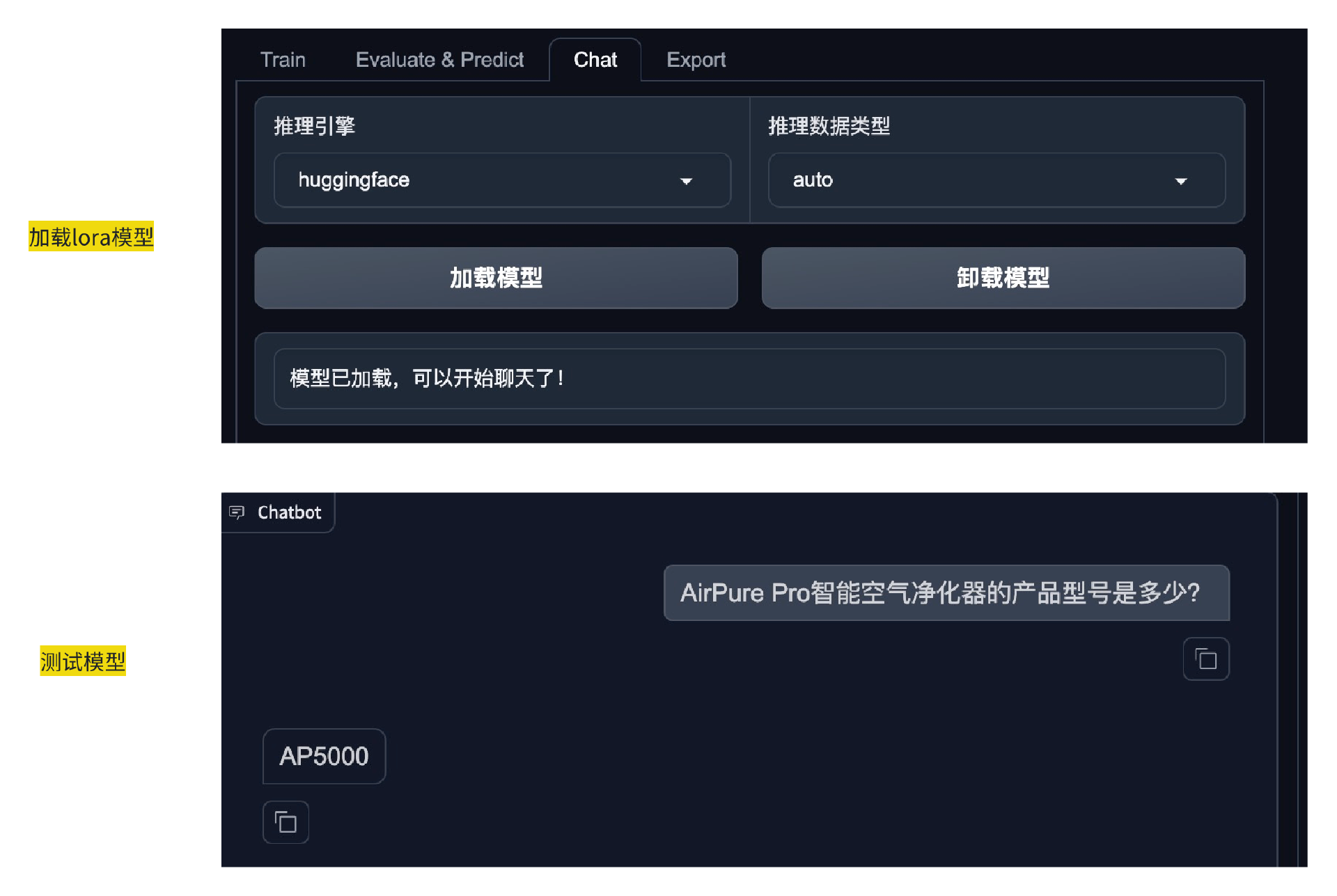
是不是觉得大功告成了?微调大模型加入产品数据的方案看起来很美好,但是实践之后,我们发现效果不好。
这个方案输出的营销文章就像普通公用大模型的输出,太泛了,不集中,而且创造性太强了。还有一个问题在于数据更新不及时,产品信息或营销策略有更新都需要重新微调大模型,很麻烦,成本也高。
怎么办呢?我们的选择是改进为提示词+知识库的模式,解决产品数据更新的问题。实现生成营销文章的提示词分为三步。
- 根据用户的提问要求提取出产品名称。
- 借助产品名称向量查询产品库,找到对应信息。
- 将产品信息补充到提示词中。
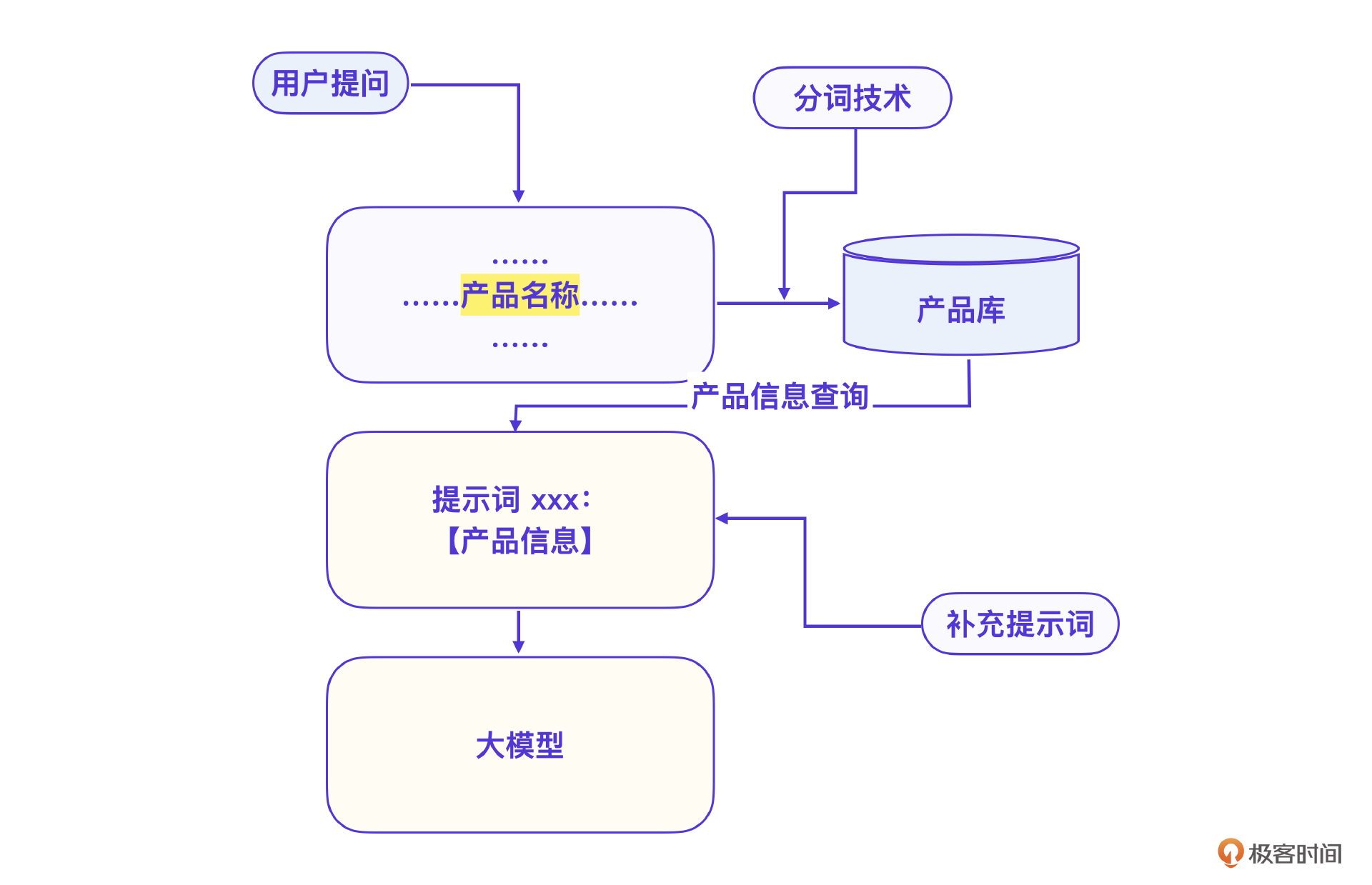
这个图中的产品库部分就是向量数据库。那么当然就要先创建向量数据库,把产品信息存到向量数据库中。
我们选用的是开源向量数据库 Milvus。Milvus 是一个查询比较高效的向量数据库,开源版支持很好的私有性,适合我们的私有化场景,还具备分布式扩展能力,将来的扩展性很好。
那产品信息如何设计成向量数据库的格式呢?这里要注意一个问题,向量数据库本质上和传统数据库没有什么差别,也可以存储传统数据库的信息,只是为了方便将来做向量查询,需要对查询字段做向量存储。
Milvus 数据库的 Collection 就相当于传统数据库的表,因为 Milvus 数据库是非结构化的,因此可以把产品信息分成若干段结构存入Milvus。
具体怎么把产品信息写入向量数据库呢?下面是一段完整的实现代码。在你看代码之前,我想先说说几处重点,方便你理解。
首先需要一个配置文件写入你的数据库连接配置,也就是代码 cfp.read('config.ini') 配置完成才可以进行数据库连接。
接下来的操作和普通数据库操作都很像。比如 collection_name = "product_info" 可以理解为表名称,schema = CollectionSchema 则是表结构。collection.insert(entities) 就是往数据表写数据。
import configparser
import time
from pymilvus import connections, utility, Collection, DataType, FieldSchema, CollectionSchema
from transformers import BertModel, BertTokenizer
import torch
if __name__ == '__main__':
# 连接到 Milvus
cfp = configparser.RawConfigParser()
cfp.read('config.ini')
milvus_uri = cfp.get('example', 'uri')
token = cfp.get('example', 'token')
connections.connect("default",
uri=milvus_uri,
token=token)
print(f"Connecting to DB: {milvus_uri}")
# 检查集合是否存在
collection_name = "product_info"
# 定义集合的 schema
dim = 64 # 向量的维度
product_id_field = FieldSchema(name="product_id", dtype=DataType.INT64, is_primary=True, description="产品ID")
product_name_field = FieldSchema(name="product_name_vector", dtype=DataType.FLOAT_VECTOR, dim=dim, description="产品名称向量")
model_number_field = FieldSchema(name="model_number", dtype=DataType.VARCHAR, max_length=50, description="产品型号")
features_field = FieldSchema(name="features", dtype=DataType.VARCHAR, max_length=1000, description="核心特点")
tech_specs_field = FieldSchema(name="tech_specs", dtype=DataType.VARCHAR, max_length=1000, description="技术参数")
target_market_field = FieldSchema(name="target_market", dtype=DataType.VARCHAR, max_length=1000, description="目标市场")
