12 Agent架构:创建一个Agent智能体应用架构需要考虑哪些要素?
你好,我是金伟。
如果你已经跟着开发了整个Agent底层框架,那对Agent这个领域应该已经有非常深入的了解。不过做为一个知其然,还要知其所以然的工程师,可能还是会产生疑问:为什么说Agent智能体这种开发范式逐渐成为了大模型AI开发的标准呢?
这节课,我会从最简单的例子开始,回归Agent核心原理,一步步拆解Agent智能体的能力,确保任何业务做智能体的时候都有思路参考。
我们将始终围绕一组核心概念展开,也就是Agent智能体四要素:感知、决策、规划、执行。
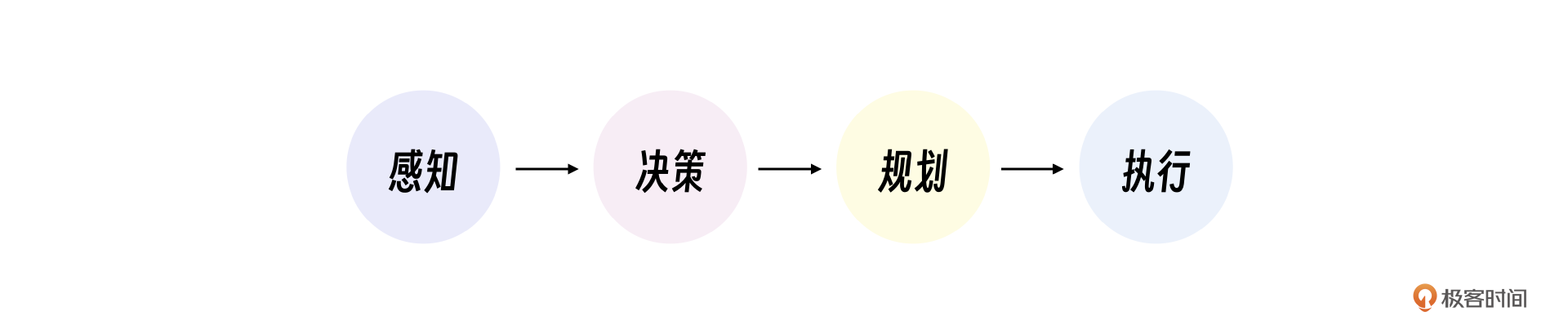
重新理解智能体
Agent智能体这个概念并没有统一的标准,而Agent这个词在AI领域就是智能体的意思。接下来我说的智能体概念是我在实战中理解到的。
提示词也是智能体?
从最简单的情况来说,大模型+提示词就是一个智能体,举个例子。
在大模型基础上,仅仅通过一段提示词,就能让大模型成为你的老师,这在以往是不可想象的。这个基于大模型的助教至少可以完成一部分人类老师的工作,就可以称为智能体。
智能体最大的特点就是可以像人类一样独立完成感知、决策、规划、执行。
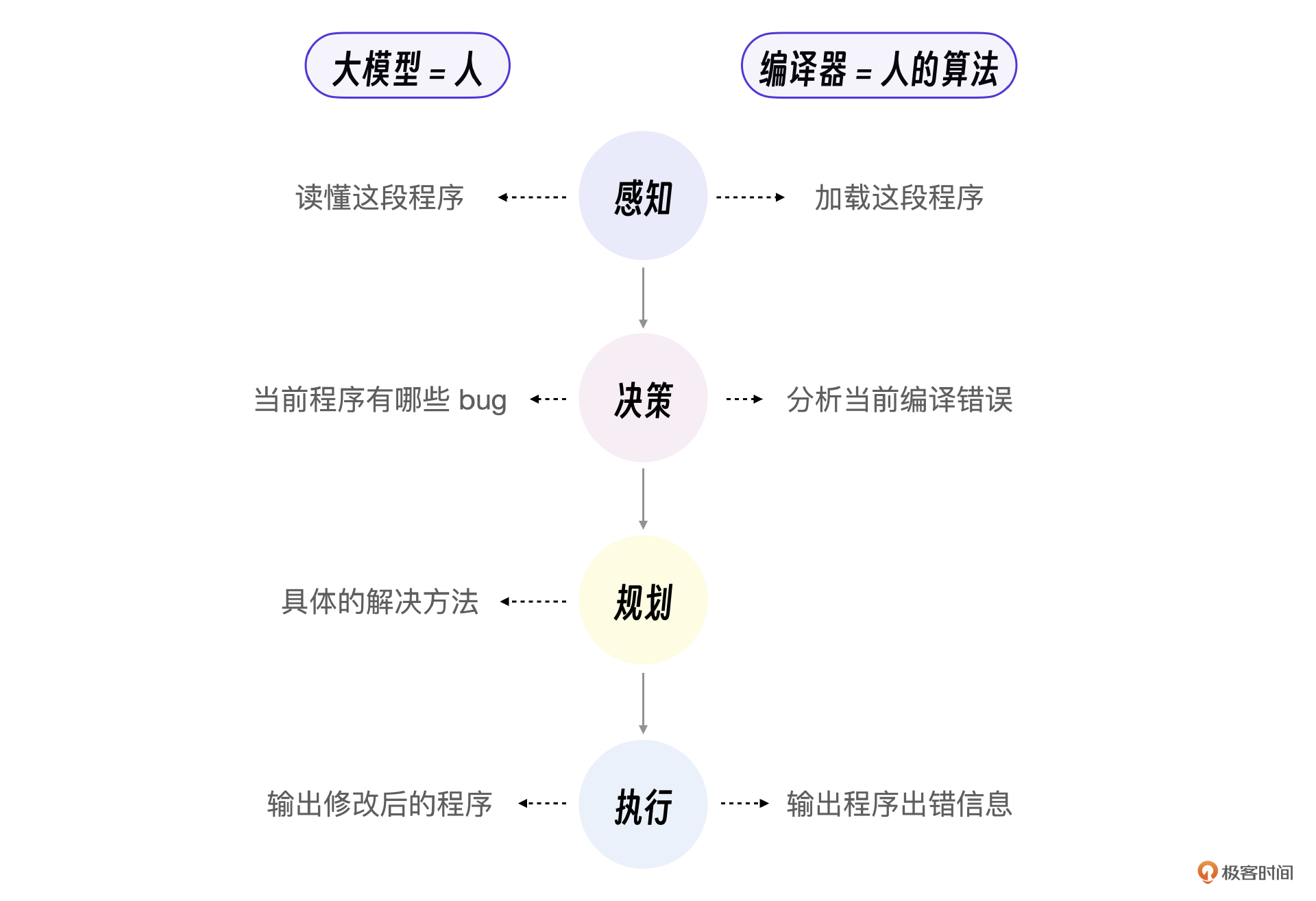
在我们这个例子里,当学生发了一段自己写的C语言程序时,大模型必须读懂这段程序,也就是大模型需要具备感知能力。学生提交的这段C语言程序可能是从来没有出现过的,因此大模型不能只是搜索信息,而是要根据新的情况自己决策当前程序有哪些bug,该往什么方向修改。接下来还需要规划具体的解决方法,执行这些修改方法,并输出修改后的程序。
