03 LLaMA 3的应用探索:指令跟随的最佳实践
你好,我是Tyler。
在上一节课中,我们深入探讨了大模型在处理长文本方面的能力。这一能力让我们在面对长篇代码文件或大量文字资料时,能够借助大模型进行高效的分析和处理。然而,即便如此,LLaMA 3 的能力在传统的“对话框”中仍然受到一定的限制。
从“对话框”到更广阔的世界
我们都知道,像 ChatGPT 这样的工具最早其实只是一个对话机器人,主要是跟人聊天,功能相对简单。但随着技术的进步,它不再局限于“对话框”里,变成了现在多功能的智能助手。能有这么大的进步,关键在于大模型具备了指令跟随的能力(Instruction Following)。简单说,指令跟随能力就是大模型可以根据用户的指令,通过使用特定的工具,完成一些比较复杂的任务。
比如,现在的 ChatGPT 插件功能就是一个很好的例子。以前 ChatGPT 主要是靠输入输出文本进行对话,而插件功能让它可以调用外部工具,去执行各种任务。不管是查找信息、进行计算,还是和其他软件协同工作,都是可以的。
指令跟随能力是 LLaMA 3 打破“对话框”限制的核心。这种能力使模型不仅能理解用户的指令,还能通过调用特定的工具或模块来执行复杂的任务。通过提升指令跟随能力,LLaMA 3 可以实现从简单对话机器人到多功能智能助手的转变。
指令指令跟随能力的本质是什么?
你有没有想过,大语言模型是如何使用这些插件的呢?这个能力背后的技术基础叫做指令微调(Instruction Tuning)。你可能注意到,现在几乎所有主流的大模型都有一个 Instruction 版本,这并不是巧合,而是因为指令微调大大增强了模型的任务执行能力。
指令微调,顾名思义,就是通过特定的训练,让模型能够更好地理解并执行各种指令。这种技术让大模型不仅能处理复杂任务,还能根据不同任务的要求,灵活地调用不同的工具或模块,最终完成预期的目标。这种能力是大模型能够胜任复杂任务的基础,也是它们能在智能体技术中大展拳脚的关键。
指令微调本质上是通过大量的带标签数据(包括人类对话数据、工具使用数据等)进行训练,使模型能够更好地理解和执行具体的任务指令。通过这些数据的微调,模型逐渐学会如何将复杂的指令分解为可执行的步骤,并准确调用相关工具。
- 人类对话数据:这一部分数据包括大量的对话实例,帮助模型理解自然语言中的指令,并能够做出正确的回应。
- 工具使用数据:这一部分数据集中在如何使用各种工具上,比如调用 API、执行查询等等。这类数据让模型不仅能理解指令,还能真正地操作工具来完成任务。
通过这些数据的深度学习,LLaMA 系列模型在接收到指令时,能迅速识别出任务类型,并调用相关的知识和工具来完成任务。这让模型不再局限于对话,而是能在更广泛的应用场景中发挥作用。
指令跟随能力的应用
下面我们来具体聊聊指令跟随能力的应用技巧。大多数时候,LLM 会遇到两个问题:一是它掌握的知识可能过时,二是由于知识面太广,有时候会“胡说八道”。通过让 LLM 调用工具,我们可以让它在某些问题上更靠谱。与其花费大量时间通过提示工程引导模型给出你想要的答案,不如直接让它调用工具,动态获取信息,再给出答案。
因此我们可以看出,目前大模型的主流技术,也就是我们后面将学到的智能体技术也好,检索增强生成技术也罢,都是大语言模型指令跟随能力的“深度用户”。
例如,我们可以让 LLM 从天气API中获取最新的上下文信息来回答问题。这样,它就可以先查询天气信息,再给出准确的回答,而不是直接提供可能不正确的答案。我们还可以让它组合使用多个工具,比如先用城市编码工具获取编码,然后用天气工具查询实时天气,最后返回结果。
下面是具体的代码示例:
1. 导入必要的库
from langchain_ollama.llms import OllamaLLM
from langchain.agents import initialize_agent
from langchain.tools import Tool
import requests
langchain_ollama.llms:用于导入 LLM 模型。langchain.agents:用于初始化智能体(agent),将模型与工具结合使用。langchain.tools:用于定义工具。requests:用于发送 HTTP 请求以获取天气数据。
2. 设置 API 基本信息
定义高德API的应用密钥和基础URL,后续请求将使用这些信息。
3. 获取城市编码的工具
# 获取城市编码的工具
def get_city_code(city_name):
url = f'{AMAP_BASE_URL}/config/district'
params = {
'key': AMAP_KEY,
'keywords': city_name,
'subdistrict': 2,
}
response = fetch_data(url, params)
