07 如何运用LLaMA 3的思维链实现频率增强?
你好,我是 Tyler。
在上一节课中,我们学习了如何构建一个简易的ChatGPT模型,这为我们后续的学习奠定了基础。你们已经掌握了生成式预训练模型的基本原理,并了解了如何应用这些原理来实现类似ChatGPT的对话系统。这节课,我们将继续深入,讨论LLaMA 3模型在进行多轮推理时的局限性,并探讨如何有效应对这些挑战。
在第四节课中,我们详细了解了基于思维链(Chain of Thought, CoT)的多步推理方法。这种方法通过将复杂问题分解成多个易于处理的子问题,逐步推进推理过程,从而帮助我们更有效地解决复杂的推理任务。尽管思维链在提升推理准确性方面有其优势,但在处理多轮推理任务时也暴露出了一些局限性。
LLaMA 3在多轮推理中的局限性
LLaMA 3模型基于自回归的生成方式进行文本生成,即通过预测下一个字符或单词来逐步构建完整的句子或段落。这种方式在大多数情况下表现良好,能够生成流畅且连贯的文本。然而,在处理复杂的、多步骤推理任务时,模型可能会出现不一致的表现——在多次尝试中,模型可能会给出不同的答案,有时是正确的,但其他时候可能出现错误。这种不一致性主要源于以下几个方面:
- 上下文依赖性:自回归模型在生成文本时依赖于先前生成的内容。如果前文的推理或上下文信息存在误差,后续的生成也可能受到影响,导致不一致的输出。
- 推理路径的随机性:自回归生成的过程包含一定的随机性,尤其是在温度采样较高时,这可能导致模型在相同问题上产生不同的回答。
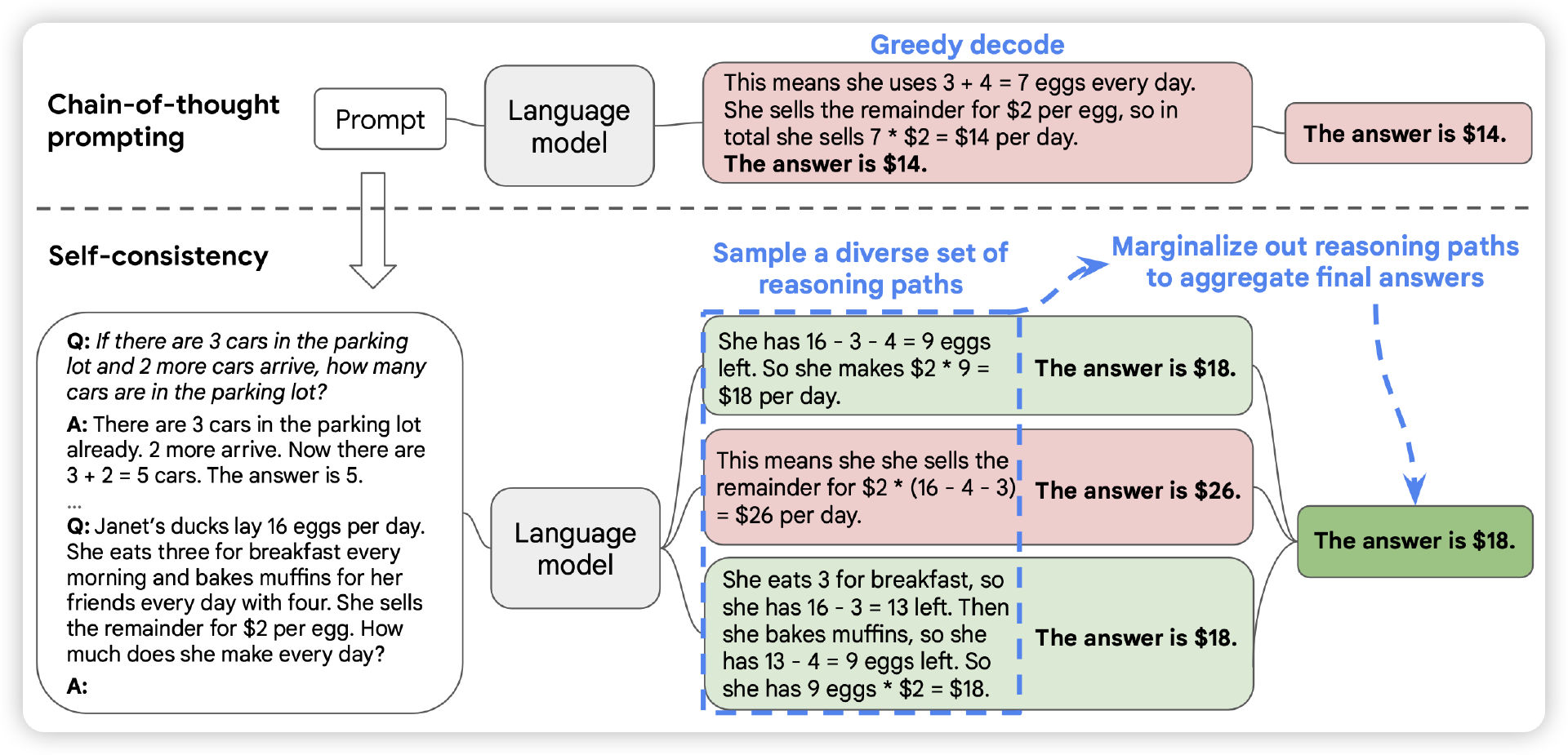
Self-Consistency
为了解决这个问题,我们可以引入一种名为 Self-Consistency 的策略。Self-Consistency方法的核心理念是通过增加模型推理的频率来提高整体表现,即通过让模型在同一问题上多次推理,并汇总这些结果,来提升最终答案的准确性。具体来说,Self-Consistency方法要求模型多次运行推理过程,将每次推理得到的结果进行比较和汇总,以确定最有可能的正确答案。这样,我们不仅能有效应对复杂的多步推理任务,还能显著提升基于思维链的推理的可靠性和准确性。
Self-Consistency的具体实施步骤如下:
- 多次生成:对同一个问题进行多次推理。每次推理的结果可能略有不同,通过多次生成可以覆盖更多可能的答案。
- 结果汇总:对每次推理的结果进行汇总,统计每个答案的出现频率。常见的答案通常是正确的,通过频率统计可以找到最可能的正确答案。
- 最终答案选择:选择出现频率最高的答案作为最终的推理结果。通过这种方式,可以减少随机性带来的影响,提高推理的可靠性和准确性。
接下来,我们将通过具体的例子,详细说明Self-Consistency方法的应用过程,以及它如何在实践中提高LLaMA 3模型的多轮推理表现。
假设我们正在应用Self-Consistency方法来解决一个需要多步推理的问题。
import ollama
import re
# 设定生成文本的函数
def generate_text(prompt):
response = ollama.chat(model='some_correct_model', messages=[
{
'role': 'user',
'content': prompt,
},
])
return response['message']['content']
# 设定一个多步推理问题
prompt = (
"假设你有一个花园,其中有3个花坛。每个花坛都需要浇水。"
"如果第一个花坛需要10升水,第二个花坛需要20升水,第三个花坛需要30升水,"
"请计算总共需要多少升水。"
)