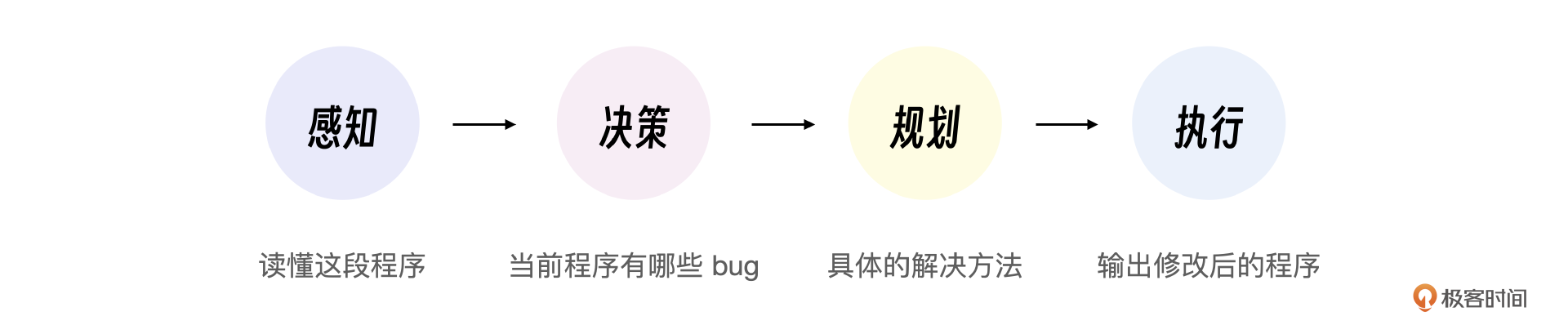
我们换个角度,其实传统应用程序也可以看做某种程度的智能体。比如C语言编译器,它也能感知、决策、规划和执行,只不过它的这些智能都是人类提前编码的而已。相比于大模型助教,C语言编译器的能力也受限,它只能查找程序编译错误,不能修改程序。
但是,C语言编译器有一个很大的优点,就是可靠性很强。基于大模型的助教可能把程序给改错了,但C语言编译器却一定不会出错。
那这里就要谈到传统应用和AI智能体的差别了。
传统智能体是把人设计的算法用计算机程序表示,而大模型则是一个具备所有算法的“人”。
刚才提到,这个助教只能完成一部分老师的工作,真实世界的智能体本就没有这么简单。理想情况下的Agent智能体应该是一个完全独立的、自我决策的系统。
比如一个经营咖啡店的智能体,它应该自主决定什么时候进货,什么时候出新的产品,在顾客到店的时候自主完成服务,出现投诉的时候能自主处理等等。什么时候这种智能体实现了,人类店员就真的可以下岗了。
颠覆应用交互
不过,即使真的有了经营咖啡店的智能体,当我们的咖啡店选址不同、客群不同的时候,仍然需要人类介入,来调教这个智能体。最终智能体还需要和人类的交互界面。我们来看看一个例子,大家都很熟悉的应用:美团。
美团APP的传统交互是什么样的呢?
大胆假设一下,现在已经基于大模型开发了美团全功能的智能体,那是不是这个智能体的交互就是一个简单的聊天交互界面了呢?
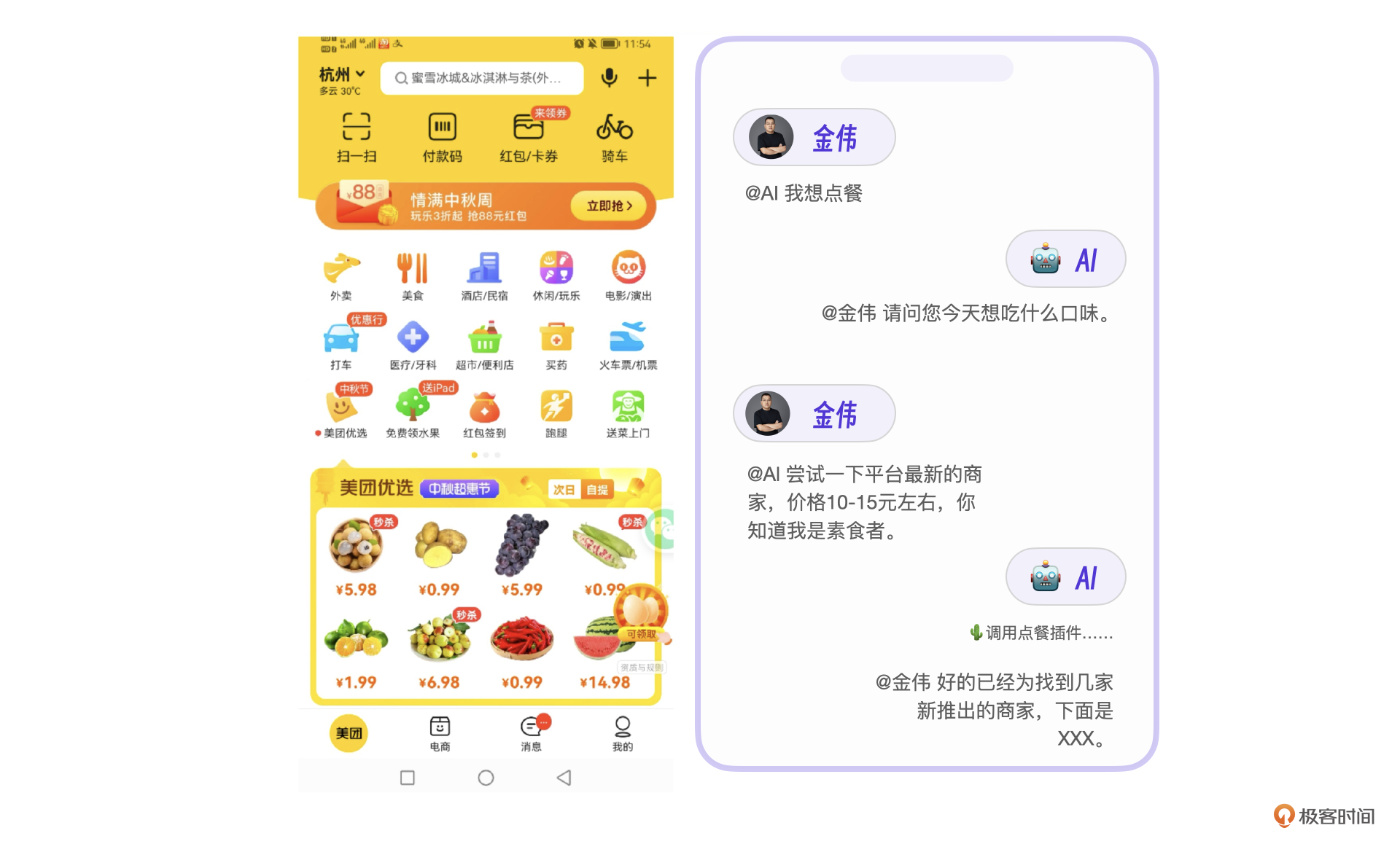
最后我们要说,现阶段基于大模型的Agent智能体仍然是能力受限严重的智能体,但大模型能力会越来越强,应用交互也会往我们设想的这个方向不断发展。
为什么离不开大模型?
