15 LLaMA 3的开源语言智能体方案
你好,我是Tyler。
今天,我们将正式开始语言智能体的学习之旅,进一步探索LLaMA3的能力边界。在第二章探索多轮对话能力的过程中,我们深入研究了如何利用“反馈增强”技术扩展 LLaMA3 的能力。尽管这种方法在很多场景下取得了不错的效果,但它仍然存在一个关键问题:智能体无法根据持续的运行进行自我进化,不能从历史经验中不断优化决策。
比如,我们曾经使用过反馈增强方法(如ReAct),在多次重复处理同一问题时,得到的答案几乎没有任何变化。这表明,传统的反馈增强方法未能促使模型实现真正的自我进化,缺乏持续学习和适应的能力。
为了让模型实现真正的自我进化,我们需要采用全新的方法。你还记得我们是如何在多步推理中不断提升大模型处理复杂任务的能力的吗?正是通过引入行动-观察闭环和思考闭环,我们增强了智能体的工具使用能力和稳定性,进而构建了ReAct的复杂闭环结构。
这次,我们将引入全新的闭环反馈机制,加入“自我反思”功能和“外部记忆”模块。通过这种方式,模型不仅能在每次执行任务时反思自己的决策,还能存储历史经验,在后续任务中不断优化表现。
自我反思(Reflexion)进化增强
自我反思是一种通过语言反馈来强化智能体行为的机制,旨在让智能体从过去的决策和行为中持续学习,提升其在复杂任务中的表现。具体来说,自我反思机制将环境反馈——无论是自由形式的语言反馈,还是标量形式的奖励(如评分)——转化为“自我反思”反馈,为下一轮决策提供必要的上下文信息。这一过程使得智能体能够从过去的错误中迅速吸取教训,避免重复相同的失误。
在自我反思框架中,主要有三个关键组成部分。
- 参与者(Actor)
参与者负责根据当前的状态观测生成文本和动作,并根据这些信息在环境中采取行动。参与者部分可以使用我们之前学习过的各类多步推理方法,以增强决策的复杂性和准确性。此外,参与者还引入了记忆组件,用于提供额外的上下文信息,帮助智能体在决策时能够回顾并利用过去的推理路径,作为历史经验。
- 评估者(Evaluator)
评估者的任务是对参与者的输出进行评价。它通过评估参与者生成的轨迹,并基于任务的目标或要求给出一个奖励分数。这个奖励分数不仅反映了智能体执行任务的效果,还能为自我反思过程提供关键信息。评估者的目标是通过明确的反馈,帮助参与者理解哪些行为是有效的,哪些是需要改进的。
- 自我反思(Self-Reflection)
自我反思的核心任务是根据评估者提供的奖励信号、当前任务的执行轨迹以及长期记忆,生成具体的语言反馈,并将这些反馈传递给参与者。通过这种反馈机制,参与者可以不断调整和优化自己的行为决策。自我反思角色通常由 LLaMA3 这类大语言模型承担,这使得模型能够结合过去的决策经验和当前的任务信息,为参与者提供更具针对性的改进建议。
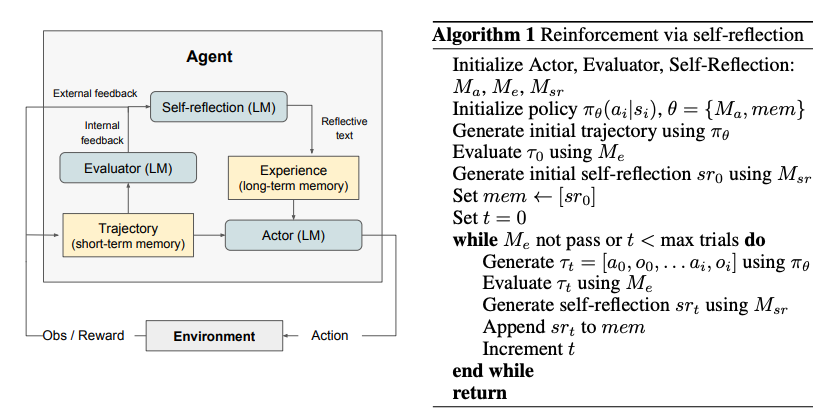
上图展示了如何通过“反思”机制增强智能体的能力,使其能够在处理问题时根据过去的经验不断优化决策,从而实现“自我进化”。
代码解释
在官方实现代码中,run 方法是智能体的主要执行流程。它的核心逻辑是,如果任务已经结束并且智能体的回答不正确,智能体会调用 reflect 方法进行反思。通过这一过程,智能体会回顾之前的决策进行,并调整后续的策略。
def run(self, reset=True, reflect_strategy: ReflexionStrategy = ReflexionStrategy.REFLEXION) -> None:
if (self.is_finished() or self.is_halted()) and not self.is_correct():
self.reflect(reflect_strategy)
ReactAgent.run(self, reset)
- 判断是否需要反思:首先检查智能体是否完成任务,或者任务是否被暂停。如果任务结束且结果不正确,便调用反思(
reflect)机制。 - 反思逻辑:在