promotion_strategy_field = FieldSchema(name="promotion_strategy", dtype=DataType.VARCHAR, max_length=1000, description="促销策略")
schema = CollectionSchema(fields=[
product_id_field,
product_name_field,
model_number_field,
features_field,
tech_specs_field,
target_market_field,
promotion_strategy_field
], auto_id=False, description="产品信息集合")
print(f"Creating collection: {collection_name}")
collection = Collection(name=collection_name, schema=schema)
print(f"Schema: {schema}")
print("Success!")
# 产品信息
product_name = "AirPure Pro 智能空气净化器"
product_name_vector = generate_vector_from_text(product_name, dim)
product_ids = [1]
product_name_vectors = [product_name_vector]
model_numbers = ["AP5000"]
features = ["四层过滤系统: 高效的四层过滤,包括初效滤网、活性炭滤网、HEPA滤网和负离子发生器,能够去除99.97%的空气污染物。空气质量检测传感器: 内置的高精度传感器实时监测空气中的PM2.5、甲醛、二氧化碳等有害物质,显示在LCD屏幕上,并自动调整净化模式。智能控制: 支持Wi-Fi连接,用户可通过专属手机App远程查看空气质量报告、设置定时开关机、调整净化速度等。节能与静音: 采用超静音风扇设计,夜间模式下噪音低至20分贝,并具备节能模式,自动调节风速以减少电能消耗。滤网寿命提示: 内置滤网更换提醒功能,根据使用情况智能提示滤网更换时间,确保净化效果最佳。"]
tech_specs = ["适用面积: 60-80平方米, CADR值: 500立方米/小时, 噪音水平: 20-50分贝, 功率: 45W"]
target_markets = ["城市家庭,特别是有婴幼儿、老人或宠物的家庭,关注室内空气质量的用户,如过敏患者、呼吸道疾病患者"]
promotion_strategies = ["新用户优惠: 首次购买享受20%折扣, 赠品: 赠送一年的替换滤网, 推荐奖励: 推荐朋友购买可获得额外优惠券"]
entities = [
product_ids,
product_name_vectors,
model_numbers,
features,
tech_specs,
target_markets,
promotion_strategies
]
print("Inserting entities...")
t0 = time.time()
collection.insert(entities)
total_rt = time.time() - t0
print(f"Succeed in {round(total_rt, 4)} seconds!")
... ...
# 断开连接
connections.disconnect("default")
下面是这个数据存储到向量数据库的显示,只有产品名称字段是向量表示。

现在测试一下向量数据库读取,我们的目标是根据产品名称获取所有信息。
import configparser
from pymilvus import connections, Collection
from transformers import BertModel, BertTokenizer
import torch
if __name__ == '__main__':
# 连接到 Milvus
cfp = configparser.RawConfigParser()
cfp.read('config.ini')
milvus_uri = cfp.get('example', 'uri')
token = cfp.get('example', 'token')
connections.connect("default",
uri=milvus_uri,
token=token)
print(f"Connecting to DB: {milvus_uri}")
... ...
