15 找工作:如何让DeepSeek帮我们找工作?
你好,我是邢云阳。
上节课,我们使用了无头浏览器的技术,准备了项目的岗位数据。有了这个基础,我们后面继续开发求职助手就会更方便。
我们今天就开发一个 MCP Server,然后测试一下,如何结合 DeepSeek-R1 模型来完成岗位信息查找,看看找到的岗位会不会更加适合自己呢?
无头浏览器的补充知识点
在开始今天的开发之前,先补充一个知识点。上节课,有同学回去测试,可能将代码跑起来后,某直聘网给出了这样的回复:
这是因为,网站认为访问网站的不是真人而是机器人、爬虫程序等等,因此将你的 IP 标注为了可疑 IP。这时候,我们就需要花点钱,去网上租用代理 IP。然后在程序中设置使用代理 IP 进行访问,由于代理 IP可以设置每分钟、每 5 分钟、每小时等等频率更换新的 IP,因此可以避免被网站标注后无法访问的情况。
那代理 IP 如何购买呢?在网上搜索代理 IP,会出来很多卖该项服务的网站。这里我就以快代理为例,为大家演示一下如何购买代理 IP,以及在程序中使用。
我们打开网站后,先注册并实名认证一下。然后选择产品–>隧道代理–>按量付费。
此时会进入到选择产品规格的页面。在这里建议换 IP 周期选择 1 分钟或 5 分钟,方便多次访问网站的测试。带宽根据自己的财力来,测试的话,3Mbps 和 5Mbps 也足够了。
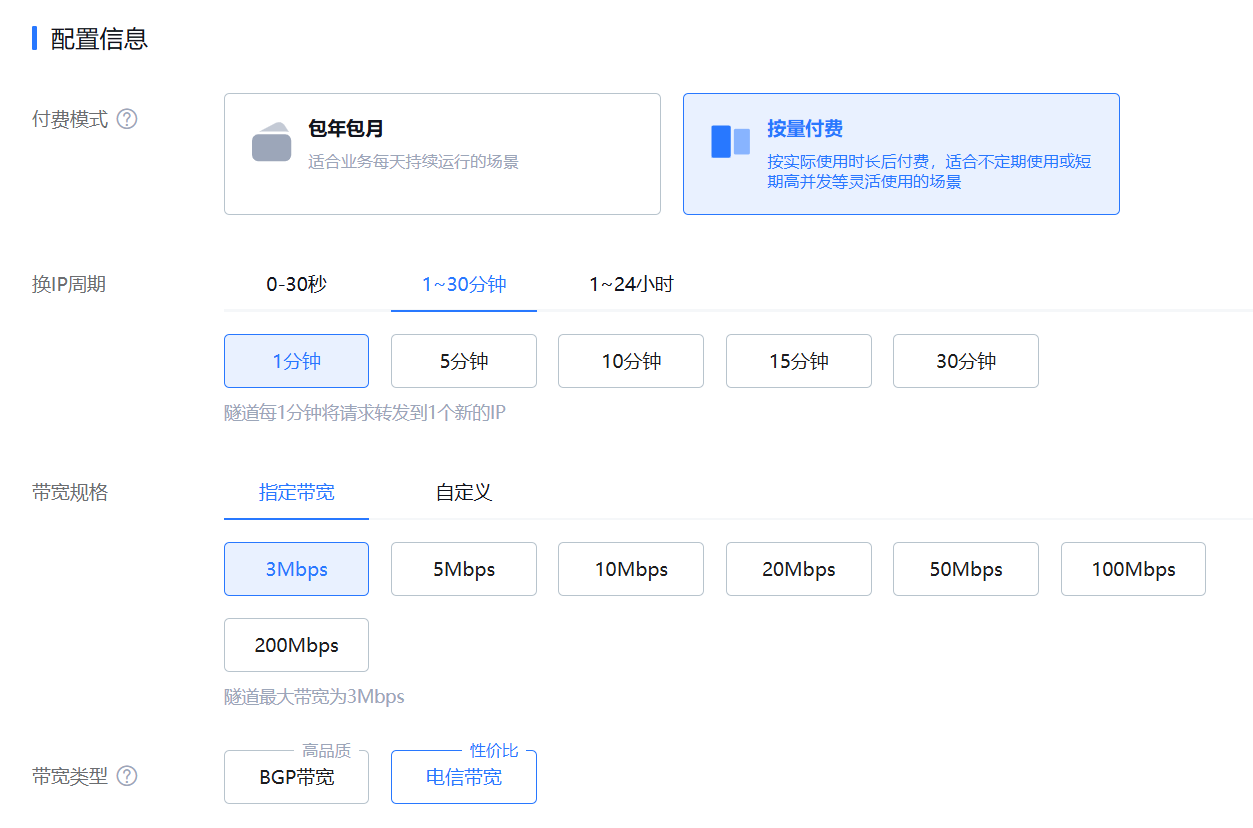
这样的配置是每小时 5.31 元。然后点击右侧的开通,付费购买即可。
付费后,点击右上角的会员中心,会进入到账户管理界面。
此时,选择隧道代理–>我的隧道代理。会看到下图所示的基本信息页面。
