13 代理(下):结构化工具对话、Self Ask with Search以及Plan and execute代理
你好,我是黄佳,欢迎来到LangChain实战课!
在上一讲中,我们深入LangChain程序内部机制,探索了AgentExecutor究竟是如何思考(Thought)、执行(Execute/Act)和观察(Observe)的,这些步骤之间的紧密联系就是代理在推理(Reasoning)和工具调用过程中的“生死因果”。
现在我们趁热打铁,再学习几种更为复杂的代理:Structured Tool Chat(结构化工具对话)代理、Self-Ask with Search(自主询问搜索)代理、Plan and execute(计划与执行) 代理。
什么是结构化工具
LangChain的第一个版本是在 2022 年 11 月推出的,当时的设计是基于 ReAct 论文构建的,主要围绕着代理和工具的使用,并将二者集成到提示模板的框架中。
早期的工具使用十分简单,AgentExecutor引导模型经过推理调用工具时,仅仅能够生成两部分内容:一是工具的名称,二是输入工具的内容。而且,在每一轮中,代理只被允许使用一个工具,并且输入内容只能是一个简单的字符串。这种简化的设计方式是为了让模型的任务变得更简单,因为进行复杂的操作可能会使得执行过程变得不太稳定。
不过,随着语言模型的发展,尤其是出现了如 gpt-3.5-turbo 和 GPT-4 这样的模型,推理能力逐渐增强,也为代理提供了更高的稳定性和可行性。这就使得 LangChain 开始考虑放宽工具使用的限制。
2023年初,LangChain 引入了“多操作”代理框架,允许代理计划执行多个操作。在此基础上,LangChain 推出了结构化工具对话代理,允许更复杂、多方面的交互。通过指定AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 这个代理类型,代理能够调用包含一系列复杂工具的“结构化工具箱”,组合调用其中的多个工具,完成批次相关的任务集合。
举例来说,结构化工具的示例包括:
- 文件管理工具集:支持所有文件系统操作,如写入、搜索、移动、复制、列目录和查找。
- Web 浏览器工具集:官方的 PlayWright 浏览器工具包,允许代理访问网站、点击、提交表单和查询数据。
下面,我们就以 PlayWright 工具包为例,来实现一个结构化工具对话代理。
先来看一看什么是 PlayWright 工具包。
什么是 Playwright
Playwright是一个开源的自动化框架,它可以让你模拟真实用户操作网页,帮助开发者和测试者自动化网页交互和测试。用简单的话说,它就像一个“机器人”,可以按照你给的指令去浏览网页、点击按钮、填写表单、读取页面内容等等,就像一个真实的用户在使用浏览器一样。
Playwright支持多种浏览器,比如Chrome、Firefox、Safari等,这意味着你可以用它来测试你的网站或测试应用在不同的浏览器上的表现是否一致。
下面我们先用 pip install playwright 安装Playwright工具。
不过,如果只用pip安装Playwright工具安装包,就使用它,还不行,会得到下面的信息。
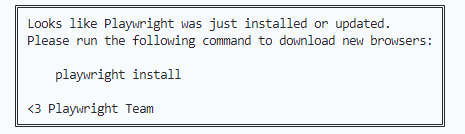
因此我们还需要通过 playwright install 命令来安装三种常用的浏览器工具。

现在,一切就绪,我们可以通过Playwright浏览器工具来访问一个测试网页。
from playwright.sync_api import sync_playwright
def run():
# 使用Playwright上下文管理器
with sync_playwright() as p:
# 使用Chromium,但你也可以选择firefox或webkit
browser = p.chromium.launch()
# 创建一个新的页面
page = browser.new_page()
# 导航到指定的URL
page.goto('https://langchain.com/')
# 获取并打印页面标题
title = page.title()
print(f"Page title is: {title}")
# 关闭浏览器
browser.close()
if __name__ == "__main__":
run()
这个简单的Playwright脚本,它打开了一个新的浏览器实例。过程是:导航到指定的URL;获取页面标题并打印页面的标题;最后关闭浏览器。
输出如下:
这个脚本展示了Playwright的工作方式,一切都是在命令行里面直接完成。它不需要我们真的去打开Chome网页,然后手工去点击菜单栏、拉动进度条等。