理解了智能体,我们解决下一个问题,为什么我们离不开大模型呢?
上节课提到的意图识别,包括在Agent应用中提到的助理,是一个对外客服的概念。在逆向分析当中,工作流输出最终交给了大模型处理。实际上,这些实战例子都说明了大模型的感知能力非常强。
或者,你也可以说它这项能力很可靠,其他的几项就不一定了。
拆解大模型的可靠度
大模型目前只有内容输出能力,实际上并不具备大多数场景下的执行能力。而大模型推理能力似乎也是受限的?我们可以看看最经典的鸡兔同笼问题。

类似的数学问题说明,大模型在深度推理方面的能力不足。这实际上影响了智能体的决策和规划能力,也就是说情况一旦稍微复杂,基于大模型的决策和规划就可能不是最优的。
显然,全部用传统的函数逻辑实现智能体不可能,因此最终 Agent智能体开发范式都会走向大模型和传统程序相融合的方案。
最重要的问题是,我们需要给大模型安排一个合适的位置。
其中有一类情况的位置非常明显,某个特定的AI能力,大模型非常擅长,比如文章总结、翻译等等,让大模型完成这些单独的任务非常可靠,这很像一个程序接口,原来不好做的NLP任务,基于大模型都不难做。
除了单独的NLP能力,大模型还非常擅长上下文理解,擅长人类语言聊天,上下文信息抽取等,也就是大模型的感知能力是可靠的。剩下的问题,我们再用程序给大模型足够的引导和限定,它在决策和规划上也能具备可靠的能力。
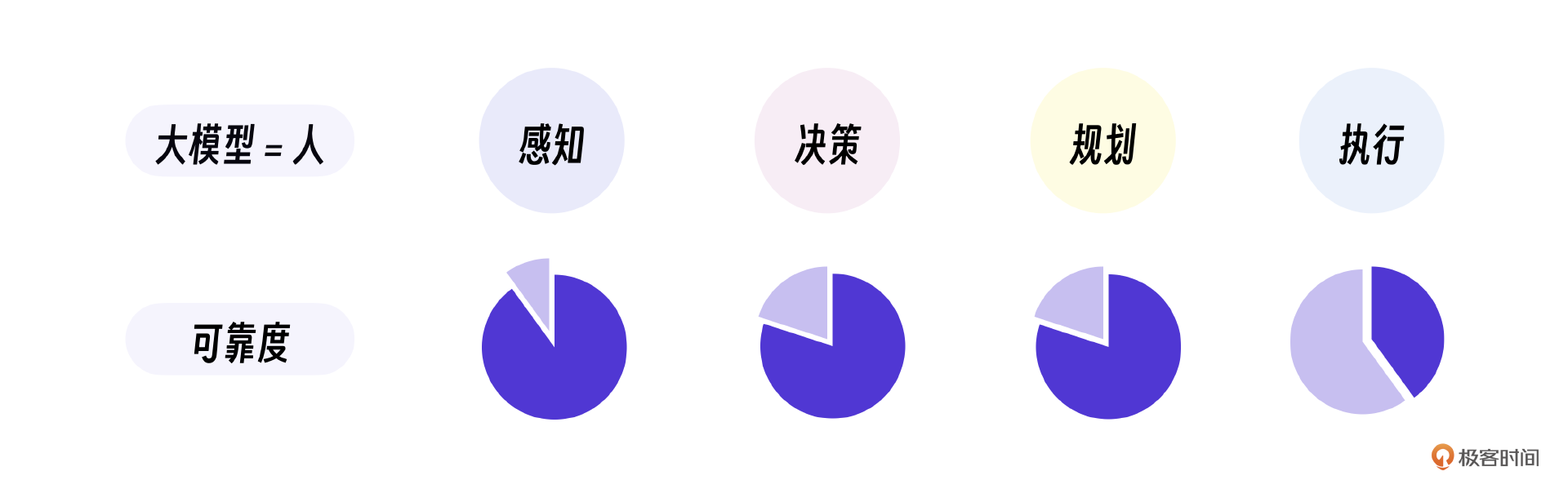
正如图中所示,大模型在智能体四要素上的可靠性决定了我们的开发范式。
简言之,我们通过编程引导大模型做决策和规划,通过传统程序做执行,在特定的前提和领域下就可以开发足够可靠的Agent智能体。
案例:一个LangChain智能体
根据Agent智能体能力级别的不同,可以分为单个能力的智能体和类人的、可聊天交互的智能体。比较简单的是单个能力的Agent智能体,我们用一个基于LangChain开发的智能体为例。
下面是一段伪代码,表示根据用户问题查询搜索引擎,最后总结出答案的Agent智能体。
from langchain.chains import SimpleChain
from langchain.llms import OpenAI
from langchain.tools import GoogleSearchTool
# 初始化语言模型和工具
llm = OpenAI(api_key="your-api-key")
google_search = GoogleSearchTool(api_key="your-google-api-key")
# 定义Chain
class QuestionAnswerChain(SimpleChain):
def __init__(self, llm, search_tool):
self.llm = llm
self.search_tool = search_tool
def call(self, input_text):
# 使用语言模型分析问题
search_query = self.llm(input_text)
# 使用搜索工具查找答案
search_results = self.search_tool(search_query)
# 通过语言模型总结答案
answer = self.llm(search_results)
return answer
# 使用Chain
qa_chain = QuestionAnswerChain(llm, google_search)
user_question = "法国的首都是哪里??"
