18 实战升级:如何提升电商客服模型理解JSON等数据协议的能力
你好,我是金伟。
回想一下前几节课和电商客服项目里的具体例子,为什么我们要开发电商客服专用模型呢?其实,总体的目的还是提升模型处理特定复杂问题的能力,具体事实上,我们采用的是微调训练JSON原子能力的方法。
之所以要训练JSON原子能力,是因为大模型需要和智能体配合才能达到较高的可靠性,而JSON是最适合跟现有编程体系对接的数据格式。
本节课将进一步探讨整个项目中JSON等数据协议的提升方法,包括基础数据格式化、专有模型构建,以及后续的各类优化。它们的灵魂还是数据工程,这些补充经验对你将来做其他项目也同样适用。
基础数据格式化
经过之前的课程,你可能会觉得只有当大模型遇到处理不了的问题时候,才会做数据工程,实际上则不然,我们回顾一下Dify的Agent智能体流程图。
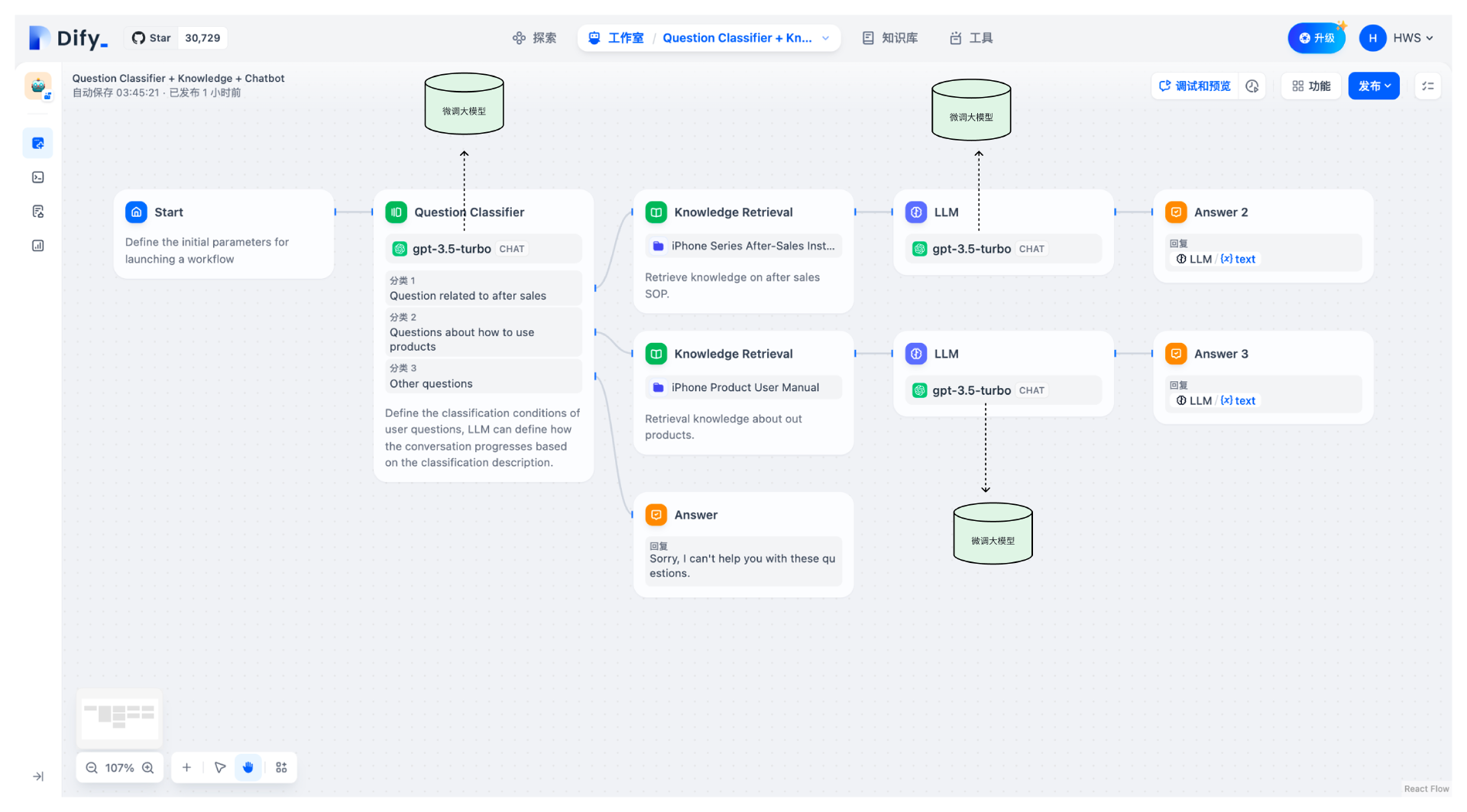
需要注意,不管客服问题有多少分类,Agent智能体在意图识别阶段,最重要的能力就是把用户的问题转化为JSON的数据格式,用作参数传递给后续的工作流。
比如这个订单物流查询的例子,Agent智能体需要抽取出如下格式的信息。
