15 如何设计Autonomous Agent应用?(下)
你好,我是李锟。
设计构建自主型智能体是一个很大的话题,上节课我只讲了一半,这节课我来继续讲解。我上节课介绍过,自主型智能体是自主型 AI 应用的一个子集。因此设计自主型智能体,我们需要同时掌握两种应用的设计方法,一种是 AI 应用的设计方法,另一种是复杂业务应用的设计方法。
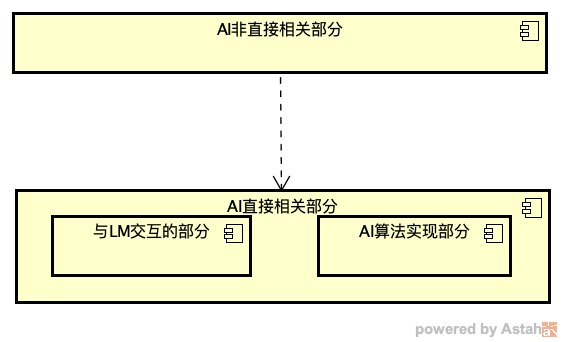
如图所示,对于复杂的自主型智能体,我们可以大致划分为两部分:一部分是真正与 AI 直接相关的部分,包括与 LM 交互的部分,还包括一些 AI 相关的算法实现部分;另一部分是不与 AI 直接相关的部分,属于普通的业务逻辑,不涉及复杂的算法。
接下来我分别介绍这两部分会用到的设计方法和技术。
提示词工程——挖掘 LLM 潜力的关键技术
自主型智能体是由 LLM 驱动的,而提示词工程是与 LLM 交互的核心,我们人类可以使用很随意的口语化语言与 LLM 交流,然而想要高效地与 LLM 交流,快速达到我们的目的,我们需要精心编辑自己的提示词。虽然已经有了 DSPy 这样的自动提示词工程开发框架,但仍然无法完全取代手工提示词工程。
高效提示词最基本的要求是必须结构化。将提示词结构化,可以采用以下两种常见结构:
- 划分为角色-上下文-任务(role-context-task)三段。
- 划分为指令-上下文-输入数据-输出格式要求(instruction-context-input data-output indicator,ICDO)四段。
编写高效提示词的常用技巧
手工编写提示词,有 4 种常用技巧,按照从简单到复杂的顺序:
- 提供少量示例,又叫少样本学习(Few-Shot Learning,FSL)。提供少量示例可以更清晰地表达你的需求,它不仅包含了你想要的输出格式、内容,还能引导 LLM 按照你的逻辑来思考。示例的重点不在于其复杂性,更重要的是其背后的逻辑。
- 有少量示例的思维链(Chain of Thought, CoT)模型。对于复杂且深入的问题,如果直接让 LLM 给出答案,结果一般都会差强人意。所以就需要我们设计开发有少量示例辅助的 CoT 模型,引导 LLM 逐步地开展思考。
- 思维树(Tree of Thought, ToT)模型,CoT 模型虽然能引导 LLM 逐步地开展思考,并最终得到我们想要的答案,但对于需要探索或预判的复杂任务来说,传统或简单的提示技巧是不够的。ToT 模型围绕着一棵思维树展开,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,语言模型能够自己对严谨推理过程的中间思维进行评估,而每个中间过程都保留最优的选项,最终结果会从这些最优子选项的排列组合中挑选出来。
- 支持自洽性的思维链(CoT with Self-consistency)模型。自洽性是对 CoT 模型的一个补充,它不仅仅生成一个思维链,而是生成多个思维链,然后取多数答案作为最终答案。这种想法是通过有少量示例的 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高 LLM 在处理算术和常识推理任务中的准确性。简而言之,一题多解,选择最优解。
为了处理复杂的用户需求,我们还需要学习一些与 LLM 交互的设计模式。
与 LLM 交互的设计模式
微信公众号“产品二姐”有一篇很棒的文章谈到了 LLM Agent最常见的九种设计模式,这里也分享给你。这九种设计模式分别是:
- ReAct:思考 -> 行动 -> 观察
- Plan and Solve(又名 Plan and Execute、Plan and Act):计划 -> 任务列表 -> 再计划
- Reason without Observation(REWOO):计划(含依赖关系) -> 行动(依赖前一步行动的结果)
- LLMCompiler:计划 -> 并行行动 -> 合并各个行动的结果
- Basic Reflection:从步骤中反省学习
- Reflexion Actor:通过强化学习增强 Agent 下一步的规划
- Language Agent Tree Search(LATS):ToT+强化学习式反思
- Self-Discover:在任务中中进行推理
- Storm:搜索大纲 -> 搜索每个主题的大纲 -> 汇总生成长文
在不同设计模式中,会应用到前面讲过的一种或多种提示词技巧。本质上所有与 LLM 交互的设计模式都是将人类的思维、管理模式以结构化提示词的方式告诉 LLM 来进行规划,并调用工具执行,且不断迭代的方法。
这些设计模式的详细介绍你可以阅读产品二姐的文章。每一种设计模式都有相应的论文,论文中也都有可测试的例子。每一种设计模式分别适用于解决不同类型的问题。例如 ReAct 模式和 Plan and Solve 模式就很适合用来实现以执行任务为主的自主型智能体。其实与 LLM 交互没有最好的设计模式,只有最适合的设计模式,最终还是要从用户需求出发来选择。
MetaGPT 中的 Role 对象与 LLM 默认的交互模式是 ReAct,也可以设置为 Plan and Act(即Plan and Solve)。如下所示:
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
...