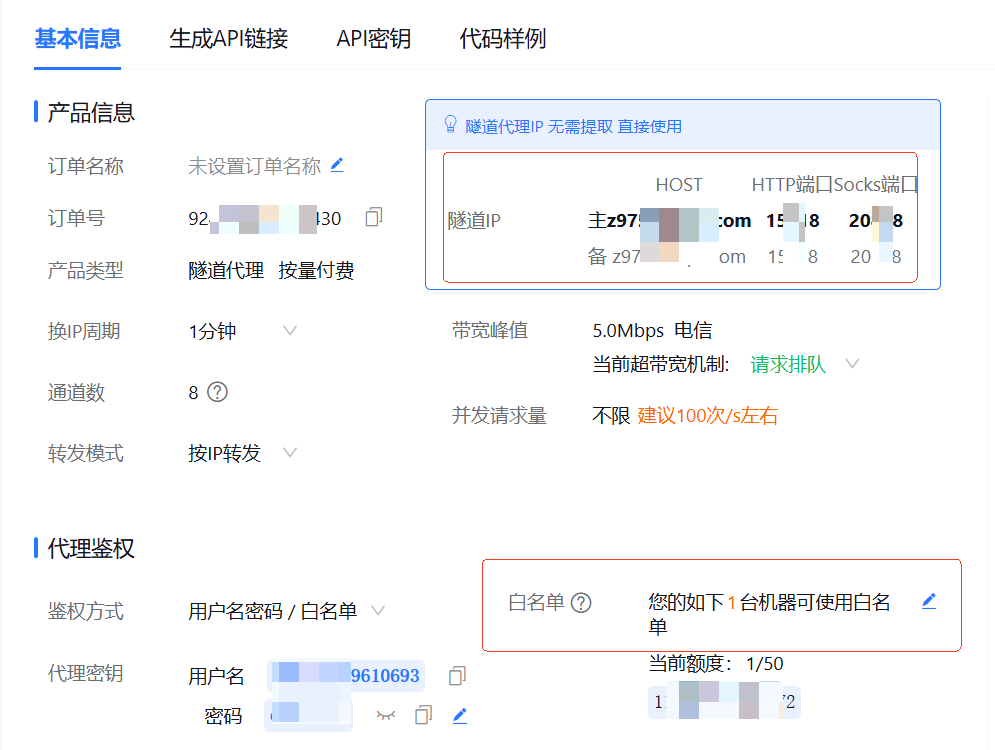
如果你是像我上节课一样,程序在本机执行的,则可以点击白名单,把本机 IP 加入进去,这样就不用使用代理密钥了。最后,我们在程序的 chrome 浏览器的 options 配置中使用红框中的隧道 IP (HOST:HTTP端口)就可以代理访问了。代码如下:
注意,这里你需要将 z976.xxxxx.com:15818 换成你自己实际的 HOST 和 HTTP端口。
这样,访问受限的问题就解决了。
利用 MCP Server 实现求职助手
前置知识补充完整后,我们正式开始实现求职助手。首先完成方案与工具的设计。
方案与工具设计
先来回忆一下人工找工作的过程。
第一步,通常我们会打开招聘网站,去选择目标城市,然后输入期望工作岗位的关键词,比如 AI 应用开发,进行搜索。
第二步,我们会根据网站给出的职位列表,一个个的查看。此时,如果我们不是面试“老油条”,对于 HR 列出的一些岗位要求、技能等等,无法做出是否适合自己的判断,可能就不太容易找到适合自己的工作。
第三步,假如查看到感觉适合自己的岗位后,就开始投递简历,或者直接海投简历。
第四步,等待面试。或许由于在第二步和第三步,我们投递的公司的要求不符合我们的技能,就导致面试官提问的问题,我们都不会,从而自信心受挫,认为自己水平不行。但实际上,这很大程度上是源于第二阶段人岗匹配的偏差,而非个人真实专业水平的体现。
因此如果能让大模型来帮助我们完成前两步,以大模型的数据分析能力,大概率会比人类自己肉眼匹配的更加精准。
我们把前两步用一个流程图抽象出来,然后思考一下,如何让大模型来完成呢?
