02 如何善用LLaMA 3长文本处理能力?
你好,我是Tyler。
在之前的课程中,我们深入探讨了如何利用 LLaMA 模型进行对话,并明确了LLaMA 在多轮对话中的核心机制。这一机制通过存储历史对话内容,将无状态的大模型推理服务转变为有状态的多轮对话服务。
这一机制显著提升了对话系统在处理复杂对话情境时的能力,但也带来了新的挑战:随着历史对话轮次的增加,模型的输入长度也随之增长。为应对这一挑战,大模型必须具备处理长文本输入的能力,这不仅是对现有技术的扩展,也是长文本处理能力发展的关键驱动力。
本节课我们将深入探讨处理长文本输入时的关键技术工作,包括当前的解决方案、优势及其局限性。我们将系统性地分析如何优化长文本输入的处理,以满足大规模对话系统对长文本的需求,并评估这些技术方案在实际应用中的表现和潜在改进方向。
长文本处理的发展与现状
LLaMA 模型的长文本处理能力有了显著提升。从 LLaMA 2 的 2048 个 token 扩展到 4096 个 token,再到 LLaMA 3 支持的 8000 个 token,甚至通过进一步微调可以处理更长的文本。这意味着这些模型现在可以处理更长的文本,理解能力也得到了增强,生成的回应更加连贯,相关性也更强。图表展示了不同模型在长文本处理方面的进展。
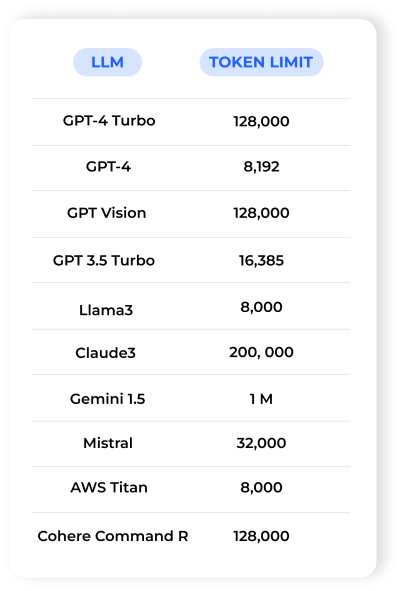
长文本处理的发展不仅是技术的进步,也是对实际应用需求的响应。长文本处理的能力直接影响到大规模对话系统在复杂场景下的表现。
LLM 长文本的必要性
在开篇的时候,我们提到了长文本对多轮对话的重要性,包括智能体自我或彼此之间的复杂提示词应用场景。长文本支持的多轮对话场景中,提示词的长度限制会影响智能体的思考深度。
下图展示了基于 ReAct 提示词的智能体多轮思考能力。可以观察到,智能体在每一步根据最新的外部数据判断是否能够完成任务。提示词的长度在一定程度上限制了智能体思考的深度。

以下是一个代码示例,展示如何使用 LLaMA 进行对话任务:
from langchain_ollama.llms import OllamaLLM
from langchain.agents import load_tools, initialize_agent
from langchain.tools import Tool
import numexpr as ne
# 定义数学计算工具
def calculate_expression(expression):
return ne.evaluate(expression).item() # 使用 numexpr 计算表达式并返回结果
math_tools = [
Tool(
name="Numexpr Math",
func=calculate_expression,
description="一个能够进行高效数学计算的工具,参数是输入的数学表达式"
)
]
# 初始化 LLM
llm = OllamaLLM(model="llama3")
# 定义 agent
agent = initialize_agent(
tools=math_tools, # 使用自定义的数学计算工具
llm=llm,
agent_type="zero-shot-react-description",
verbose=True,
agent_kwargs={"handle_parsing_errors": True} # 处理解析错误
)
# 用户问题
user_question = "What is 37593 * 67?"
print(f"用户问题:{user_question}")
# 执行并打印结果
response = agent.run(user_question)
print(response)
假设上述代码处理一个关于计算问题的初始提示,并经过多轮对话,可能的输出如下:
Question: What is 37593 * 67?
