08 使用AutoGPT实现Autonomous Agent应用
你好,我是李锟。
在前面两节课中,我们花费了不少工夫安装好 AutoGPT,熟悉了 AutoGPT 的工作和开发模式,并且解决了开发 AutoGPT 应用的两个直接挑战。这节课将开启一个非常有意思的部分,开发我们自己的第一个 Autonomous Agent 应用(为了吃这碟醋,我们来包一顿饺子)。我会带着你基于 AutoGPT 实现 01 课中讨论过的那个 24 点游戏智能体应用。
角色建模和工作流设计
与 04 课的设计开发过程相同,我们要做的第一步仍然是角色和工作流设计。因为我们在 04 课中已经基于 MetaGPT 实现过一次这个应用,很熟悉这个应用中的角色和工作流。不需要重复相同的内容,在这节课里我们要做的是把 04 课针对 MetaGPT 的设计和实现移植到 AutoGPT 的环境。
从 06 课中学习到的 AutoGPT 基础概念,我们理解了 MetaGPT 的 Action 对应 AutoGPT 的 Block,因此 Action 可以直接移植为 Block。那么 MetaGPT 的 Role 在 AutoGPT 中对应的是什么呢?在 AutoGPT 中,与 Role 对应的概念就是 Agent。MetaGPT 支持多个 Role 的协作,同样的,AutoGPT 新版本也支持多个 Agent 的协作 (老版本仅支持单个 Agent)。
关于 AutoGPT 新版本中的多 Agent 协作,因为代码才实现不久,官方文档严重滞后,甚至没有说这件事。好在其开发团队还有一个 官方 blog 网站,他们在 2024年11月22日的一篇 blog:Introducing Agent Blocks: Build AI Workflows That Scale Through Multi-Agent Collaboration 中说了这件事。
更早之前在2024年7月,创始人 Toran Bruce Richards 发布在 X (即 Twitter) 上的文章 Introducing the Next Generation of AutoGPT 介绍了新版本的 AutoGPT。根据 Toran 的这篇文章以及他对留言的回复,AutoGPT 新版本的一个重要目标,就是能够很好地支持多 Agent 的协作。国内的技术媒体机器之心对 Toran 的这篇文章有及时的报道:GitHub 星标超 16 万,爆火 AutoGPT 进阶版来了:定制节点、多智能体协同。
既然 AutoGPT 新版本的 Agent 对应着 MetaGPT 的 Role,貌似 04 课中的工作流不需要做任何修改。然而经过我的测试,AutoGPT 新版本现有代码不是很稳定,每个 Agent 如果有两个输入,工作流在运行时会卡住。
在 24 点游戏应用的这个例子中具体来说就是 GameJudger 有两个输入 (承担了两个职责):发牌和验证表达式是否正确。解决方法其实不难,可以把发牌的职责从 GameJudger 中分出来,单独创建一个 GameDealer (游戏发牌员),这样每个 GameJudger 就只有一个输入了。按照新的角色划分方式,我对 04 课中的流程图做了修改,新的流程图如下:
