07 AIGC的核心魔法:搞懂Transformer
你好,我是南柯。
前两讲中,我们已经学习了扩散模型的加噪去噪过程,了解了UNet模型用于预测噪声的算法原理。事实上,Stable Diffusion模型在原始的UNet模型中加入了Transformer结构(至于怎么引入的,我们等下一讲学完UNet结构便会清楚),这么做可谓一举两得,因为Transformer结构不但能提升噪声去除效果,还是实现prompt控制图像内容的关键技术。
更重要的是,Transformer结构也是GPT系列工作的核心模块之一。也就是说,我们只有真正理解了Transformer,才算是进入了当下AIGC世界的大门。这一讲,我就为你揭秘Tranformer的算法原理。
初识Transformer
在深度学习中,有很多需要处理时序数据的任务,比如语音识别、文本理解、机器翻译、音乐生成等。不过,经典的卷积神经网络,也就是CNN结构,主要擅长处理空间相关的任务,比如图像分类、目标检测等。
因此,RNN(循环神经网络)、LSTM(长短时记忆网络)以及 Transformers 这些解决时序任务的方案便应运而生。
RNN和LSTM解决序列问题
RNN专为处理序列数据而设计,可以灵活地处理不同长度的数据。RNN的主要特点是在处理序列数据时,对前面的信息会产生某种“记忆”,通过这种记忆效果,RNN可以捕捉序列中的时间依赖关系。这种“记忆”在RNN中被称为隐藏状态(hidden state)。
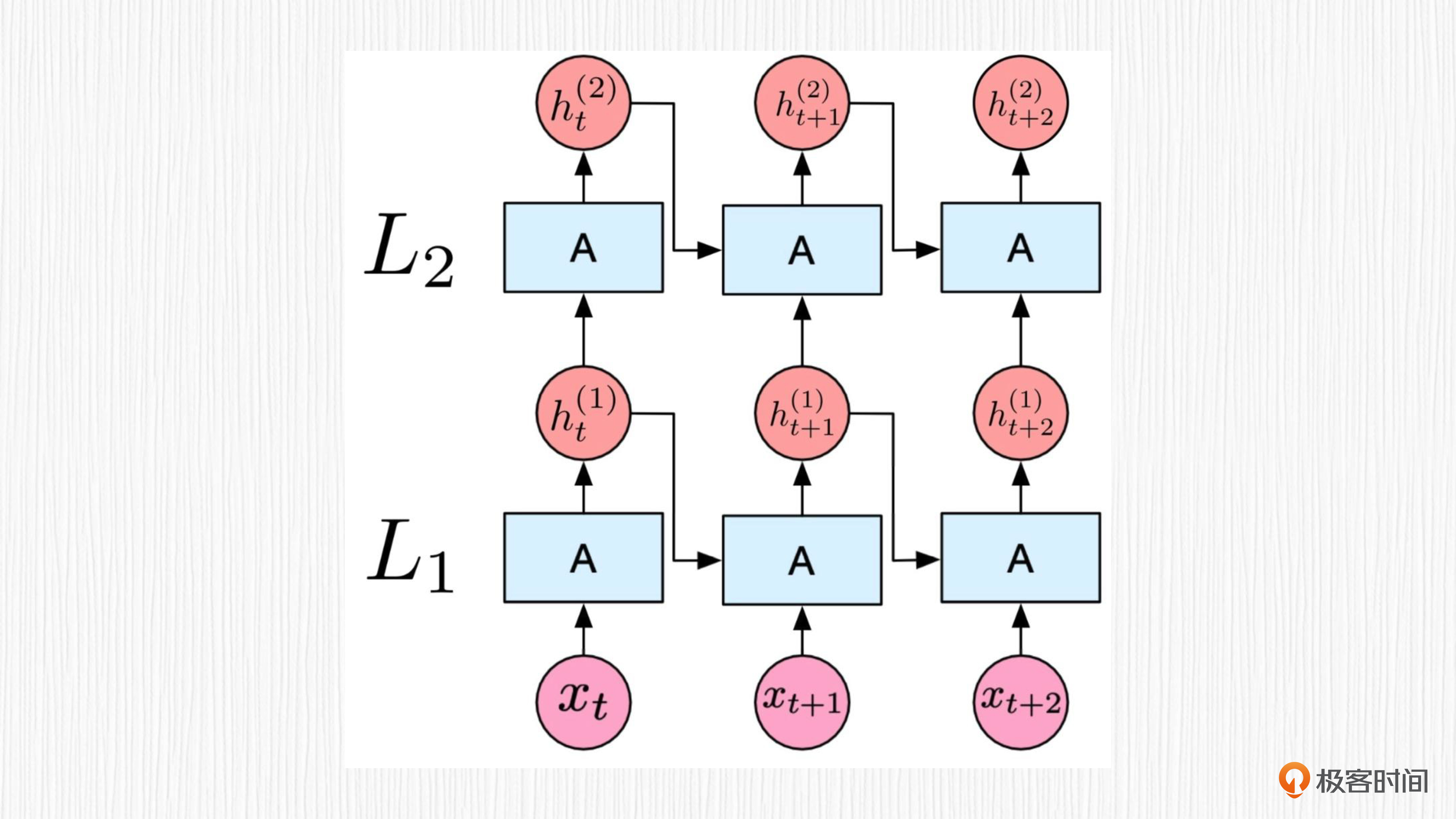
然而,传统的RNN存在一个关键的问题,即“长时依赖问题”——当序列很长时,RNN在处理过程中会出现梯度消失(梯度趋近于0)或梯度爆炸(梯度趋近于无穷大)现象。这种情况下,RNN可能无法有效地捕捉长距离的时间依赖信息。
为了解决这个问题, LSTM这种特殊的RNN结构就派上用场了。LSTM通过加入遗忘门、记忆门和输出门来处理长时依赖问题。这些门有助于LSTM更有效地保留和更新序列中的长距离信息。

以LSTM为代表的RNN类方案虽然在许多时序任务中取得了良好的效果,但是也有它的局限,主要是三个方面。
第一,并行计算问题。由于LSTM需要递归地处理序列数据,所以在计算过程中无法充分利用并行计算资源,处理长序列数据时效率较低。