Thought: Let's get started!
Thought: I need to perform a mathematical operation using Numexpr Math.
Action: Numexpr Math
Action Input: 37593 * 67
Observation: 2518731
Thought:I'm excited to help! Here are the answers:
Final Answer: 2518731
> Finished chain.
但是这都谈不上长文本输入的刚需,因为存在一些提示词压缩的替代方案。真正长文本的“刚需”场景,我们只能把一个完整的文件放进去,需要通过上下文内容联合分析,才能生成出目标内容的场景。
长文本处理的“刚需”场景包括处理完整的文档,如文章、代码、脚本、报告等。以下是一个将 Python 代码翻译为 JavaScript 的例子,展示了全文输入的必要性:
import ollama
def translate_code_to_js(python_code):
# 优化翻译提示
prompt = f"""
You are a code translation assistant. Your task is to translate Python code into JavaScript while ensuring the following:
1. Maintain the original logic and functionality.
2. Adapt Python-specific constructs to their JavaScript equivalents.
3. Use clear and idiomatic JavaScript syntax.
Here is the Python code you need to translate:
Python Code:
{python_code}
Please provide the corresponding JavaScript code below:
JavaScript Code:
"""
# 使用 Ollama 模型 'llama3' 进行对话
response = ollama.chat(model='llama3', messages=[
{
'role': 'user',
'content': prompt,
},
])
# 获取生成的 JavaScript 代码
js_code = response['message']['content']
return js_code
# 示例 Python 代码
python_code = """
def fibonacci(n):
a, b = 0, 1
while n > 0:
yield a
a, b = b, a + b
n -= 1
for number in fibonacci(5):
print(number)
"""
# 调用函数并打印 JavaScript 代码
print(translate_code_to_js(python_code))
输出的代码:
function* fibonacci(n) {
let a = 0, b = 1;
for (let i = 0; i < n; i++) {
yield a;
[a, b] = [b, a + b];
}
}
for (const number of fibonacci(5)) {
console.log(number);
}
这个例子表明,通过多次输入不同的代码片段,很难让模型生成全局一致的变量声明和逻辑表达。因此,长文本输入在一些场景下是不可或缺的。
长文本处理能力的快速发展,不由让大家提出了一个新的问题:提示语工程方法,比如 RAG 和思维链(CoT),是否仍然必要?
长文本处理的局限性
长文本处理性能问题
上节课我们讨论了LLaMA生成内容的方法。我们了解到,LLaMA在处理长文本时,会面临很大的算力开销。接下来,我们将更详细地了解LLaMA的工作原理,特别是它的自回归生成机制如何影响推理时的算力需求,以及为什么长文本会消耗更多资源。
这里快速回顾一下,LLaMA模型的文本生成依赖于自回归方法。自回归生成方法逐步生成每一个词:
- 初始化上下文:模型从一个起始文本或种子信息开始。
- 预测下一个词:每生成一个新词,模型会根据当前上下文(已经生成的词)来预测下一个最可能的词。它会计算当前上下文与词汇表中所有可能词汇的相似度,找到最合适的下一个词。
- 更新上下文:生成的新词会被添加到上下文中,模型会更新状态,准备生成下一个词。这一过程会一直进行,直到生成完整的文本。
自回归方法的推理算力开销和输入文本的长度有很大关系。
- 自注意力机制的计算复杂度:由于自注意力机制的计算复杂度为O(n^2),其中n是序列长度,处理长文本时计算复杂度会显著增加。每新增一个位置,模型需要处理和记忆整个上下文,从而导致计算时间和资源需求以平方级增长。
- 显存占用:处理长文本不仅增加了计算复杂度,还增加了显存的需求。由于模型需要在生成每一个词时保留和计算之前所有位置的状态,显存占用也随序列长度增加而增加。
因此,尽管LLaMA模型在处理文本生成时展现了强大的能力,但长文本的输入仍然会导致显著的资源消耗。这包括计算时间和显存的需求。因此,在实际应用中,需要对长文本进行合理的裁剪和预处理,以平衡资源的消耗并保持模型的高效运行。
生成长文本通常需要大量的计算和通信资源,并且耗时较长。在这种情况下,RAG 的关键作用是提升生成质量的同时保持效率。例如,在处理长文档时,我们往往只需要其中的一个关键片段来回答问题。下面基于向量数据库和 LLaMA 3 RAG 的例子可以很好地说明这一点。