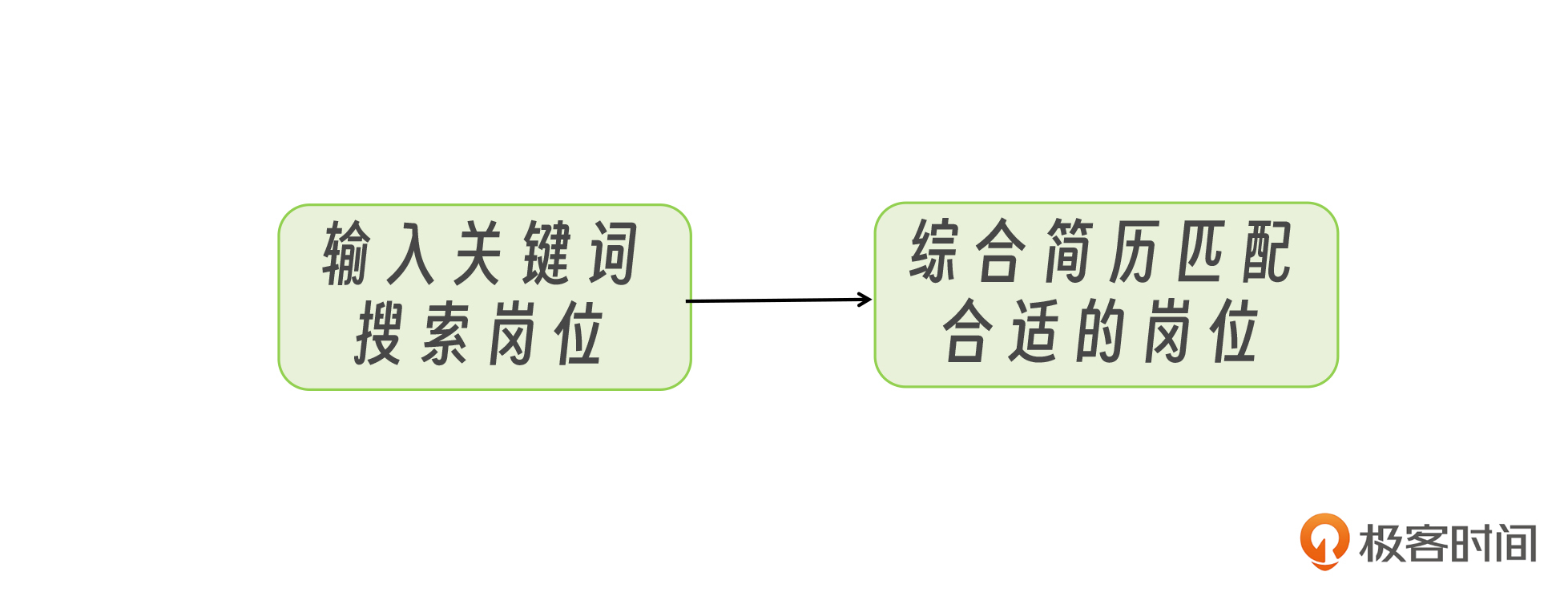
实际上很简单,就是要把大模型想象成人,以前这两步是人来做,现在是要把这两步封装成两个工具,然后把工具交给大模型来调用。
方案框架明确以后,我们再来看输入输出。首先是搜索岗位工具,其入参是用户期望岗位,返回值是岗位列表;而匹配岗位的入参有两个,分别是岗位列表以及用户简历,返回值是合适的岗位。
那入参从哪来呢?也非常简单。用户期望岗位以及简历是由用户输入的,而岗位列表是执行搜索岗位的工具后获取的。
OK,那基于以上的分析呢,我们就可以把上图再完善一下,形成一个带数据流的方案架构图。
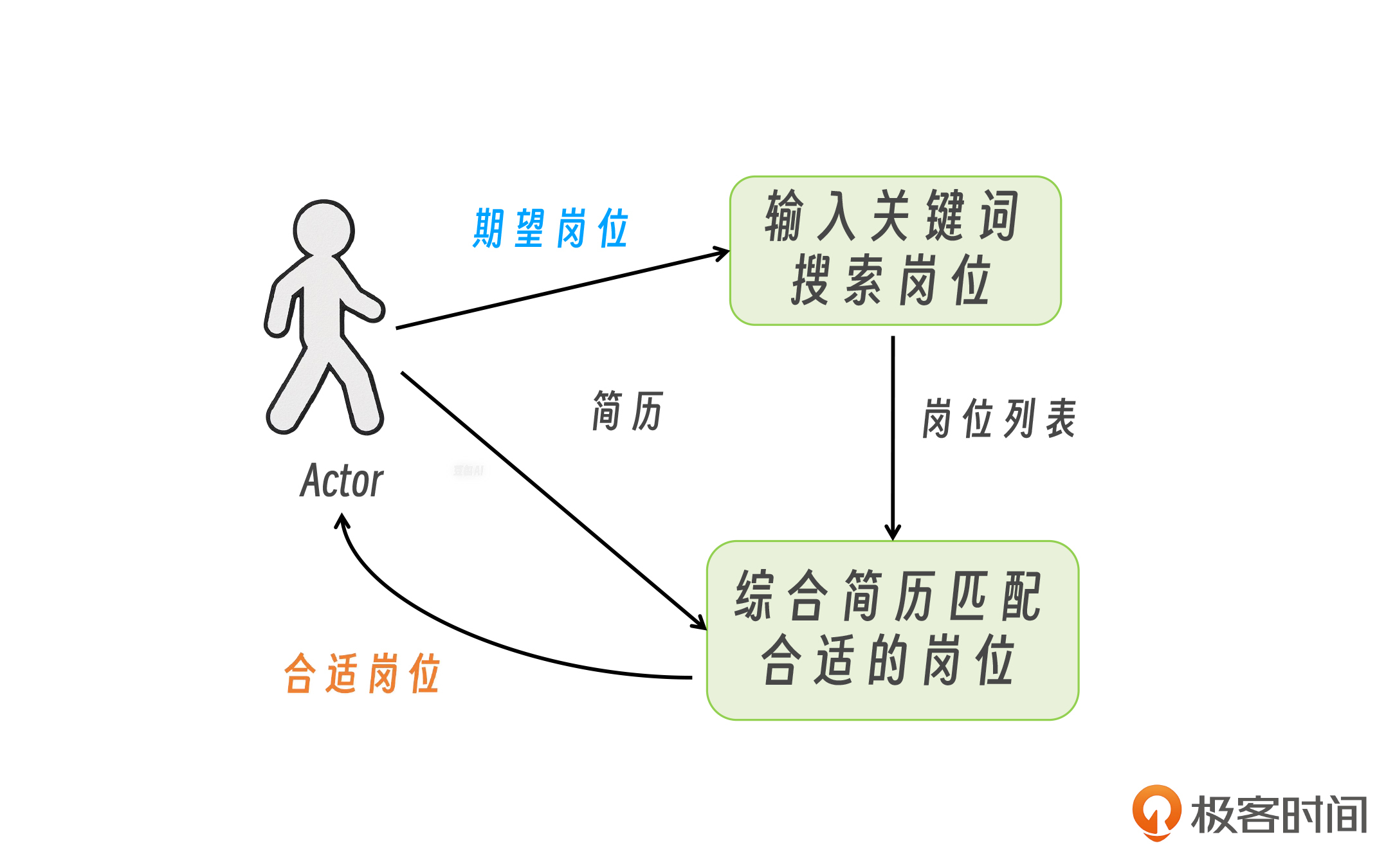
至此方案就非常明确了,我们只需要写一个 MCP Server,把图中的小人换成 DeepSeek,就可以搞定。
再来说说工具的设计。搜索岗位工具,其实我们在上一节课已经实现了,就是通过用户输入的期望岗位,使用一些手段去招聘网站获取岗位数据。
匹配岗位工具呢,也非常简单。我们只需要将用户简历与岗位列表,都交给 DeepSeek-R1,让其进行分析和推荐即可。这个过程就完全取决于我们的 prompt 怎么写了,我会在后面代码实现部分再为你详细讲解。
MCP Server 目录层级与配置管理
接下来,我们就开始写代码了。首先还是按照之前课程讲解的方法,使用 uv 创建出一个 MCP 工程来。
之前,我们写代码都比较简单,整个工程下,只有一个 server.py,因此也没给大家讲 uv 的项目管理配置等知识。但今天我们这个项目稍微复杂一点,涉及到工具的调用、大模型的调用等,因此我们就需要分目录分文件进行代码管理。我设计的目录结构如下:
.
