17 企业员工AI助理的架构设计
你好,我是李锟。
在上节课中,我们学习了时间管理方法 GTD,然后基于 GTD 方法讨论了企业员工 AI 助理的需求。在这节课,我们的角色将从 AI 产品经理转换到应用架构师,基于上节课讨论的产品需求,设计这个产品的技术架构。
上节课中我曾经强调过,软件需求文档(主要内容为详细用例描述)是必须认真完成的工作,不可以轻视甚至忽略。因为时间问题,我们暂时不完成详细的软件需求文档,而是假设我们已经有了这样一份需求文档。我可以略过这份需求文档而直接做架构设计,只是因为我对 GTD 的流程以及这个产品要实现的目标非常熟悉,已经胸有成竹。但是这种做法不值得鼓励。在一个团队里面除了开发人员,还有 UED 设计人员、测试人员、运维人员,如果连个高质量的软件需求文档都没有,希望他们高效地开展工作是不可能的。
言归正传,我们马上进入应用的技术架构设计。
应用软件架构设计的内容
设计应用软件的技术架构,通常需要完成以下工作:
确定产品的应用类型:
- 服务器端应用(在线服务)、客户端应用还是两者都有。
- B/S 架构还是 C/S 架构,或者 Serverless 架构。
- 服务器端应用设计成单体还是分布式?
确定应用的技术选型:
- 服务器端编程语言 + 开发框架、客户端编程语言 + 开发框架。
- 需要使用什么关系数据库、NoSQL数据库、向量数据库?
- 需要使用哪些中间件?
编写应用的架构设计文档,其中包括以下内容:
- 应用的领域模型设计(Domain Model Design):以 DDD 作为指导,遵循面向对象设计原则。
- 应用的关系数据库设计(ER Design):包括 ER 图和数据库 DDL。
- 应用的对外服务 API 设计:如果应用是一个 Web 服务,对外暴露了一套 API,就需要有专门的服务 API 设计,确保 API 的易用性、松耦合、可伸缩性、安全性。
- 应用的安全设计:安全性要求很高的应用,需要有专门的安全设计。
- 应用的高可用性(HA)设计:可用性要求很高的应用,需要有专门的高可用性设计。
上述这些是普通应用软件中需要包括的技术架构设计部分。对于 LLM + AI 类型的应用,如果使用了较为复杂算法或者实现策略,还需要增加这一部分的设计。
需要强调的是,应用的技术架构设计文档不是只写一次就万事大吉了,而是要随着应用开发过程的深入开展而持续更新。架构设计、开发、测试、运维是增量 + 迭代的过程,而不是一次性瀑布式的过程。
接下来我们就按照上述这些部分来设计 企业员工 AI 助理的技术架构。以下还是把这个应用简称为“AI 助理”。
确定 AI 助理的应用类型和技术选型
- 确定产品的应用类型
根据上节课讨论的企业员工 AI 助理的需求,这个应用最合适的应用类型是 B/S 架构的应用,也就是一个包括客户端应用的在线服务。这个应用的业务复杂度不高,另外这个应用因为运行在企业私有云或局域网环境,并发访问量也不高,所以根本没有必要设计成分布式应用,设计成单体应用足够了。未来即使需要支持较高的并发访问量,也可以通过“无状态 + Share Nothing 架构 + 负载均衡集群”来轻易解决。
- 确定应用的技术选型
首先考虑服务器端应用的技术选型。因为我们最熟悉的编程语言是 Python,这门课使用的编程语言也是 Python,所以很自然我们选择 Python 来开发服务器端应用。Python 性能较差对于这个应用来说不是大问题。
因为这个应用是一个 B/S 应用,所以我们需要选择一个流行的 Web 应用开发框架。流行的 Python Web 开发框架有 Django、Flask、Tornado、FastAPI 等等。此外还有 Streamlit、Gradio 这类开发演示应用的快速开发框架。我的选择是 FastAPI,因为 FastAPI 性能优越,学习门槛较低,而且可以非常好地支持设计开发 RESTful API,以便支持未来客户端应用的开发。Streamlit、Gradio 开发演示应用虽然很高效,用来支持 RESTful API 和客户端应用就比较差了。
选择 Web 开发框架固然很重要,不过对于一个 LLM + AI 应用来说,选择一个 LLM 应用开发框架就更重要了。前面我们已经确定,这个应用是一个 B/S 架构的在线服务,虽然这个应用的 UI 有一半是 NUI(自然语言界面),然而这个应用并非一个以聊天为主的 ChatBot,而是一个 Autonomous Agent(自主型智能体),我们需要选择一个最合适的 Autonomous Agent 开发框架。我们已经学习过 MetaGPT、AutoGPT、Swarm 三个 Autonomous Agent 开发框架,究竟选择哪一个呢?