下面这个表,我列出了使用命令行进行自动化网页测试的优势。

现在你了解了Playwright这个工具包的基本思路,下面我们就开始使用它来作为工具集,来实现结构化工具对话代理。
使用结构化工具对话代理
在这里,我们要使用的Agent类型是STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION。要使用的工具则是PlayWrightBrowserToolkit,这是LangChain中基于PlayWrightBrowser包封装的工具箱,它继承自 BaseToolkit类。
PlayWrightBrowserToolkit 为 PlayWright 浏览器提供了一系列交互的工具,可以在同步或异步模式下操作。
其中具体的工具就包括:
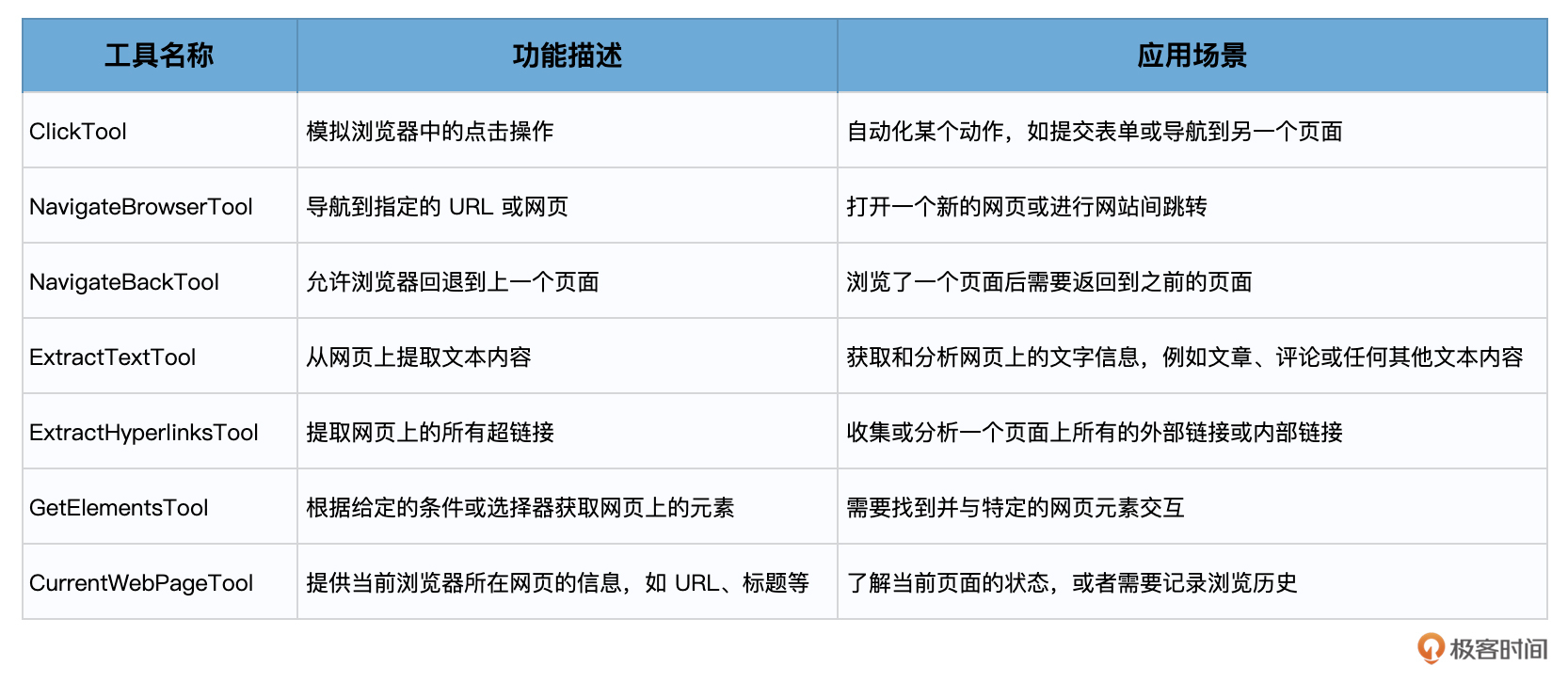
下面,我们就来看看结构化工具对话代理是怎样通过组合调用PlayWrightBrowserToolkit中的各种工具,自动完成我们交给它的任务。
from langchain.agents.agent_toolkits import PlayWrightBrowserToolkit
from langchain.tools.playwright.utils import create_async_playwright_browser
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
print(tools)
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatAnthropic, ChatOpenAI
# LLM不稳定,对于这个任务,可能要多跑几次才能得到正确结果
llm = ChatOpenAI(temperature=0.5)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
async def main():
response = await agent_chain.arun("What are the headers on python.langchain.com?")
print(response)
import asyncio
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
在这个示例中,我们询问大模型,网页python.langchain.com中有哪些标题目录?
很明显,大模型不可能包含这个网页的内部信息,因为ChatGPT完成训练的那一年(2021年9月),LangChain还不存在。因此,大模型不可避免地需要通过PlayWrightBrowser工具来解决问题。
第一轮思考
代理进入AgentExecutor Chain之后的第一轮思考如下:

这里,我对上述思考做一个具体说明。
I can use the “navigate_browser” tool to visit the website and then use the “get_elements” tool to retrieve the headers. Let me do that.
这是第一轮思考,大模型知道自己没有相关信息,决定使用PlayWrightBrowserToolkit工具箱中的 navigate_browser 工具。
Action:```{“action”: “navigate_browser”, “action_input”: {“url”: “https://python.langchain.com”}}```
行动:通过Playwright浏览器访问这个网站。
Observation: Navigating to https://python.langchain.com returned status code 200
观察:成功得到浏览器访问的返回结果。
在第一轮思考过程中,模型决定使用PlayWrightBrowserToolkit中的navigate_browser工具。
第二轮思考
下面是大模型的第二轮思考。

还是对上述思考做一个具体说明。
Thought:Now that I have successfully navigated to the website, I can use the “get_elements” tool to retrieve the headers. I will specify the CSS selector for the headers and retrieve their text.