self.rc.react_mode = RoleReactMode.PLAN_AND_ACT
...
在自动提示词开发框架 DSPy 中,已经把 CoT 模型组件化,实现为 dspy.ChainOfThought 模块。DSPy 中另一个非常有用的组件就是 dspy.ReAct 模块,对应上面提到的 ReAct 模式。
我们学习了 DSPy 之后,已经理解了严重依赖手工提示词工程会导致团队陷入困境。我在这里再次强调一下,只要 DSPy 的自动提示词工程方法能够解决问题,就应该采用 DSPy,除非 DSPy 确实无法解决,再考虑手工编写复杂的提示词。另外,还可以考虑基于 DSPy 的方法将上述设计模式实现为新的模块。
此外,如果有大量的专业数据,希望确保 LLM 生成的内容具有高度准确性,还可以调用 LLM 的微调(fine-tuning)API 对 LLM 做微调。对 LLM 做微调的成本会比采用提示词工程高出一个数量级,因此需要慎重权衡。
自主型智能体相关算法一览
构建复杂的自主型智能体,除了与 LLM 交互外,还需要使用一些算法。复杂的自主型智能体会涉及到以下 6 类算法:

上述算法中一部分算法属于 AI 算法,会用到深度强化学习(DRL),其他的算法属于常规算法。关于这些算法的具体内容,你可以参考相关的教程和图书。我提倡的是从真实需求出发、学以致用的“剑宗模式”,而不是不考虑真实需求,一股脑学习大量算法的“气宗模式”。 Python 开发者可以从学习 PyTorch 这个最流行的 ML 框架入手,入门之后根据具体的需要学习相应的算法。
自主型智能体的能力边界从根本上说与其算法息息相关。从长远来看,这些算法使它们能够在复杂多变的环境中做出决策和执行行动。
接下来我再来介绍一下复杂业务应用的设计方法,目前最流行的就是 DDD。
使用 DDD 指导自主型智能体的设计
领域驱动设计(DDD)是一种通用的软件设计方法,可用于设计开发具有复杂业务逻辑的应用。对于设计自主型智能体,DDD 是否仍然适用呢?我的答案是肯定的,DDD 中的那些设计策略和原则,仍然适用于设计自主型智能体。
DDD 中的设计策略和原则,可以划分为两层:战略层和战术层。微观层面的具体代码设计和实现是战术层,其他那些与具体代码设计无关的宏观层面的设计则是战略层。我们需要更多关注的,是 DDD 战略层面的设计策略和原则。战略层面设计策略有很多,我无法一一详细讲解,只介绍一下其中最重要的分层架构(Layered Architecture)和限界上下文(Bounded Context)。