import chromadb
from chromadb.config import Settings
from FlagEmbedding import BGEM3FlagModel
import ollama # 导入Ollama库
# 初始化Chroma数据库
chroma_client = chromadb.PersistentClient(path="./chromadb")
# 创建一些测试文档
documents = [
{
"page_content": "合同是两方或多方之间的法律协议,通常包括各方的权利和义务。合同必须具备合法性和可执行性。",
"metadata": {"id": "doc1"}
},
{
"page_content": "在合同中,主要义务包括:1) 付款义务,2) 商品交付义务,3) 相关服务的提供。合同中的这些义务必须在约定的时间内履行。",
"metadata": {"id": "doc2"}
},
{
"page_content": "合同的解除通常需要双方的同意,或者由于法律规定的特殊情况,如违约或不可抗力事件。",
"metadata": {"id": "doc3"}
},
{
"page_content": "违约责任是指一方未能履行合同义务时,应承担的法律后果,通常包括赔偿损失和继续履行合同的责任。",
"metadata": {"id": "doc4"}
},
{
"page_content": "在合同生效之前,所有相关方必须理解合同条款,并同意其内容。签字是合同生效的重要标志。",
"metadata": {"id": "doc5"}
},
{
"page_content": "合约的履行必须符合诚信原则,即各方应诚实守信地履行自己的义务,并尊重对方的合法权益。",
"metadata": {"id": "doc6"}
},
{
"page_content": "在合同争议中,双方可通过调解、仲裁或诉讼的方式解决争端。选择合适的方式取决于争议的性质及金额。",
"metadata": {"id": "doc7"}
},
{
"page_content": "关于合同的法律法规各国有所不同,了解适用的法律条款是签订合同前的重要步骤。",
"metadata": {"id": "doc8"}
}
]
# 初始化BGE M3模型
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
# 将文档添加到向量存储中
documentation_collection = chroma_client.get_or_create_collection(name="legal_docs")
# 生成文档嵌入并添加到集合中
for doc in documents:
embedding = model.encode([doc['page_content']], batch_size=1)['dense_vecs'][0]
documentation_collection.add(
ids=[doc['metadata']['id']], # 假设文档有唯一的id
embeddings=[embedding],
documents=[doc['page_content']]
)
# 查询示例
query = "合同中的主要义务是什么?"
query_embedding = model.encode([query], batch_size=1)['dense_vecs'][0]
# 执行向量查询
results = documentation_collection.query(
query_embeddings=[query_embedding],
n_results=1 # 获取最相似的一个结果
)
# 提取检索到的文档内容
data = results['documents'][0] # 假设只检索到一个结果
document_content = data # 这里取出文档内容
# 将上下文与查询一起传递给 Ollama LLM
prompt = f"根据以下信息,请回答:{query}"
# 使用Ollama生成响应
output = ollama.chat(model='llama3', messages=[
{
'role': 'user',
'content': f"使用以下数据:{document_content}. 响应这个提示:{prompt}"
},
])
# 输出生成的结果
print("生成的结果:", output['message']['content'])
在这段代码中,RAG 模型通过检索与问题相关的文本片段来生成回应。这种方法可以减少长文本处理的计算负担,提高响应速度。
另一方面,思维链方法可以提升生成内容的质量,但长文本的信息量过大时,LLM(大语言模型)的指令理解能力会显著下降。这与思维链的目标,即通过分解和聚焦指令,正好相反。通过思维链多步推理的 Python 例子,可以更清楚地看到这一点。
from langchain.chains import LLMChain, SequentialChain
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
# 创建 LLM 实例
llm = OllamaLLM(model="llama3") # 使用 Ollama 模型
def create_chain(template: str, input_vars: list, output_key: str) -> LLMChain:
"""创建 LLMChain 实例"""
prompt = PromptTemplate(
input_variables=input_vars,