第二轮思考:模型决定使用PlayWrightBrowserToolkit工具箱中的另一个工具 get_elements,并且指定CSS selector只拿标题的文字。
Action: ```{“action”: “get_elements”, “action_input”: {“selector”: “h1, h2, h3, h4, h5, h6”, “attributes”: [“innerText”]}}```
行动:用Playwright的 get_elements 工具去拿网页中各级标题的文字。
Observation: [{“innerText”: “Introduction”}, {“innerText”: “Get started”}, {“innerText”: “Modules”}, {“innerText”: “Model I/O”}, {“innerText”: “Data connection”}, {“innerText”: “Chains”}, {“innerText”: “Agents”}, {“innerText”: “Memory”}, {“innerText”: “Callbacks”}, {“innerText”: “Examples, ecosystem, and resources”}, {“innerText”: “Use cases”}, {“innerText”: “Guides”}, {“innerText”: “Ecosystem”}, {“innerText”: “Additional resources”}, {“innerText”: “Support”}, {“innerText”: “API reference”}]
观察:成功地拿到了标题文本。
在第二轮思考过程中,模型决定使用PlayWrightBrowserToolkit中的get_elements工具。
第三轮思考
下面是大模型的第三轮思考。
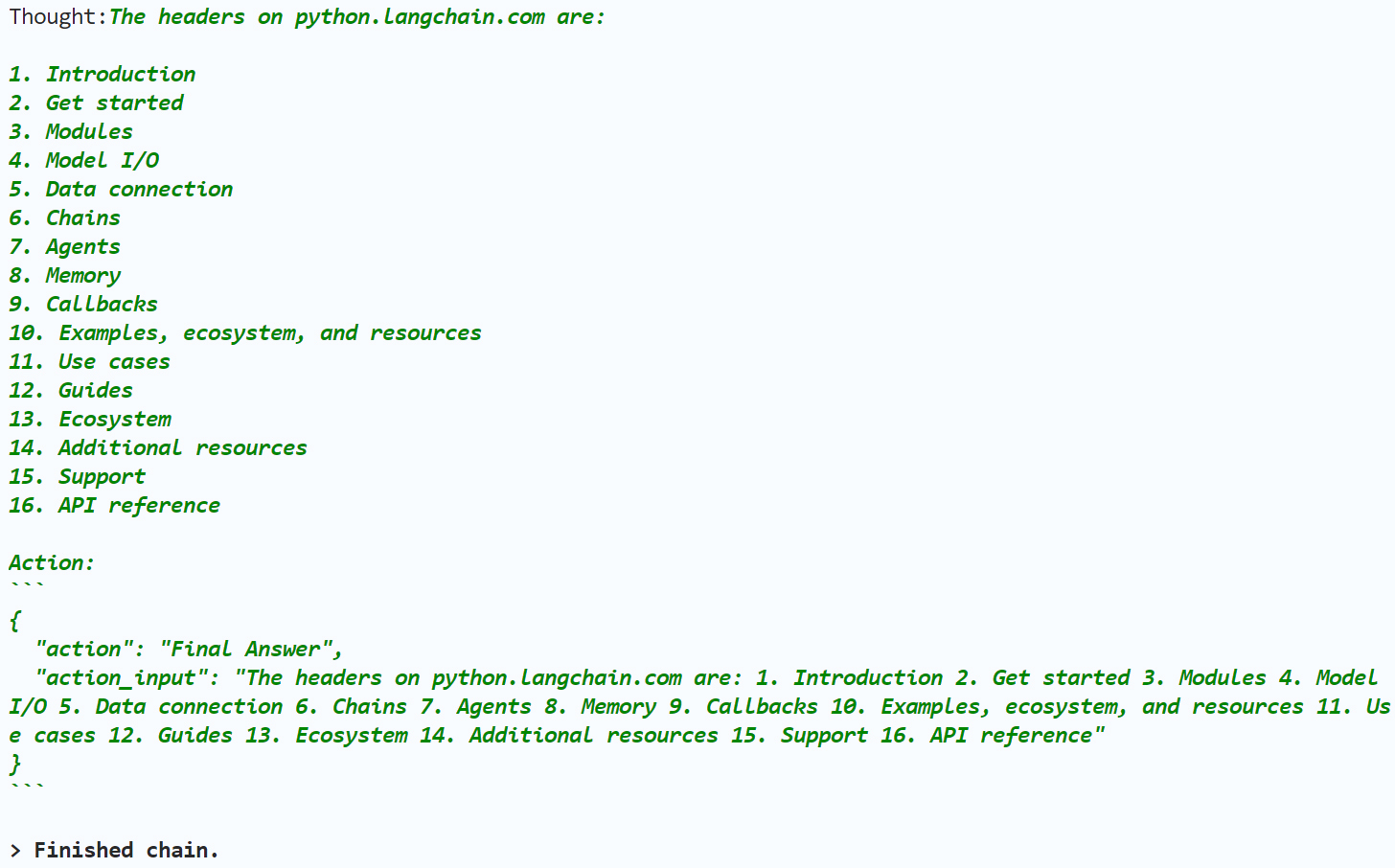
对上述思考做一个具体说明。
Thought:The headers on python.langchain.com are:
- Introduction … …
- API reference
第三轮思考:模型已经找到了网页中的所有标题。
Action:
{ "action": "Final Answer", "action_input": "The headers on python.langchain.com are: 1. Introduction 2. Get started 3. Modules 4. Model I/O 5. Data connection 6. Chains 7. Agents 8. Memory 9. Callbacks 10. Examples, ecosystem, and resources 11. Use cases 12. Guides 13. Ecosystem 14. Additional resources 15. Support 16. API reference" }
行动:给出最终答案。
AgentExecutor Chain结束之后,成功输出python.langchain.com这个页面中各级标题的具体内容。

在这个过程中,结构化工具代理组合调用了Playwright工具包中的两种不同工具,自主完成了任务。
使用 Self-Ask with Search 代理
讲完了Structured Tool Chat代理,我们再来看看Self-Ask with Search代理。
Self-Ask with Search 也是LangChain中的一个有用的代理类型(SELF_ASK_WITH_SEARCH)。它利用一种叫做 “Follow-up Question(追问)”加“Intermediate Answer(中间答案)”的技巧,来辅助大模型寻找事实性问题的过渡性答案,从而引出最终答案。
这是什么意思?让我通过示例来给你演示一下,你就明白了。在这个示例中,我们使用SerpAPIWrapper作为工具,用OpenAI作为语言模型,创建Self-Ask with Search代理。
from langchain import OpenAI, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search",
)
]
self_ask_with_search = initialize_agent(
tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True
)
self_ask_with_search.run(
"使用玫瑰作为国花的国家的首都是哪里?"