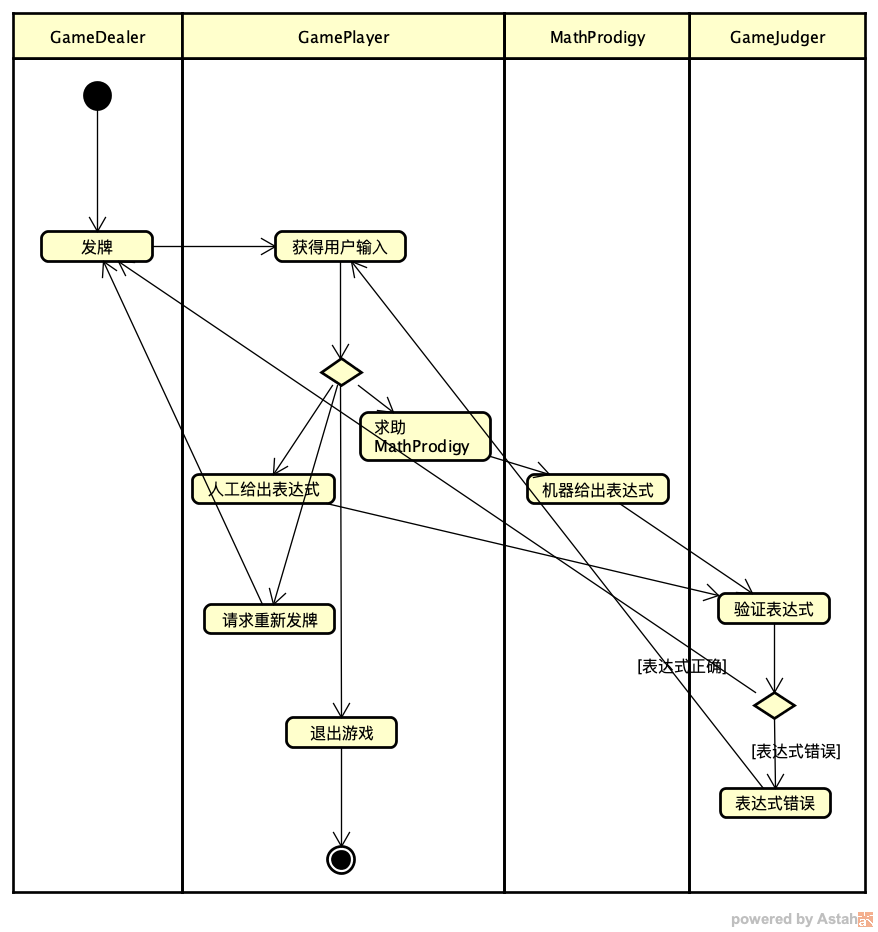
既然实现思路确定了,是不是就会一切顺利了呢?很遗憾,并非如此。
因为 AutoGPT 新版本正处于快速发展过程中,相关的文档极为欠缺。对于初学者来说,学习 AutoGPT 新版本可谓是障碍重重。我们必须采取不断探索的方式,通过解决实现过程中遇到的挑战来进行学习。很重要的是与 AutoGPT 开发团队保持密切的沟通,AutoGPT 开发团队的成员 (包括 Toran 在内) 大多都非常友善,可以直接与他们取得联系,向他们求教。
与 AutoGPT 开发团队最直接的联系方式是通过 Discord,此外还可以向 AutoGPT 的 GitHub 项目直接提交 issue。
逢山开路,遇水架桥——解决应用实现时遇到的挑战
我们需要先解决一些实现 24 点游戏应用过程中遇到的挑战,然后才能顺利将这个应用移植到 AutoGPT。学以致用极为重要,如果我们不从应用的需求出发亲自动手,就不会遇到这些挑战。
我们遇到的第一个挑战是:如何将 AutoGPT 的 Agent 实现为人类用户,即可接受人类用户的输入。
在 04 课的 MetaGPT 应用中,GamePlayer 这个 Role 是人类用户,因此在 AutoGPT 中,对应的 GamePlayer 这个 Agent 也应该是人类用户。在 04 课的实现中,接受人类用户输入的 Action 是 GetHumanReply,因此我在 AutoGPT 中建造了一个对应的 GetHumanReplyBlock,希望在这个 Block 的实现中接受用户的输入。然而尝试了一段时间,并且在 Discord 群里向 AutoGPT 开发团队成员求助,我发现目前这个功能是无法实现的。
在 AutoGPT 的 官方 Blocks 列表 中我发现有一个现成的 Agent Input Block,做的事情就是接受用户的输入。我想这下子省事了,直接使用这个 AgentInputBlock 就好了,不需要自己实现 GetHumanReplyBlock。
很快我就发现了一个严重问题,现有版本的 AgentInputBlock 只支持在整个工作流运行之前输入内容,而不是在工作流运行过程的中间节点输入内容。这样就不符合我们的要求了,因为 GamePlayer 输入内容是在他收到 GameDealer 发的牌之后。我与 AutoGPT 开发团队成员讨论过这个需求 (支持工作流中间节点的用户输入),他们承诺会尽快解决这个问题。
预计在本课程上线时,这个问题已经得到解决,到那个时候我会及时更新本节课的内容。本节课目前的内容是过渡性的,我们需要找到一个临时解决方案,绕开这个问题。一个绕开这个问题的方法是模仿用户的输入,在 GamePlayer 的所有允许的选项中,每次随机选择其中一种。
在 GetHumanReplyBlock 当前的过渡实现中,run() 函数是这样的:
def run(self, input_data: Input, **kwargs) -> BlockOutput:
cards_posted = input_data.cards_posted
input_list = [
"deal",
"help",
"exit",
"12 + 2 * (1 + 5)",
"5 * 3 - 7 + 11",
