18 企业员工AI助理开发前的扫雷工作
你好,我是李锟。
上节课,我初步讲解了企业员工 AI 助理的技术架构设计。一节课的篇幅无法讲解完一个真实企业应用架构设计的全貌,不过好在设计和开发是迭代式的 ,我们还有机会回来完善设计,这个应用复杂度不太高,不必过于追求设计文档的完备性。
与 UI 设计团队密切协作
在应用的详细需求文档完成后,可以同时并行开展的两项工作是应用的 UI 设计和技术架构设计。UI 设计可以划分为两个阶段:
- UI 原型设计:使用某种 UI 原型设计工具(例如墨刀)设计出界面原型。与团队成员讨论。
- 详细 UI 设计:基于讨论通过的 UI 原型设计,完成详细 UI 设计。再次与团队成员讨论。
虽然 UI 设计和技术架构设计这两项工作是并行开展的,然而应用架构师需要密切关注 UI 设计的工作,并且积极参与相关讨论,因为 UI 设计也会影响到架构设计方面的一些决策。
AI 助理的 UI 设计除了传统的那种 GUI 外,还需要支持全新的 NUI (Natural User Interface,自然用户界面),AI 助理的 UI 有一半是传统 GUI,另一半是 NUI。团队的开发人员也有必要学习一下 NUI 的特点和相关技术,其中最重要的就是 VUI (语音用户界面)。与 VUI 直接相关的技术是语音语言模型 (Speech LM),我们需要延续上节课的工作,对语音语言模型做一个技术选型。
语音语言模型的技术选型
在 LLM 出现前的传统 NLP 应用开发时代,语音输入、语音输出是两个细分产品线,分别叫做 ASR(Automatic Speech Recognition 自动语音识别,又名 STT,Speech to Text 语音转文本)和 TTS(Text to Speech,文本转语音)。这两个产品线都有很多不同厂商的产品,收费和免费的产品都有。有些 ASR 产品收费很高,自然有它的价值,例如非常好地支持多种语言(中文、英文、日文等)混合、普通话+方言混合等等。一个支持语音输入输出的 NLP 应用的处理流程为:ASR -> NLU (自然语言理解) -> 执行识别出的相关的业务逻辑 -> NLG (自然语言生成) -> TTS。
这些 ASR 和 TTS 产品有三种部署方式:
- 部署在中心云,通过远程 API 访问。
- 私有化部署,部署在企业私有云或局域网内,通过远程 API 访问。
- 部署在终端设备上,通过本地 API 调用。显然这种方式只适合部署尺寸很小的模型,其能力也严重受限。
从 AI 助理这个应用的运行环境来看,最适合它的 ASR 和 TTS 产品部署方式,是上述第二种方式。然而商业化的 ASR 和 TTS 产品要做私有化部署,成本会非常高。因此我们应该选择开源的 ASR 和 TTS 产品。幸运的是,时至今日这样的产品已经有不少了。其中最老牌的开源语音语言模型产品是 OpenAI 的 Whisper,甚至早于 2022 年公认的 LLM 元年。进入 LLM 时代之后,这方面的开源产品仍然层出不穷,例如阿里云的 Qwen2-Audio、智谱 AI 的 GLM-4-Voice 等等。
此外,因为 ASR 和 TTS 的应用场景非常广阔,在现代 Web 浏览器中,有一个相关规范叫做 Web Speech API,就是用来实现 ASR 和 TTS 的。各种桌面版的 Web 浏览器都已经支持了这个规范,然而移动设备的 Web 浏览器对这个规范的支持参差不齐。我使用桌面版 Chrome 浏览器测试过这个 API,发现存在以下问题:
- 调用这个 API,默认是转发到不同浏览器对应的云端服务来实现 ASR 和 TTS,而不是在本地完成。例如 Chrome 调用的是谷歌对应的云端服务。众所周知,传说中的谷歌云端服务在我国是不存在的。
- 因为上述原因,Chrome、Firefox、Edge 等主流浏览器内建的 Web Speech API 默认访问在国外的云端服务,所以对于中文语音的支持比英文语音差得多,而且延迟较大,也很容易出错。