reflect方法中,智能体会根据过去的决策记录反思失败的原因,并重新制定策略,从而避免在未来重复同样的错误。这就是“自我进化”的体现。 - 反思策略:反思策略通过
ReflectStrategy.REFLEXION来控制反思的深度和方式,使智能体根据不同场景调整反思的策略,该代码中的反思策略对应于下文中的提示语方法。
REFLECT_INSTRUCTION 结构就是反思的提示模板,它要求智能体根据之前的任务失败情况进行自我诊断,并生成新的策略。这种机制使得智能体能够对失败的原因进行分析,并制定新的高层次决策,提升其未来的表现。
REFLECT_INSTRUCTION = """You are an advanced reasoning agent that can improve based on self reflection. You will be given a previous reasoning trial in which you were given access to a Docstore API environment and a question to answer. You were unsuccessful in answering the question either because you guessed the wrong answer with Finish[<answer>], or you used up your set number of reasoning steps. In a few sentences, Diagnose a possible reason for failure and devise a new, concise, high level plan that aims to mitigate the same failure. Use complete sentences.
Here are some examples:
{examples}
Previous trial:
Question: {question}{scratchpad}
Reflection:"""
反思策略中主要包含两个步骤:
- 诊断失败原因:智能体需要分析为什么之前的尝试失败了,可能是因为选择了错误的答案,或者是没有足够的推理步骤来完成任务。
- 制定新的计划:根据失败的诊断,智能体需要提出一个新的、简洁的高层次计划,旨在避免重复之前的错误,并优化下一步的决策过程。
这种反思机制对于复杂任务尤为重要,它能够帮助智能体避免重复性错误,提高决策质量。通过反复的自我反思,智能体不仅能改进短期决策,还能从长期的任务执行中积累经验,进而实现自我进化。
记忆流与反思树:应对存储和效率问题
尽管反思闭环显著提升了智能体的能力,但在实际应用中,仍然面临一些挑战。随着历史记录的不断积累,外部记忆的膨胀可能带来存储成本增加和检索效率下降的问题。同时,有限的输入窗口限制了智能体能够处理的历史信息量。为了应对这些挑战,我们引入了“记忆流”和“反思树”两项关键技术。

记忆流技术
记忆流根据历史记录的时效性、重要性和相关性进行评分,从大量历史数据中筛选出最相关的记忆。这种方法确保了智能体能够在有限的输入窗口内检索到最相关的信息,避免了冗余数据干扰。
- 时效性(Recency):记录更新的时间点越近,意味着信息对当前任务的相关性更高。
- 重要性(Importance):某些记录在决策中比其他记录更加关键。
- 相关性(Relevance):信息与当前任务的关联程度。
在代码实现中,我们为每条历史记录计算综合得分,并基于得分进行筛选。以下是代码的逐步解析:
- 节点筛选与排序
我们首先从智能体的记忆中获取所有历史记录(节点),然后按照其最后访问时间进行排序。这样,就可以优先考虑最新的记录。
nodes = [[i.last_accessed, i] for i in agent.a_mem.seq_event + agent.a_mem.seq_thought if "idle" not in i.embedding_key]