第二,长时依赖问题。虽然LSTM有效地改善了传统RNN中的长时依赖问题,但在处理特别长的序列时,仍然可能出现依赖关系捕捉不足的问题。
第三,复杂性高。LSTM相比简单的RNN结构更复杂,增加了网络参数和计算量,这在一定程度上影响了训练速度和模型性能。
Transformer的整体方案
在2017年由Google提出的Transformer,是一种基于自注意力机制(self-attention)的模型,它有效解决了RNN类方法的并行计算和长时依赖两大痛点。
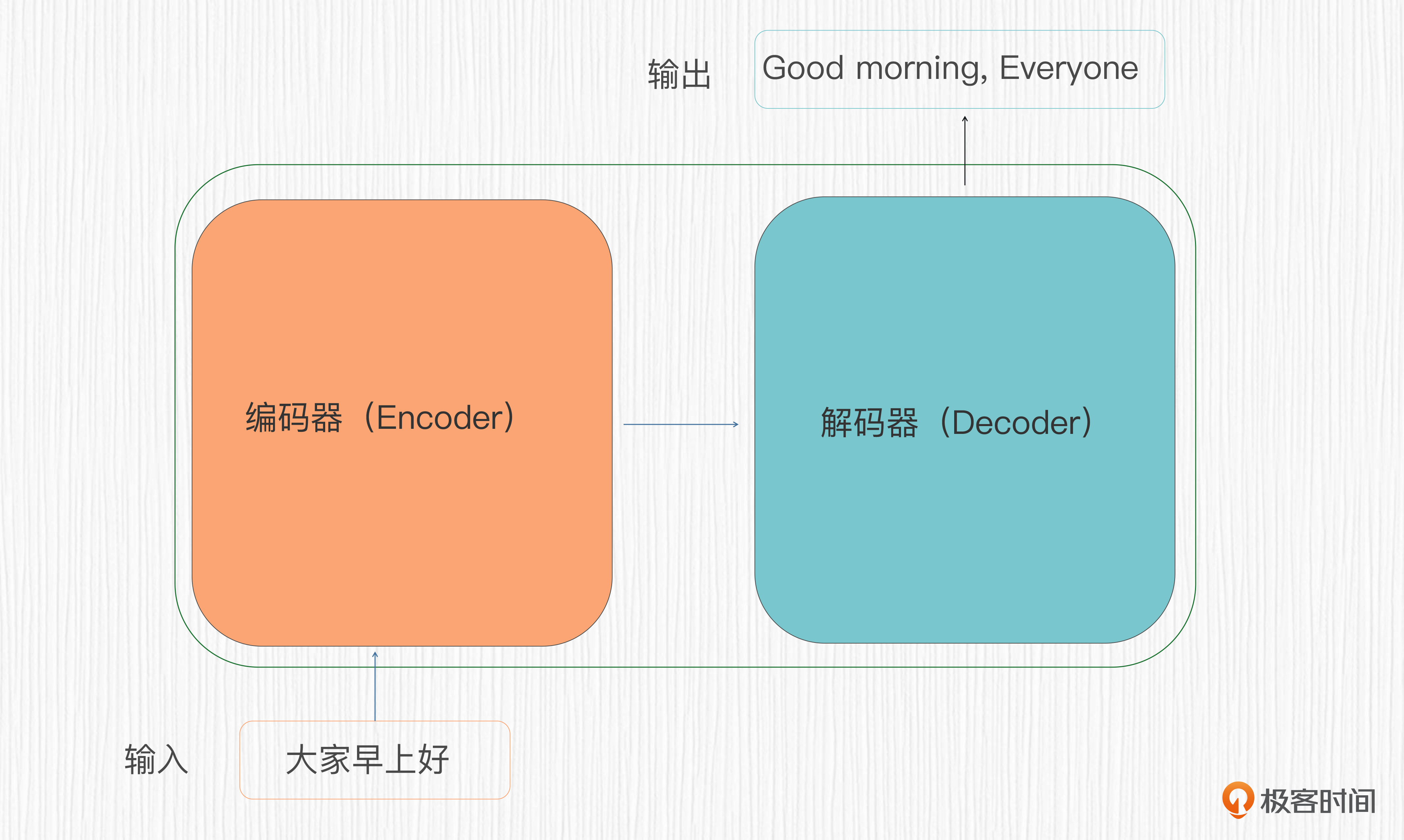
Transformer结构包括编码器(Encoder)和解码器(Decoder)两个部分,通过这两个部分完成对输入序列的表示学习和输出序列的生成。
编码器负责处理输入序列。它会根据全局上下文,提取输入数据中的有用信息,并学习输入序列的有效表示。
解码器则会根据编码器输出的表示,生成目标输出序列。它会关注并利用输入序列的表示以及当前位置的上下文信息,生成输出序列中每个元素的预测。
如果将编码器、解码器当作黑盒,Transformer可以看作是下图的样子。
实际上,编码器和解码器分别由6层相同的结构堆叠而成,就像下面这幅图所展示的这样。
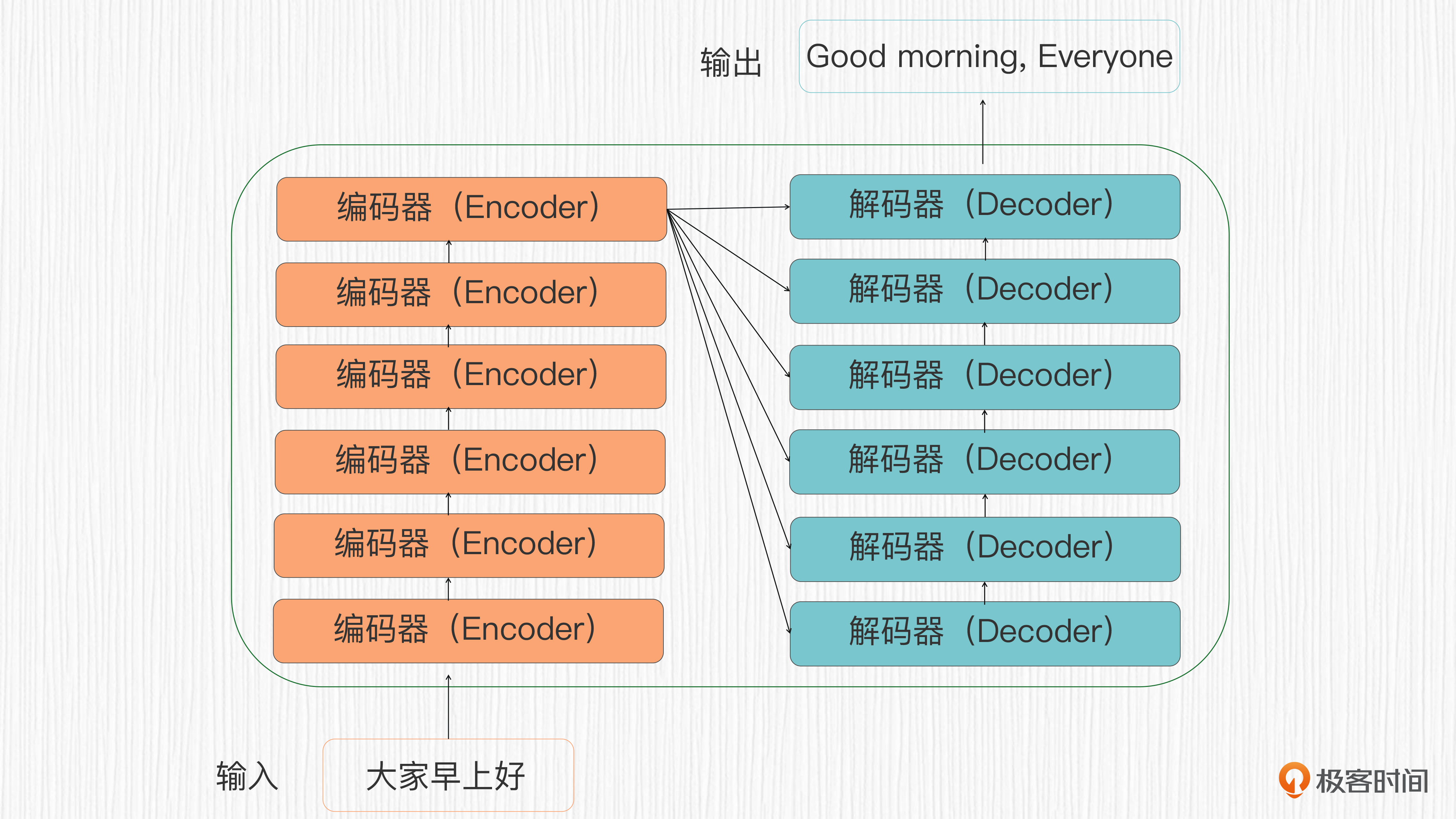
论文中也给出了Transformer的整体架构,我放在文稿中。这个图左侧对应编码器结构,右侧对应解码器结构,图中的N论文中设置为6,也就是上面图中我们展示的样子。总之,编码器负责对输入序列进行抽象表示,解码器根据这些表示构建合适的输出序列。

Attention细节探究
Transformer是当下公认的处理时序任务的最强模型,最初提出是为了解决自然语言处理领域的问题,比如机器翻译等任务。最近几年,Transformer广泛应用在语音领域、计算机视觉领域等,表现不俗。特别是当下的AI绘画模型和GPT模型,也都依赖了Transformer模块。
在Transformer结构中,最关键的便是注意力模块。事实上,AI绘画中也是复用了注意力机制来实现prompt对图像内容的控制。所以我们重点来拆解Transformer中的注意力模块。
序列、Token和词嵌入
正式学习注意力模块前,我们要先掌握4个关键的概念,这些概念共同构成了Transformer模型的基本组成部分。