不过 Web Speech API 除了访问默认的云端 ASR 和 TTS 服务外,还可以配置为访问私有化部署的 ASR 和 TTS 服务,例如访问我们私有化部署的 Whisper 服务。以下我们将 ASR 和 TTS 这两类产品统称为语音语言模型产品。
进入了 LLM 时代之后,最初的 LLM 也是只支持文本输入,后来出现了能够同时支持语音、图片输入的 LLM,也就是多模态 (multi-modal) 的 LLM。目前各大基础 LLM 开发商都有自己的多模态 LLM。直接访问多模态 LLM,因为减少了一步语音转文本的转换过程,可以大幅降低应用响应的延迟。
然而遗憾的是直接支持文本 + 语音 + 图片输入的开源多模态 LLM 对硬件配置要求比较高,不大适合普通的开发者。而通过远程 API 访问云端的多模态 LLM,一方面是有一些费用,另一方面会影响应用的性能和可伸缩性,因此我们就不考虑这个方向了。不过我们在架构设计层面需要留出一些灵活性,以便于未来更实用的开源多模态 LLM 出现后,AI 助理可以很容易地切换到使用这种产品。
综上所述,我决定选择 OpenAI 的 Whisper 作为 AI 助理使用的语音语言模型产品。
在这节课的后半部分,我们再次进入实战环节,基于上节课确定的技术选型做一些探索性的开发。解决掉 AI 助理开发过程中马上会遇到的两个主要难点。
上节课中我们选择了 AutoGPT Platform 作为 Autonomous Agent 开发框架。AutoGPT Platform 不支持多模态的输入/输出,因此我们需要自行解决这个问题(其实 MetaGPT、Swarm 和其他绝大多数 Autonomous Agent 开发框架目前都不支持多模态输入,仅支持文本输入)。AI 助理的 UI 部分应该完全脱离 AutoGPT Server,把 AutoGPT Server 当作一个可以通过 API 调用的后台服务来使用。
因此我们马上面临的两个技术难点是:
- 如何支持多模态的输入/输出?首先是要支持语音的输入/输出。
- 如何通过 API 访问 AutoGPT Server?
在本地部署和使用 Whisper
前面我们已经确定使用 OpenAI 的 Whisper 来支持语音的输入/输出。Whisper 是知名度最高的开源语音语言模型产品,而且支持很多种语言。
Whisper 依赖 ffmpeg,因此在 Linux 主机上,需要先安装 ffmpeg:
Whisper 自身只提供了 Python 语言的开发库。17 课里我们确定了 AI 助理的客户端应用将开发为 PWA 应用,使用的是 JavaScript 语言。因此我们除了安装 Whisper 外,还需要再安装一个 Whisper 的 WebUI 产品,支持通过浏览器调用 Whisper。PWA 应用把用户的语音录制下来,然后传到服务器端做转换。这个 Whisper 的 WebUI 产品最好,非常简单,便于我们在其基础上做二次开发。
幸运的是,我找到了一个满足条件的开源项目 whisper-website,支持通过 Web 浏览器访问 Whisper。而且这个项目的服务器端使用的就是 FastAPI,和上节课我们确定的技术选型一致。从拿来主义的角度,我们可以基于这个项目来开发 AI 助理的 Web 应用。
首先我们基于 whisper-website 的代码来创建 AI 助理的 Python 项目。
cd ~/work
git clone https://github.com/Kabanosk/whisper-website.git
cp -R whisper-website/src ai-assistant
cd ai-assistant
touch README.md
poetry init