我思考了较长时间,最后决定还是选择 AutoGPT。有以下原因:
- AutoGPT 本身就是一个 B/S 架构的在线服务,而且支持高可用性,跟 AI 助理的应用类型一致。
- AutoGPT 的 Agent Builder 提供了方便易用的图形化开发、测试工具,从概念上支持更为强大的工作流。MetaGPT 当前 0.8.x 版中的工作流支持很笨拙,而 MetaGPT 1.0 版迟迟未发布,其中的全新工作流支持不知道是否真的很强大、很好用。Swarm 虽然支持开发多 Agent 应用,然而完全没有对于复杂工作流的支持,需要完全手工实现。
- AutoGPT Platform 的开发已经逐渐走入正轨,进度明显加快。Autonomous Agent 开发框架的王者之战,在 2025 年内即将展开。AutoGPT Platform 是有力的竞争者。
- AutoGPT Platform 提供了一些可重用的 Block,而如果功能无法满足要求,自己基于这些 Block 定制一个 Block 也很容易。在 08 课中我们已经看到过。
- AutoGPT 团队的响应速度更快,在其 Discord 群里提的问题很快都能得到回复,虽然需要使用英语。
在服务器端我们确实需要有一个关系数据库,否则很多功能实现起来会更麻烦。因为这个应用的并发访问量不大,数据量也不大,我们用普通的 MySQL 数据库就足够了。也可以使用 supabase 安装的 PostgreSQL,和 AutoGPT Platform 使用相同的数据库,这样可以减少一种数据库。此外,对于开发者在开发机上做测试,使用嵌入式数据库 SQLite 会很方便,我们可以通过 O-R Mapping(对象-关系映射)框架,方便地切换 SQLite、MySQL、PostgreSQL。
未来我们可能会实现一些 RAG 相关的功能,例如访问企业的内部知识库,因此我们需要有一个向量数据库。目前向量数据库可选的也非常多,有轻量级的,也有重量级的。我建议先选择一个轻量级、便于开发的向量数据库。未来如果确实无法满足要求,再考虑迁移到重量级向量数据库。我推荐的轻量级向量数据库是 Weaviate,重量级向量数据库是 Milvus,我们可以先使用 Weaviate。