首先是源序列。源序列是输入的文本序列。例如在机器翻译任务中,源序列就是待翻译的文本。
其次是目标序列。目标序列是输出的文本序列,例如在机器翻译任务中,目标序列代表翻译后的文本,通常为目标语言。
之后是Token(词符)。Token是文本序列中的最小单位,可以是单词、字符等形式。文本可以拆分为一系列tokens。举个例子,文本 Hello world 经过特殊的分词,可以被分为以下tokens:[“Hello”, " world"]。Token的词汇表中包含了所有可能情况,每个token预先被分配了唯一的数字ID,称为token ID。
最后是词嵌入(Word Embedding)。词嵌入的目标是把每个token转换为固定长度的向量表示,这些向量可以根据token ID在预训练好的词嵌入库(例如Word2Vec等)中拿到。在Transformer中,编码器和解码器的输入的都是序列经过token化之后得到的词嵌入。
Self-Attention模块
你可能听过许多不同类型的注意力机制,例如自注意力(Self-Attention)、交叉注意力(Cross Attention)、单向注意力(Unidirectional Attention)、双向注意力(Bidirectional Attention)和因果注意力(Causal Attention)、多头注意力(Multi-Head Attention)、编码器-解码器注意力(Encoder-Decoder Attention)等概念。
这些注意力模块构成了当今AIGC领域的基础。不过你可以放轻松,死记硬背只会让你越来越混淆,跟着我的节奏来学习。这里传授你一个学习技巧,遇到新知识可以先从它们的作用和原理来入手。
注意力模块通常作为一个子结构嵌入到更大的模型中,作用是提供全局上下文信息的感知能力。下面的两张图是对Transformer中一层的编码器和解码器结构的简化。可以看出,这里用到的便是自注意力模块和交叉注意力模块。
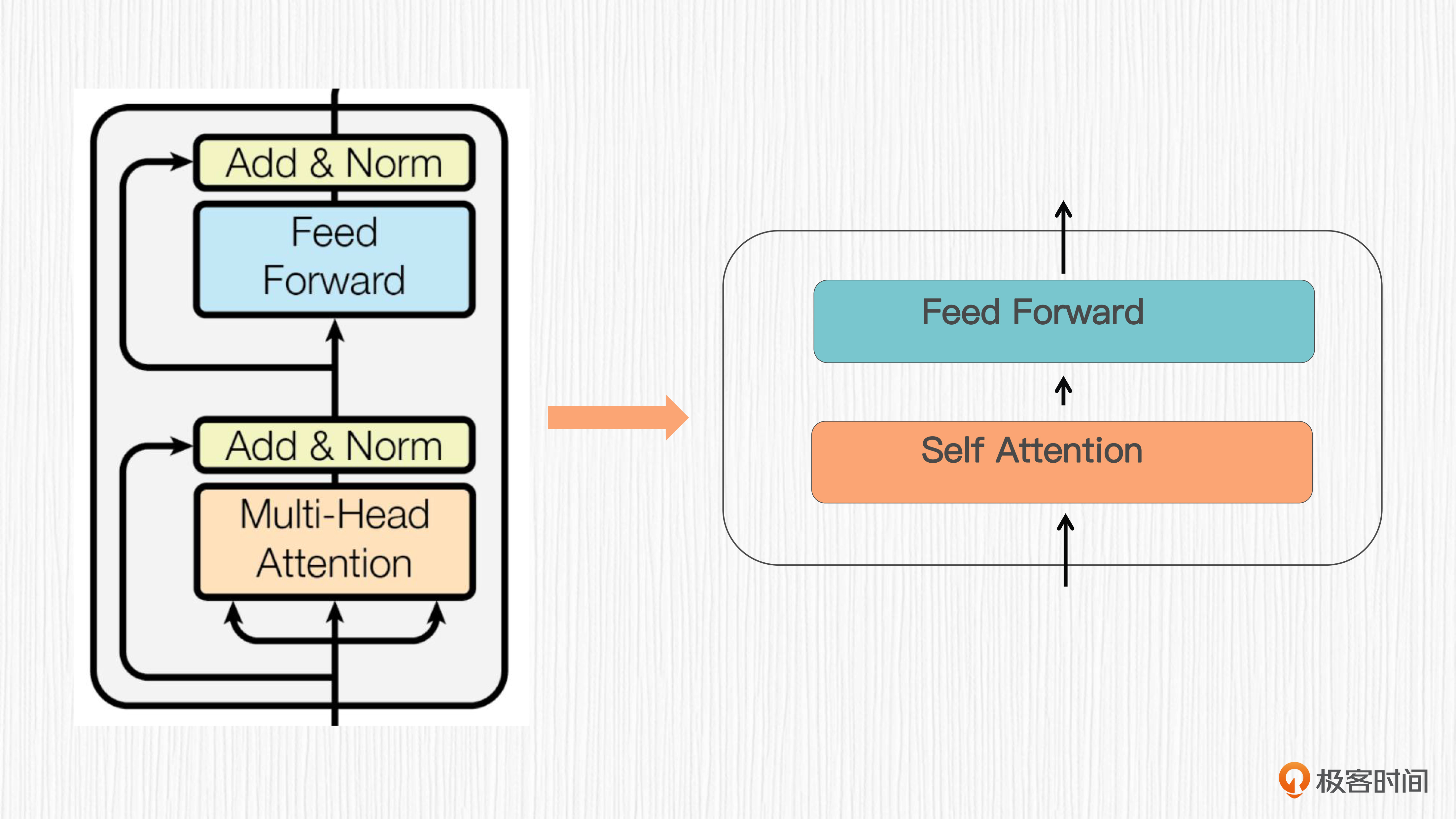

我们先来看最基础的自注意力模块,计算方法你可以看下面这张图。自注意力模块会计算输入序列中所有元素之间的相似性得分,再通过归一化处理得到注意力权重。这些权重可以视为输入元素与其他元素之间的联系强度。注意力模块通过对权重与输入元素做加权求和来生成输出,输出的向量维度与输入相同。