return parse_city_code_response(response)
该函数接收城市名称并调用高德API以获取对应的城市编码。请求参数中包括API密钥和城市名称。
4. 获取天气数据的工具
# 获取天气数据的工具
def get_weather_data(city_code, forecast=False):
url = f'{AMAP_BASE_URL}/weather/weatherInfo'
params = {
'key': AMAP_KEY,
'city': city_code,
'extensions': 'all' if forecast else 'base'
}
response = fetch_data(url, params)
return response
该函数接收城市编码并请求天气信息。可以选择获取实时天气(base)或预报天气(all)。
5. 封装 API 请求逻辑
def fetch_data(url, params):
try:
res = requests.get(url=url, params=params)
data = res.json()
if data.get('status') == '1':
return data
return {"error": "请求失败"}
except Exception as e:
return {"error": f"请求时出错: {str(e)}"}
该函数负责发送HTTP请求并处理响应。它会检查请求是否成功,并返回相应的数据或错误信息。
6. 定义工具
# 定义获取城市编码的工具
city_code_tool = Tool(
name="GetCityCode",
func=get_city_code,
description="根据城市名称获取对应的城市编码,参数是中文城市名称,例如:上海"
)
# 定义获取天气的工具
weather_tool = Tool(
name="GetWeather",
func=get_weather_data,
description="获取指定城市的天气信息,参数是城市编码和是否需要预报"
)
创建 Tool 对象,分别用于获取城市编码和天气信息,便于在智能体中使用。
7. 初始化 LLM 和定义智能体
# 初始化 LLM
llm = OllamaLLM(model="llama3")
# 定义 agent
agent = initialize_agent(
tools=[city_code_tool, weather_tool], # 使用自定义工具
llm=llm,
agent_type="zero-shot-react-description",
verbose=True,
agent_kwargs={"handle_parsing_errors": True}
)
实例化 LLM 模型,并初始化智能体,将定义的工具与模型关联,允许模型根据用户输入自动选择合适的工具进行处理。
8. 用户输入和执行
user_question = "北京的天气怎么样?"
print(f"用户问题:{user_question}")
response = agent.run(user_question)
print(response)
用户输入一个关于天气的问题。调用智能体的 run 方法处理用户问题,智能体会自动调用适当的工具,获取城市编码并查询天气信息,最后返回结果。
这段代码展示了如何利用指令跟随能力,将用户的问题转化为具体的工具调用,动态获取最新的信息并提供准确的答案。通过结合多个工具,LLaMA 3 能够更好地处理复杂的查询,提供更高质量的回答。
小结
我希望这节课能够帮助你澄清RAG技术和智能体技术的实际情况。这些技术并非独立的能力,而是由一系列相关技术组合而成。其核心在于大模型的指令跟随技术,这一技术使模型能够按照指令进行有效的响应和操作。
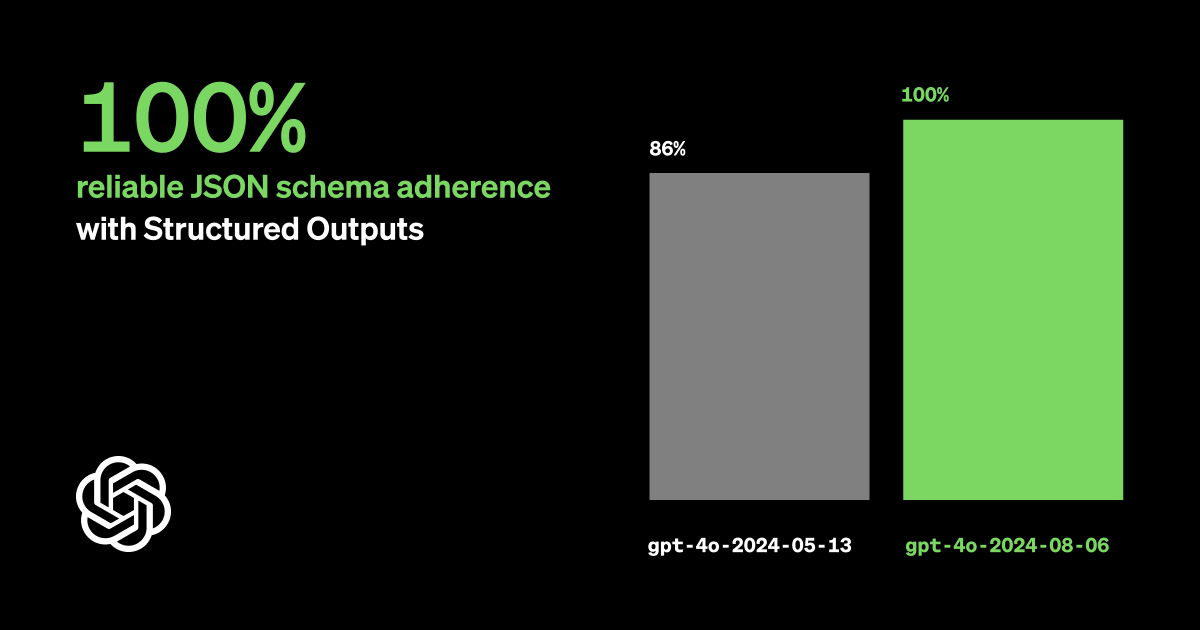
具体来说,大模型的指令跟随技术依赖于大量的数据和先进的算法,以确保模型能够准确理解和执行各种指令。OpenAI的API已经实现了支持安全结构化输出的功能,这主要是为了满足指令跟随场景的需求。这个功能允许模型生成经过结构化处理的输出,从而提高其在实际应用中的安全性和可靠性。
在后续的RAG和智能体课程中,我们将进一步探讨如何在LLaMA中实现这些能力。我们将详细讨论如何利用这些技术来优化模型的表现,并展示实际应用中的具体实现方法。通过这些内容,你将能够更清晰地理解RAG技术和智能体技术的实际应用,以及它们如何与大模型的指令跟随技术紧密结合。
思考题
格式化(如JSON)的大语言模型输出有哪些优势?为什么我们将它作为一个大模型能力的质变?欢迎你把思考后的结果分享到留言区,和我一起讨论,如果你觉得这节课的内容对你有帮助的话,欢迎你分享给其他朋友,我们下节课再见!