我们在真实项目中的经验是,可以对每一个基础的问题分类都做数据抽取格式的训练。这样能极大提高大模型的意图识别能力。
我准备了下面两个语料例子,已经可以覆盖大部分需求。
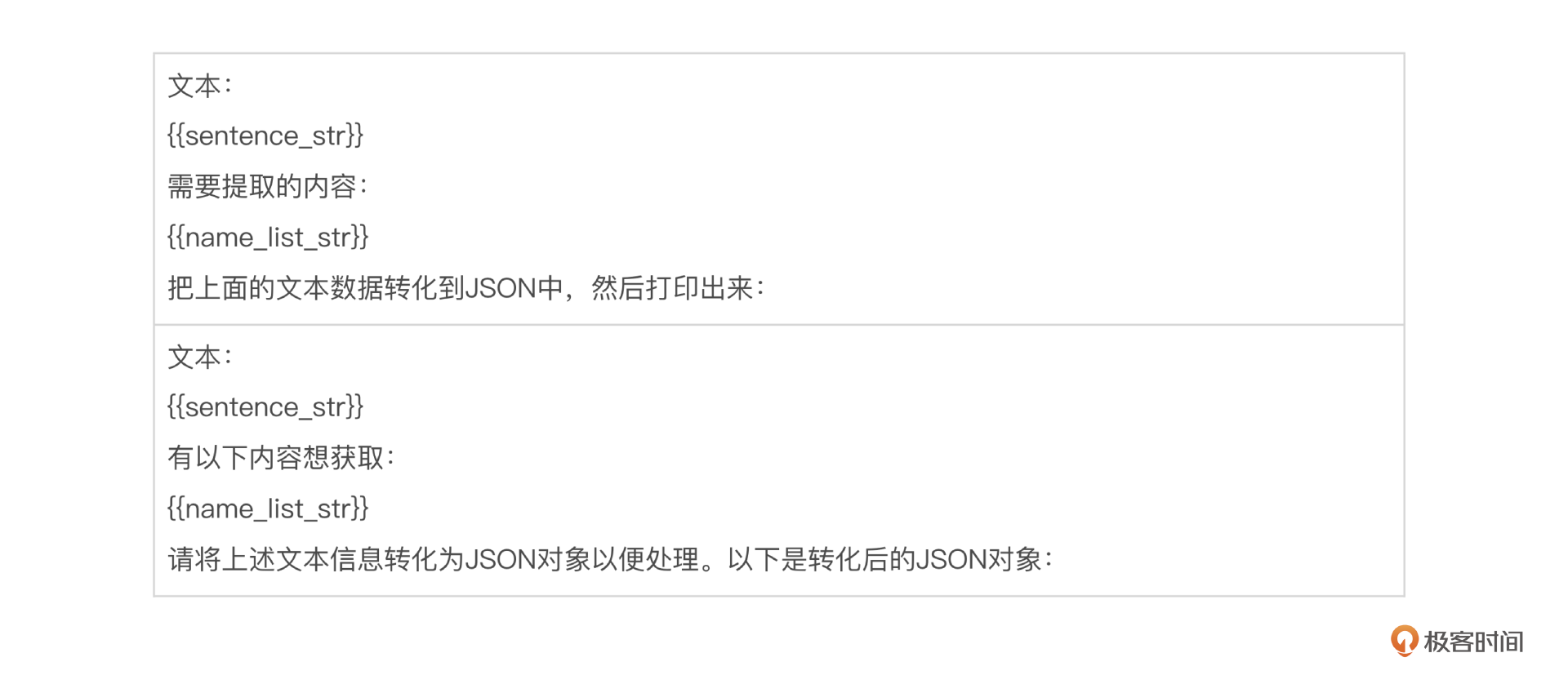
我们继续拆分例子里的 {{sentence_str}} 部分,我先针对具体场景把可变的部分做成模版变量,从例子出发,你会更好理解一些。
先看这个例子。
我们采取{{处理措施}}措施来提高员工的能力,以应对客户描述中的高级零容忍能力要求。
这是在{{列车类型}}上实施的,并且设备状态ID是{{设备状态ID}}。
我们非常欢迎{{点赞类型}}的点赞类型反馈。
此时,我们想要提取的内容字段名列表 {{name_list_str}} 对应的值如下。
之后,我们要把模版里具体的参数做成有意义的随机值,还是用 Jinja2 和 Faker 技术完成。
下面是这个场景下填充了值的句子。
与之对应的大模型回复JSON格式的内容如下。
回到我们智能客服场景,你也可以思考类似下面的顾客退款流程中的基础数据格式应该怎么设计。
顾客:
“请问我上次的退款申请进展如何?”