可能用到的中间件方面,通常服务器端应用都需要有一个分布式缓存。Redis 是最流行的分布式缓存中间件,我们选择 Redis 就好了。此外 Redis 还可以作为轻量级的 NoSQL 数据库和消息中间件来使用,可谓是中间件领域的“瑞士军刀”。
我们再来看考虑客户端应用的技术选型。客户端应用我们既可以开发为原生(native)的桌面应用 + 移动应用,也可以开发为一个 PWA 应用(Progressive Web App,渐进式 Web 应用)。
因为我们希望客户端应用具有多端支持和非常高的包围度,需要支持电脑 (台式机 + 笔记本)、智能手机、智能手表。要达到很好的用户体验,还是需要开发原生的应用。但是开发支持多端的原生应用,不同操作系统的应用需要使用不同的编程语言,代码不具有可移植性,开发成本非常高。即使使用了 ReactNative、Flutter、Xamarin 这一类跨平台的原生应用开发框架,开发成本也是比较高的。
为了节省成本,也为了快速迭代,我们可以先把客户端应用开发为一个 PWA 应用。PWA 应用的开发技术和服务器端的 Web 应用基本上是一样的,就是 JS + HTML + CSS,会这些开发的人员有一大把,相关教程、图书也极其丰富。
决定将客户端应用开发为 PWA 应用之后,我们还需要选择一种前端开发框架。前端开发框架可以划分为支持 SPA(单页面)应用的开发框架和不支持 SPA 应用的开发框架。
-
支持 SPA 开发的开发框架
-
React
- Vue
- Angular
- Svelet & SveletKit
-
不支持 SPA 开发的开发框架
-
HTMX
这里我罗列的是支持组件化开发的前端开发框架,jQuery 这类古老的开发框架不支持组件化开发,没有列在其中。
选择前端开发框架有很多考虑因素,这方面其实没有特别严格的选择标准。如果我亲自做开发,我倾向于选择最轻量级的 HTMX,虽然这个开发框架比较小众。
最后总结一下 AI 助理的技术选型:
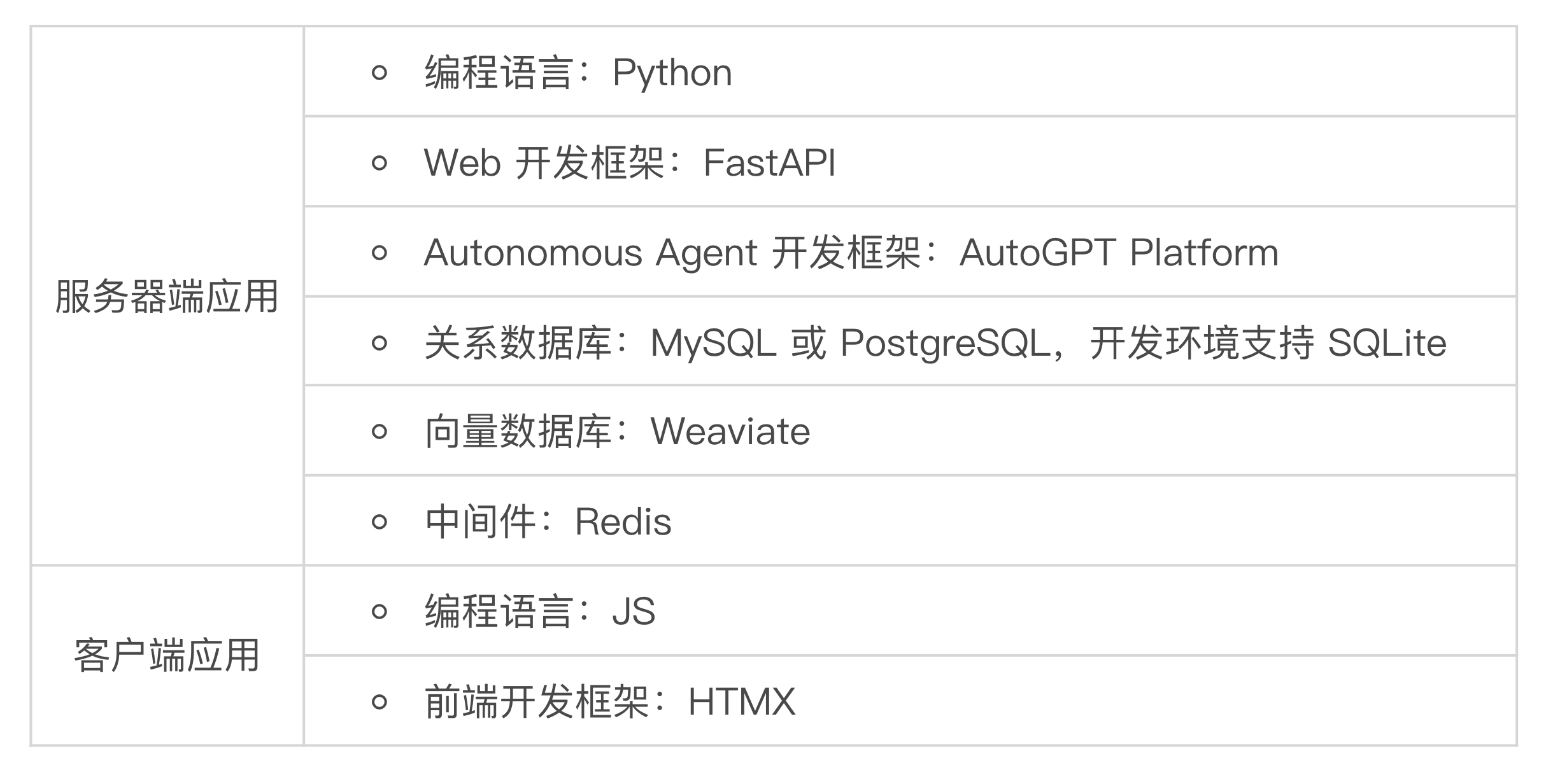
编写 AI 助理的架构设计文档
应用的领域模型设计
应用软件的架构设计包括很多内容,如果一定要说其中哪一部分最重要,在我看来就是领域模型设计了。因为应用的领域模型设计是应用最核心的部分,这一部分没设计好,应用连基本的功能都存在问题,更别提什么用户体验、高可用性了。