分层架构
复杂的软件系统,为了分而治之,通常都会划分为不同的层。不同的层之间要保持单向依赖和调用,避免任何循环依赖和调用。分层有两种方法,最简单的分层方法是从上至下堆栈式的分层,例如很常见的三层架构或者四层架构。在 DDD 中标准的四层架构如下图所示:
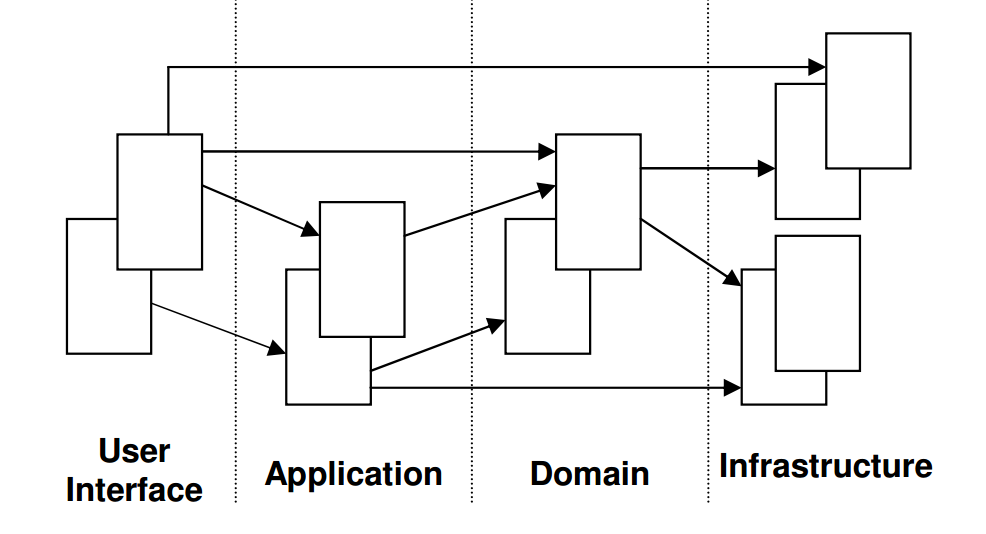
对于更为复杂的应用,除了从上至下的分层方式外,还有一种从外向内的分层方式。这类分层方式中最有名的是六边形架构,由软件专家 Alistair Cockburn 在 2005 年提出。如图所示:
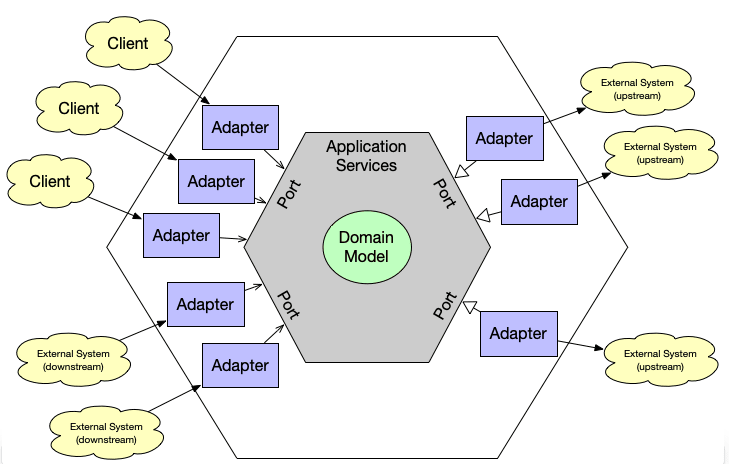
在六边形架构中,中心位置是系统的领域模型,也就是系统最重要的业务逻辑部分。六个边代表不同的外围功能,例如用户界面、访问数据库、网络调用、消息通知等等。图中的每个边有一个接入的端口(Port),一个端口可以有多个适配器(Adapter),因此六边形架构也被称作“端口与适配器”架构。
上述两种分层方式,对于设计自主型智能体来说都是可以采用的。
限界上下文
前面我们学习了 MetaGPT 和 AutoGPT,大家了解到,一个复杂的自主型智能体中的多个 Agent(MetaGPT 中叫做 Role)可以被划分到不同的工作组(MetaGPT 中叫做 Team)之中,工作组还可以分层,形成类似公司或军队的体系架构。前面我已经介绍过 DDD 中分层的方法,那么在同一层内如何划分不同的工作组呢?我们需要的就是限界上下文。
限界上下文对于设计复杂的业务系统来说,是一个非常重要的设计策略,也是软件系统实现组件化开发的关键(不同的限界上下文构成了组件的边界)。除了可以用来划分 Agent 的工作组,也可以用来划分分布式应用的服务(远程服务)。这里我建议你读一下 Martin Fowler 的这篇文章。
自主型智能体的分层的例子
在复杂的自主型智能体中,与 AI 并不直接相关的部分,DDD 的分层方法已经处理得很好了。与 AI 直接相关的部分,还可以再划分成不同的层。
下面我以一个 AI 驱动的 DevOps 系统为例,来讲解自主型智能体的分层。选择这个例子的原因是这样一个系统比较容易理解,而且很有代表性。这个例子来自于这篇很棒的文章:Building Autonomous AI Agents based AI Infrastructure。
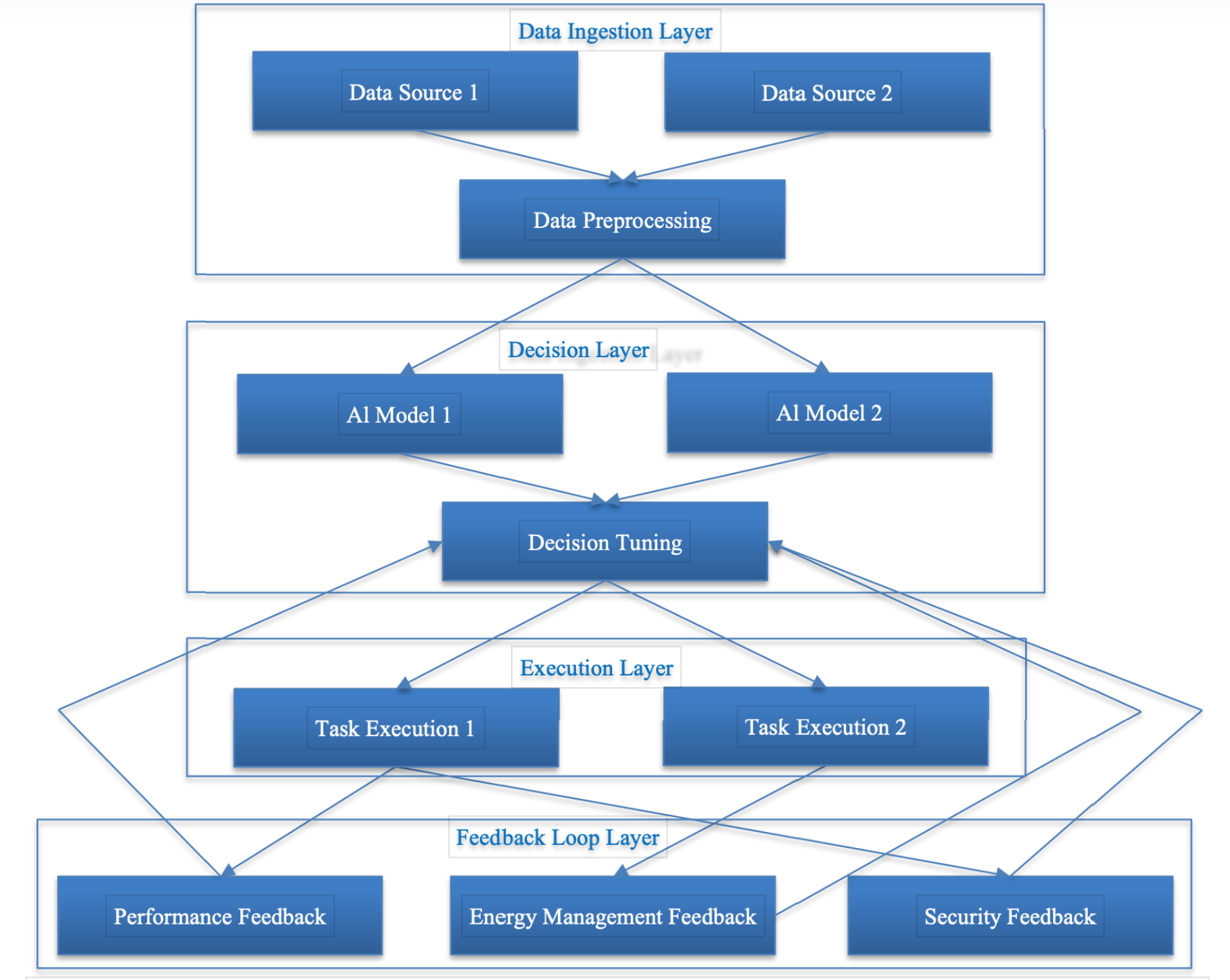