)
该代理对于这个问题的输出如下:

其实,细心的你可能会发现,“使用玫瑰作为国花的国家的首都是哪里?”这个问题不是一个简单的问题,它其实是一个多跳问题——在问题和最终答案之间,存在中间过程。
多跳问题(Multi-hop question)是指为了得到最终答案,需要进行多步推理或多次查询。这种问题不能直接通过单一的查询或信息源得到答案,而是需要跨越多个信息点,或者从多个数据来源进行组合和整合。
也就是说,问题的答案依赖于另一个子问题的答案,这个子问题的答案可能又依赖于另一个问题的答案。这就像是一连串的问题跳跃,对于人类来说,解答这类问题可能需要从不同的信息源中寻找一系列中间答案,然后结合这些中间答案得出最终结论。
“使用玫瑰作为国花的国家的首都是哪里?”这个问题并不直接询问哪个国家使用玫瑰作为国花,也不是直接询问英国的首都是什么。而是先要推知使用玫瑰作为国花的国家(英国)之后,进一步询问这个国家的首都。这就需要多跳查询。
为什么 Self-Ask with Search 代理适合解决多跳问题呢?有下面几个原因。
- 工具集合:代理包含解决问题所必须的搜索工具,可以用来查询和验证多个信息点。这里我们在程序中为代理武装了SerpAPIWrapper工具。
- 逐步逼近:代理可以根据第一个问题的答案,提出进一步的问题,直到得到最终答案。这种逐步逼近的方式可以确保答案的准确性。
- 自我提问与搜索:代理可以自己提问并搜索答案。例如,首先确定哪个国家使用玫瑰作为国花,然后确定该国家的首都是什么。
- 决策链:代理通过一个决策链来执行任务,使其可以跟踪和处理复杂的多跳问题,这对于解决需要多步推理的问题尤为重要。
在上面的例子中,通过大模型的两次follow-up追问,搜索工具给出了两个中间答案,最后给出了问题的最终答案——伦敦。
使用 Plan and execute 代理
在这节课的最后,我再给你介绍一种比较新的代理类型:Plan and execute 代理。
计划和执行代理通过首先计划要做什么,然后执行子任务来实现目标。这个想法是受到 Plan-and-Solve 论文的启发。论文中提出了计划与解决(Plan-and-Solve)提示。它由两部分组成:首先,制定一个计划,并将整个任务划分为更小的子任务;然后按照该计划执行子任务。
这种代理的独特之处在于,它的计划和执行不再是由同一个代理所完成,而是:
- 计划由一个大语言模型代理(负责推理)完成。
- 执行由另一个大语言模型代理(负责调用工具)完成。
因为这个代理比较新,它隶属于LangChain的实验包langchain_experimental,所以你需要先安装langchain_experimental这个包。
下面我们来使用一下这个代理。在这里,我们创建了Plan and execute代理,这个代理和之前看到的代理不同,它有一个Planner,有一个Executor,它们可以是不同的模型。
当然,在这个示例中,我们都使用了ChatOpenAI模型。
from langchain.chat_models import ChatOpenAI