因为众所周知的原因,我建议使用国内的 Python 库镜像服务器,例如上海交大的镜像服务器:
如果上海交大镜像服务器的访问速度很慢,也可以使用其他镜像服务器,你可以自己搜索其他镜像服务器的地址。
然后安装 AI 助理需要使用的 Python 库:
poetry add pysocks socksio
poetry add $(cat ../whisper-website/requirements.txt)
poetry add uvicorn fastapi ffmpeg srt llvmlite numba stable-ts deep-translator python-multipart torch
poetry install --no-root && poetry run pip install -e "../AutoGPT/autogpt_platform/backend" --config-settings editable_mode=compat
测试一下 whisper 命令能否访问:
如果执行后没有报错,说明 whisper 命令已经可以使用。
然后从网上下载一个做测试的音频文件:
cd ~/work/ai-assistant
mkdir audios
wget -O audios/test_audio.mp3 -c https://gitee.com/mozilla88/autonomous_agent/raw/master/lesson_18/test_audio.mp3
下载的这个音频文件是电影《让子弹飞》中的一段台词,我们可以用这个文件测试一下 whisper 的 ASR 能力究竟如何。台词的内容可参考:《让子弹飞》的台词。
在使用 whisper 之前,我们需要下载一些模型文件。可以先下载如下 3 个模型文件,对应 small、medium、large-v3-turbo 三个模型:
mkdir ~/.cache/whisper
wget -c -O ~/.cache/whisper/small.pt https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt
wget -c -O ~/.cache/whisper/medium.pt https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt
wget -c -O ~/.cache/whisper/large-v3-turbo.pt https://openaipublic.azureedge.net/main/whisper/models/aff26ae408abcba5fbf8813c21e62b0941638c5f6eebfb145be0c9839262a19a/large-v3-turbo.pt
如果模型文件没有提前下载,其实 Whisper 库在执行时也会自动下载的。那么为何我们还要提前下载呢?那是因为 Whisper 库不支持断点续传,下载较大的模型文件(超过 1GB)时非常容易断掉。而 使用 “wget -c” 命令下载是支持断点续传的。
然后用刚才下载的《让子弹飞》台词片段做一下测试:
mkdir outputs
poetry run whisper audios/test_audio.mp3 --model small --language Chinese --output_dir ./outputs
whisper 花了一些时间来处理 test_audio.mp3。然后生成了各种格式的字幕文件,在 outputs 子目录中生成了 json、srt、tsv、txt、vtt 5 个格式的输出文件。
