07 扫清AutoGPT开发道路上的障碍
你好,我是李锟。
在上节课中,我们成功完成了 AutoGPT 的安装部署,包括 Server 和 Frontend 两部分。因为 AutoGPT 新版本安装起来比较复杂,我花费了很多时间讲解具体的步骤,没有在上一课中运行一个 Agent 的例子,并且介绍如何开发自定义的 Block。所以在这一课中,我将继续讲解 AutoGPT 开发方面的内容。这一课是上一课的延续,这两节课是密不可分的整体。
理解 AutoGPT 的工作和开发模式
前面几节课中的 MetaGPT 是作为一个库来使用而设计的,因此非常容易理解。基于 MetaGPT,你既可以开发一个服务器端应用,也可以开发一个客户端应用。作者给你提供了 100% 的选择权利。
然而从上节课中,我们了解到 AutoGPT 与 MetaGPT 的设计大不相同,它被设计出来是为了作为一个支持高可用性的在线服务(一个服务器端应用)来使用。使用 AutoGPT 必须先部署这个 Server,然后在其现有源代码的基础之上,叠加我们自己的业务逻辑实现。主要的业务逻辑实现为自定义的 Block,并且使用 Frontend 所提供的图形界面工具组装和配置这些 Block,根据业务需求实现各种 Workflow,然后基于这些 Workflow 建造一个强大的 Autonomous Agent 应用。
运行和测试 MetaGPT 应用,我们可以简单地使用命令行来完成,这种方式最为简单直接。然而运行和测试 AutoGPT 应用,目前 AutoGPT 尚未提供命令行工具,我们只能通过其 Frontend 在浏览器的图形界面中完成。在我看来,这其实是一个设计缺陷。我预测未来 AutoGPT 新版本也会提供命令行工具。我会密切跟踪 AutoGPT 的最新发展,并及时更新。
另一个 AutoGPT 与 MetaGPT 的主要不同是,因为 AutoGPT 是一个 B/S 架构的在线服务,因此 AutoGPT 依赖服务器端的数据库来实现自己的功能。数据库包括了关系数据库和向量数据库两大类,由 Supabase(基于 PostgreSQL)来统一提供。要理解 AutoGPT 的工作和开发模式,我们需要先理解 AutoGPT 的数据库设计。
AutoGPT 的这种工作和开发模式,带给了我们以下几个挑战:
- 如何清晰分隔 AutoGPT(开源的)自身的代码和基于 AutoGPT 的应用项目的业务代码 (通常是闭源的),使得两者之间能够完美协作,而不会相互冲突?两者需要有不同的 git 仓库,确保既可以及时更新 AutoGPT 自身的代码,也不会破坏已开发的应用项目代码。我们尽量不要修改 AutoGPT 自身的代码,否则必须向 AutoGPT 的官方 git 仓库提出 pull 请求,得到批准之后才能够将修改的代码提交到官方仓库。另一方面,如果我们的能力很强,并且认为修改和新增的代码非常有价值,也应该把修改的代码回馈给 AutoGPT 社区,形成与社区的良性互动。
- 如何支持我们希望使用的开源 LLM。上节课中我介绍了 AutoGPT 可以通过 ollama 来使用 Meta 的 Llama,然而现有的 AutoGPT 代码仅支持 Llama3,而不是最新的 Llama3.3。而我们更青睐于阿里巴巴的 qwen2.5,也希望能继续使用 qwen2.5。未来我们可能还想使用更多优秀的开源 LLM。在目前阶段,达到这些目标需要靠我们自己 DIY。不过好消息是 AutoGPT 开发团队也把支持更多开源 LLM 列入了优先事项,正在开发过程中。我们的 DIY 是一种临时的解决方案,未来会改为采用 AutoGPT 官方的实现。
- 在 AutoGPT 新版本中,AutoGPT 团队优先实现了以一种图形界面类似低代码平台的方式来开发智能体应用,貌似这与我在前面课程中批评过的 Dify 以及字节跳动的扣子区别不大。然而 AutoGPT 新版本与 Dify 这些低代码平台仍然是有本质区别的,它为开发者提供了更大的灵活性。我们在以图形界面完成 Agent 的基本开发之后,仍然希望有机会对实现细节进行细微的控制。因此我们需要了解在图形界面之下(汽车的引擎盖),系统是如何工作的,我们还能在底层做哪些工作。
你估计已经很不耐烦了,迫切希望看到一个 Agent 应用是如何开发和运行的。不过在运行第一个 Agent 之前,我们需要先解决上述的前两个挑战。
分隔 AutoGPT 自身代码和应用项目代码
我们希望将应用项目的代码放在另一个目录中,与上节课中通过 git 从 github 拉取的 ~/work/AutoGPT 目录分隔开。
与学习 MetaGPT 类似,我们先初始化一个 Python 项目。
mkdir -p ~/work/learn_autogpt
cd ~/work/learn_autogpt
touch README.md
# 创建poetry虚拟环境,一路回车即可
poetry init
因为众所周知的原因,建议使用国内的 Python 库镜像服务器,例如上海交大的镜像服务器:
如果上海交大镜像服务器的访问速度很慢,也可以使用其他镜像服务器,请你自行搜索其他镜像服务器的地址。
然后安装一些常用的 Python 库:
接下来我们需要思考一下在应用项目中包括哪些代码。我们先简单阅读一下如何开发自定义 Block 的官方文档。这个文档很长,而且写得有些乱,条理性不大好。好在我们没有必要从头到尾仔细读完,大致读一下前面 1/3 的部分就好了。其余内容等我们在下节课亲自实现自定义的 Block 时再来查阅。
根据这个文档,自定义的 Block 应该放置在 autogpt_platform/backend/backend/blocks 目录中。既然我们希望将自定义的 Block 放在应用项目的目录中,一个最直接的思路是也许可以通过创建符号链接(symbol link)的方式将自定义 Bolck 的目录链接到上述这个目录下。究竟能不能这样做,我们需要先读一下 autogpt_platform/backend/backend/blocks 目录中的 init.py,这个文件中有加载所有 Block 的代码实现。
import importlib
import os
import re
from pathlib import Path
from typing import Type, TypeVar
from backend.data.block import Block
# Dynamically load all modules under backend.blocks
AVAILABLE_MODULES = []
current_dir = Path(__file__).parent
modules = [
str(f.relative_to(current_dir))[:-3].replace(os.path.sep, ".")