了解了基本原理,我们理解Transformer中自注意力模块的设计就会更加容易。
首先,我们通过三个可学习的权重矩阵$W_{Q}$、$W_{K}$、$W_{V}$分别将模块输入序列投影成Q、K、V三个向量。Q代表Query,K代表Key,V代表Value。然后通过计算Q、K之间的关系,获得注意力权重,最后将这些权重与V向量相结合,得到输出向量。
整个计算过程你可以参考后面的伪代码。
# 从同一个输入序列产生Q、K和V向量。
Q = X * W_Q
K = X * W_K
V = X * W_V
# 计算Q和K向量之间的点积,得到注意力分数。
Scaled_Dot_Product = (Q * K^T) / sqrt(d_k)
# 应用Softmax函数对注意力分数进行归一化处理,获得注意力权重。
Attention_Weights = Softmax(Scaled_Dot_Product)
# 将注意力权重与V向量相乘,得到输出向量。
Output = Attention_Weights * V
这里有三个小细节你需要注意一下。
- Q和K的向量维度是相同的,比如都是d_k,V和Q、K的向量维度可以不同,称之为d_v。
- 缩放因子Scale的计算方式是对d_k开根号之后的结果,在Transformer论文中,d_k的取值为64,因此Scale的取值为8。
- 图中被标记为可选(Opt)的Mask模块的作用是屏蔽部分注意力权重,限制模型关注特定范围内的元素。你可别小看这个Mask模块,它便是自注意力升级为单向注意力、双向注意力、因果注意力的精髓所在!
了解了自注意力的计算,我们再来看交叉注意力的计算便不再困难。
自注意力和交叉注意力的区别你只需要记住一句话:自注意力的Q、K、V都源自同一个输入序列,而交叉注意力的K、V源自源序列,Q源自目标序列,其余计算过程完全相同。对于Transformer这类编码器-解码器结构来说,源序列从编码器输出,目标序列从解码器输出。
Encoder-Decoder Attention模块
编码器-解码器注意力(Encoder-Decoder Attention)模块是解码器中的一个关键子模块,实际上它是一个交叉注意力模块,点开下面的图你一眼便会发现这个模块的Q、K、V源自不同序列。
编码器-解码器注意力模块的目标是统合源序列和目标序列之间的关系,以便生成更准确的输出序列。图中我已经标记了编码器-解码器注意力模块、源序列、目标序列所在的位置。