from langchain_experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from langchain.llms import OpenAI
from langchain import SerpAPIWrapper
from langchain.agents.tools import Tool
from langchain import LLMMathChain
search = SerpAPIWrapper()
llm = OpenAI(temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
]
model = ChatOpenAI(temperature=0)
planner = load_chat_planner(model)
executor = load_agent_executor(model, tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.run("在纽约,100美元能买几束玫瑰?")
输出如下:
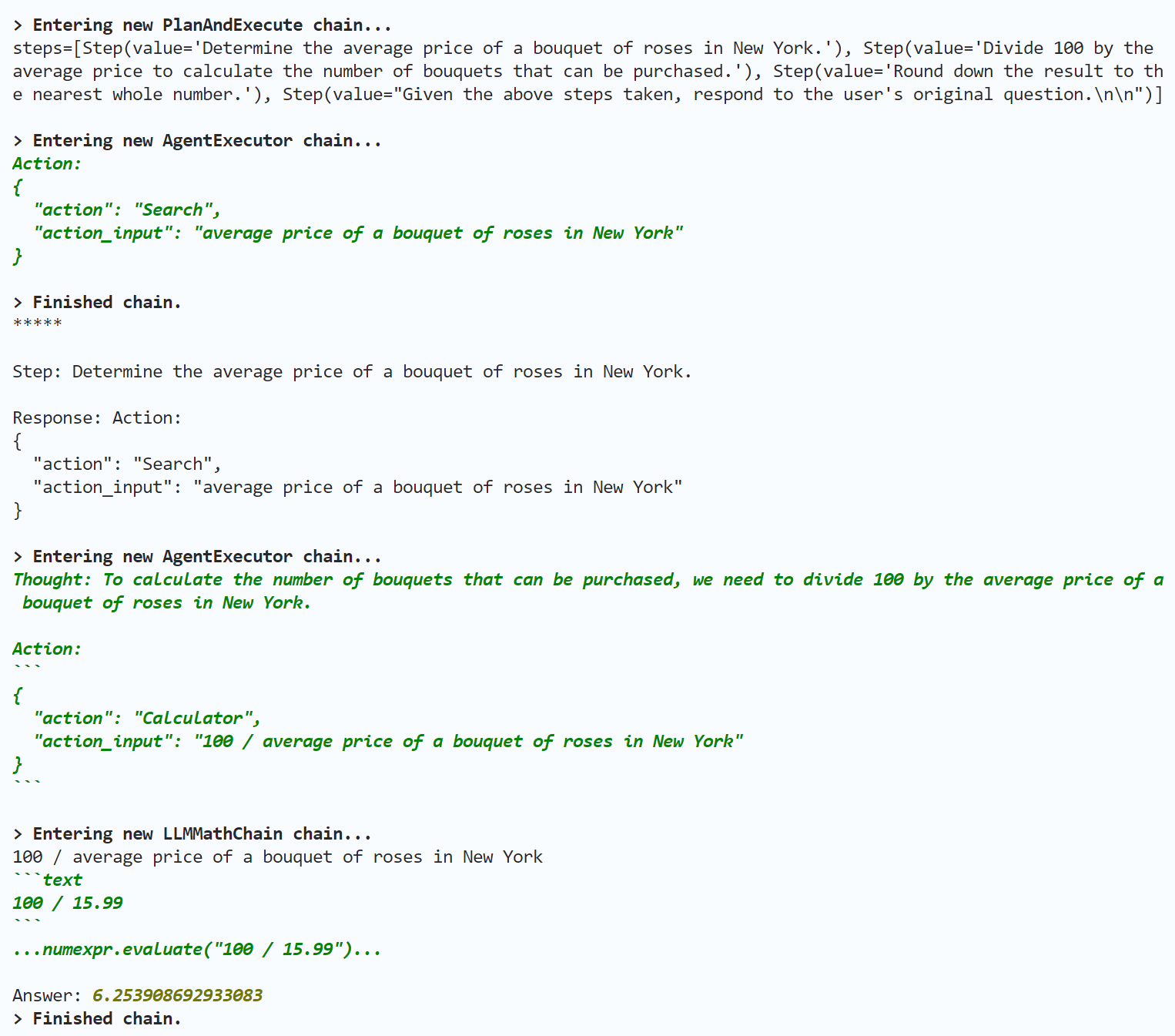
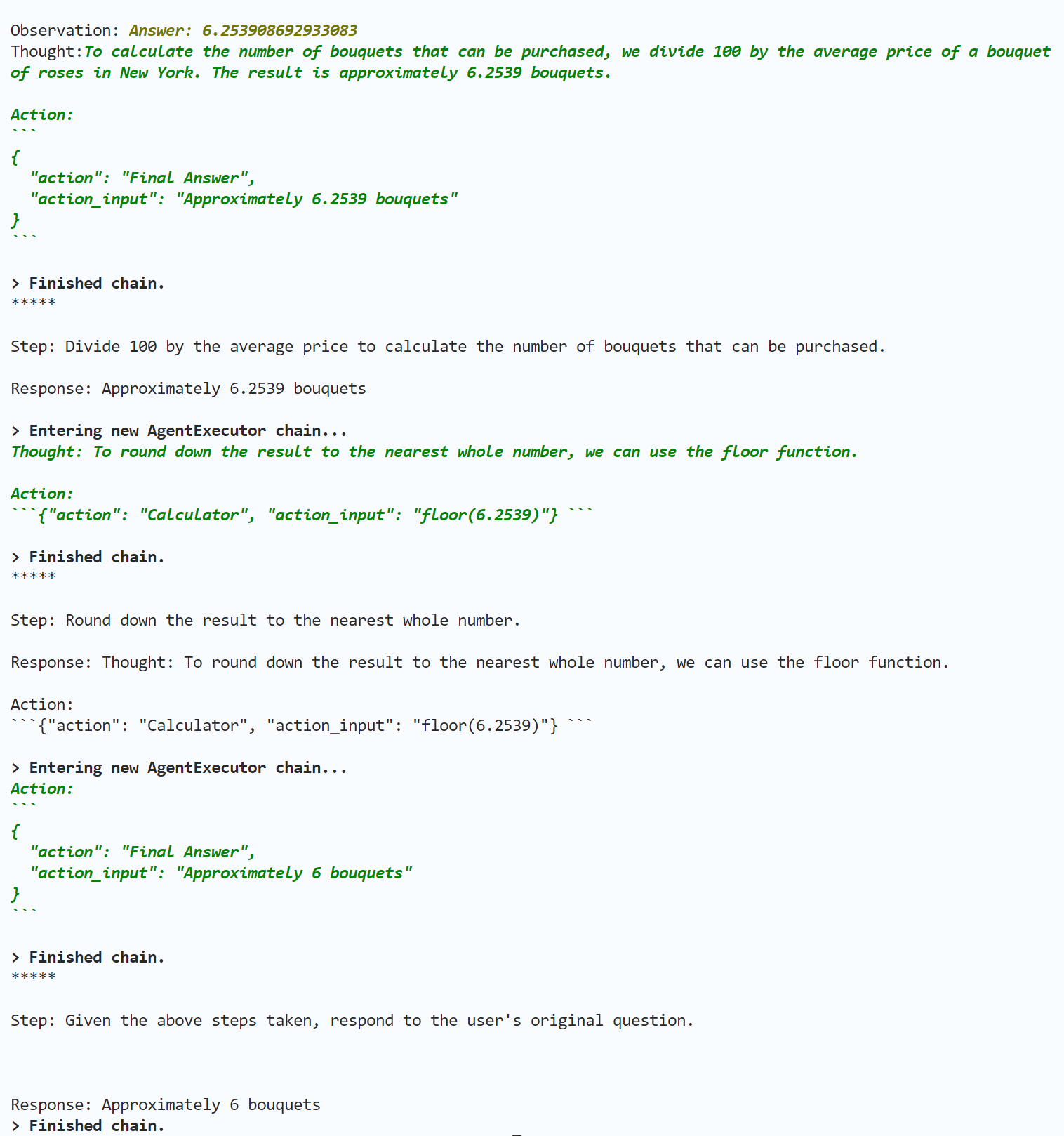
在上面输出中,PlanAndExecute 链的调用流程以及代理的思考过程,我就留给你来做分析了,相信你可以把握住Plan and execute代理解决问题的基本脉络。
总结时刻
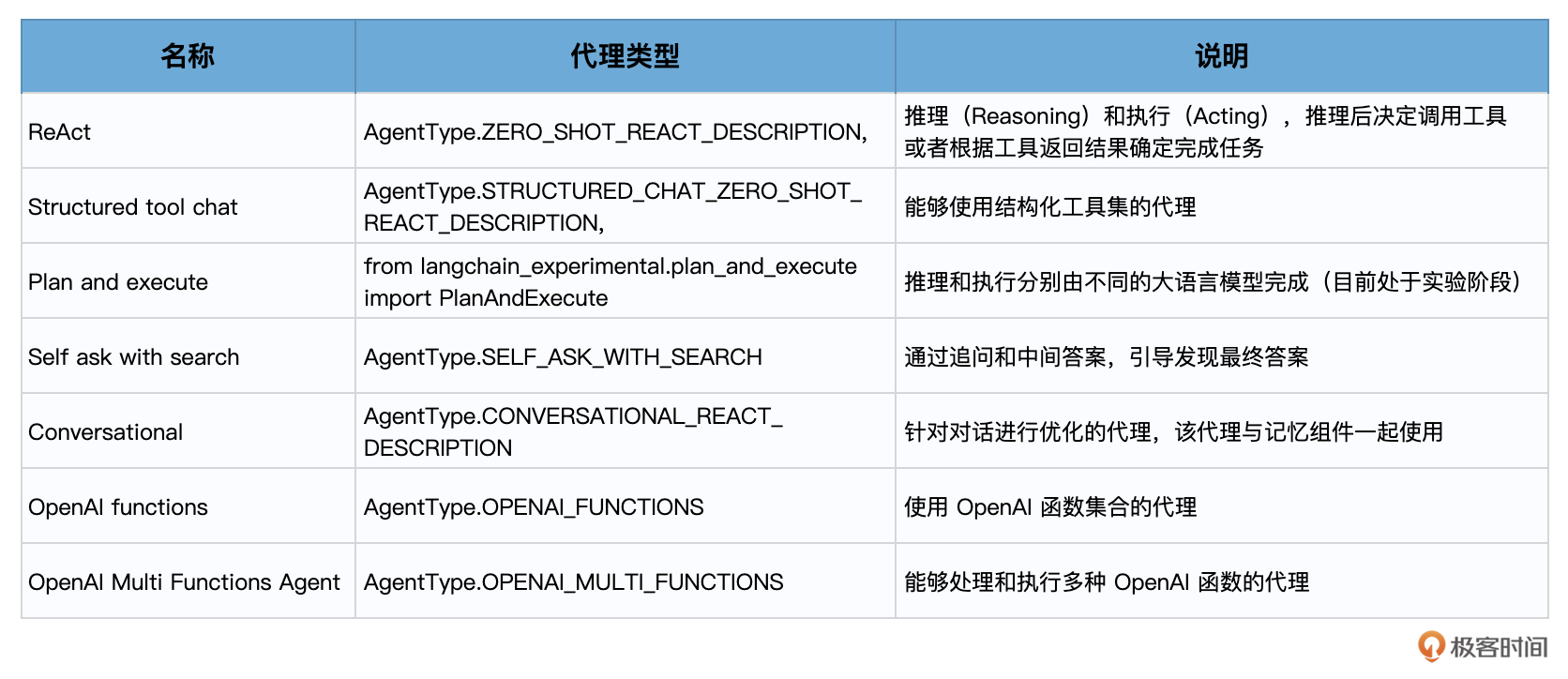
这节课是Agent的最后一课,也是LangChain所有基础知识的最后一课。我给你总结了两张的表。
第一个表,是LangChain中常见的代理类型和它们的介绍。在这些代理中,有很多我们已经一起使用过了,有些则需要你自己去阅读相关文档,自己去探索它的使用方法。
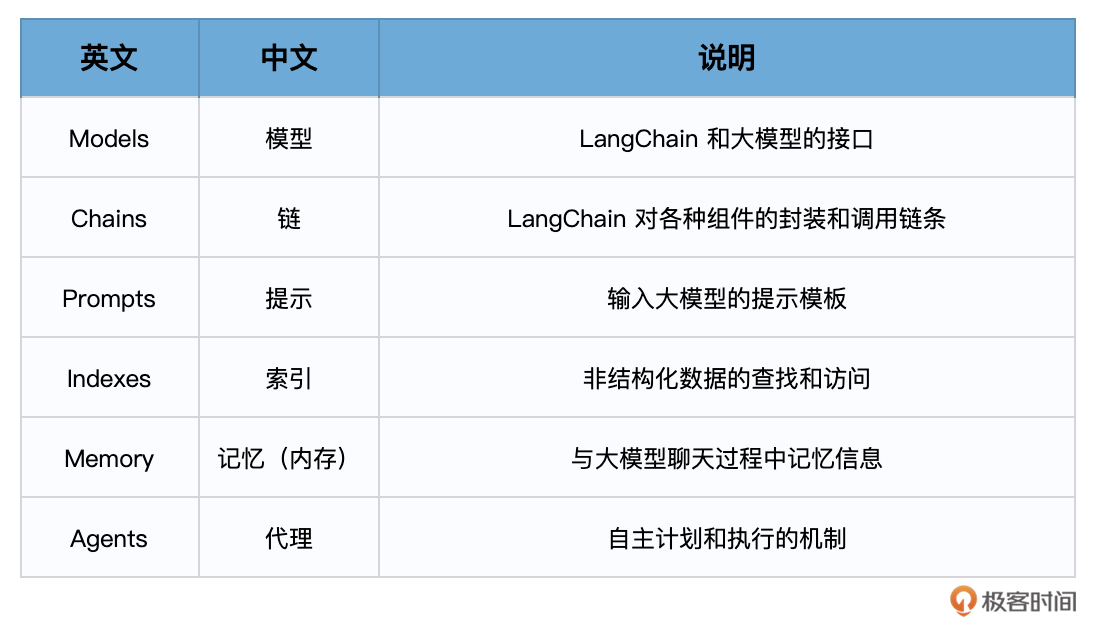
第二个表,是我对LangChain各个组件的一个简明总结。
上面这个图片,相信此时你已经不再陌生了,也掌握了它们的精髓所在。
最后还有一个问题值得讲一讲,就是图中的 Indexes,到底是什么,其实这个Indexes是LangChang早期版本的一个组件,现在已经被整合到Retrieval(数据检索)这个单元中了。而Retrieval(包括Indexes),讲的其实就是如何把离散的文档及其他信息做嵌入,存储到向量数据库中,然后再提取的过程。这个过程我们在第3课已经讲过,在后面的课程中还会再深入介绍。
")
此外,在LangChain文档中,新的6大组件中其实还有一个模块——Callbacks,目前我们尚未涉及,在后续的课程中也会介绍。
好了,LangChain的基础知识就讲到这里,从下节课起,我们将整合以前学过的各个组件的内容,为你讲解更多偏重具体应用的内容。
思考题