for f in current_dir.rglob("*.py")
if f.is_file() and f.name != "__init__.py"
]
从这个文件开头的代码片段,我们可以了解到,代码会读取 autogpt_platform/backend/backend/blocks 目录中的所有(包含其子目录)Python 文件,将其作为包含了自定义 Block 的模块加载。 然而 current_dir.rglob() 这个函数不会读取符号链接的子目录和文件,为了支持符号链接,需要修改一下这段代码,改为以下实现:
import importlib
import os
import re
from glob import glob
from pathlib import Path
from typing import Type, TypeVar
from backend.data.block import Block
# Dynamically load all modules under backend.blocks
AVAILABLE_MODULES = []
current_dir = Path(__file__).parent
file_list = [
Path(f)
for f in list(glob(f"{current_dir.resolve()}/**/*.py", recursive=True))
]
modules = [
str(f.relative_to(current_dir))[:-3].replace(os.path.sep, ".")
for f in file_list
if f.is_file() and Path(f).name != "__init__.py"
]
修改文件之前,我建议你先做一下备份。
修改了上述的 init.py 以支持符号链接之后,我们就可以在应用项目下为自定义 Block 创建目录,并在 AutoGPT 的 autogpt_platform/backend/backend/blocks 目录下为这个目录创建一个符号链接。
cd ~/work/learn_autogpt
mkdir -p backend/blocks/customized
cd ~/work/AutoGPT/autogpt_platform/backend/backend/blocks
ln -s ~/work/learn_autogpt/backend/blocks/customized .
然后我们复制一个 AutoGPT 最简单的官方 Block——maths.py,这是一个简单的计算器,只能算加减乘除,我们做一点点修改,看看在 Frontend 图形界面中能否正常使用。
修改这个新建的 my_maths.py,把文件中的类名 CalculatorBlock 改为 CustomizedCalculatorBlock,并且为这个 Block 创建一个新的 block id。因为 AutoGPT Server 要求运行在同一个服务器的不同 Block 都使用自己全局唯一的 block id,也就是一个 uuid,如果不修改 my_maths.py 中的 block id,就会与原先官方 maths.py 中的 CalculatorBlock 发生 id 冲突。
我们可以启动一个 Python shell,执行以下代码创建 uuid。
在 CustomizedCalculatorBlock 的 初始化函数 init() 中的 id=“”,添加刚才创建的 uuid。在 my_maths.py 中还有另外一个 CountItemsBlock,其 id 同样也需要修改为新的 uuid。