template=template
)
return LLMChain(llm=llm, prompt=prompt, output_key=output_key)
# 第一步:头脑风暴解决方案
template_step1 = """
步骤 1:
我面临一个关于{input}的问题。请提供三个不同的解决方案,考虑到以下因素:{perfect_factors}。
A:
"""
chain1 = create_chain(template_step1, ["input", "perfect_factors"], "solutions")
# 第二步:评估解决方案
template_step2 = """
步骤 2:
请评估以下解决方案的优缺点、实施难度和预期结果,并为每个方案分配成功概率和信心水平。
{solutions}
A:
"""
chain2 = create_chain(template_step2, ["solutions"], "review")
# 第三步:深化思考过程
template_step3 = """
步骤 3:
请深入分析每个解决方案,提供实施策略、所需资源和潜在障碍,同时考虑意外结果及应对措施。
{review}
A:
"""
chain3 = create_chain(template_step3, ["review"], "deepen_thought_process")
# 第四步:排序解决方案
template_step4 = """
步骤 4:
根据评估和分析结果,对解决方案进行排序,说明理由,并给出最终考虑。
{deepen_thought_process}
A:
"""
chain4 = create_chain(template_step4, ["deepen_thought_process"], "ranked_solutions")
# 将各个链条连接起来
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=["input", "perfect_factors"],
output_variables=["ranked_solutions"],
verbose=True
)
# 示例输入
result = overall_chain({
"input": "人类对火星的殖民",
"perfect_factors": "地球与火星之间的距离非常遥远,使得定期补给变得困难"
})
print(result)
因此,CoT 和 RAG 依然是提升长文本生成质量的重要方法,仍然具有不可或缺的价值。
面向超长文本的定制与优化
随着大模型技术的发展,处理超长文本的能力也在不断提升,除了我们前面提到的标准版本 LLaMA之外,我们还有专门针对超长文本处理的定制版本。例如,针对法律文书的处理,我们可以利用 1M(百万级别)上下文长度的模型来处理复杂的法律文本。这些超长文本处理能力可以有效地解决全局用词一致性问题。以下是一些面向长文本的优化版本:
import ollama
with open('data/legal_document.txt', 'r', encoding='utf-8') as f:
legal_text = f.read()
# 系统提示词,指定模型的背景信息和回答风格
SYSTEM_PROMPT = f'法律文书内容: {legal_text}\n\n' + """
上下文: 你是一个法律助手,基于提供的法律文书内容提供答案。
你只能讨论文书中的内容。用户将询问有关文书的具体问题,你需要基于文书内容提供详细的回答。
如果信息不足以回答问题,请要求用户提供更具体的文书部分。
"""
QUESTION = '文中关于合同中的主要义务的描述是否一致?'
# 构造聊天消息
messages = [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': QUESTION},
]
# 调用Ollama的LLM生成结果
response = ollama.chat(model='llama3-gradient', messages=messages)
# 输出结果
print('\n\n')
print(f'系统提示: ...{SYSTEM_PROMPT[-500:]}') # 打印最后500个字符的系统提示
print(f'用户提问:', QUESTION)
print('回答:')
print(response['message']['content']) # 输出生成的回答
小结
好的,我们来总结一下这节课的内容吧。这节课我们讨论了长文本处理的几个关键点。
首先,我们聊到了长文本处理的现状以及它在多轮对话、智能体和上下文分析中的重要性。长文本处理能力现在成了各大公司争相提升的焦点,因为它在处理复杂信息时的价值非常大。
但要注意,长文本处理并不是万能的解决方案。由于LLM的Next Token Prediction的特性,处理长文本会消耗很多算力,所以我们得在必要时才用它。也就是说,虽然长文本处理很重要,但它的高计算开销意味着我们要谨慎使用。
另外,虽然像CoT这样的多步推理技术在优化性能方面表现不错,但它们还不能完全替代长文本处理的能力。这说明我们需要学会在实际应用中,判断什么时候该用长文本处理,什么时候可以用其他优化方法。
最后,我们举了一个例子,展示了针对长文本优化的LLaMA 3模型。这个模型能处理百万级别的数据,并在一些特定场景中展现了它的独特价值。这个例子说明了长文本处理在实际应用中的潜力和必要性。
思考题
具备长文本处理能力后,是否意味着我们可以将所有内容一并交给大模型处理呢?欢迎你把思考后的结果分享到留言区,和我一起讨论,如果你觉得这节课的内容对你有帮助的话,欢迎你分享给其他朋友,我们下节课再见!
