04 LLaMA 3的思考之道:思维链的源流与应用
你好,我是Tyler。
在上节课中,我们讨论了如何将大模型从传统的“对话框”应用场景中解放出来,通过指令和工具的使用,扩展其在实际应用中的能力。然而,即便如此,大模型在处理复杂任务时,仍然会出现力不从心的情况。面对长篇复杂的任务描述,模型往往会抓不住重点,甚至可能产生一些奇怪的错误,这在实际应用中显然是不可接受的。
那么,如何让大模型在处理复杂问题时更加得心应手?研究人员通过不断的探索,提出了一种名为思维链(Chain of Thought, CoT)的技术。它不仅能帮助模型更好地理解复杂问题,还能逐步推理出准确的答案。今天我将带你深入探讨思维链的概念、应用场景、技术实现及其在未来智能体应用中的潜力。
什么是思维链?
思维链,顾名思义,就是引导模型进行逐步推理的链条。通过分步骤思考,模型能够在复杂的任务中逐渐接近正确答案,避免因直接跳到结论而产生的错误。这种方法最初是由一句简单的提示语“Let’s think step by step”衍生出来的。这句提示语告诉模型:“我们一步一步来,别急。”这句话可以显著提高模型在处理复杂问题时的准确性。

在探讨思维链的过程中,我们需要思考一个重要的问题:所有的思维链是否都是链?实际上,思维链的灵活性和复杂性远不止于此。尽管“链”暗示了一个线性结构,但实际上,思维链可以表现为更加复杂的多步骤推理路径。这些路径有时可能是树状结构,有时则可能需要在多个平行的推理分支中进行选择和组合。因此,思维链的设计并非总是线性的,而是根据具体任务的复杂性和需求进行灵活调整。
思维链的核心在于逐步引导模型进行推理,而不是让它一次性得出结论。通过这一策略,模型在每个推理步骤中都需要认真思考,确保每一步都是逻辑严谨且正确的。这种方法不仅可以减少错误,还能帮助模型更好地理解问题的整体框架。
为了更直观地理解思维链,我们可以通过一个简单的例子来说明。假设我们让模型解决一个数学问题,直接问它“5 + 3 + 7等于多少?”模型通常可以直接给出正确答案。但是,如果问题更复杂,比如涉及多个步骤的推理,模型可能会出错。这时,如果我们在问题前加上“Let’s think step by step”,模型就会逐步进行解题,并最终得出正确答案。
数学问题中的思维链
import ollama
def cot(problem):
# 提示模型逐步思考
prompt = f"{problem} Let's think step by step."
response = ollama.chat(model='llama3', messages=[
{
'role': 'user',
'content': prompt,
},
])
return response['content']
def solve_math_problem():
problem = "What is 5 + 3 + 7?"
result = cot(problem)
return result
result = solve_math_problem()
print(result)
在这个例子中,模型通过逐步计算,最终得出了正确的答案。这样的方式不仅能够让模型更好地理解问题,还能避免因为直接推理导致的错误。
逻辑推理与任务规划中的应用
思维链不仅适用于数学问题,还可以广泛应用于逻辑推理、复杂问答、任务规划等场景中。例如,在任务规划中,我们可以引导模型逐步拆解任务,并按照逻辑顺序完成每一步,从而保证任务的正确性和完整性。

比如我们看到的 GPT-4o1 中强大的推理能力,就是来自于思维链的赋能。它甚至已经能在信息学竞赛中超过人类的表现。
复杂思维链的实际应用
随着研究的深入,思维链技术已经从最初的提示语工程,逐渐发展成了一种广泛的多步骤推理方法。在更复杂的应用场景中,思维链不仅仅是一个提示语,而是一种多步骤推理的全新方法论。例如,在跨会话的多步骤推理中,模型需要在多个对话中逐步积累信息,并在最终的会话中得出综合性的结论。
以下是一个示例代码,其中设计了一系列精巧的问题,引导模型逐步推理并整合信息:
import ollama
def cross_session_reasoning(session_data):
accumulated_info = ""
for session in session_data:
prompt = f"Based on our previous discussions: {accumulated_info} {session['question']}"