然后启动 AutoGPT Server:
在电脑上,把 Frontend 运行起来。
然后使用浏览器直接访问:http://localhost:3000/build。
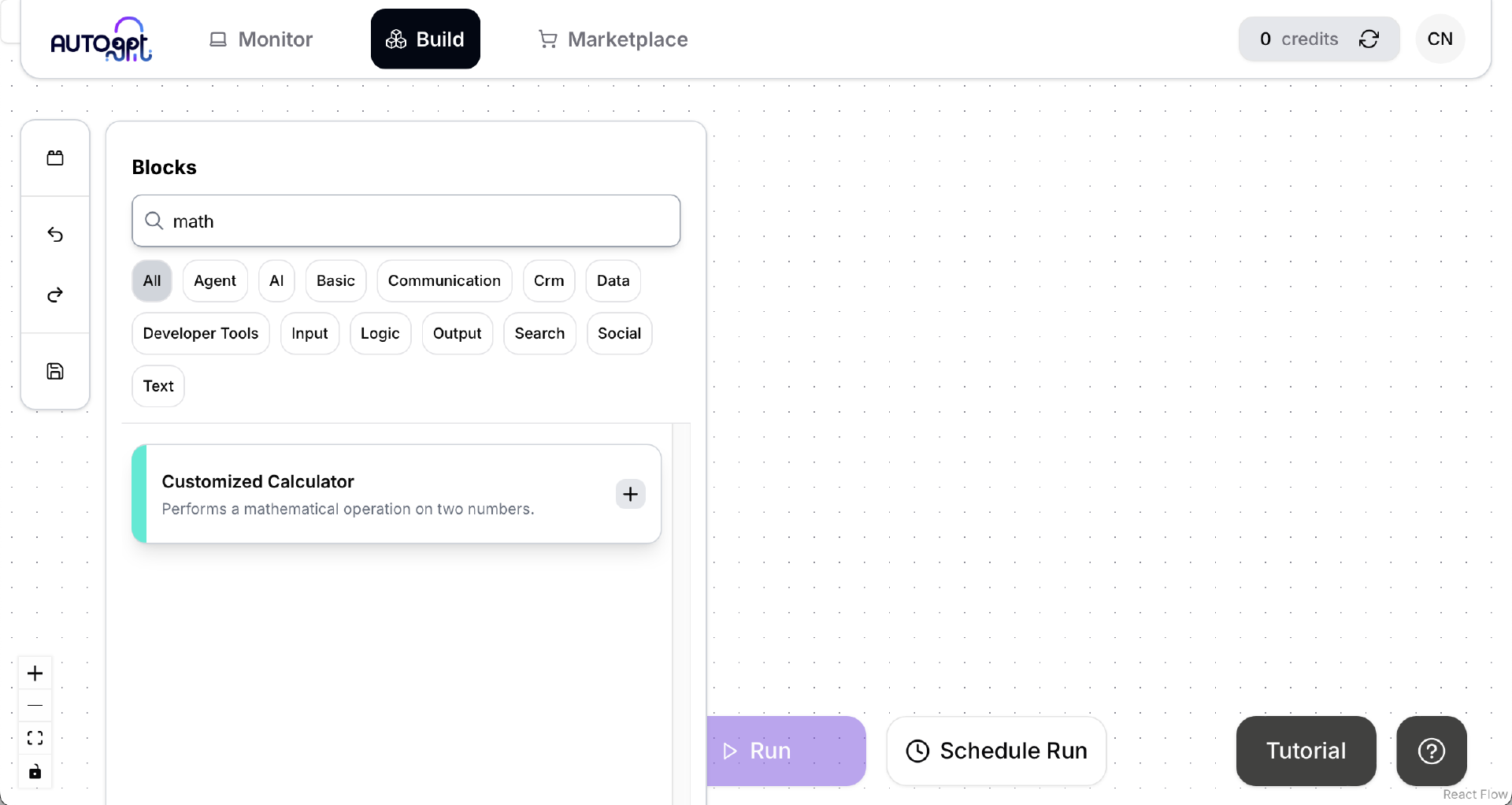
点击左侧工具栏最上面的 Blocks 按钮,在搜索框里输入 math,会出现一个叫做“Customized Calculator”的 Block。这个 Block 不是官方提供的,而是我们刚才创建的那个 customized/my_maths.py 中被我们改名的 CustomizedCalculatorBlock 类。看来 AutoGPT Server 是成功加载了我们的自定义 Block,太棒了!
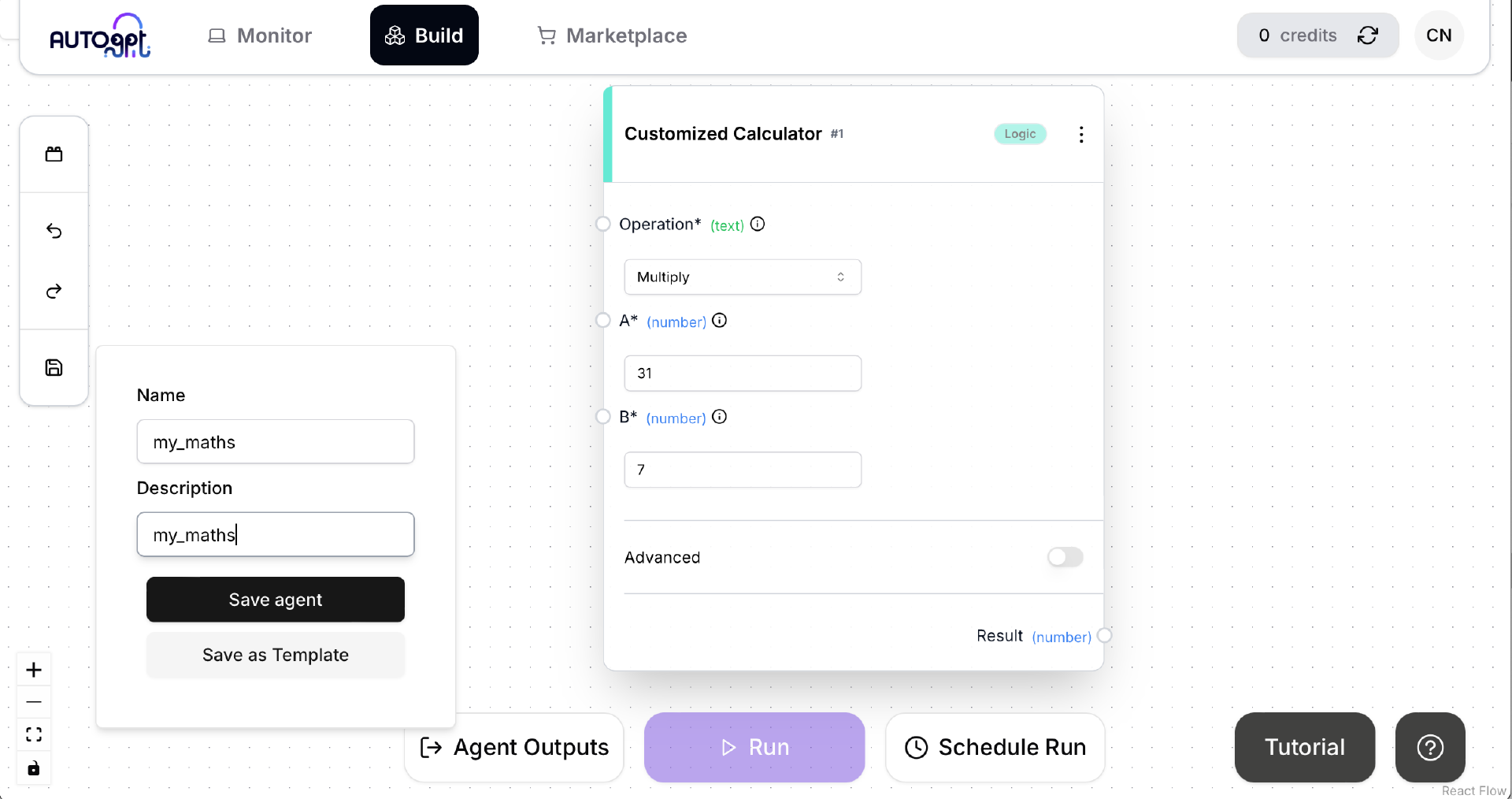
我们再试一下这个 Block 能否正常工作。添加这个 Block 并设置 Block 的参数,然后点击左侧工具栏最下面的 Save 按钮,随便取一个名字,将其保存为一个 Agent。这是一个最简单的 Agent,只有一个 Block。这个 Block 也是一个最简单的 Block,只能做简单的加减乘除。保存成功之后,下方原先灰度显示且无法点击的 Run 按钮不再为灰度状态,可以点击了。点击 Run 按钮运行这个 Agent。
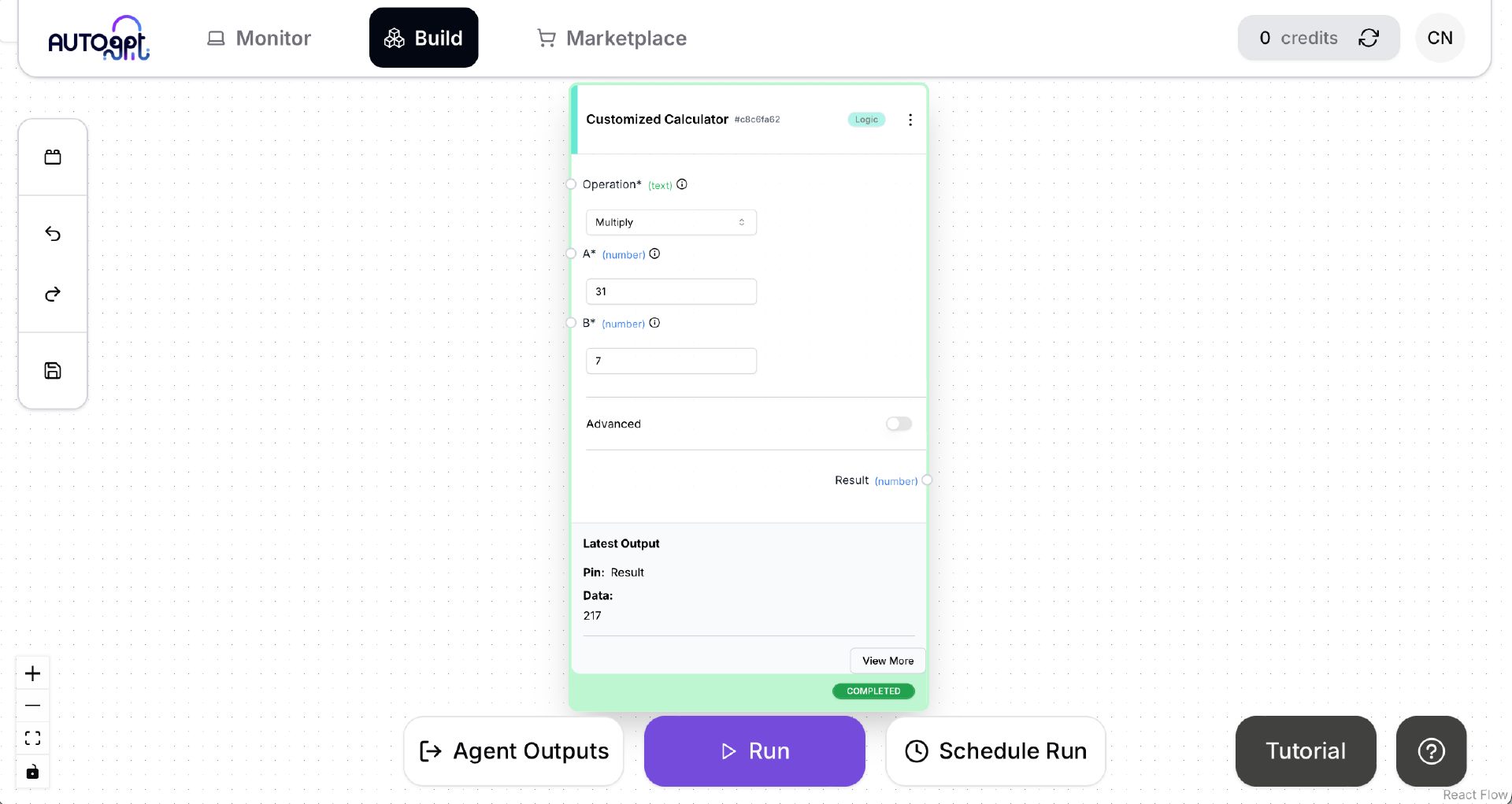
稍等片刻,等到 Agent 运行完成后,界面中 Customized Calculator 框中的“Latest Output”会显示这个 Block 运行后的结果 。计算结果正确,状态为 COMPLETED,看起来运行也没有什么问题。