# 输入产品名称
product_name = "AirPure Pro"
dim = 64 # 与存储时的向量维度一致
# 生成产品名称的向量
search_vector = generate_vector_from_text(product_name, dim)
# 搜索相似产品
search_params = {"metric_type": "L2", "params": {"level": 2}}
topk = 1 # 搜索结果的数量
print(f"Searching for: {product_name}")
results = collection.search([search_vector],
anns_field="product_name_vector",
param=search_params,
limit=topk,
output_fields=["product_id", "model_number", "features", "tech_specs", "target_market", "promotion_strategy"])
# 输出结果
for result in results:
for hit in result:
print(f"Product ID: {hit.entity.get('product_id')}")
print(f"Model Number: {hit.entity.get('model_number')}")
print(f"Features: {hit.entity.get('features')}")
print(f"Technical Specifications: {hit.entity.get('tech_specs')}")
print(f"Target Market: {hit.entity.get('target_market')}")
print(f"Promotion Strategy: {hit.entity.get('promotion_strategy')}")
print(f"Distance: {hit.distance}")
print("------")
# 断开连接
connections.disconnect("default")
OK, 可以看到下面结果中,这个查询已经把整个产品信息用向量的方式查询出来了,特别注意最后一个输出 Distance 表示这次查询的输入向量和结果向量的相似度,数字越小表示越相似。

回过头看我们的流程图。
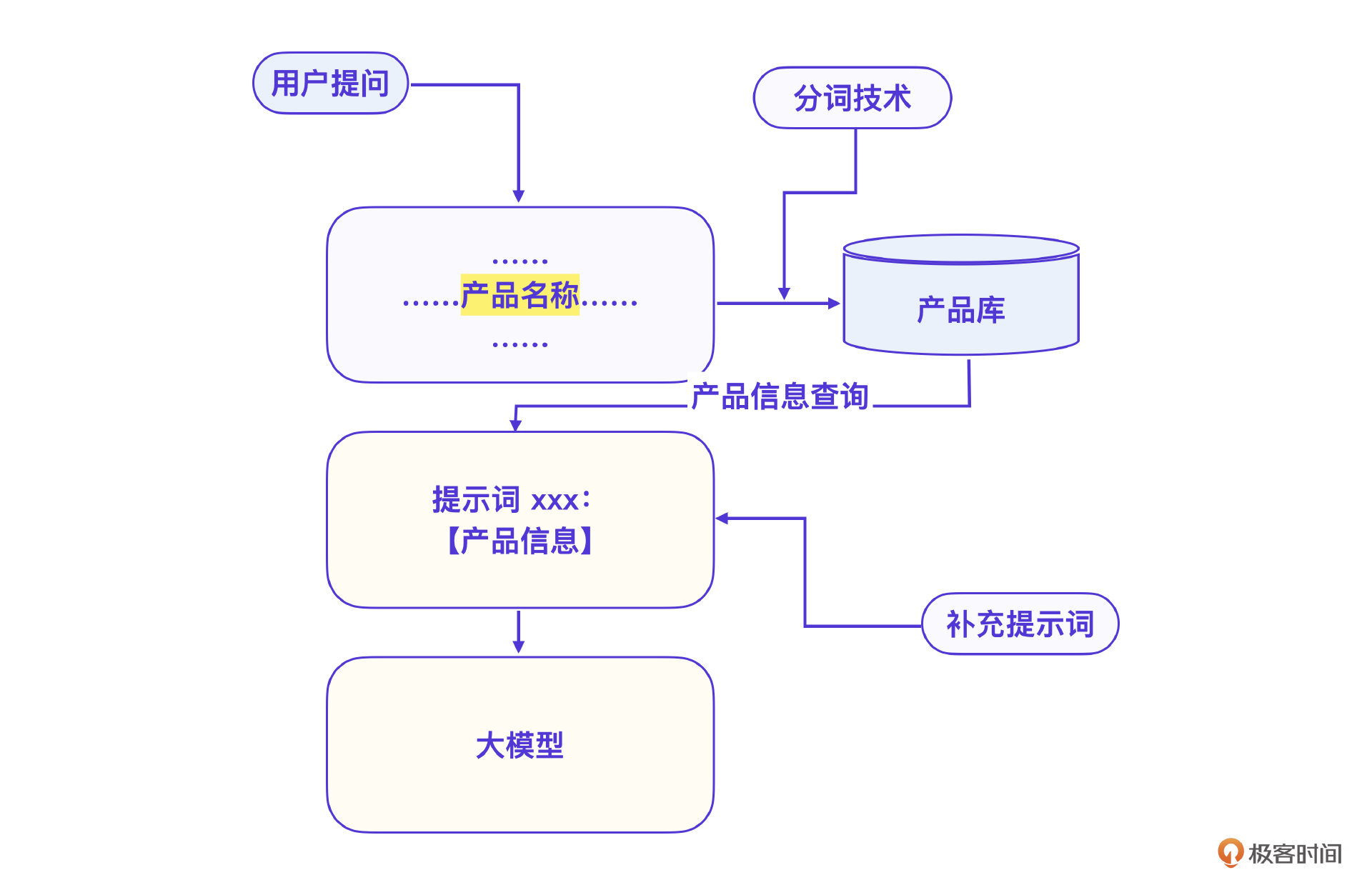
其实刚才说的就是产品信息查询这一步。
按照设计图,第一步是根据用户提问的问题,用分词技术提取出产品名,这一步咱们还没说。具体怎么做呢?可以用Python的分词库 jieba 库,提取专有名词,也就是产品名称。
import jieba.posseg as pseg
def extract_english_names(sentence):
words = pseg.cut(sentence)
# 提取词性为英文的单词
english_names = [word for word, flag in words if flag == 'eng']
return " ".join(english_names)