answer = qa_chain.call(user_question)
print(answer)
例子中的 QuestionAnswerChain 是一个自定义的 Chain,而 Chain 就是LangChain框架的核心概念,你可以理解为一个 Chain 就是一个自定义的具备单独能力的智能体。
针对用户搜索的输入,通过 self.llm(input_text) 来感知到用户搜索的关键词,这一步是大模型微完成的。第二步用 GoogleSearchTool 查找信息,实际上是我们编程做的决策和规划。最后我们利用了大模型的语言能力来做输出的执行,也就是 self.llm(search_results)。
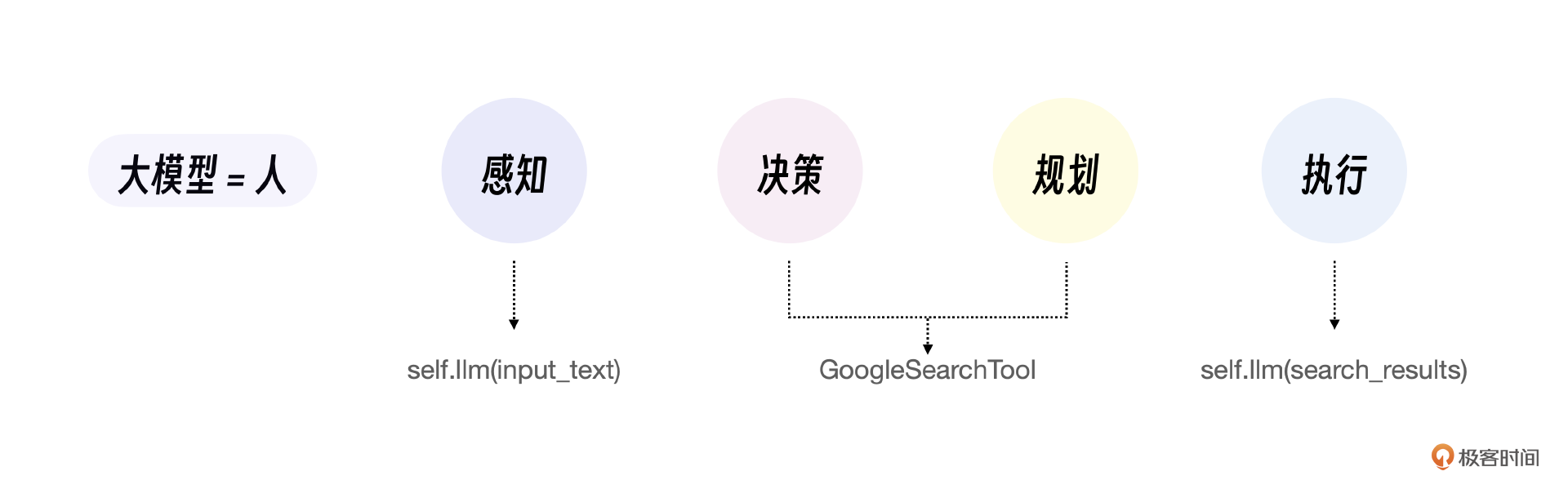
总结来说,一个基于 Chain 的简单智能体,其感知、决策、规划、执行,每一步都有我们人类的设定和参与,就能很好的完成这个小任务。
类似任务其实可以用更加智能的处理方式,让大模型做更多决策。在 LangChain 框架中,意图识别和工具选择可以依赖大模型的理解和预定义的代理逻辑。下面是这种方式对应的伪代码。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
# 首先,我们加载将用于控制代理的语言模型。
chat = ChatOpenAI(temperature=0)
# 接下来,我们加载一些工具来使用。请注意,`llm-math` 工具使用了一个 LLM,因此我们需要传入它。
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 最后,我们使用工具、语言模型和我们想要使用的代理类型来初始化代理。
agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# 现在我们来测试一下!
agent.run("Tom的女朋友是谁?他的年龄的0.23次方是多少?")
在这个 LangChain 的示例中,智能体的感知部分接收和理解用户的输入,具体就是理解 "Tom的女朋友是谁?他的年龄的0.23次方是多少?" 并识别出需要搜索信息,内部是由大模型完成的。
决策部分,负责分析和确定如何处理用户的输入,该代理需要决定选用合适工具(如 serpapi 用于信息查询,llm-math 用于数学计算)。当 agent.run() 被调用时,这个决策过程在内部有由大模型完成。
规划也会在 agent.run() 内部实现。规划负责调用工具的顺序和方式。本例中,首先使用 serpapi 查找 Tom的女朋友 的年龄信息,然后将结果输入 llm-math 进行数学计算。
执行则包括工具的调用和大模型的响应生成。
总结来说,LangChain 的核心概念就是例子中的 Chain 和 Agent,实际上 Chain 就是一个人类可以自定义决策和规划执行逻辑的智能体,Agent 则在更高层,可以根据上下文自主决策和规划调用这些智能体。