接下来我们还要解决一个问题,我们是在应用项目的目录中开发自定义 Block,在编辑 Block 文件时自然希望能够方便地获取与 AutoGPT 相关的引用信息。因此我们需要把 AutoGPT 添加到应用项目的依赖中,而且要使用源代码的方式来添加依赖。这个做法我们在 03 课学习 MetaGPT 时已经使用过。在命令行执行:
cd ~/work/learn_autogpt
# poetry add --editable "../AutoGPT/autogpt_platform/backend"
poetry install --no-root && poetry run pip install -e "../AutoGPT/autogpt_platform/backend" --config-settings editable_mode=compat
OK,我们的 AutoGPT 应用项目的开发环境就完成了,可以在这个项目下开发自定义的 Block。
接下来我们解决前面提到的第二个挑战,配置我们希望使用的开源 LLM——qwen2.5。因为我们未来要开发的应用中的自定义 Block 会大量使用 LLM,能够直接使用部署在本地的开源 LLM 自然是最为方便的。
让 AutoGPT Server 支持其他开源 LLM
虽然目前 AutoGPT Server 通过 ollama 直接支持的开源 LLM 数量很少,不过通过阅读其源代码,我发现添加其他开源 LLM 也很容易。只需要修改两个文件:autogpt_platform/backend/backend/blocks/llm.py 和 autogpt_platform/backend/backend/data/block_cost_config.py。
以下是具体的修改方法,我们在 llm.py 中添加两行。
# Ollama models
OLLAMA_LLAMA3_8B = "llama3"