]
input_idx = random.randint(0, 4)
yield "user_input", input_list[input_idx]
GamePlayer 一共有 4 种允许的选项:
- 输入 “deal” 请求 GameDealer 重新发牌
- 输入 “help” 请求 MathProdigy 协助给出正确的 24 点表达式
- 输入 “exit” 请求退出游戏
- 输入一个 24 点表达式(正确、错误的表达式各一种)
在上述代码中,GetHumanReplyBlock 会随机返回 4 种选项中的一种(具体实现中是 5 种,因为 24 点表达式还分成正确、错误两种)。
注意:为了简化教学起见,GameJudger 的实现中并未检查 GamePlayer 给出的 24 点表达式中的 4 个整数是否与 GameDealer 最近发的牌一致,而只是简单检查了 24 点表达式的结果是否正确。检查 24 点表达式中的 4 个整数是否与发的牌一致,我将这个任务留给你在课后自行实现。
第二个挑战是搞清楚在 AutoGPT 中如何根据不同的情况调用不同的 Block,而不是只能串行工作。
我们需要有一个能够执行条件判断的 Block,以便实现工作流中的不同分支,类似编程语言之中的 if…elif…else 这样的结构。查找 官方 Blocks 列表 我发现有一个 Condition Block,就是来做条件判断的。OK,我们尝试使用这个 ConditionBlock 来实现条件判断,而不是自己发明轮子。
第三个挑战是搞清楚在 AutoGPT 的 Block 中如何与 LLM 交互。
在 官方 Blocks 列表 中有一个 AI Conversation Block,在上节课中我已经展示了它的用法,这个 Block 可以用来实现与 LLM 的一次对话。然而试用了这个 AIConversationBlock 之后,我发现它的输入格式无法满足 24 点游戏应用的需要。
具体来说,发牌和验证表达式是否正确,这两个 Block 需要的输入格式与 AIConversationBlock 是不同的,无法直接使用 AIConversationBlock。因此我选择了实现两个 AIConversationBlock 的子类 DealCardsBlock 和 CheckExpressionBlock,对应 04 课 play_24_points_game_v2.py 中的 DealCards 和 CheckExpression 这两个 Action。
还有一件事我们在上节课中忘记做了,除了 qwen2.5 外,还需要支持 qwen2.5-math。解决方法与上节课的方法类似,只需要修改两个文件:autogpt_platform/backend/backend/blocks/llm.py 和 autogpt_platform/backend/backend/data/block_cost_config.py。
我们在 llm.py 中添加两行。
# Ollama models
OLLAMA_LLAMA3_8B = "llama3"
OLLAMA_LLAMA3_405B = "llama3.1:405b"
OLLAMA_QWEN2_5_7B = "qwen2.5"