LangChain 框架还有其他概念,都是辅助的智能体工作的。比如 llm 是大模型,PromptTemplate 是处理提示词的,memory 是处理会话消息历史的,Message 表示各种消息,tool 是传统工具。
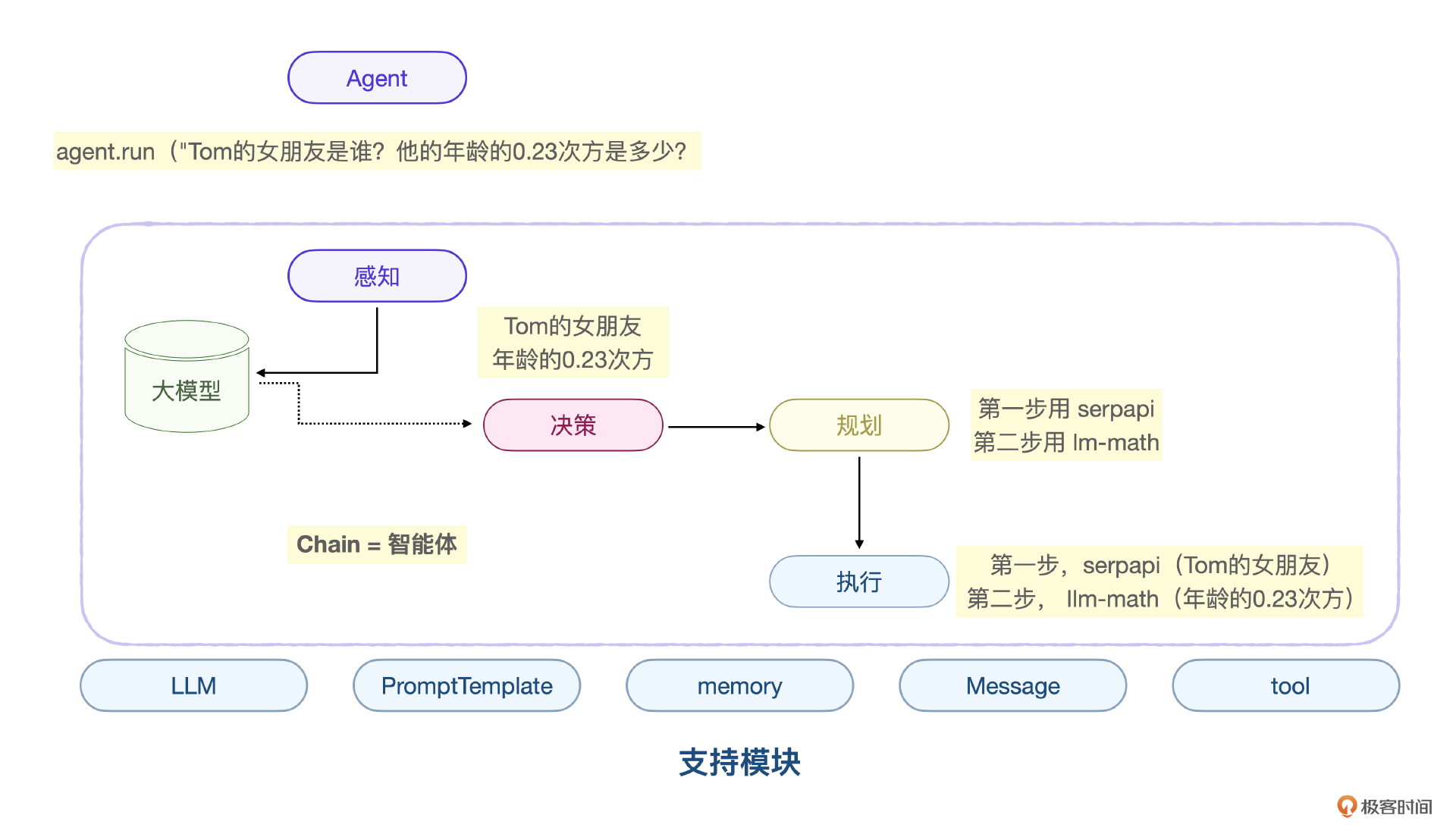
大模型技术发展非常迅速,将来大模型的推理能力、执行能力是会不断增强的,比如例子里的网络搜索和数字计算,实际上大模型慢慢发展都会将常见的这些能力内化为自身的能力。
那是不是将来只需要大模型就可以做出全功能智能体了呢?我们看一个复杂一点的例子。
案例:自动编程智能体
我们的案例是:可以基于大模型实现自动编程吗?我们都知道可以让大模型写一个具体的函数,比如下面提示词。
大模型完全可以自主决策和规划,写出对应的代码。那我们看看这个例子里大模型作为智能体的四个要素。
- 感知:系统理解用户的编程需求。
- 决策:选择适当的算法。
- 规划:生成详细的代码结构。
- 执行:输出代码,并进行解释。
当然,由于大模型的幻觉问题,有些大模型写的程序有bug,需要人来发现并进一步让大模型修改bug。那么,如果把这个思路扩展一下,把人类在编程中常见的决策和规划写入智能体,是不是就实现全自动了呢?
具体而言,让大模型在编写代码后自动生成测试用例,然后逐步测试并修复代码中的问题,直到解决所有bug。
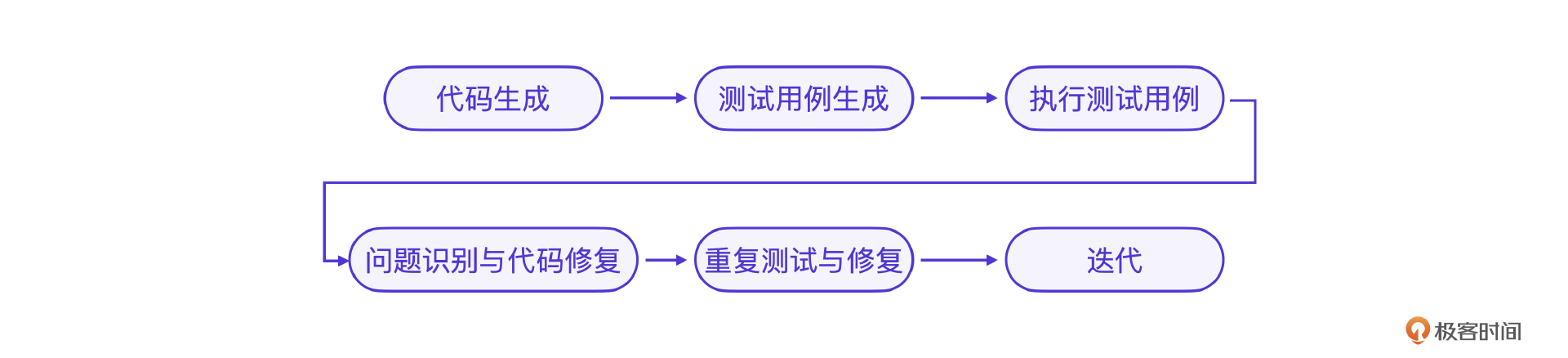
下面是这个设计的伪代码。
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType
# 初始化大模型
chat = ChatOpenAI(temperature=0)
llm = OpenAI(temperature=0)
# 初始化工具和代理
tools = ["static-analyzer", "auto-tester"] # 假设有这些工具
agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# 代码生成模块
def generate_code(user_input):
# 测试用例生成模块
def generate_test_cases(code):
# 执行测试模块
def run_tests(code, test_cases):
# 修复代码模块
def fix_code(code, test_results):
# 主流程
def auto_programming_pipeline(user_input):
code = generate_code(user_input)
print(f"生成的代码:\n{code}")
while True:
test_cases = generate_test_cases(code)
test_results = run_tests(code, test_cases)
if "通过" in test_results:
print("所有测试用例都通过了!代码没有问题。")
break
else:
print("存在未通过的测试用例,正在修复代码...")