我们打开一个输出文件看一下,例如 test_audio.srt,与音频文件和前面的台词内容参考做一下对比,看看识别的效果。small 是 Whisper 默认使用的模型。除了 small 外,可以选择的模型还有小于 small 的 tiny、base,大于 small 的 medium、large 等等,详见 Whisper 的官方文档。
我们再试一下另外两个模型文件 medium、large-v3-turbo 的识别效果。
poetry run whisper audios/test_audio.mp3 --model medium --language Chinese --output_dir ./outputs
poetry run whisper audios/test_audio.mp3 --model large-v3-turbo --language Chinese --output_dir ./outputs
对于这个测试音频文件来说,确实是模型越大,识别效果越好。large-v3-turbo 是三个模型里面识别效果最好的。
对于英文语音,small 模型就足够了。对于中文语音,至少要使用 medium 模型。从开发角度,本地开发环境可以使用 medium 模型来开发。而测试环境、生产环境可以使用更大的模型。
下图是 Whisper 默认的 small 模型对于不同语言的错误率。
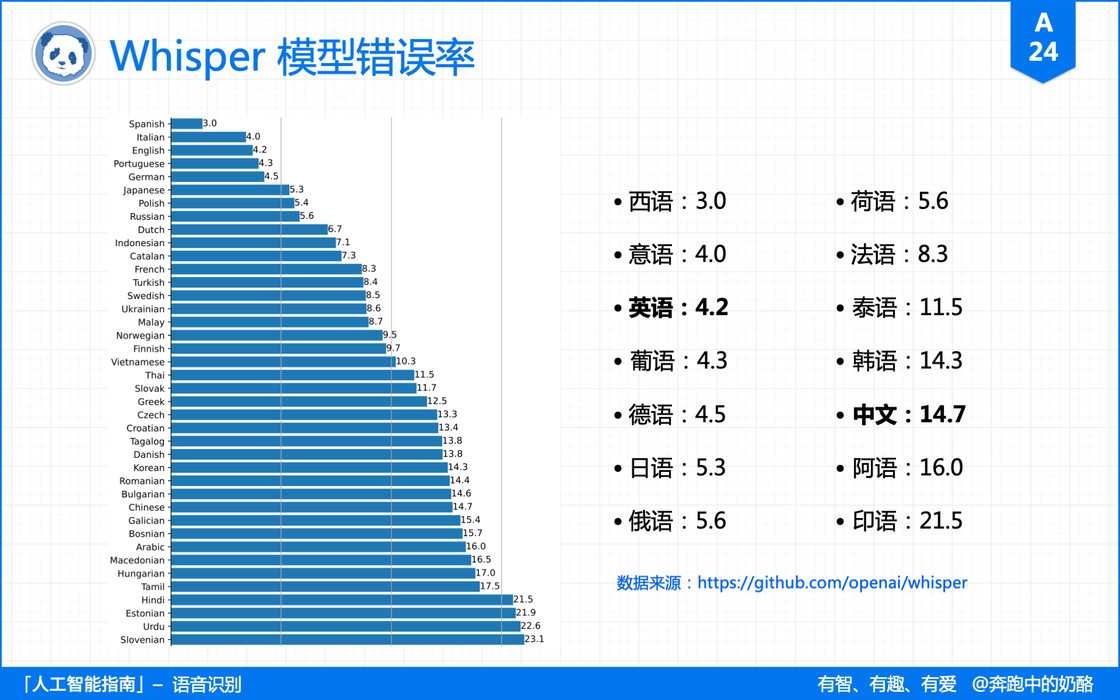
关于 Whisper 有 3 篇不错的文档,你可以参考一下:
接下来我们把 AI 助理的 Web 应用跑起来,测试一下如何通过 Web 浏览器访问 Whisper。
运行 AI 助理的 Web 应用之前,我们需要修改一下这个文件 ~/work/ai-assistant/run.py。以下是修改之后的文件内容:
from pathlib import Path
from time import sleep
import uvicorn
import webbrowser
from multiprocessing import Process
def open_browser():
webbrowser.open('http://127.0.0.1:8000')
def run_localhost():
uvicorn.run('main:app', host='0.0.0.0', port=8000)
if __name__ == '__main__':
# open_browser_proc = Process(target=open_browser)
run_localhost_proc = Process(target=run_localhost)
Path("../data").mkdir(parents=True, exist_ok=True)
run_localhost_proc.start()
sleep(2)
# open_browser_proc.start()
运行 AI 助理的 Web 应用:
Web 应用运行于 Linux 主机的 8000 端口。在另外一台客户端机器,打开浏览器,访问:http://<server_host_ip>:8000。server_host_ip 需要替换为 Linux 主机的 IP 地址。
正常的测试页面如下:
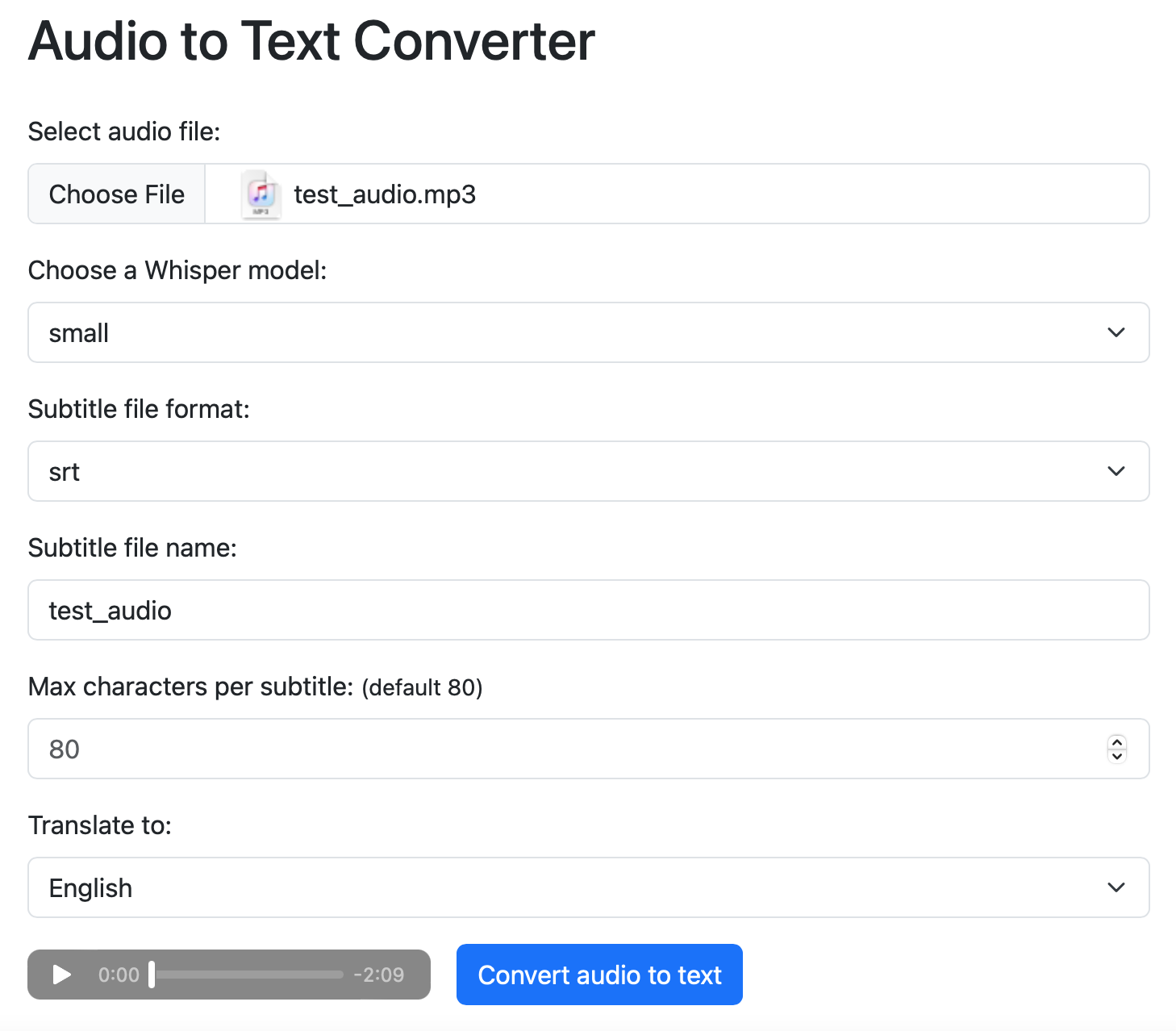
我们还是使用刚才用的那个《让子弹飞》台词片段做一下测试,模型先使用 small。需要注意的是,这个例子 Web 应用在调用服务器本地部署的 Whisper 做完语音识别之后,还会调用 Google Translate API 把识别后的文件翻译为其他语言(这里是翻译为英语),因此运行这个 Web 应用的 Linux 主机需要先解决好访问 Google Translate API 的问题。
如果运行正常,测试页面会下载一个翻译为英文的 srt 字幕文件(《让子弹飞》台词片段的英文版)。