# 示例
sentence = "帮我写一个AirPure Pro 智能空气净化器的文案"
english_name = extract_english_names(sentence)
print(f"提取的英文名称: {english_name}")
最后把名字提取和向量数据库查询结合起来,再把整个结果组织成大模型提示词就可以了。我再把这个流程用文字描述一遍。
- 提取产品名称。
- 向量查询产品信息。
- 将字段组合为提示词。
- 用提示词访问大模型输出文章。
V2:规则引擎方案,输出文章
其实,V1版本的向量数据库方案效果已经很好了,不过离人工写的文章还是有差距,还是有一股 “AI味”。因此我们开发了V2版本,也就是基于规则引擎的方案,在V1版本的基础上更进一步。
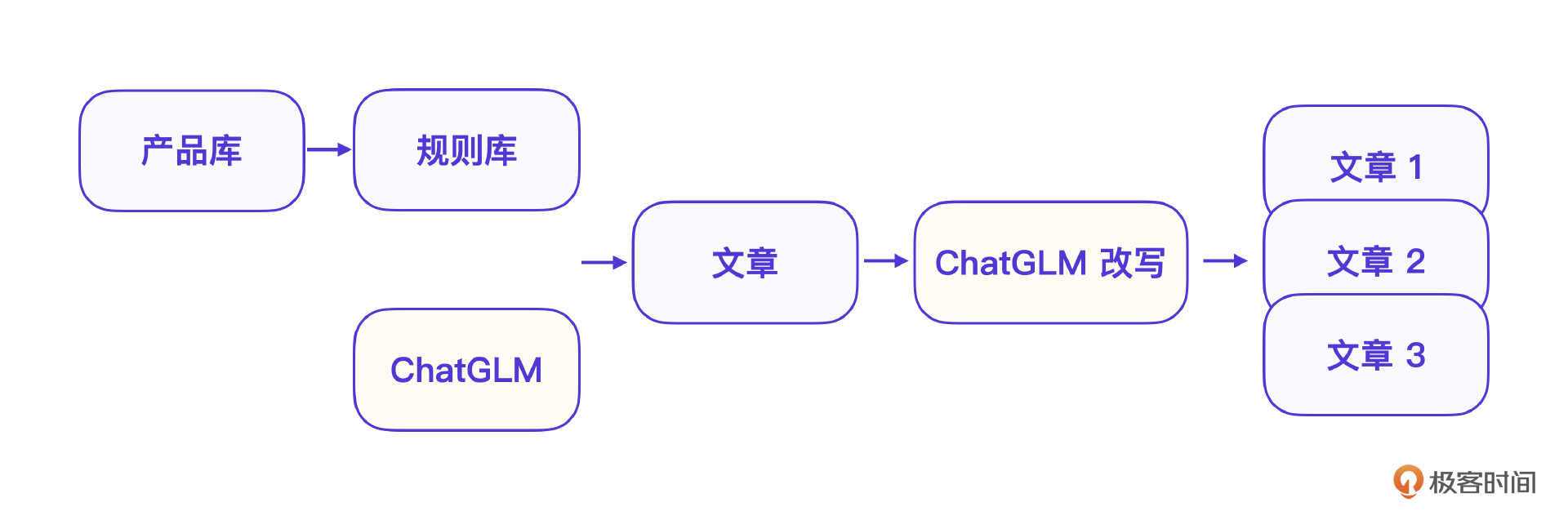
总体思路特别像用AI写代码。简单地说,就是先由人工提供一个文章架构,再由 AI 写具体的模块内容,实际上这也是目前用 AI 做内容的标准方法。
营销文章生成过程分为规则引擎 + 产品信息 + ChatGLM 改写。第一步,就是复用已有的营销模版,限定大模型的创造范围;第二步是利用大模型结合产品信息填写模版变量;第三步,再用大模型改写生成多个文章。
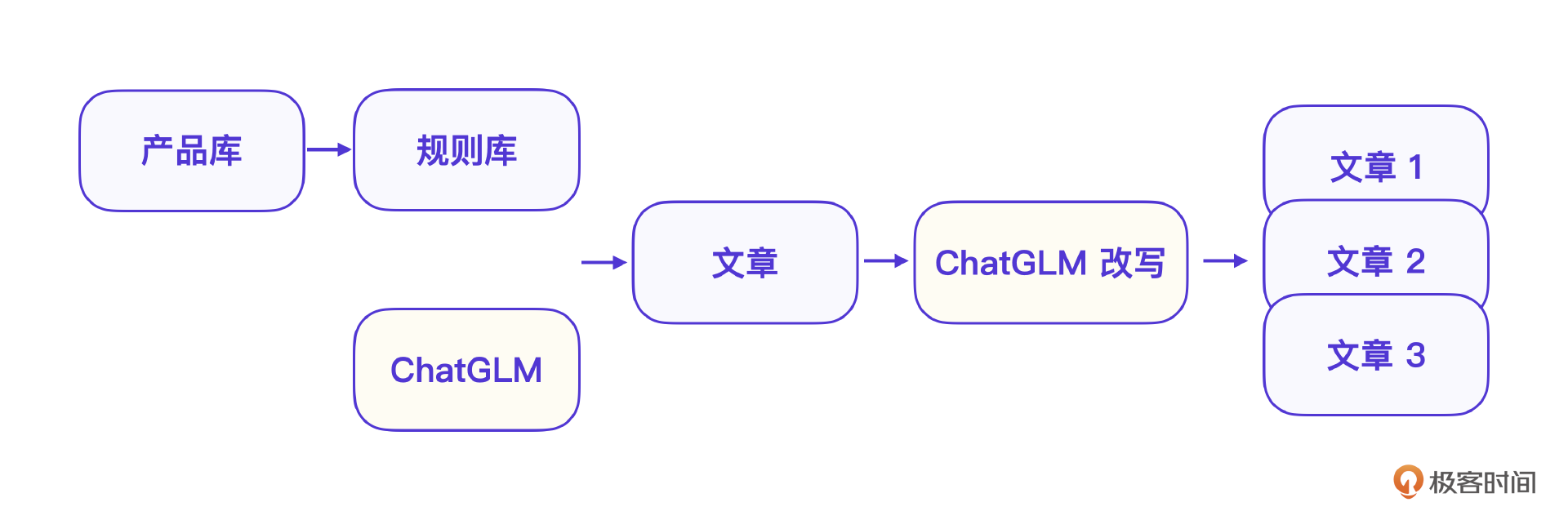
下面是已经成型的传统营销文章模板例子,也就是文章的架构,可以限定大模型的创造范围。
标题
规则1:{产品名称} - {主要卖点}
规则2:{主要卖点},选择 {产品名称}
..
引言
..
规则2:{产品名称} 是{目标市场}的理想选择,其{特性1} 和 {特性2} 深受喜爱。
...
使用场景
规则1:无论是{场景1}还是{场景2},{产品名称} 都能提供最佳解决方案。
规则2:在{场景1} 和 {场景2} 中,{产品名称} 的表现无可挑剔。
..
购买信息
规则1:了解更多信息,请访问{购买渠道}或联系我们:{联系方式}。
规则2:欲了解详情,请访问{购买渠道}或拨打{联系方式}。
规则3:更多信息,请访问{购买渠道},或拨打{联系方式}与我们联系。
接着就是第二步,结合规则库和向量数据库生成文章。

你看,规则库的核心是提供一种模版,向量数据库核心是读取产品数据,比如要用某个规则库写某个产品,那么输入就是规则和产品信息,输出就是按规则编写的文章。因为原来人工的方式也是按模版编写的,所以这种方式可以把大模型的创造性控制到我们想要的方向上。
下面还有一个智能硬件的案例,最关键的就是把这些信息用提示词组合到一起。
请写一篇营销文章,要求遵照营销文章模版并结合产品信息来写,文章要求是:突出产品的核心功能和与竞争对手的不同之处,通过具体的应用场景和实际用户的成功体验,展示产品的实用性和价值。
营销文章模版:
"""
标题
规则:{产品名称} - {主要卖点}
引言
规则:{产品名称} 是{目标市场}的理想选择,其{特性1} 和 {特性2} 深受喜爱。
使用场景
规则:无论是{场景1}还是{场景2},{产品名称} 都能提供最佳解决方案。
购买信息
规则:了解更多信息,请访问{购买渠道}或联系我们:{联系方式}。
"""
产品信息:
"""
1. 智能空气净化器 AirPure Pro
...