code = fix_code(code, test_results)
# 运行示例
auto_programming_pipeline("请编写一个Python函数来计算两个数的最大公约数。")
实际上,你按照这个逻辑编写智能体真的可以工作,并自主修复所有bug。然而当这个智能体处理复杂任务时,问题就来了。如果问题复杂,那么修复代码时,大模型可能会引入新的错误,系统就进入了一个修复-测试的死循环。反复调用大模型生成代码,资源消耗可能不断累积,导致高昂的成本和长时间的响应。
这个例子表明,目前大模型离开人不可能实现这个级别智能,更不要说更高级别的智能体了。所以目前来讲,最优的范式就是人类辅助决策和规划。

一方面是人类辅助,另一方面还可以通过大模型微调提高大模型在特定场景的推理能力。
案例:微调智能体决策能力
很多人认为大模型微调是给大模型增加特定的数据。真实情况是,大模型微调,是让它具备基础的某种特定能力。
比如在我们的自动编程智能体案例中,如果要让智能体掌握一门新的开发语言,就可以用大量的现成代码微调大模型。目的并不是让大模型记住这些代码,而是让大模型通过这些代码找到这门语言内在的语法和逻辑关系。当新的开发需求出现时,大模型可以根据这些内在逻辑去推理。
你可以用数据微调大模型,也可以通过智能体的提示词微调大模型。提示词的微调方法往往适用于某个场景下大模型决策不够精准的情况,用提示词可以引导大模型在特定条件下的决策。
上节课提到的Agent底层demo,我们编写的提示词和各个工作流的输入输出参数,实际上就是在对大模型的决策和规划做微调,我们写的提示词的好坏会直接影响大模型的决策规划表现。
特别注意,如果提示词的方法无法调整大模型的决策表现,还可以用大模型微调的方法继续调整它的能力。
当然,这两个微调方法并不冲突,都是给大模型插入新的可靠决策和规划能力。那么现在,大模型沟通是可靠的,插件能力是可靠的,微调让意图识别变的可靠,最终开发的Agent智能体自然是可靠的。
现在,我们可以整理出一个基于场景的Agent智能体应用架构了。
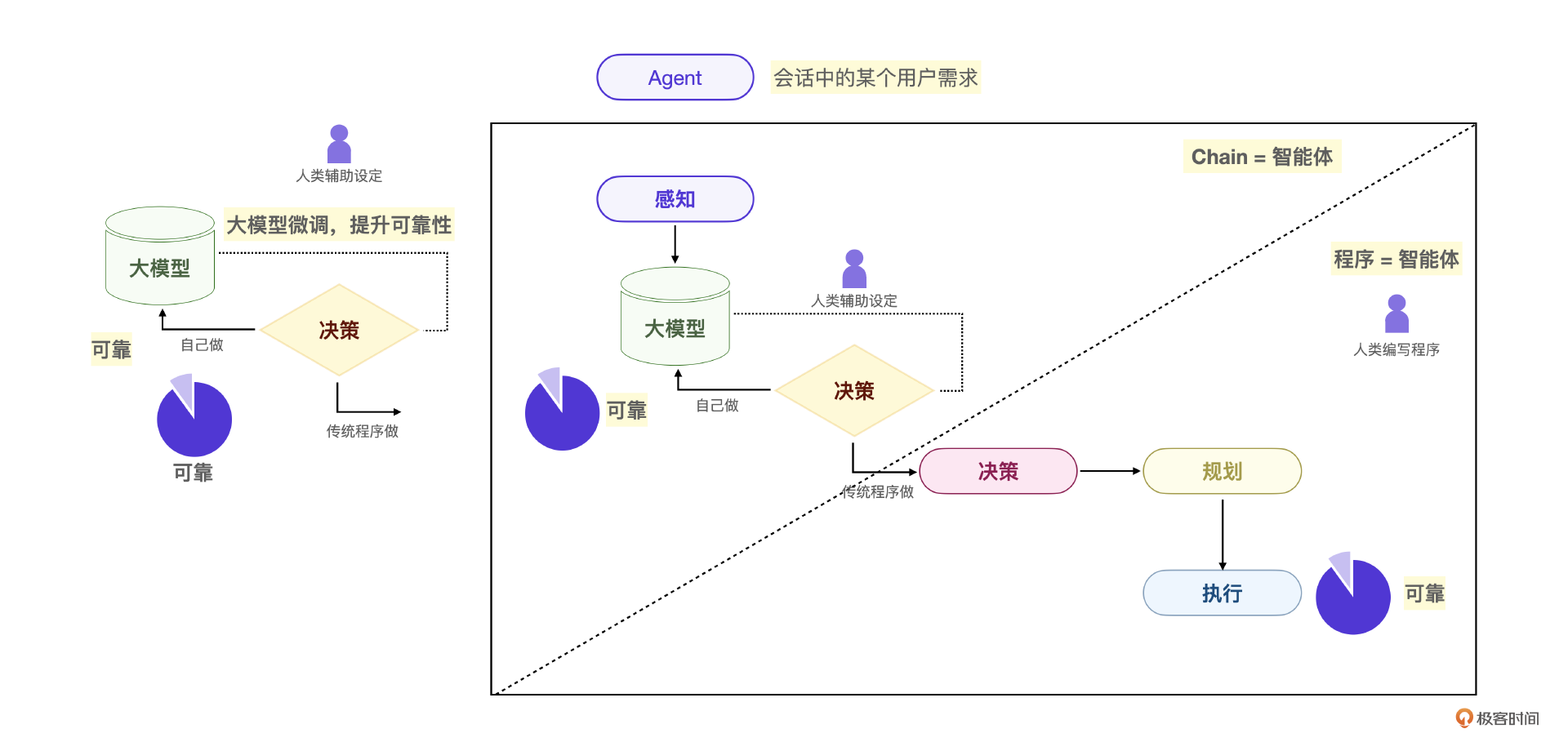
从这一节的分析你可以看出,目前阶段的智能体开发,作为开发者最核心的能力实际上是低成本地构建可靠的智能体应用,接下来我就一个例子进一步说明这个问题。
低成本才是核心
上节课的Agent底层框架和应用yaml模版设计,再之前的Coze拖拽式工作流开发模式,都体现了大模型智能体开发中对成本问题的重视。
合理规划大模型在感知、决策、规划、执行各部分的工作是一种成本优化的体现,而必须要人工编程实现的工作也要考虑尽量低成本实现。
真实项目中的营销Agent智能体是一个多轮聊天交互的智能体。它像一个人,有多个能力。具体实现可以通过简单智能体的组合来完成。
而这里的简单智能体,就是 Chain 或上一节课提到的 工作流。

分而治之
从一个具体的营销场景下的智能体例子,能看到这类智能体的基本结构。
先说场景,公司希望使用Agent智能体自动生成广告文案,推广新产品。需要生成符合品牌调性、能吸引目标用户的高质量广告内容。
真实项目中可以设计一个人机结合的工作流,既可以发挥大模型的创造性,又可以保证智能体的可靠性,该工作流的基本步骤是初步内容生成、内容审查模块、个性化内容和人类反馈。

初步内容生成,输入包括品牌信息、产品特点、目标用户描述等。
内容审查模块,使用预定义的品牌规则和词汇库,自动检测不符合标准的部分。
示例:
def review_content(content):
# 假设有一组品牌规则和关键词
brand_rules = ["创新的", "优质的", "实惠的"]
restricted_words = ["便宜的", "不好的", "低质量的"]
个性化内容,基于用户历史行为和兴趣生成用户画像,根据用户画像调整内容的风格和重点。
示例:
def personalize_content(base_content, user_profile):
if user_profile['interest'] == 'photography':
...
elif user_profile['interest'] == 'gaming':
...