OLLAMA_QWEN2_5_MATH_7B = "qwen2.5-math" # 新增内容
# Limited to 16k during preview
LlmModel.LLAMA3_1_70B: ModelMetadata("groq", 131072),
LlmModel.LLAMA3_1_8B: ModelMetadata("groq", 131072),
LlmModel.OLLAMA_LLAMA3_8B: ModelMetadata("ollama", 8192),
LlmModel.OLLAMA_LLAMA3_405B: ModelMetadata("ollama", 8192),
LlmModel.OLLAMA_QWEN2_5_7B: ModelMetadata("ollama", 8192),
LlmModel.OLLAMA_QWEN2_5_MATH_7B: ModelMetadata("ollama", 8192), # 新增内容
在 block_cost_config.py 中添加一行。
LlmModel.OLLAMA_LLAMA3_8B: 1,
LlmModel.OLLAMA_LLAMA3_405B: 1,
LlmModel.OLLAMA_QWEN2_5_7B: 1,
LlmModel.OLLAMA_QWEN2_5_MATH_7B: 1, # 新增内容
第四个挑战是搞清楚如何把多个 Agent 连接起来。
通过阅读 AutoGPT 的官方文档,我们判断出实现这个目标的就是 AgentInputBlock 和 AgentOutputBlock 这两个 Block。在 04 课的 MetaGPT 实现中,CallMathProdigy、WrongExpression、RequireDealCardsAgain、ExitGame 这几个不需要业务逻辑,仅仅作为事件信息载体的 Action,在 AutoGPT 中都可以使用 AgentOutputBlock 来实现。
解决了上述这四个挑战之后,我们就可以分别来实现并测试流程图中的 4 个 Agent 了。我们按照从简单到复杂的顺序来分别实现。
实现并测试 GameDealer
对于 AutoGPT 中的每个 Agent,其实现都包括了两部分:
- 以 Python 代码形式实现的自定义 Block。
- 在 AutoGPT Frontend 的图形界面中,基于 AutoGPT 官方 Block + 自定义 Block 实现 Agent 的工作流。工作流实现和相关配置会保存在 AutoGPT Server 的 PostgreSQL 数据库中。
在 GameDealer 这个 Agent 中,我们需要移植 MetaGPT 实现中的 DealCards。我创建了一个对应的 DealCardsBlock,这个类是 AIConversationBlock 的子类。在这里我只展示其 run() 函数的实现。
def run(
self, input_data: Input, *, credentials: APIKeyCredentials, **kwargs
) -> BlockOutput:
old_cards_arrays = get_old_cards_arrays()