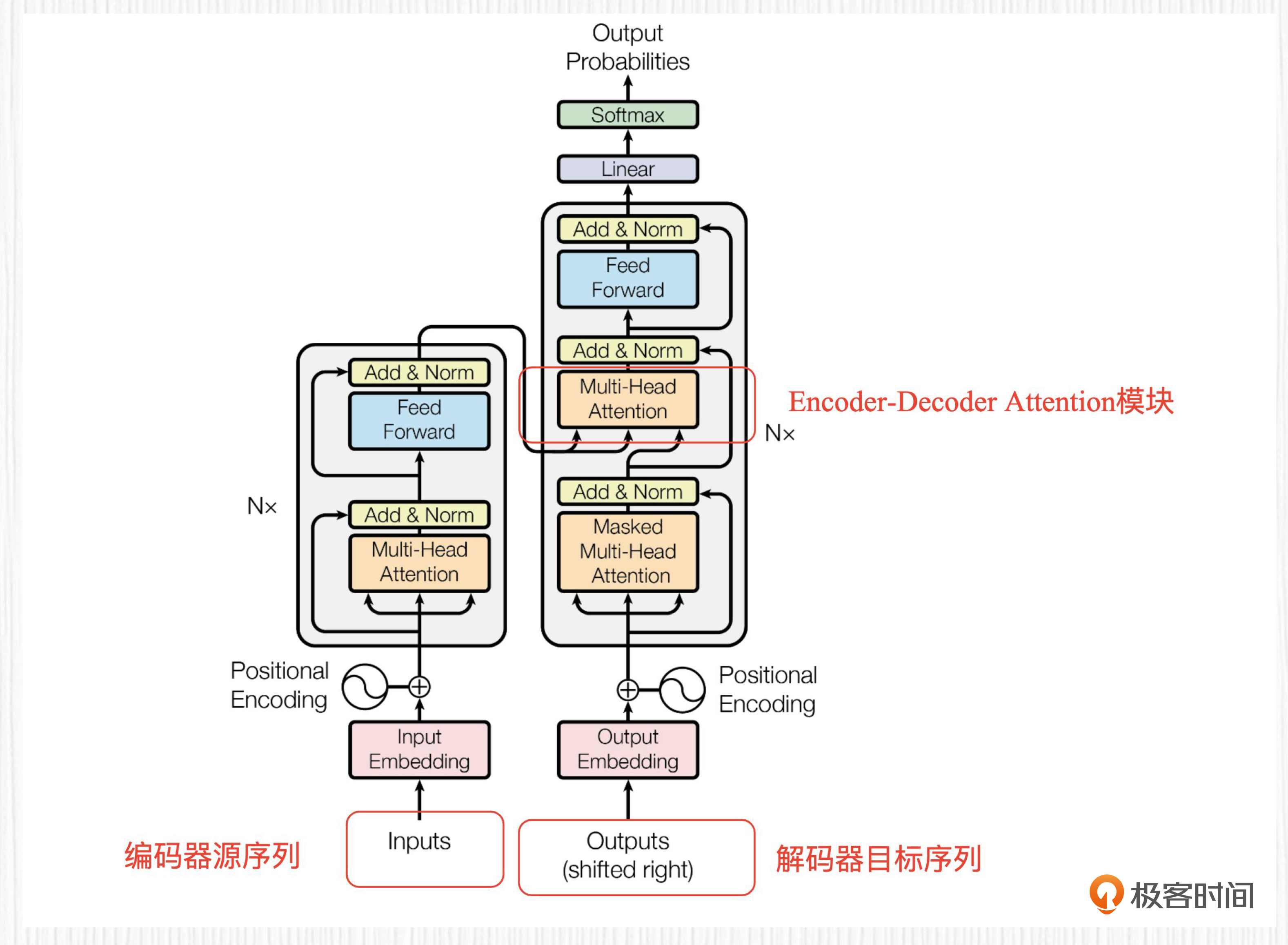
这里有一个非常关键的点,编码器的输入可以是我们要翻译的文本、或者是我们问ChatGPT的问题,那么解码器的目标序列又要如何获得的呢?
在训练阶段,目标序列通常是从训练数据获取的。例如,在机器翻译任务中,训练数据包含源语言序列及其对应的目标语言序列。在训练过程中,目标序列会被输入到解码器,解码器同时根据编码器提取的特征表示(Encoder-Decoder Attention)去预测相应的输出序列。通常情况下,目标序列会以一个特殊的开始符号(如<start>)开始,以确保模型在生成序列时从预定义的起点开始。
在训练阶段,我们使用成对的数据来训练模型。例如,在机器翻译中,训练数据包括一种语言的句子(源语言)及其另一种语言的翻译(目标语言)。在训练过程中,我们把这些目标句子输入到解码器部分,让Transformer学会根据源句子生成正确的翻译。我们通常在目标句子的开头加一个特殊的开始符号,比如<start>,这样模型就能知道要从哪里开始生成句子。
在训练阶段,解码器输入的目标序列是从实际的训练数据中获得的,而不是解码器在前一步生成的输出。这意味着,即使模型在前一个时间步预测错误,训练阶段的解码器输入仍然会使用正确的目标序列。这种做法有助于训练模型更好地捕捉源序列和目标序列之间的映射关系,加速收敛过程。
在预测或推断阶段,目标序列使用训练时用到的特殊符号作为初始值。随后,解码器会生成目标序列,一次生成一个token。对于每一步生成的token,都会将其添加到目标序列中,并将这个扩展后的目标序列作为输入输送到解码器。这个过程会一直持续,直到生成一个特殊的结束符号(如<end>)或达到预定义的最大序列长度。这便是人们常说的自回归模型。
知道了这些,编码器-解码器注意力模块的计算过程便非常容易理解了。首先基于源序列的特征计算得到K和V向量,然后从目标序列的表示(比如前一层的输出)中获得Q向量。之后的过程就和标准的自注意力一样了。
多头注意力机制的设计和优势
多头注意力(Multi-head Attention)是Transformer的工作里首次提出和使用的,它强化了编码器解码器的能力,你可以把它看作注意力模块的升级版。那么,它的工作原理是怎样的呢?