OLLAMA_LLAMA3_405B = "llama3.1:405b"
OLLAMA_QWEN2_5_7B = "qwen2.5" # 新增内容
# Limited to 16k during preview
LlmModel.LLAMA3_1_70B: ModelMetadata("groq", 131072),
LlmModel.LLAMA3_1_8B: ModelMetadata("groq", 131072),
LlmModel.OLLAMA_LLAMA3_8B: ModelMetadata("ollama", 8192),
LlmModel.OLLAMA_LLAMA3_405B: ModelMetadata("ollama", 8192),
LlmModel.OLLAMA_QWEN2_5_7B: ModelMetadata("ollama", 8192), # 新增内容
在 block_cost_config.py 中添加一行。
同样,修改这两个文件前,我建议你先做一下备份。
然后启动 AutoGPT Server:
在运行 Frontend 的笔记本电脑上,把 Frontend 运行起来。
注意:重新启动 AutoGPT Server,不需要重新启动 AutoGPT Frontend。
然后使用浏览器直接访问:http://localhost:3000/build。
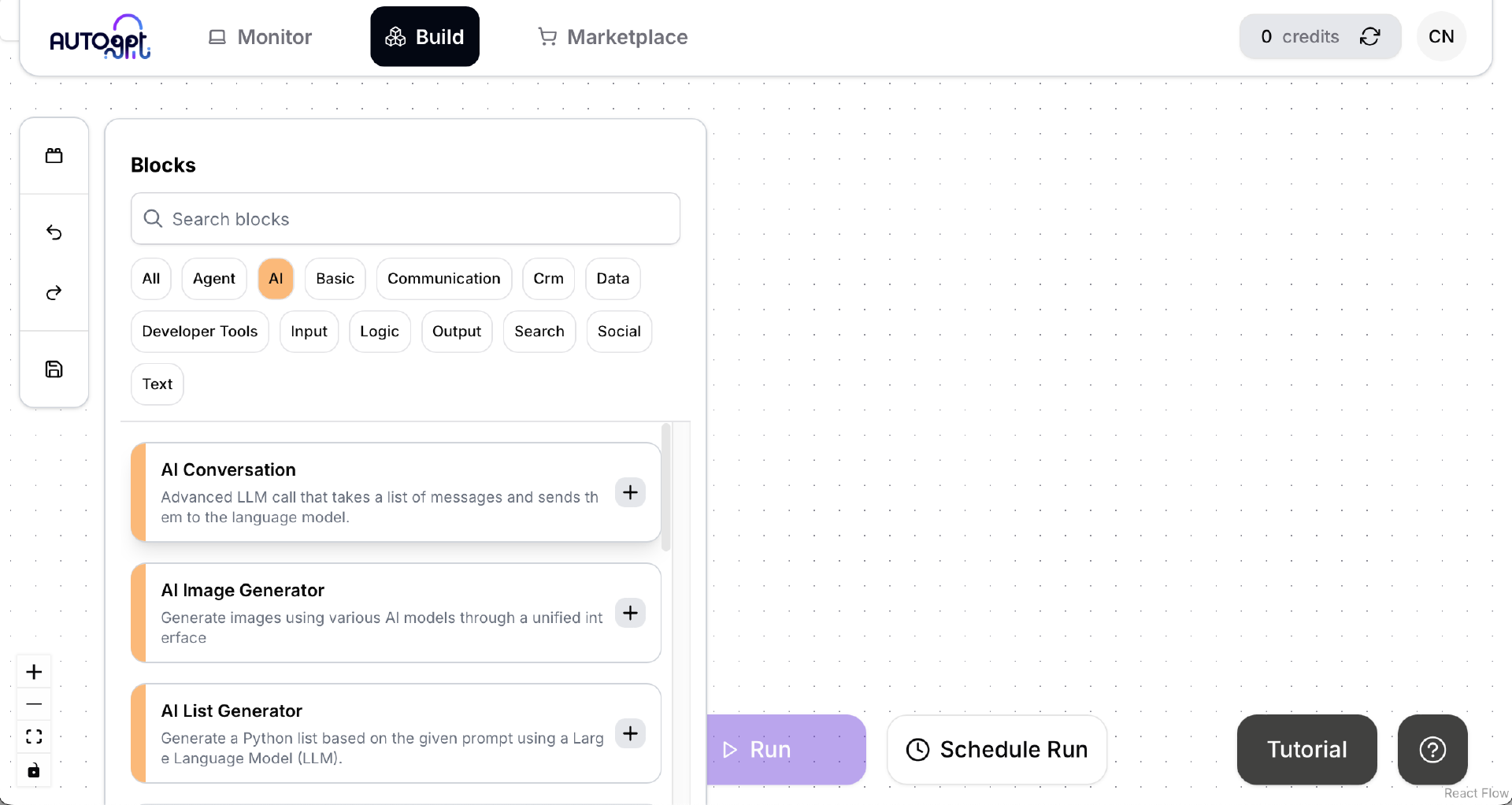
点击左侧的 Blocks 按钮,然后点击 AI 标签,这次我们将使用官方的 AI Conversation 这个 Block 来做测试。
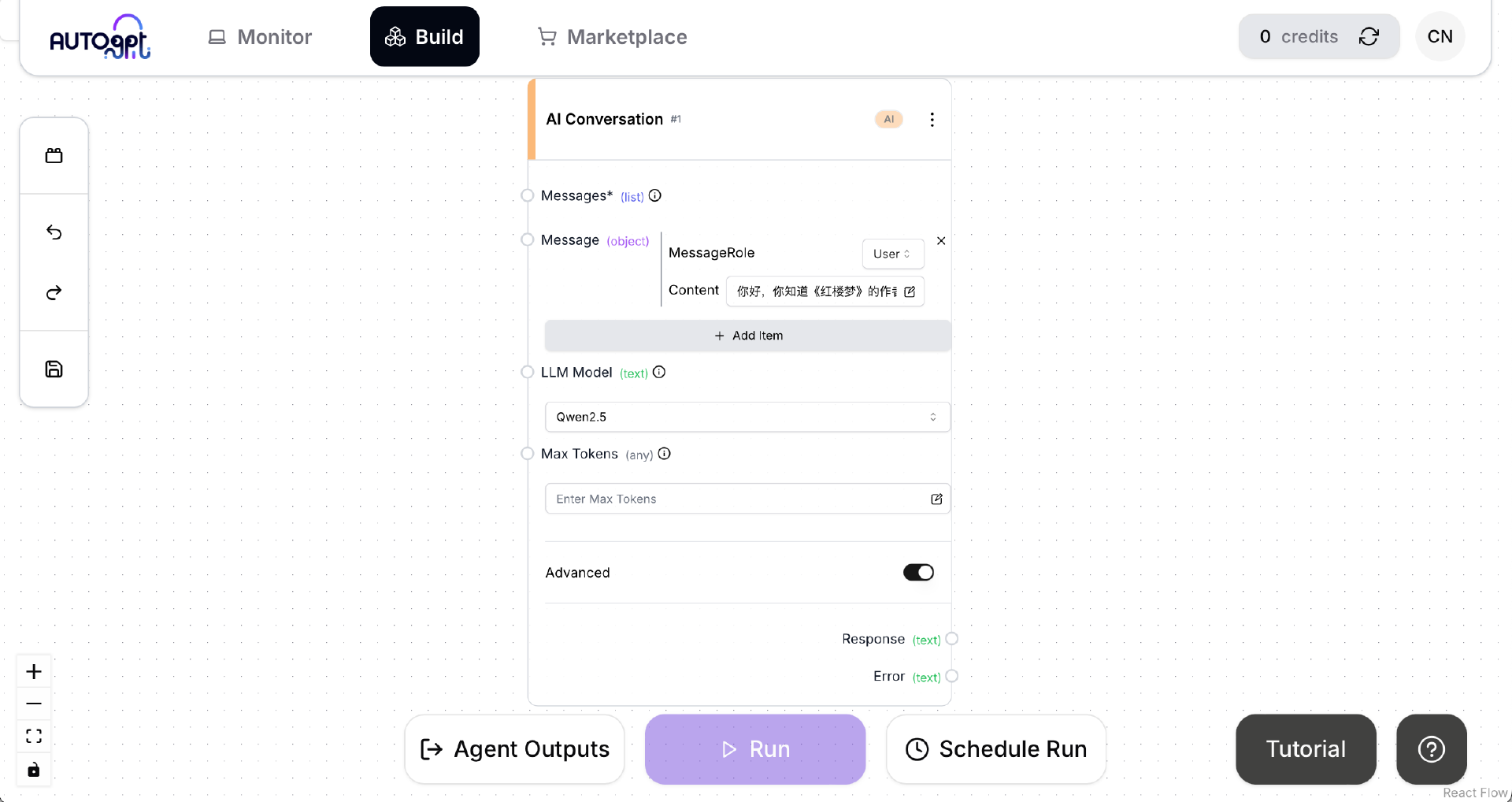