# Self-Consistency: 多次生成并汇总结果
n_trials = 5
results = []
for _ in range(n_trials):
generated_text = generate_text(prompt)
if generated_text is not None:
print(f"推理结果: {generated_text}")
results.append(generated_text)
# 统计推理结果并寻找最常见的答案
def extract_answer(text):
# 尝试从文本中提取数字
match = re.search(r'\d+', text)
if match:
return int(match.group(0))
return None
# 提取每次推理的结果
extracted_answers = [extract_answer(text) for text in results]
# 计算每个答案出现的次数
answer_counts = Counter(filter(None, extracted_answers))
# 找到最常见的答案
if answer_counts:
most_common_answer = answer_counts.most_common(1)[0][0]
print(f"最终确定的答案是:{most_common_answer} 升水。")
else:
print("没有找到有效的答案。")
以下是这个示例中每个部分的详细解释:
- 模型加载:我们使用了Hugging Face上的Llama-2-13b-chat模型,这是一个强大的生成式语言模型。
- 生成文本:函数
generate_text根据输入的提示生成模型的输出。在这个例子中,提示是一个多步推理的问题,要求模型计算总共需要多少升水。 - Self-Consistency:我们通过多次生成推理结果,并将每次的结果记录下来。然后,我们统计这些结果,寻找最常见的答案,作为最终的推理结果。
- 结果汇总:使用Python的
Counter库,我们统计每个推理结果出现的频率,并选出出现次数最多的答案。这种方法有效地减少了推理过程中的随机性,增强了模型输出的可靠性。
结合温度采样
此外,为了进一步增强Self-Consistency的效果,我们还可以结合温度采样(Temperature Sampling)策略。在生成文本的过程中,温度采样通过调整采样温度来控制模型输出的随机性。当温度较高时,模型生成的内容更加多样化;当温度较低时,生成的内容则更加确定。
通过结合温度采样和Self-Consistency方法,我们可以在推理过程中引入适度的随机性,从而在多次推理中探索更多可能的解答路径。随后,我们将这些多次推理结果进行汇总,进一步提高正确答案的出现概率。这种方法特别适用于需要多步推理或面对复杂问题的场景,能够有效提升模型的整体推理表现。
这些思路实际上体现了集成学习的原理,即通过集成不同的方法来提高最终的准确性。Self-Consistency集成不同的思维链,其实是集成学习的一种特例。集成学习方法通过结合多个模型或策略来减少误差、提高性能。在Self-Consistency中,我们通过多次生成并汇总结果,类似于集成学习中的模型融合策略,能够有效提升推理结果的准确性。
例如,《More Agents Is All You Need》这一研究在智能体领域中展示了集成学习的原理,表明多个智能体的集成可以显著提高系统的整体表现。在推理任务中,通过集成不同的推理路径或模型,可以获得更加稳健和准确的结果。
当然,是不是这种用算力换准确率的方法就是最好的方案了呢?当然不是。这种类似的频率增强方案有非常明显的局限性,就是搜索过程的无序,我们只能通过增加频率来让答案更接近真实结果。然而精准的答案搜索过程是需要结合回溯策略的。
