04 使用MetaGPT实现Autonomous Agent应用
你好,我是李锟。
在上节课中,我们学习了 MetaGPT 的基础概念,并且初步体验了 MetaGPT 的使用方法。在第一课中我们已经讨论过待开发的第一个 Autonomous Agent 应用的需求,即一个陪伴用户玩24点游戏的智能体应用。在这一课中我们把这个需求实现为可运行的代码。按照魔术师刘谦老师的话说:见证奇迹的时刻到了!
角色建模和工作流设计
从上一课中我们已经了解到,多 Agent 应用是基于 Role Playing 来实现的。为了实现这个应用的需求,我们首先需要思考的是,在这个应用中我们最少需要创建几个角色。这里我出于方便借用了软件工程中的“角色建模”这个术语,不过两者概念还是有些差异的。
- 因为这个游戏是提供给人类用户使用的,首先要有一个人类用户作为游戏玩家,我们给这个角色 (Role子类) 取名 GamePlayer,其 name 属性设置为 David。
- 这个游戏确实有较高难度,人类用户很多时候自己搞定比较困难,因此需要求助于一个程序实现的角色。这个程序角色擅长给出满足24点游戏规则的表达式,我们给这个角色 (Role子类) 取名 MathProdigy (数学神童),其 name 属性设置为 Gauss (高斯)。
- 系统还需要有一个游戏裁判,负责发牌和对上述两个角色给出的表达式做检查,并且控制流程的顺利进行。人类用户只是游戏的玩家,并不是游戏的裁判,否则就不公平了。我们给这个角色 (Role子类) 取名 GameJudger,其 name 属性设置为 Peter。
这个游戏比较简单,所以创建三个角色就足够了。接下来我们来设计这个游戏的工作流。工作流设计是任何 BPA 应用的核心,也是企业应用的核心之一。
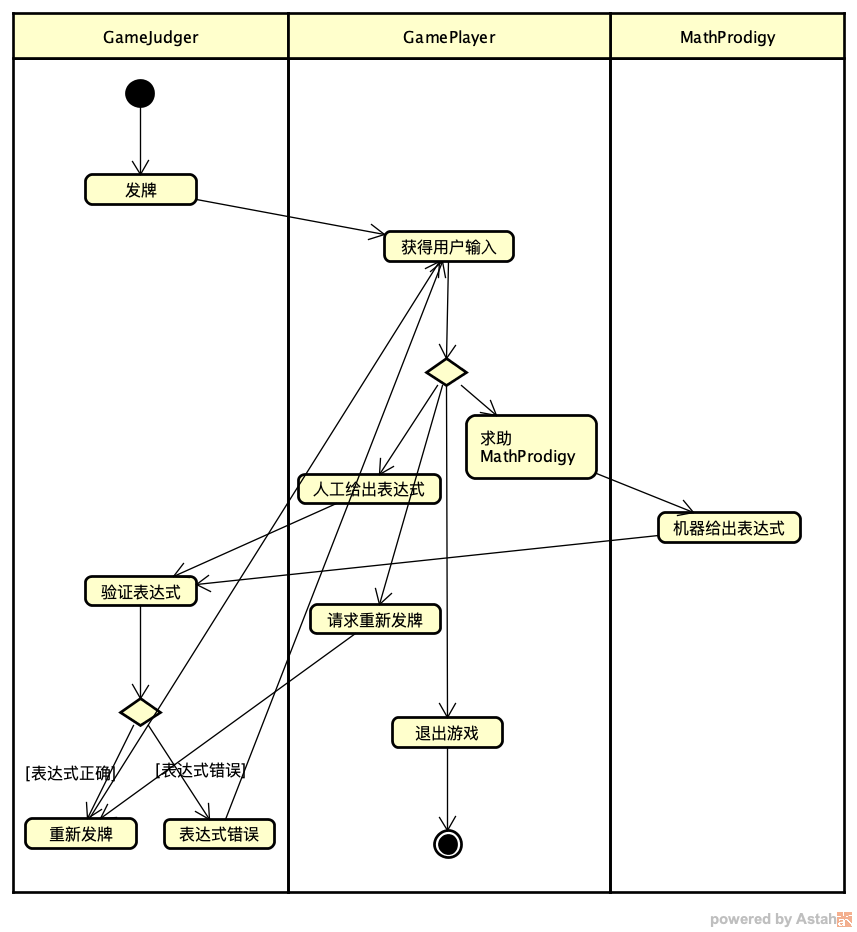
- 在一幅扑克牌中,去掉大小王一共 52 张牌。GameJudger 在这 52 张牌中随机抽取 4 张,发给 GamePlayer。
-
GamePlayer 拿到这 4 张牌之后,他有 4 种选择:
-
如果他非常自信,可以不求助任何人,自行给出满足要求的表达式。
- 如果发现自己给出表达式很困难,可以求助 MathProdigy,由 MathProdigy 给出满足要求的表达式。
- 放弃这一轮游戏,请求重新发牌。
- 请求退出游戏,则应用直接退出。
-
GameJudger 收到步骤 2 GamePlayer 的选择之后,根据不同情况做出选择:
-
若收到的是一个表达式,对表达式进行检查。若发现表达式正确,则跳到步骤 1,重新发牌,进入下一轮游戏。若发现表达式错误,给出错误的信号,跳到步骤 2,要求 GamePlayer 重新给出表达式。
- 若收到的是重新发牌的请求,则跳到步骤 1,重新发牌,进入下一轮游戏。
一图胜千言,虽然这个游戏的流程很简单,我们还是使用 UML 工具画一个流程图。
编写应用的框架代码
设计工作完成后,我们进入实战环节,使用 MetaGPT 来实现这个工作流。MetaGPT 暂时还不支持用图形方式来实现工作流,所以我们需要采用手工方式来做,幸运的是,其实也不难。你可以先需要阅读一下 MetaGPT 的这份官方文档。
参考上节课我们学习到的知识,首先我们需要创建三个 Role 子类:GameJudger、GamePlayer、MathProdigy。
接下来我们还要实现一些 Action 子类,需要创建的 Action 子类和上面流程图中的 Action (圆角矩形框) 基本上是一一对应的。包括DealCards (发牌+重新发牌)、GetHumanReply (获得用户输入)、HumanGiveExpression (自行给出表达式)、CallMathProdigy (求助MathProdigy)、MachineGiveExpression (机器给出表达式)、CheckExpression (验证表达式)、WrongExpression (表达式错误)、RequireDealCardsAgain (请求重新发牌)、ExitGame (退出游戏)。
在目前 MetaGPT 0.8.x 版的实现中,事件或消息的主要载体是 Action 子类,恰好对应上述 UML 流程图中的每个 Action。需要注意的是 Action 子类其实有两类,一类是需要执行某个任务 (包含了业务逻辑代码) 的 Action,另一类是不需要执行某个任务,纯粹只是事件信息的载体。