- 小虎子11🐯 👍(1) 💬(0)
课程代码地址:https://github.com/tylerelyt/LLaMa-in-Action
2024-11-25 - 午夜修铃 👍(0) 💬(0)
Windows本地模型,使用ollama时如何调用本地显卡?
2024-12-17 - 午夜修铃 👍(0) 💬(0)
生成的结果: 根据给出的数据,合同中的主要义务包括: 1. 付款义务 2. 商品交付义务 3. 相关服务的提供 Exception ignored in: <function AbsEmbedder.__del__ at 0x00000174DDF64540> Traceback (most recent call last): File "C:\Users\xxx\miniconda3\Lib\site-packages\FlagEmbedding\abc\inference\AbsEmbedder.py", line 270, in __del__ File "C:\Users\xxx\miniconda3\Lib\site-packages\FlagEmbedding\abc\inference\AbsEmbedder.py", line 89, in stop_self_pool TypeError: 'NoneType' object is not callable 这里报错了。 flagembedding 1.3.3
2024-12-17 - 江慧明 👍(0) 💬(0)
具备长文本处理能力,也意味着需要更多资源,显存资源,CPU资源,也意味着回答用户问题需要更长时间,所以具备长文本处理能力模型,在具体实践中也不能毫无节制使用,而是充分有理由使用,为取得速度、资源、上下文的平衡,我们需要充分设计,利用langchain工具,可以把问题拆分多个聚焦点,然后用LLM快速获得答案,然后再讲问题组合
2024-11-30 - 旅梦开发团 👍(0) 💬(0)
在合同RAG的案例中 我安装FlagEmbedding报错了,可能是python版本的问题。 我使用nomic-embed-text:latest 嵌入模型代替, 大家也可以试试。 我的完整代码如下 ```python # 向量数据库 import chromadb # Settings 配置 from chromadb.config import Settings # 生成器嵌入 图像处 自然语言处理 # from FlagEmbedding import BGEM3FlagModel import ollama chroma_client = chromadb.PersistentClient(path="./chromadb") # document, metadata embedding documents = [ ... ] documentation_collection = chroma_client.get_or_create_collection(name="legal_docs") for doc in documents: embedding = ollama.embeddings(model='nomic-embed-text:latest',prompt=doc['page_content']) # print(embedding.get('embedding')) # id, embedding, 原内容 documentation_collection.add( ids=[doc['metadata']['id']], embeddings=embedding.get('embeddings'), documents=[doc['page_content']] ) query = "合同是什么?" query_embedding = ollama.embeddings(model='nomic-embed-text:latest', prompt=query) query_embedding = query_embedding.get('embedding')[:384] # print(query_embedding.get()) # # # 根据embedding 查询 results = documentation_collection.query( query_embeddings = query_embedding, n_results=1 ) # # # # 取出原内容 data = results['documents'][0] document_content = data prompt = f"根据一下信息, 请回答:{query}" output = ollama.chat(model='qwen2.5:latest', messages=[ { 'role': 'user', 'content': f"使用一下数据:{document_content},响应这个提示:{prompt}" } ]) print("生成的结果:", output['message']['content']) ```
2024-10-29 - willmyc 👍(0) 💬(0)
超长文本是否应该考虑跟llama3多轮对话的情况,llama3如何处理,可否介绍一下,谢谢!
2024-10-22