- 在结构化工具对话代理的示例中,请你打印出PlayWrightBrowserToolkit中的所有具体工具名称的列表。
提示:
- 在Plan and execute代理的示例中,请你分析PlanAndExecute、AgentExecutor和LLMMathChain链的调用流程以及代理的思考过程。
期待在留言区看到你的分享,如果你觉得内容对你有帮助,也欢迎分享给有需要的朋友!最后如果你学有余力,可以进一步学习下面的延伸阅读。
延伸阅读
- 代码 Github Playwright 工具包
- 论文"计划与解决"提示:通过大型语言模型改进Zero-Shot链式思考推理 Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R. K.-W., & Lim, E.-P. (2023). Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. arXiv preprint arXiv:2305.04091.
放假通知
相信细心的同学已经发现了,我们这个专栏的更新节奏还是很快的,前面的内容基本接近工作日日更。从内容的重要程度来说,基础篇其实相当重要,值此中秋&国庆双节长假来临之际,希望大家能好好休息,也能空出一段时间好好复习前面所学,所以我们的专栏计划停更一周,10月9日恢复正常更新,也期待你能把前面的思考题都做一做,我会在留言区等你的分享,与你交流探讨。最后祝大家小长假愉快,中秋阖家团圆!
- Geek_617b3f 👍(4) 💬(2)
老师请问下,ReAct框架的原理是:”大语言模型可以通过生成推理痕迹和任务特定行动来实现更大的协同作用。引导模型生成一个任务解决轨迹:观察环境 - 进行思考 - 采取行动,也就是观察 - 思考 - 行动。那么,再进一步进行简化,就变成了推理 - 行动,也就是 Reasoning-Acting 框架。“ 那么Plan and execute的方式对做Plan的那个大模型的要求不是更高么?因为做计划的那个大模型,直接就根据问题做计划了,过程中没有接收任何反馈,不像ReAct方式那样,中间是接收一些信息的。 另外这个做计划的过程,不是思维链的过程么,还是有什么区别呢? 所以…… 不是很理解为何Plan and execute是一个更灵活、更新的一种方式。还请老师答疑解惑,谢谢!
2023-11-16 - 陈东 👍(4) 💬(1)
老师节日快乐。
2023-09-30 - 抽象派 👍(2) 💬(4)
使用结构化工具对话代理的实例代码报错,请问怎么改?。具体输出如下: Traceback (most recent call last): File "/Users/abc/project/python/learnlangchain/struct_tool.py", line 17, in <module> agent_chain = initialize_agent( ^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/agents/initialize.py", line 57, in initialize_agent agent_obj = agent_cls.from_llm_and_tools( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/agents/structured_chat/base.py", line 132, in from_llm_and_tools _output_parser = output_parser or cls._get_default_output_parser(llm=llm) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/agents/structured_chat/base.py", line 65, in _get_default_output_parser return StructuredChatOutputParserWithRetries.from_llm(llm=llm) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/agents/structured_chat/output_parser.py", line 82, in from_llm output_fixing_parser = OutputFixingParser.from_llm( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/output_parsers/fix.py", line 45, in from_llm return cls(parser=parser, retry_chain=chain) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/lib/python3.11/site-packages/langchain/load/serializable.py", line 74, in __init__ super().__init__(**kwargs) File "pydantic/main.py", line 339, in pydantic.main.BaseModel.__init__ File "pydantic/main.py", line 1076, in pydantic.main.validate_model File "pydantic/fields.py", line 860, in pydantic.fields.ModelField.validate pydantic.errors.ConfigError: field "retry_chain" not yet prepared so type is still a ForwardRef, you might need to call OutputFixingParser.update_forward_refs().