response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])
accumulated_info += response['content'] + " "
final_prompt = f"Now, let's summarize the conclusion based on all the steps we've discussed: {accumulated_info.strip()}"
final_response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': final_prompt},
])
return final_response['content']
session_data = [
{"question": "What foundational concepts should we consider when addressing problem X?"},
{"question": "Based on those concepts, what is the initial action we should take to approach problem X?"},
{"question": "What factors should we evaluate after the initial action to determine its effectiveness?"},
{"question": "Considering the evaluation results, what would be the next logical step?"},
{"question": "What potential challenges might arise from this next step, and how can we mitigate them?"},
{"question": "Finally, how can we integrate all these steps to formulate a comprehensive solution to problem X?"}
]
result = cross_session_reasoning(session_data)
print(result)
在这个例子中,模型在多个会话中逐步积累信息,最终得出一个全面的结论。这种方法能够确保复杂任务处理的连贯性和准确性。
灵活性与安全性的平衡
在处理复杂任务时,如何平衡模型的灵活性与推理过程的安全性,是一个不可忽视的重要问题。随着任务描述的复杂化,如果没有合适的推理策略,模型可能会忽略重要信息,导致出现幻觉,最终影响任务的处理质量。
单一职责原则:分解任务,确保可控性
为了应对这一挑战,我们引入了“单一职责原则”,这一原则要求将复杂任务分解为多个独立的步骤,每个步骤只负责解决特定的子问题。通过明确每个步骤的职责,模型能够更加专注,减少错误的发生,并提高整体任务的处理质量。
import ollama
def decompose_task(task_description):
# 假设这里有一个逻辑来分解任务
return [
{"role": "analyst", "description": "analyze the data"},
{"role": "developer", "description": "write the code"},
# 添加更多步骤...
]
def combine_results(results):
# 假设这里有逻辑来组合结果
return " ".join(results)
def task_decomposition(task_description):
steps = decompose_task(task_description)
results = []
for step in steps:
# 每个步骤都有明确的职责和约束
prompt = f"As a {step['role']}, let's solve the specific part: {step['description']}"
response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])
results.append(response['content'])