智能客服:
“您好!请提供您的订单号,我们将立即为您查询退款进度。”
顾客:
“订单号是123456789。”
智能客服:
“感谢提供信息!您的退款申请正在处理中,预计1-3个工作日内完成。请耐心等待。”
这种通过基础性格式化输出相关基础数据的方法,可以规范大模型的数据输出,为电商客服模型对应格式输出的稳定性打下基础。另外还有一个小技巧,你在实操这一步的时候,可以在已有数据的基础上,批量制作足够多的基础 nlp原子能力相关语料。
数据格式的设计
接下来我们说说数据格式的设计。数据工程是大模型微调里最重要的环节,而不是很多人认为的代码开发和微调训练过程。我们甚至可以说,针对特定场景的大模型微调其实就是做这个场景对应的数据工程。
你有没有想过,为什么给大模型1000条示例数据,它就能泛化出一类数据的抽取能力呢?甚至这个具体数据是一个世界上从来没有出现过的数据。注意,了解这个问题,对你将来做其他场景的数据工程至关重要。
大模型的基础 nlp 能力是数据孪生数据格式设计的理论基础,换句话说,因为大模型在预训练阶段已经具备了大量的 nlp 能力,所以,我们只要给大模型提供少量的数据例子,大模型就能组织原有的基础 nlp 能力形成全新的 nlp 能力。
这样说可能还是太抽象,我们先看一看大模型都具备哪些基础 nlp 能力,再用一个例子来说明它是怎么进化的。

其实,数据格式设计本质,就是准确利用好大模型的基础 NLP 能力,提升复杂对话场景下的数据提取能力。而在智能客服复杂对话场景下设计数据格式,就需要训练大模型的原子能力。我们回顾一个第15课的案例。
从以下对话中提取客户需求信息和时间地点信息:
{
“问:请问有没有兼容我{{设备}}型号的{{配件}}?
答:有{A}{B}{C}{D}种。
问:{{时间}}上能不能送到{{地点}}?
答:{A}种可以{{今晚}}送到。”
}
假设我们想让模型具备提取下面信息的能力。
我们来分析分析,怎么设计数据格式才能引导大模型发挥它的基础能力呢?要知道,数据孪生最本质的地方就在于数据格式设计,也就是引导大模型去思考,处理数据。
我们知道,这个例子代表了一类场景,想要提取出关键的信息,显然大模型需要具备一个基础能力:分词能力。更进一步,我们希望大模型能提取出具体的产品名称,设计出一个模版。