我们已经知道Self-Attention通过三个可学习的权重矩阵$W_{Q}$、$W_{K}$、$W_{V}$分别将模块输入投影成Q、K、V三个向量。多头注意力机制设计了多个独立的注意力子层并行地计算,捕捉和融合多种不同抽象层次的语义信息。
具体过程是后面这三步。
- 首先,将输入的Q、K和V向量线性投影到各自对应的子空间。这些投影会分别使用不同的$W_{Q}$、$W_{K}$、$W_{V}$权重矩阵进行学习。
- 然后,为每一个子空间计算注意力权重和加权向量,并将所有子空间计算出的加权向量拼接起来。
- 使用一个线性层,将拼接后的结果再次投影成一个输出向量,该向量与输入向量具有相同的维度。
关于多头注意力机制,你可以看下面这张原理图进一步加强理解。
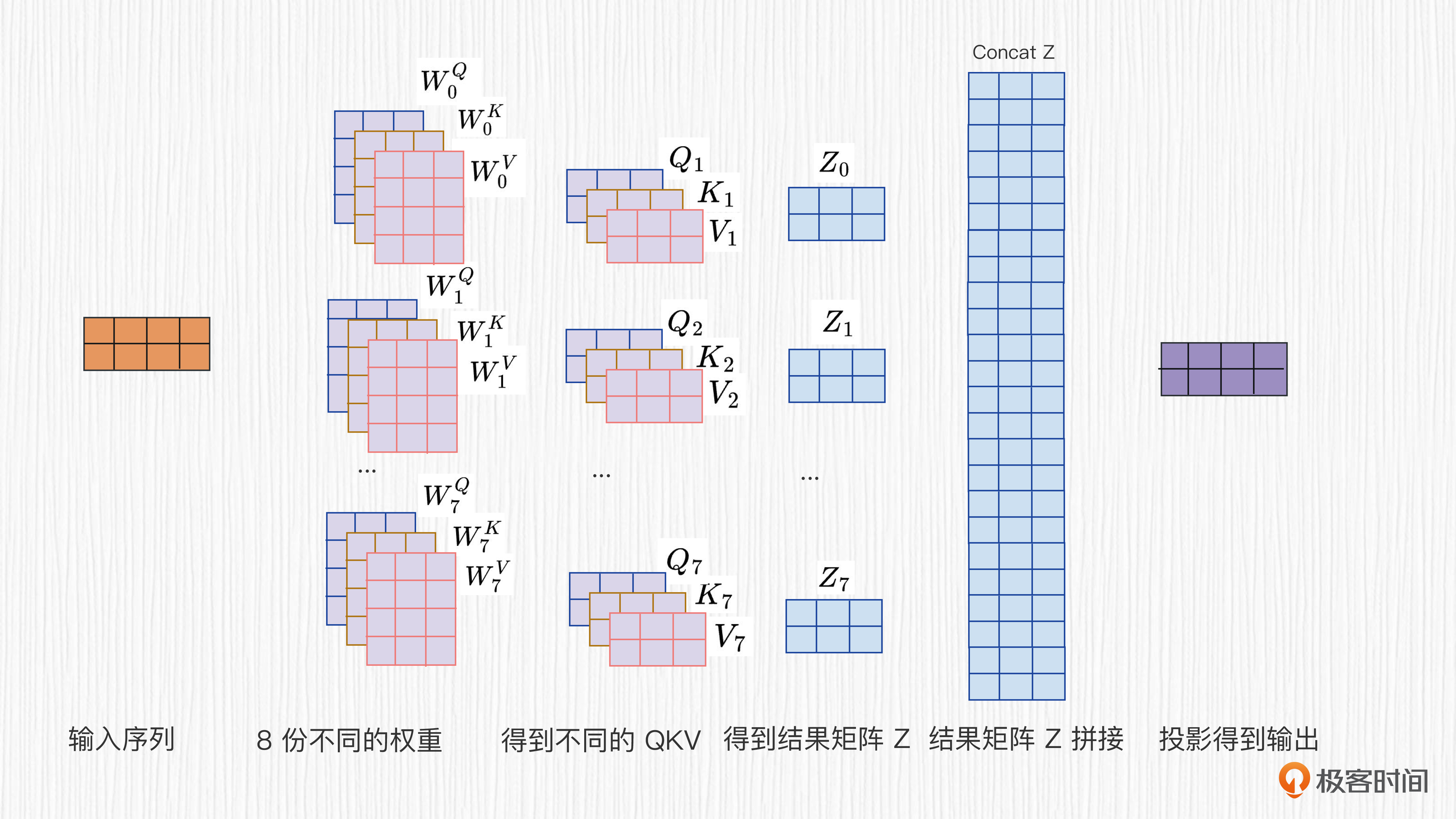
你也许会好奇,多头注意力机制不就是把自注意力机制重复了N次么?这样做有什么好处呢?
我用一个简单的类比来给你解释。假设一个团队有N个成员,每个成员专注于解决输入序列中不同类型的问题(例如不同领域的语义关系),然后将每个成员的结果结合起来,从而组合不同领域的知识。
多头注意力机制可以捕捉不同类型的依赖关系。每个Q、K、V都可以看作是不同子空间,多头注意力机制允许模型在不同表示的子空间中,捕捉序列中存在的多种上下文关系。例如,一个头可能关注词法关系,另一个头关注句法关系,还有一个头关注长距离的依赖关系。将这些从不同头获得的信息结合起来,模型就可以更好地理解输入序列。

更多注意力模块
说完了自注意力、交叉注意力、多头注意力,我们再来看看单向注意力、双向注意力和因果注意力,这三种注意力是通过Mask操作,也就是屏蔽部分注意力权重实现的。

- 单向注意力机制主要关注给定位置之前或者之后的上下文,从而捕捉输入序列中的单向依赖关系。比如,在看电影时只观察当前时间点之前发生的事件,电影甚至允许倒着放,只要是单向就行。
- 双向注意力机制能够同时关注给定位置之前和之后的上下文,从而捕捉输入序列中的双向依赖关系。不带Mask操作的自注意力和交叉注意力都属于双向注意力机制。比如,我们已经看过整个电影,了解了所有事件情节。
- 因果注意力机制仅关注给定位置之前的信息,因此在生成过程中通过Mask操作避免暴露之后的内容。比如,从头开始写一本小说,只能根据已经写了的情节合理地续写未来情节。
Transformer vs LSTM
理解了这些复杂的注意力机制,让我们回到今天的主角Transformer。相信你已经清楚,Transformer不依赖于递归的序列运算,而是使用自注意力机制同时处理整个序列,这使得Transformer在处理长序列数据时速度更快,更易于并行计算。
自注意力机制允许Transformer直接关注序列中任意距离的依赖关系,不再受制于之前的隐状态传递。这样,Transformer可以更好地捕捉长距离依赖关系。
然而,需要注意的是,尽管Transformer在很多任务中表现出优越性能,但它的训练通常需要大量的数据,对内存和计算资源的需求通常较高。另外,LSTM和Transformer在特定任务上可能具有各自的优势,我们仍然需要根据具体问题和数据情况来选择最合适的模型。
总结时刻
这一讲比较烧脑,但这是你深入理解AIGC的关键一环,下次别人聊到注意力机制时,你也可以根据今天学到的知识发表自己的见解。
今天,我们深入探讨了Transformer的算法原理。包括编码器、解码器的设计思路,自注意力、交叉注意力的实现原理,这些都是Transformer工作推出之前就已经广泛使用的经典技术。
同时,我们还学习了多头注意力机制这项Transformer工作中提出的原创技术亮点。实际上,除了我们今天重点分析的注意力机制,Transformer中还有很多技术细节,比如位置编码、Feed-Forward神经网络、残差连接、层归一化等,感兴趣的同学可以课后做更多拓展学习。
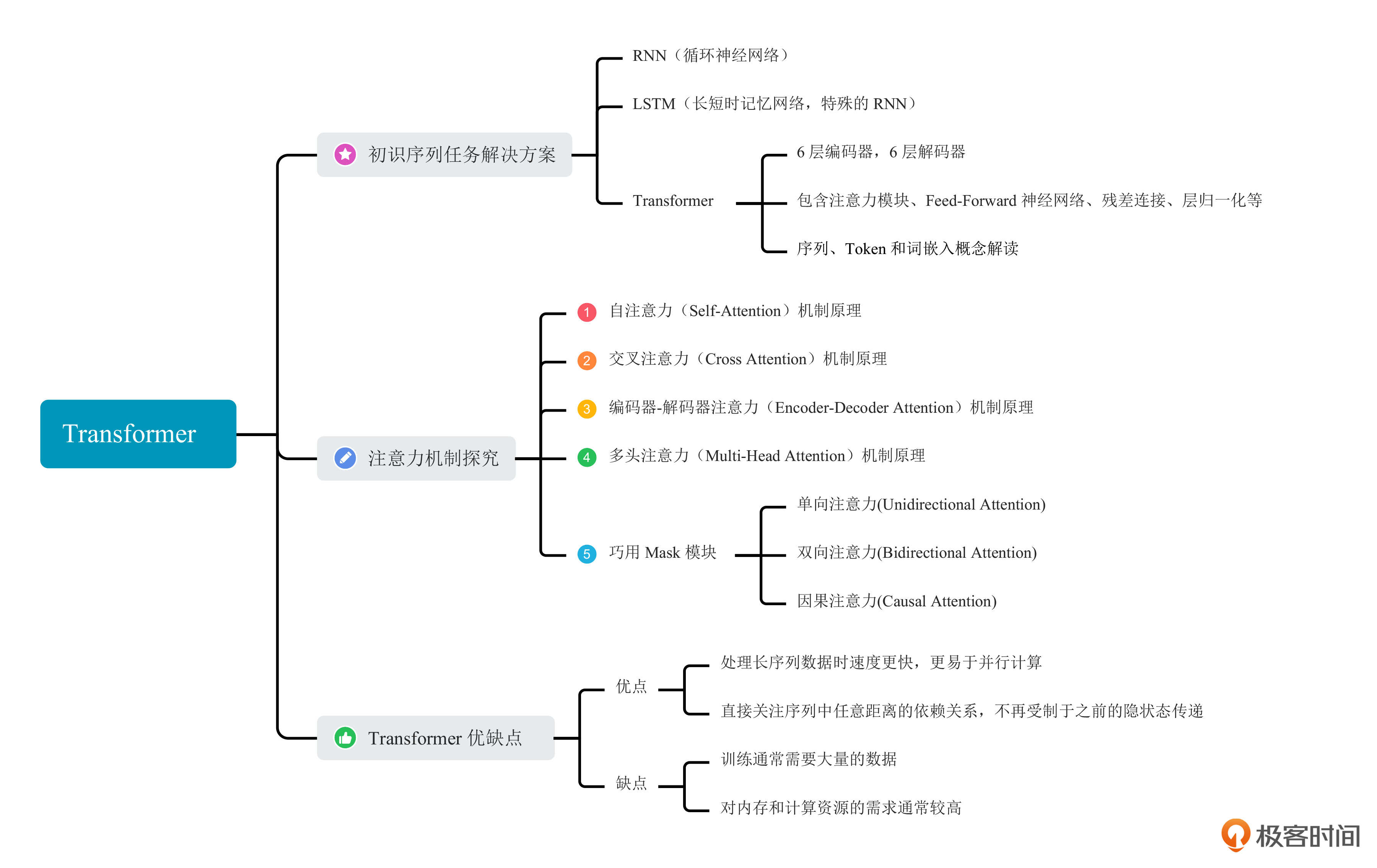
关于这节课的知识回顾,你可以查看下面的知识点小结。
思考题
如何改进Transformer的自注意力机制,提高它的效率,并减少计算资源需求呢?
期待你在留言区和我交流讨论,也推荐你把今天的内容分享给身边更多朋友。
- 听水的湖 👍(4) 💬(0)