如何在 Web 浏览器中使用 JavaScript 录制语音并上传到服务器,网上有很多例子,你可以自行搜索。我们接下来需要做的是实现在网页中输入文本 + 语音,在服务器端调用 Whisper 库将语音转换为文本,与其他文本输入合并在一起。然后再调用 LLM 分析用户的输入,根据其输入生成对应的 idea 或 action 条目(见上节课的领域模型设计),保存到数据库中。
通过 RESTful API 调用 AutoGPT Platform
现在我们有了一个支持语音输入的 Web 应用(基于 FastAPI + Whisper 实现),我们还要把这个 Web 应用与 AutoGPT Server 连接起来。
在 AutoGPT Server 中运行的 Agent 除了可以通过客户端浏览器中 Agent Builder 图形界面来启动外,还可以通过 RESTful API 来启动。不过目前 AutoGPT Server 对于通过 RESTful API 启动的支持还比较弱,需要我们自己做一些 DIY。
在 09 课中,我们开发过一个简单的例子 get_wikipedia_summary.py。这节课我们还是使用这个例子中的 MyWikipediaSummaryBlock 创建一个简单的 Agent,然后再通过 RESTful API 来调用这个简单的 Agent。
首先启动 AutoGPT Server:
然后在客户端机器上启动 AutoGPT Frontend(详见 06 课、07 课)。
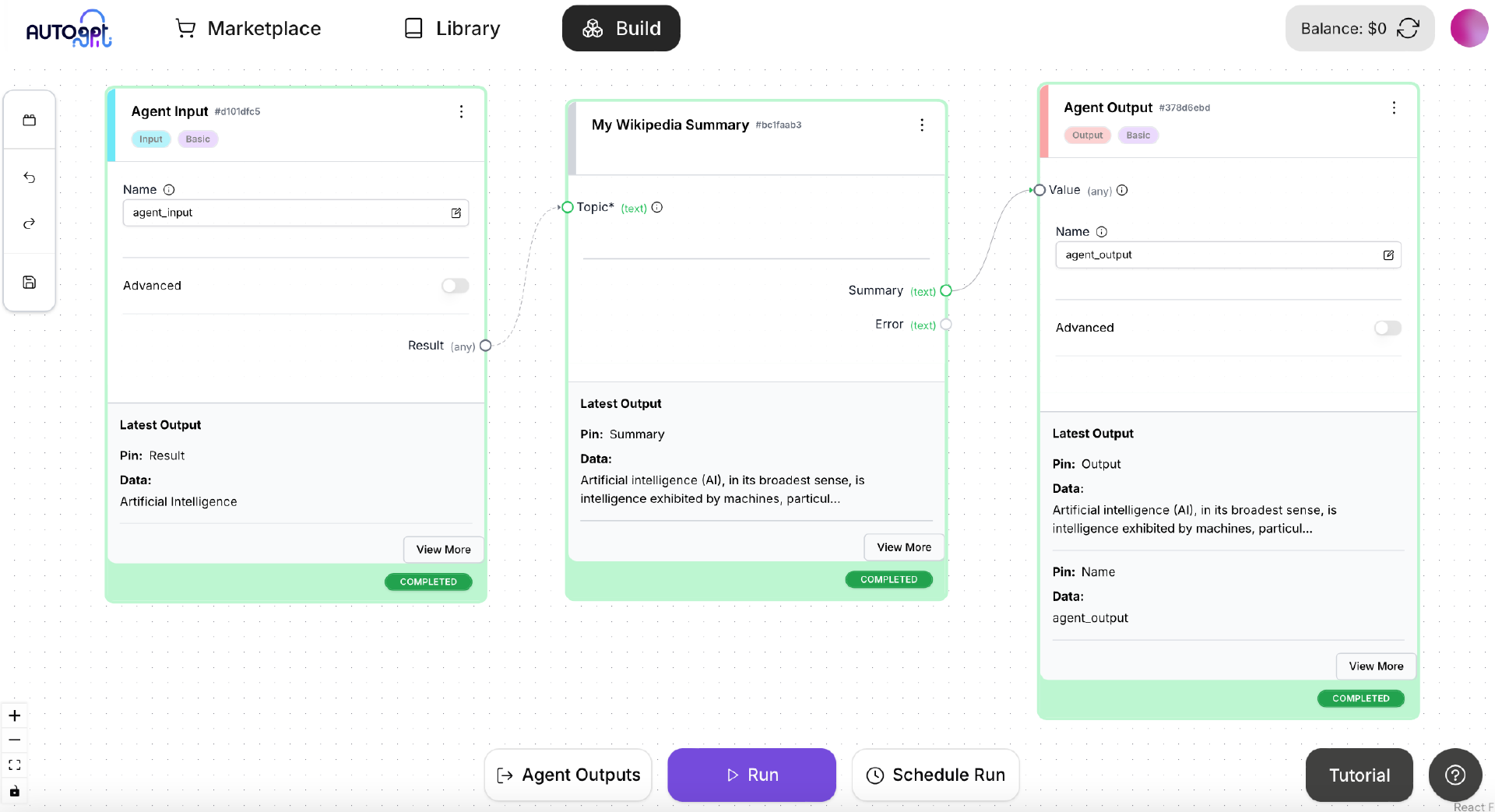
如上图所示,在 Agent Builder 中使用 MyWikipediaSummaryBlock 创建一个 Agent,包括 AgentInput 和 AgentOutput。保存这个 Agent,然后点击 Run 按钮测试是否运行正常。我们要通过 RESTful API 调用一个 Agent,首先必须确保这个 Agent 在 Agent Builder 能够正常运行。
要通过 RESTful API 来调用 AutoGPT Server 中的一个 Agent,至少需要两个信息:
- 这个 Agent 对应的 graph_id。每个 Agent 对应于一个通过 Agent Builder 创建的 DAG 图,所以可以使用 这个图的 graph_id 来作为 Agent 的唯一标识。
- 创建这个 Agent 的登录用户的 user_id。每个 Agent 都有一个所属用户。
我们可以通过 PostgreSQL 客户端去数据库中查到这两个信息。
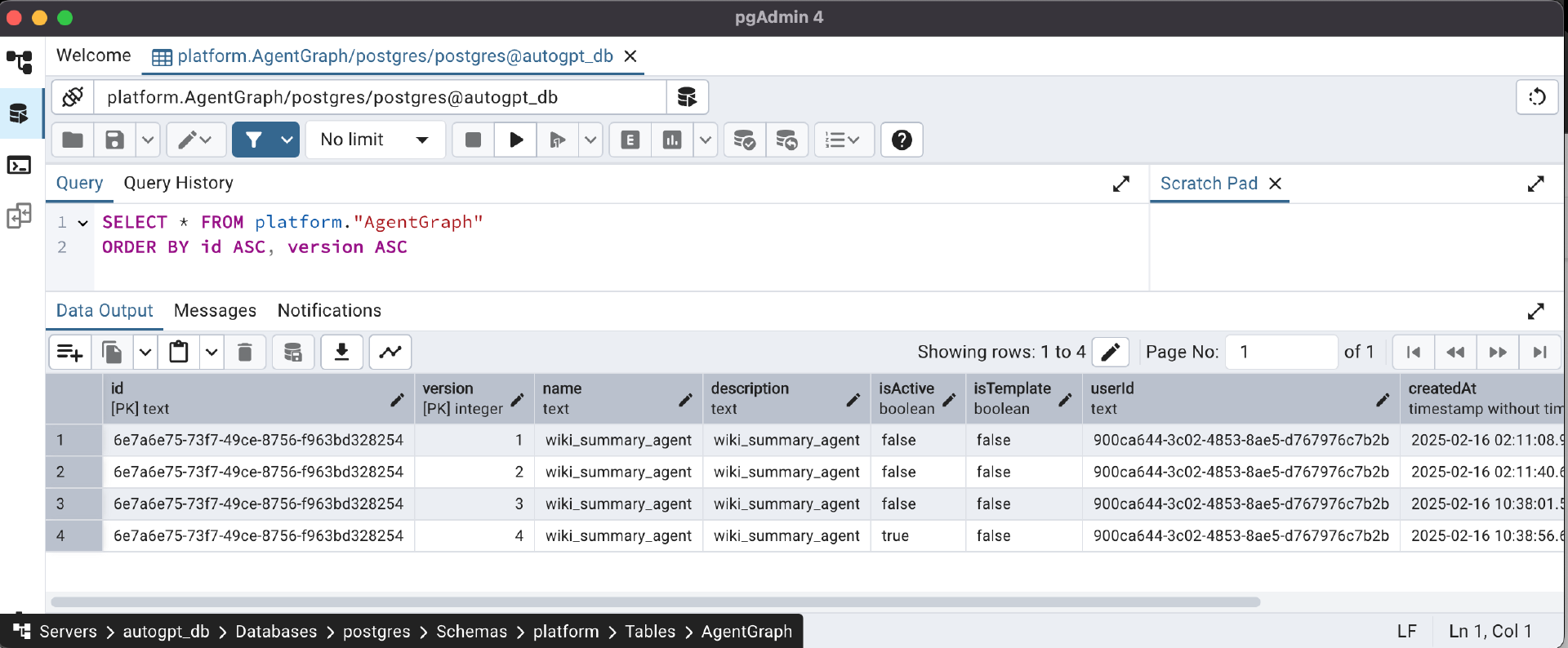
以使用 pgAdmin4 为例,如图所示,我们可以查询 platform.AgentGraph 这张表,只看 isActive 为 true 的记录。其中的 id 和 userId 就是我们需要的 graph_id 和 userId,记录下这两个信息。
为了使用 RESTful API 调用 Agent,需要对 AutoGPT Server 的代码做两个修改。第一个修改是 backend/server/routers/v1.py 文件。
找到 def execute_graph 这个函数。修改为以下内容:
def execute_graph(
graph_id: str,
node_input: dict[Any, Any],
user_id: Annotated[str, Depends(get_user_id)],
graph_version: Optional[int] = None,
) -> ExecuteGraphResponse:
try:
# added by Li Kun at 2025-02-16
if len(node_input) > 0 and 'user_id' in node_input:
user_id = node_input['user_id']
graph_exec = execution_manager_client().add_execution(
graph_id, node_input, user_id=user_id, graph_version=graph_version
)
return ExecuteGraphResponse(graph_exec_id=graph_exec.graph_exec_id)
except Exception as e:
msg = e.__str__().encode().decode("unicode_escape")
raise HTTPException(status_code=400, detail=msg)
其中加了注释 “added by Li Kun at 2025-02-16” 的代码是添加的内容。这里做的事情是,当通过 RESTful API 调用时,使用从外部传入的 user_id。
第二个修改是 backend/executor/manager.py 文件。
找到 “def add_execution” 这个函数,修改其中这一段内容。
# Extract request input data, and assign it to the input pin.
if block.block_type == BlockType.INPUT:
name = node.input_default.get("name")
if name in data.get("node_input", {}):
input_data = {"value": data["node_input"][name]}
# added by Li Kun at 2025-02-16
if block.block_type == BlockType.STANDARD:
for name in node.input_default:
if name in data.get("node_input", {}):
input_data[name] = data["node_input"][name]
其中加了注释 “added by Li Kun at 2025-02-16” 的代码是添加的内容。这里做的事情是使用外部传入的值取代 Block 的 默认输入值。对于 MyWikipediaSummaryBlock 来说,它有两个输入 topic 和 credentials。我们需要使用外部传入的 topic,取代 Agent Builder 中设置的默认 topic “Artificial Intelligence”。而 credentials 可沿用 Agent Builder 中设置的默认 credentials(这里是 api_key,详见 09 课内容)。
然后创建一个测试 RESTful API 的命令行工具 customized_cli.py,这个文件可以从 gitee 下载。
在 customized_cli.py 中目前我们仅使用以下代码:
@test.command()
@click.argument("graph_id")
@click.argument("content")
def execute(graph_id: str, content: dict):
"""
Execute an event graph
"""
import requests
headers = {"Accept": "application/json", "Content-Type": "application/json"}
execute_url = f"http://0.0.0.0:8006/api/graphs/{graph_id}/execute/2"