这实际上要求大模型在分词基础上识别出这些名词是专有实体名称。最复杂的一个例子是产品-地址-配送的需求,形成一个可识别的模板,也就是下面的模版。
这个模版需要大模型在名称,地址,时间,事件基础识别的基础上,更进一步地识别出这些名词和时间的关系,也就是实体关系的识别。
换一个角度来说,我们实际上应该先了解大模型有这些基础的 nlp 能力,再来设计相应的数据模版,让这些 nlp 能力组合发挥出来。当你设计其他数据模版的时候,这个设计原则可以帮你最大限度的发挥大模型的能力。

专有模型构建
好了,数据问题说完之后,我们来说专有模型的构建。这块在电商客服的专用模型训练过程,还有几个之前的课程里没有提及,我在这里补充说明一下。
电商领域数据
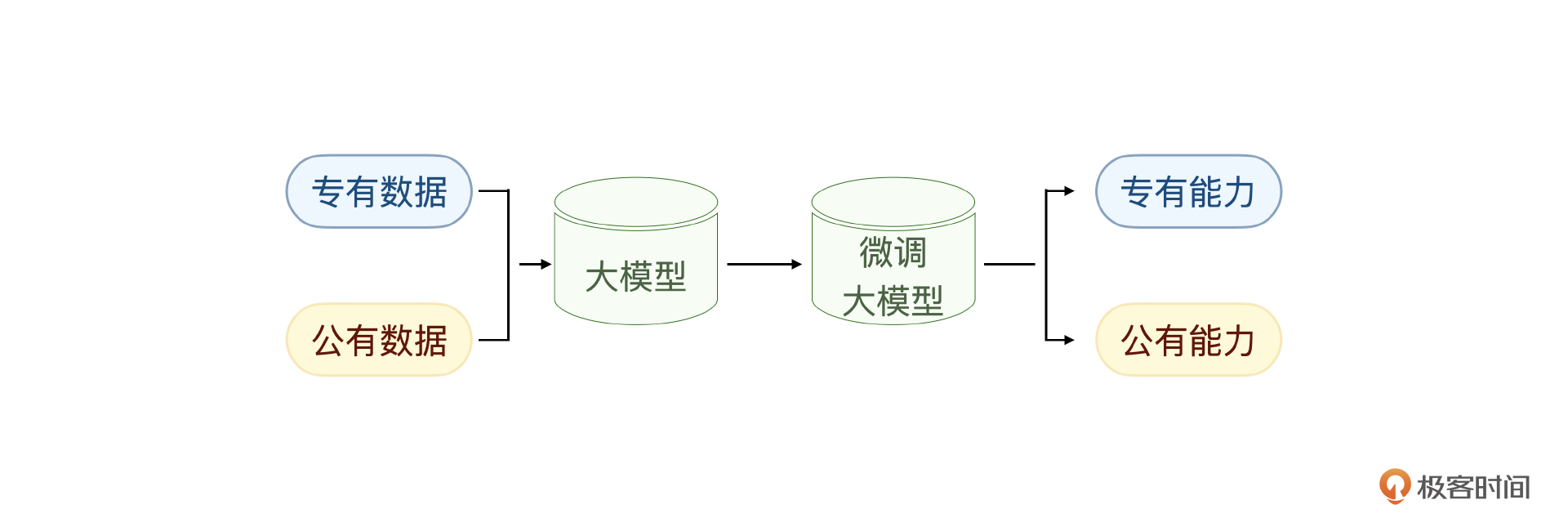
不管是前面提到的基础数据JSON格式化,还是专有问题的数据格式设计,都是专用私有数据的数据工程,微调的是大模型的专有能力,甚至是针对特定场景的某个能力。
在真实的智能电商客服项目中,还需要加入基础的电商领域数据微调,让大模型具备电商领域基础能力。举个例子,一个电商客服如果连基础的电商平台和规则都不清楚,实际上是没有资格做专有场景客服的。
所以,我们需要收集大量电商平台过程数据。这些数据包括电商平台的商品信息、用户评论、订单详情、客户地址等。将这些格式化数据按照字段等组合成完整语义的上下文,再组合成JSON和Markdown格式的数据。通过电商客服模型专用语料的训练,就可以强化模型对电商数据的理解力。具体的开源训练数据集,我已经放在了群资料里,记得去领取。
如果说专有问题的数据工程就像传统程序开发里的私有函数,那公共数据集的微调就像传统开发里的底层函数。我用一个具体的公有数据集的数据来说清楚这个问题。
{
"instruction": "描述一件新棉质衬衫的颜色和质地",
"input": "",
"output": "这件新棉质衬衫有一种柔软、丝滑的质地和一种明亮、充满活力的色调。颜色是一种明亮的蓝色,几乎像电一样。"
}
看起来这只是一条简单的数据,实际上它的作用并不是让大模型遇到这个问题时这样回答,而是用于训练大模型更上层的能力。
- 理解能力:在这个例子中,客服机器人必须理解用户的要求是关于产品特性的描述。