CallMathProdigy、WrongExpression、RequireDealCardsAgain、ExitGame 4 个 Action 就属于后者,在它们的 run() 函数中,不需要业务逻辑代码,返回一个字符串即可。HumanGiveExpression 也属于后者,在它的 run() 函数中,简单地返回输入参数 content,也就是把之前执行 GetHumanReply 这个 Action 时用户输入的表达式简单透传给 GameJudger 即可。
class HumanGiveExpression(Action):
name: str = "HumanGiveExpression"
async def run(self, content: str):
return content
class CallMathProdigy(Action):
name: str = "CallMathProdigy"
async def run(self, content: str):
return "CallMathProdigy"
class WrongExpression(Action):
name: str = "WrongExpression"
async def run(self, context: str):
return "WrongExpression"
class RequireDealCardsAgain(Action):
name: str = "RequireDealCardsAgain"
async def run(self, content: str):
return "RequireDealCardsAgain"
class ExitGame(Action):
name: str = "ExitGame"
async def run(self, content: str):
return "ExitGame"
三个角色 MathProdigy、GameJudger、GamePlayer 的初始化函数如下:
class MathProdigy(Role):
name: str = "Gauss"
profile: str = "MathProdigy"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._watch([CallMathProdigy])
self.set_actions([MachineGiveExpression])
class GameJudger(Role):
name: str = "Peter"
profile: str = "GameJudger"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.set_actions([DealCards])
self._watch([UserRequirement, RequireDealCardsAgain, MachineGiveExpression, HumanGiveExpression])
class GamePlayer(Role):
name: str = "David"
profile: str = "GamePlayer"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.set_actions([GetHumanReply])
self._watch([DealCards, WrongExpression])
实现第一个角色——MathProdigy
有了框架代码,接下来我们继续编写三个角色的代码。首先实现的角色就是应用中最核心的角色——MathProdigy。
MathProdigy 这个角色调用的 Action 是 MachineGiveExpression,在这个 Action 的 run() 函数中,我调用了一个外部的函数库来给出一个满足要求的表达式。在这里我自己手写一个函数库来给出表达式,看起来这似乎不是一种理想的选择,理想情况下还有另外两种选择:
- 请求 LLM 生成一个给出表达式的函数库代码,然后调用这个函数库给出满足要求的表达式。
- 直接请求 LLM 给出满足要求的表达式。
上述两种选择无论选择哪一种,任务都很难分解,只能由单个角色来实现,也就是完全考验基础 LLM 的能力,所需要的提示词写起来会非常复杂。基础 LLM 生成的代码会存在各种 bug,需要手工来做修改。我确实花了不少时间,尝试通过人工提示词工程,使用基础 LLM(即包括OpenAI的GPT-4o和阿里巴巴的qwen2.5)来实现这两种选择,然而最后放弃了。至少目前来说,基础 LLM 的能力暂时还不足以完美实现上述这两个任务。这是基础 LLM 目前能力的限制造成的,我们就没必要钻这个牛角尖了。