logger.info(f"used old_arrays is :{old_cards_arrays}")
prompt = self.PROMPT_TEMPLATE.format(old_arrays=old_cards_arrays)
msg_list = [ {"role": "user", "content": prompt} ]
rsp = self.llm_call(
AIStructuredResponseGeneratorBlock.Input(
prompt="",
credentials=input_data.credentials,
model=input_data.model,
conversation_history=msg_list,
max_tokens=input_data.max_tokens,
expected_format={},
),
credentials=credentials,
)
cards_posted = rsp
save_cards_cache(cards_posted)
yield "cards_posted", cards_posted
接下来我们按照 06 课介绍的方法,在 Linux 主机上启动 AutoGPT Server,在客户端机器上启动 AutoGPT Frontend。然后使用客户端机器的浏览器访问 Frontend 的 build 页面,创建并保存一个新的 Agent,取名为 GameDealer。如下图所示:
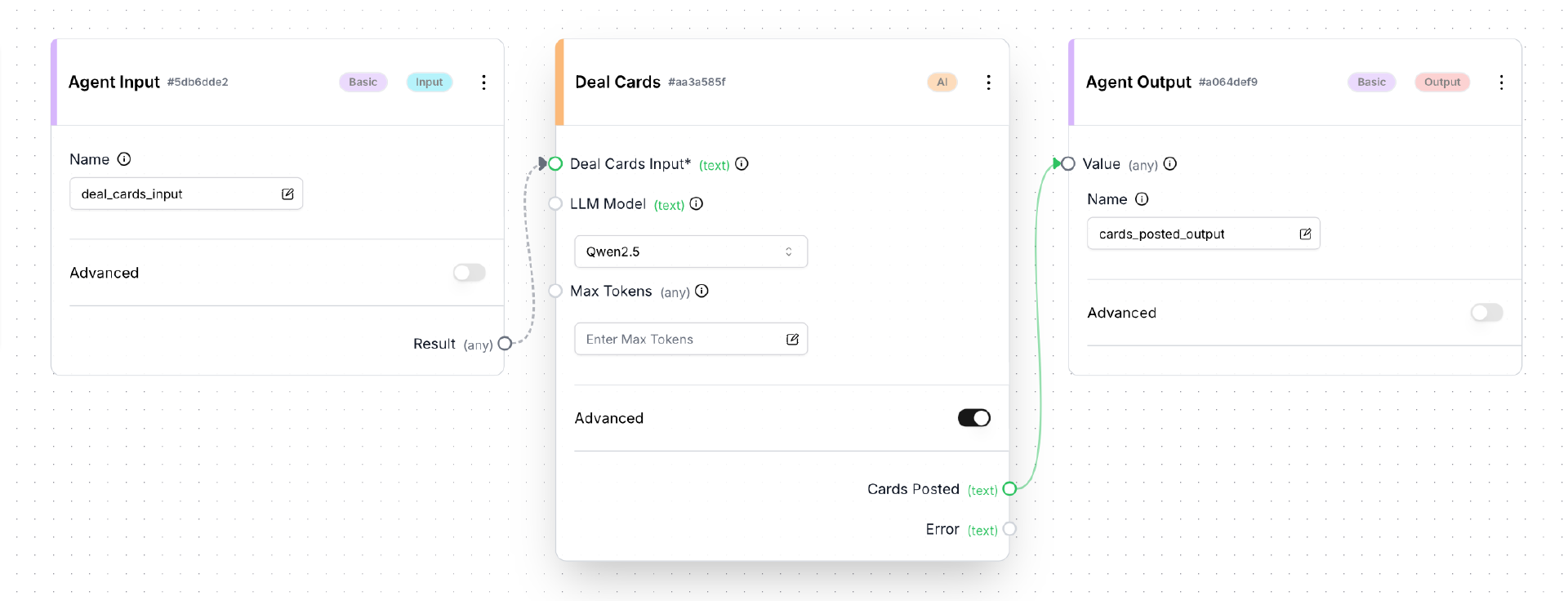
注意:在点击保存按钮之前,在 Deal Cards 框中需要打开 Advanced 选项,然后在 LLM Model 下拉框中选择 Qwen2.5。配置方法与上节课介绍 AIConversationBlock 的使用时完全一样。
保存成功后,点击 build 页面中的 Run 按钮,测试 GameDealer 工作是否正常。
实现并测试 MathProdigy
在 MathProdigy 这个 Agent 中,我们需要移植 MetaGPT 实现中的 MachineGiveExpression。我创建了一个对应的 MachineGiveExpressionBlock,以下是其 run() 函数的实现。
def run(self, input_data: Input, **kwargs) -> BlockOutput:
last_cards_posted = get_last_cards_posted()
if last_cards_posted == "":
yield "expression", "expression not found"
else:
point_list = json.loads(last_cards_posted)
expressions = get_cached_expressions(point_list)
result = "expression not found"
if len(expressions) > 0:
random_idx = random.randint(0, len(expressions)-1)
result = expressions[random_idx]