else:
return base_content
generated_text = "这是基础内容。"
user_profile = {'interest': 'photography'}
personalized_content = personalize_content(generated_text, user_profile)
print(personalized_content)
人类反馈,让人类审查员最终审核内容,提供反馈并最终确认内容。
实际上,上述每一个模块还可以进一步在其他工作流复用,这样成本会更低。
一个复杂的智能体,分拆为多个可以简单实现的智能体,这个范式本身就是智能体开发中最节省成本的模式,也是一种比较拟人化的开发思路。
低成本开发
对智能体的规划分治法是设计上的范式,而具体逻辑开发中的复用性是开发上的低成本范式。
回顾上节课的插件开发,会发现实战中是在原有业务逻辑里抽象成不同插件,给智能体直接复用,更之前的Coze平台开发范式中,插件和工作流的分享可复用性也提现了这一点。
另外一个例子是Langchain中的 memory、llm、prompt、tool、Message 等模块。当然,这些模块也可以在Coze这类智能体平台上找到对应的模块。
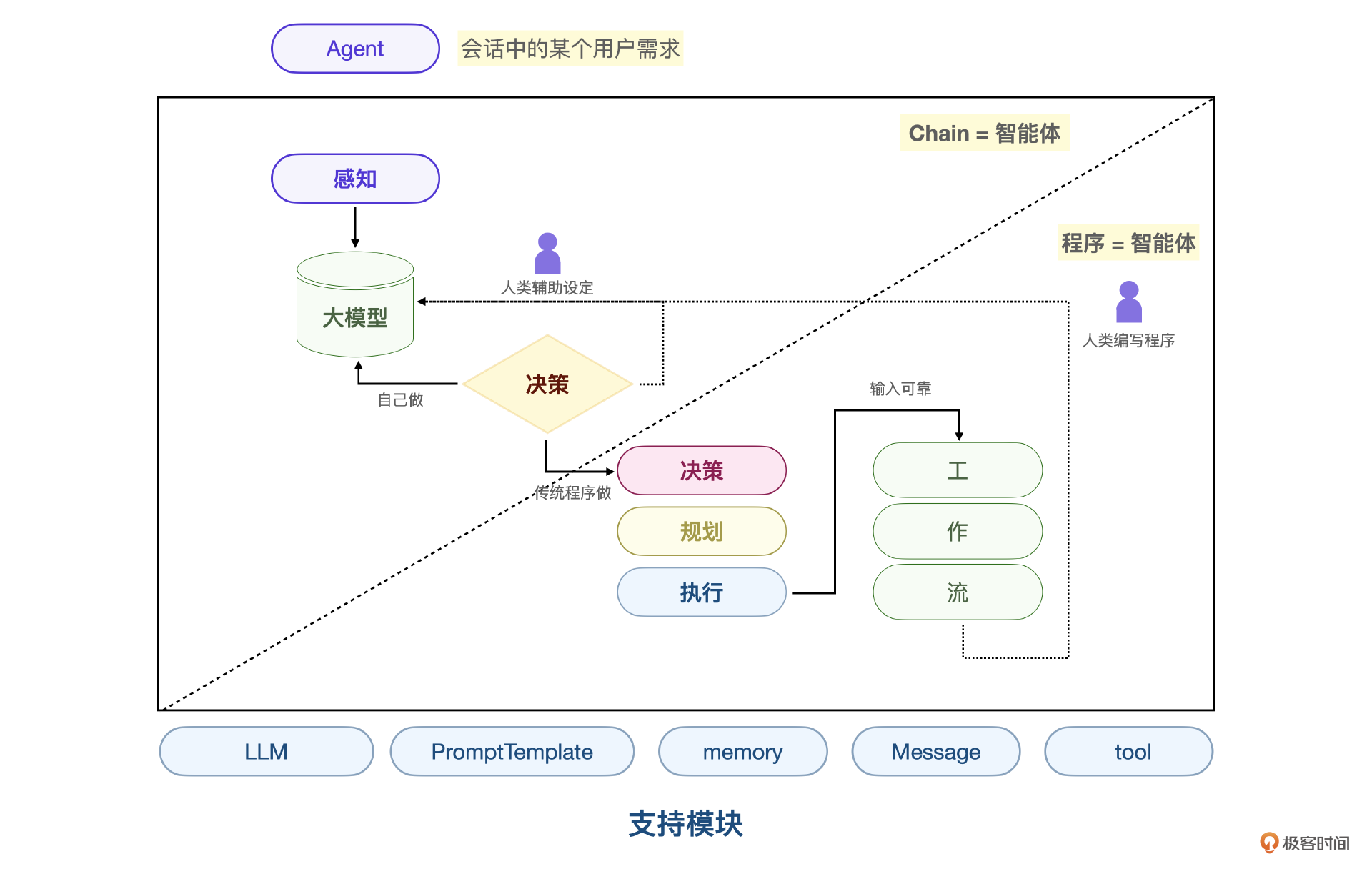
现实项目中,插件一般由平台开发,如果是公司内部,由研发统一开发的公共插件,工作流就是单个智能体。将一个复杂的智能体分而治之。在这个框架之下,将现有能力迁移到Agent平台上也非常方便。
合理利用大模型的感知、决策能力,快速迁移已有模块和复用插件,都可以降低开发成本,而交互流程创新则可以把界面开发成本直接降为零。
最后我想特别强调一点,你仔细去想,大模型这种聊天式的交互,将交互方式统一,交互开发成本为零,这个特性才是让 Coze这类Agent平台可以实现低代码,低成本开发的根本,也是我坚信基于大模型的智能体开发可以做到百倍效率提升的根本。
小结
智能体这个概念并不是特指现在AI领域的Agent智能体,一个提示词+大模型是智能体,甚至一个传统程序也可以看做一个智能体。只是我们在实战中会发现,提示词+大模型生产的智能体往往不靠谱,而传统程序更靠谱。
要提高大模型的“靠谱”程度,需要先理清大模型在智能体的四个基本能力上的“靠谱”程度。
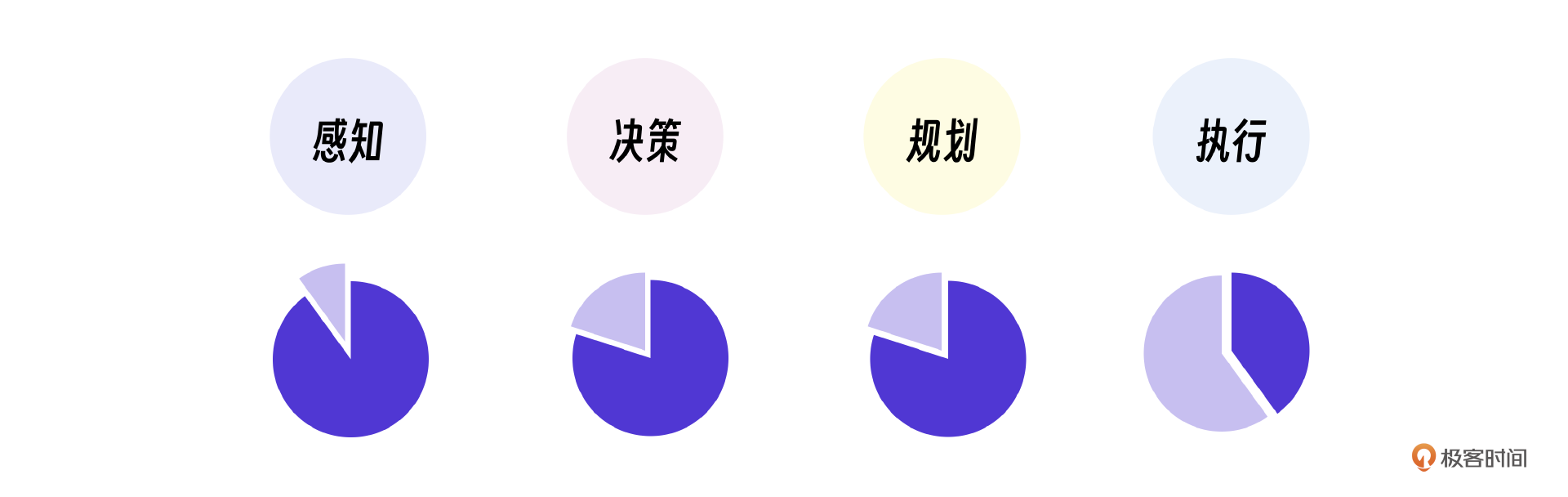
基于大模型现在的能力,它在感知、决策、规划、执行四个能力上的“靠谱”程度实际上是越来越低的,那怎么才能提升呢?