目前业界最常用的领域模型设计方法是 DDD(领域驱动设计),我曾经在 15 课中简单介绍过 DDD。在这一课中,我们用 DDD 作为指导来设计 AI 助理的领域模型。
另外 UML 对于设计业务系统来说是非常有用的工具。我推荐一本 UML 入门图书——Martin Fowler 的《UML 精粹》(UML Distilled)。我使用的 UML 设计工具是免费的 Astah 社区版。遗憾的是这个版本官方已经不提供了,我分享在百度网盘,你可以从这里下载安装。
UML 图中最重要的图是用例图、类图、活动图、序列图、状态机图、组件图这 6 种,活动图和用例图在前面的课程中我们已经看到过。
首先我们使用类图来确定应用中存在哪些实体(Entity)。实体就是一些名词性的概念,按照面向对象设计的要求,我们设计一个应用软件应该从名词(系统中的实体)开始,然后再考虑动词(与每个实体有关的动作),而不是反过来,先考虑动词再考虑名词。
与上节课的企业员工相关的 UseCase 图对应的企业员工相关类图如下:
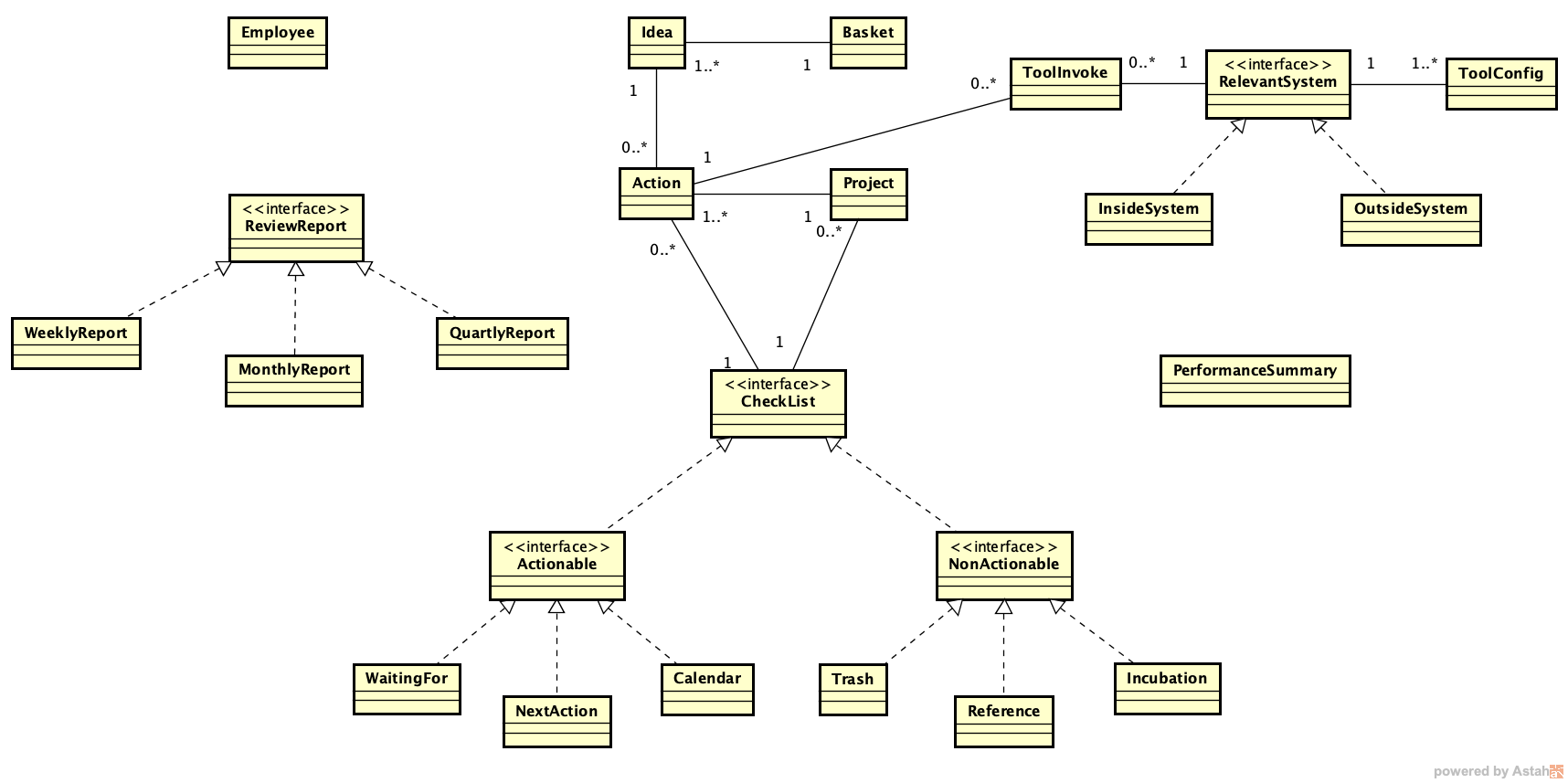
我对上面的类图做一些说明:
- Employee:企业员工,使用企业员工 AI 助理这个应用的所有用户。其他所有实体都隶属于 Employee。
- Idea 是与工作时间有关的所有想法。可以把 Idea 放在不同的 Basket 中,并且添加适当的标签。
- Action 是 Idea 整理之后要做的动作。可以把多个相关的 Action 组织在一个 Project 中,而且一个 Project 可以包括不同 Employee 的 Action。
- CheckList 可包括多个独立的 Action + Project。按照上节课的介绍,可以划分为 Actionable(可操作)、NonActionable(不可操作)两个大类。而两个大类各自又可划分为三个小类。我们重点关注的是 Actionable 这一类。NextAction 是虽然没有明确时间要求,但已经打算执行的动作。Calendar 是有明确时间要求,必须在某个时间完成的动作。WaitingFor 是等待其他同事完成某个前置动作后,才能完成的动作。