yield "expression", result
然后使用客户端机器的浏览器访问 Frontend 的 build 页面,创建并保存一个新的 Agent,取名为 MathProdigy。如下图所示:
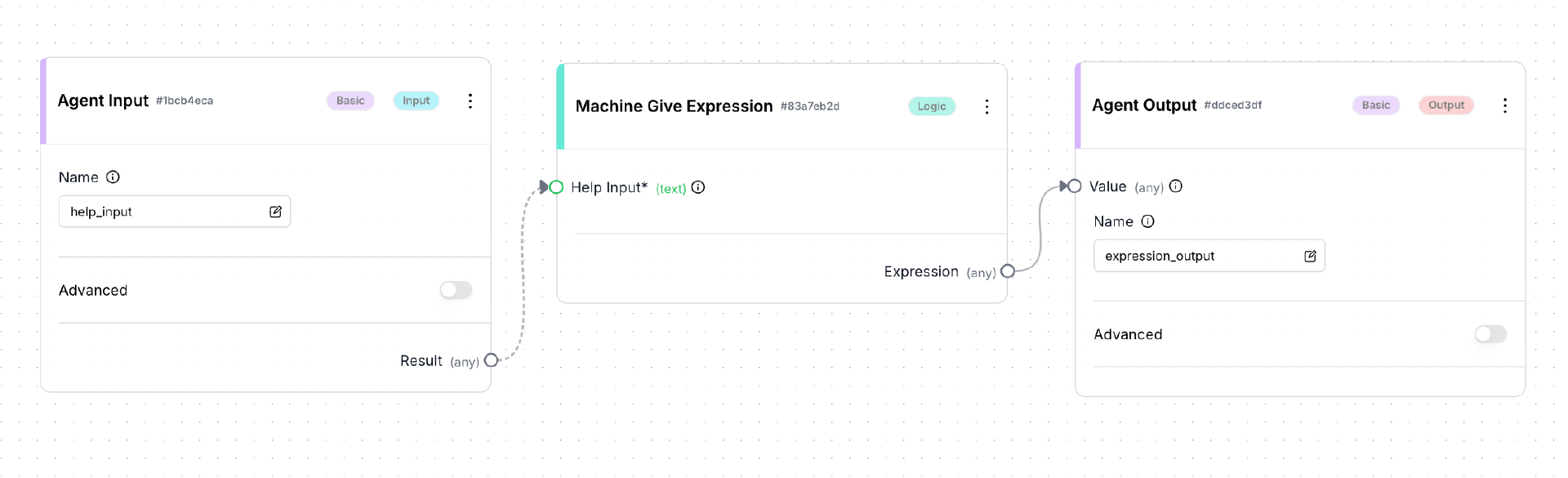
保存成功后,点击 build 页面中的 Run 按钮,测试 MathProdigy 工作是否正常。
实现并测试 GameJudger
在 GameJudger 这个 Agent 中,我们需要移植 MetaGPT 实现中的 CheckExpression。我创建了一个 CheckExpressionBlock,这个类是 AIConversationBlock 的子类。以下是其 run() 函数的实现。
def run(
self, input_data: Input, *, credentials: APIKeyCredentials, **kwargs
) -> BlockOutput:
last_cards_posted = get_last_cards_posted()
expression = input_data.expression
if expression == "expression not found":
yield "check_result", "Correct"
yield "last_cards_posted", last_cards_posted
else:
prompt = self.PROMPT_TEMPLATE.format(expression=expression)
msg_list = [ {"role": "user", "content": prompt} ]
rsp = self.llm_call(
AIStructuredResponseGeneratorBlock.Input(
prompt="",
credentials=input_data.credentials,
model=input_data.model,
conversation_history=msg_list,
max_tokens=input_data.max_tokens,
expected_format={},
),
credentials=credentials,
)
check_result = extract_result(rsp)
yield "check_result", check_result
yield "last_cards_posted", last_cards_posted
然后使用客户端机器的浏览器访问 Frontend 的 build 页面,创建并保存一个新的 Agent,取名为 GameJudger。如下图所示:
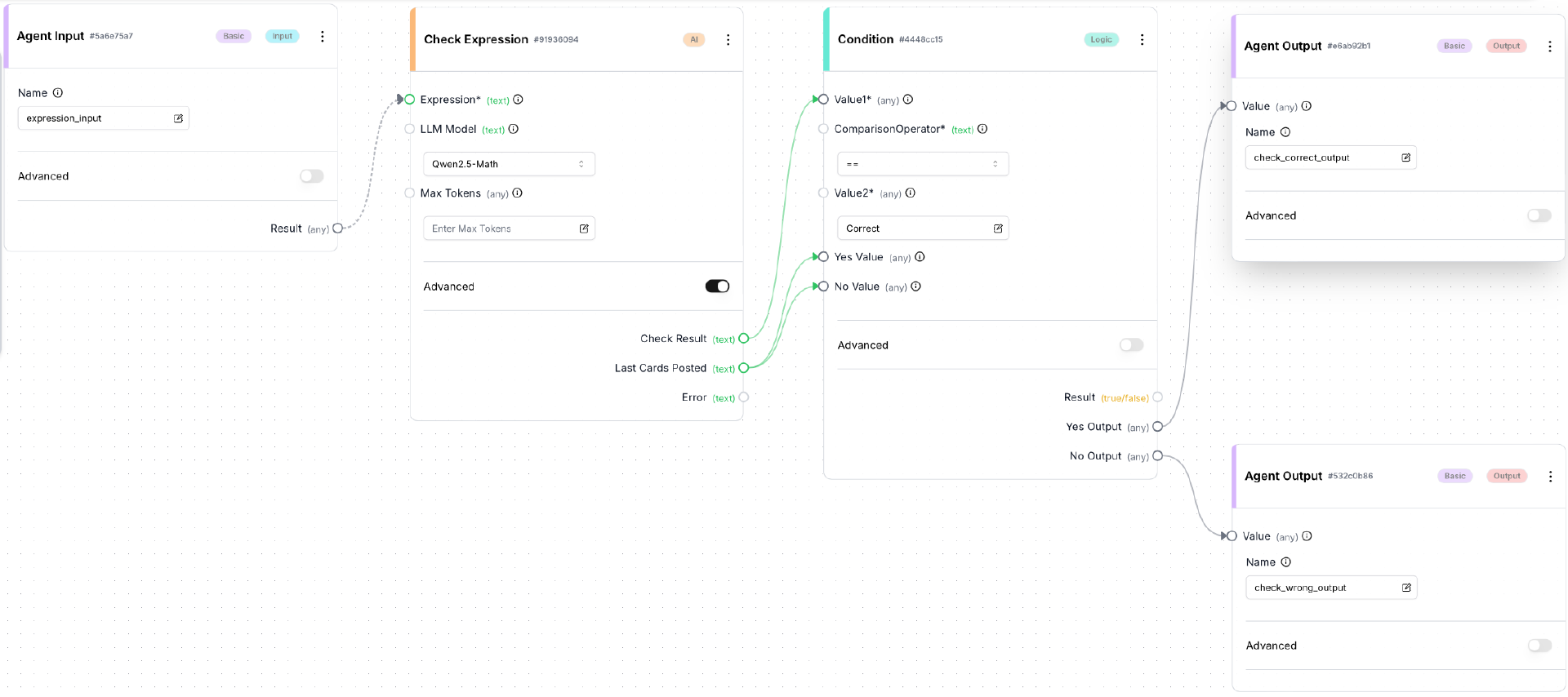
注意:在点击保存按钮之前,在 Check Expression 框中需要打开 Advanced 选项,然后在 LLM Model 下拉框中选择 Qwen2.5-Math。配置方法与上节课介绍 AIConversationBlock 的使用时完全一样。
与前面两个 Agent 相比, 因为增加了一个 ConditionBlock,GameJudger 显得复杂了一些。