nodes = sorted(nodes, key=lambda x: x[0])
nodes = [i for created, i in nodes]
- 计算各维度得分
接下来,我们分别计算时效性、重要性和相关性得分,并将它们归一化至 [0, 1] 范围内。这是为了确保每个维度的得分都处于相同的量级,便于后续加权计算。
recency_out = normalize_dict_floats(extract_recency(agent, nodes), 0, 1)
importance_out = normalize_dict_floats(extract_importance(agent, nodes), 0, 1)
relevance_out = normalize_dict_floats(extract_relevance(agent, nodes, focal_pt), 0, 1)
- 加权得分计算
我们为每个维度设置不同的加权因子,表示每个维度在最终综合评分中的重要性。例如,recency_w 为时效性的权重,importance_w 为重要性的权重。
gw = [0.5, 3, 2] # 加权因子
master_out = dict()
for key in recency_out.keys():
master_out[key] = (recency_w * recency_out[key] * gw[0] +
relevance_w * relevance_out[key] * gw[1] +
importance_w * importance_out[key] * gw[2])
通过加权,我们得到每个历史记录的最终得分,并根据得分筛选出最相关的历史记忆。
- 返回最相关的记忆
最后,我们从综合得分中筛选出得分最高的若干条记忆,并返回这些记忆。此时,智能体能够根据历史经验选择出最相关的决策信息。
master_out = top_highest_x_values(master_out, n_count)
master_nodes = [agent.a_mem.id_to_node[key] for key in list(master_out.keys())]
- 更新访问时间
每次检索记忆时,我们都会更新这些记忆的最后访问时间,以确保它们的时效性得以反映在后续的检索过程中。
通过记忆流技术,智能体能够基于历史数据中最相关、最重要、最及时的信息来优化当前决策。记忆流不仅减少了存储成本,还提高了检索效率。在复杂任务中,智能体可以更好地学习和调整自己的策略。
反思树技术
记忆流能高效地找出最相关的历史记录,但问题是,随着时间推移,历史信息会变得越来越多,可能会导致遗漏一些重要的内容。为了避免这种情况,我们引入了“反思树”技术。反思树通过定期总结历史信息,将详细的记录转化成更高层次的反思,这些总结后的信息被保存在记忆流中,这样就能避免存储过多的低层次数据,同时提高检索效率。
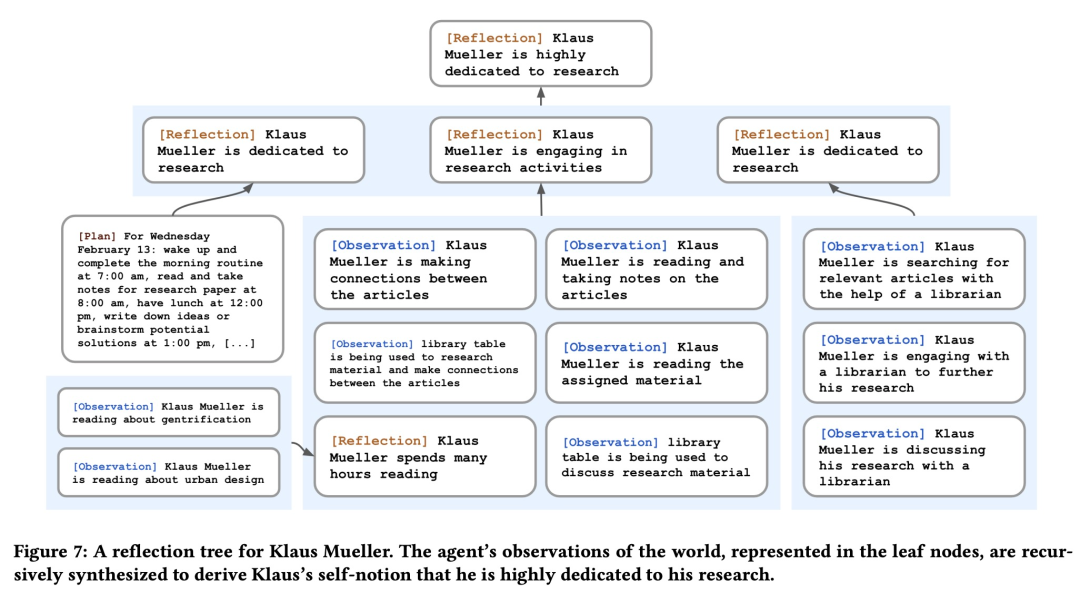
反思树通过定期检查历史事件,把这些具体的历史信息转化为更高层次的见解和总结。这样不仅能减少冗余存储,还能提高检索效率。反思树的结构像一棵树,叶子节点表示具体的历史事件,非叶子节点表示抽象的总结。智能体会定期检查历史记录,决定哪些事件重要,然后启动反思过程。
反思树通过周期性地总结历史事件,将详细的历史信息转化为更高层次的反思结果。这些反思结果不仅减少了冗余的存储,还能在检索时提高效率。反思树的结构包括叶节点(表示基本的历史观察)和非叶节点(表示更高层次的抽象总结)。智能体会定期检查历史记录,判断其重要性,并触发反思过程。
当智能体认为某个历史事件足够重要时,就会启动反思过程。这些反思结果会被存储成反思树的节点,随后不断归档被反思过的叶子节点,避免过多的细节影响存储和效率。