此类难以分解且基础 LLM 都难以实现的任务,使用多 Agent 开发框架其实也无法解决。我决定还是采取笨程序员的老办法,手撸代码!虽然实现起来有些细节,但代码其实并不难写。函数库代码在库文件 calc_24_points.py 中,你感兴趣的话可以自行打开查看。
实现第二个角色——GameJudger
在 GameJudger 的初始化函数中,watch 了 4 个 Action:UserRequirement、RequireDealCardsAgain、HumanGiveExpression、MachineGiveExpression。这 4 个 Action 触发的后续 Action 其实有两个。
UserRequirement、RequireDealCardsAgain 触发的后续 Action 都是 DealCards。而 HumanGiveExpression、MachineGiveExpression 则应该首先触发执行 CheckExpression,然后根据 CheckExpression 返回的表达式是否正确的检查结果决定下一步要执行的 Action。若 CheckExpression 返回 “Correct” (正确) 则执行 DealCards;若 CheckExpression 返回 “Wrong” (错误) 则执行 WrongExpression。这些条件判断的代码需要在 GameJudger 的 _act() 函数内实现。
_act() 函数中值得注意的有 4 个地方。
- 通过从记忆中获取最后一条消息的 cause_by 属性来判断最近执行的 Action 是哪一个。UserRequirement 代表 MetaGPT 应用刚刚启动时的第一个 Action,消息的 content 属性内容是在命令行输入的 idea 参数。其他 Action 用各自 Action 子类的类名来表示。
-
todo 代表了当前要执行的后续 Action。获得 todo 有两种方式。
-
一种方式是通过 self.rc.todo 获得,我们在上节课的例子 build_customized_multi_agents.py 中已经看到。这样获得的 todo 就是在 Role 子类的初始化函数中通过 set_actions() 函数设置的第一个 Action。
- 另一种方式是直接创建一个 Action 子类的实例作为 todo,这样后续执行的 Action 就是这个 Action 子类。
- 使用 self.rc.env.publish_message() 函数发布一个新的消息,消息的 cause_by 通常设置为最近执行的 Action 子类的类名。对于上述 CallMathProdigy、WrongExpression、RequireDealCardsAgain、ExitGame 这一类 Action,不需要执行什么业务逻辑,只需要发一条消息即可。例如:
- 在 _act() 函数的末尾,如果之前的代码已经发布了消息,就无需发布其他消息,可以简单发布一个 send_to 设置为 MESSAGE_ROUTE_TO_NONE 的消息,这个消息不会被任何 Role 子类对象接收到。
实现第三个角色——GamePlayer
在 GamePlayer 角色的 _act() 函数中,同样也需要执行的一些条件判断。这个函数首先通过执行 GetHumanReply 这个 Action 来获得用户的输入。然后根据用户的输入来发布不同类型的消息(cause_by 设置为不同的 Action 子类)。
- 如果用户输入 “deal”,代表用户放弃当前这一轮游戏,请求重新发牌,则发布 RequireDealCardsAgain 消息。这个消息会被 GameJudger 接收到。
- 如果用户输入 “exit”,代表用户决定退出游戏,则发布一个 ExitGame 消息。ExitGame 这个 Action 子类没有被设置在任何 Role 子类的 _watch() 函数内,因此这是一条无人接收的消息,会导致 MetaGPT 应用的退出。
- 如果用户输入 “help”,代表用户难以自行解决表达式的问题,需要求助于 MathProdigy,则发布一个 CallMathProdigy 消息。这个消息会被 MathProdigy 接收到。
- 上述三种情况都不是,系统认为是用户自行输入了表达式,则发布一个 HumanGiveExpression 消息。这个消息会被 GameJudger 接收到。
实现 main() 函数并运行应用
main() 函数的实现与上节课的例子 build_customized_multi_agents.py 类似,这里因为 GamePlayer 这个角色只需要是真人,所以直接把 is_human 设置为 True。另外为了能够长期玩游戏,我把 n_round 设置为一个很大的值 500。n_round 值默认为 3,这样只能玩 3 轮游戏,应用就会自动退出。