一种具有通用决策层的分层架构,由自主型智能体来控制任务的执行,并使用性能、能源和安全反馈来加强和改进其未来的决策。
如图所示,AI 驱动的 DevOps 系统可以划分为以下四层:
- 数据输入和监测:数据输入层是实时决策的基础,它从基础设施的各种来源收集数据。来自服务器、网络设备和应用程序的传感器、日志、度量数据和遥测数据都会输入该层,从而提供系统状态的全面视图。
- 决策引擎:决策引擎构成了 AI 驱动的 DevOps 系统的核心智能。这是一个可配置的组件,可根据应用需求为每个 Agent 配置不同的 AI/ML 或基于启发式的算法。该组件处理传入的数据,并根据 Agent 的业务目标做出决策。
- 执行和控制:一旦做出决定,执行和控制层就会在基础设施内采取行动。该层通过应用程序接口和自动化工具将 Agent 与各种基础设施组件连接起来,使其能够执行诸如扩展资源、负载均衡、重新配置网络设置和启动故障恢复过程等任务。
- 反馈回路和持续学习:反馈回路对这种架构至关重要,它能让 Agent 从自己的行为中学习,并随着时间的推移不断改进。有关过去决策结果的数据被反馈到决策引擎中,使 Agent 能够调整其行为,从而更好地实现目标。持续学习功能通常通过机器学习算法实现,使 Agent 能够微调其性能,并适应基础设施内不断变化的条件。这一组件对长期适应性至关重要,因为它能确保 Agent 与基础设施共同发展,并在系统要求或工作负载发生变化时保持高效。
对于 AI 驱动的 DevOps 系统来说,上述四层只是最基础的分层,你还可以根据需要添加更多分层。这个分层系统架构旨在提供一个健壮的、适应性强的框架,可以在大规模计算环境中自主管理复杂的任务。
构建自主型智能体的陷阱
上节课我说过,设计构建自主型智能体是一个需要不断探索和学习的过程。事先了解道路上会存在的陷阱,会很有帮助。
教授技能的陷阱
向自主型智能体教授技能时,我们需要避免以下陷阱:一是将解决方案与问题混为一谈。这可能会导致我们忘记还有其他方法来解决同样的业务问题。现有解决方案只是业务问题的一种解决手段,不要有了一把锤子看到什么都是钉子。
二是过于关注某个部分而忽视全局。如果我们过多关注某个部分,就会失去全局视野。在我们看到完整的端到端流程之前,很难识别出重要的技能并做出权衡。为了避免这个陷阱,在确定子组件模块和选择决策技术之前,检查整个流程是至关重要的。缺乏大局观会导致过早做大量局部优化,结果事倍功半。
开发方法的陷阱