可以通过提示词引导大模型,让它对特定的任务做特定的决策和规划。这样就能在用户提出需求时,决策那些业务交由大模型自身处理,哪些业务抛给传统程序处理。如果大模型还是无法准确地识别和分配这些任务,我们可以通过微调大模型提升准确性,也可以提高任务划分的颗粒度,把更多的业务逻辑交给传统程序处理。
目前的大模型还不具备很多的执行能力,因此智能体最终的执行大部分还是交给了传统程序逻辑处理。这种融合的架构方案会在未来很长一段时间内存在,其本质在于,完全基于大模型的智能体成本极高,引入人工辅助的智能体才能降低成本。
最终我们得到一个适应所有业务场景下的Agent智能体架构流程。
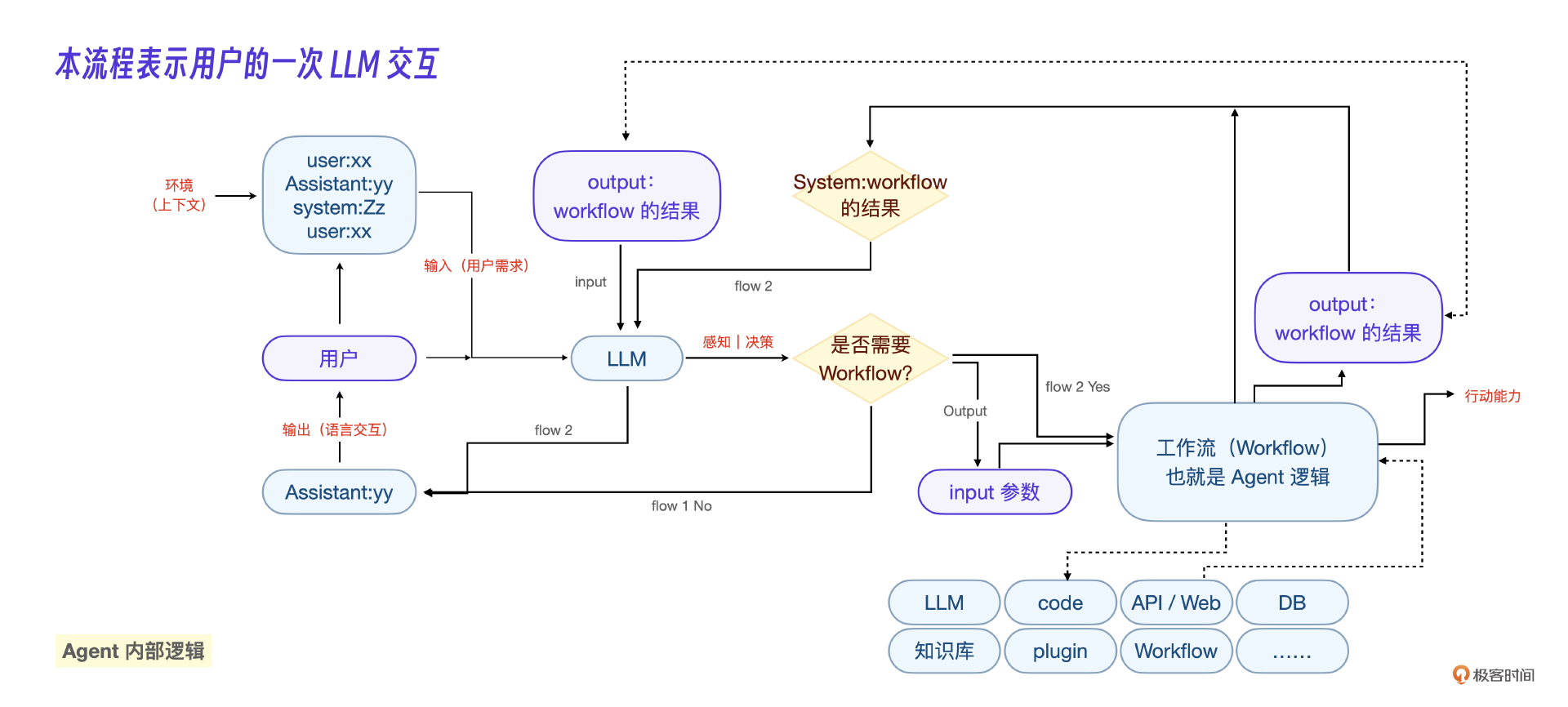
思考题
我们说到,智能体开发的一个核心问题是提高智能体的可靠性,那在我们这套Agent智能体架构下是如何保证可靠性达到100%的呢?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 石云升 👍(0) 💬(2)
大概理一下这个工作流。 1. 首先,用户提出一个问题或要求。 2. 这个问题传给了AI助手。 3. AI助手会思考:"这个问题我能直接回答吗,还是需要更复杂的处理?" 4. 如果问题简单,AI助手就直接回答用户。 5. 如果问题复杂,AI助手会启动一个叫"工作流"的特殊程序来处理。 6. 这个"工作流"程序可以使用很多工具,比如查资料、写代码、上网搜索等,来解决复杂问题。 7. 最后,"工作流"会给出答案,AI助手再把这个答案传达给用户。
2024-09-21 - 石云升 👍(0) 💬(1)
100%的可靠性技术上实现不了吧..
2024-09-21 - littleboy 👍(0) 💬(0)
老师文章里面的图是哪个软件画的?
2025-01-11 - Geek_3b5445 👍(0) 💬(0)
还是看场景, 有些场景传统图形化程序员更直接高效交互,大模型的落地机会是满足传统程序不好用的场景.
2024-12-21 - xuwei 👍(0) 💬(0)
chain不等于智能体吧,老师这里有特别的含义吗
2024-11-13