- RelevantSystem 是与动作执行相关的其他系统。可以划分为企业内部系统 InsideSystem 和企业外部系统 OutsideSystem 两大类。每一个系统都有一些相关的工具 (tool),ToolConfig 对应这些工具相关的配置,例如访问云端 LLM 的 api_key 等等。ToolInvoke 记录每一次 Tool 调用,包括调用的输入参数、返回的结果等等。
- ReviewReport 是对系统做回顾生成的报告。可以划分为周期性的报告,周报、月报、季报,也可以不定期。手工生成回顾报告确实相当繁琐,这是 LLM 和 AI 能够唱主角的领域。
这个类图只是第一个雏形版本,目的是划分出与企业员工 UseCase 相关的名词性实体。你看到了,图中所有的接口和类都尚未添加属性(attribute)和操作(operation)。不过这个版本的类图已经可以拿出来在开发团队内部讨论了。把这个雏形版本讨论清楚了,大家对于系统中有哪些实体可以达成共识,然后可以为图中的每个实体添加属性,再做一轮讨论。讨论达成一致意见后,名词性的设计就基本上完成了。
接下来进入动词性设计,为图中的每个实体添加操作。但是类图本身是静态的,无法表现出这些操作的整体流程或者时间顺序,因此可以再补充一些活动图(整体流程)、序列图(操作发生的时间顺序),还可以根据需要补充状态机图、组件图。
这个设计过程就是面向对象设计的标准做法,有很多相关的图书。我推荐 Peter Coad 写的一本薄薄的旧书《面向对象的设计》。Peter Coad 是面向对象分析、面向对象设计领域的宗师级人物。他写的所有图书都不厚,言简意赅,值得反复阅读。也非常适合 Sam Altman 近期访谈中强调的“边做边学”。
前面我已经说过,架构设计的各个环节其实也是增量迭代式的,而不是一次性瀑布式的。如果严格按照瀑布式的方式来做领域模型设计,很容易陷入设计瘫痪状态。贪大求全,一味追求完美设计,试图在设计阶段捕捉到所有的细节并且加以考虑,其实没有一个架构师能够做到。我们识别出来上图中的这些实体,其实已经足以展开一轮迭代开发了。然后我们带着开发过程中获得的知识,再继续补充识别出来的其他实体,进入下一轮迭代开发。如此循环往复,步步为营,稳扎稳打。