"""
大模型轻松识别这些模版信息之后,就能写出一篇营销文章了。自动化的工作则可以用编程调用ChatGLM接口来解决。
V3:GPT改写方案,优化版本
最后,说一个真实经验:让GPT改写这篇文章,继续生成,继续提升内容生产效率。这里说的GPT改写是一个优化方案,就是在系统自动生成营销文章的基础之上,再针对特定用户单独生成文章。想要实现这个功能,我们只要在营销文章功能中加入一个改写模块即可。
GPT改写的好处是,保证质量情况下低成本地生成多个文章,其实这也是真实项目的标准做法。同样的文章还可以根据客户的特性做个性化处理,这是以前想到但做不到的。
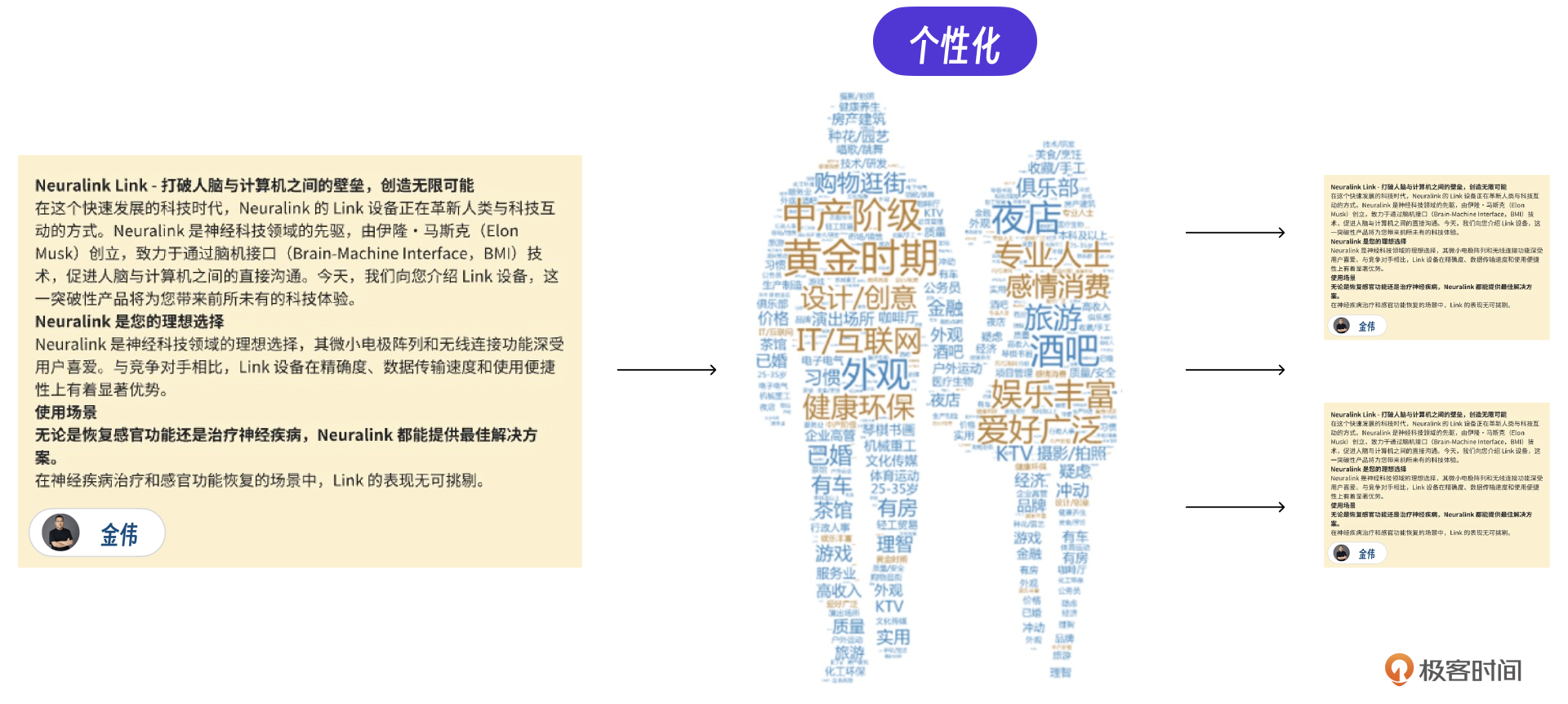
真实情况下,用ChatGLM改写也是可以完成,具体实现取决于的客户、成本的要求。
比如下面的文章在模版文章生成之后,根据用户年轻化的特点,再用大模型对文章改写,可以生成针对年轻人的营销文章。

当然,真实场景下,最终还需要人工审核优化文章,确保生成内容符合规范,并根据SEO规则,继续优化关键词和内容结构。
运营小结
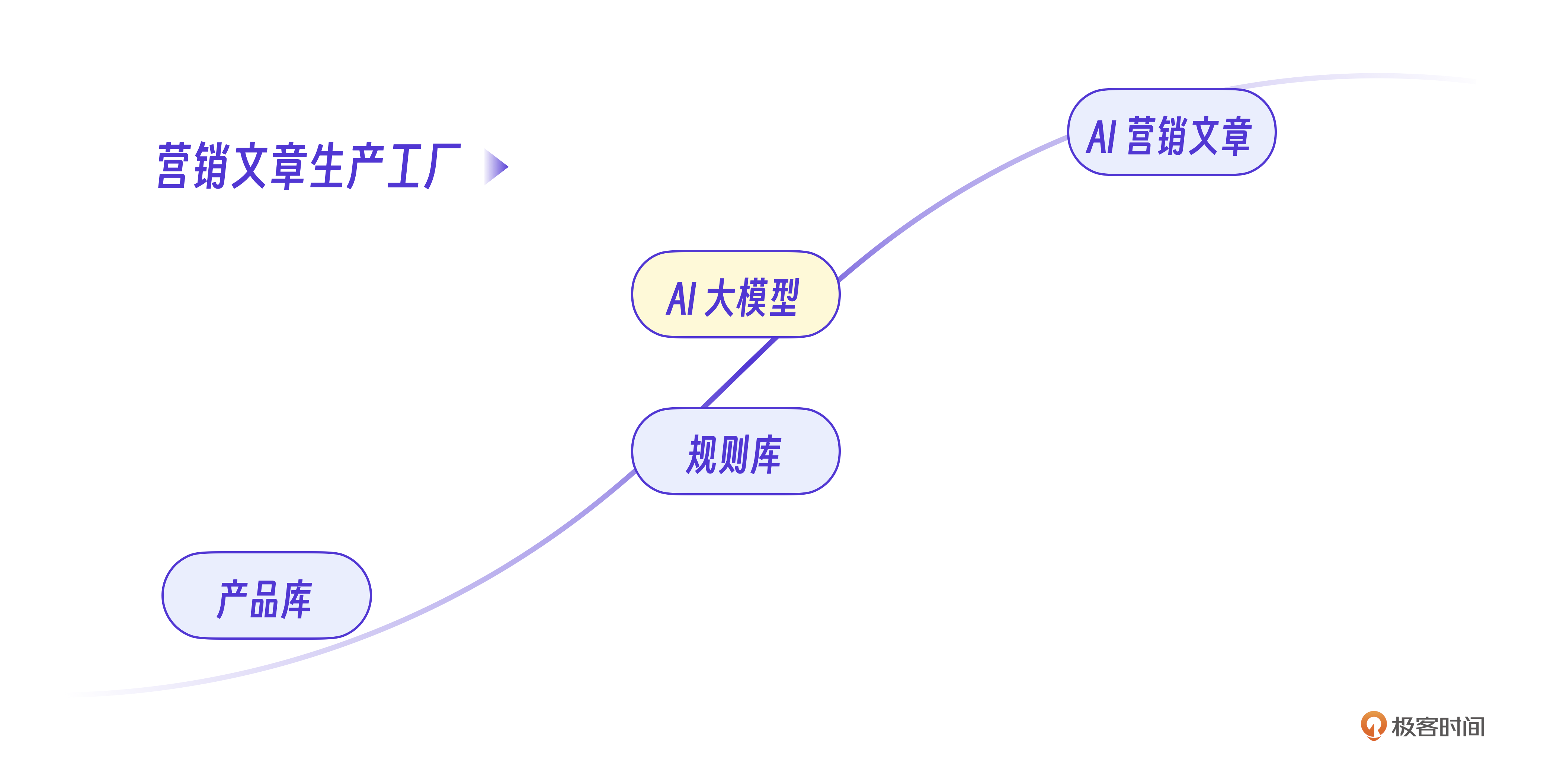
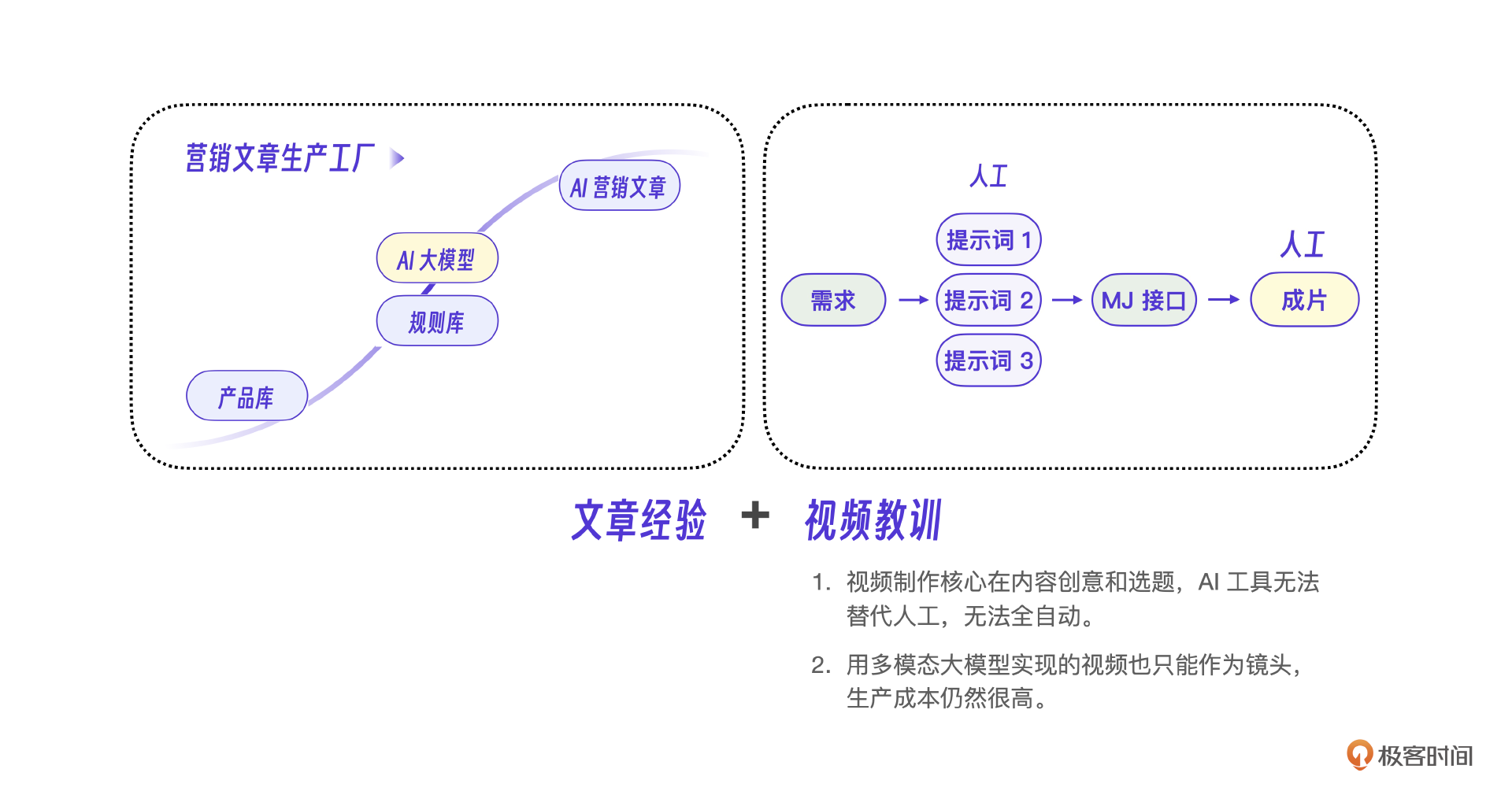
营销文章最终的运营效果还可以,基本可以达到原有营销系统客户效果,重点是将AI能力嵌入了原有业务,在原有业务上加入了AI的创造性,实现了自动生成营销文章的功能,让效率提升了10倍以上,可以说,我们实现了一个小型的营销文章生产工厂。
图片视频AIGC
最后我来说说图片视频的生成。我们是一个自研精神拉满的团队,几乎是从头开始搭建了整套系统。这也是你可以参考的地方。
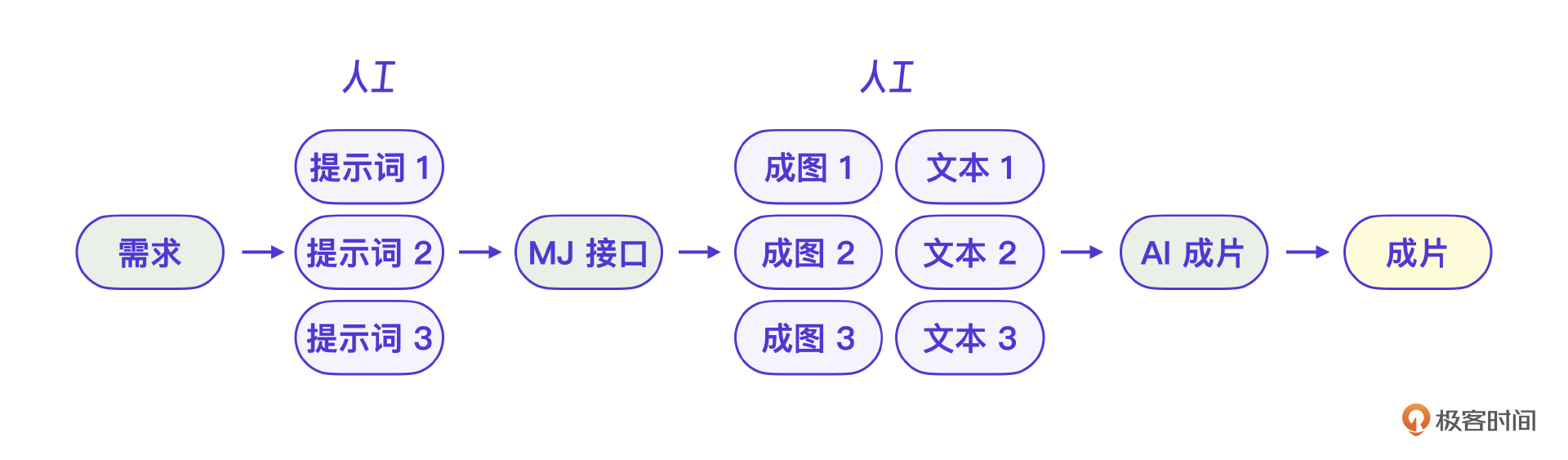
图片视频,顾名思义,就是图片拼接组成的视频。所以我们先来看最基础的AI图片开发。这里需要做的是扩展AI指令支持图片。要注意,因为AI生成图片速度较慢,所以在实际的用户交互里,可以先回复一条消息让用户等待,避免用户产生焦虑。
