你好,我是金伟。
上节课我们说到评估专家的案例和设计模式,这节课我们就用一个实际的例子来说明如何训练一个评估专家。我会带着你实现一个评估专家模型,用于评估数字孪生的数据质量。最后你会看到,这个过程可以用评估专家实现完全自动化。
当然,就像做大模型微调训练一样,要得到一个符合客户需求的大模型不是一件容易的事,在评估专家模型下也是一样的,要实现超过人类的评估水平会面临很多挑战。
评估专家的难点
要实现评估专家,核心的问题还是要提前人工标注数据,人工标注的数据质量好坏直接决定了结果的好坏。可以说,偏好数据质量是奖励模型学习的首要挑战。
偏好数据的来源和标注标准往往不一致,不同标注者可能对同一个问题的偏好有不同理解,导致偏好数据中存在噪声。例如,某些数据可能包含两个相近但质量不同的回复,在对这些回复进行标注时,标注者之间的意见分歧较大。这使得奖励模型在学习过程中难以对数据作出统一的判断。此外,偏好数据的标签也并不总是可靠,在某些情况下,经过训练的奖励模型反而对某些标注产生了负反馈。为了解决数据噪声问题,可以采取标签翻转、损失函数平滑处理以及数据区分度调整等方法来提高数据质量。
数据质量是第一个难点,另外一个难点则是奖励函数的泛化程度。