|-- src
| |-- jobsearch_mcp_server
| | |-- llm
| | | |-- llm.py
| | |-- prompt
| | | |-- prompt.py
| | |-- tools
| | | |-- job.py
| | |-- server.py
| | |-- __init__.py
|-- .env
|-- pyproject.toml
|-- LICENSE
相比以前,我不是直接在根目录下创建一个 server.py 就开始写代码了,而是先创建了一个 src 文件夹,之后又在 src 文件夹下创建了 jobsearch_mcp_server 文件夹。
注意,这个文件夹的命名必须用下划线,不能用横杠,例如写成 jobsearch-mcp-server 是不行的。这是因为这个文件夹下放置的就是我的主函数(可以理解为以前的server.py),因此这个文件夹是一个包,而在 python 语法中,包名不能用横杠,因此要写成下划线。
在根目录下还包括 .env 文件,这是用来存放环境变量的。pyproject.toml 文件,这是整个 uv 项目的依赖管理、编译管理、运行管理等功能的配置文件,类似于 maven 的 pom 文件。而LICENSE 文件是项目的许可证,许可证的内容一般是一些商业规则,比如代码是否是开源可商用的等等。
我们再回到 jobsearch_mcp_server 包文件夹,文件夹下包含了 llm、prompt、tools 三个文件夹,功能分别是大模型的访问,匹配岗位时的 prompt 以及工具。
除此之外,就是 server.py 以及 init.py 了。以前我们的主函数是放在 server.py 的,但现在,由于工程下不止 server.py 一个文件,因此就需要用一个 init.py 来作为入口文件,将主函数放到这个文件中,之后工程运行时,python 会自动找到该文件,执行主函数。该文件的内容如下:
from . import server
def main():
"""Main entry point for the package."""
server.main()
# Optionally expose other important items at package level
__all__ = ["main", "server"]
最后说说 pyproject.toml 的写法。先看内容:
[project]
name = "jobsearch-mcp-server"
version = "1.0.0"
description = "MCP Server for interacting with Jobsearch"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"mcp[cli]>=1.0.0",
"python-dotenv>=1.0.0",
"fastmcp>=0.4.0",
]
[project.license]
file = "LICENSE"
[project.scripts]
jobsearch-mcp-server = "jobsearch_mcp_server:main"
[build-system]
requires = [
"hatchling",
]
build-backend = "hatchling.build"
当我们使用 uv 创建好一个工程时,[project] 部分会被自动填入。其中前 6 行是工程描述信息,第 7 行的 dependencies 就是工程运行时依赖的 python 包。[project.license] 制定了 LICENSE,照抄即可。[project.scripts] 表示工程运行时,应该去哪找主函数。“jobsearch_mcp_server:main” 就是包名:主函数名。[build-system] 是编译相关的,我们照抄即可。
建议大家第一次这样管理工程时,一定要和我保持一致,先保证能运行,然后再去理解,否则会在配置上走很多弯路,出现各种奇奇怪怪的、运行不起来的问题。
搜索岗位工具