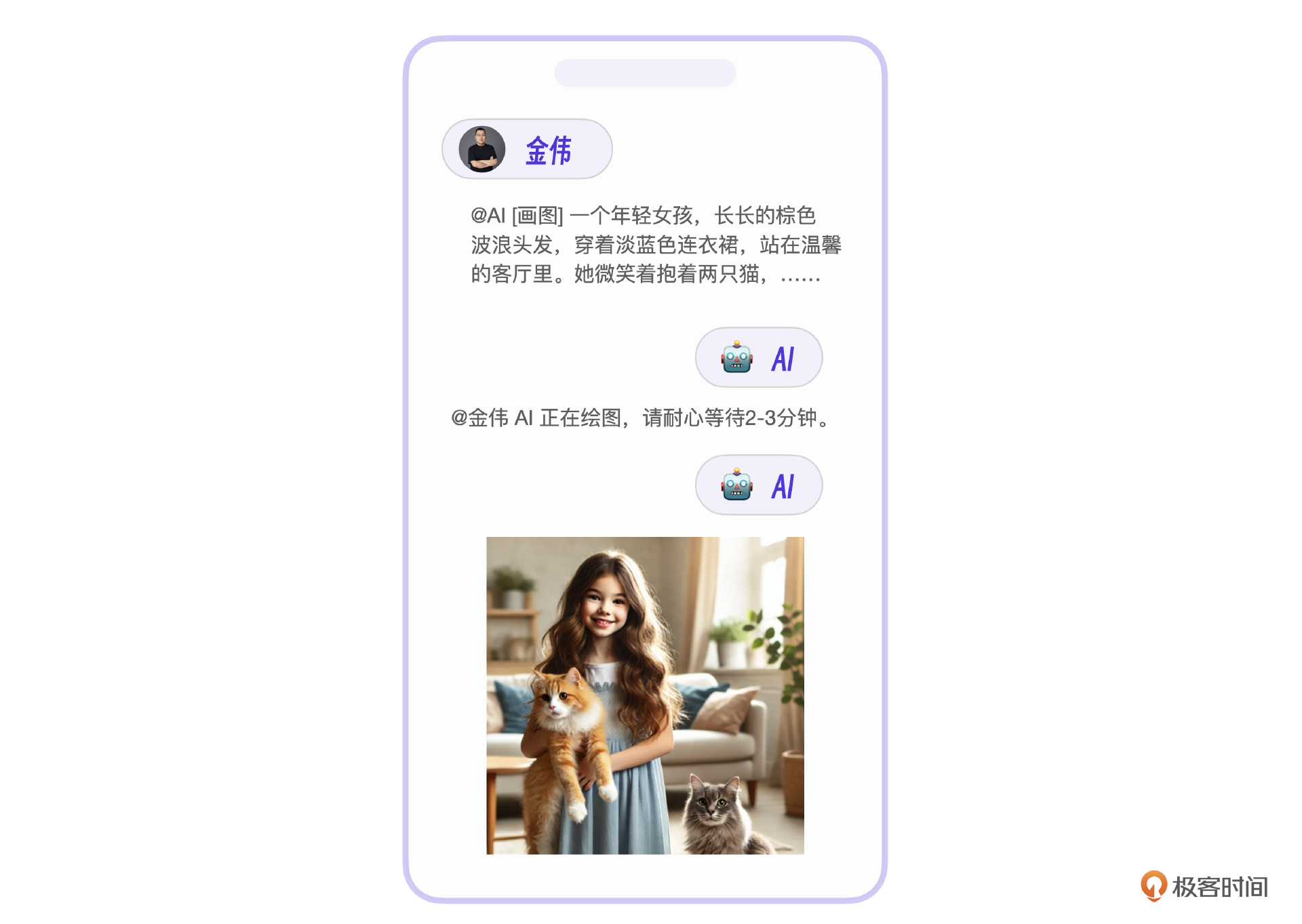
图片生成
市面上有两个文生图片的方案,SD是开源方案,但是从图片效果上来说,MJ效果更好。不过MJ官方不提供接口,所以我们选用了一个代理MJ接口,这样实现也简单,直接用微信图片指令调用MJ接口。
MJ文生图有两个核心的接口操作,_Imagine操作和Change操作,分别负责文生图和放大图片。下面是Imagine的具体参数和调用示例。
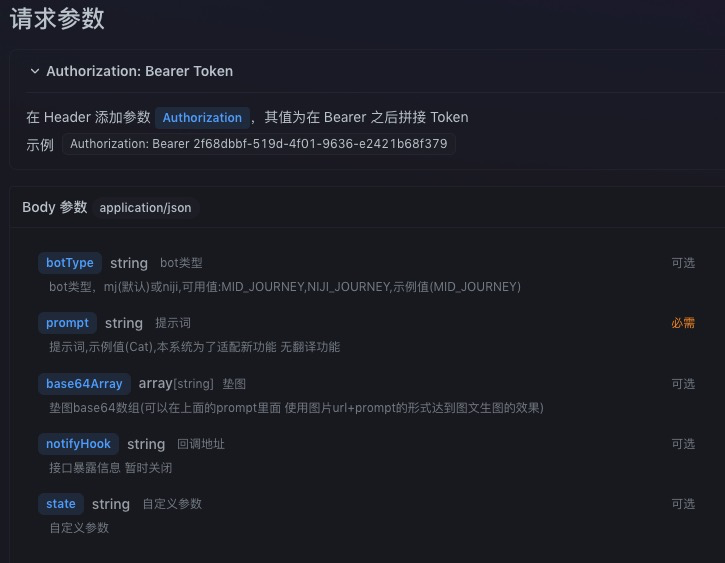
这里有一个基本文生图代码例子,你可以参考。
import requests
import json
url = "https://mj.openai-next.com/mj/submit/imagine"
payload = json.dumps({
"botType": "MID_JOURNEY",
"prompt": "一个年轻女孩,长长的棕色波浪头发,穿着淡蓝色连衣裙,站在温馨的客厅里。她微笑着抱着两只猫,一只是橙色虎斑猫,另一只是灰色猫。背景是米色沙发和木质咖啡桌,阳光透过窗帘洒进来,房间里有几盆绿植。",
"base64Array": [],
"accountFilter": {
"channelId": "",
"instanceId": "",
"modes": [],
"remark": "",
"remix": True,
"remixAutoConsidered": True
},
"notifyHook": "",
"state": ""
})
headers = {
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
注意, 第8行代码里 "prompt": "一个年轻女孩...", 是文生图操作的提示词。接收到提示词之后, Imagine 接口会返回一个Taskid,后续能用这个Taskid表示为同一次图片操作。
比如对同一张图片用 Change 接口做 UPSCALE(放大) 操作,就需要传入Taskid。