泛化能力是指奖励模型能否有效地处理训练数据之外的情况。然而,很多奖励函数在不同任务之间的泛化能力较差。为了提升泛化能力,可以通过对比学习的方式来优化奖励函数。通过对比学习,奖励函数能够更好地区分不同回复之间的细微差别,从而提升其泛化能力。此外,还可以通过改进训练过程中的梯度更新策略,确保奖励函数在给定的分布下能够有效区分不同的回复。这不仅能够提升奖励模型在当前任务中的表现,也能提升其在新任务中的适应性。
总之,奖励模型的难点主要集中在如何提升偏好数据的质量以及奖励函数的泛化能力,只有解决这两个核心问题,才能确保大模型能够更好地对齐人类偏好,并在不同的任务中具有广泛的适应性。
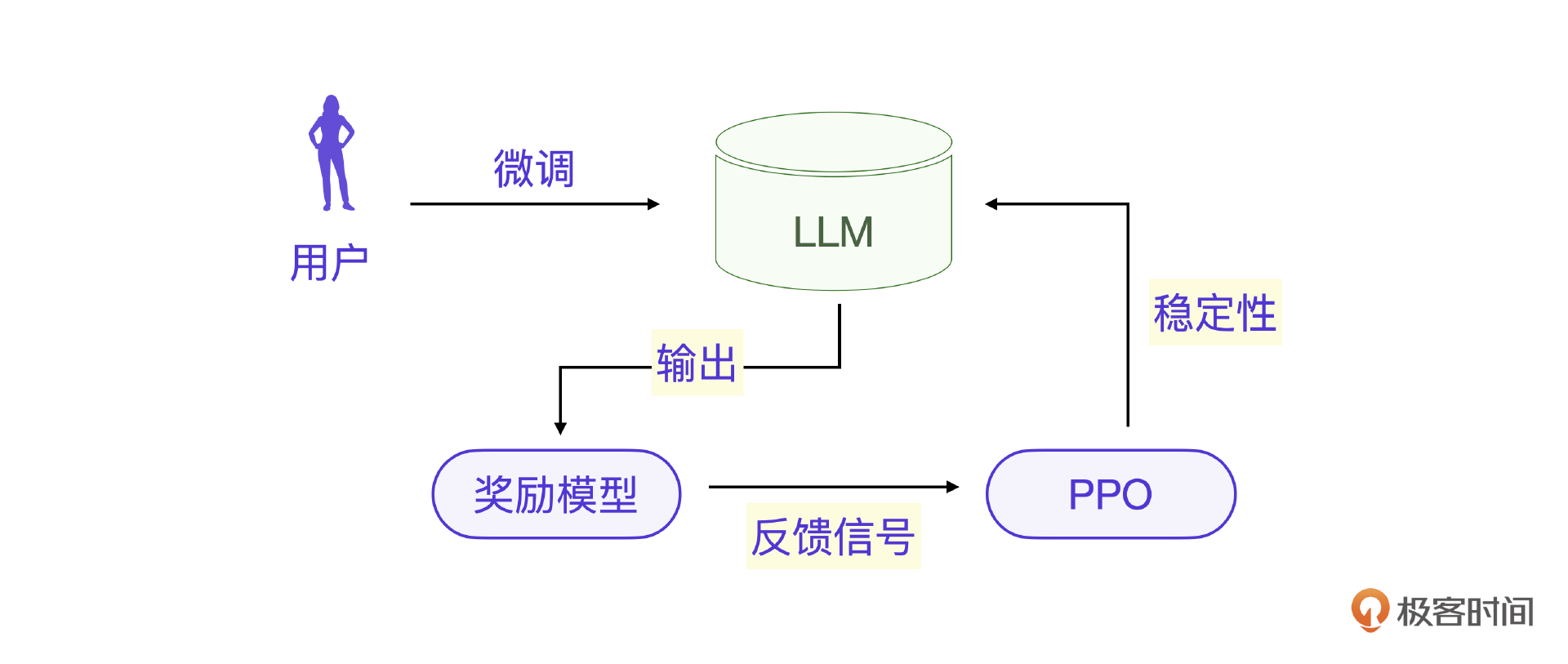
奖励模型在强化学习中扮演着重要角色,尤其是在RLHF(人类反馈强化学习)中,它用于帮助大模型更好地对齐人类的偏好和价值观。
然而,如果你要做类似ChatGPT里的RLHF学习过程,则问题会更加复杂,实际上不是单个奖励模型的问题,而是要结合PPO算法才能保证模型的稳定性。
 总结一下:
总结一下:
- 奖励模型负责对大语言模型的输出打分,提供反馈信号。
- PPO 通过这些反馈信号稳定地优化模型策略,确保训练过程平稳有效。
ChatGPT内部实现我们无法获得,下面是一个开源的RLHF的实现流程图,可以更好地说明这个过程。其中图1是一个基于奖励模型的PPO流程。图2是更详细的PPO策略和流程图。

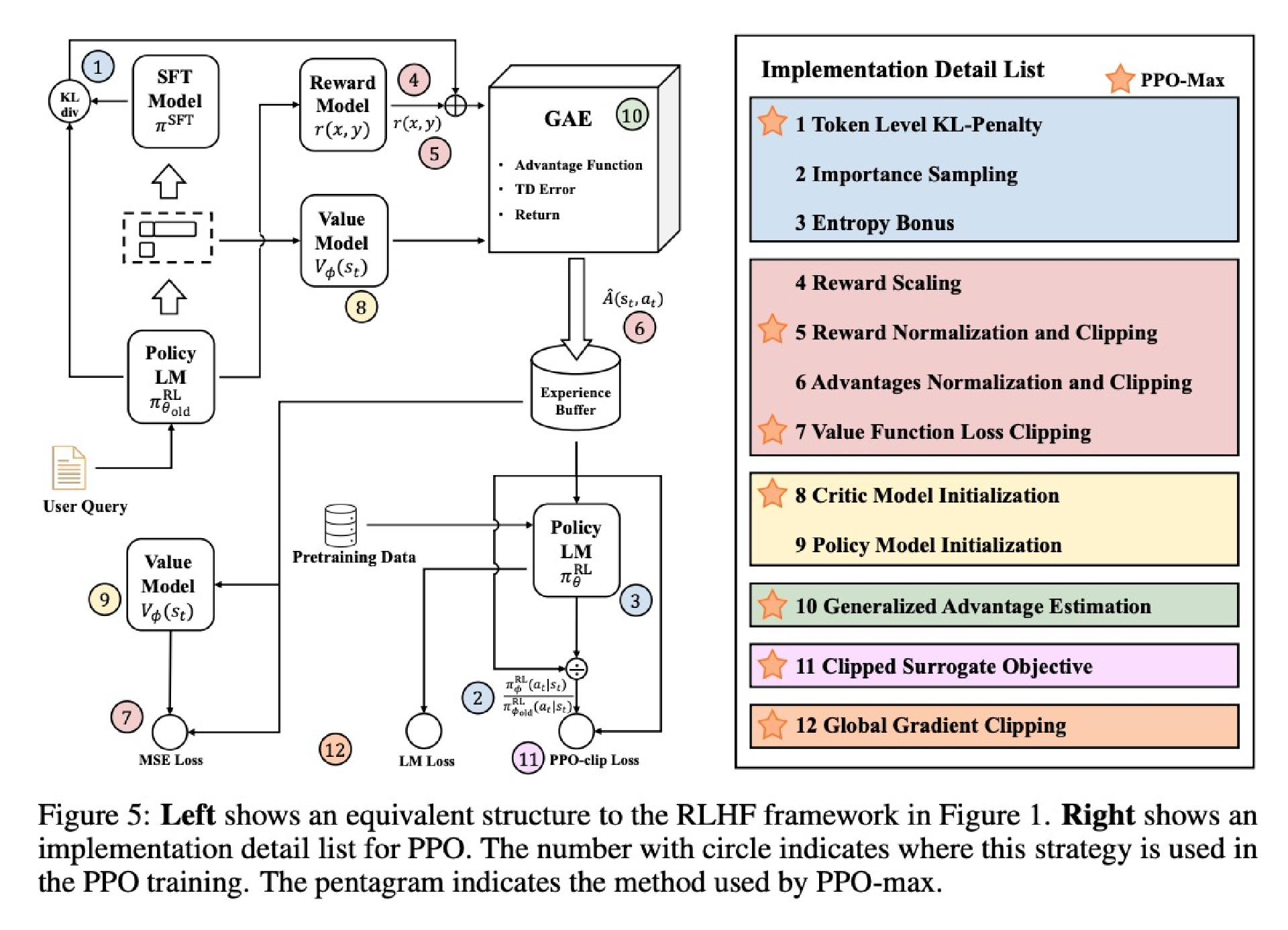
实际上,上述提到的偏好数据质量,奖励函数的泛化和开源的PPO算法流程,都是我从多篇相关的研究论文中整理总结的信息,如果要基于论文从头实现一个评估专家显然不现实,在实际工程中我们往往直接使用已经开源的训练方法,这些理论只是作为参考即可。
评估专家的实现
我们考虑数字孪生的数据质量这个常见问题,其实用开源的专家模型训练器就足够了。现在我们就用一个开源的评估专家训练器 trl 为例,你也可以完全应用到实战中。
训练奖励模型
TRL 支持用户在其数据集和模型上进行定制的奖励建模,允许对奖励模型进行个性化训练和优化。其底层核心是两个类,RewardTrainer 和 RewardConfig。
在准备好数据集后,你可以像使用Transformers 的 Trainer 类一样使用 RewardTrainer。你需要将一个 AutoModelForSequenceClassification 模型传递给 RewardTrainer,同时还需要提供 RewardConfig,用于配置训练的超参数。
下面是一个模型训练的伪代码。
from peft import LoraConfig, TaskType
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer, RewardConfig
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)
...