敏捷开发方法是业界最为流行的开发方法,敏捷开发方法对于构建自主型智能体当然也会很有帮助。然而自主型智能体还有作为复杂 AI 应用的很多特点,敏捷开发方法在开发复杂 AI 应用方面存在一些局限性,我们需要事先有所认知。
设计构建自主型智能体,在开发方法方面存在以下两个陷阱,这两个陷阱刚好是两个对立的极端。
陷阱1:追求完美设计,采用瀑布式开发流程,忽略迭代。
设计自主型智能体更像是构建软件。是需要进行迭代的。因为自主型智能体设计是向一个学习系统传授技能,在让它尝试之前,你永远无法确切知道这个系统会学到什么。当你看到它学到了什么,你可能会重新制定你的教学策略。这种情况也会发生在人身上。许多教师在制定教学计划后,看到学生学得很好,就会更新计划。
敏捷软件设计和开发起源于利用软件提供的机会来构建和测试软件的小部分,而不是一次性实现整个设计。可以从系统的一小部分开始构建、测试,并在构建过程中让这些信息影响设计。我们可以采用这种方法来避免自主型智能体设计过程中的谬误。
陷阱2:完全忽略设计规划。
如果过于追求敏捷和迭代,轻视完整的设计,就会陷入另一个陷阱。迭代确实很重要,因为我们不可能在第一次就做出完美的设计。但大多数复杂的自主型智能体,与其说是软件,不如说更像钢铁厂。推土机、机器人、汽车、仓库、石油钻探机、化工厂、数控机床以及控制它们的自动化系统都是针对特定功能和可靠性而设计的,然后按照规格制造。随着时间的推移,更新的速度非常慢,慢到你可以认为它们是全新的设计。
这意味着我们不能采用完全敏捷的方法。我们确实需要预先进行完整的设计,但在实现过程中得到反馈后也需要及时修改设计。
总结时刻
这节课,我们学习了与提示词工程相关的技巧和设计模式,以及复杂自主型智能体中可能会用到的算法。此外,我们还了解了复杂业务应用的设计方法——DDD,其中重点讲解了两个战略级设计策略:分层架构和限界上下文,并且以 AI 驱动的 DevOps 系统为例,了解了其中的分层架构。最后你在设计的过程中还需要注意避免掉入构建自主型智能体过程中会遇到的两大类陷阱。
关于设计自主型智能体的这两课内容很丰富,其实是很多相关知识的浓缩。带着这两课我们学习到的知识,我们将设计开发一个真实的行业应用——企业员工AI助理。下节课我们先在产品设计层面详细讨论这个行业应用的需求。
思考题
- 与 LLM 交互的设计模式有哪些?
- 分层架构对于设计自主型智能体来说,为何很重要?
欢迎你把你的想法分享到留言区,和我一起交流,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给需要的朋友,我们下节课再见!