# 综合所有步骤的结果,得出最终结论
final_result = combine_results(results)
return final_result
task_description = "Complex task involving multiple roles and responsibilities."
result = task_decomposition(task_description)
print(result)
在这个示例中,不同的角色设定帮助模型专注于特定任务,从而提高任务处理的质量和安全性。
安全策略:引入检查机制
为了进一步确保任务处理的安全性,我们还引入了检查机制。通过在每一个推理步骤后添加检查机制,可以验证模型的输出是否符合预期。这不仅能够及时发现并纠正错误,还能提高模型的整体推理质量。
import ollama
def decompose_task(task_description):
"""将任务描述分解为可操作的步骤"""
prompt = f"请将以下任务分解为具体的可操作步骤,并以编号的形式列出每个步骤:{task_description}"
response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])
steps = response['content'].strip().split('\n') if response['content'] else []
return steps
def check_result(response):
"""验证模型输出的合理性"""
prompt = f"以下响应是否存在安全隐患?{response} 请回答“是”或“否”。"
validation_response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])
return "是" in validation_response['content']
def combine_results(results):
"""综合所有有效结果"""
if not results:
return "没有有效结果可供总结。"
prompt = "请总结以下结果,并以段落形式呈现:" + "; ".join(results) # 使用分号分隔
summary_response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])
return summary_response['content']
def handle_error(step, response):
"""处理错误情况"""
print(f"处理步骤时出错:{step}。响应:{response}") # 可以增加更详细的错误处理
def reasoning_with_checkpoints(task_description):
"""多步骤推理中的检查机制"""
steps = decompose_task(task_description) # 将任务分解为多个步骤
results = []
for step in steps:
prompt = f"让我们解决这个问题:{step.strip()} 请以清晰的步骤形式回答。"
response = ollama.chat(model='llama3', messages=[
{'role': 'user', 'content': prompt},
])['content'] # 生成模型响应
# 检查输出有效性
if check_result(response):
results.append(response)
else:
handle_error(step, response) # 处理错误情况
return combine_results(results) # 返回综合结果
task_description = """
把大象放入冰箱
"""
result = reasoning_with_checkpoints(task_description)
print(result)
在这个例子中,检查机制确保每个推理步骤都符合预期,从而提高整体任务的安全性。
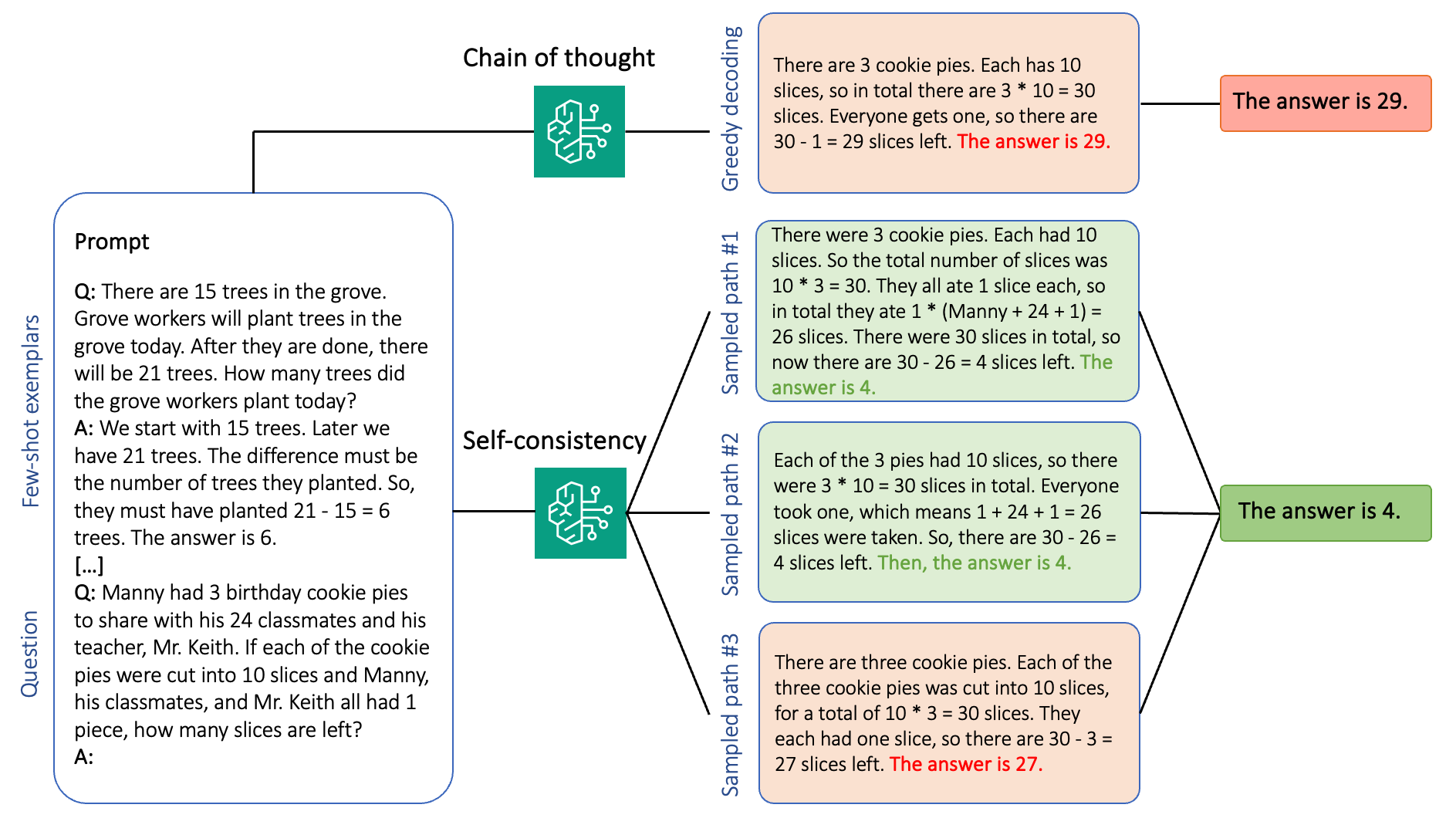
进一步来说,如上图所示的一致性检测算法是一种更为高级的检测方法。它通过整合多条推理链的返回结果,综合评估后选出最优策略,从而提高检测的准确性和可靠性。
为什么LLaMA模型适合做思维链?