trainer = RewardTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()
RewardConfig 用来做参数配置。
训练一个奖励模型也需要做loss评估,你可以通过向数据集添加一个“margin”列来将边际添加到损失函数中。奖励处理器将会自动传递该列,并根据传递的列计算损失。
def add_margin(row):
# Assume you have a score_chosen and score_rejected columns that you want to use to compute the marginreturn {'margin': row['score_chosen'] - row['score_rejected']}
return {'margin': row['score_chosen'] - row['score_rejected']}
dataset = dataset.map(add_margin)
具体来说,模型会对两个候选的输出进行打分,一个对应“优选”(score_chosen),另一个对应“拒绝”(score_rejected)。通过比较这两个分值的差异,模型能够模拟人类的偏好,从而进行训练和优化。模型的目标是通过这种分值差异,使自己的预测与标注数据中的偏好更为一致,从而降低损失函数。
比模型训练程序更重要的是数据集的准备工作。
数据集格式
上节课我们说到数据质量的评估可以用KTO的数据集格式,这种二值化处理使其特别适合需要明确正确或错误判断的任务,而不是基于主观偏好的评分。
我先举一个错误数据的例子,你可以看一下。
一开始我们是人工判断数字孪生的数据集,把错误的挑出来,留下正常的数据。当我们考虑用KTO来训练评估模型的时候,则需要把常见的错误数据标注出来,这样才能让评估模型学习到数据出错的特点。
如果你使用 KTO 来做数据集,尤其是用于数字孪生系统的数据质量判断,数据集应包含符合或不符合质量标准的数据项,并标注为 Chosen 或 Rejected。在地址信息的场景下,你可以按照以下格式构建数据集:
[{"address": "北京市海淀区学院路29号", "chosen": true}]
[{"address": "北京市1234海淀区学院路", "rejected": true}]
[{"address": "上海市静安区南京西路1000号", "chosen": true}]
[{"address": "广州市天河区#?@!路", "rejected": true}]
- Chosen:表示数据符合预期标准,例如格式正确、内容完整。
- Rejected:表示数据不符合标准,比如存在逻辑错误、格式不规范等问题。
很显然,KTO的数据集格式就是正确/错误二值化的分类。当然,如果用 trl 框架做评估模型训练的话,还需要进一步处理为 trl 的数据集格式。
数据集构建
实战中,我们的数据集要转为TRL支持格式就行了。
一个典型的TRL数据集是 trl-lib/ultrafeedback_binarized,我这里拿出一条数据的Json格式,你可以先自己分析一下,我再详细地分析一遍。
{
"chosen": [
{
"content": "As an HR manager, you want to test a potential employee's ability...",
"role": "user"
},
{
"content": "Here's an extended list of questions ...",
"role": "assistant"
}
],
"rejected": [
{
"content": "As an HR manager, you want to test a potential employee's ability...",
"role": "user"
},
{
"content": "Here is a Python script that you can use to generate ...",
"role": "assistant"
}
],
"score_chosen": 8.5,
"score_rejected": 4
}
这是数据集里一条数据的格式,ultrafeedback_binarized 也是通过 chosen 和 rejected 对数据进行分类的,实际上 ultrafeedback_binarized 数据集是一个完整的奖励模型训练数据集,你完全可以基于这个数据集训练大模型RLHF阶段的奖励模型。
在 ultrafeedback_binarized 数据集里有上百万条已经标注好的数据,你可能会想,RLHF的奖励模型不是要对输出做排序吗?类似B>A>C>D,现在怎么只有 chosen 和 rejected 呢?
实际上,数据集完全可以做到排序。
注意看上述的数据中,chosen 和 rejected 只表示某个问题的回答倾向性。当 role 为 user 时,chosen 和 rejected 数据的 content 字段内容是完全一样的,当 role 为 assistant 时 content 才不一样。这其实代表了同一个问题不同输出的倾向性选择。
具体的倾向性大小通过score_chosen 和 score_rejected 的大小来表示,通过多条数据的倾向性数据,就能做到排序。
要实现数字孪生的数据质量对错判断,还是要借鉴上述数据集格式,那具体怎么做呢?