async def main(
idea: str = "play 24 points game with me",
investment: float = 3.0,
n_round: int = 500):
logger.info(idea)
team = Team()
team.hire(
[
MathProdigy(),
GameJudger(),
GamePlayer(is_human=True),
]
)
team.invest(investment=investment)
team.run_project(idea)
await team.run(n_round=n_round)
完整的代码实现在 play_24_points_game_v1.py 中,就不在这里贴全部的代码。
OK,我们已经按照角色和工作流的设计,实现了应用的第一个版本。我们把这个应用跑起来看看:
这个代码目前还很脆弱,当用户决定手工给出满足要求的表达式时,直接输入表达式内容即可,不要包括任何其余内容。例如:若这一轮发的牌为 [2, 3, 10, 1],“2 + (10 / 3) + 1”、“10 - 1 + 2 * 3” 都是合法的输入,输入表达式时不需要加上引号。
对第一版实现的强烈不满——LLM在哪里?
在 play_24_points_game_v1.py 这个实现中,你应该很快就会注意到所有的 Action 实现都并未调用 LLM,我只是以手工方式实现了前面设计的工作流。那么这还是一个 AI 应用吗?老师,您这不是在挂羊头卖狗肉嘛!我要退钱!!!
这个反应完全正常。不过不必着急,第一版这个实现其实只是一个雏形。我们在实现此类 Autonomous Agent 应用时,应该始终着眼全局,首先实现应用中最为重要的角色和工作流。为了达到这个目标,哪怕先采用手工方式实现也没关系,为的就是让工作流能够先运转起来。这个开发思想其实就是敏捷开发所提倡的 KISS 原则,并且可以与测试驱动开发 TDD 结合起来。首先我们完成一套最简单的实现,让一组初始测试用例能够跑起来。然后再添加更复杂、更细节的测试用例,并且扩充实现代码以便让新的测试用例能够跑通。
基于现有的 play_24_points_game_v1.py,后续可以使用 LLM 来实现的 Action 包括:
- 在 DealCards 中使用 LLM 来实现以随机的方式发牌。
- 在 CheckExpression 中使用 LLM 来判断表达式的正确性。
这两个目标,我已经实现在第二版代码 play_24_points_game_v2.py 中,你可以打开查看。
上述这两个目标都属于应用的局部优化,并不会影响应用整体的工作流和用户使用应用的方式。通过学习两个版本的代码,你可以理解抓大放小、先全局后局部、分离关注点的开发思想,其优点是可以让我们的开发过程有条不紊、步步为营、渐入佳境。无论使用 MetaGPT 实现我们的应用,还是使用其他开发框架实现我们的应用,都可以采用这种开发思想。
此外,在 MachineGiveExpression 中使用 LLM 来直接给出满足要求的表达式,这个目标确实难度很大,不过也是有解的。在后面的课程中,我会给出具体的解决方案。
为不同 Action 设置不同的 LLM
在第二版的 CheckExpression 实现中,为了判断表达式的正确性,需要执行四则运算。这时候 qwen2.5 就有些力不从心了,幸好它还有一个亲兄弟 qwen2.5-math 更适合做这件事。
MetaGPT 的设计非常灵活,支持为不同的 Action 或者不同的 Role 设置不同的 LLM。可参考官方文档。
不过我们在使用 qwen2.5-math 之前需要做一些配置。
ollama 网站上目前并没有阿里巴巴官方版本的 qwen2.5-math。我们需要从 HuggingFaceHub 上下载一个 gguf 格式的模型文件(也不是官方发布的,官方并未发布 gguf 格式的模型文件。各种模型文件的格式,参考 02 课的预备知识)。地址为:https://huggingface.co/bartowski/Qwen2.5-Math-7B-Instruct-GGUF/blob/main/Qwen2.5-Math-7B-Instruct-Q5_K_S.gguf
下载完这个模型文件后,编辑一个模型配置文件 qwen2.5-math.mf,内容为:
执行以下命令,在 ollama 中创建新的模型 qwen2.5-math。
然后为 qwen2.5-math 创建一个 MetaGPT 配置文件:~/.metagpt/qwen2.5-math.yaml,内容为:
llm:
api_type: 'ollama'
base_url: 'http://127.0.0.1:11434/api'
model: 'qwen2.5-math'
temperature: 0
CALC_USAGE: True
repair_llm_output: true
在代码中,首先创建 qwen2.5-math 的 Config 对象:
在创建 Action 子类的对象实例时,可以传入这个 Config 对象,这样这个 Action 子类的对象实例就使用对应的 LLM 了。例如:
第二版实现的主要修改
除了为 CheckExpression 配置单独使用的 LLM qwen2.5-math 外,其余主要的修改包括:
- 因为要修改的两个 Action 都是由 GameJudger 执行的,为了维护方便,把这两个 Action 和 GameJudger 分离到单独的文件 game_judger_v1.py 中。同时把其余未修改的 Action 分离到一个 all_actions.py 中。
- DealCards 中调用 qwen2.5 的提示词设计为:
PROMPT_TEMPLATE: str = """
Generate 4 random natural numbers between 1 and 13, include 1 and 13. Just return 4 numbers in an array, don't include other content. The returned array should not be repeated with the following arrays:
{old_arrays}
"""
这里需要注意的是为了避免出现重复的数组 (重复的发牌),需要把之前已经使用过的所有数组通过 old_arrays 传给 qwen2.5。
- CheckExpression 中调用 qwen2.5-math 的提示词设计为:
PROMPT_TEMPLATE: str = """
Calculate the result of this conditional expression 'abs(({expression}) - 24) < 0.1'.
Just return "True" or "False", don't return other content.
"""
这里需要注意的是,考虑到 qwen2.5-math 执行算数计算 (主要是除法) 时可能会有浮点数误差,不应该直接将表达式与整数 24 做相等比较,而是比较它们之间的差值是否小于 0.1。
- 添加了两个辅助函数,get_old_point_arrays() 用来获取之前使用过的所有数组,extract_result() 用来从 qwen2.5-math 的输出内容中获取到对表达式的判断结果。
除了文件名不同外,第二版实现的运行方法与第一版完全一致:
总结时刻
对于应用软件的开发者来说,带着具体的开发任务来开展学习,实现满足业务需求的可运行代码,是最有效率的学习方法。这就是本课程所推崇的“剑宗模式”学习方法,在不断的编程练习中,循序渐进,学以致用。而不是像“气宗模式”那样,长篇累牍地介绍理论和算法,却吝啬写出能运行的代码。你会感觉是在隔靴揣痒,一直在卖关子、玩套路。
在这一课中,我带着你实现了第一个 Autonomous Agent 应用我们学习到了以下知识:
- 设计方面:做角色建模和工作流设计。
-
编程方面:根据之前的设计,自顶向下、逐步求精。
-
首先实现应用的框架代码 (创建各个 Action 子类、各个 Role 子类的初始化函数),然后编写每个 Action 子类的 run() 函数,并在 Role 子类的 _act() 函数中实现设计的工作流。
- 为了开展对照,我实现了应用的两个版本。第一个版本所有 Action 子类的 run() 函数均未调用 LLM。第二个版本中 DealCards、CheckExpression 的 run() 函数调用了 LLM。从中我们也可以理解,并非所有的 Action 子类都需要调用 LLM,还是需要根据具体情况来具体分析。有些 Action 甚至都可以没有自己的业务逻辑,仅仅作为系统中的一个事件来使用。
在下一课中,我们继续学习 MetaGPT 的一些更加高级和复杂的知识,并且介绍 MetaGPT 未来即将发布的 1.0 版的发展方向和变化。
课程代码链接:https://gitee.com/mozilla88/autonomous_agent/tree/master/lesson_04
思考题
在 MetaGPT 应用中,Action 与 Message 是什么关系?将 Action 直接作为系统中可订阅的事件,这样设计有哪些优点?