- 生成能力:当用户在电商平台上询问产品的特定特性时,客服机器人需要生成类似的描述。
- 泛化能力:虽然这个例子看起来只是一个产品理解能力的问题,但在实际应用中,如果用户问“这件衬衫适合夏天穿吗?”,客服机器人需要将这个理解能力迁移到新的场景里。
我们再来看电商基础数据集的一条评论数据。
这条数据的目的也不仅仅是识别评论正面还是负面,而是为了将这个评价能力迁移到电商客服的会话中。你可以想象一下,如果一个智能客服连基本的用户投诉都识别不了,肯定是不合格的。
这样的数据在数据集里还有很多,实际上,每条数据的设计都是有特定目的的。它们都是为了提高模型对整个电商业务的理解能力,你也可以理解为为整个电商专有模型提供电商能力,让它在回答客户问题的时候具有基础的电商客服能力,免得不专业。
要制作这样的基础数据集成本会很高,就像传统开发中开发一个底层框架总是成本更高一样。现在,我想你一定更能理解我说的这个观点了:大模型微调的核心不是编程开发,而制作数据集就相当于二次开发大模型的能力。
微调训练经验
不管是基础数据,专用数据还是公有数据集,都是为了在预训练模型上进行微调做准备。相比于数据工程,微调训练过程实际上需要工程师不断在数据,训练,评估,调整之间切换,大多数还是靠工程经验。我们先通过一张图回顾一下这个过程。
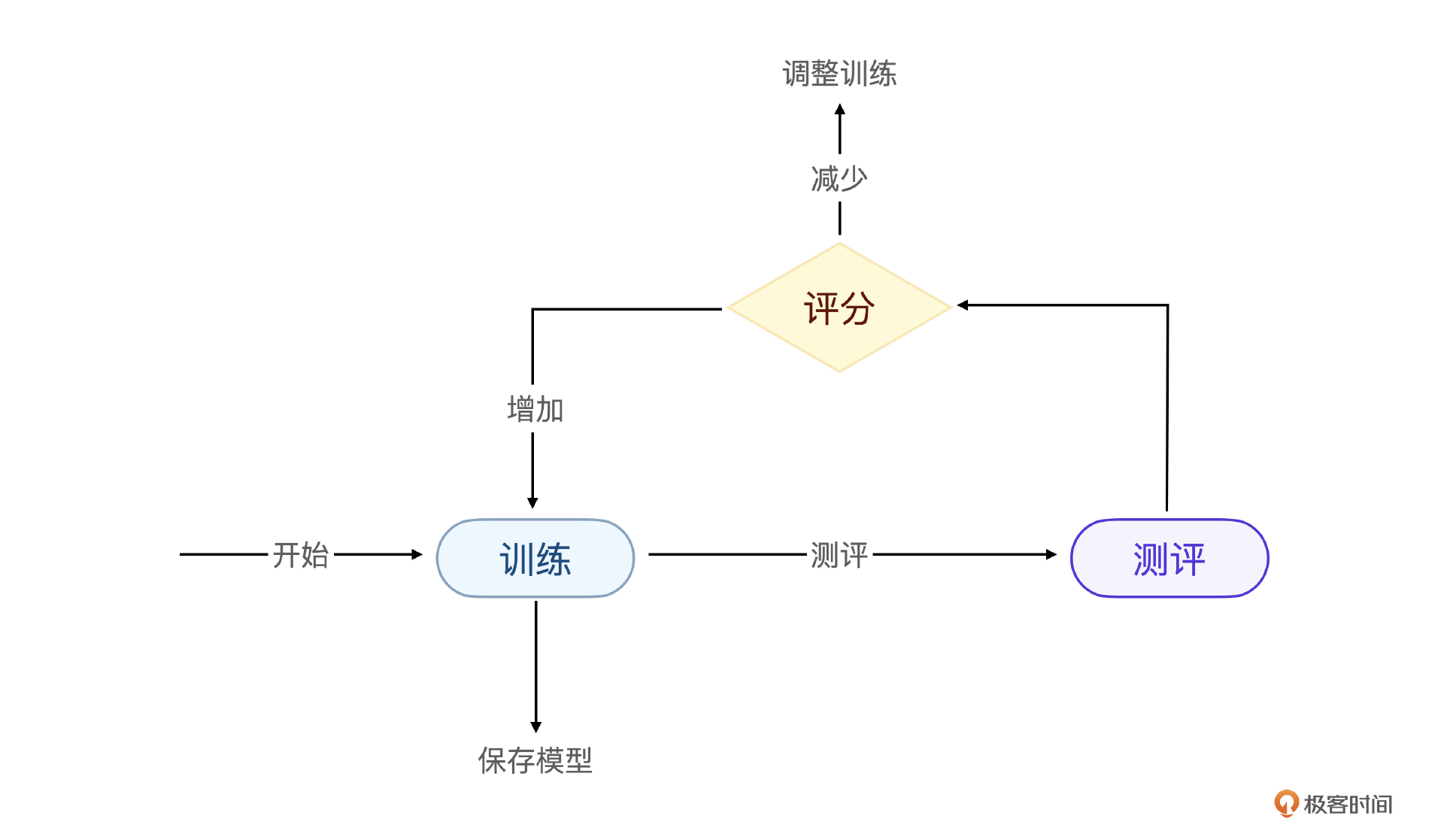
接下来我会再强调几个工程经验,注意,这些经验替代不了你的工程实战,一个可商用的微调模型至少都要经过上百次的微调过程。
先说一个重要的工程经验,在之前提到过模型评估的过程中,输出JSON解析的通过率可以作为一种重要的评估方式。
甚至,你可以把人工评估、通用数据集评分并列作为第三种评估方式,这就需要你在训练时综合考量。注意,这个指标纯粹是我们的工程经验,也再次说明了数据工程在微调过程中的重要性。
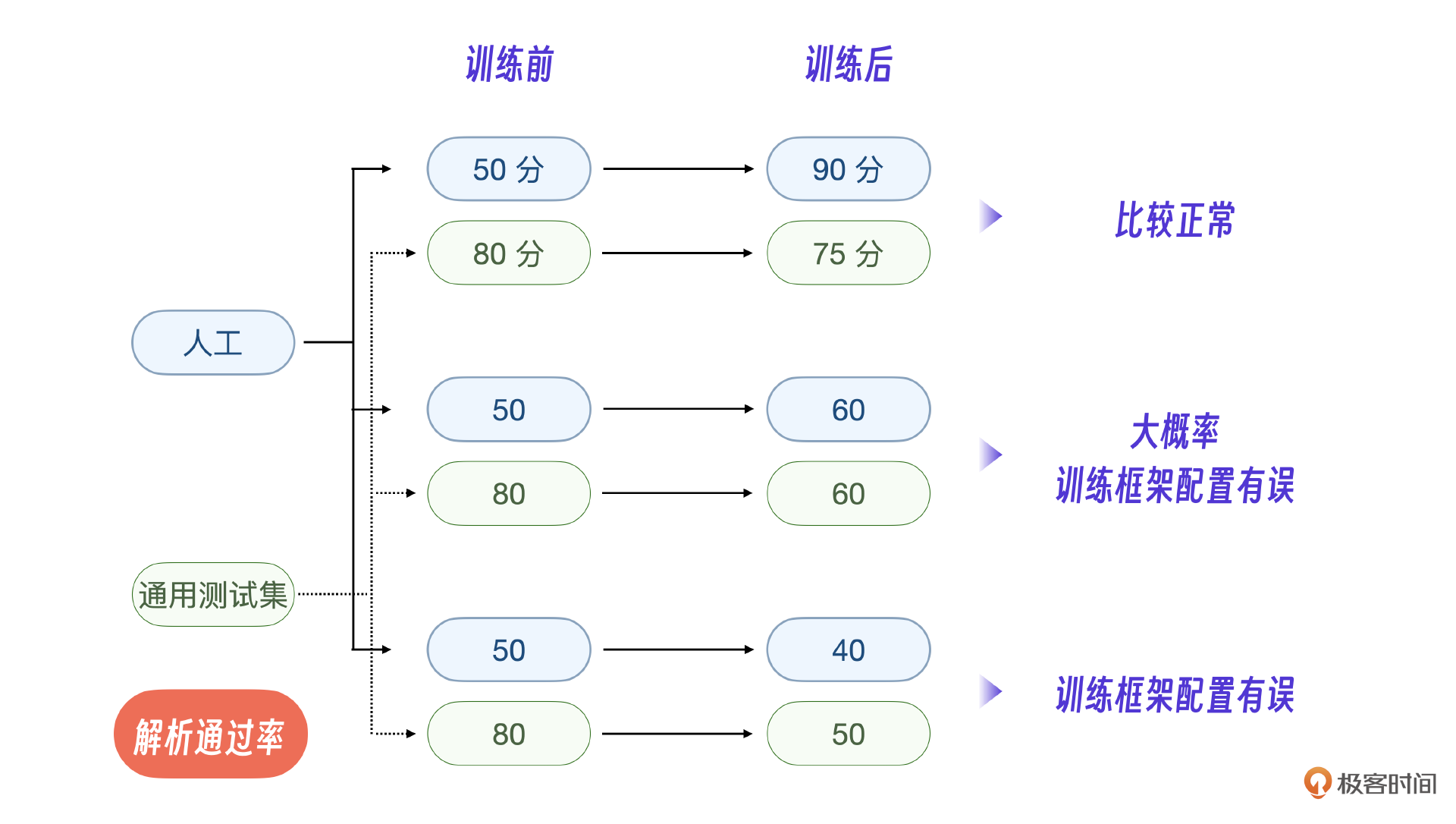
另外一个经验是通过专有数据集训练专用能力后,往往会遇到一些问题,我把这些问题和具体解法也一并总结供你参考。

优化开发经验
如果说上面的经验是专有模型开发过程中一些战略经验,那么下面关于数据的细节则是更多战术性的开发经验。
数据协议解析