代码工程建立后,我们开始写代码。我们先了解一下搜索岗位工具的写法。核心代码如下:
@mcp.tool(description="根据求职者的期望岗位获取岗位列表数据")
def get_joblist_by_expect_job(job: str) -> str:
"""根据求职者的期望岗位获取岗位列表数据"""
# 取得岗位信息
#with open('job.txt', 'r', encoding='utf-8') as f:
# jobs = f.read()
#以下就是无头浏览器获取岗位的代码
jobs = listjob_by_keyword(job)
return jobs
我们依然采用 FastMCP SDK 编写 MCP Server,因此工具函数的写法与之前完全一致,就不再赘述了。具体到工具的内容,就是上节课我们讲的无头浏览器的代码。
但因为我们使用无头浏览器抓取数据大概率需要用代理(付费),因此如果你在抓取数据方面有问题,我会在我的代码中,为你提供一份岗位列表测试数据,也就是 job.txt。你可以把代码的 5、 6行的注释放开,再把第 8 行无头浏览器的代码注释掉,改为从本地读取岗位列表,便于进行测试,数据并不重要,我们学习的是做项目的思路。
岗位匹配工具
接下来看一下岗位匹配工具,原理在上面的设计小节已经讲过,关键看 prompt 怎么写,内容如下:
【AI求职助手】
你是一个AI求职助手, 我正在寻找与我的技能和经验相匹配的工作机会。以下是我的简历摘要和搜集到的岗位需求列表
【个人简历】
{resume}
【岗位需求列表】
{job_list}
请帮我匹配最合适的3个岗位, 并根据我的简历提供简要的求职建议。
开头给了人设,然后告诉大模型我们想要干什么。之后附上了个人简历和岗位列表。最后告诉大模型匹配 3 个岗位,给出匹配理由和求职建议。整个模板在每一块内容前都用中括号加了小标题,这样会让大模型更容易理解哪里是重点。
代码就非常简单了。
@mcp.tool(description="根据求职者的简历获取适合该求职者的岗位以及求职建议")
def get_job_by_resume(jobs: str, resume: str) -> str:
"""根据求职者的简历获取适合该求职者的岗位以及求职建议"""
#将简历以及岗位列表注入到 prompt 模板
prompt = Job_Search_Prompt.format(resume=resume,job_list=jobs)
messages = [{"role": "user", "content": prompt}]
self.logger.info(f"prompt: {prompt}")
#发送给 ds
response = LLMClient.send_messages(self,messages)
response_text = response.choices[0].message.content
return response_text
这部分也很好理解,就是按我们前面的设计来实现,将岗位列表和简历注入到 prompt 模板,然后发给大模型。
测试
最后,我们还要进行测试。由于我们的代码结构发生了改变,因此在 MCP Hosts(Cline, Cluade Desktop)的配置和之前也不一样了。我把配置贴到下面, 你需要根据自己的实际路径更改。
{
"mcpServers": {
"jobsearch": {
"command": "uv",
"args": [
"--directory",
"D:\\workspace\\python\\mcp-test\\jobsearch-mcp-server\\src\\jobsearch_mcp_server",
"run",
"jobsearch-mcp-server"
]
}
}
}
这里还要说一个坑。我们的岗位匹配工具使用的是 DeepSeek-R1 模型,因为这个模型需要深度思考,回复会比较慢。所以如果我们用 Cline 进行测试,大概率会报请求 MCP Server 超时的错误,这是因为 Cline 设置的与 MCP Server 的通信超时时间太短,还没等 R1 给出回复,就超时了。