肯定不是排序,你可以先想一想,我把一条数据的案例先放在下面。
{
"chosen": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:100102,联系电话:13812345678",
"role": "user"
},
{
"content": "正确",
"role": "assistant"
}
],
"rejected": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:100102,联系电话:13812345678",
"role": "user"
},
{
"content": "错误",
"role": "assistant"
}
],
"score_chosen": 1,
"score_rejected": 0
}
首先需要沿用数据集里的倾向性格式。chosen的数据表示我们选择的,rejected的数据表示我们排斥的。和标准数据集一样,第一个content字段要保持一致,只不过这里我们直接写的是数字孪生的一条数据,不需要问答。当然,为了和标准数据集一致,仍然要填写assistant的content字段。
最后一定要注意,我们的任务是做二值分类,因此score_chosen一定是1,而score_rejected一定是0,不做倾向性也不做排序。
在这种情况下,输入的是地址信息,奖励模型将对多个候选地址进行评分和选择,帮助判断哪个地址更符合标准。构建完数据集就可以直接训练评估模型了。注意要在实战中采用TRL已经封装好的训练脚本,而不是自己编写程序。
模型训练示例
之前提到要自己训练一个评估专家模型可以用开源的TRL库,在TRL库基础上开发一个用于训练模型的程序即可,但在实战中,则可以直接利用TRL提供的训练程序 reward_modeling.py 。
reward_modeling.py 是一个完整的训练脚本,下面分别是利用这个脚本做全量训练和Lora训练的两个例子。
这个脚本最主要的参数有两个,一个是 Qwen/Qwen2-0.5B-Instruct 表示用于训练评估专家模型的基模型,trl-lib/ultrafeedback_binarized表示用于训练评估专家的数据集。
TRL 提供一个完整的训练脚本 reward_modeling.py。提供全量训练和Lora训练两种模式。
Full training:
python examples/scripts/reward_modeling.py \
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
--dataset_name trl-lib/ultrafeedback_binarized \
--output_dir Qwen2-0.5B-Reward \
--per_device_train_batch_size 8 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--remove_unused_columns False \
--gradient_checkpointing True \
--learning_rate 1.0e-5 \
--logging_steps 25 \
--eval_strategy steps \
--eval_steps 50 \
--max_length 2048
LoRA:
python examples/scripts/reward_modeling.py \
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
--dataset_name trl-lib/ultrafeedback_binarized \
--output_dir Qwen2-0.5B-Reward \
--per_device_train_batch_size 8 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--remove_unused_columns False \
--gradient_checkpointing True \
--learning_rate 1.0e-5 \
--logging_steps 25 \
--eval_strategy steps \
--eval_steps 50 \
--max_length 2048 /
--use_peft \
--lora_r 32 \
--lora_alpha 16
这个模型训练脚本实际上就是用 ultrafeedback_binarized 数据集训练一个奖励模型。其实就是运行 reward_modeling.py 这个脚本,这个脚本的主程序逻辑在之前的小节已经提到过,这里再说明一下它最核心的数据转换逻辑。
也就是下面这个 preprocess_function 函数。
def preprocess_function(examples):
new_examples = {
"input_ids_chosen": [],
"attention_mask_chosen": [],
"input_ids_rejected": [],
"attention_mask_rejected": [],
}
for chosen, rejected in zip(examples["chosen"], examples["rejected"]):
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])
new_examples["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])
new_examples["input_ids_rejected"].append(tokenized_rejected["input_ids"])
new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])
return new_examples
这里的 examples 就是我们输入的数据集数据,在内部被转换为 new_examples,需要用四个字段表示chosen和rejected数据,因为这两个数据分别需要做token转化和掩码转化。
这个脚本执行看起来很简单,但是工程实战中还是有不少细节需要注意。