虽然没有什么“跳关”秘籍,但还是有些技巧让你快速掌握一节课内容的。就像数据结构一样,每节课也有“内容结构”,想要快速消化,可以着重理一理后面这几点:这个模块 / 这节课要解决什么问题(What)思路是什么 / 为什么要这么解决(Why)具体如何解决的。 记各种名词没什么印象,可以试试结合例子去分析一下这个技术在里面发挥的作用。如果学习以后,能用自己的话整理一遍,也能帮助自己加深理解,查漏补缺。
2023-08-17 - Toni 👍(6) 💬(1)
注意力机制给大语言模型的发展带来蓬勃动力,近期,2023年8月谷歌的一个研究团队发表了一篇文章,将AI的“领悟”机制第一次带入人们的视野,一项非常有价值的开创性工作。虽然目前还影响不到AI绘画,但还是将链接发给大家,以了解AI的重要进展。 下面是个人观点和一些感悟。 AI绘画出现后,人们就一直关注AI绘画能力的边界问题,由于AI绘画技术具有外延性属性,即它是通过数据训练学习得到的绘画能力,只能是学了什么会什么,这极大地限制了AI绘画会导致新的艺术流派出现的可能性。 我以前的想法是如果能训练AI“懂”一种流派,这个不难实现,比如今天在模型中常见到的梵高模式,然后将几种流派的特征元素提取出来,再重新结合起来,无论是随机组合还是人为干预形成的组合,就可以"创建"出一种新的流派。只要在AI模型所对应的参数上下下功夫,创新流派还是可以实现的。至于什么人喜欢什么人不喜欢并不重要,因它属于另一个范畴,单单艺术审美就与诸如神经元,人的阅历,喜好等众多因素有关,极其复杂,所以不在流派创新要考虑的范围内。 AI“感悟”力的出现,为AI绘画突破外延式限制打开了一扇全新的大门: 如果AI模仿艺术大师的作品,画着画着,突然有了全新的领悟,不就是新艺术流派的诞生吗?这与人类的创造过程及其相似。有趣的是这篇文章还展示了为什么有些AI没有产生“领悟”力的原因: 训练过程中的过拟合和欠拟合都会导致AI模型“领悟”力的匮乏,用大家都懂的话说"过拟合"就如“墨守成规”,"欠拟合"就如“东施效颦”。 “感悟”力机制就像本课讲到的注意力机制一样重要,非同凡响,石破惊天。 随笔记下几个“遐想”,欢迎评论。 参考文献: <<谷歌发现大模型“领悟”现象!训练久了突然不再死记硬背>> https://view.inews.qq.com/a/20230812A05OD900?devid=AD054D9E-92ED-41C6-BFC8-03C4A22E78E4&qimei=f31d129575675bc1d4bebf5e000012117112# 原文: Do Machine Learning Models Memorize or Generalize? https://pair.withgoogle.com/explorables/grokking/
2023-08-13 - vincent 👍(5) 💬(3)
老师讲的非常好,但是对于我这个小白来说,难度还是比较高,听完后又在网上找了一些视频,结合着在看就更加理解了,在B站看到这个视频我觉得讲的比较适合小白https://www.bilibili.com/video/BV1MY41137AK/?spm_id_from=333.337.search-card.all.click&vd_source=eab8536a6dc6fd2252e60d2ccb546be1
2023-08-02 - 一只豆 👍(3) 💬(2)
不知道大家是否和我有同样的感触啊,上节课内容能听懂,这节课好像也凑活。但是,开篇那一句“事实上,Stable Diffusion 模型在原始的 UNet 模型中加入了 Transformer 结构,”这句桥梁一样的话,好像有点跳。所以看课程的总体过程中,脑子里一直在想,是怎么加进去的。。。总觉得有一种缺半句话 or 一句话的感觉~~~见笑了
2023-07-31 - 五木老祖 👍(1) 💬(1)
平时写前端和后端,想了解一下ai,但是太专业了,估计知识点缺失听不懂了。
2023-08-03 - syp 👍(0) 💬(1)
是我肤浅了,开始前几讲还觉得老师讲的不够深入,现在发现深不见底变成看不懂的天书了😨
2023-08-30 - ~风铃~ 👍(0) 💬(3)
好深奥,身为程序员的我,一点也没看懂。可能没学过人工智能的都弄不懂吧
2023-08-18 - 留点空白 👍(0) 💬(1)
确实听不懂这几讲,就过一遍了解一下吧
2023-08-05 - 海杰 👍(0) 💬(1)
记得好像在输入层对token进行编码的时候,还会掺入用三角函数算出来的位置信息,所以同一个token 出现在序列中的不同位置,得到的K,Q,V值是不一样的。所以跟距离远的token 和距离近的token 算出来的注意力权重值也不一样。这样理解对吧?