完整示例
from langchain_ollama.llms import OllamaLLM
from langchain.agents import initialize_agent
from langchain.tools import Tool
import requests
# 高德API的基本信息
AMAP_KEY = 'f1ea5fb70d21c088eb45bdbce898e8a9' # 替换为你的高德应用 key
AMAP_BASE_URL = 'https://restapi.amap.com/v3'
# 获取城市编码的工具
def get_city_code(city_name):
url = f'{AMAP_BASE_URL}/config/district'
params = {
'key': AMAP_KEY,
'keywords': city_name,
'subdistrict': 2,
}
response = fetch_data(url, params)
return parse_city_code_response(response)
# 解析城市编码返回值
def parse_city_code_response(response):
if response.get('status') == '1':
districts = response.get('districts', [])
if districts:
# 假设 adcode 在第一个 district 中
city_info = districts[0]
adcode = city_info.get('adcode', '未知')
# 如果需要进一步查找 adcode,可以遍历下级行政区
if 'districts' in city_info:
for district in city_info['districts']:
if 'adcode' in district:
adcode = district['adcode'] # 更新为子级的 adcode
break
return adcode
return {"error": f"无法获取城市编码: {response.get('info', '未知错误')}"}
# 获取天气数据的工具
def get_weather_data(city_code, forecast=False):
url = f'{AMAP_BASE_URL}/weather/weatherInfo'
params = {
'key': AMAP_KEY,
'city': city_code,
'extensions': 'all' if forecast else 'base'
}
response = fetch_data(url, params)
return response
# 封装API请求逻辑
def fetch_data(url, params):
try:
res = requests.get(url=url, params=params)
data = res.json()
if data.get('status') == '1':
return data
return {"error": f"请求失败: {data.get('info', '未知错误')}"}
except Exception as e:
return {"error": f"请求时出错: {str(e)}"}
# 定义获取城市编码的工具
city_code_tool = Tool(
name="GetCityCode",
func=get_city_code,
description="根据城市名称获取对应的城市编码,参数是中文城市名称,例如:上海"
)
# 定义获取天气的工具
weather_tool = Tool(
name="GetWeather",
func=get_weather_data,
description="获取指定城市的天气信息,参数是城市编码和是否需要预报"
)
# 初始化 LLM
llm = OllamaLLM(model="llama3")
# 定义 agent
agent = initialize_agent(
tools=[city_code_tool, weather_tool], # 使用自定义工具
llm=llm,
agent_type="zero-shot-react-description",
verbose=True,
agent_kwargs={"handle_parsing_errors": True}
)
# 用户问题
user_question = "北京的天气怎么样?"
print(f"用户问题:{user_question}")
# 执行并打印结果
response = agent.run(user_question)
print(response)
- 小虎子11🐯 👍(1) 💬(0)
课程代码地址:https://github.com/tylerelyt/LLaMa-in-Action
2024-11-25 - 悟光 👍(3) 💬(0)
格式化(如 JSON)的大语言模型输出我觉得会很好和现有的系统集成,标准的输出格式类似一个接口,这个接口已经被现有的系统广泛使用,理想情况下大模型可以应用到现有系统的任何一个模块里面
2024-12-09 - edward 👍(2) 💬(0)
请问老师 大模型是如何判断什么时候该调用什么工具的。
2024-10-18 - Geek_820805 👍(1) 💬(0)
改成 prompt = hub.pull("hwchase17/react") tools=[city_code_tool, weather_tool] agent=create_react_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, agent_kwargs={"handle_parsing_errors": True} )好用了
2024-10-23 - Geek_820805 👍(1) 💬(0)
运行代码,最后出现 ValueError: An output parsing error occurred. In order to pass this error back to the agent and have it try again, pass `handle_parsing_errors=True` to the AgentExecutor. This is the error: Could not parse LLM output: `The weather in Beijing is晴 (sunny) with a temperature of 15°C and humidity of 47%.` 看起来tool已经返回结果了,但是llm解析结果出问题了,应该如何解决呢?
2024-10-23