期待你的分享。如果今天的内容对你有所帮助,也期待你转发给你的同事或者朋友,大家一起学习,共同进步。我们下节课再见!
- mxzjzj 👍(2) 💬(1)
有没有交流群啊
2025-01-24 - Geek_8cf9dd 👍(0) 💬(1)
老师,完整源代码在哪里可以下载
2025-02-21 - mxzjzj 👍(0) 💬(1)
学完这课,不知道从哪里开始下手,需要本地先部署大模型吗
2025-02-06 - Geek_30bdf2 👍(0) 💬(1)
我发现一个问题,如果让它不返回步骤只返回结果,则很容易出现错误答案,但是如果有步骤,那就会计算正确了,这是什么原因? ### 分析步骤 1. LLM的计算行为差异分析: - 无步骤时:可能使用快速直觉判断 - 有步骤时:被迫进行详细计算 2. 这种现象的原因: - 链式思考(Chain-of-Thought)效应 - 当需要展示步骤时,LLM被迫进行更严谨的思考 - 类似人类解题:写出步骤会更仔细 ### 改进建议
关键点: - 强制LLM展示计算步骤 - 在最后单独返回True/False - 计算过程和结果分离 这样设计可以: 1. 确保LLM进行完整计算 2. 保持最终输出简洁 3. 便于调试和验证2025-02-01 - Geek_30bdf2 👍(0) 💬(1)
在v2版本输入后中出现了 Traceback (most recent call last): File "/root/autodl-tmp/work/MetaGPT/metagpt/utils/common.py", line 664, in wrapper return await func(self, *args, **kwargs) File "/root/autodl-tmp/work/MetaGPT/metagpt/roles/role.py", line 551, in run rsp = await self.react() AttributeError: 'NoneType' object has no attribute 'group' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/root/autodl-tmp/work/MetaGPT/metagpt/utils/common.py", line 650, in wrapper result = await func(self, *args, **kwargs) File "/root/autodl-tmp/work/MetaGPT/metagpt/team.py", line 134, in run await self.env.run() Exception: Traceback (most recent call last): File "/root/autodl-tmp/work/MetaGPT/metagpt/utils/common.py", line 664, in wrapper return await func(self, *args, **kwargs) File "/root/autodl-tmp/work/MetaGPT/metagpt/roles/role.py", line 551, in run rsp = await self.react() File "/root/autodl-tmp/work/MetaGPT/metagpt/roles/role.py", line 520, in react rsp = await self._react() File "/root/autodl-tmp/work/MetaGPT/metagpt/roles/role.py", line 475, in _react rsp = await self._act() File "/root/autodl-tmp/work/learn_metagpt/autonomous_agent/lesson_04/game_judger_v2.py", line 92, in _act check_result = await todo.run(msg.content) File "/root/autodl-tmp/work/learn_metagpt/autonomous_agent/lesson_04/game_judger_v2.py", line 69, in run check_result = extract_result(rsp) File "/root/autodl-tmp/work/learn_metagpt/autonomous_agent/lesson_04/game_judger_v2.py", line 32, in extract_result result = eval(search_obj.group(1)) AttributeError: 'NoneType' object has no attribute 'group' 的情况,请问是什么原因呢
2025-01-30