我们多次提到大模型微调中的具体数据格式JSON、Markdown格式,在实现解析和生成JSON、Markdown格式的模块时,可以使用Python的内置库和第三方库来完成相应的任务。
解析和生成JSON格式,可以使用Python的内置 json 库。该库能够方便地将Python对象转换为JSON格式的字符串,或者将JSON字符串解析为Python对象。
import json
# 解析JSON字符串
json_str = '{"name": "John", "age": 30, "city": "New York"}'
data = json.loads(json_str)
print(data)
# 输出: {'name': 'John', 'age': 30, 'city': 'New York'}
# 生成JSON字符串
data_dict = {"name": "John", "age": 30, "city": "New York"}
json_output = json.dumps(data_dict, indent=4)
print(json_output)
# 输出格式化后的JSON:
# {
# "name": "John",
# "age": 30,
# "city": "New York"
# }
JSON格式数据要特别注意一些特殊字符,JSON字符串中如果包含特殊字符(如双引号、反斜杠),必须进行正确的转义。否则,解析JSON时会出现错误。比如下面例子中的引号字符。
import json
# 包含特殊字符的JSON字符串
json_str = '{"quote": "He said, \\"Hello, World!\\""}'
data = json.loads(json_str)
print(data)
# 输出: {'quote': 'He said, "Hello, World!"'}
对于Markdown格式,可以使用第三方库如 markdown 库或 mistune 库来解析和生成Markdown文本。
import markdown
import mistune
# 解析Markdown字符串为HTML
md_text = "# Hello World\nThis is a *Markdown* text."