应用的关系数据库设计
完成了一个阶段的领域模型设计,我们可以基于最终获得的详细类图,来画数据库设计的 ER 图。把类图中的类映射到关系数据库的表中,这个工作叫做 O-R Mapping(对象-关系映射)。有很多映射策略,最简单的映射策略是 ActiveRecord,适用于简单的业务系统。我们这个 AI 助理应用,使用 ActiveRecord 策略就足够了。
此外还有 DataMapper 等更复杂的设计策略,适用于复杂的系统。关于 O-R Mapping 的映射策略,可以参考 Martin Fowler 的名著《企业应用架构模式》(Patterns of Enterprise Application Architecture, PoEAA)。
具体的 ER 图我就不画了。按照 ActiveRecord 策略,将上面的类图映射到数据库设计,会生成 Employee、Idea、Basket、Action、Project、CheckList、RelevantSystsm、ToolConfig、ToolInvoke、ReviewReport、PerformanceSummary 11 张表。
总结时刻
这节课我先介绍了应用软件架构设计包括的工作,然后确定了 AI 助理的应用类型和技术选型,接下来我们介绍了编写 AI 助理的架构设计文档中最重要的两部分:领域模型设计和关系数据库设计。
从这节课中,我们可以看到,即使是设计开发自主型智能体,我们仍然可以沿用 DDD、OOD 等成熟的软件设计方法,这些设计方法与 LLM、AI 并无任何矛盾之处,反而相得益彰。认为学习了 LLM 应用开发就可以完全抛弃 DDD、OOD 的想法是幼稚的。没有 DDD、OOD 的指导,LLM 生成的代码甚至架构设计仍然是低质量的,可能会充满隐患。
下节课中我们将进入开发阶段,来基于 AutoGPT Platform 来实现一些基础 Block,并测试相关的提示词。
思考题
LLM 应用的架构设计文档,应该包括哪些内容?有哪些内容是与 AI 直接相关的?
欢迎你把你的想法分享到留言区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!