第一个细节是数据集格式问题。标准的 ultrafeedback_binarized 数据集其实是 .parquet 格式的,包含两个文件 train-00000-of-00001.parquet 和 test-00000-of-00001.parquet。
.parquet 格式无法直接查看,我们自己的数字孪生数据质量检测的数据集最好使用Json格式。这里可以先写一个Python脚本把 .parquet 格式转为Json格式,方便我们分析和制作后续的Json数据集。
import pandas as pd
# 读取 Parquet 文件
df = pd.read_parquet('test-00000-of-00001.parquet')
# 转换为 JSON 格式
df.to_json('output.json', orient='records', lines=True)
实际上Json格式就是上一小节提到的Json, 不过上一节是单条数据,我这里再把多条数据的情况展示一下。
{
"chosen": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:100102,联系电话:13812345678",
"role": "user"
},
{
"content": "正确",
"role": "assistant"
}
],
"rejected": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:100102,联系电话:13812345678",
"role": "user"
},
{
"content": "错误",
"role": "assistant"
}
],
"score_chosen": 1,
"score_rejected": 0
}
{
"chosen": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:10010222,联系电话:13812345678",
"role": "user"
},
{
"content": "错误",
"role": "assistant"
}
],
"rejected": [
{
"content": "张三,北京市朝阳区望京街道123号院5号楼,邮编:10010222,联系电话:13812345678",
"role": "user"
},
{
"content": "正确",
"role": "assistant"
}
],
"score_chosen": 1,
"score_rejected": 0
}
有两点特别注意,一是多条数据的Json之间是没有逗号的,直接连接到一起即可,你注意看第24-25行;第二这个数据展示了当信息错误的时候怎么标注数据,注意是将错误的数据放到 chosen 字段里,最后的score还是保持1和0。
完成数据集构建后,你可以通过奖励模型训练脚本进行训练。
运行时要将数据集 trl-lib/ultrafeedback_binarized 替换为我们整理好的数据集。现在需要注意第二个细节,如果这个脚本运行过程中由于网络原因无法自动下载 Qwen/Qwen2-0.5B-Instruct 这个基模型,则需要手动下载 Qwen/Qwen2-0.5B-Instruct 模型文件并按这个目录结构放置,脚本就可以直接读取本地模型。
python examples/scripts/reward_modeling.py \
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
--dataset_name path_to_your_dataset.json \
--output_dir Qwen2-0.5B-Reward \
--per_device_train_batch_size 8 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--remove_unused_columns False \
--gradient_checkpointing True \
--learning_rate 1.0e-5 \
--logging_steps 25 \
--eval_strategy steps \
--eval_steps 50 \
--max_length 2048
如果看到下面的训练进度,就说明一切顺利,已经开始训练了,1000条数据之内训练的时间都很短。
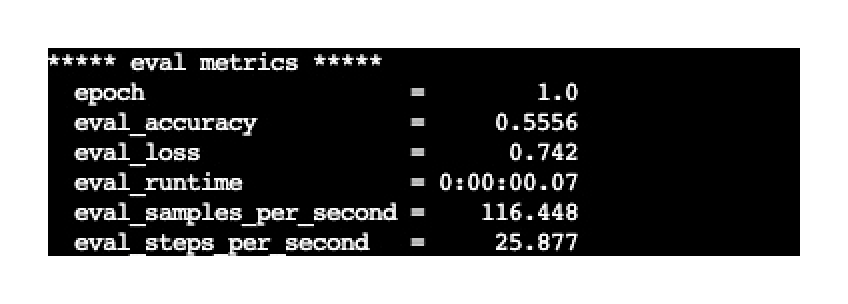
最终训练完成会给出结果数据,这个结果实际上是拿test数据集来做的评估,重点关注 eval_acc 字段的结果,表示预测的准确率。
 训练过程实际上没有太多难度,不过工程上可能会出现结果不理想的情况,这就是我想说的第三个细节,还是跟数据集有关系。我这里提供一个数据集的案例,你可以思考一下,这个数据集最终的预测结果会如何?
训练过程实际上没有太多难度,不过工程上可能会出现结果不理想的情况,这就是我想说的第三个细节,还是跟数据集有关系。我这里提供一个数据集的案例,你可以思考一下,这个数据集最终的预测结果会如何?
{
"chosen": [
{
"content": "联系电话:a",
"role": "user"
},
{
"content": "错误",
"role": "assistant"
}
],
"rejected": [
{
"content": "联系电话:a",
"role": "user"
},
{
"content": "正确",
"role": "assistant"
}
],
"score_chosen": 1,
"score_rejected": 0
}
{
"chosen": [
{
"content": "联系电话:1",
"role": "user"
},
{
"content": "正确",
"role": "assistant"
}
],
"rejected": [
{
"content": "联系电话:1",
"role": "user"
},
{
"content": "错误",
"role": "assistant"
}
],
"score_chosen": 1,
"score_rejected": 0
}
... ... 重复以上数据10000条
注意这个数据集非常简单,一共就两种情况的数据,重复放了10000条,训练之后,是不是当内容为 联系电话:1 时应该输出 正确,内容为 联系电话:a 时输出错误呢? 实际运行结果却不是我们想的这样,你可以自己训练一次试一试。
评估专家的应用
刚才的训练过程就是微调训练一个大模型。那训练完成后怎么应用这个模型呢?