2023-08-05 - vincent 👍(0) 💬(1)
哈哈,听不懂
2023-08-02 - Geek_053403 👍(0) 💬(1)
感觉基础篇专业性太强了
2023-07-31 - peter 👍(0) 💬(2)
请教老师两个问题: Q1:以SD为例,研发SD,需要多少人?需要多少机器? Q2:AI绘画能制作表情包吗?
2023-07-31 - 石云升 👍(1) 💬(0)
这节课比较难理解,所以我让AI帮我举例个例子。想象我们在做一个巨大的拼图,这个拼图是一张巨大的森林图片,而每一块拼图代表森林中的一个小部分,比如一只小鸟、一棵树、一朵花等。我们的目标是把这些拼图块正确地拼在一起,重现整个森林的图案。 Transformer模型 如果把这个拼图比作是Transformer模型要完成的任务,那么Transformer模型就像是一个超级聪明的机器人,它可以同时看到手中的所有拼图块,并且知道怎样快速准确地把它们拼在一起。这个机器人不需要像我们一样,一块一块地试着去拼,它可以利用它的超级大脑(自注意力机制),一眼就看出哪些拼图块应该放在一起。 自注意力机制 现在,我们来聊聊这个机器人的超级大脑,也就是自注意力机制。这个大脑能让机器人在看每一块拼图时,同时记住其他所有拼图块的样子。这样,当它看到一块拼图时,就能立即知道这块拼图周围应该是什么样的其他拼图块。比如,如果它手里有一块拼图是一只小鸟的一部分,它的大脑会立刻告诉它,这块拼图旁边应该是包含树枝的拼图块,因为小鸟通常会停在树枝上。 用一个简单的例子来说,假如你正在玩一个游戏,需要你描述你的朋友给你看过的一张很酷的贴纸。如果你只能记住贴纸的一小部分,比如上面有一只猫,但忘记了猫旁边有什么,这会让描述变得很难。但如果你记得猫旁边有一棵树,猫下面有一条鱼,这样的所有细节,你就能更好地描述整张贴纸。Transformer模型里的自注意力机制,就像是帮助机器人记住贴纸上每一个细节的超级能力,让它可以更好地完成任务。 结论 所以,想象一下你有一个超级机器人朋友,它有一个特别厉害的大脑,可以帮助它记住和理解每一块拼图是如何与其他拼图块一起工作的。这就是Transformer模型和自注意力机制的魔力——它们帮助机器理解和处理信息,就像是把一个巨大的、复杂的拼图拼在一起一样容易和有趣!
2024-03-14 - 听水的湖 👍(1) 💬(0)
接下来的分享就是“用自己的话做整理,加深学习理解”的小案例。 我们让机器具备人的信息理解能力,有两个要解决的关键问题。 【问题一,看了后面忘前面】:当一个字一个字喂给计算机时,它很快就会忽略了前面的字。 【问题二,机器无法评估一段内容里,啥信息重要】:句子里有的词重要有的不重要,句子和句子之间也是,段落和段落之间也是这样。 为了解决这些问题,我们要把人类“不言自明”的一些天赋,换成机器能理解的描述方法教给他。类似于三角形加辅助线,或者我们通过多个维度的信息得出“唯一确定解”的思路,我们把机器本来不理解的输入信息,抽象成它能理解的数字。 结合Transformer里encoder的decoder,大概可以分成四步。 第一步,输入信息,但这个信息人类能懂。 第二步,encoder把它转化成机器可以计算的数据。 第三步,算法专家设计好的计算方法帮助机器“画辅助线”,提示机器注意信息的重点是啥,每个信息有多重要(重要程度一样也可以用数字表示)。做复杂计算,计算的目的是让机器用它能理解的方式,给出规定任务(比如让它把输入序列翻译成另一个语言)的“输出”。 第四步,机器给的输出还是“机器语言”,一堆数,我们人直接看不友好,再通过decoder把“答案”,转换成人类语言输出出来,大功告成。 有描述不准确的地方,欢迎批评指正。感谢热心群友Toni同学的讲解和提出Transformer不好理解的和某欢同学。 另外,关于Transformer,也推荐极客时间李沐老师的公开课最后一章(121~123讲)的内容,适合学有余力想深入代码跟技术细节的同学。https://time.geekbang.org/course/detail/100077201-428460
2023-08-17 - 静心 👍(0) 💬(0)
因为是初学,有一个初级的问题请教一下老师: Q = X * W_Q K = X * W_K V = X * W_V 我想知道其中的X表示什么?权重矩阵 WQ、WK、WV 又是怎么来的?
2023-10-25