注意一下 ConditionBlock 的用法:
- Yes Output 和 No Output 分别连接两个 AgentOutBlock,未来会通过这两个 AgentOutBlock 连接到不同的 Agent。两个 AgentOutputBlock 用不同的 name(check_correct_output、check_wrong_output)来进行区分。
- 将 CheckExpressionBlock 的输出项 last_cards_posted(最近发的牌)连接到 ConditionBlock 的 Yes Value 和 No Value 输入,这样做是为了将 last_cards_posted 通过 Yes Output 和 No Output 传递给两个 AgentOutputBlock,以备后续使用,下面就会看到。
保存成功后,点击 build 页面中的 Run 按钮,测试 GameJudger 工作是否正常。
实现并测试 GamePlayer
在 GamePlayer 这个 Agent 中,我们需要移植 MetaGPT 实现中的 GetHumanReply。我创建了一个 GetHumanReplyBlock,这个 Block 的 run() 函数在前面我们已经展示过了。然后使用客户端机器的浏览器访问 Frontend 的 build 页面,创建并保存一个新的 Agent,取名为 GamePlayer。如下图所示:
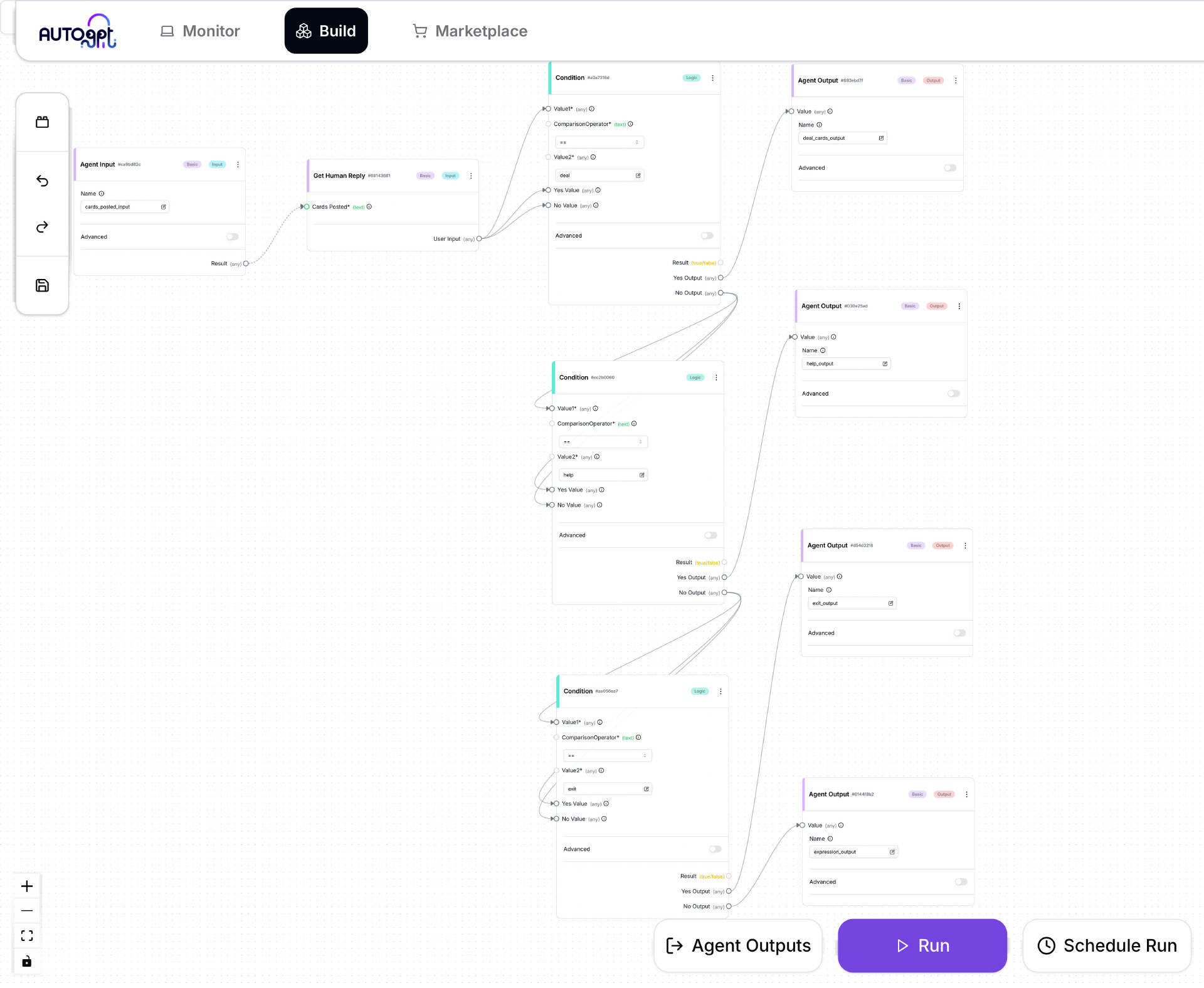 GamePlayer 这个 Agent 最为复杂,因为在其中级联了三个 ConditionBlock。这样做的是因为用户的输入有 4 种选项:deal、help、exit 和 24 点表达式。一个 ConditionBlock 只能做两个值的比较,要区分 4 种情况,就需要级联三个 ConditionBlock。对应这 4 种情况,也有 4个 AgentOutputBlock,每个AgentOutputBlock用不同的 name 来进行区分。
GamePlayer 这个 Agent 最为复杂,因为在其中级联了三个 ConditionBlock。这样做的是因为用户的输入有 4 种选项:deal、help、exit 和 24 点表达式。一个 ConditionBlock 只能做两个值的比较,要区分 4 种情况,就需要级联三个 ConditionBlock。对应这 4 种情况,也有 4个 AgentOutputBlock,每个AgentOutputBlock用不同的 name 来进行区分。
保存成功后,点击 build 页面中的 Run 按钮,测试 GamePlayer 工作是否正常。
实现并测试完整的游戏工作流
在成功地分别实现了 4 个 Agent 之后,最后一步是把这 4 个 Agent 连接起来,实现完整的工作流。
最后这一步不需要实现自定义的 Block,而是完全在 Frontend 的图形界面中完成。
使用客户端机器的浏览器访问 Frontend 的 build 页面,创建并保存一个新的 Agent,取名为 24_points_game。如下图所示:
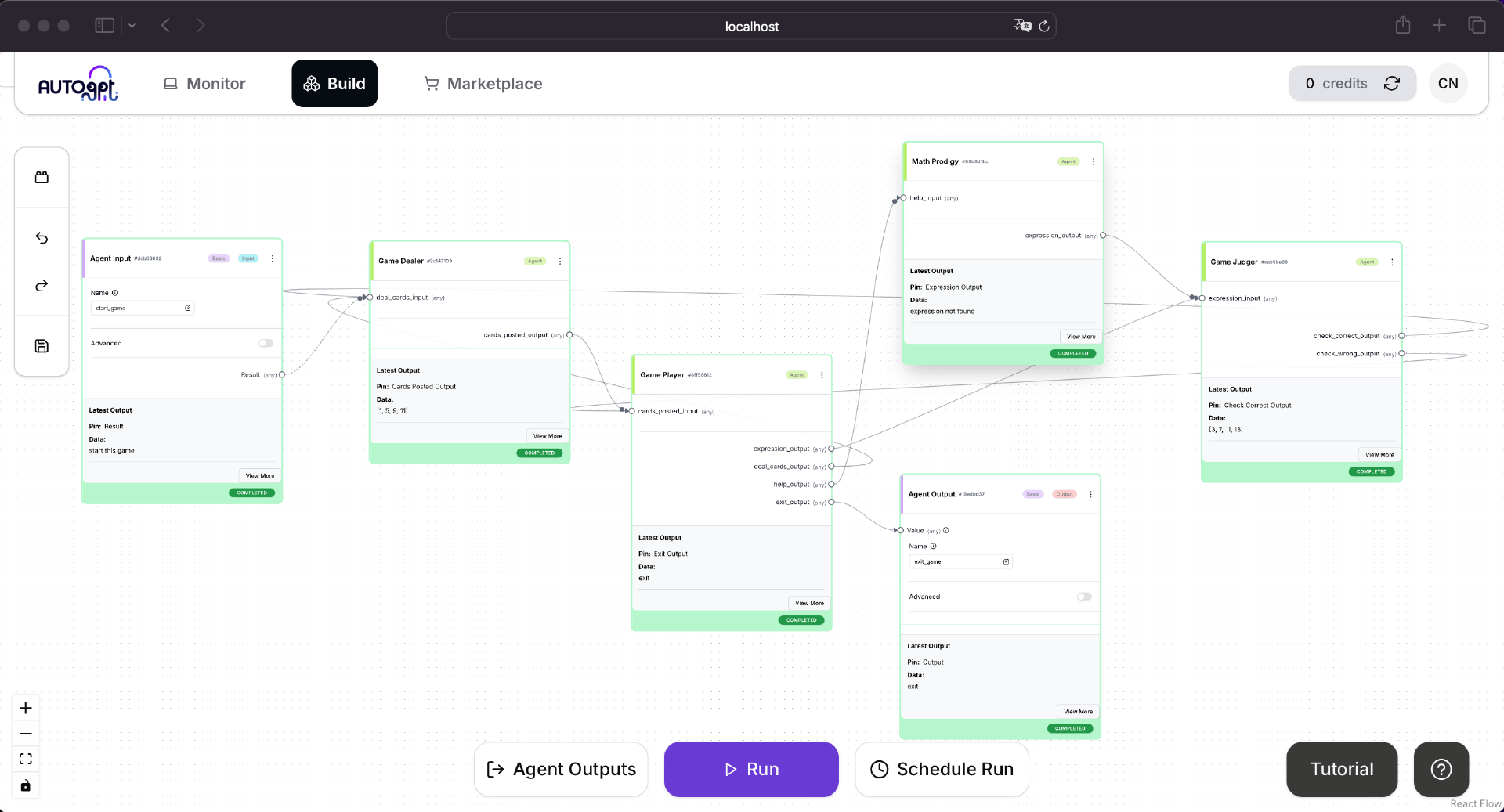