LLaMA模型在思维链推理中的出色表现,主要得益于其在指令微调和模型涌现能力方面的优化。
指令微调的优势:LLaMA 3模型通过大量的指令微调数据进行了训练。这些数据不仅包含传统的问答和对话任务,还包括复杂推理任务。在这些任务中,模型不仅要给出正确答案,还需要解释每一个推理步骤。这种训练方式让LLaMA 3在处理多步推理任务时表现得尤为出色。
模型的涌现能力:涌现能力是指随着模型规模和数据量的增加,模型自发产生的一些新能力。这些能力并没有被明确编码或设计出来,而是在模型训练过程中自然涌现的。对于思维链来说,LLaMA 3能够自发地进行更复杂的逻辑推理和任务规划,甚至在没有明确提示的情况下,也能展现出良好的推理能力。
代码数据的贡献:LLaMA 3在训练数据中包含了大量的代码数据。这使得模型在推理和规划任务中具有更强的结构化思维能力。代码数据的逻辑性和严格的语法规则,让模型在推理时能够更好地遵循逻辑步骤,避免无序推理。
小结
在上节课中,我们探讨了智能体工具使用的本质,即指令跟随能力。本节课的重点则是深入讨论智能体的“思考”能力,尤其是跨会话的多步推理。通过对思维链的深入探讨,我们了解到,这项技术不仅提升了模型的推理能力,还帮助模型更好地理解和处理复杂任务。
在本节课中,我们梳理了从思维链到多步推理,再到跨会话推理及智能体发展的技术脉络,这是专栏对智能体技术“祛魅”的第二步。我们通过逐步剖析,明确了实现智能体高效、准确任务执行的关键——跨会话的多步推理能力。
未来,随着技术的进一步发展,思维链将成为智能体不可或缺的一部分,为解决更复杂的任务提供强有力的支持。这节课的内容也将成为智能体状态机设计的重要前序知识。在接下来的课程中,我将详细讲解思维链在智能体架构设计中的实际应用,带你了解如何将这项技术集成到智能体中,从而增强其逻辑推理能力。
思考题
GPT-4o1 的能力和思维链之间的关系是什么?欢迎你把思考后的结果分享到留言区,和我一起讨论,如果你觉得这节课的内容对你有帮助的话,欢迎你分享给其他朋友,我们下节课再见!
- 小虎子11🐯 👍(0) 💬(0)
课程代码地址:https://github.com/tylerelyt/LLaMa-in-Action
2024-11-25 - 兵戈 👍(3) 💬(1)
Tyler老师,学完了您《LLaMA 3 前沿模型实战课》的第4课,并跑通了其中的相关案例代码。 但我看当前工程中还一直没有第4课的工程代码,于是我提交PR:https://github.com/tylerelyt/llama/pull/2 您看看是否需要,可以Merge进来,或者直接上传您那边的工程代码: 对应课程代码,有些地方稍作修改,使得能运行成功或者更顺畅: # 1、修改所有example中 response 的获取方式 response['content'] -> response['message']['content'] # 2、example4 中添加step判断,减少循环次数 if step == '': continue
2024-10-23