在 AI Conversation 框中打开 Advanced 选项,然后在 LLM Model 下拉框中选择新出现的选项 Qwen2.5。在 Messages 下添加一个消息“你好,你知道《红楼梦》的作者是谁吗?”,并且将 MessageRole 设置为“User”。
保存 Agent,点击 Run 按钮运行 Agent。

稍等片刻,等到 Agent 运行完成。如果出现上述界面,说明 AutoGPT Server 已经成功地通过 ollama 调用了我们安装的 qwen2.5。
学习到这里,你应该感受到了开源的力量所在,开源赋予了我们 DIY 的全部潜力和乐趣。接下来我们再简单看一下 AutoGPT Server 的数据库设计。
AutoGPT Server 的数据库设计
在 Frontend 的图形界面中创建了 Agent 之后,所有 Agent 的相关设置均保存在通过 Supabase 安装的 PostgreSQL 数据库中。我们有必要了解一下 AutoGPT Serever 的数据库设计,才能使用好 AutoGPT Server。这种基于关系数据库的开发方式,与之前基于 Python 代码的 MetaGPT 相比,显然复杂了很多。不过考虑到 AutoGPT 被设计为一个支持高可用性的在线服务,这样设计也很容易理解。
通过上节课的 supabase 命令行工具安装的 PostgreSQL 数据库支持远程连接,因此我们可以使用任意支持 PostgreSQL 的客户端工具来连接到数据库。我推荐使用 PostgreSQL 官方提供的 pgAdmin 4。PostgreSQL 数据库运行在 Linux 主机的 54322 端口,用户名、密码、数据库名均为 postgres,AutoGPT Server 自身的表在 platform 这个 schema 下。