实现这个完整工作流的 Agent 时,注意图中每个 Agent 不同的输入、输出节点的连接方式,确保完全按照图示中进行连接。
还要注意 GameJudger 的输出项 check_wrong_output 直接连接到 GamePlayer 的输入项 cards_posted_input。这就是前面实现 GameJudger 时,把 last_cards_posted 通过输出项 check_wrong_output 传递出来的原因。GameJudger 判断出 GamePlayer 给出的表达式错误,此时无需重新发牌,而是把上次发的牌重新传递给 GamePlayer,让 GamePlayer 重新输入。
保存成功后,点击 build 页面中的 Run 按钮,测试 24_points_game 工作是否正常。
我专门录制了一段展示视频,展示 24_points_game 成功运行的样子。这段视频略微有些卡顿,这是我故意而为,因为我为了降低课程对硬件配置的要求,故意在较低硬件配置的机器上开发和运行,包括 Linux 主机和客户端机器。
如果 24_points_game 工作正常,可喜可贺,我们基于 AutoGPT 实现的第一个 Autonomous Agent 应用——24 点游戏智能体应用就大功告成了。辛苦学习了三节课之后,我们终于收获了一个重大的成果。你真的太棒了,应该为自己自豪!喝杯咖啡庆祝一下吧。
本节课完整的自定义 Block 代码在随课程附赠的代码 my_game_blocks.py 中,其中用到的工具函数在 my_game_helpers.py 和 calc_helpers.py 中。如果你打算创建并测试自己的自定义 Block,注意为每个自定义 Block 分配一个新的全局唯一 block id,方法在上节课中已经介绍过,这里不再赘述。
总结时刻
这节课我带你用 AutoGPT 再次实现了 04 课中 MetaGPT 实现的 24 点游戏智能体应用。在实现这个应用的过程中,我们又遇到了很多挑战。大多数挑战都被我们解决了,只有唯一的一个挑战暂时无法解决,AutoGPT 新版本暂时不支持在工作流的中间节点接受用户输入。我采用了一个临时解决方案绕开了这个问题。这其实是软件开发过程中我们经常采用的策略,永远把握全局、抓大放小,不在局部的细节问题上过早花费大量精力(甚至完全卡在细节问题上面,过早追求完美)。
与字节跳动的扣子之类闭源低代码平台不同,AutoGPT 是完全开源的,其开发团队还非常友善。积极与其开发团队保持沟通,提供必要的协助,进步的速度将比闭源平台快得多。只要其核心设计和发展方向不存在问题,随着时间的推移,一切细节问题都会得到解决。
在下一课中,我们继续学习 AutoGPT 的一些更加高级和复杂的知识,并且对 AutoGPT 未来的发展方向做出展望。
思考题
请你仔细阅读自定义 Block 的代码实现,尝试自行实现更多的 Block。
期待你的分享。如果今天的内容对你有所帮助,也期待你转发给你的同事或者朋友,大家一起学习,共同进步。我们下节课再见!
- 流沙 👍(1) 💬(1)
视频怎么看?提示没有权限观看
2025-01-22 - 颛顼 👍(0) 💬(1)
上面提到的临时方案,课程上线也没更新了
2025-02-08