# res = requests.post(execute_url, headers=headers, json=content)
s = requests.session()
s.headers = headers
resp = s.post(execute_url, json=json.loads(content))
if resp.status_code == 200:
resp.encoding = "utf-8"
print(f"{resp.text}")
@test.command()
@click.argument("graph_id")
@click.argument("graph_exec_id")
def execute_result(graph_id: str, graph_exec_id: str):
"""
Get execution result of an event graph
"""
import requests
headers = {"Accept": "application/json"}
execute_url = f"http://0.0.0.0:8006/api/graphs/{graph_id}/executions/{graph_exec_id}"
# res = requests.get(execute_url, headers=headers)
s = requests.session()
s.headers = headers
resp = s.get(execute_url)
if resp.status_code == 200:
resp.encoding = "utf-8"
print(f"{resp.text}")
其中的 execute() 函数用来启动一个 Agent,execute_result() 函数用来获取 Agent 执行的结果,都是通过调用 AutoGPT Server 的 RESTful API 来实现的。
在 AI 助理的 Web 应用内部通过 RESTful API 调用 AutoGPT Server 时,是不需要登录的,因此 AutoGPT Server 应该以无身份认证模式来启动。
修改一下 AutoGPT Server 的配置文件 .env,将其中的 ENABLE_AUTH=true 改为ENABLE_AUTH=false,然后重新启动 AutoGPT Server。
使用 customized_cli.py 中的 execute() 函数启动一个 Agent 的运行:
cd ~/work/AutoGPT/autogpt_platform/backend
poetry run python customized_cli.py test execute 6e7a6e75-73f7-49ce-8756-f963bd328254 '{"user_id":"900ca644-3c02-4853-8ae5-d767976c7b2b", "node_input": {"topic": "Artificial Intelligence"}}'
注意,在命令中有两个 uuid,第一个是 Agent 的 graph_id,第二个是 user_id。
输出的结果如下:
记下这个 graph_exec_id,后面会用到。
在 AutoGPT Server 中运行某个 Agent 是异步方式实现的,这样可以确保服务的可伸缩性。在启动某个 Agent 的运行后,可以通过 RESTful API 来轮询 Agent 执行的结果。
使用 customized_cli.py 中的 execute_result() 函数获得 Agent 的运行状态和运行结果:
poetry run python customized_cli.py test execute-result 6e7a6e75-73f7-49ce-8756-f963bd328254 38dea71f-8e22-4a11-9692-f8e8b9a72075