在数字孪生的数据质量检查中,可以用这个模型直接过滤数据,得到高质量的数据分类。
现在我们把这个训练好的评估专家模型应用到数据质量管理中。
实际上就是写一个程序,调用具备评估能力的大模型。应用其中的Reward Modeling,可以快速对数据进行分类。
要实现全自动的数据评估,则需要写一个Python程序,调用刚才的评估模型,对数据做出分类。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
# 加载训练好的奖励模型和分词器
model = AutoModelForSequenceClassification.from_pretrained('/root/autodl-tmp/Qwen2-0.5B-Reward')
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/Qwen2-0.5B-Reward')
# 模型评估时需要设备支持,使用 GPU 优先
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 新的数据
new_input = {
"chosen": [
{"content": "联系电话:ddee", "role": "user"},
{"content": "正确", "role": "assistant"}
],
"rejected": [
{"content": "联系电话:ddee", "role": "user"},
{"content": "错误", "role": "assistant"}
]
}
# 将 'chosen' 和 'rejected' 数据分别编码
chosen_text = " ".join([item["content"] for item in new_input["chosen"]])
print(chosen_text)
rejected_text = " ".join([item["content"] for item in new_input["rejected"]])
print(rejected_text)
# 将输入编码为模型的格式
inputs_chosen = tokenizer(chosen_text, return_tensors="pt").to(device)
inputs_rejected = tokenizer(rejected_text, return_tensors="pt").to(device)
with torch.no_grad():
score_chosen = model(**inputs_chosen).logits
score_rejected = model(**inputs_rejected).logits
# # 打印分数
print("Chosen score:", score_chosen.item())
print("Rejected score:", score_rejected.item())
import torch.nn.functional as F
import torch
# 将两个 logits 放入一个张量
logits = torch.tensor([score_chosen.item(), score_rejected.item()])
# 应用 softmax,将 logits 转换为概率分布
probabilities = F.softmax(logits, dim=0)
# 输出 chosen 和 rejected 的概率
print("Chosen probability:", probabilities[0].item())
print("Rejected probability:", probabilities[1].item())
这个预测程序的核心思想是对同一条数据分别做chosen 和 rejected两个预测,看哪个概率大,如果chosen概率大则表示数据正确,如果rejected概率大,则表示错误。我用一个实际运行的截图来说明。

注意看数据结果里的 Rejected probability 大于 Chosen probability,可以理解为这条数据是错误的数据的概率更大,当然具体判断还需要设定阈值,这样就可以分拣这些数据的质量了。
别忘了最后一步,还是要对分类结果进行人工验核,反复训练可以得出更好的奖励模型。
小结
一个完整的RLHF训练包含3个步骤,分别是数据预训练,奖励模型训练,大模型的PPO稳定性调整,这是大模型领域难度最高的一个过程了。当然,从工程实践上,我们不会从头开始实现整个过程,因为已经有很好的开源项目实现了这个过程。
如果要自己训练一个评估专家模型,我们可以基于TRL项目的开源训练脚本就可以完成,其核心还是整理数据集,这里需要注意TRL标准的数据集分为chosen和rejected两个部分,但是每条数据还可以打分,这样就能实现一个完整的具有排序能力的评估专家模型了。
在数字孪生的数据质量检测中,我们也要将数据集整理成标准的格式,需要注意两点,第一点是assistant的回复用正确,错误字样来表示二值分类,第二点,具体的score分数填为1和0。训练数据集要保持一定的多样性,否则容易导致准确率不足。
思考题
在我们的数字孪生数据质量判断的数据集中,用于标注数据的“正确/错误”字样可以换成1/0吗?为什么?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 石云升 👍(0) 💬(1)
直观感觉是可以换成1/0的,这样机器处理起来应该效率更快。
2024-09-23