这个流程很简单,实现单个图片的微信AI指令是没问题的。你可以在自己的微信AI基础上接入图片功能。
好,再说说视频AIGC的开发。用一句话总结就是,理想很丰满,现实很骨感。我们是一步步由全自动AIGC方案,被逼着一步步往人工+ AI方向去实现的。做到最后,我们发现这个AI视频生成的步骤需要引入太多人工环节了,所以最后没有把生成视频的功能接入微信AI,但是成片在短视频平台上发布测试了,平均也有几千的播放量,从生产成本来说还算可以。
因为这不是一个成功的经验,我把具体的实现过程和代码放社群资料库了,对视频自动AIGC感兴趣的同学可以去领取并实验。
下面是一张生产环境的流程图,给你参考。
Sora为什么能成
可以说,我们在AI视频生成中最大的教训就是低估了这个模块的难度。当Sora类视频AI出现的时候,我们才感受到大模型能力迭代得非常快。自有开发在这个级别的能力上不应该选择和巨人团队竞争。而且视频创作的核心并不在技术,而在于运营人员,因此技术上后期我们偏向应用创新。
另外一点是,我们的AI视频效果不好。怎么不好?一是不流畅,转场粗糙,画面衔接不足,达不到商用级别。二是人工参与过多,最终不能集成到微信AI里。既然这是一个暂时离不开人的事,那最终也就选择废弃。
直到Sora这类视频生成AI发布,我们团队才意识到原来对AI视频的认知太粗浅了,一开始我们以为AI做视频就是要让AI自动生成整个视频,实际上视频的创造性决定了不能通过这种控制的方式来完成,因为控制的方式无法实现画面的语义转化。
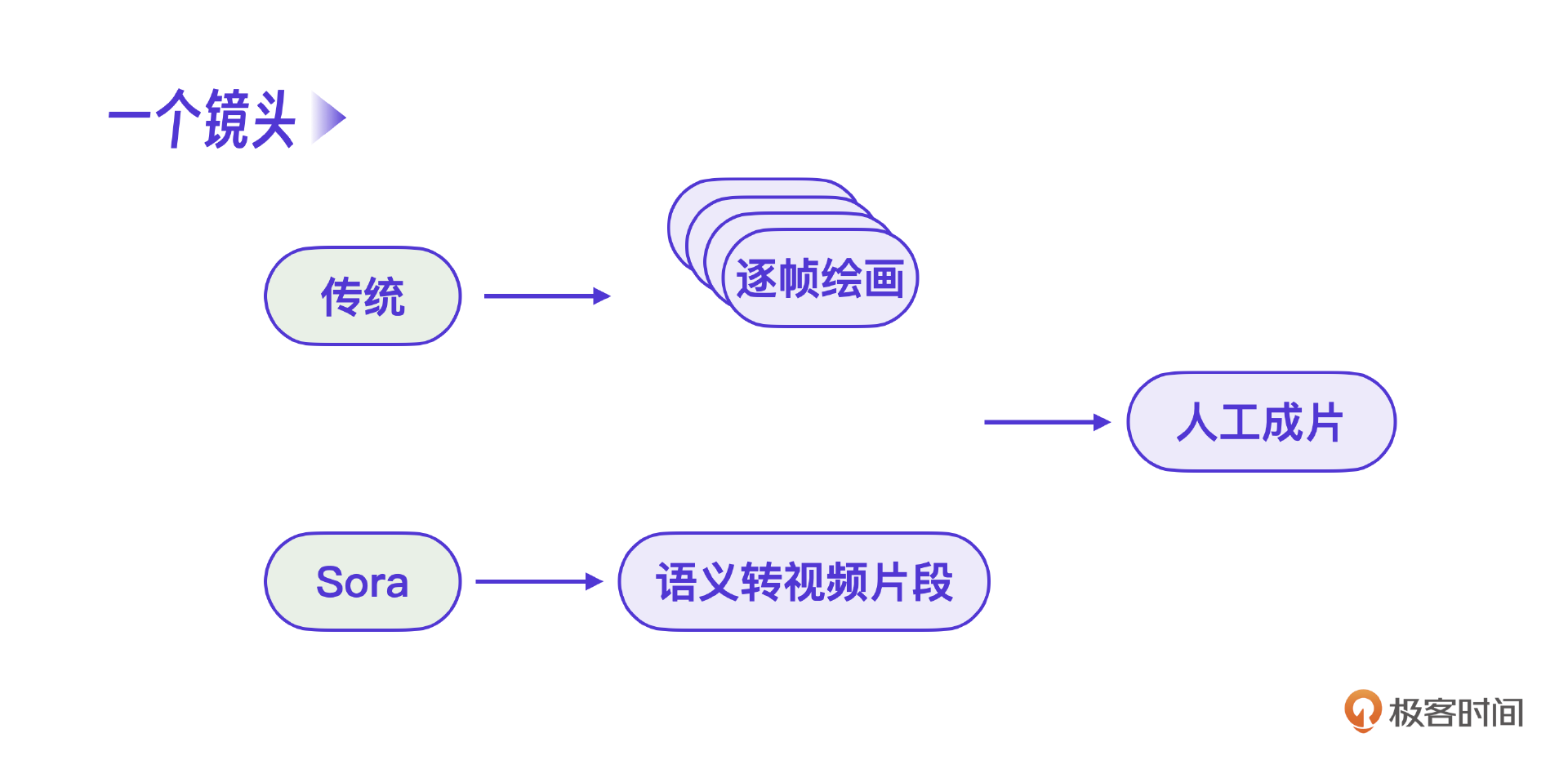
要用控制的方式制作视频,就必须退回到逐帧绘制视频画面才能完成,否则语义是不连贯的。而真正Sora类的视频平台的原理是什么呢?注意,Sora的核心就是真正把一个镜头的语义完整地表示出来,底层是通过视频大模型的训练完成的。而其目的也不是生成整个视频,只是生成一个镜头,最终的完整视频制作还需要人工制作。换句话说,Sora类视频AI是替换了原工业流程里的逐帧绘画。