注意,在命令中有两个 uuid,第一个是 Agent 的 graph_id,第二个是前面启动 Agent 的运行后,AutoGPT Server 返回的 graph_exec_id。
得到如下结果:
[{"graph_id":"6e7a6e75-73f7-49ce-8756-f963bd328254","graph_version":2,"graph_exec_id":"d4c8e54f-b118-4406-bea5-2e045ae3fe8c","node_exec_id":"2598aa96-594b-4aeb-aa5a-30b68b495e54","node_id":"0ef64e79-4eef-4762-a0ce-d0ce6a5fdd00","block_id":"b05aa1e2-2ebc-4a7d-b71c-07802d6642bc","status":"COMPLETED","input_data":{"topic":"Artificial Intelligence","credentials":{"id":"c3812d5b-6f78-4506-8b45-fe7e4741e05a","title":"wiki_api_key","provider":"github","type":"api_key"}},"output_data":{"summary":["Artificial intelligence (AI), in its broadest sense, is intelligence exhibited by machines, particularly computer systems. It is a field of research in computer science that develops and studies methods and software that enable machines to perceive their environment and use learning and intelligence to take actions that maximize their chances of achieving defined goals. Such machines may be called AIs."]},"add_time":"2025-02-18T04:10:57.937000Z","queue_time":"2025-02-18T04:10:58.007000Z","start_time":"2025-02-18T04:11:01.173000Z","end_time":"2025-02-18T04:11:02.255000Z"}]
结果的 “summary” 部分就是 Wikipedia API 返回的对于人工智能这个标题的摘要。
总结时刻
在这节课中,我们首先确定了语音语言模型(Speech LM)的技术选型为 OpenAI 的 Whisper。然后在 Linux 主机上部署并测试了 Whisper 的命令行工具,还测试了通过浏览器来调用 Whisper。接下来我们解决了通过 RESTful API 来调用 AutoGPT Server 中的第一个关键问题:启动一个 Agent 的运行并获得 Agent 运行的状态和结果。
解决这两个技术难题为我们后续的开发铺平了道路。在下一课中,我们来开发 AutoGPT Server 中的 Agent 和相关的 Block。
思考题
单独的语音语言模型产品(包括 ASR 和 TTS产品),与多模态的 LLM 产品相比,各自有哪些优缺点?欢迎你在留言区交流你的看法,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!