html_output = markdown.markdown(md_text)
print(html_output)
# 输出: <h1>Hello World</h1><p>This is a <em>Markdown</em> text.</p>
# 使用Mistune生成Markdown
markdown_renderer = mistune.Markdown()
html_output_mistune = markdown_renderer(md_text)
print(html_output_mistune)
# 输出: <h1>Hello World</h1><p>This is a <em>Markdown</em> text.</p>
Markdown有不同的标准,在解析或生成Markdown时,应注意所使用库的标准是否符合需求。例如,某些库可能不支持特定的表格语法。
测试评估方面,要配合大模型输出做出通过率高的解析程序,更高的解析成功率代表更好的召回率。
持续优化数据
做过人工智能的朋友可能有这样的意识,一个模型上线后最重要的工作是不断提高模型的性能,也就是人工智能领域说的99.9%到99.99%的提升,在电商客服专有模型里,这意味这通过更新数据集或加入数据集持续优化模型。
举一个例子,在某个时间点而言,相对传统电商来说,仅退款这个概念是一个全新的概念,当这种行业规则发生变化时,都需要针对性的优化数据,重新微调模型,这正像我们针对一个客服培训新的行业知识。
下面是常见的数据更新时机。
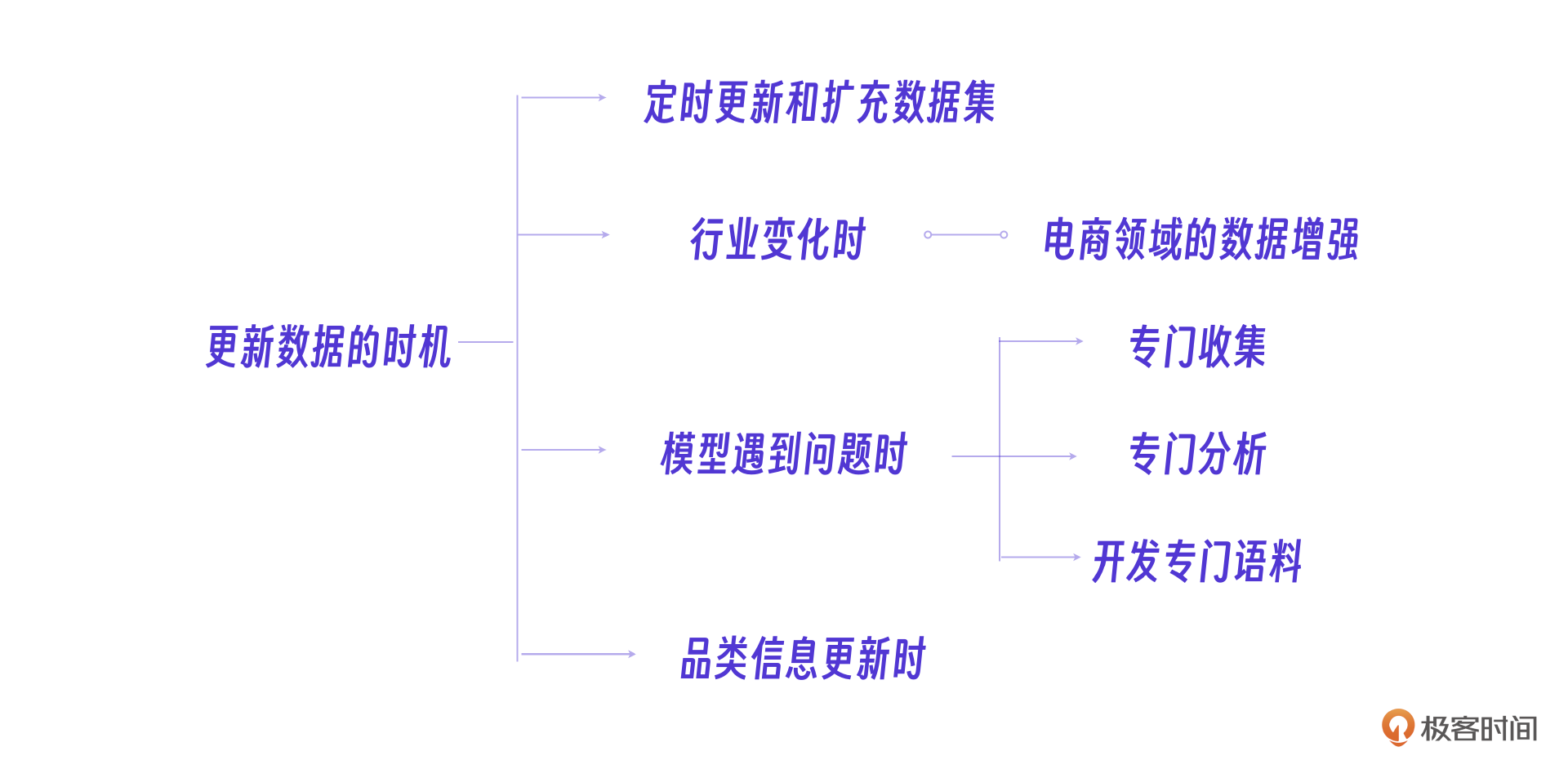
对于在业务过程中产生的,大语言模型无法进行正确结果生成的提问,需要专门收集起来,做专门的分析,针对性的开发语料,在后续的训练中加入。
意图识别的微调
下面这个关于微调的例子,也是一个在实际工程中跑出来的工程经验。之前的课程中提到意图识别的微调,但没有具体指出何时做意图识别的微调?
我们可以把意图识别想象成一个提示词的例子,在用户和智能客服的上下文基础上,让大模型根据会话总结出用户的意图,类似下面这样的训练数据例子。
请阅读下文,选出最接近的一个总结:
问:请问有没有让{性别}{功能}的产品?
答:有{A}{B}{C}{D}种。