小结
在营销场景下,用AI生产内容,是AIGC是一个非常普遍的需求,我们选择了文章的AIGC和视频AIGC作为切入点,有经验也有教训。
在营销文章AIGC重,我们经历了V1版本的大模型微调方案、向量数据库方案,V2版本的规则引擎方案和V3版本的GPT改写方案。整个开发过程是一步步递进的。总结来说,用AI写文章和用AI写代码非常类似,都是先由人工写一个框架,再由AI写具体细节。
用AI做视频其实也是同样的套路。本来我们预想的方案是要实现完整的视频内容创作和输出,支持全自动生成,但是开发过程中才发现即使Sora类的生成式AI产品也只能做到一个很短的镜头生成,整体还是离不开人。
我把这些经验形成了一张“营销文章工厂化生产流程”图,对AI做内容的项目会有参考意义。
思考题
在营销文章模块,最后一步是AI改写文章,请你想一下这一步的改写使用什么提示词?要注意什么?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 一点点就好 👍(1) 💬(1)
您好老师,请教一哈从输入文本中提取产品名称,因为用户输入的文本是任意形式的,就会导致提取名称拿不到预期。向量搜索出的产品也就不对,这种情况您们是怎么处理的
2024-08-30 - daydaygo 👍(0) 💬(1)
有代码仓库么?
2024-10-12 - 大魔王汪汪 👍(1) 💬(0)
从2024年底这个时间点往回看,问下老师,想要提升模型准确度是不是就以下几种方式: 1)选择参数更大的模型; 2)数据微调; 3)RAG; 4)写好Prompt; 5)如果可能的话,做些工程上的事情,比如借助规则引擎重写Prompt;
2024-12-30 - V 👍(0) 💬(1)
这里的规则引擎没太明白,文中所描述的是指规则引擎是否是运营或开发定义好提示词的模板,通过占位符配置,保存在库中。模板中的占位符内容的信息,通过用户语义提取或引导用户指定输入相关占位符对应的内容,然后把模板对应的占位符进行替代,生成对应的提示词模块。最后调用LLM ?
2025-02-05