因此建议你使用 Claude Desktop进行测试。如果没有这个条件,只能用 Cline,就把岗位匹配工具的模型改为 DeepSeek-V3,这样就不会超时了。
接下来,我们来看测试效果。我的请求 prompt 是:
效果如下。
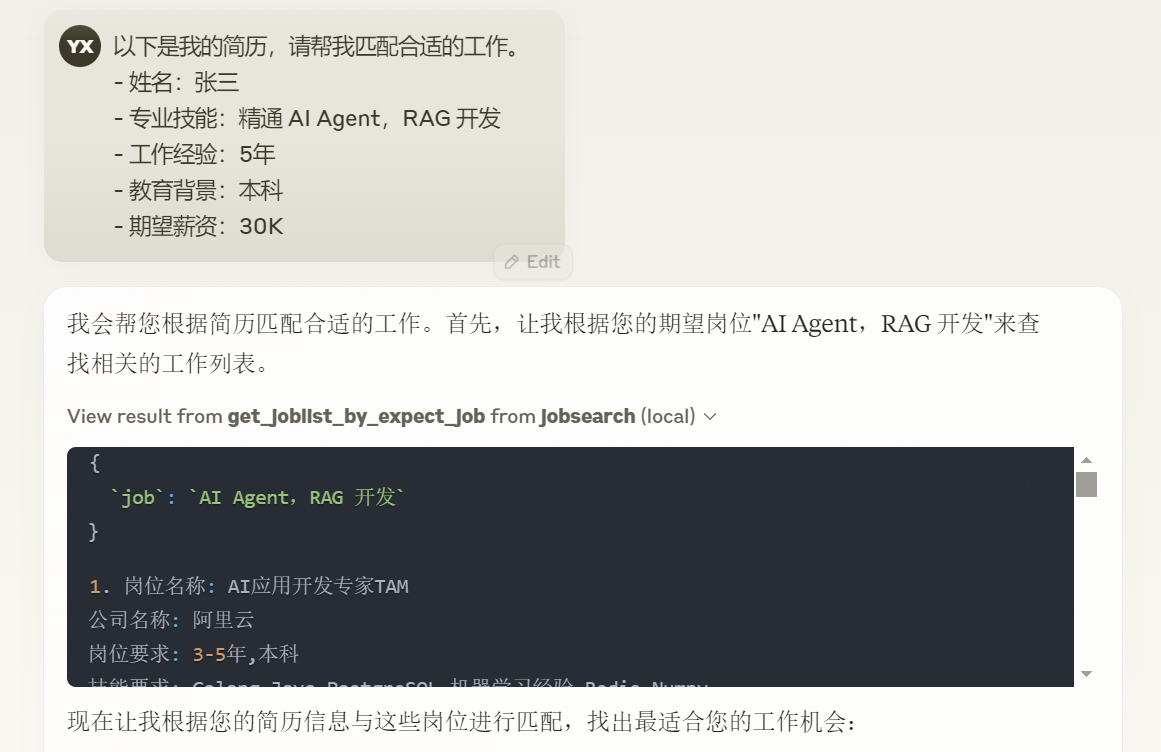




怎么样,效果比自己手工找工作强吧?
总结
今天这节课主要分成了两个部分。第一是解决了抓取直聘网岗位信息时,需要验证身份的问题。第二部分则是基于前面讲过的知识,完成了一个求职助手 MCP Server。通过该 MCP Server,我们只需将简历丢给大模型,大模型就会帮我们匹配到合适的工作,并给出求职建议。
整个过程,我们就像找了一名专业的职业发展顾问一样,不仅完全代替了传统的手工找工作的方式,而且还要比手工找工作的效率更高,准确度也更高。这就是 AI 给人类带来的生活方式的转变。
项目其实做下来后,难度并不大,但思维很重要。我们的核心思想就是把大模型当人看,以前人怎么找工作的,现在就让大模型怎么找工作。就像《少帅》电视剧中,张作霖给张学良说的话一样,“你就把老子走过的路完完全全地再走一遍”。希望你能多多体会,课后多多实践。
这节课的代码,我已经上传到 Github,链接为:Geek02/class15 at main · xingyunyang01/Geek02,大家可以下载后阅读一下代码,把课程中没讲到的点再看一下,有不理解的地方可以留言区交流。
思考题
如果我们要做一个做饭助手,让其根据我们输入的口味、食材等给出合适的菜谱,并给出烹饪建议,应该怎么做呢?
欢迎你在留言区展示你的思考结果,我们一起来讨论。如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 听水的湖 👍(9) 💬(1)
[Prompt] 你是一个擅长营养美味家常菜、快手菜的厨师专家。 任务: 1. 根据用户提供的口味或者食材,先调用菜谱数据库,如果没有搜到再通过网络搜索Agent做查询。 2. 查询到数据之后,进行文字梳理,给出菜品的分步骤菜谱,例如宫保鸡丁的步骤为: - 1. 鸡胸肉切丁,加入花雕酒、白胡椒粉、少量盐和玉米淀粉抓匀,最后再加一点食用油抓匀锁住味道,没有花雕酒也可以用料酒代替。 - 2. 黄瓜和胡萝卜切丁,加入一点点盐抓匀腌制一会儿,下锅前要提前把盐冲洗干净,攥干水分。 - 3. 提前调一碗料汁,生抽、蚝油、米醋、白糖、玉米淀粉和清水调匀,还可以加一点点鸡粉提鲜,没有也可以不放。 - 4. 起锅热油…… 3. 给出菜品所需而当前食材清单没有的食材。 4. 提供烹饪建议,例如火候、调料替代等。 要求: - 不需要过分创新菜品,尽量选择已知的家常菜、快手菜。 - 菜谱中的主要食材必须存在于用户提供的食材清单中,配菜可以提醒用户补充。 - 菜谱要简单、清晰,步骤明确,在关键的火候、时机处描述清楚,易于用户操作。 - 按照参数输出菜品名、分点步骤、补充提示。 【有待优化的方向】 1.做饭的时候能够语音支持调用这个助手会更方便,可以考虑接入语音交互功能。 2.可以提供每个步骤或者关键步骤的图解,这样更方便烹饪新手对照。 3.支持拍图识图功能,让用户拍一下自己的食材和想吃的口味,做菜助手根据已有食材提供建议。 4.做菜助手的数据库可以做一些优化,按照菜品功能或者热量等等标签做一些分类,不但有利于智能体做数据查找,还能在输出时给出菜品营养、功效、热量等方面的信息。
2025-04-02 - Feng 👍(3) 💬(1)
这里get_job_by_resume中获取提示词模板后,是在mcp server中调用了LLM,之前以为mcp server只需要负责返回提示词模板
2025-04-07 - jogholy 👍(3) 💬(1)
通过输入的口味或菜名去食谱网站上抓取对应食谱,然后根据食材内容构造提示词让选出最合适的食谱并给出烹饪建议交给大模型,最后获取反馈的答案。
2025-04-02 - 晓波 👍(2) 💬(1)
@mcp.tool(description="根据求职者的简历获取适合该求职者的岗位以及求职建议") 请教下,为什么大模型处理的逻辑是写在mcp server端进行处理,而不是在mcp clinet端处理?