问:{时间}上能不能送到{地点}?
答:{A}种可以{今晚}送到。
总结可能如下:
1、客户需要某种的产品。
2、介绍我们的品牌。
3、向客户传递健康知识。
4 ... ...
请给出最接近的一个选项,回复给我。
虽然我们这样想象,但实际上,例子里的具体分类数据,也就是:
这些具体的用户意图,实际上只要做好配置问题分类,根本不需要微调,基础的大模型就能识别的很好。在实际工程中,只有当这个问题分类非常大时,比如分类达到上百种,基础大模型意图识别才可能会出现偏差,这种情况下,才需要按这个数据格式专门做意图识别能力的微调。
小结
电商客服模型的开发目的是提升模型处理复杂问题的能力,尤其提升意图识别和数据提取的能力。当某些情况大模型表现不好的时候,就可以采用大模型微调了。
在实际工程中,即使是基础的数据提取能力也要用相应的格式数据微调,通过训练JSON格式的原子能力,模型能够准确地提取用户需求并将其转化为参数,进而传递给后续工作流。
数据工程在这一过程中至关重要,大模型通过少量的例子就能泛化出新的NLP能力。同时,具体数据格式的设计要参考大模型现有的NLP能力,这样才能在现有能力上进一步加强。
最后我想说,模型的微调并非单纯的代码开发,而是基于数据工程的持续优化。针对电商领域,需要用电商基础数据微调大模型的电商能力,领域数据更新优化和微调训练才是不断提升模型性能的关键。
思考题
当问题分类很多时可能要用到意图识别微调,那怎么设计微调数据呢?你可以思考一下,并做一做实验。
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- Aoinatsume 👍(1) 💬(0)
《Does Prompt Formatting Have Any Impact on LLM Performance?》(https://arxiv.org/html/2411.10541v1)这篇论文里有提到提示格式化方式会显著影响基于GPT的模型性能,例如,在GPT-4模型上使用Markdown的表现更好一些,而GPT-3.5-turbo模型中使用JSON进行翻译任务时性能会比其他提示格式高40%。老师您觉得以后不同的提示格式、不同的大模型和不同的任务类型进行适配会是一项常规工作吗,还是最终会统一出一种格式。
2024-11-28