def run_reflect(agent):
"""
执行反思过程,生成焦点点、检索相关节点并生成思考与见解,最后存储到智能体记忆中。
INPUT:
agent: 当前Agent对象
OUTPUT:
None
"""
# 检索历史节点
retrieved = new_retrieve(agent)
# 生成见解并保存到智能体记忆中
for focal_pt, nodes in retrieved.items():
# 生成高层次的思考与见解
thoughts = generate_insights_and_evidence(nodes, 5)
# 遍历每个思考,生成对应的关键信息并存储
for thought, evidence in thoughts.items():
# 计算思考的痛点得分
thought_poignancy = generate_poig_score(agent, "thought", thought)
# 获取思考的嵌入向量
thought_embedding = get_embedding(thought)
thought_embedding_pair = (thought, thought_embedding)
# 将思考结果添加到智能体记忆
add_thought(thought, keywords, thought_poignancy, thought_embedding_pair, evidence)
为了生成高层次的见解,反思树依赖于精心设计的提示词,这些提示词帮助智能体从历史记录中提取关键信息,并生成抽象总结。以下是生成见解时使用的一些提示词示例:
Variables:
!<INPUT 0>!:事件/思维陈述的编号列表!<INPUT 1>!:目标智能体的名称
Input 示例:
Input:
!<INPUT 0>!
What !<INPUT 1>! high-level insights can you infer from the above statements? (example format: insight (because of 1, 5, 3))
1.
这种提示词设计能够引导智能体从原始的事件数据中提炼出更有意义的总结和见解,使得智能体在处理复杂任务时能更快速地利用历史经验。
小结
学到这里,我们做个总结吧。今天我们整合了之前学到的多步推理和检索增强技术,并通过引入反思闭环,为智能体添加了外部记忆和基于历史经验的自我反思功能,这让它能不断进化和优化自己的决策。
不过,随着记忆量不断增加,我们也遇到了一个问题——记忆积累过多。这就像是数据过载,导致智能体处理起来效率低下。为了应对这个问题,我们引入了两个新技术:记忆流和反思树。
它们结合起来,帮助智能体更高效地存储和检索历史数据,同时还能定期总结和反思,提取出重要的见解。这两者具体是怎么做的呢?
- 记忆流:通过给每条记忆打分,智能体能筛选出最相关的历史记录,从而确保它处理的是最有价值的信息。
- 反思树:把这些历史记录转化为更高层次的见解,减少冗余信息的存储,同时让检索效率更高。
这样,智能体不仅能在复杂任务中做出更智能的决策,还能在长期的任务中不断进化,学习从过往经验中提取有用的知识,并应用到新的决策中。
思考题
基于 Ollama 重新实现一个独立的系统,用于模拟人工智能小镇中的“记忆检索和反思”过程。假设这个系统的目标是实现智能体能够从历史事件中提取有价值的记忆,并基于这些记忆进行反思,以优化决策。后续我会在 GitHub 上给出我的实现,供你对比自己的实现。
欢迎你把你实现的代码贴在留言区,和我一起一起交流、讨论,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 小虎子11🐯 👍(0) 💬(0)
课程代码地址:https://github.com/tylerelyt/LLaMa-in-Action
2024-11-25 - 小歪歪的狗子 👍(0) 💬(1)
很好,很期待老师给出具体的代码实现
2024-11-15