AutoGPT 新版本的官方文档中并没有其数据库表的说明文档。这也难不倒我们,我们可以使用 pgAdmin 4 连接到服务器端的 PostgreSQL 数据库,然后生成创建数据库表的 DDL,并生成数据库设计的 ER 图。数据库表的 DDL 在课程文件 autogpt_ddl.sql 中,其 ER 图如下:
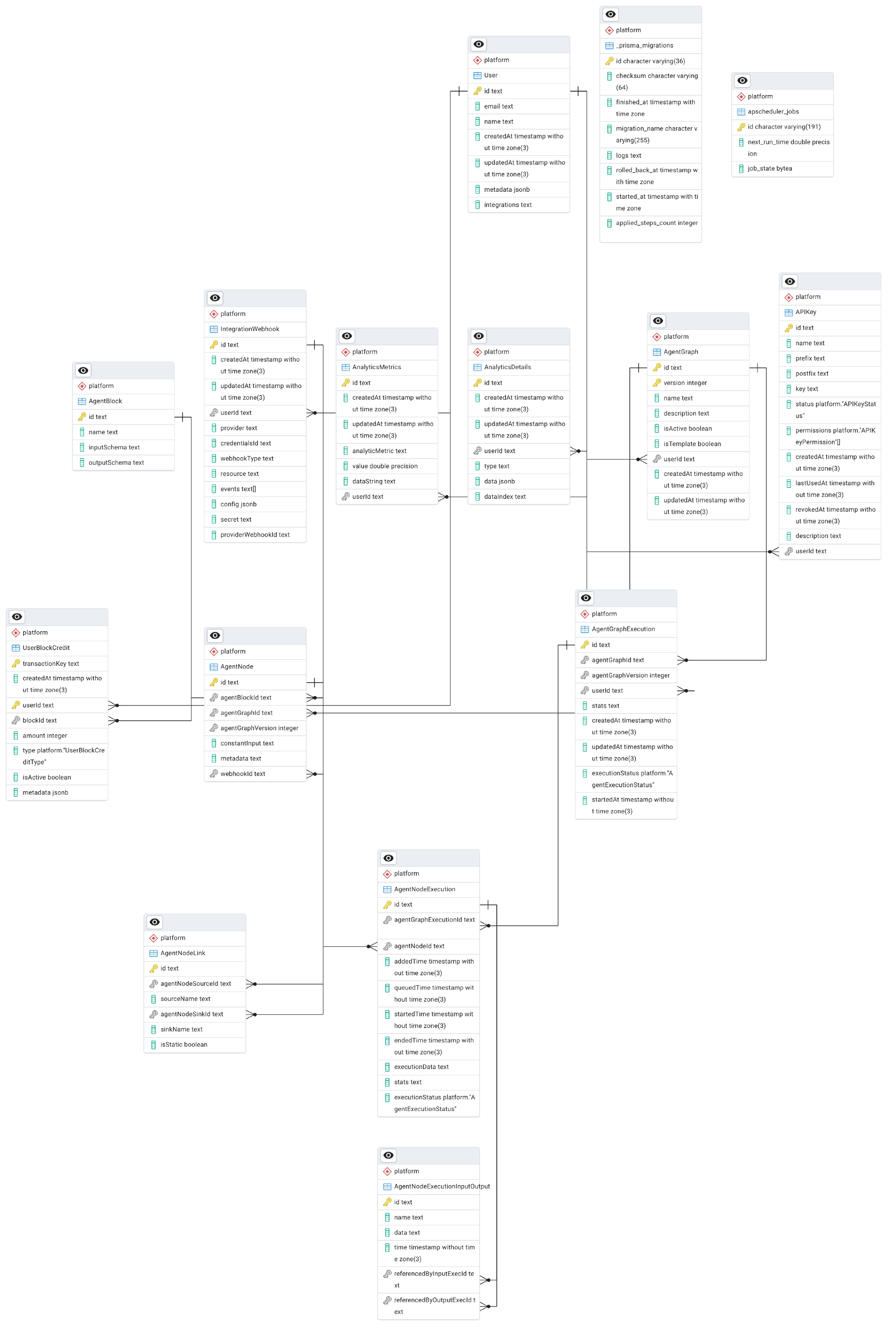
这节课我们先简单浏览一下数据库 DDL,在后续课程中我还会深入介绍 AutoGPT Server 数据库的细节。
总结时刻
这一课与上一课紧密衔接,我带你循序渐进地继续学习 AutoGPT。首先我们介绍了 AutoGPT 的工作和开发模式,然后引出了我们开发 AutoGPT 应用时会面临的三个挑战。这些挑战就是我们要解决的问题,而且需要靠我们 DIY 来解决,这就是开源的力量和乐趣所在。
在这节课中,我们解决了前两个挑战。在解决这两个挑战的过程中,还展示了如何使用 AutoGPT Frontend 的图形界面开发以及运行 Agent。AutoGPT 官方已经提供了很多 Block,我们还可以开发自定义的 Block,然后通过组合官方和自定义的 Block,建造功能强大的 Autonomous Agent 应用。在课程的末尾,我简单介绍了 AutoGPT Server 的数据库设计。
在下一课中,我们开始使用 AutoGPT 实现我们真正的需求——一个陪伴我们玩24点游戏的智能体应用。
课程代码:https://gitee.com/mozilla88/autonomous_agent/tree/master/lesson_07
思考题
AutoGPT Frontend 的全图形化开发方式,其优缺点各有哪些?
期待你的分享。如果今天的内容对你有所帮助,也期待你转发给你的同事或者朋友,大家一起学习,共同进步。我们下节课再见!