2025-04-29 - 南天 👍(2) 💬(0)
能否举例使用mysql或其他数据库里的信息进行案例讲解
2025-04-17 - Geek_30842d 👍(1) 💬(1)
老师,我想通过 运行python server.py 的方式,然后通过 curl -X POST http://localhost:8000/tools/get_job_by_resume \ -H "Content-Type: application/json" \ -d '{ "jobs": "Python工程师,Java工程师", "resume": "我有5年Python开发经验..." }' 这样可以吗? 目前FastMCP 不能暴露端口号 class JobSearchServer: def __init__(self): self.name = "jobsearch_mcp_server" self.mcp = FastMCP(self.name, host="0.0.0.0", port=8000,debug=True) # 配置日志 logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s' ) self.logger = logging.getLogger(self.name) self._register_tools() def _register_tools(self): """注册所有MCP工具""" job_tools = JobTools(self.logger) job_tools.register_tools(self.mcp) def run(self): """运行MCP服务""" self.logger.info("Starting job search server...") try: self.mcp.run(host="0.0.0.0", port=8000) # 在这里传入参数 except Exception as e: self.logger.error(f"Server failed to start: {str(e)}") raise def main(): server = JobSearchServer() server.run() if __name__ == "__main__": main()
2025-05-07 - CrazyCodes 👍(1) 💬(1)
老师,claude是不是必须用pro版本才可以选择mcp,我用模型 claude 3.7 sonnet得free版本找不到导入的地方
2025-04-28 - Geek_5dacb9 👍(1) 💬(1)
"jobsearch": { "command": "uv", "args": [ "--directory", "D:\\python-study\\AI\\极客时间\\searchjobs\\jobsearch\\src\\jobsearch_mcp_server", "run", "jobsearch-mcp-server" ] } class JobSearchMCPServer: def __init__(self): self.name = "jobsearch_mcp_server" self.mcp = FastMCP(self.name) 老师,mccserver中jobsearch这段配置我有些不太理解,参数args中run后边的参数为"jobsearch-mcp-server",是什么意思啊,我看注册时用的是"jobsearch_mcp_server",中间是带下划线的啊?
2025-04-17 - Geek_ca6a8b 👍(1) 💬(2)
老师您好,有两个问题: 1. 在job.py的代码中 get_job_by_resume的jobs入参是怎么知道需要输入get_joblist_by_expect_job的输出呢,是自动按照tool的顺序运行吗?2. 如果配置多个独立的任务(比如找工作和做饭两套程序) 该怎么在roo code中配置?
2025-04-13 - Johar 👍(1) 💬(1)
vscode 插件Roo Code调用本地mcp server,示例中的mcp server 日志是否打印?打印的具体路径多少?是否可以支持配置?
2025-04-06 - maybe 👍(0) 💬(1)
cline配置mcp服务报错,in __init__ raise OpenAIError( "The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable" ) openai.OpenAIError: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable MCP error -32000: Connection closed
2025-05-19 - 完美坚持 👍(0) 💬(1)
做起来还是太难了
2025-05-05 - 完美坚持 👍(0) 💬(1)
老师,那种付费的API接口有吗
2025-05-05 - Ryan 👍(0) 💬(2)
Job_Search_Prompt 是怎么来的?
2025-04-16 - ifelse 👍(1) 💬(0)
学习打卡
2025-04-15