频率增强的局限性
频率增强(如Self-Consistency)虽然能提高多轮推理的准确性,但也有其局限性。增加生成频率有助于通过统计找到最可能的正确答案,但这种方法依赖于在生成过程中捕捉到的多样性,而不一定能保证每次推理都接近真实答案。这就带来了几个挑战。
- 搜索过程的无序:频率增强方法依赖于大量生成的结果来统计最常见的答案,但这种方法在生成过程中没有明确的方向或策略,可能导致生成的答案分布不均,尤其是在复杂的、多步骤的推理任务中,答案的正确性可能受到生成顺序和上下文依赖的影响。
- 上下文信息的丢失:在自回归生成中,模型依赖于先前生成的文本。如果在多次推理中,模型无法保持一致的上下文信息,可能会导致结果的不一致性或错误。
- 计算资源的消耗:频率增强需要进行多次推理,这会消耗大量的计算资源。对于大规模的应用场景,这种方法的计算开销可能较大,尤其是在面对需要高精度的推理任务时。
结合回溯策略的精准搜索
为了克服这些局限性,我们可以结合回溯策略(Backtracking)来提高推理的准确性。回溯策略是一种系统的探索问题空间的方法,通过逐步尝试不同的选项并在发现错误时回溯到先前的状态,从而找到更优解。
回溯策略如何与频率增强结合来提升推理效果呢?
- 有序的推理路径:回溯策略可以引导模型在推理过程中按照一定的顺序和规则进行探索。通过定义明确的推理路径,模型可以避免频率增强方法中的无序搜索,提高搜索效率和答案的准确性。
- 局部优化与全局验证:回溯策略允许模型在推理过程中进行局部优化,并在需要时回溯到先前状态进行调整。这种方法可以帮助模型在复杂的推理任务中更好地处理长文本和多步骤问题,同时保证最终答案的准确性。
- 结合回溯与频率增强:可以将回溯策略与频率增强方法结合使用。首先,通过回溯策略探索潜在的正确答案空间,然后使用频率增强方法来对回溯过程中产生的结果进行进一步验证和优化。这种组合策略可以充分利用回溯的系统性和频率增强的统计优势,提高最终推理结果的可靠性。
基于回溯策略的思维链方法需要在生成路径上进行剪枝优化,我们将在后续课程中具体学习。
总结
学到这儿,我们做个总结吧。在本节课中,我们探讨了LLaMA 3模型在多轮推理中的局限性,并介绍了Self-Consistency方法。Self-Consistency通过多次生成推理结果并汇总,以减少模型输出的随机性,从而提高准确性。我们通过示例演示了如何应用这一方法,并讨论了结合回溯策略以进一步提升推理效果的可能性。
下一节课我们将继续深入探讨如何优化模型推理路径并引入更多先进技术,敬请期待。
思考题
- 为什么要做频率增强?
- 频率增强和人类推理中的哪类行为比较像?
欢迎你把思考后的结果分享到留言区,也欢迎你把这节课分享给需要的朋友,我们下节课再见!
- willmyc 👍(1) 💬(0)
老师,您好,这段代码 # 统计推理结果并寻找最常见的答案def extract_answer(text): # 尝试从文本中提取数字 match = re.search(r'\d+', text) if match: return int(match.group(0)) return None,准确的做法是否应该是匹配最后一个数字,因为模型的生成结果中第一个数字一般会是推理过程的输出的数字,并不是最终的答案,所以我把代码改成了下面这样,# 统计推理结果并寻找最常见的答案 def extract_answer(text): # 尝试从文本中提取数字 match = re.findall(r'\d+', text) if match: return int(match[-1]) return None
2024-12-05