2023-09-28 - SH 👍(1) 💬(1)
老师, 把离散的文档及其他信息做嵌入,存储到向量数据库中,然后再提取的过程。 这类利用大模型的时候(比如:openai 的 api) 这类的数据是否会被大模型 获取到? 导致信息泄露~
2023-11-05 - 抽象派 👍(1) 💬(1)
老师,在使用plan and execute代理时,推理的上下文比较大的时候,结果就不太如意了。例如:一个go项目,我要求给指定的方法增加一个日志输出的代码逻辑,然后代理读取了整个源代码文件,最后代码是加了,但是只有那个方法还保留着是完整的,其他的代码就没了。请问这种情况有什么手段可以优化吗?
2023-10-11 - 抽象派 👍(1) 💬(1)
老师,agent可以结合chain来用吗?有示例吗?
2023-10-10 - 陈东 👍(1) 💬(1)
老师好。您平时的工作业务和业务流是什么?
2023-09-30 - Final 👍(1) 💬(1)
中秋快乐 ~
2023-09-29 - iLeGeND 👍(1) 💬(1)
老师提下代码
2023-09-28 - Geek2808 👍(0) 💬(1)
对于StructedToolChat部分,异步总是有问题,可能是VPN网络的问题,改成同步方式跑起来就可以了: import os os.environ["OPENAI_API_KEY"] = 'xxxx' from langchain.agents.agent_toolkits import PlayWrightBrowserToolkit from langchain.tools.playwright.utils import create_sync_playwright_browser sync_browser = create_sync_playwright_browser() toolkit = PlayWrightBrowserToolkit.from_browser(sync_browser=sync_browser) tools = toolkit.get_tools() print(tools) from langchain.agents import initialize_agent, AgentType from langchain.chat_models import ChatOpenAI # LLM不稳定,异步方式总是得不到结果。尝试使用同步方式 llm = ChatOpenAI(temperature=0.5) agent_chain = initialize_agent( tools, llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True, ) def main(): response = agent_chain.run("What are the headers on python.langchain.com?") print(response) main()
2024-01-09 - shatu 👍(0) 💬(1)
Plan and execute受限于大模型的不稳定性,还是可能出错,而且一步错步步错,这对于复杂多步骤流程还是很有挑战性【Thought:To calculate the number of bouquets that can be purchased, you need to divide 100 by the average price of a bouquet of roses in New York. Action:
> Entering new LLMMathChain chain... 100 / (63.98 + 56.99 + 18.70)```text 100 / (63.98 + 56.99 + 18.70) ``` ...numexpr.evaluate("100 / (63.98 + 56.99 + 18.70)")... Answer: 0.7159733657907926】2023-11-17 - Geek_995b81 👍(0) 💬(1)
老师,结构化工具那一个demo,比如模型决定使用 PlayWrightBrowserToolkit 中的 get_elements 工具。这里我们没有给他提示,他是怎么知道用get_elements工具的呢?另外,结构化工具还有其他工具吗?
2023-10-31 - Monin 👍(0) 💬(3)
老师 请教下 Plan and execute和之前说的ReAct感觉很相似 都可以概括为推理+行动? 那两者的区别是啥? 我个人理解是 ①Plan and execute可以由两个LLM代理完成 ReAct一般由一个LLM完成整个推理+行动 ②Plan and execute由多个LLM 可以让推理+行动并行操作 实现fork-join操作 缩短执行时间
2023-10-25 - 旅梦开发团 👍(0) 💬(2)
我这里执行 playwright install 报了以下错误: Downloading Chromium 117.0.5938.62 (playwright build v1080) from https://playwright.azureedge.net/builds/chromium/1080/chromium-win64.zip Error: read ECONNRESET 大家怎么解决的
2023-10-03 - yanyu-xin 👍(1) 💬(0)
***** 修订课程中“使用结构化工具对话代理”部分的代码,改为通义千问,将旧版 langchain的改为新版本 ## 旧代码1: from langchain.agents.agent_toolkits import PlayWrightBrowserToolkit from langchain.tools.playwright.utils import create_async_playwright_browser from langchain.chat_models import ChatAnthropic, ChatOpenAI ## 新代码1:( 新版本用 langchain_community 代替 旧版本的 langchain ) from langchain_community.agent_toolkits import PlayWrightBrowserToolkit from langchain_community.tools.playwright.utils import create_async_playwright_browser from langchain_openai import ChatOpenAI ---- ## 旧代码2: llm = ChatOpenAI(temperature=0.5) ## 新代码2:(用千问模型代替 OpenAI ) llm = ChatOpenAI( api_key="KEY", # 用你的DASHSCOPE_API_KEY base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus" ) ---- ## 旧代码3: response = await agent_chain.arun("What are the headers on python.langchain.com?") ## 新代码3:(Chain.arun' 方法已弃用,改用 ainvoke ) response = await agent_chain.ainvoke("What are the headers on python.langchain.com?") **** 修订课程中“使用 Self-Ask with Search 代理”部分的中代码,用通义千问 和Perplexity ## 旧代码4 from langchain import OpenAI, SerpAPIWrapper ## 新代码4 from langchain_openai import ChatOpenAI from langchain_community.chat_models import ChatPerplexity ---- ## 旧代码5 llm = OpenAI(temperature=0) search = SerpAPIWrapper() ## 新代码5 # 用千问大模型初始化 llm = ChatOpenAI( api_key= "key", # 你的DASHSCOPE_API_KEY base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-long") # 新用Perplexity 初始化网络搜索工具 search = ChatPerplexity( temperature=0.3, pplx_api_key= ”key“, # 你的PPLX_API_KEY model="llama-3-sonar-small-32k-online") --- ## 旧代码6 func=search.run, self_ask_with_search.run( "使用玫瑰作为国花的国家的首都是哪里?" ) ## 新代码6 ,将run方法改为invote func=search.invoke, self_ask_with_search_agent.invoke("使用玫瑰作为国花的国家的首都是哪里?")
2024-08-10